Netflix уменьшил время аварийного переключения с 45 до 7 минут без каких-либо затрат

Изображение: Florida Memory. Доработано Opensource.com. CC BY-SA 4.0
Зимой 2012 года Netflix пережил длительный сбой, уйдя в отключку на семь часов из-за проблем с сервисом AWS Elastic Load Balancer в регионе US-East (Netflix работает на AWS — у нас нет собственных дата-центров. Всё ваше взаимодействие с Netflix происходит через AWS, кроме самого потокового видео. Как только вы нажмете Play, начинает загружаться видеопоток из нашей собственной сети CDN). Во время сбоя ни один пакет из региона US-East не доходил до наших серверов.
Чтобы такого больше не повторилось, мы решили создать систему аварийного переключения, устойчивую к сбоям базовых поставщиков услуг. Аварийное переключение (failover) — это система обеспечения отказоустойчивости, когда в случае сбоя основной системы автоматически активируется резервное оборудование.
Мы расширились на три региона AWS: два в США (US-East и US-West) и один в Евросоюзе (EU). Зарезервировали достаточно ресурсов для переключения, если один регион выйдет из строя.
Типичная отработка отказа выглядит следующим образом:
- Понять, что один из регионов испытывает проблемы.
- Масштабировать два спасательных региона.
- Проксировать трафик спасателям из проблемного региона.
- Изменить DNS из проблемного региона на спасателей.
Изучим каждый шаг.
1. Определить наличие проблемы
Нужны метрики, а лучше одна метрика, которая говорит о здоровье системы. В Netflix используется бизнес-метрика «запуски потоков в секунду» (stream starts per second, сокращённо SPS). Это число клиентов, успешно запустивших потоковую трансляцию.
Данные сегментированы по регионам. В любой момент времени можно построить график SPS для каждого региона — и сравнить текущее значение со значением за прошлый день или неделю. Когда мы замечаем падение SPS, то знаем, что клиенты не в состоянии запустить потоковую трансляцию — следовательно, у нас проблема.
Проблема необязательно связана с облачной инфраструктурой. Это может быть плохой код в одном из сотен микросервисов, которые составляют экосистему Netflix, обрыв подводного кабеля и т. д. Мы можем не знать причину: мы просто знаем, что-то не так.
Если падение SPS произошло только в одном регионе, то это отличный кандидат для аварийного переключения. Если в нескольких регионах, то не повезло, потому что мы в силах эвакуировать только один регион за раз. Именно поэтому мы разворачиваем микросервисы в регионах по очереди. Если возникла проблема с развёртыванием, можно немедленно эвакуироваться и исправить проблему позже. Точно так мы хотим избежать сбоя, если проблема сохранится после перенаправления трафика (как это происходит в случае DDoS-атаки).
2. Масштабировать спасателей
После того, как мы определили пострадавший регион, нужно подготовить другие регионы («спасателей») к переводу трафика. До начала эвакуации нужно соответствующим образом масштабировать инфраструктуру в регионах спасателей.
Что означает масштабирование в данном контексте? Шаблон трафика Netflix меняется в течение дня. Есть пиковые часы, как правило, в районе 6−9 вечера, но в разных частях мира это время наступает в разный момент. Пик трафика в регионе US-East наступает на три часа раньше, чем в регионе US-West, который на восемь часов отстаёт от региона EU.
При аварийном отключении US-East мы направляем трафик с Восточного побережья в регион EU, а трафик из Южной Америки — в US-West. Это необходимо для уменьшения задержки и наилучшего качества работы сервиса.
Принимая это во внимание, можно использовать линейную регрессию для прогнозирования трафика, который будет направляться в регионы спасателей в это время суток (и дня недели), используя историческое данные масштабирования каждого микросервиса.
После того, как мы определили соответствующий размер для каждого микросервиса, мы запускаем для них масштабирование, устанавливаем желаемый размер каждого кластера — и позволяем AWS сделать свою магию.
3. Прокси для трафика
Теперь, когда кластеры микросервисов масштабированы, мы начинаем проксировать трафик из пострадавшего региона в регионы спасателей. Netflix разработал высокопроизводительный межрегиональный пограничный прокси-сервер под названием Zuul, который мы выложили с открытым исходным кодом.
Эти прокси предназначены для аутентификации запросов, сброса нагрузки, повтора неудачных запросов и т. д. Прокси-сервер Zuul может выполнять и проксирование между регионами. Мы используем эту функцию, чтобы перенаправить трафик от пострадавшего региона, а затем постепенно увеличить количество перенаправленного трафика, пока оно не достигнет 100%.
Такое прогрессивное проксирование позволяет сервисам использовать свои правила масштабирования для реагирования на входящий трафик. Это нужно для компенсации любого изменения трафика между моментом, когда произведён прогноз масштабирования и временем, нужным для масштабирования каждого кластера.
Zuul делает трудную работу, перенаправляя входящий трафик от пострадавшего в здоровые регионы. Но наступает момент, когда нужно полностью отказаться от использования пострадавшего региона. Здесь вступает в игру DNS.
4. Смена DNS
Последний шаг в аварийной эвакуации — обновление DNS-записей, указывающих на пострадавший регион, и перенаправление их в рабочие регионы. Это полностью переведёт туда трафик. Клиентов, не обновивших DNS-кэш, по-прежнему будет перенаправлять Zuul в пострадавшем регионе.
Таково общее описание процесса, как происходит эвакуация Netflix из региона. Раньше процесс занимал много времени — около 45 минут (если повезёт).
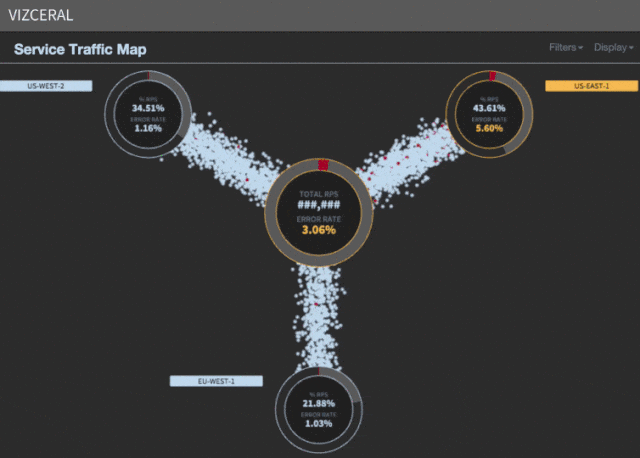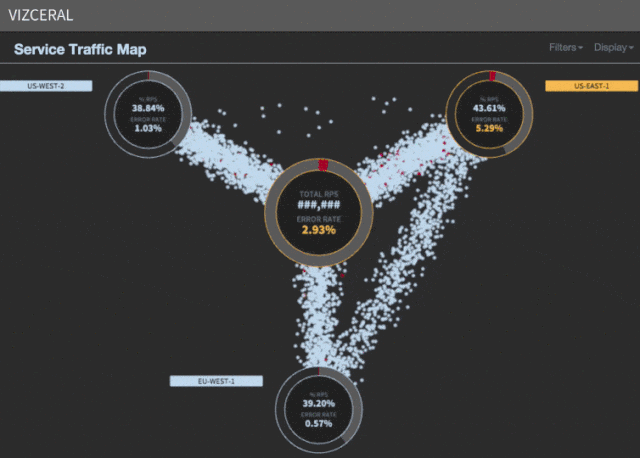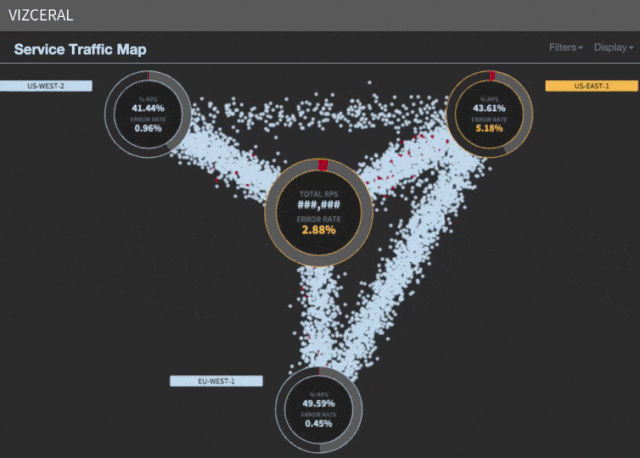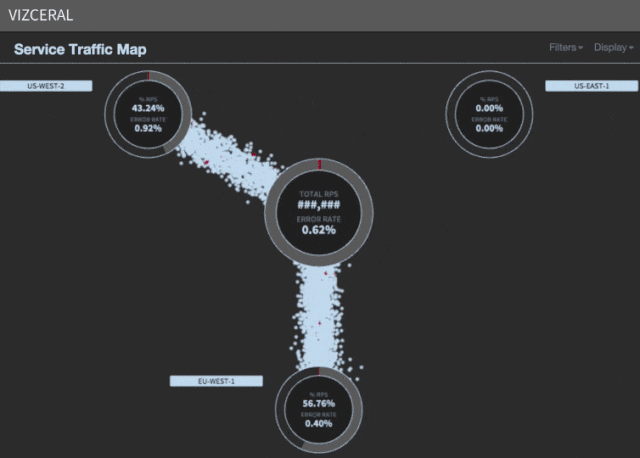
Мы заметили, что бóльшая часть времени (примерно 35 минут) уходит на ожидание масштабирования спасательных регионов. Хотя AWS может предоставлять новые инстансы в течение нескольких минут, но в процессе масштабирования львиную долю времени отнимают запуск сервисов, разогрев, а также обработка других необходимых задач, прежде чем будет зарегистрирован UP в discovery.
Мы решили, что это слишком долго. Хотелось бы, чтобы эвакуация занимала менее десяти минут. И хотелось бы оптимизировать процесс без дополнительной операционной нагрузки. Также нежелательно увеличивать финансовые расходы.
Мы резервируем мощности во всех трёх регионах на случай отказа одного. Если мы уже платим за эти мощности, почему бы не использовать их? Так стартовал Project Nimble (проект «Шустрик»).
Идея заключалась в том, чтобы поддерживать в «горячем» резерве пул инстансов для каждого микросервиса. Когда мы готовы к миграции, то просто внедряем «горячий» резерв в кластеры, чтобы принять текущий трафик.
Неиспользованная зарезервированная ёмкость называется «кормушкой» (trough). Некоторые команды разработчиков Netflix иногда используют часть «кормушки» для своих пакетных заданий, поэтому мы просто не можем взять её целиком в горячий резерв. Но можно поддерживать теневой кластер для каждого микросервиса, чтобы в каждое время суток впритык хватало инстансов для эвакуации трафика, если такая необходимость возникнет. Остальные инстансы доступны для пакетных заданий.
Во время эвакуации вместо традиционного масштабирования AWS мы внедряем инстансы из теневого кластера в рабочий кластер. Процесс занимает около четырёх минут, в отличие от прежних 35-ти.
Поскольку такая инъекция проходит быстро, то не нужно осторожно перемещать с помощью прокси, чтобы правила масштабирования успевали реагировать. Мы можем просто переключить DNS — и открыть шлюзы, тем самым сэкономив ещё несколько драгоценных минут во время простоя.
Мы добавили фильтры в теневой кластер, чтобы эти инстансы не попадали в отчёты метрик. Иначе они загрязнят метрики и собьют нормальное рабочее поведение.
Мы также убрали регистрацию UP для инстансов из теневых кластеров, изменив наш клиент обнаружения. Инстансы останутся в тени, пока не начнётся эвакуация.
Теперь мы производим аварийное переключение региона всего за семь минут. Поскольку используются существующие зарезервированные мощности, то мы не несём никаких дополнительных затрат на инфраструктуру. Программное обеспечение для аварийного переключения написано на Python командой из трёх инженеров.
Комментариев нет:
Отправить комментарий