
Этот пост является введением в мой проект "самодельной" консольной видеоприставки сделаной с нуля. Я вдохновлялся как ретро консолями так и современными образцами, но у меня получилась своя собственная архитектура. Мои друзья постоянно мне говорили, что я должен рассказать о своём проекте, а не делать всё исключительно "для себя", так что вот я публикую этот пост.
Меня зовут Серхио Виейра (Sérgio Vieira) я выроc в Португалии в 80-е и 90-е годы, у меня давно ностальгия по ретро-геймингу, особенно по приставкам третьего и четвертого поколения.
Несколько лет назад я решил получше разобраться в электронике и попытаться сделать свою собственную приставку.
По профессии я программист и не имел никакого опыта как электронщик, если не считать (и не стоит этого считать) самостоятельных апгрейдов своего десткопа.
Хотя у меня и не было опыта, я сказал себе "почему бы и нет?", купил несколько книжек, несколько наборов электронщика и начал изучать исходя из своих ощущений о том, что именно стоит изучать.
Я хотел сделать приставку похожую на те которые вызывают у меня ностальгические чувства, я хотел что-то между NES и Super Nintendo, или может между Sega Master System и Mega Drive.
У этих приставок были CPU, оригинальный видео чип (тогда их ещё не называли GPU) и аудио чип, иногда встроеный, а иногда внешний.
Игры распространялись на картриджах, которые в общем были расширениями железа иногда просто ROM чипами, а иногда имели дополнительные компоненты.
Изначальный план был сделать приставку со следущими характеристиками:
- Без эмуляции, игры и программы должны работать на настоящем железе, не обязательно том самом из тех времён, но достаточно быстром для задачи, и не более того.
- С настоящим ретро CPU.
- С аналоговым ТВ выходом.
- Со звуком
- С поддержкой двух контроллеров
- Скроллинг бэков и анимация спрайтов
- С возможностями для поддержки платформерных игр вроде Mario, ну и конечно всяких других игр.
- С загрузкой игр и программ с SD карт.
Почему именно SD карты, а не картриджи, ну в основном просто так намного практичнее, их можно копировать с компа. А картриджи это значило бы, во-первых больше железа в приставке, а во-вторых производить железо для каждой программы.
Видео сигнал
Первое чем я занялся это генерация видео сигнала.
Любая консоль того периода который я взял за образец имела различные проприетарные графические чипы, что означает, что у всех у них были различные технические характеристики.
По этой причине я не хотел использовать готового графического чипа, я хотел чтобы и моя консоль имела уникальные технические характеристики по графике. И поскольку я не мог сделать свой собственный графический чип, и в то время ещё не умел использовать FPGA, я решил ограничиться софтварным генерированием графического сигнала используя 8-битный, 20 мегагерцовый микроконтроллер.
Это не перебор, и как раз достаточно мощное решение для графики того уровня который мне был интересен.
И так, я начал использовать микроконтроллер Atmega644 на чистоте 20 Мгц для генерации видеосигнала в формате PAL для телевизора. Мне пришлось бит-бангить протокол PAL, поскольку сам чип не умеет его.


Микроконтролл выдаёт 8-битный цвет (RGB332, 3 бита красный, 3 бита зелёный и 2 синий) и пассивный ЦАП преобразует это всё в RGB. К счастью в Португалии почти все телевизоры оборудованы разъёмом SCART и они поддерживают RGB вход.
Правильная графическая подсистема
Поскольку микроконтроллер довольно мощный, а использовать его я решил исключительно для генерации видео сигнала (я назвал это VPU — Video Processing Unit), то я решил заодно организовать дабл-буфер.
У меня получилось что второй микроконтроллер (PPU, Picture Processing Unit, чип Atmega1284 тоже на 20 МГц) генерировал картинку в микросхему ОЗУ номер 1 (я назвал её VRAM1), а первый в это же время отправлял содержимое второй микросхемы (VRAM2) в телевизор.
После одного кадра, а два кадра в системе PAL это 1/25 секунды, VPU переключает VRAM-ы и они меняются местами, PPU генерирует картинку в VRAM2, а VPU дампит VRAM1 на ТВ вывод.
Видео плата получилась очень сложной поскольку мне пришлось использовать внешнее железо чтобы оба микроконтроллера могли пользоваться обоими модулями памяти и чтобы ускорить доступ к ОЗУ, ведь там тоже бит-бангинг, так что пришлось добавить чипы 74 серии как счётчики, line-селекторы, трансиверы и тд.
Прошивки для VPU и PPU тоже получились громоздкие поскольку пришлось писать много кода чтобы выжать максимум скорости из графики. Сначала всё было написано на ассемблере, потом часть была переписана на Си.

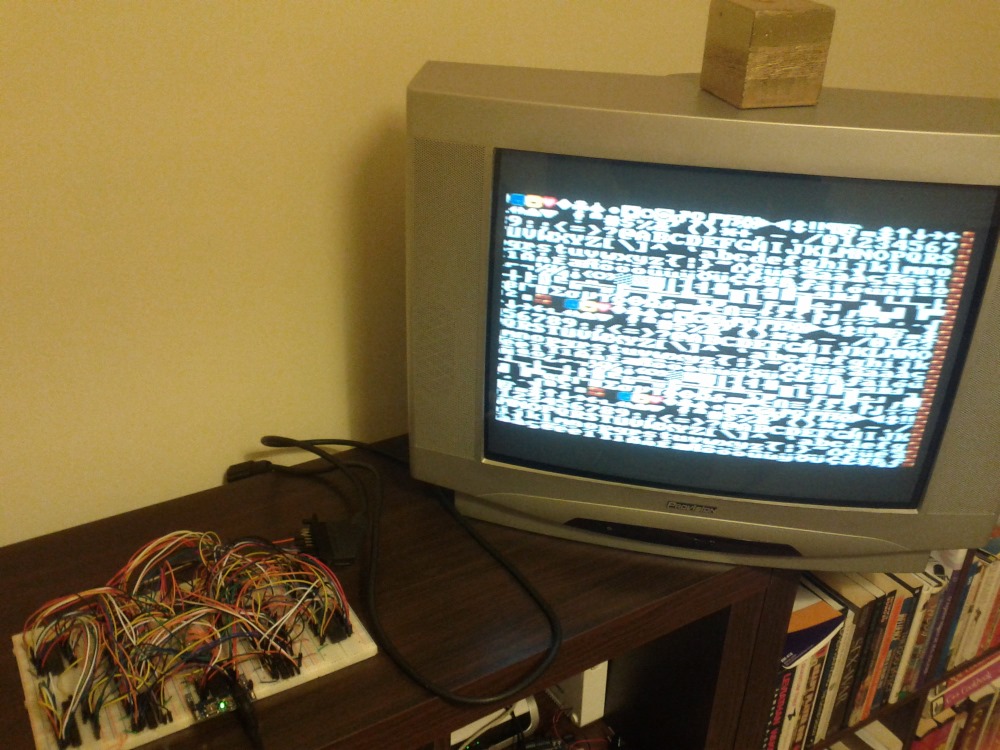
В результате PPU генерирует картинку 224x192 пикселей, которая потом отпраляется на ТВ через VPU. Может разрешение вам покажется низким, но вообще-то это почти столько, сколько консоли того времени имели на самом деле, обычно 256x224. Несколько меньшее разрешение зато позволило мне добавить больше фич которые система успевает просчитать за один кадр.
Как и в старину, PPU имеет свою жёсткую механику которой надо уметь пользоваться. Подложка (бэк) рендерится из символов 8x8 пикселей, так же называемых тайлами. Получается что размер бэкграунда 28х24 тайла.
Чтобы бэк могл скролится плавно, попиксельно, я сделал так что всего есть 4 виртуальных экрана, каждый по 28х24 тайла которые идут в памяти последовательно и обёрнуты вокруг друг друга, на картинке это понятнее.


Поверх бэкграунда, PPU может отрендерить 64 спрайта которые могут быть 8 или 16 пикселей по высоте или ширине, то есть 1, 2 или 4 тайла и ещё могут быть флипнуты горизонтально и/или вертикально.
Сверху бэка можно ещё рендерить оверлеем один буфер размером 28х6 тайлов, это было задумано для отрисовки HUD-ов, скоров так чтобы не мешать основным спрайтам и скроллингу бэка.
Одна "продвинутая" фича в том, что бэк можно скролить не целиком, а каждую линию в отдельности, что позволяет всякие интересные эффекты вроде сплит скрина или почти-параллакса.
Ещё есть таблица аттрибутов, которая позволяет задавать каждому тайлу значение от 0 до 3, и потом можно всем тайлам с одним аттрибутом задать страницу тайлов или инкрементировать их символьное значение. Это удобно когда есть части бэка которые надо регулярно изменять и CPU не придётся обсчитывать каждый тайл в отдельности, ему достаточно только сказать что-то вроде: "все тайлы с аттрибутом 1 инкрементируйте числовое значение своего символа на 2", подобные вещи реализованые разными техниками можно наблюдать, например, в блочных тайлах в Mario где знак вопроса анимируется или в играх где есть водопад в котором все тайлы постоянно меняются создавая эффект падающей воды.
CPU
Когда моя видеоплата заработала, я начал работать с CPU в качестве которого для моей приставки был выбран Zilog 80.
Одна из причин по который был выбран именно Z80, ну кроме того, что это класный ретро CPU, это его способность адресовать два 16 битных пространства, одно для памяти и второе для портов ввода-вывода, не менее легендарный 6502, например, так не может, он может только одно адресовать 16 битное пространство и в него приходится мапить как память так и различные внешние устройства, видео, аудио, джойстики, апаратный генератор случайных чисел и тд. Удобнее иметь два адресных пространства, одно полность отданное на 64 килобайта кода и данных в памяти и второе для доступа к внешним устройствам.
Сначала я подсоединил CPU к EEPROM в котором разместилась моя тестовая программка и ещё присоединил его через пространство ввода-вывода к микроконтроллеру который я установил чтобы можно было общаться с моим компом через RS232, и мониторить как работает CPU и всё остальное. Этот микроконтроллер Atmega324 работающий на 20 МГц я называю IO MCU — input/output microcontroller unit, он отвечает за контроль доступа к игровым контроллерам (джойстикам), SD карт ридеру, клавиатуре PS/2 и коммуникатору по RS232.

CPU подключается к микросхеме памяти на 128 килобайт, из которых только 56 килобайт доступны, это конечно бред, но я мог достать только микросхемы по 128 или 32 килобайта. Получилось, что память состоит из 8 килобайт ПЗУ и 56 килобайт ОЗУ.
После этого я обновил прошивку IO MCU с помощью этой библиотеки и у меня появилась поддержка SD карт ридера.
Теперь CPU мог ходить по директориям, смотреть что в них лежит, открывать и читать файлы. Всё это делается посредством записи и чтения в определённые адреса пространства ввода-вывода.
Подключение CPU к PPU
Следущее, что я сделал это связь между CPU и PPU. Для этого я применил "простое решение" которое заключалось в приобретении двухпортового ОЗУ, это такая микросхема ОЗУ которую можно подключать сразу к двум разным шинам. Это позволяет избавиться он дополнительных микросхем вроде лайн-селекторов и, к тому-же, позволяет практически одновременный доступ к памяти с обоих чипов. Ещё PPU напрямую может обращаться к CPU на каждом кадре активируя свои немаскируемые прерывания. Получается, что CPU получает прерывание на каждом кадре, что полезно для разных задач по таймингу и для понимания когда пора заняться апдейтом графики.
Каждый кадр взаимодествия CPU, PPU и VPU происходит согласно следующей схеме:
- PPU копирует информацию из памяти PPU в внутреннюю память.
- PPU отправляет сигнал прерывания на CPU.
- Одновременно:
- CPU прыгает на функцию прерывания и начинает обновлять PPU память новым графическим состоянием. Программа должна вернуться из прерывания до следующего кадра.
- PPU рендерит картинку на основании информации ранее скопированой в одну из VRAM.
- VPU отправляет картинку из другой VRAM на ТВ выход.
Примерно тогда же я занялся поддержкой игровых контроллеров, сначала я хотел использовать контроллеры от Nintendo, но сокеты для них проприетарные и вообще их трудно найти, поэтому я остановился на 6-кнопочных контроллерах совместимых с Mega Drive/Genesis, у них стандартные сокеты DB-9 которые везде есть.

Написание первой настоящей игры
В это время у меня уже был CPU способный контролировать PPU, работать с джойстиками, читать SD карточки… пора было писать первую игру, конечно на ассемблере Z80, у меня на это ушло несколько дней из свободного времени.
Добавляем динамическую графику
Всё было супер, у меня была своя игровая приставка, но мне этого было мало, потому-что приходилось в игре использовать графику прошитую в памяти PPU и нельзя было нарисовать тайлы для конкретной игры и изменить её можно было только перепрошив ПЗУ. Я стал думать как добавить ещё памяти, чтобы CPU в неё мог бы загружать символы для тайлов, а PPU потом мог оттуда это всё считывать и как это сделать попроще поскольку приставка и так уже получалась сложной и большой.
И я придумал следущее: только PPU будет иметь доступ к этой новой памяти, а CPU будет загружать туда данные через PPU и пока этот процесс загрузки происходит, эта память не может быть использована для отрисовки, но можно будет в это время рисовать из ПЗУ.
После конца загрузки CPU переключит внутреннюю ПЗУ память на эту новую память, которую я назвал Character RAM (CHR-RAM) и в этом режиме PPU начнет рисовать динамическую графику, это наверное не лучшее решение, но оно работает. В результате новая память была установлена 128 килобайт и может хранить 1024 символа 8х8 пикселей каждый для бэкаграунда и ещё столько-же символов для спрайтов.

И наконец звук
До звука руки дошли в последнюю очередь. Сперва я хотел звук наподобие того что есть в Uzebox, то есть чтобы микроконтроллер генерировал 4 канала ШИМ-звука.
Однако, оказалось, что я могу легко достать винтажные чипы и я заказал несколько микросхем FM синтеза YM3438, эти ребята полностью совместимы с YM2612 которые использовались в Mega Drive/Genesis. Установив их можно получить музыку качества Mega Drive и звуковые эффекты производимые микроконтроллером.
Я установил ещё один микроконтроллер и назвал его SPU (Sound Processor Unit), он управляет YM3438 и сам может генерировать звуки. CPU управляет им через двух-портовую память, в этот раз она всего 2 килобайта.
Как и в графическом блоке, звуковой блок имеет 128 килобайта памяти для хранения PCM сэмплов и звуковых патчей, CPU загружает данные в эту память обращаясь к SPU. Получилось, что CPU либо говорит SPU исполнять комманды из этой памяти или обновляет комманды для SPU каждый кадр.
CPU управляет четырьмя ШИМ каналами через четыре циркулярных буфера находящихся в памяти SPU. SPU проходит через эти буферы и исполняет комманды записаные в них. Ещё есть один такой-же буфер для микросхемы FM синтеза.
Итого, как и в графике взаимодействие между CPU и SPU идёт согласно схеме:
- SPU копирует данные из памяти SPU во внутреннюю память.
- SPU ждёт сигнала прерывания от PPU (это для синхронизации)
- Одновременно
- CPU обновляет буферы ШИМ каналов и буферы FM синтезатора.
- SPU исполняет комманды в буферах согласно данным во внутренней памяти.
- Одновременно со всем этим, SPU обновляет ШИМ звуки на частоте 16 килогерц.

После того как все блоки были готовы, некоторые пошли на макетные платы.
Для блока CPU я смог разработать и заказать кастомную PCB, не знаю стоит ли сделать это и для остальных модулей, думаю мне на самом деле повезло, что моя PCB сразу заработала.
На макетной плате сейчас (пока) остался только звук.
Вот как всё выглядит на сегодняшний день:

Архитектура
Диаграмма иллюстрирует компоненты в каждом блоке и как они взаимодействуют друг с другом. Единственное, что не показано это сигнал от PPU к CPU на каждом кадре в виде прерывания и такой-же сигнал который идёт в SPU.
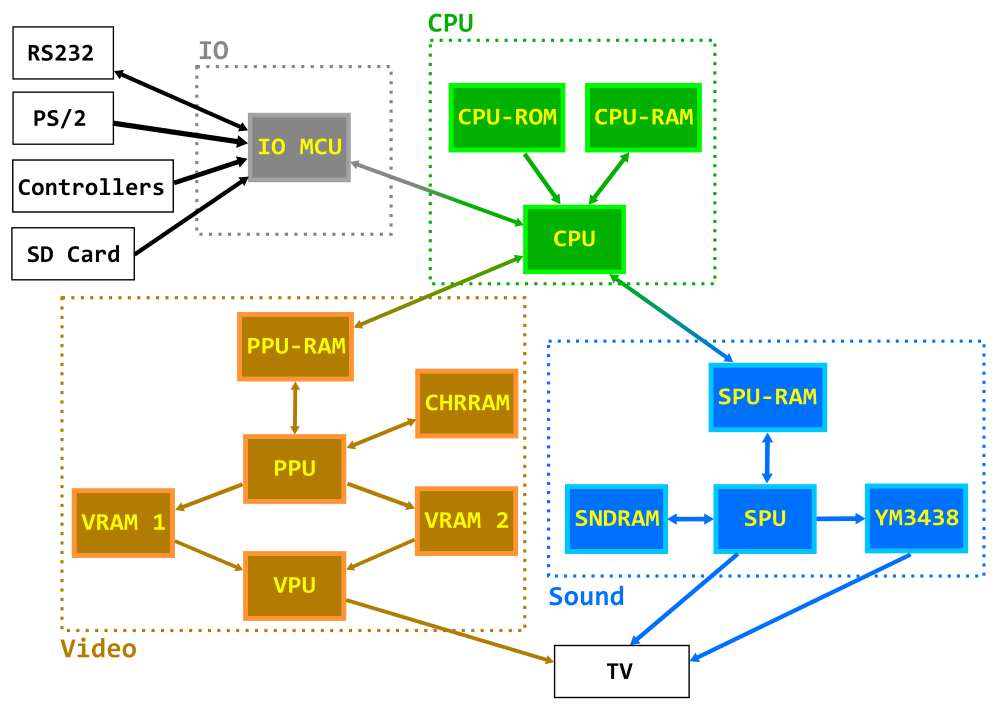
- CPU: Zilog Z80 на 10 МГц
- CPU-ROM: 8KB EEPROM, содержит код загрузчика
- CPU-RAM: 128KB RAM (56KB доступных), код и данные для программ/игр
- IO MCU: Atmega324, является интерфейсом между CPU и RS232, клавиатурой PS/2, джойстиками и файловой системой SD карт
- PPU-RAM: 4 килобайта двухпортовой памяти, промежуточная память между CPU и PPU
- CHR-RAM: 128KB RAM, хранит динамические тайлы для бэка (подложки) и спрайтов (в символах по 8x8 пикселей).
- VRAM1, VRAM2: 128KB RAM (43008 реально доступно), используются для фреймбуфера в них пишет PPU и читает из них VPU.
- PPU (Picture Processing Unit): Atmega1284, рисует кадр во фреймбуфер.
- VPU (Video Processing Unit): Atmega324, читает фреймбуфер и генерирует RGB и PAL сигнал и синхронизацию.
- SPU-RAM: 2KB двухпортовая RAM, служит интерфейсом между CPU и SPU.
- SNDRAM: 128KB RAM, хранит ШИМ патчи, PCM сэмплы и блоки инструкций для FM синтезатора.
- YM3438: YM3438, микросхема FM синтеза.
- SPU (Sound Processing Unit): Atmega644, генерирует звуки на принципе широтно-импульсной-модуляции (ШИМ) и управляет YM3438.
Окончательные спецификации
CPU:
- 8-bit CPU Zilog Z80 на частоте 10Mhz.
- 8KB ROM для загрузчика.
- 56KB RAM.
IO:
- Чтение данных с FAT16/FAT32 SD карт ридера.
- Чтение/запись в порт RS232.
- 2 MegaDrive/Genesis-совместимых игровых контроллера.
- Клавиатура PS2.
Видео:
- Разрешение 224x192 пикселя.
- 25 кадров в секунду (половина FPS от PAL).
- 256 цветов (RGB332).
- 2x2 виртуальная подложка (448x384 пикселей), с двунаправленым по-пиксельным скроллингом, на базе четырёх полноэкранных страниц.
- 64 спрайта с шириной и высотой 8 или 16 пикселей с возможностью как вертикального так и горизонтального флипа.
- Подложка и спрайты состоят из символов по 8х8 пикселей каждый.
- Символьная видеопамять на 1024 символа для бэкграунда и 1024 для спрайтов.
- 64 независимых горизонтальных скроллинга по задаваемым линиям
- 8 независимых вертикальных скроллингов по задаваемым линиям
- Оверлей на 224х48 пикселей с опциональной прозрачностью по цветовому ключу.
- Таблица аттрибутов бэкграунда.
- RGB и композитный PAL через разъём SCART.
Звук:
- ШИМ на 8 бит и 4 канала, с встроенными вейвформами: квадрат, синус, пила, шум и тд.
- Сэмплы на 8 бит, 8 КГц в одном из ШИМ каналов.
- Микросхема FM синтеза YM3438 загружаемая инструкциями на частоте 50 герц.
Для приставки был написан загрузчик. Загрузчик помещается в CPU ПЗУ и может занимать до 8 килобайт. Он использует первые 256 байт ОЗУ. Загрузчик это первое, что исполняет CPU. Он нужен чтобы показать программы находящиеся на SD карте.
Эти программы находятся в файлах которые содержат скомпилированый код и могут также содержать графику и звук.
После выбора программы она загружается в память CPU, память CHR и память SPU. После чего программный код исполняется. Максимальный размер кода загружаемого в приставку 56 килобайт, кроме первых 256 байт и конечно надо учесть место для стека и данных.
И этот загрузчик и другие программы написаные для этой приставки создавались одинаковым нижеописаным способом.
Memory/IO Mapping
Что важно при разработке под эту приставку, так это учитывать как CPU обращается к различным блокам, и правильно распределять адресное пространство ввода вывода и адресное пространство памяти.
CPU обращается к оперативной и постоянной памяти загрузчика через адресное пространство памяти.
Адресное пространство памяти

А к PPU-RAM, SPU-RAM и IO MCU через адресное пространство ввода-вывода.
Адресное пространство ввода-вывода
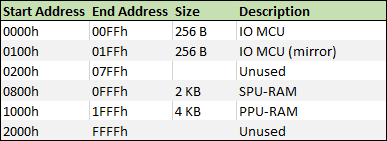
Как видно из таблицы, внутри адресного пространства ввода-вывода выделены адреса для всех устройств, IO MCU, PPU и SPU.
Управление PPU
Из информации в таблице видно, что для управления PPU надо писать в память PPU которая доступна по адресам 1000h-1FFFh в адресном пространстве ввода-вывода.
Распределение адресного пространства PPU

PPU Status может принимать следущие значения:
- Режим вшитой графики
- Режим динамической графики (CHR-RAM)
- Режим записи в CHR память
- Запись завершена, ждём подтверждения режима от CPU
Вот, например, как можно работать со спрайтами:
Приставка может рисовать 64 спрайта одновременно. Данные по ним доступны через CPU через адресное пространство ввода-вывода по адресам 1004h-1143h (320 байт), на каждый спрайт приходится 5 байт информации (5 * 64 = 320):
- Байт разных флагов, каждый бит этого байта флаг: Active, Flipped_X, Flipped_Y, PageBit0, PageBit1, AboveOverlay, Width16, Height16.
- Байт символа, номер символа из таблицы (определяемой флагами выше).
- Байт цветового ключа (то есть какой цвет — прозрачность)
- Байт координаты X
- Байт координаты Y
Итого, чтобы увидеть спрайт, надо установить флаг Active в 1, и задать координаты X и Y в пределах видимости, координаты 32/32 помещают спрайт в верхний левый угол экрана, меньшие значения спрячут его либо сделают частично видимым.
Потом мы можем установить код символа и цвет прозрачности.
Например, если нам нужно показать спрайт номер 10, то адрес будет 4145 (1004h + (5 x 9)), пишем значение 1 для активирования и координаты, например, x=100 и y=120, пишем по адресу 4148 значение 100 и по адресу 4149 значение 120.
Используем ассемблер
Один из способов программирования для приставки это ассемблер.
Вот пример как показать один спрайт и анимировать его чтобы он двигался и отталкивался от краёв экрана.
ORG 2100h
PPU_SPRITES: EQU $1004
SPRITE_CHR: EQU 72
SPRITE_COLORKEY: EQU $1F
SPRITE_INIT_POS_X: EQU 140
SPRITE_INIT_POS_Y: EQU 124
jp main
DS $2166-$
nmi: ; обработчик немаскируемого прерывания (NMI)
ld bc, PPU_SPRITES + 3
ld a, (sprite_dir)
and a, 1
jr z, subX
in a, (c) ; увеличить X
inc a
out (c), a
cp 248
jr nz, updateY
ld a, (sprite_dir)
xor a, 1
ld (sprite_dir), a
jp updateY
subX:
in a, (c) ; уменьшить X
dec a
out (c), a
cp 32
jr nz, updateY
ld a, (sprite_dir)
xor a, 1
ld (sprite_dir), a
updateY:
inc bc
ld a, (sprite_dir)
and a, 2
jr z, subY
in a, (c) ; увеличить Y
inc a
out (c), a
cp 216
jr nz, moveEnd
ld a, (sprite_dir)
xor a, 2
ld (sprite_dir), a
jp moveEnd
subY:
in a, (c) ; уменьшить Y
dec a
out (c), a
cp 32
jr nz, moveEnd
ld a, (sprite_dir)
xor a, 2
ld (sprite_dir), a
moveEnd:
ret
main:
ld bc, PPU_SPRITES
ld a, 1
out (c), a ; активировать спрайт 0
inc bc
ld a, SPRITE_CHR
out (c), a ; задать символ спрайту 0
inc bc
ld a, SPRITE_COLORKEY
out (c), a ; установить цветовой ключ спрайту 0
inc bc
ld a, SPRITE_INIT_POS_X
out (c), a ; установить координату Х спрайту 0
inc bc
ld a, SPRITE_INIT_POS_Y
out (c), a ; установить координату Y спрайту 0
mainLoop:
jp mainLoop
sprite_dir: DB 0
Использование языка Си
Можно также использовать язык Си, для этого нам понадобится компилятор SDCC и некоторые дополнительные утилиты.
Код на Си может получится медленнее, но зато написать его быстрее и проще.
Вот пример кода, который делает то же самое, что и код на ассемблере выше, тут используется библиотека которая помогает делать вызовы к PPU:
#include <console.h>
#define SPRITE_CHR 72
#define SPRITE_COLORKEY 0x1F
#define SPRITE_INIT_POS_X 140
#define SPRITE_INIT_POS_Y 124
struct s_sprite sprite = { 1, SPRITE_CHR, SPRITE_COLORKEY, SPRITE_INIT_POS_X, SPRITE_INIT_POS_Y };
uint8_t sprite_dir = 0;
void nmi() {
if (sprite_dir & 1)
{
sprite.x++;
if (sprite.x == 248)
{
sprite_dir ^= 1;
}
}
else
{
sprite.x--;
if (sprite.x == 32)
{
sprite_dir ^= 1;
}
}
if (sprite_dir & 2)
{
sprite.y++;
if (sprite.y == 216)
{
sprite_dir ^= 2;
}
}
else
{
sprite.y--;
if (sprite.x == 32)
{
sprite_dir ^= 2;
}
}
set_sprite(0, sprite);
}
void main() {
while(1) {
}
}
Динамическая графика
(В оригинале Custom graphics. прим. пер.)
В ПЗУ приставки зашиты 1 страница тайлов для бэка и ещё страница готовых спрайтов), по умолчанию можно использовать только эту фиксированую графику, однако можно переключиться на динамическую.
Цель у меня была такая, чтобы вся необходимая графика в бинарной форме сразу грузилась в оперативную память CHR, причём делать это умеет код в загрузчике из ПЗУ. Для этого я сделал несколько кратинок правильного размера с разными полезными символами:
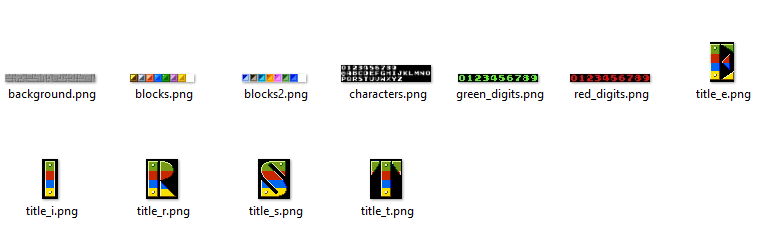
Поскольку память динамической графики состоит из 4-х страниц по 256 символов 8х8 пикселей каждый и 4-х страниц таких же символов для спрайтов, я перевёл картинки в PNG формат, удалил повторяющиеся одинаковые:

И потом использовал самописную тулзу чтобы перевести это всё в бинарный формат RGB332 с блоками 8х8.

В результате имеем файлы с символами, где все символы идут последовательно один за другим и каждый занимает по 64 байта.
Звук
Волновые RAW сэмплы переведены в 8-битный 8-килогерцовые PCM сэмплы.
Патчи для звуковых эффектов на ШИМ и музыки пишутся особыми инструкциями.
Что касается микросхемы FM синтеза Yamaha YM3438, то я нашел программку называемую DefleMask которая выдаёт музыку синхронизируемую по PAL и предназначеную для YM2612 микросхемы из Genesis, которая совместима с YM3438.
DefleMask экспортирует музыку в формате VGM и я её конвертирую ещё одной самописной утилитой в свой собственный двоичный формат.
Все бинарники всех трёх типов звука комбинируются в один двоичный файл, который мой загрузчик умеет читать и загружать в звуковую память SDN RAM.
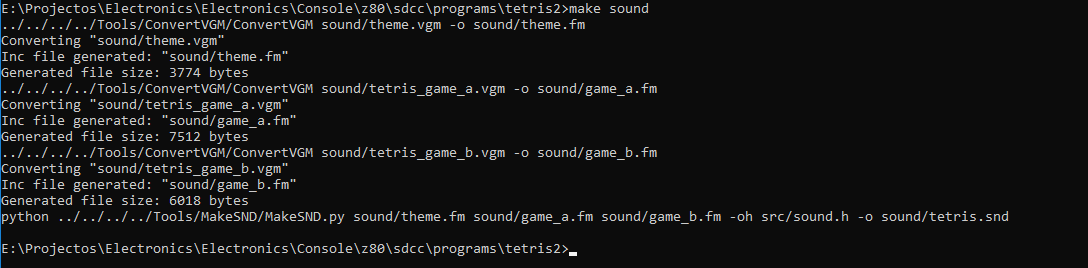
Линковка окончательного файла
Двоичный исполняемый код, графика и звук соединяются в один PRG файл. PRG файл имеет заголовок в котором всё описано, есть ли звуковые и графические данные, сколько они занимают и сами эти данные.
Такой файл можно записать на SD карту и загрузчик приставки считает его и загрузит всё в соотвествующие места и запустит исполняемый код программы.
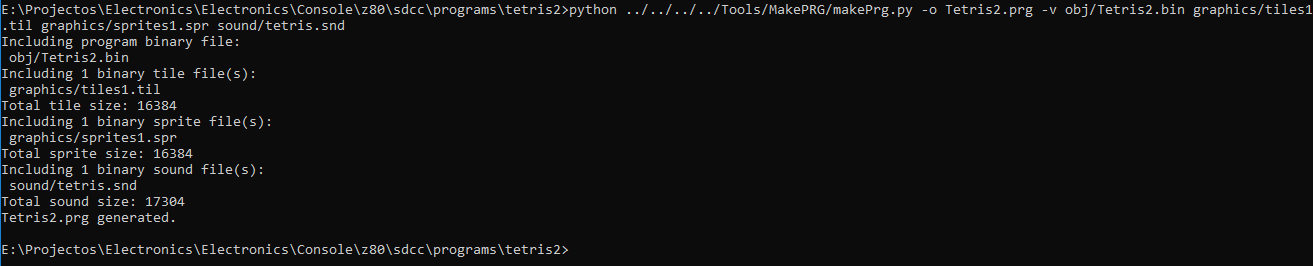
Эмулятор
Я написал эмулятор своей приставки на С++ с применением wxWidgets, чтобы проще было девелопить для неё.
CPU эмулируется библиотекой libz80.
В эмулятор добавлены фичи для отладки, я могу его остановить в любой момент и заняться пошаговой отладкой ассемблера, есть маппинг к исходному коду на Си если для игры был использован этот язык.
По графике, я могу заглянуть в видео память, в таблицы символов и в саму CHR память.
Вот пример программы запущеной на эмуляторе со включёнными средствами отладки.
Эти видео снимались камерой смартфона направленой на экран ЭЛТ телевизора, прошу прощения за неидеальное качество картинки.
Интерпретатор БЭЙСИКа программируемый с PS/2 клавиатуры, после первой программы, я показываю как писать напрямую в память PPU через адресное пространство ввода-вывода активируя и двигая спрайт:
Демка графики, в этом видео программно скачут 64 спрайта 16х16, на фоне бэкграунда с динамическим скроллингом и оверлеем который двигается под и над спрайтами:
Звуковая демка показывает возможности YM3438 и ШИМ звук, звуковые данные этой демки и FM музыка и ШИМ звуки вместе занимают почти все доступные 128 килобайт звуковой памяти.
Тетрис, для графики использваны почти только возможности бэкграунда, музыка на YM3438, звуковые эффекты на ШИМ патчах.
Этот проект поистине воплощение мечты, я над ним работал уже несколько лет, с перерывами, смотря по свободному времени, никогда не думал, что дойду так далеко в создании собственной игровой ретро видео приставки. Она, естественно, не идеальна, я уж точно не эксперт в электронике, в приставке явно вышло слишком много элементов и несомненно можно было сделать лучше и наверное кто-то из читателей как раз об этом думает.
Но всё-же, в процессе работы над этим проектом, я узнал многое об электронике, игровых приставках и дизайне компьютеров, языке ассемблера и других интересных вещах, и главное я получил огромное удовлетворение играя в игры которые я сам написал на железе которое я сам разработал и собрал.
У меня есть планы делать приставки/компьютеры и дальше. Вообще-то, я уже делаю новую приставку, она почти готова, и является упрощёной ретро приставкой на базе FPGA платы и нескольких дополнительных компонетов, (в намного меньшем количестве чем в этом проекте, уж точно), задуманой быть намного дешевле и повторяемее.
Хотя я тут очень много написал об этом проекте, несомненно ещё многое можно обсудить, я едва упомянул как звуковой движок работает, как CPU с ним взаимодействует, да и о графической системе и других входах-выходах и обо всей приставке в целом ещё много чего можно было бы расказать.
Смотря на реакцию читателей я может быть напишу ещё статей сфокусировавшись на обновлениях, подробностях об отдельных блоках приставки или других проектах.
Проекты, сайты, каналы Youtube которые вдохновляли меня и помогали мне с техническими знаниями:
Эти сайты/каналы не только вдохновляли, но и помогли мне найти решения сложных проблем которые возникали по ходу работы над этим проектом.
Спасибо, если дочитали до сюда. :)
Если у вас есть вопросы или фидбек пишите в комментариях внизу (Оригинальной статьи на английском языке на Гитхабе. прим. пер.)
Let's block ads! (Why?)











 Ивао подняла 25 виртуальных машин: «Но вместо того, чтобы нажимать эту кнопку виртуальной машины 25 раз, я автоматизировала её, — объясняет она. — Ты можешь сделать это за пару минут, но если тебе нужно так много компьютеров, то потребуется несколько дней, чтобы всё настроить». Затем непрерывно в течение 121 дня Ивао управляла работой y-cruncher на этих 25 виртуальных машинах.
Ивао подняла 25 виртуальных машин: «Но вместо того, чтобы нажимать эту кнопку виртуальной машины 25 раз, я автоматизировала её, — объясняет она. — Ты можешь сделать это за пару минут, но если тебе нужно так много компьютеров, то потребуется несколько дней, чтобы всё настроить». Затем непрерывно в течение 121 дня Ивао управляла работой y-cruncher на этих 25 виртуальных машинах.







{kind=link}
{kind=link}