Выступления и посты в блогах о производительности JavaScript часто обращают внимание на важность мономорфного кода, однако обычно не дается внятного никакого объяснения, что такое мономорфизм/полиморфизм и почему это имеет значение. Даже мои собственные выступления зачастую сводятся к дихотомии в стиле Невероятного Халка: «ОДИН ТИП ХОРОШО! ДВА ТИП ПЛОХО!». Неудивительно, что когда люди обращаются ко мне за советом по производительности, чаще всего они просят объяснить, что на самом деле такое мономорфизм, откуда берется полиморфизм и что в нем плохого.
Ситуацию осложняет еще и то, что само слово «полиморфизм» имеет множество значений. В классическом объектно-ориентированном программировании полиморфизм связан с созданием дочерних классов, в которых можно переопределить поведение базового класса. Программисты, работающие с Haskell, вместо этого подумают о параметрическом полиморфизме. Однако полиморфизм, о котором предупреждают в докладах о производительности JavaScript – это полиморфизм вызовов функции.
Я объяснял этот механизм столькими различными путями, что наконец-то собрался и написал данную статью: теперь можно будет не импровизировать, а просто дать на нее ссылку.
Я также попробовал новый способ объяснять вещи – изображая взаимодействие составных частей виртуальной машины в виде коротких комиксов. Кроме того, данная статья не покрывает некоторые детали, которые я посчитал незначительными, излишними или не связанными напрямую.
Динамический поиск для чайников

Ради простоты изложения мы будем преимущественно рассматривать самые элементарные обращения к свойствам в JavaScript, как например
o.x в коде ниже. В то же время важно понимать, что всё, о чем мы говорим, относится к любой операции с
динамическим связыванием, будь то обращение к свойству или арифметический оператор, и применимо не только в JavaScript.
function f(o) {
return o.x
}
f({ x: 1 })
f({ x: 2 })
Представьте на минуту, что вы собеседуетесь на отличную должность в ООО «Интерпретаторы», и вам предлагают придумать и реализовать механизм обращения к свойству в виртуальной машине JavaScript. Какой ответ был бы самым банальным и простым?
Сложно придумать что-то проще, чем взять готовую семантику JS из спецификации ECMAScript (ECMA 262) и переписать алгоритм [[Get]] слово в слово с английского языка на C++, Java, Rust, Malbolge или любой другой язык, который вы предпочли использовать для собеседования.
Вообще говоря, если открыть случайный интерпретатор JS, скорее всего можно увидеть нечто наподобие:
jsvalue Get(jsvalue self, jsvalue property_name) {
// 8.12.3 здесь реализация метода [[Get]]
}
void Interpret(jsbytecodes bc) {
// ...
while (/* остались необработанные байткоды */) {
switch (op) {
// ...
case OP_GETPROP: {
jsvalue property_name = pop();
jsvalue receiver = pop();
push(Get(receiver, property_name));
// TODO(mraleph): выкинуть исключение в strict mode, как сказано в 8.7.1 шаг 3.
break;
}
// ...
}
}
}
Это абсолютно правильный способ реализовать обращение к свойству, однако у него есть один значительный недостаток: в сравнении с современными виртуальными машинами JS наша реализация очень медленная.
Наш интерпретатор страдает амнезией: каждый раз при обращении к свойству он вынужден выполнять весь обобщенный алгоритм поиска свойства. Он научится на предыдущих попытках и вынужден каждый раз платить по максимуму. Поэтому виртуальные машины, ориентированные на производительность, реализуют обращение к свойству иначе.
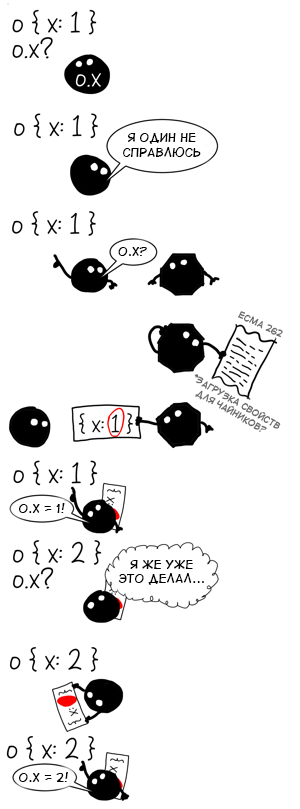
Вот если бы можно было получить информацию о тех объектах, которые мы уже видели, и применить ее к похожим объектам! В теории это позволило бы нам сэкономить уйму времени, используя не общий алгоритм, а наиболее подходящий для объектов конкретной формы.
Мы знаем, что поиск свойства в случайном объекте — трудозатратная операция, поэтому хорошо бы сделать это один раз, а найденный путь закешировать, используя форму объекта в качестве ключа. Когда мы в следующий раз встретим объект той же формы, можно будет получить путь из кеша гораздо быстрее, чем вычислять его с нуля.
Эти техника оптимизации называется инлайн-кешированием и я уже писал про нее раньше. Для данной статьи не будем вдаваться в детали реализации, а обратим внимание на две важные вещи, о которых я раньше умалчивал: как и любой другой кеш, инлайн-кеш имеет размер (количество закешированных элементов в данный момент) и емкость (максимальное количество элементов, которое может быть закешировано).
Вернемся к примеру:
function f(o) {
return o.x
}
f({ x: 1 })
f({ x: 2 })
Сколько записей будет в инлайн-кеше для значения
o.x?
Поскольку {x: 1} и {x: 2} имеют одинаковую форму (она иногда называется скрытый класс), ответ — 1. Именно это состояние кеша мы называем мономорфным, потому что нам попадались объекты только одной формы.
Моно («один») + морф («форма»)
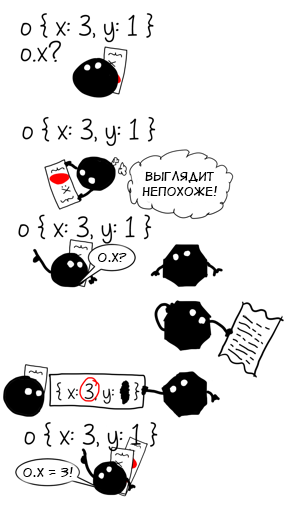
А что случится, если мы вызовем функцию f с объектом другой формы?
f({ x: 3 })
// кеш o.x все еще мономорфен
f({ x: 3, y: 1 })
// а теперь?
Объекты
{x: 3} и
{x: 3, y: 1} имеют разную форму, поэтому наш кеш теперь содержит две записи: одну для
{x: *} и одну для
{x: *, y: *}. Операция стала полиморфной с уровнем полиморфизма, равным двум.
Если мы продолжим передавать в f объекты различных форм, уровень полиморфизма будет расти, пока не достигнет предела емкости для инлайн-кеша (например, в V8 для обращения к свойствам предел емкости будет равен четырем). После этого кеш перейдет в мегаморфное состояние.
f({ x: 4, y: 1 }) // полиморфизм, уровень 2
f({ x: 5, z: 1 }) // полиморфизм, уровень 3
f({ x: 6, a: 1 }) // полиморфизм, уровень 4
f({ x: 7, b: 1 }) // мегаморфизм

Мегаморфное состояние нужно для того, чтобы не дать кешу бесконтрольно разрастись, и по сути означает «Здесь слишком много форм, отслеживать их дальше бесполезно». В виртуальной машине V8 кеши в мегаморфном состоянии могут все равно продолжать что-то кешировать, но уже не локально, а в глобальную хеш-таблицу. Она имеет фиксированный размер и при коллизиях значения перезаписываются.
Небольшое упражнение для проверки понимания:
function ff(b, o) {
if (b) {
return o.x
} else {
return o.x
}
}
ff(true, { x: 1 })
ff(false, { x: 2, y: 0 })
ff(true, { x: 1 })
ff(false, { x: 2, y: 0 })
- Сколько инлайн-кешей обращения к свойству объявлены в функции
ff?
- В каком они состоянии?
Ответы
Кешей два и оба мономорфны, поскольку в каждый из них попадали только объекты одной формы.
Влияние на производительность
На данном этапе производительность различных состояний инлайн-кеша становятся очевидными:
- Мономорфное — самое быстрое, если вы каждый раз обращаетесь к значению из кеша (ОДИН ТИП ХОРОШО!)
- Полиморфное — линейный поиск среди значений кеша
- Мегаморфное — обращение к глобальной хеш-таблице. Самый медленный вариант из кешированных, но все равно быстрее, чем промах кеша
- Промах кеша — обращение к полю, которого нет в кеше. Приходится платить за переход в рантайм и использование самого общего алгоритма
На самом деле, это только половина правды: кроме прямого ускорения кода, инлайн-кеши также работают шпионами на службе у всемогущего оптимизирующего компилятора, который рано или поздно придет и ускорит ваш код еще больше.
Спекуляции и оптимизации
Инлайн-кеши не могут обеспечить максимальную производительность в одиночку по двум причинам:
- Каждый инлайн-кеш работает независимо и ничего не знает о соседях
- Каждый инлайн-кеш может промахнуться, и тогда придется использовать рантайм: в конечном счете это обобщенная операция с обобщенными побочными эффектами, и даже тип возвращаемого значения зачастую неизвестен
function g(o) {
return o.x * o.x + o.y * o.y
}
g({x: 0, y: 0})
В примере выше инлайн-кешей аж семь штук: два на
.x, два на
.y, еще два на
* и один на
+. Каждый действует самостоятельно, проверяя объект
o на соответствие закешированной форме. Арифметический кеш оператора
+ проверит, являются ли оба операнда числами, хотя это можно было бы вывести из состояний кешей операторов
*. Кроме того, в V8 есть несколько внутренних представлений для чисел, так что это тоже будет учтено.
Некоторые арифметические операции в JS имеют присущий им конкретный тип, например a | 0 всегда возвращает 32-битное целое, а +a — просто число, но для большинства остальных операций таких гарантий нет. По этой причине написание AOT-компилятора для JS является безумно сложной задачей. Вместо того, чтобы компилировать JS-код заранее один раз, большинство виртуальных машин JS имеет несколько режимов исполнения.
Например, V8 сначала компилирует всё обычным компилятором и сразу же начинает исполнять. Позже часто используемые функции перекомпилируются с применением оптимизаций. С другой стороны, Asm.js использует неявные типы операций и с их помощью описывает очень строго ограниченное подмножество Javascript со статической типизацией. Такой код можно оптимизировать еще до его запуска, без спекуляций адаптивной компиляции.
«Прогрев» кода нужен для двух целей:
- Сокращает задержку при старте: оптимизирующий компилятор включается только в том случае, если код был использован достаточное количество раз
- Инлайн-кеши успевают собрать информацию о формах объектов
Как уже было сказано выше, написанный людьми код на JavaScript обычно содержит недостаточно информации для того, чтобы его можно было полностью статически типизировать и провести AOT-компиляцию. JIT-компилятору приходится строить догадки о том, как ведет себя ваша программа, и выдавать оптимизированный код, который подходит только при определенных допущениях. Иными словами, ему нужно знать, какие объекты используются в оптимизируемой функции. По счастливому стечению обстоятельств, это именно та информация, которую собирают инлайн-кеши!
- Мономорфный кеш говорит: «Я видел только тип A»
- Полиморфный кеш говорит: «Я видел только типы А1, ..., AN»
- Мегаморфный кеш говорит: «Да я много чего видел...»
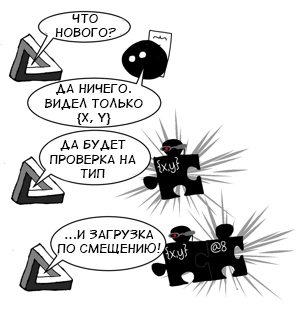
Оптимизирующий компилятор анализирует информацию, собранную инлайн-кешами, и по ней строит
промежуточное представление (
IR). Инструкции IR обычно более специфичные и низкоуровневые, нежели операции в JS. Например, если кеш для обращения к свойству
.x видел только объекты формы
{x, y}, тогда компилятор может сгенерировать IR-инструкцию, которая получает значение по фиксированному смещению от указателя на объект. Разумеется, использовать такую оптимизацию для любого приходящего объекта небезопасно, поэтому компилятор также добавит
проверку типа перед ней. Проверка типа сравнивает форму объекта с ожидаемой, и если они отличаются — оптимизированный код выполнять нельзя. Вместо этого вызывается неоптимизированный код и исполнение продолжается оттуда. Этот процесс называется
деоптимизацией. Несовпадение типа — не единственная причина, по которой деоптимизация может произойти. Она также может случиться, если арифметическая операция была «заточена» под 32-битные числа, а результат предыдущей операции вызвал переполнение, или при обращении к несуществуюшему индексу массива
arr[idx] (выход за пределы диапазона, разреженный массив с пропусками и т.д.).

Становится понятно, что оптимизация нужна для устранения описанных выше недостатков:
| Неоптимизированный код |
Оптимизированный код |
| Каждая операция может иметь неизвестные побочные эффекты и реализует полную семантику |
Специализация кода устраняет или ограничивает неопределенность, побочные эффекты строго известны (например, у обращения к свойству по смещению их нет) |
| Каждая операция сама по себе, обучается самостоятельно и не делится опытом с соседями |
Операции раскладываются на низкоуровневые IR-инструкции, которые оптимизируются вместе, что позволяет устранить избыточность |

Разумеется, построение IR под конкретные формы объектов — это только первый шаг в цепочке оптимизации. Когда промежуточное представление сформировано, компилятор будет пробегаться по нему несколько раз, обнаруживая инварианты и вырезая лишнее. Этот тип анализа обычно ограничен областью процедуры и компиляторы вынужден учитывать самые худшие из возможных побочных эффектов на каждом вызове. Следует помнить, что вызов может скрываться в любой неконкретизированной операции: например, оператор
+ может вызвать
valueOf, а обращение к свойству вызовет его getter-метод. Таким образом, если операцию не получилось конкретизировать на первом этапе, об нее будут спотыкаться все последующие проходы оптимизатора.
Один из наиболее распространенных видов избыточных инструкций — это постоянные проверки на то, что один и тот же объект имеет одну и ту же форму. Вот так изначальное промежуточное представление может выглядеть для функции g из примера выше:
CheckMap v0, {x,y} ;; shape check
v1 Load v0, @12 ;; load o.x
CheckMap v0, {x,y}
v2 Load v0, @12 ;; load o.x
i3 Mul v1, v2 ;; o.x * o.x
CheckMap v0, {x,y}
v4 Load v0, @16 ;; load o.y
CheckMap v0, {x,y}
v5 Load v0, @16 ;; load o.y
i6 Mul v4, v5 ;; o.y * o.y
i7 Add i3, i6 ;; o.x * o.x + o.y * o.y
Здесь форма объекта в переменной
v0 проверяется 4 раза, хотя между проверками нет операций, которые могли бы вызвать ее изменение. Внимательный читатель также заметит, что загрузка
v2 и
v5 также избыточна, поскольку никакой код их не перезаписывает. К счастью, последующий проход
глобальной нумерации значений удалит эти инструкции:
;; После ГНЗ
CheckMap v0, {x,y}
v1 Load v0, @12
i3 Mul v1, v1
v4 Load v0, @16
i6 Mul v4, v4
i7 Add i3, i6
Как уже было сказано выше, убрать эти инструкции стало возможно только потому, что между ними не было операций с побочными эффектами. Если бы между загрузками
v1 и
v2 был вызов, нам пришлось бы допускать, что он может изменить форму объекта в
v0, а следовательно проверка формы
v2 была бы обязательна.
Если же операция не мономорфна, компилятор не может просто взять ту же самую связку «проверка формы и конкретизированная операция», как в примерах выше. Инлайн-кеш содержит информацию о нескольких формах. Если взять любую из них и завязаться только на нее, то все остальные будут приводить к деоптимизации, что нежелательно. Вместо этого компилятор будет строить дерево решений. Например, если инлайн-кеш обращения к свойству o.x встречал только формы A, B и C, то развернутая структура будет аналогична следующему (это псевдокод, на самом деле будет построен граф потока управления):
var o_x
if ($GetShape(o) === A) {
o_x = $LoadByOffset(o, offset_A_x)
} else if ($GetShape(o) === B) {
o_x = $LoadByOffset(o, offset_B_x)
} else if ($GetShape(o) === C) {
o_x = $LoadByOffset(o, offset_C_x)
} else {
// в o.x попадали только A, B, C
// поэтому мы предполагаем, что *ничего* иного быть не может
$Deoptimize()
}
// Здесь мы знаем только то, что o имеет одну
// из форм - A, B или C. Но мы уже не знаем,
// какую именно
У мономорфных обращений есть одно очень полезное свойство, которого нет у полиморфных: до следующей операции с побочным эффектом существует гарантия того, что форма объекта осталась неизменной. Полиморфное обращение дает только слабую гарантию «объект имеет одну из нескольких форм», с помощью которой мало что можно оптимизировать (в лучшем случае, можно было бы убрать последнее сравнение и блок с деоптимизацией, но V8 так не поступает).
С другой стороны, V8 может сформировать эффективное промежуточное представление, если поле располагается по одинаковому смещению во всех формах. В этом случае будет использована полиморфная проверка формы:
// Проверяем, что форма о является одной из A, B или C - иначе деоптимизируем
$TypeGuard(o, [A, B, C])
// Загружаем свойство, поскольку во всех трех формах смещение одинаковое
var o_x = $LoadByOffset(o, offset_x)
Если между двумя полиморфными проверками нет операций с побочными эффектами, вторая может также быть удалена за ненадобностью, как и в случае с мономорфными.
Когда инлайн-кеш передает компилятору информацию о возможных формах объекта, компилятор может посчитать, что делать для каждой из них по ветвлению в графе нецелесообразно. В таком случае будет сгенерирован немного другой граф, где в конце будет не деоптимизация, а обобщенная операция:
var o_x
if ($GetShape(o) === A) {
o_x = $LoadByOffset(o, offset_A_x)
} else if ($GetShape(o) === B) {
o_x = $LoadByOffset(o, offset_B_x)
} else if ($GetShape(o) === C) {
o_x = $LoadByOffset(o, offset_C_x)
} else {
// Мы знаем, что обращение к o.x мегаморфно.
// Во избежание деоптимизации оставим лазейку
// для случайных объектов:
o_x = $LoadPropertyGeneric(o, 'x')
// ^^^^^^^^^^^^^^^^^^^^ неизвестные побочные эффекты
}
// В этот момент о форме объекта "о"
// больше ничего не известно, и могли
// произойти побочные эффекты
В некоторых случаях компилятор может вообще отказаться от затеи конкретизировать операции:
- Нет способа эффективно ее конкретизировать
- Операция полиморфна и компилятор не знает, как построить дерево решений (такое раньше происходило с полиморфным обращением к
arr[i], но уже исправлено)
- Нет информации о типе, которым операция может быть конкретизирована (код ни разу не выполнялся, сборщик мусора удалил собранную информацию о формах и т.д.)
В этих (довольно редких) случаях компилятор выдает обобщенный вариант промежуточного представления.
Влияние на производительность
В итоге имеем следующее:
- Мономорфные операции оптимизируются легче всего и дают оптимизатору простор для действий. Как сказал бы Халк — "ОДИН ТИП БЛИЗКО К ЖЕЛЕЗУ!"
- Операции с небольшим уровнем полиморфизма, требующие проверку формы, или дерево решений, медленнее мономорфных:
- Деревья решений усложняют поток исполнения. Компилятору сложнее распространять информацию о типах и убирать лишние инструкции. Условные переходы дерева также могут запороть производительность, если попадут в нагруженный цикл.
- Полиморфные проверки форм не так сильно препятствуют оптимизации и все еще позволяют удалять некоторые излишние инструкции, но все равно медленнее мономорфных. Влияние на производительность зависит от того, как хорошо ваш процессор работает с условными переходами.
- Мегаморфные или высокополиморфные операции не конкретизируются вообще, и в промежуточном представлении будет вызов, со всеми вытекающими последствиями для оптимизации и производительности CPU.
Примечание переводчика: автор давал ссылку на микробенчмарк, однако сам сайт больше не работает.
Необсужденное
Я умышленно не стал вдаваться в некоторые детали реализации, чтобы статья не стала слишком обширной.
Формы
Мы не обсуждали, как формы (или скрытые классы) устроены, как они вычисляются и присваиваются объектам. Общее представление можно получить из моей
предыдущей статьи или
выступления на AWP2014.
Нужно только помнить, что само понятие «формы» в виртуальных машинах JS — это эвристическое приближение. Даже если с точки зрения человека у двух объектов форма одинакова, с точки зрения машины она может быть разной:
function A() { this.x = 1 }
function B() { this.x = 1 }
var a = new A,
b = new B,
c = { x: 1 },
d = { x: 1, y: 1 }
delete d.y
// a, b, c, d - четыре разных формы для V8
Поскольку объекты в JS беззаботно реализованы в виде словарей, можно применить полиморфизм по случайности:
function A() {
this.x = 1;
}
var a = new A(), b = new A(); // форма одинакова
if (something) {
a.y = 2; // форма a больше не совпадает с формой b
}
Умышленный полиморфизм
Во многих языках, где форма созданного объекта не может быть изменена (Java, C#, Dart, C++ и т.д.), полиморфизм также поддерживается. Возможность написать код, основанный на интерфейсах и выполняющихся в зависимости от конкретной реализации — очень важный механизм абстракции. В статически типизированных языках полиморфизм влияет на производительность аналогичным образом.
Неудивительно, что JVM использует инлайн-кеши для оптимизации инструкций invokeinterface и invokevirtual.
Не все кеши одинаково полезны
Следует иметь в виду, что некоторые кеши основаны не на формах объектов, и\или имеют меньшую емкость по сравнению с другими. Например, инлайн-кеш вызова функции может иметь только три состояния: неинициализированное, мономорфное или мегаморфное. Промежуточного полиморфного состояния у него нет, потому что для вызова функции форма объекта не имеет значения, а кешируется сам объект функции.
function inv(cb) {
return cb(0)
}
function F(v) { return v }
function G(v) { return v + 1 }
inv(F)
// инлайн-кеш мономорфный, указывает на F
inv(G)
// инлайн-кеш становится мегаморфным
Если функция
inv оптимизирована и инлайн-кеш находится в мономорфном состоянии, оптимизатор может встроить тело функции в место вызова (что особенно важно для коротких функций в часто вызываемых местах). Если же кеш в мегаморфном состоянии, оптимизатор не знает, тело
какой именно функции можно встраивать, и поэтому оставит обобщенный оператор вызова в промежуточном представлении.
С другой стороны, вызовы методов вида o.m(...) работает аналогично обращению к свойству. Инлайн-кеш вызова метода также может иметь промежуточное полиморфное состояние. Виртуальная машина V8 может встроить вызов такой функции в мономорфном, полиморфном, или даже мегаморфном виде тем же способом, как со свойством: сначала проверка типа или дерево решений, после которого располагается само тело функции. Есть только одно ограничение: метод должен содержаться в форме объекта.
На самом деле, o.m(...) использует сразу два инлайн-кеша — один для загрузки свойства, другой для непосредственно вызова функции. Второй имеет только два состояния, как в примере выше у функции cb. Поэтому его состояние игнорируется при оптимизации вызова и используется только состояние инлайн-кеша обращения к свойству.
function inv(o) {
return o.cb(0)
}
var f = {
cb: function F(v) { return v },
};
var g = {
cb: function G(v) { return v + 1 },
};
inv(f)
inv(f)
// инлайн-кеш в мономорфном состоянии,
// видел только объекты типа f
inv(g)
// а теперь в полиморфном, потому что
// кроме f видел еще и g
Может показаться неожиданным, что в примере выше
f и
g имеют разную форму. Так происходит потому, что когда мы присваиваем свойству объекта функцию, V8 старается (если возможно) привязать ее к форме объекта, а не к самому объекту. В примере выше
f имеет форму
{c: F}, то сама форма ссылается на замыкание. Во всех примерах до этого формы содержали только признак наличия определенного свойства — в данном же случае сохраняется и его значение, а форма становится похожа на класс из языков наподобие Java или C++.
Конечно, если потом перезаписать свойство другой функцией, V8 посчитает, что это больше не похоже на взаимоотношение класса и метода, поэтому форма изменится:
var f = {
cb: function F(v) { return v },
};
// Форма f равна {cb: F}
f.cb = function H(v) { return v - 1 }
// Форма f равна {cb: *}
Про то, как V8 строит и поддерживает формы объектов, стоило бы написать отдельную большую статью.
Представление пути к свойству
К этому моменту создается впечатление, что инлайн-кеш обращения к свойству
o.x — это такой словарь, сопоставляющий формы и смещение внутри класса, наподобие
Dictionary<Shape, int>. На самом деле такое представление не передает глубину: свойство может принадлежать одному из объектов в цепочке прототипов, или же иметь методы доступа. Очевидно, что свойства с геттерами-сеттерами считаются менее конкретизированными, чем обычное свойства с данными.
Например, объект o = {x: 1} можно представить как объект, свойство которого загружает и сохраняет значение в специальный скрытый слот с помощью методов виртуальной машины:
// псевдокод, описывающий o = { x: 1 }
var o = {
get x () {
return $LoadByOffset(this, offset_of_x)
},
set x (value) {
$StoreByOffset(this, offset_of_x, value)
}
// геттер/сеттер сгенерированы виртуальной машиной
// и невидимы для обычного JS-кода
};
$StoreByOffset(o, offset_of_x, 1)
Кстати, примерно так реализованы свойства в Dart VM
Если смотреть так, то инлайн-кеш должен быть скорее представлен в виде Dictionary<Shape, Function> — сопоставляя формы с функциями-аксессорами. В отличие от наивного представления со смещением, так можно описать и свойства из цепочки прототипов, и геттеры-сеттеры, и даже прокси-объекты из ES6.
Премономорфное состояние
Некоторые инлайн-кешы в V8 имеют еще одно состояние, которые называется
премономорфным. Оно служит для того, чтобы не компилировать код для кешей, к которым обращались всего один раз. Я не стал упоминать про это состояние, поскольку оно является малоизвестной особенностью реализации.
Финальный совет по производительности
Самый лучший совет касательно производительности можно взять из названия книги Дэйла Карнеги «Как перестать беспокоиться и начать жить».
И правда, переживать из-за полиморфизма обычно бессмысленно. Вместо этого прогоните ваш код с нормальными данными, поищите узкие места профайлером — и если они связаны с JS, то стоит взглянуть на промежуточное представление, которое производит компилятор.
И только тогда, если в середине вашего нагруженного цикла вы увидите инструкцию под названием XYZGeneric или что-то будет помечено атрибутом changes [*] (то есть «меняет всё»), тогда (и только тогда) можно начинать волноваться.
Комментарии (0)