В Java 8 кардинально переработали процедуру вывода типов выражений. В спецификации появилась целая новая глава на эту тему. Это весьма сложная штука, изложенная скорее на языке алгебры, чем на языке нормальных людей. Не каждый программист готов в этом разобраться. Я, разработчик IDE, которому приходилось ковыряться в соответствующем коде, к своему стыду тоже довольно плохо разбираюсь в этой теме и понимаю процесс только по верхам. Причём сложно не только мне, но и авторам компилятора Java. После выхода Java 8 обнаружились десятки багов, когда поведение компилятора не соответствовало спецификации, либо текст спецификации был неоднозначен. В средах разработки для Java ситуация обстояла не лучше: там тоже были баги, причём другие, поэтому код мог отображаться ошибочным в вашей IDE, но успешно компилироваться. Или наоборот. С годами ситуация улучшилась, многие баги исправили, хотя всё ещё в спецификации остались тёмные углы.
Если вы просто пишете на Java, вам в целом необязательно знать в деталях, как это всё работает. В большинстве случаев либо результат вывода типов соответствует вашей интуиции, либо вывод типов не работает вообще, и надо ему помочь. Например, указав типы-аргументы в <угловых скобках> при вызове метода, либо указав явно типы параметров лямбды. Тем не менее есть некоторый начальный уровень этого тайного знания, и его несложно освоить. Овладев им, вы будете лучше понимать, почему компилятор не всегда может вывести то, что вы хотите. В частности, вы сможете ответить на вопрос, который мне часто задавали в той или иной форме: какие из следующих строчек не компилируются и почему?
Comparator<String> c1 = Comparator.comparing(String::length).reversed();
Comparator<String> c2 = Comparator.comparing(s -> s.length()).reversed();
Comparator<String> c3 = Collections.reverseOrder(Comparator.comparing(s -> s.length()));Первое важное знание: в Java есть два типа выражений (JLS §15.2). Первый тип — «автономные выражения» (standalone expression), а второй — «поли-выражения» (poly expression). Тип автономных выражений вычисляется, глядя исключительно на само выражение. Если выражение автономное, совершенно неважно, в каком оно встретилось контексте, то есть что вокруг этого выражения. Для поли-выражений контекст важен и может влиять на их тип. Если поли-выражение вложено в другое поли-выражение, то фактически выбирается самое внешнее из них, и для него запускается процесс вывода типов. По всем вложенным поли-выражениям собираются ограничения (constraints). Иногда к ним добавляется целевой тип. Например, если поли-выражение — это инициализатор переменной, то тип этой переменной является целевым и тоже включается в ограничения. После этого выполняется редукция ограничений и определяются типы для всех поли-выражений сразу. Скажем, простой пример:
Comparator<String> c2 = Comparator.comparing(s -> s.length());Здесь лямбда является поли-выражением. Вообще лямбды и ссылки на методы всегда являются поли-выражениями, потому что их нужно отобразить на какой-то функциональный интерфейс, а по содержимому лямбды вы никогда не поймёте, на какой. Вызов метода Comparator.comparing тоже является поли-выражением (ниже мы поймём, почему). У лямбды надо определить точный функциональный тип, а у Comparator.comparing — значения типовых параметров T и U. В процессе вывода устанавливается, что
- T = String
- U = Integer
- Тип лямбды = Function<String, Integer>
- Тип параметра s = String
Только некоторые выражения в Java могут быть поли-выражениями. Вот их полный список (на момент Java 17):
- Выражения в скобках
- Создание нового объекта (new)
- Вызов метода
- Условные выражения (?:)
- switch-выражения (те что в Java 14 появились)
- Ссылки на методы
- Лямбды
Но «могут» не значит «должны». Могут быть, а могут и не быть. Проще всего со скобками: они наследуют «полистость» выражения, которое в скобках. В остальных случаях важен контекст.
Контексты определяются в пятой главе спецификации. Нам будут интересны только три из них:
- Контекст присваивания (assignment context) — это контекст, при котором автоматически выполняется преобразование присваивания. Включает в себя инициализацию переменной (кроме переменной с неявным типом
var), оператор присваивания, а также возврат значения из метода или лямбды (как с использованиемreturn, так и без). - Контекст вызова (invocation context) — аргумент вызова метода или конструктора.
- Контекст приведения (cast context) — аргумент оператора приведения типа.
Для определения контекста можно подниматься через скобки, условные операторы и switch-выражения. Поли-выражения могут быть только в контексте присваивания и контексте вызова. Для лямбд и ссылок на методы дополнительно разрешён контекст приведения. В любых других контекстах использование лямбд и ссылок на методы недопустимо вообще. Это правило, кстати, приводит к интересным последствиям:
Runnable r1 = () -> {}; // можно
Runnable r2 = true ? () -> {} : () -> {}; // можно
Object r3 = (Runnable)() -> {}; // можно
Object r4 = (Runnable)(true ? () -> {} : () -> {}); // нельзя!
Object r5 = true ? (Runnable)() -> {} : (Runnable)() -> {}; // можноУсловный оператор во второй строке является поли-выражением, потому что он в контексте присваивания. Поэтому он может посмотреть наружу и увидеть, что результат должен быть типа Runnable, а значить использовать эту информацию для вывода типов веток и в итоге присвоить обеим лямбдам тип Runnable. Однако четвёртая строчка в таком виде не работает, несмотря на большое сходство. Здесь условный оператор true ? () -> {} : () -> {} находится в контексте приведения, что по спецификации делает его автономным выражением. Поэтому мы не можем выглянуть за его пределы и увидеть тип Runnable, а значит мы не знаем, какой тип назначить лямбдам — возникает ошибка компиляции. В этом случае придётся переносить приведение типов в каждую ветку условного оператора (или не писать такой код вообще).
Не только контекст, но и вид выражения может влиять на полистость. Например, выражение new может быть поли-выражением (в соответствующем контексте), только если используется оператор «ромб» (new X<>(), JLS §15.9). В противном случае тип результата всё равно однозначен и нет смысла усложнять компиляцию. Аналогичная мысль применяется к выражениям вызова метода, только это приводит к более сложным условиям (JLS §15.12):
- Мы вызываем generic-метод
- Этот generic-метод упоминает хотя бы один из своих типовых параметров в возвращаемом типе
- Типы-аргументы не заданы явно при вызове в <угловых скобках>
Если хоть одно из этих условий не выполнено, тип результата метода устанавливается однозначно и разумно считать выражение автономным. Тут ещё дополнительная сложность в том, что мы можем не сразу знать, какой конкретно метод вызываем, если имеется несколько перегруженных методов. Но тут может открыться портал в ад, поэтому не будем копать эту тему.
Интересная история с условным оператором (JLS §15.25). Сначала в зависимости от типов выражений в ветках выясняется разновидность оператора: это может быть булев условный оператор, числовой условный оператор или ссылочный условный оператор. Только ссылочный условный оператор может быть поли-выражением, а булев и числовой всегда автономные. С этим связано много странностей. Вот например:
static Double get() {
return null;
}
public static void main(String[] args) {
Double x = true ? get() : 1.0;
System.out.println(x);
}Здесь типы веток условного оператора — конкретно Double и конкретно double. Это означает, что условный оператор числовой (numeric conditional expression, JLS §15.25.2), то есть автономный. Соответственно, мы не смотрим наружу, нас не волнует, что мы присваиваем результат в объектный Double. Мы определяем тип только по самому оператору, и этот тип — примитивный double. Соответственно, для балансировки типов добавляется unboxing левой ветки, а потом для присваивания добавляется снова boxing:
Double x = Double.valueOf(true ? get().doubleValue() : 1.0);Здесь мы разворачиваем результат метода get(), а потом заново сворачиваем. Разумеется, этот код падает с NullPointerException, хотя казалось бы мог бы и не падать.
Ситуация в корне меняется, если мы объявим метод get() по-другому:
static <T> T get() { ... }Теперь в одной из веток не числовой тип Double, а неизвестный ссылочный тип T. Весь условный оператор становится ссылочным (reference conditional expression, JLS §15.25.3), соответственно становится поли-выражением и может посмотреть наружу, на целевой тип Double и использовать именно его как целевой тип веток. В итоге обе ветки успешно приводятся к типу Double, для чего добавляется boxing в правой ветке:
Double x = true ? get() : Double.valueOf(1.0);Теперь программа успешно печатает null и завершается. Такие нестыковки обусловлены историческими причинами и необходимостью совместимости. В первых версиях Java никаких поли-выражений не было, все были автономными, поэтому надо было выкручиваться, и выкручивались не всегда идеально. К счастью, это не распространяются на более новые switch-выражения. Для них нет дополнительных условий на полистость кроме контекста, поэтому такой код вполне ожидаемо печатает null вместо падения с исключением:
static Double get() {
return null;
}
public static void main(String[] args) {
Double x = switch (0) {
case 0 -> get();
default -> 1.0;
};
System.out.println(x);
}Вернёмся к нашему примеру с компараторами. Я раскрою карты: второй вариант не компилируется.
Comparator<String> c1 = Comparator.comparing(String::length).reversed(); // можно
Comparator<String> c2 = Comparator.comparing(s -> s.length()).reversed(); // нельзя
Comparator<String> c3 = Collections.reverseOrder(Comparator.comparing(s -> s.length())); // можноВот главное, что следует запомнить:
Квалификатор никогда не находится в контексте присваивания или контексте вызова, поэтому не может быть поли-выражением.
В первых двух строчках у нас есть квалификаторы: Comparator.comparing(String::length) и Comparator.comparing(s -> s.length()). При определении типа квалификатора мы не можем смотреть на то что происходит вокруг, нам остаётся пользоваться только самим содержимым квалификатора.
Comparator.comparing возвращает Comparator<T>, принимая функцию Function<? super T, ? extends U>, и нам необходимо определить значения T и U. В случае со ссылкой на метод у нас есть дополнительная информация: ссылка однозначно указывает на метод length() в классе String. соответственно, выводу типов хватает этого, чтобы понять, что T = String и U = Integer. Однако в случае с лямбдой у нас нет никаких указаний на то что s — это строка. Соответственно, у нас нет ограничений на T, а значит в соответствии с правилами редукции выбирается максимально общий тип: T = Object. Далее запускается анализ тела лямбды и мы обнаруживаем, что у класса Object нет метода length(), из-за чего компиляция останавливается. Вот такое, кстати, бы сработало, потому что hashCode() в объекте есть:
Comparator<Object> cmp = Comparator.comparing(s -> s.hashCode()).reversed();Понятно и почему работает строчка c3. Так как Comparator.comparing здесь в контексте вызова, мы можем подняться наверх и добраться до контекста присваивания, а значит, использовать целевой тип Comparator<String>. Тут вывод сложнее, потому что есть ещё переменная типа в методе reverseOrder. Тем не менее компилятор справляется и успешно всё выводит.
Как починить c2, если всё-таки хочется использовать квалификатор? Мы уже знаем достаточно, чтобы понять, что вот это не сработает:
Comparator<String> c2 =
((Comparator<String>)Comparator.comparing(s -> s.length())).reversed();Приведение типа не чинит результат вызова метода, так как контекст приведения не действует на вызовы. Зато приведение типа срабатывает с лямбдой, хотя и выглядит ужасно:
Comparator<String> c2 =
Comparator.comparing((Function<String, Integer>) s -> s.length()).reversed();Вариант проще: сделать вызов метода автономным. Для этого надо добавить типы-аргументы. В итоге тип вызова comparing устанавливается однозначно, и из него уже выводится тип лямбды:
Comparator<String> c2 =
Comparator.<String, Integer>comparing(s -> s.length()).reversed();Ещё проще в данном случае — явно указать тип параметра лямбды. Тут у нас вызов comparing по-прежнему является поли-выражением, но появляется ограничение на тип s, и его хватает, чтобы вывести всё остальное правильно:
Comparator<String> c2 =
Comparator.comparing((String s) -> s.length()).reversed();Можно ли было распространить вывод типов на квалификаторы, чтобы c2 работало без дополнительных подсказок компилятору? Возможно. Но, как я уже говорил, процедура вывода типов и так невообразимо сложная. В ней и так до сих пор есть тёмные места, а даже когда она правильно работает, она может работать ужасно долго. К примеру, возможно написать относительно несложный код, который создаст сотню ограничений и поставит на колени и IDE, и компилятор javac, потому что реализация вывода типов может быть полиномом довольно высокой степени от количества ограничений. Если мы в этот замес добавим квалификаторы, всё станет сложнее на порядок, ведь они будут интерферировать со всем остальным. Также возникнут проблемы из-за того, что мы можем вообще толком не знать, какой метод какого класса мы пытаемся вызвать. Например:
<T> T fn(UnaryOperator<T> op) {
return op.apply((T) " hello "); // грязно, но имеем право!
}
String s = fn(t -> t).trim();Если мы выводим тип квалификатора fn(t -> t) вместе с типом всего выражения, то мы даже не знаем, у какого класса вызывается метод trim(). Нам подходит любой метод trim() в любом классе, который не принимает аргументов и возвращает строку. Например, метод String.trim() подойдёт. Или ещё какой-нибудь. У этого уравнения может быть много решений. Придётся как-то отдельно обговаривать в спецификации такие случаи. Так или иначе, я не был бы счастлив заниматься поддержкой данной возможности в IDE.








































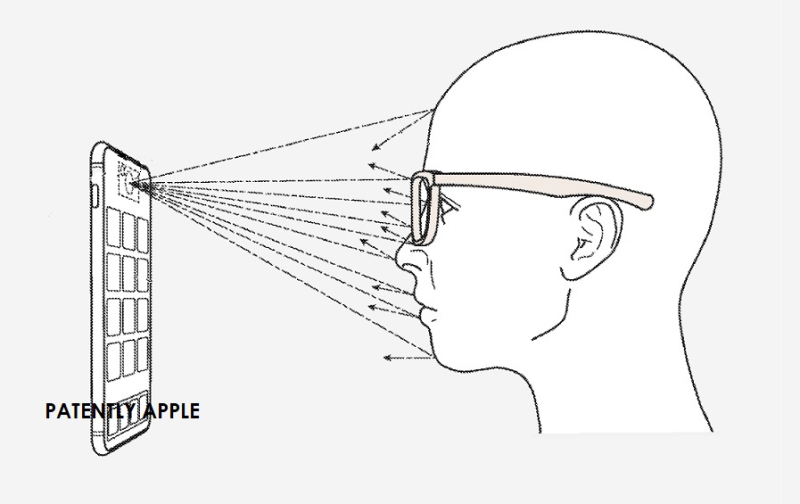
 пользователя и использует систему # 102 оптических датчиков. Фронтальная камера №105 (например, камера, предназначенная для обнаружения видимого, инфракрасного и / или ультрафиолетового света, не показана) может захватывать изображения точечного рисунка (например, части точечного рисунка, которые отражаются от лица пользователя) и создавать карту глубины биометрической идентичности и / или набор карт биометрической идентичности лица пользователя на основе расстояния между отдельными точками.")