Или то, почему вы не можете издать свою улучшенную версию Counter Strike и уехать жить на Гавайи.
О чём речь?
Обфуска́ция (от английского obfuscate — делать неочевидным, запутанным, сбивать с толку) в широком смысле - приведение исходного текста или исполняемого кода программы к виду, сохраняющему её функциональность, но затрудняющему анализ, понимание алгоритмов работы и модификацию при декомпиляции.
Красивый пример из Википедии кода, прошедшего обфускацию.
Далее в программе
Зачем это нужно?
Как это должно работать?
Как это работает?
Методы
Состояние дел сейчас
Зачем это нужно?
Как известно, одним из основных методов взлома программного обеспечения является исследование кода, полученного в результате работы дизассемблера на предмет уязвимостей. На основе такого когда нетрудно, например, составить программу генерации ключей активации коммерческого программного обеспечения или, наоборот, внести в исполняемый файл изменение - патч, позволяющий злоумышленникам отключить "нежелательные" модули исходной программы.
Всему вышеперечисленному как раз и может противодействовать специальная программа - обфускатор.
Так же, алгоритмы обфускации активно используются не только для затруднения анализа кода, но и для уменьшения размера программного кода, что, в свою очередь, активно используется при разработке различных веб-сервисов и баз данных.
Как это должно работать?
Как понятно из вышесказанного, методы обфускации должны усложнить код, преобразовав его таким образом, чтобы скрыть от третьих лиц логику его работы.
В идеале хотелось бы, чтобы программа, прошедшая обфускацию, давала бы не больше информации нежели чёрный ящик, имитирующий поведение исходной программы. Гипотетический алгоритм, реализующий такое преобразование называется "Обфускация чёрного ящика". Декомпиляция зашифрованной таким образом программы дала бы злоумышленникам не больше информации, чем декомпиляция клиента мессенджера, представляющего собой лишь обёртку над апи "настоящего" приложения, что бы полностью решило поставленную в предыдущем блоке проблему. Однако показано[3], что реализация такого алгоритма для произвольной программы невозможна.
Как это работает
Большинство методов обфускации преобразуют следующие аспектов кода:
• Данные: делают элементы кода похожими на то, чем они не являются
• Поток кода: выставляют исполняемую логику программы абсурдной или даже недетерминированной
• Структура формата: применяют различное форматирование данных, переименование идентификаторов, удаление комментариев кода и т.д.
Инструменты обфускации могут работать как с source или байт кодом, так и с бинарным, однако обфускация двоичных файлов сложнее, и должна варьироваться в зависимости от архитектуры системы.
При обфускации кода, важно правильно оценить, какие части когда можно эффективно запутать. Следует избегать обфускации кода, критичного относительно производительности.
Методы
1. Преобразование данных
Одним из наиболее важных элементов обфускации является преобразование данных, используемых программой, в иную форму,оказывающее минимальное виляние на производительность кода, но значительно усложняющее хакерам возможность обратного нижинирнга.
По ссылке можно ознакомится с интересными примерами использования двоичной формы записи чисел для усложнения читабельности кода, а так же изменений формы хранения данных и замены значений различными тождественными им выражениями.
2. Обфускация потока управления кодом
Обфускация потока управления может быть выполнена путем изменения порядка операторов выполнения программы. Изменение графа управления путем вставки произвольных инструкций перехода и преобразования древовидных условных конструкций в плоские операторы переключения, как показано на следующей диаграмме.
3. Обфускация адресов
Данный метод изменяет структура хранения данных, так чтобы усложнить их использование. Например алгоритм, может выбирать случайными адреса данных в памяти, а также относительные расстояния между различными элементами данных. Данный подход примечателен тем, что даже если злоумышленник и сможет "декодировать" данные, используемые приложением на каком-то конкретном устройстве, то на других устройствах он всё равно не сможет воспроизвести свой успех.
Этот метод предотвращает атаки, регулярно выпуская обновления обфусцированного программного обеспечения. Своевременные замены частей существующего программного обеспечения новыми обфусцированными экземплярами, могут вынудить злоумышленника отказаться от существующего результата обратного анализа, так как усилия по взлому кода в таком случае могут превысить получаемую от этого ценность.
5. Обфускация инструкций ассемблера
Преобразование и изменение ассемблерного когда также может затруднить процесс обратного инжиниринга. Одним из таких методов является использование перекрывающихся инструкций (jump-in-a-middle), в результате чего дизассемблер может произвести неправильный вывод. Ассемблерный код также может быть усилен против проникновения за счёт включения бесполезных управляющих операторов и прочего мусорного кода.
6. Обфускация отладочной информации
Отладочную информацию можно использовать для обратного проектирования программы, поэтому важно блокировать несанкционированный доступ к данным отладки. Инструменты обфускации достигают этого, изменяя номера строк и имена файлов в отладочных данных или полностью удаляя из программы отладочную информацию.
Заключение
Я не стал описывать историю развития различных подходов к обфускации, так как на мой взгляд, она неплохо отражена в уже существующей на Хабре статье.
Данная статья была написана в 2015 году, и мне не удалось найти в интернете существенного количества статей и иных материалов на тему моего поста, накопившихся за это время. На мой взгляд, в наш век всё большую популярность приобретает разработка всевозможных веб приложений, которые мало нуждаются в обфускации в качестве метода защиты информации. Однако как раз таки сжатие исходного кода программ, при помощи методов обфускации в таких приложениях зачастую оказывается полезным.
В заключение, хотел бы добавить, что при использовании методов обфускации не следует пренебрегать и прочими методами защиты вашего кода, ведь обфускация далеко не серебряная пуля в вопросе защиты программ от взлома.
Недорогой широкополосный спутниковый интернет — мечта миллионов людей, живущих в удаленных регионах. В большинстве таких мест подключиться к обычной магистрали не получится, а все остальные способы либо недоступны, либо очень дороги. Поэтому спутниковый интернет сейчас развивают сразу три компании — Starlink Илона Маска, OneWeb и Project Kuiper от Amazon.
На днях Amazon рассказала о завершении создания антенны для недорогого спутникового пользовательского терминала. По словам разработчиков, основа конструкции антенны — новая архитектура, которая позволила сделать систему небольшой и легкой. При этом она обеспечивает пропускную способность канала вплоть до 400Mbps.
Что из себя представляет эта антенна?
Она предназначена для работы в Ka-спектре. Чтобы снизить стоимость производства, Amazon потребовалось уменьшить размер, вес и сложность антенны. В обычной ситуации все решалось бы легко и просто, но здесь компания имела дело именно с Ka-спектром, где требуется физическое разделение приемной и передающей антенны для того, чтобы избежать помех и проблем со связью. Обычно приемную и передающую антенны устанавливают в разных местах. Но это требует дополнительного пространства, плюс увеличивается стоимость производства.
Amazon удалось разработать систему, где обе антенны наслаиваются друг на друга — элементы конструкции перекрываются, причем так, чтобы не мешать приему или передаче данных. Конструкция предусматривает комбинацию цифровых и аналоговых компонентов. Такой вариант компоновки дал возможность создать антенну диаметром всего 12 дюймов, которая обеспечивает пропускную способность вплоть до 400Mbps.
«Ключевым достижением стало объединение передающей и приемной антенн с фазированной решеткой в одной апертуре. Это можно сделать и в других частотных диапазонах, но Project Kuiper планирует работать в Ka-диапазоне, где частоты передачи и приема отстоят далеко друг от друга», — говорится в заявлении компании.
Фазированные решетки — это класс излучающих систем, в которых несколько антенн — их может быть две, а может быть и тысячи — находятся на одной апертуре, создавая сфокусированный луч радиоволн.
Главной задачей было не просто создать эффективную антенну, но и сделать ее доступной для массового производства, с условием невысокой стоимости для конечного пользователя.
Amazon собирается использовать спектр частот 17.7-18.6 ГГц и 18.8-20.2 ГГц для сигнала «космос-Земля» и 27.5-30.0 ГГц для связи «Земля-космос».
Этап тестирования уже пройден
Компания заявила, что прототип уже прошел испытания, все элементы теста выполнены успешно, так что дальше — этап практического внедрения. Испытания проведены в полевых условиях, причем условия были разными — как погодные, так и все прочие. Как оказалось, пропускной способности канала хватает для обеспечения передачи видео в 4К качестве.
Сейчас Amazon нанимает сотрудников для расширения масштабов проекта. То есть, он входит в практическую фазу и нужны люди, новые сотрудники.
Приоритет — на загрузке контента
Компания постаралась сбалансировать скорости приема и передачи данных, но все же приоритет отдан загрузке. Разрабочтики считают, что они создали сразу несколько инновационных элементов, которые дают возможность создавать новые виды антенн. Они сильно отличаются от того, что широко используется сейчас.
Одно из достижений — рассеивание тепла в самих спутниках. Проблема в том, что в космосе нет воздуха, который может отводить тепло. Поэтому пришлось разработать не только мощные системы, способные обеспечивать надежный сигнал, но и подумать над снижением энергопотребления этих систем. Участники проекта говорят, что им пришлось поломать голову над этой проблемой, но в итоге ее удалось решить.
К сожалению, рассказав о таких подробностях, участники проекта умолчали о том, что Kuiper станет доступным для конечных пользователей. FCC дала Amazon 6 лет на разворачивание спутниковой системы — за это время на орбите должны оказаться минимум 50% аппаратов. Все остальные должны быть запущены к 30 июля 2029 года.
Ранее компания рассказала, что сеть станет доступной как только 578 спутников окажутся на орбите. Всего FCC дала разрешение на запуск 3236 аппаратов.
Главный конкурент спутниковой сети Amazon — Starlink от SpaceX, уже предоставила тестовый доступ нескольким сотням абонентов. Доступная скорость — от 50 до 150 Mbps с задержками от 20 до 40 мс. К 2021 году компания обещает значительно улучшить все показатели работы сети.
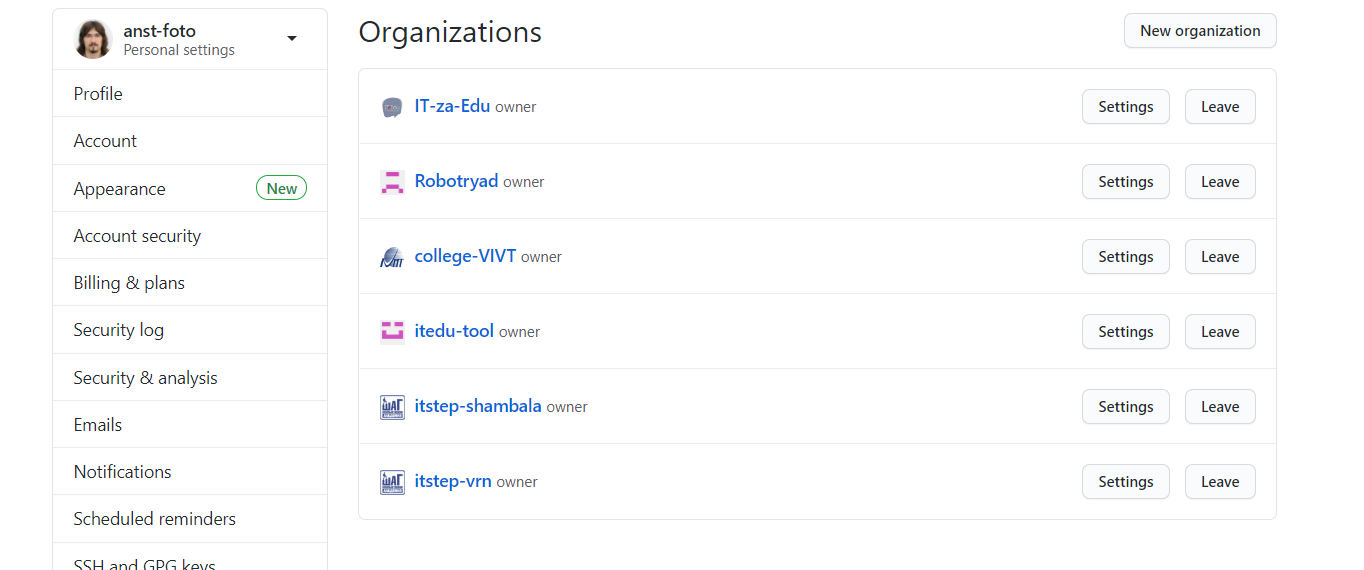
В своей преподавательской практике использую GitHub...
Но для начала давайте представлюсь. Зовут меня Старинин Андрей. И я преподаю программирование, хотя по первому образованию я биолог. А ещё один из основателей и ведущих подкаста "IT за Edu".
Мой стек дисциплин:
Кажется, что всего много. Но успеваем не сильно погрузиться в отдельные технологии. После какого-то времени (точно не помню уже какого) понял, что студентов можно и даже нужно "приучать" к системам управления версиями почти сразу с начала обучения. Для обучения выбрал GitHub. Хотя Bitbucket тоже нравится. Да, я не учу студентов сразу по харду, они не сразу изучают git в CLI. Я их знакомлю сначала с web-интерфейсом GitHub'а. Потом рассказываю про GUI-клиенты. Из них мне нравится GitKraken. Но не заставляю их пользоваться тем, что нравится мне - они вольны выбирать сами чем пользоваться.
Постепенно - это примерно так:
Просто показываю как выкладывать код
Прошу их выкладывать свои решения и присылать мне ссылки на репозитории
Выкладываю текст заданий и прошу ответы присылать через pull-request'ы
Пробуем поработать в маленьких командах над одним репозиторием без веток
Пробуем поработать небольшой командой над одним репозиторием с отдельными ветками
Пробуем работать над большим проектом большой командой с несколькими репозиториями и ветками.
И вот такой постепенный подход стараюсь применять при изучении тем. Иногда темы заканчиваются быстрее, чем успеем перейти к большому или маленькому проекту. Но это не сильно страшно. По изучении нескольких тем мы можем полученные знания объединить в один большой проект.
Не все студенты сразу всё понимают и принимают. Но тем интереснее и приятнее когда они "доходят". Ещё люблю подход: учимся на своих ошибках. Во время обучения есть возможность ошибаться и понять к чему это приводит.
Что мне нравится в GitHub при обучении?
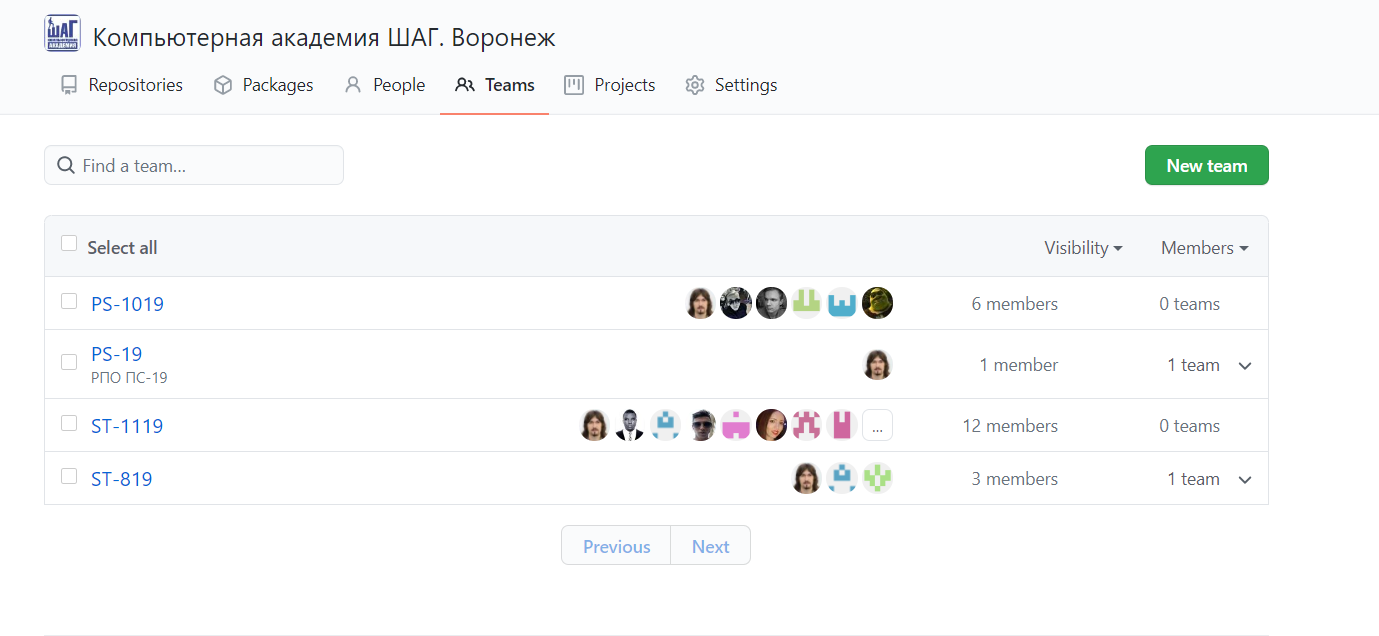
Поддержка аккаунтов для организаций, а в аккаунтах возможность создания команд с гибкими настройками доступов
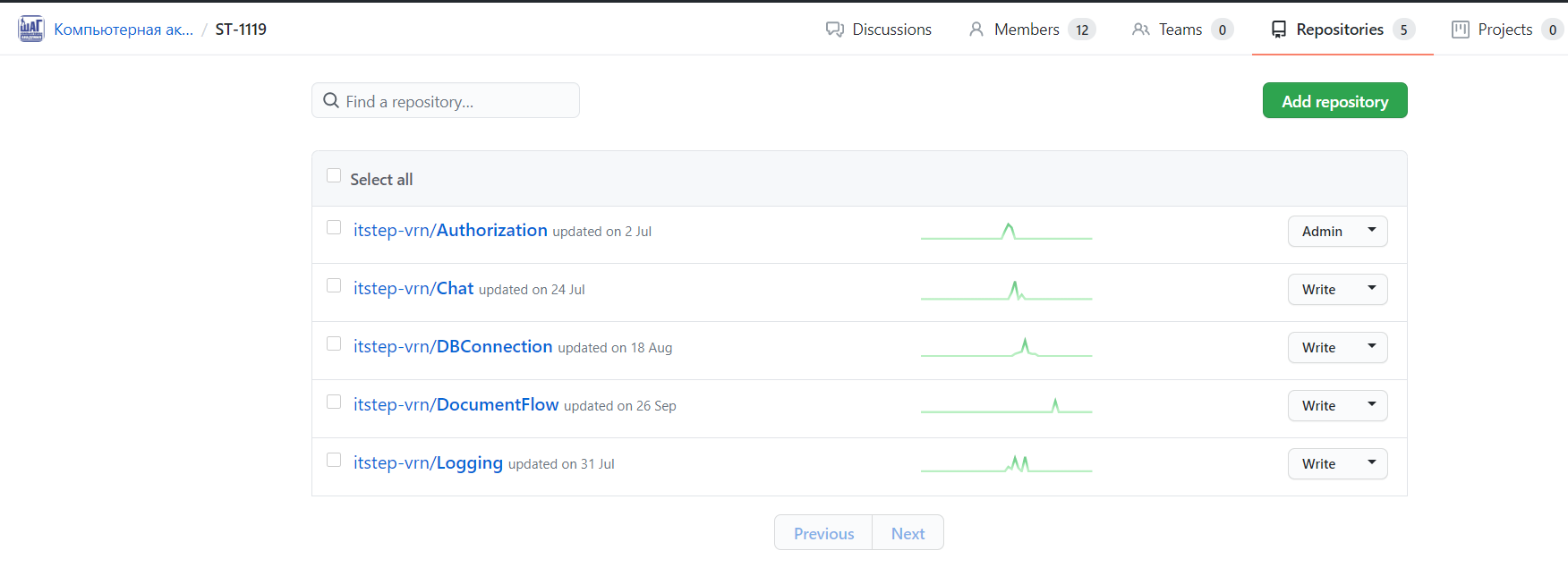
Система форков. Может любой человек сделать форк, а потом предложить запрос на слияние. Не всегда нужно всех студентов добавлять в команду.
Возможность назначать ревьюером любого члена команды. Студенты должны уметь не только хорошо писать программы, но и проверять чужой код.
Система issues. Можно давать другим командам студентов задание на проверку кода и выявления багов, с занесением всего в issues.
Для чего я приучаю студентов к GitHub'у?
Создание своего портфолио уже с самого начала обучения, а не только под конец.
Понимание принципов написания кода. Когда начинают чужой код проверять - многое понимают
Понимание "соглашения об именовании". Пока не наступят на грабли разного именования в одной команде - не понимают. Ну или не все понимают
Понимание как работать в команде. И как командам между собой взаимодействовать.
Прекрасно понимаю, что мои методы не самые лучшие и далеки от совершенства, да и от реальности далековаты. Но стараюсь их приблизить к реальности.
Заканчивается 2020 год, а значит, настало время подвести статистические итоги и составить уже традиционный рейтинг лучших статей Хабра за этот год. Этот рейтинг не является официальным, данные собираются парсером с помощью Python. Сортируя данные по тем или иным параметрам, можно получать разные выборки, что на мой взгляд, даёт довольно неплохие результаты. Для читателей также может быть интересно перечитать какие-то статьи, которые они пропустили в течении года.
Поехали.
Общая информация
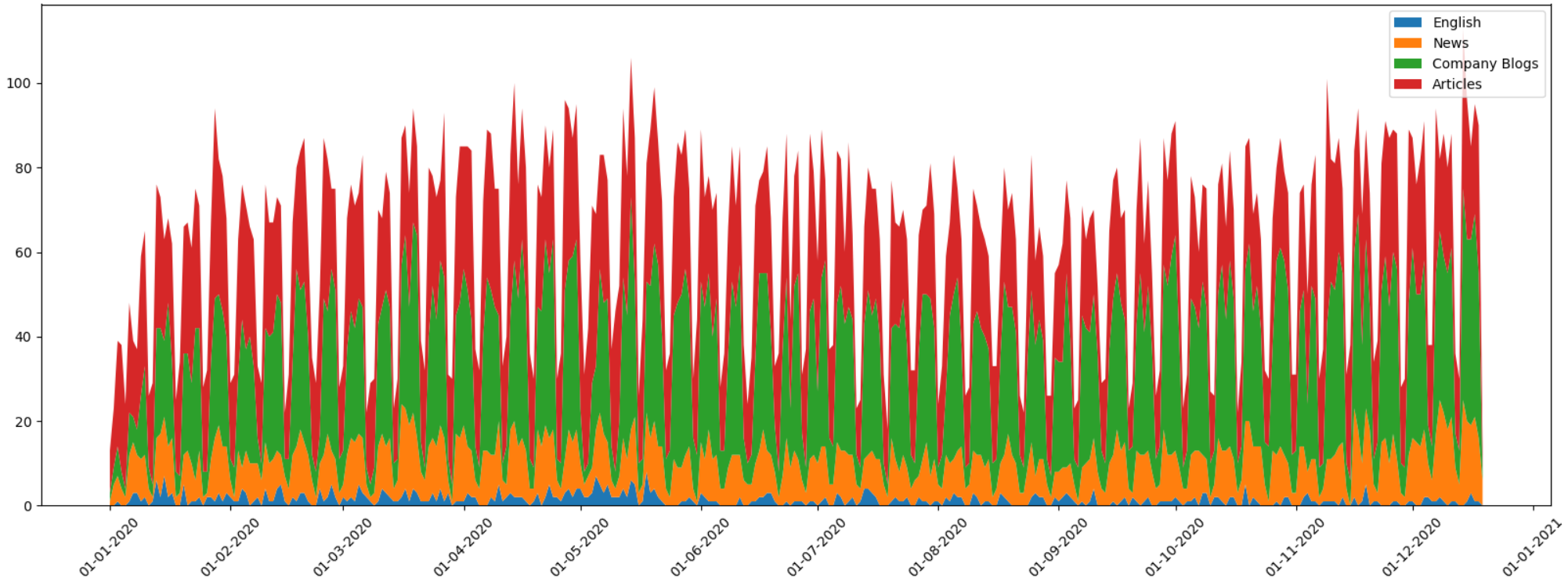
Всего на Хабр было выложено 22 тыс статей, или примерно 60 статей в день. Довольно внушительная цифра, и с сожалением нужно признать, что я наверно не прочитал и 1% от этого числа.
Было интересно посмотреть, не произошло ли каких-то кардинальных изменений по сравнению с прошлым годом. Число публикаций немного выросло, но не кардинально, каких-либо всплесков связанных с локдаунами, на графике не видно. Соотношение количества новостей, статей и корпоративных блогов также осталось примерно на том же уровне. Было также интересно проверить, повлияла ли эпидемия на число просмотров — как оказалось, и да и нет. Есть несколько статей про Covid, число просмотров которых достигает нескольких миллионов (рекорд — 5.5 млн просмотров), но для всех остальных материалов какого-то существенного роста заметно не было.
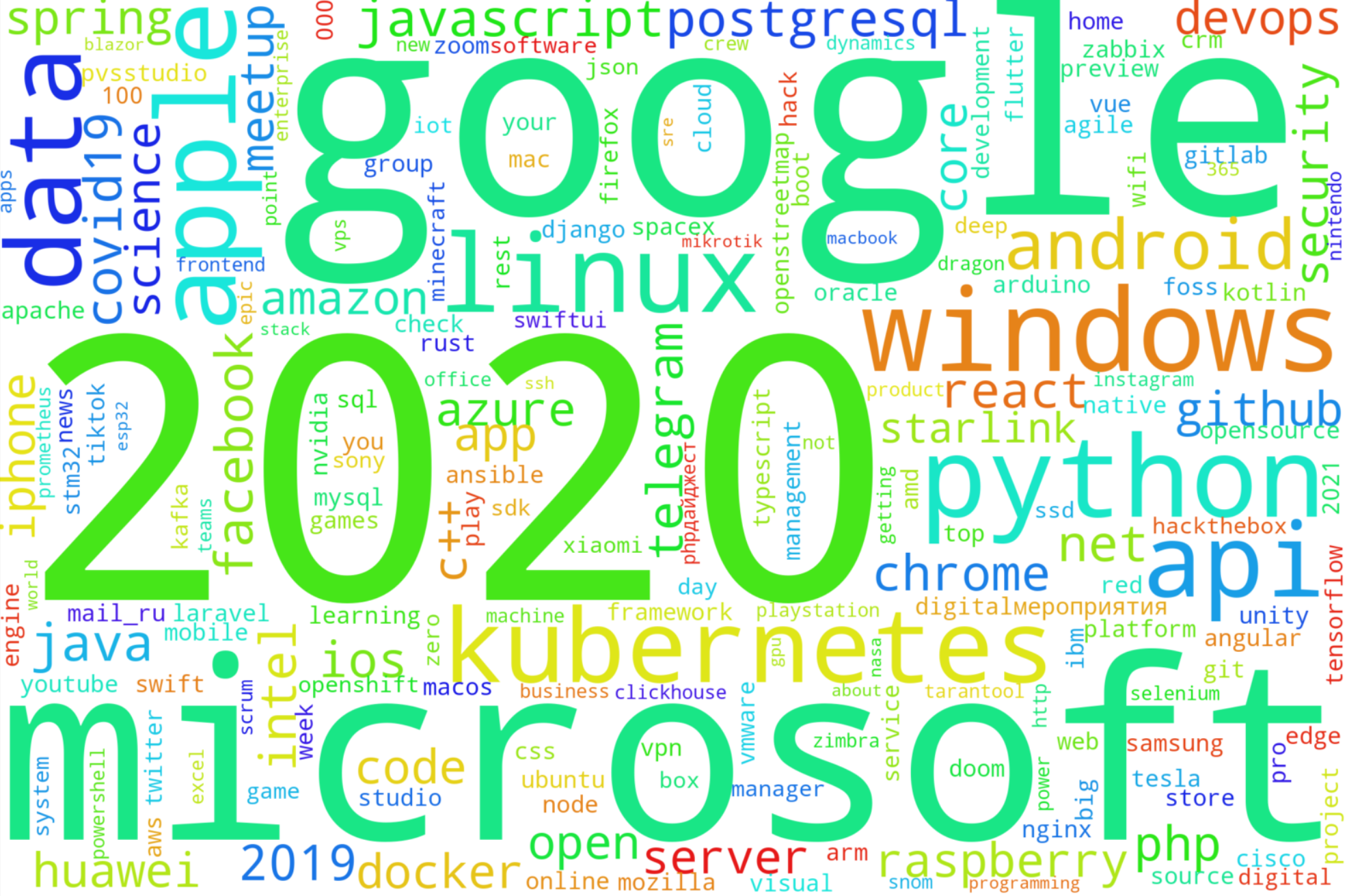
Самые популярные слова в названиях статей принципиально не изменились:
Как «примету года» можно отметить новое слово covid19, которое по популярности оказалось на 14м месте. Впрочем, нельзя сказать, что оно попадалось в названиях так уж часто — про Google, Microsoft и Apple все же писали заметно чаще.
Рейтинг
Перейдем к обещаному рейтингу. При расчете рейтинга я решил сделать одну правку — я намеренно не стал включать в рейтинг статьи про Covid. Во-первых, он и так всем надоел, во-вторых, данные о вирусе довольно быстро устаревают и статьи полугодовой давности уже не столь актуальны, а в третьих, высокие значения просмотров статей про Covid не дадут попасть в рейтинг другим, не менее интересным материалам.
В качестве бонуса я решил составить рейтинг по двум категориям, не относящихся к программированию. В прошлом году это были хабы «Эмиграция» и «Здоровье», в этом году про «здоровье» вещают и так из каждого утюга, так что возьмем… «Эмиграцию» и «Космонавтику». Никакой логической связи между этим выбором просьба не искать, я не призываю эмигрировать на Луну или Марс (а может, и неплохая идея?). Просто космонавтика это хороший повод отвлечься от проблем земных, и прочитать про что-то в прямом смысле слова возвышенное и небесное ;)
Надеюсь, здесь достаточно интересного материала для чтения. И как уже говорилось выше, рейтинг неофициальный — если я кого-то пропустил, пишите, добавлю вручную.
Заключение
В завершение можно поздравить всех авторов попавших в рейтинг, и пожелать всем, и авторам и читателям творческих успехов в следующем году. Надеюсь, приведенная выше подборка окажется полезной в новогодние каникулы, чтобы узнать что-то новое и интересное.
Journalctl — отличный инструмент для анализа логов, обычно один из первых с которым знакомятся начинающие администраторы linux систем. Встроенные возможности ротации, богатые возможности фильтрации и возможность просматривать логи всех systemd unit-сервисов одним инструментом очень удобны и заметно облегчают работу системным администраторам.
Эта статья рассматривает основные возможности утилиты journalctl и различные варианты ее применения. С помощью journalctl можно просматривать логи системы, чтобы решить возникшие проблемы на рабочей станции или сервере использующие дистрибутив linux с демоном инициализации systemd, де-факто уже ставшим стандартом в современных Linux-системах, например: RHEL, CentOS, Fedora, Debian и многих других.
Существует мнение, что systemd не так уж и хорош — он нагружает систему и это все еще предмет для споров на сегодняшний день, но нельзя отрицать, что он предоставляет прекрасный набор инструментов для управления системой и поиска проблем. Представьте, что вам приходится иметь дело с проблемным сервером, который даже не загружается — в таком случае можно загрузиться с live-дистрибутива, смонтировать системный раздел и просмотреть логи systemd, чтобы понять, в чем проблема.
Systemd
Systemd состоит из трех основных компонентов:
systemd — менеджер системы и сервисов
systemctl — утилита для просмотра и управление статусом сервисов
systemd-analyze — предоставляет статистику по процессу загрузки системы, проверяет корректность unit-файлов и так же имеет возможности отладки systemd
Journald
Journald — системный демон журналов systemd. Systemd спроектирован так, чтобы централизованно управлять системными логами от процессов, приложений и т.д. Все такие события обрабатываются демоном journald, он собирает логи со всей системы и сохраняет их в бинарных файлах.
Преимуществ централизованного логирования событий в бинарном формате достаточно много, например системные логи можно транслировать в различные форматы, такие как простой текст, или в JSON, при необходимости. Так же довольно просто можно отследить лог вплоть до одиночного события используя фильтры даты и времени.
Файлы логов journald могут собирать тысячи событий и они обновляются с каждым новым событием, поэтому если ваша Linux-система работает достаточно долго — размер файлов с логами может достигать несколько гигабайт и более. Поэтому анализ таких логов может происходить с задержками, в таком случае, при анализе логов можно фильтровать вывод, чтобы ускорить работу.
Файл конфигурации journald
Файл конфигурации можно найти по следующему пути: /etc/systemd/journald.conf, он содержит различные настройки journald, я бы не рекомендовал изменять этот файл, если вы точно не уверены в том, что делаете.
Каталог с журналом journald располагается /run/log/journal (в том случае, если не настроено постоянное хранение журналов, но об этом позже).
Файлы хранятся в бинарном формате, поэтому нормально их просмотреть с помощью cat или nano, как привыкли многие администраторы — не получится.
Использование journalctl для просмотра и анализа логов
Основная команда для просмотра:
# journalctl
Она выведет все записи из всех журналов, включая ошибки и предупреждения, начиная с того момента, когда система начала загружаться. Старые записи событий будут наверху, более новые — внизу, вы можете использовать PageUp и PageDown чтобы перемещаться по списку, Enter — чтобы пролистывать журнал построчно и Q — чтобы выйти.
По умолчанию journalctl выводит время событий согласно настроенного в вашей системе часового пояса, также journalctl позволяет просмотреть логи с временем UTC (в этом стандарте времени сохраняются события внутри файлов journald), для этого можно использовать команду:
# journalctl --utc
Фильтрация событий по важности
Система записывает события с различными уровнями важности, какие-то события могут быть предупреждением, которое можно проигнорировать, какие-то могут быть критическими ошибками. Если мы хотим просмотреть только ошибки, игнорируя другие сообщения, введем команду с указанием кода важности:
# journalctl -p 0
Для уровней важности, приняты следующие обозначения:
Когда вы указываете код важности, journalctl выведет все сообщения с этим кодом и выше. Например если мы укажем опцию -p 2, journalctl покажет все сообщения с уровнями 2, 1 и 0.
Настройка хранения журналов
По умолчанию journald перезаписывает свои журналы логов при каждой перезагрузке, и вызов journalctl выведет журнал логов начиная с текущей загрузки системы.
Если необходимо настроить постоянное сохранение логов, потребуется отдельно это настроить, т.к. разработчики отказались от постоянного хранения всех журналов, чтобы не дублировать rsyslog.
Когда в конфигурационном файле /etc/systemd/journald.conf параметру Storage= задано значение auto) и каталога /var/log/journal/ не существует, журнал будет записываться в /run/log/journal без сохранения между перезагрузками, если /var/log/journal/ существует, журналы будут сохраняться в нем, на постоянной основе, но если каталог будет удален, systemd не пересоздаст его автоматически и вместо этого будет вести журнал снова в /run/systemd/journal без сохранения. Каталог может быть пересоздан в таком случае, если добавить Storage=persistent в journald.conf и перезапустить systemd-journald.service (или перезагрузиться).
Создадим каталог для хранения журналов, установим необходимые атрибуты и перезапустим службу:
Если journald был настроен на постоянное хранение журналов, мы можем просматривать журналы логов по каждой отдельной загрузке, следующая команда выведет список журналов:
# journalctl --list-boots
Первый номер показывает номер журнала, который можно использовать для просмотра журнала определенной сессии. Второй номер boot ID так же можно использовать для просмотра отдельного журнала.
Следующие две даты, промежуток времени в течении которого в него записывались логи, это удобно если вы хотите найти логи за определенный период.
Например, чтобы просмотреть журнал начиная с текущего старта системы, можно использовать команду:
# journalctl -b 0
А для того, чтобы просмотреть журнал предыдущей загрузки:
# journalctl -b -1
Просмотр журнала за определенный период времени
Journalctl позволяет использовать такие служебные слова как “yesterday” (вчера), “today” (сегодня), “tomorrow” (завтра), или “now” (сейчас).
Поэтому мы можем использовать опцию "--since" (с начала какого периода выводить журнал).
С определенной даты и времени:
# journalctl --since "2020-12-18 06:00:00"
С определенной даты и по определенное дату и время:
Чтобы просмотреть сообщения от ядра Linux за текущую загрузку, используйте команду с ключом -k:
# journalctl -k
Просмотр журнала логов для определенного сервиса systemd или приложения
Вы можете отфильтровать логи по определенному сервису systemd. Например, что бы просмотреть логи от NetworkManager, можно использовать следующую команду:
# journalctl -u NetworkManager.service
Если нужно найти название сервиса, используйте команду:
# systemctl list-units --type=service
Так же можно просмотреть лог приложения, указав его исполняемый файл, например чтобы просмотреть все сообщения от nginx за сегодня, мы можем использовать команду:
# journalctl /usr/sbin/nginx --since today
Или указав конкретный PID:
# journalctl _PID=1
Дополнительные опции просмотра
Следить за появлением новых сообщений (аналог tail -f):
# journalctl -f
Открыть журнал «перемотав» его к последней записи:
# journalctl -e
Если в каталоге с журналами очень много данных, то фильтрация вывода journalctl может занять некоторое время, процесс можно значительно ускорить с помощью опции --file, указав journalctl только нужный нам журнал, за которым мы хотим следить:
По умолчанию journalctl отсекает части строк, которые не вписываются в экран по ширине, хотя иногда перенос строк может оказаться более предпочтительным. Управление этой возможностью производится посредством переменной окружения SYSTEMD_LESS, в которой содержатся опции, передаваемые в less (программу постраничного просмотра, используемую по умолчанию). По умолчанию переменная имеет значение FRSXMK, если убрать опцию S, строки не будут обрезаться.
Например:
SYSTEMD_LESS=FRXMK journalctl
Ограничение размера журнала
Если journald настроен что бы сохранять журналы после перезагрузки, то по умолчанию размер журнала ограничен 10% от объема файлового раздела и максимально может занять 4 Гб дискового пространства.
Максимальный объем журнала можно скорректировать, раскомментировав и отредактировав следующий параметр в файле конфигурации journald:
SystemMaxUse=50M
Удаление журналов
Удалить файлы архивных журналов, можно вручную с помощью rm или использовав journalctl.
Удалить журналы, оставив только последние 100 Мб:
# journalctl --vacuum-size=100M
Удалить журналы, оставив журналы только за последние 7 дней:
# journalctl --vacuum-time=7d
Заключение
Служба журналирования логов journald очень мощный и гибкий инструмент, и если вы знаете как его использовать, он может сделать вашу жизнь намного проще во время поиска причин проблем с системой или ее сервисами.
На волне ажиотажа вокруг новых карточек от Nvidia с поддержкой RTX, я, сканируя хабр в поисках интересных статей, с удивлением обнаружил, что такая тема, как трассировка путей, здесь практически не освящена. "Так дело не пойдет" - подумал я и решил, что неплохо бы сделать что-нибудь небольшое на эту тему, да и так, чтоб другим полезно было. Тут как кстати API собственного движка нужно было протестировать, поэтому решил: запилю-ка я свой простенький path-tracer. Что же из этого вышло вы думаю уже догадались по превью к данной статье.
Немного теории
Трассировка пути является одним из частных случаев трассировки лучей и представляет собой наиболее точный с физической точки зрения способ рендеринга. Используя непосредственное моделирование распространения света для расчета освещения, этот алгоритм позволяет с минимальными усилиями получать весьма реалистичные сцены, для рендеринга которых традиционным способом ушло бы неимоверное количество усилий.
Как и в большинстве классических алгоритмов трассировки лучей, при трассировке путей мы испускаем лучи из позиции камеры на сцену, и смотрим, с чем каждый из них сталкивается. По сути, мы "трассируем путь" фотона, прошедшего от источника света до нашего глаза, но только делаем это в обратную сторону, начиная от позиции наблюдателя (ведь нет смысла рассчитывать свет, который в итоге не дойдет до нашего глаза).
трассировка лучей от позиции наблюдателя
Одним из первых вопросов, которым можно задаться при рассмотрении данного алгоритма: а до какого вообще момента нам нужно моделировать движение луча? С точки зрения физики, практически каждый объект, что нас окружает, отражает хоть сколько-то света. Соответственно, естественный способ моделирования пути фотона - вычисление траектории движения вплоть до тех пор, пока количество отраженного света от объекта станет настолько малым, что им можно пренебречь. Такой метод безусловно имеет место быть, однако является крайне непроизводительным, и поэтому в любом трассирующем лучи алгоритме все же приходится жертвовать физической достоверностью изображения ради получения картинки за хоть сколько-то вменяемое время. Чаще всего выбор числа отражений луча зависит от сцены - для грубых диффузных поверхностей требуется гораздо меньше итераций, нежели для зеркальных или металлических (можете вспомнить классический пример с двумя зеркалами в лифте - свет в них отражается огромное число раз, создавая эффект бесконечного туннеля, и мы должны уметь это моделировать).
различные материалы, отрисованные физически-корректным рендерингом
Другой вопрос, который у нас возникает - какие объекты могут быть на нашей сцене, и какими свойствами они обладают. И тут уже все не так очевидно и чаще всего зависит от конкретной реализации трассировщика. Для примера: в классическом физически-корректном рендеринге для описания объектов используют заранее заготовленный материалы с варьирующимися параметрами: албедо (диффузная отражательная способность материала), шероховатость (параметр, аппроксимирующий неровности поверхности на микро-уровне) и металличность (параметр, задающий отражательную способность материала). Иногда к ним добавляют и другие свойства, такие как прозрачность и показатель преломления.
Я же для своего алгоритма решил условно выделить для материала объекта следующие параметры:
Отражательная способность (reflectance) - какое количество и какой волны свет отражает каждый объект
Шероховатость поверхности (roughness) - насколько сильно лучи рассеиваются при столкновении с объектом
Излучение энергии (emittance) - количество и длина волны света, которую излучает объект
Прозрачность (transparency/opacity) - отношение пропущенного сквозь объект света к отраженному
В принципе, этих параметров достаточно, чтобы смоделировать источники света, зеркальные и стеклянные поверхности, а также диффузные материалы, поэтому я решил, что на данный момент лучше остановиться на них и сохранить простоту получившегося трассировщика.
Реализуем наш алгоритм на GLSL
К сожалению (или к счастью?) сегодня мы не будем делать профессиональный трассировщик путей, и ограничимся лишь базовым алгоритмом с возможностью трассировать на сцене параллелепипеды и сферы. Для них относительно легко находить пересечения c лучем, рассчитывать нормали, да и в целом такого набора примитивов уже достаточно, чтобы отрендерить классический cornell-box.
один из вариантов cornell box'a для тестирования корректности рендеринга
Основной алгоритм мы будем делать во фрагментном GLSL шейдере. В принципе, даже если вы не знакомы с самим языком, код будет достаточно понятным, так как во многом совпадает с языком С: в нашем распоряжении есть функции и структуры, возможность писать условные конструкции и циклы, и ко всему прочему добавляется возможность пользоваться встроенными примитивами для математических расчетов - vec2, vec3, mat3 и т.д.
Ну что же, давайте к коду! Для начала зададим наши примитивы и структуру материала:
Для примитивов реализуем проверки пересечения с лучем: будем принимать начало луча и его направление, а возвращать расстояние до ближайшей точки пересечения и нормаль объекта в этой точке, если, конечно, такое пересечение в принципе произошло:
bool IntersectRaySphere(vec3 origin, vec3 direction, Sphere sphere, out float fraction, out vec3 normal)
{
vec3 L = origin - sphere.position;
float a = dot(direction, direction);
float b = 2.0 * dot(L, direction);
float c = dot(L, L) - sphere.radius * sphere.radius;
float D = b * b - 4 * a * c;
if (D < 0.0) return false;
float r1 = (-b - sqrt(D)) / (2.0 * a);
float r2 = (-b + sqrt(D)) / (2.0 * a);
if (r1 > 0.0)
fraction = r1;
else if (r2 > 0.0)
fraction = r2;
else
return false;
normal = normalize(direction * fraction + L);
return true;
}
bool IntersectRayBox(vec3 origin, vec3 direction, Box box, out float fraction, out vec3 normal)
{
vec3 rd = box.rotation * direction;
vec3 ro = box.rotation * (origin - box.position);
vec3 m = vec3(1.0) / rd;
vec3 s = vec3((rd.x < 0.0) ? 1.0 : -1.0,
(rd.y < 0.0) ? 1.0 : -1.0,
(rd.z < 0.0) ? 1.0 : -1.0);
vec3 t1 = m * (-ro + s * box.halfSize);
vec3 t2 = m * (-ro - s * box.halfSize);
float tN = max(max(t1.x, t1.y), t1.z);
float tF = min(min(t2.x, t2.y), t2.z);
if (tN > tF || tF < 0.0) return false;
mat3 txi = transpose(box.rotation);
if (t1.x > t1.y && t1.x > t1.z)
normal = txi[0] * s.x;
else if (t1.y > t1.z)
normal = txi[1] * s.y;
else
normal = txi[2] * s.z;
fraction = tN;
return true;
}
В рамках данной статьи мы не будем вдаваться в реализацию алгоритмов пересечений - это расписано уже много-много раз. В частности, код двух функций, приведенных в блоке выше, я нагло взял с этого сайта.
Хранить все наши объекты будем в обычных массивах, благо, GLSL создавать их также позволяет. Сцена у нас небольшая, поэтому никаких оптимизаций при поиске пересечения не реализуем - просто проходим по всем объектам и вычисляем ближайшее расстояние до точки пересечения:
#define FAR_DISTANCE 1000000.0
#define SPHERE_COUNT 3
#define BOX_COUNT 8
Sphere spheres[SPHERE_COUNT];
Box boxes[BOX_COUNT];
bool CastRay(vec3 rayOrigin, vec3 rayDirection, out float fraction, out vec3 normal, out Material material)
{
float minDistance = FAR_DISTANCE;
for (int i = 0; i < SPHERE_COUNT; i++)
{
float D;
vec3 N;
if (IntersectRaySphere(rayOrigin, rayDirection, spheres[i], D, N) && D < minDistance)
{
minDistance = D;
normal = N;
material = spheres[i].material;
}
}
for (int i = 0; i < BOX_COUNT; i++)
{
float D;
vec3 N;
if (IntersectRayBox(rayOrigin, rayDirection, boxes[i], D, N) && D < minDistance)
{
minDistance = D;
normal = N;
material = boxes[i].material;
}
}
fraction = minDistance;
return minDistance != FAR_DISTANCE;
}
Функция выше позволяет нам найти точку столкновения луча с поверхностью. Это работает, но мы получаем информацию только о прямом освещении. Мы же хотим учитывать еще и непрямое освещение, поэтому давайте немного подумаем над тем, как меняется поток света при столкновениях с объектами на нашей сцене.
Трассировка пути
В нашей реализации каждый объект может излучать свет, отражать свет, и поглощать (случай с преломлением пока опустим). В таком случае формулу для расчета отраженного света от поверхности можно задать следующим образом: L' = E + f*L, где E - излучаемый объектом свет (emittance), f - отражаемый объектом свет (reflectance), L - свет, упавший на объект, и L' - то, что объект в итоге излучает.
И в итоге такое выражение легко представить в виде итеративного алгоритма:
// максимальное количество отражений луча
#define MAX_DEPTH 8
vec3 TracePath(vec3 rayOrigin, vec3 rayDirection)
{
vec3 L = vec3(0.0); // суммарное количество света
vec3 F = vec3(1.0); // коэффициент отражения
for (int i = 0; i < MAX_DEPTH; i++)
{
float fraction;
vec3 normal;
Material material;
bool hit = CastRay(rayOrigin, rayDirection, fraction, normal, material);
if (hit)
{
vec3 newRayOrigin = rayOrigin + fraction * rayDirection;
vec3 newRayDirection = ...
// рассчитываем, куда отразится луч
rayDirection = newRayDirection;
rayOrigin = newRayOrigin;
L += F * material.emmitance;
F *= material.reflectance;
}
else
{
// если столкновения не произошло - свет ничто не испускает
F = vec3(0.0);
}
}
// возвращаем суммарный вклад освещения
return L;
}
Если бы мы писали наш код на условном C++, можно было бы напрямую получать L как результат работы рекурсивно вызываемой функции CastRay. Однако, GLSL не разрешает рекурсивные вызовы функций в любом виде, поэтому приходится развернуть наш алгоритм так, чтобы он работал итеративно. С каждым отражением мы уменьшаем коэффициент, на который умножается испускаемый или отражаемый объектом свет, и тем самым повторяем описанную выше формулу. В моей реализации потенциально каждый объект может излучать какое-то количество света, поэтому emittance учитывается при каждом столкновении. Если же луч ни с чем не сталкивается, мы считаем, что никакого света до нас не дошло. В принципе для таких случаев можно добавить выборку из карты окружения или задать "дневной свет", но после экспериментов с этим я понял, что больше всего мне нравится текущая реализация, с пустотой вокруг сцены.
Об отражениях
Теперь давайте решим следующий вопрос: а по какому же принципу луч отражается от объекта? Очевидно, что в нашем path-tracer'е это будет зависеть от нормали в точке падения и микро-рельефа поверхности. Если обратиться к реальному миру, мы увидим, что для гладких материалов (таких как отполированный металл, стекло, вода) отражение будет очень четким, так как все лучи, падающие на объект под одним углом, будут и отражаться примерно под одинаковым углом (см. specular на картинке ниже), когда как для шероховатых, неровных поверхностей мы наблюдаем очень размытые отражения, чаще всего диффузные (см. diffuse на картинке ниже), так как лучи распространяются по полусфере относительно нормали объекта. Именно этой закономерностью мы и воспользуемся, задав итоговое направление отраженного луча как D = normalize(a * R + (1 - a) * T), где a - коэффициент шероховатости/гладкости поверхности, R - идеально отраженный луч, T - луч, отраженный в случаном направлении в полусфере относительно нормали. Очевидно, что при коэффициенте a = 1 в такой формуле мы всегда будет получать идеальное отражение луча, а при a = 0, наоборот, равномерно распределенное по полусфере. При коэффициенте шероховатости, лежащем в интервале от 0 до 1, на выходе будем иметь некоторое распределение лучей, ориентированное по углу отражения, что в вполне корректно и как раз характерно для глянцевых поверхностей (см. glossy на картинке ниже).
распределение лучей для различных типов поверхностей
Вернемся к коду. Давайте начнем в этот раз с самого сложного - напишем реализацию функции, которая бы возвращала нам случайный луч в полусфере относительно нормали. Для этого сначала возьмем какой-нибудь набор случайно распределенных чисел, и сгенерируем по ним луч, лежащий в на границе сферы единичного радиуса, а затем тривиальным образом спроецируем его в ту же полусферу, где находится нормаль объекта:
Не забываем: сгенерированный нами луч хоть и лежит в одной полусфере с нормалью, но множество таких случайных лучей все еще не ориентировано под нужным нам углом. Чтобы это исправить, давайте спроецируем их в пространство нормали: зададим еще один случайный вектор, затем найдем третий через векторное произведение, и соединим их всех в матрицу трансформации:
Небольшое примечание: здесь и далее Random?D генерирует случайные числа в интервале от 0 до 1. В GLSL шейдере делать это можно разными способами. Я использую следующую функцию, генерирующую случайным шум без явных паттернов (любезно взята со StackOverflow по первому запросу):
В комбинации с такими параметрами как координатой текущего пикселя (gl_FragCoord), временем работы приложения, и еще какими-то независимыми переменными можно сгенерировать достаточно много псевдослучайных чисел. Вы также можете пойти иначе и просто передавать массив случайных чисел в шейдер, но это уже дело вкуса.
отражения с различной шероховатостью
После всех наших модификацийкод нашей функции TracePath будет выглядеть вот так:
vec3 TracePath(vec3 rayOrigin, vec3 rayDirection)
{
vec3 L = vec3(0.0);
vec3 F = vec3(1.0);
for (int i = 0; i < MAX_DEPTH; i++)
{
float fraction;
vec3 normal;
Material material;
bool hit = CastRay(rayOrigin, rayDirection, fraction, normal, material);
if (hit)
{
vec3 newRayOrigin = rayOrigin + fraction * rayDirection;
vec3 hemisphereDistributedDirection = RandomHemispherePoint(Random2D(), normal);
randomVec = normalize(2.0 * Random3D() - 1.0);
vec3 tangent = cross(randomVec, normal);
vec3 bitangent = cross(normal, tangent);
mat3 transform = mat3(tangent, bitangent, normal);
vec3 newRayDirection = transform * hemisphereDistributedDirection;
vec3 idealReflection = reflect(rayDirection, normal);
newRayDirection = normalize(mix(newRayDirection, idealReflection, material.roughness));
// добавим небольшое смещение к позиции отраженного луча
// константа 0.8 тут взята произвольно
// главное, чтобы луч случайно не пересекался с тем же объектом, от которого отразился
newRayOrigin += normal * 0.8;
rayDirection = newRayDirection;
rayOrigin = newRayOrigin;
L += F * material.emmitance;
F *= material.reflectance;
}
else
{
F = vec3(0.0);
}
}
return L;
}
Преломление света
Давайте рассмотрим еще такой важный для нас эффект, как преломление света. Все же помнят, как соломка, находящаяся в стакане, кажется сломанной в том месте, где она пересекается с водой? Этот эффект происходит потому, что свет, переходя между двумя средами с разными свойствами, меняет свою волновую скорость. Вдаваться в подробности того, как это работает с физической точки зрения мы не будем, вспомним лишь, что если свет падаем под углом a, то угол преломления b можно посчитать по следующей несложной формуле (см. закон Снеллиуса): b = arcsin(sin(a) * n1 / n2), где n1 - показатель преломления среды, из которой пришел луч, a n2 - показатель преломления среды, в которую луч вошел. И к счастью для нас, показатели преломления уже рассчитаны для интересующих нас сред, достаточно лишь открыть википедию, или, накрайняк, учебник по физике.
Угол падения, отражения и преломления
Стоит заметить следующий интересный факт: sin(a) принимает значения от 0 для 1 для острых углов. Относительный показатель преломления n1 / n2 может быть любым, в том числе большим 1. Но тогда выходит, что аргумент sin(a) * n1 / n2 не всегда находится в области определения функции arcsin. Что же происходит с углом преломления? Почему наша формула не работает для такого случая, хотя с физической точки зрения ситуация вполне возможная?
Ответ кроется в том, что в реальном мире при таких условиях луч света попросту не преломится, а отразится! Данный эффект абсолютно логичен, если вспомнить, что в момент столкновения луча с границей раздела двух сред, он по сути "делится на двое", и лишь часть света преломляется, когда как остальная отражается. И с увеличением наклона под которым падает этот луч, все больше и больше света будет отражаться, пока не дойдет до того вырожденного, критического момента. Данное явление в физике носит название внутреннее отражение, а частный его случай, когда абсолютно весь свет отражается от границы раздела сред, называется полным внутренним отражением. И этот факт нужно будет учитывать в реализации нашего трассировщика путей.
эффект Френеля
Сколько же света в итоге будет отражено от поверхности, а сколько пройдет сквозь нее? Чтобы ответить на этот вопрос, нам необходимо обратиться к формулам Френеля, которые как раз и используются для расчета коэфициентов отрадения и пропускания. Но не спешите ужасаться - в нашем трассировщике мы не будем расписывать эти громоздкие выражения. Давайте воспользуемся более простой аппроксимирующей формулой за авторством Кристофе Шлика - аппроксимацией Шлика. Она достаточно простая в реализации и дает приемлимые визуальные результаты, поэтому не вижу причин не добавить ее в наш код:
Ну что же, применим весь наш пройденный материал: первым делом реализуем функцию, которая бы возвращала преломленный луч с учетом полного внутреннего отражения, о котором мы говорили выше:
vec3 IdealRefract(vec3 direction, vec3 normal, float nIn, float nOut)
{
// проверим, находимся ли мы внутри объекта
// если да - учтем это при рассчете сред и направления луча
bool fromOutside = dot(normal, direction) < 0.0;
float ratio = fromOutside ? nOut / nIn : nIn / nOut;
vec3 refraction, reflection;
refraction = fromOutside ? refract(direction, normal, ratio) : -refract(-direction, normal, ratio);
reflection = reflect(direction, normal);
// в случае полного внутренного отражения refract вернет нам 0.0
return refraction == vec3(0.0) ? reflection : refraction;
}
Чтобы учитывать эффект френеля, будем просто генерировать случайное число, и на его основе решать, преломится ли луч или отразится. Также не забываем, что у наших объектов есть параметр плотности, который также отвечает за отношение преломленного света к отраженному. Соединить оба этих условия можно по-разному, но я взял самый примитивный вариант:
Теперь наконец можно склеить все вместе: добавим в нашу функцию TracePath логику, которая бы рассчитывала преломление света и при этом учитывала и шереховатость объекта - ее для полупрозрачных тел никто не отменял:
#define N_IN 0.99
#define N_OUT 1.0
vec3 TracePath(vec3 rayOrigin, vec3 rayDirection)
{
vec3 L = vec3(0.0);
vec3 F = vec3(1.0);
for (int i = 0; i < MAX_DEPTH; i++)
{
float fraction;
vec3 normal;
Material material;
bool hit = CastRay(rayOrigin, rayDirection, fraction, normal, material);
if (hit)
{
vec3 newRayOrigin = rayOrigin + fraction * rayDirection;
vec3 hemisphereDistributedDirection = RandomHemispherePoint(Random2D(), normal);
randomVec = normalize(2.0 * Random3D() - 1.0);
vec3 tangent = cross(randomVec, normal);
vec3 bitangent = cross(normal, tangent);
mat3 transform = mat3(tangent, bitangent, normal);
vec3 newRayDirection = transform * hemisphereDistributedDirection;
// проверяем, преломится ли луч. Если да, то меняем логику рассчета итогового направления
bool refracted = IsRefracted(Random1D(), rayDirection, normal, material.opacity, N_IN, N_OUT);
if (refracted)
{
vec3 idealRefraction = IdealRefract(rayDirection, normal, N_IN, N_OUT);
newRayDirection = normalize(mix(-newRayDirection, idealRefraction, material.roughness));
newRayOrigin += normal * (dot(newRayDirection, normal) < 0.0 ? -0.8 : 0.8);
}
else
{
vec3 idealReflection = reflect(rayDirection, normal);
newRayDirection = normalize(mix(newRayDirection, idealReflection, material.roughness));
newRayOrigin += normal * 0.8;
}
rayDirection = newRayDirection;
rayOrigin = newRayOrigin;
L += F * material.emmitance;
F *= material.reflectance;
}
else
{
F = vec3(0.0);
}
}
return L;
}
Для коэффициентов преломления N_IN и N_OUT я взял два очень близких числаdoo. Это не совсем физически-корректно, однако создает желаемый эффект того, что поверхности сделаны из стекла (как шар на первом скриншоте статьи). Можете смело их изменить и посмотреть, как поменяется угол преломления лучей, проходящих сквозь объект.
Давайте уже запускать лучи!
Дело осталось за малым: инициализировать нашу сцену в начале шейдера, передать внутрь все параметры камеры, и запустить лучи по направлению взгляда. Начнем с камеры: от нее нам потребуется несколько параметров: direction - направление взгляда в трехмерном пространстве. up - направление "вверх" относительно взгляда (нужен чтобы задать матрицу перевода в мировое пространство), а также fov - угол обзора камеры. Также передадим для рассчета чисто утилитарные вещи - экранную позицию обрабатываемого пикселя (от 0 до 1 по x и y) и размер окна для рассчета отношения сторон. В математику в коде тоже особо углубляться не буду - о том, как переводить из пространство экрана в пространство мира можно почитать к примеру в этой замечательной статье.
Как бы ни прискорбно это было заявлять, но законы, по которым отражаются наши лучи имеют некоторую случайность, и одного семпла на пиксель нам будет мало. И даже 16 семплов на пиксель не достаточно. Но не расстраивайтесь! Давайте найдем компромисс: каждый кадр будем считать от 4 до 16 лучей, но при этом результаты кадров аккамулировать в одну текстуру. В итоге мы делаем не так много работы каждый кадр, можем летать по нашей сцене (хоть и испытывая на своих глазах ужасные шумы), а при статичной картинке качество рендера будет постепенно расти, пока не упрется в точность float'а. Преимущества такого подхода видны невооруженным взглядом:
рендер одного кадра и нескольких, сложенных вместе
В итоге наша функция main будет выглядеть примерно следующим образом (в алгоритме нет ничего сложного - просто запускаем несколько лучей и считаем среднее от результата TracePath):
Давайте закроем вопрос с тем, как мы будем отображать результат работы трассировщика. Очевидно, что если мы решили накапливать кадры в одной текстуре, то классический вариант с форматом вида RGB (по байту на каждый канал) нам не подойдет. Лучше взять что-то вроде RGB32F (проще говоря формат, поддерживающий числа с плавающей точкой одинарной точности). Таким образом мы сможем накапливать достаточно большое количество кадров прежде чем упремся в потолок из-за потерь точности вычислений.
Также сходу напишем шейдер, принимающий нашу аккамулирующую текстуру и вычисляющий среднее от множества кадров. Тут же применим тональную коррекцию изображения, а затем гамма-коррекцию (в коде я использую самый простой вариант tone-mapping'а, вы можете взять что-то посложнее, к примеру кривую Рейнгарда):
// post_process_fragment.glsl
in vec2 TexCoord;
out vec4 OutColor;
uniform sampler2D uImage;
uniform int uImageSamples;
void main()
{
vec3 color = texture(uImage, TexCoord).rgb;
color /= float(uImageSamples);
color = color / (color + vec3(1.0));
color = pow(color, vec3(1.0 / 2.2));
OutColor = vec4(color, 1.0);
}
И на этом часть с GLSL кодом можно считать оконченной. Как будет выглядеть наш трассировщий снаружи - вопрос открытый и зависит полностью от вас. Ниже я конечно же приведу реализацию рендеринга в контексте API моего движка, на котором я и писал данный трассировщик, но информация эта скорее опциональная. Думаю вам не составит труда написать связующий код на том фреймворке или графическом API, с которым лично вам удобнее всего работать:
virtual void OnUpdate() override
{
// получаем текущую камеру и текстуру, в которую осуществляется рендер
auto viewport = Rendering::GetViewport();
auto output = viewport->GetRenderTexture();
// получим текущие параметры камеры (позицию, угол обзора и т.д.)
auto viewportSize = Rendering::GetViewportSize();
auto cameraPosition = MxObject::GetByComponent(*viewport).Transform.GetPosition();
auto cameraRotation = Vector2{ viewport->GetHorizontalAngle(), viewport->GetVerticalAngle() };
auto cameraDirection = viewport->GetDirection();
auto cameraUpVector = viewport->GetDirectionUp();
auto cameraFOV = viewport->GetCamera<PerspectiveCamera>().GetFOV();
// проверим, что камера неподвижна. От этого зависит, нужно ли очищать предыдущий кадр
bool accumulateImage = oldCameraPosition == cameraPosition &&
oldCameraDirection == cameraDirection &&
oldFOV == cameraFOV;
// при движении снизим количество семплов ради приемлемой частоты кадров
int raySamples = accumulateImage ? 16 : 4;
// установим все униформы в шейдере, осуществляющем трассировку лучей
this->rayTracingShader->SetUniformInt("uSamples", raySamples);
this->rayTracingShader->SetUniformVec2("uViewportSize", viewportSize);
this->rayTracingShader->SetUniformVec3("uPosition", cameraPosition);
this->rayTracingShader->SetUniformVec3("uDirection", cameraDirection);
this->rayTracingShader->SetUniformVec3("uUp", cameraUpVector);
this->rayTracingShader->SetUniformFloat("uFOV", Radians(cameraFOV));
// меняем тип блендинга в зависимости от того, аккамулируем ли мы кадры в одну текстуру
// также считаем количество кадров, чтобы потом получить среднее значение
if (accumulateImage)
{
Rendering::GetController().GetRenderEngine().UseBlending(BlendFactor::ONE, BlendFactor::ONE);
Rendering::GetController().RenderToTextureNoClear(this->accumulationTexture, this->rayTracingShader);
accumulationFrames++;
}
else
{
Rendering::GetController().GetRenderEngine().UseBlending(BlendFactor::ONE, BlendFactor::ZERO);
Rendering::GetController().RenderToTexture(this->accumulationTexture, this->rayTracingShader);
accumulationFrames = 1;
}
// рассчитаем среднее от множества кадров и сохраним в рендер-текстуру камеры
this->accumulationTexture->Bind(0);
this->postProcessShader->SetUniformInt("uImage", this->accumulationTexture->GetBoundId());
this->postProcessShader->SetUniformInt("uImageSamples", this->accumulationFrames);
Rendering::GetController().RenderToTexture(output, this->postProcessShader);
// обновим сохраненные параметры камеры
this->oldCameraDirection = cameraDirection;
this->oldCameraPosition = cameraPosition;
this->oldFOV = cameraFOV;
}
В заключение
Ну что же, на этом все! Всем спасибо за прочтение этой небольшой статьи. Хоть мы и не успели рассмотреть множество интересных эффектов в path-tracing'е, опустили обсуждение различных ускоряющих трассировку структур данных, не сделали денойзинг, но все равно итоговый результат получился весьма сносным. Надеюсь вам понравилось и вы нашли для себя что-то новое. Я же по традиции приведу в конце несколько скриншотов, полученных с помощью path-tracer'а:
эффект бесконечного туннеля от двух параллельных зеркалпреломление света при взгляде сквозь прозрачную сферунепрямое освещение и мягкие тени