Посвящается моей дорогой маме, по совместительству лучшему эксперту в раздельной сортировке пластмасс...
Если, дорогой читатель, у тебя никогда в жизни не возникал за вопрос "что, черт побери, это за пластмасса такая?", то можешь статью не читать :). Вниманию же всех остальных — очередная статья из серии "положи в закладки!". Сегодня у нас тема — "Определение пластмасс в домашних условиях" и я продолжаю wikipedia-ровать Хабр полезной информацией, которая осталась у меня после выполнения моих научно-технических проектов. Сегодня под кат смело могут идти экологи, биотехнологи, мастера полимерных производств, инженеры по переработке пластмасс и все, кому приходилось сортировать пластики, клеить пластики, паять пластики — автолюбители, самодельщики и все заинтересованные лица. Традиционно — минимум FUN-а, максимум информации, полнее русскоязычную мануалку по пластикам просто не найти, "я гарантирую это" :)
… И наконец-то руки дошли вспомнить советский детский роман 1966 года, в котором практических рекомендаций ребенку "которому нравится химия" гораздо больше чем в современных белорусских учебниках химии вместе взятых.

Зашел тут ко мне мой старый химический дружок Сережа и заговорили мы про мои хабра статьи. Плавно перешли от растворителей пластмасс на клея для все тех же пластмасс и вдруг я не нашелся что ответить на "а вот я в машинке сына так и не разобрался что за пластмасса, чтобы ее склеить по твоим статьям". И я решил исправить ситуацию, помочь всем отцам, которые столкнулись с нелегкой задачей ремонта пластиковой китайской радиоуправляемой машинки, подаренной их чадам и упорядочить имеющуюся информацию по "обратной разработке" пластика. Предупрежден — значит вооружен. Чтобы подобрать оптимальный клей — нужно знать, что будем клеить :) Кстати, читателю genseq также рекомендую мой опус прочитать, вдруг это поможет идентифицировать пластик нанопорового секвенатора ;)
Фактически, с понятием анализа пластмасс впервые я столкнулся еще в глубоком детстве, когда прочитал книгу Владимира Киселева "Девочка и птицелет" (если что, издательство "Детская литература", Москва, 1966 (!)). Очень чистый и светлый роман, и что главное, с ядреными для ребенка лабораторными подходами. Больше всего мне запомнился эпизод с перегонкой органического стекла, который я еще упомяну по тексту статьи...
Про разложение PMMA в детской книге
<...> После школы я не стала заниматься с Колей, а направилась к Вите, где наши ребята сегодня собирались приготовить из чернильного прибора — бывают такие чернильные приборы из прозрачной пластмассы — полиметилметакрилат — очень ценное для наших опытов химическое вещество. Для этого нужно было построить специальную установку с холодильником и конденсатором готового продукта. В холодильнике я предложила использовать сухой лед, который всегда остается у мороженщицы в нашем гастрономе, и Витя сказал, что это ценное рационализаторское предложение <...> Тем временем мы приготовили прибор для перегонки осколков чернильного прибора в полиметилметакрилат. Для этого мы соединили колбу из жаростойкого
стекла с холодильником, который приготовили из коробки из-под ботинок. В эту коробку мы сложили сухой лед. Холодильник стеклянной трубкой мы связали с конденсатором — широкогорлой бутылкой из-под молока.
Анализ и "обратная разработка" полимеров — дело сложное, неблагодарное и в бытовых условиях достаточно сложно реализуемое. В зависимости от типа пластика и присутствующих в нем функциональных добавок может понадобится как минимум ИК-Фурье спектрометр (как заметил в моей статье про растворители для пластмасс читатель CactusKnight "хотя бы простейший ИК-Фурье спектрометр, на котором за 30 секунд можно получить спектры пластмасс"), а лучше ЯМР, масс-спектрометрия, рентгенофазовый анализ или что похлеще. Естественно, учитывая стоимость подобного оборудования (и наличие специально обученного персонала), становится ясно, что удовольствие это не из дешевых. Но дело в том, что чаще для многих практических целей часто достаточно определить, к какому классу пластмасс относится неизвестный образец, без анализа на пластификаторы, наполнители и т.п. (хотя от них очень часто зависят важные свойства пластика). Для этого можно и нужно использовать простые методы, которые, по большому счету, даже не требуют специальных химических знаний. Говоря про ограничения, помимо уже упомянутых добавок, можно упомянуть и анализ сложных сополимеров и смесей полимеров. Такие вещи очень сложно идентифицировать без привлечения серьезных инструментальных способов анализа.
Вводно о пластмассах
Пластмассы представляют собой высокомолекулярные (полимерные) органические вещества, которые обычно синтезируются из низкомолекулярных соединений (мономеров). Они могут быть получены как путем химической модификации высокомолекулярных природных материалов (целлюлозы и т.п.), так и из природного минерального сырья (нефть, природный газ, каменный уголь). Наиболее важные промышленные способы получения пластмасс из мономеров могут быть классифицированы по механизму реакции образования полимера, например, полимеризация или конденсация. Но так как различные химически идентичные пластмассы могут быть получены разными способами и из разных видов сырья, то эта классификация слабо поможет при анализе неизвестных образцов. Но с другой стороны, помимо химических исследований, внешний вид пластика, а также его поведение при нагревании дает полезную информацию для его точной идентификации.
За знакомые нам полезные свойства полимеров отвечают чаще всего физические взаимодействия между отдельными макромолекулами, составляющими "каркас" пластика. Эти взаимодействия отвечают за сцепление молекул, а значит и за прочность, твердость, эластичность. Пластмассы, состоящие из линейных нитевидных молекул (длиной в несколько сотен нанометров и диаметром в несколько десятых нанометра), макромолекулы которых слабо связаны (сшиты) между собой, легко размягчаются при нагревании. Когда полимерный материал нагревается выше определенной температуры, макромолекулы, которые более или менее ориентированы относительно друг друга при низких температурах, начинают скользить мимо друг друга, образуя высоковязкий расплав. В зависимости от степени упорядоченности макромолекулы в твердом состоянии можно различать частично кристаллизованные (частично упорядоченные и аморфные (неупорядоченные) пластики. Степень упорядоченности очень сильно влияет на поведение пластика при нагревании и на его растворимость. На картинке ниже представлено схематическое изображение структуры пластмасс, показывая три основных типа макромолекулярных структур:
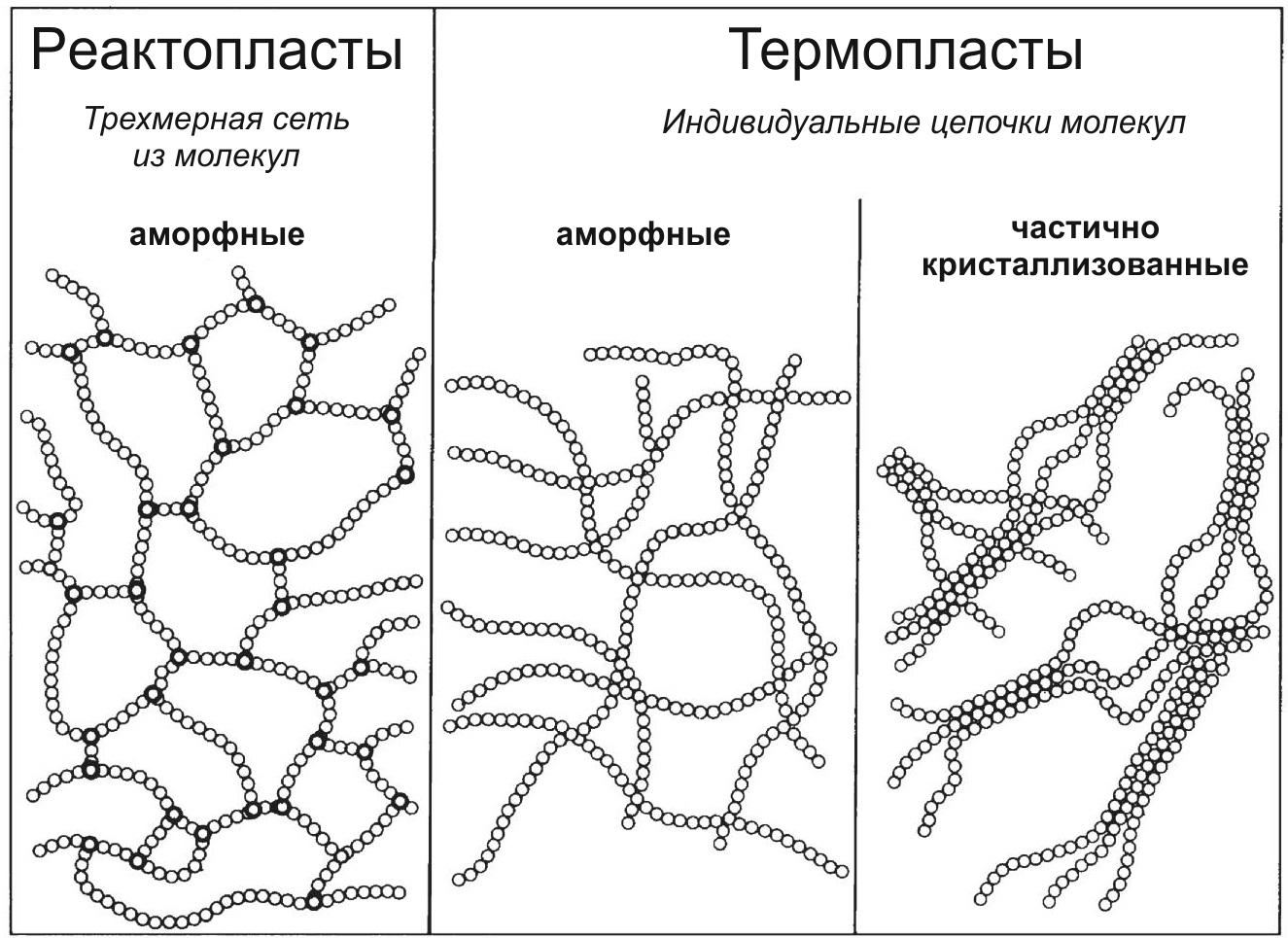
Термопласты и реактопласты
Пластмассы, которые размягчаются при нагревании и обладают в таком состоянии текучестью, принято называть термопластами. При охлаждении такие пластики снова становятся твердыми. Этот процесс может повторяться много раз. Правда существуют и исключения, когда температура при которой пластик начинает разлагаться ниже, чем температура размягчения. Пластмасса просто не успевает поплыть, потому что распадается на химические составляющие. Кстати, растворимость в органических жидкостях (подробно освященная в моей прошлой статье), наравне с температурным воздействием может служить индикатором линейности/разветвленности макромолекул полимера. Потому что растворители внедряясь между полимерными цепями, уменьшает силы взаимодействия между макромолекулами и дает им возможность перемещаться относительно друг друга. Важно! Поэтому кстати информация из хабра-статьи Растворители для пластмасс и защита от них может служить индикатором для определения типа пластмассы так же, как и все методы описанные в статье ниже.
В отличие от термопластичных материалов, иной класс полимеров, так называемые термореактивные материалы, или реактопласты обладают высокой термостабильностью. Такие вещества представляют собой трехмерные сети из намертво сшитых макромолекул, которые уже не могут ни плавиться, ни растворяться. Разрушить сшивки можно только очень высокими температурами или агрессивными химическими реагентами.
Отдельно можно отметить эластичные, резиноподобные эластомеры, состоящие из относительно слабо сшитых макромолекул. Жесткую структуру такие материалы приобретают в процессе вулканизации. Из-за сшитой структуры эластомеры не плавятся при нагревании вплоть до температуры, которая незначительнониже температуры их разложения. В отличие от химически сшитых эластомеров, вроде химического каучука, сшивка в так называемых термопластичных эластомерах ("резины для 3D принтеров) происходит посредством физических взаимодействий между макромолекулами. При нагреве силы физического взаимодействия между молекулами цепи уменьшаются, так что эти полимеры становятся обычными термопластами. При охлаждении, когда физическое взаимодействие между молекулами становится более сильным, материал снова ведет себя как эластомер. В таблице ниже перечислены наиболее важные характеристики упомянутых групп полимерных материалов. Однако следует помнить, что пигменты, пластификатор и различные наполнители (например, сажа или стекловолокно) приводят к значительным отклонениям от этих свойств. Поэтому не всегда возможно идентифицировать полимерные материалы только на основе этих критериев. Плотности даны для ориентира и представляют собой грубые приближения с акцентом на твердые монолитные материалы (потому что вспененные пластики разительно по плотности отличаются от пластиков монолитных).
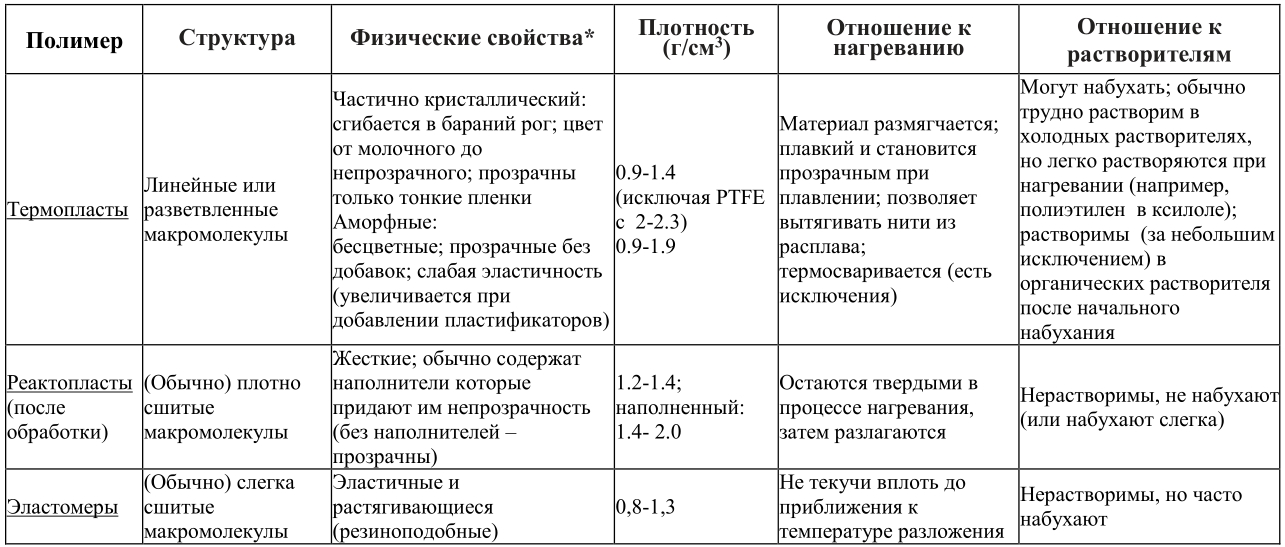
В копилку "физических свойств". Примерным показателем твердости пластика является его поведение при царапании ногтем: твердый пластик царапает ноготь; роговидные пластики имеют примерно одинаковую твердость с пластиком; гибкий или эластичный пластик царапается/продавливается ногтем.
Если мысленный эксперимент с использованием таблицы не дал результатов — самое время читать дальше и переходить к более радикальным мерам.
С чего начать ?
Начать нужно с визуального осмотра. Производители практически всегда с помощью штамповки указывают на пластиковых изделиях их тип. Каждый наверное встречал где-нибудь (чаще на нижней части пластиковой упаковки) такие вот значки:

Это так называемые коды переработки — специальные знаки, применяются для обозначения материала, из которого изготовлен предмет, и упрощения процедуры сортировки перед его отправкой на переработку для вторичного использования. На данный момент утверждено не так и много кодов, характерных для определенного типа пластика. Связано это с тем, что все чаще используются смеси различных разнородных материалов (вроде пластик+фольга+бумага). Треугольник, в котором указаны цифры — подразумевает возможность повторной переработки. Ну а сами цифры — тип пластмассы. Цифры могут быть проштампованы и без треугольника, но идентифицировать пластмассу по ним все равно можно. Для этого используем данные из таблицы под спойлером, со списком утверждённых IUPAC аббревиатур для пластмасс.
Цифровые коды для пластиков по IUPAC
Если опознавательных знаков не найдено — переходим к физическим испытания. Сначала — самые простые
Идентификация пластика по плотности
Технически, понятие плотности пластмасс используется очень редко как описательная характеристика. Связано это с тем, что многие пластмассы содержать всевозможные пустоты, поры и дефекты (что напрямую зависит от культуры производства). Истинная плотность в принципе может быть определена из массы и объема по "методу Архимеда", т.е. вытеснением равного объема жидкости. Такой метод вполне подходит для гранулированных или порошкообразных образцов. Для многих материалов гораздо удобнее использовать т.н. флотационный подход, когда образец плавает в жидкости с одинаковой с ним плотностью.
Плотность используемой жидкости измеряется с помощью ареометра (повсеместно распространенные спиртометры — вариация ареометра с разметкой шкалы в объемных процентах спирта).
Ареометр для электролита/тосола
В качестве модельных жидкостей можно использовать водные растворы
хлорида цинка или хлорида магния. Если плотности ниже 1 г/см3 подойдут смеси метанола/этанола с водой. Ограничение при флотационном методе: образец не должен растворяться/набухать в жидкости; образец должен полностью смачиваться; на образце должны полностью отсутствовать пузырьки воздуха.
Важно отметить, что сажа, стекловолокно и другие наполнители могут сильно влиять на показатель плотности. Например, плотность могут варьироваться в зависимости от содержания наполнителя от 0,98 г/см3 (полипропилен вес. 10% талька) до 1,71 г/см3 (полибутилентерефталат, содержащий вес. 50% стекловолокна). Вспененные полимеры вообще нет смысла оценивать по параметру плотности, там один воздух.
В простейшем случае, если отсутствуют точные методы определения плотности, можно погрузить исследуемый образец в метанол (плотность при 20 °C = 0,79 г/см3), воду (1 г/см3), насыщенный водный раствор хлорида магния (1,34 г/см3) или насыщенный водный раствор хлорида цинка (2,01 г/см3). Далее смотрим на поведение кусочка пластмассы в жидкости, тонет он или всплывает. Это говорит о том, больше его плотность или меньше, чем плотность жидкости, в которую он погружен. Для приготовления 1 литра насыщенного раствора нужно примерно 1575 г хлорида цинка или 475 г хлорида магния. Доводим отвешенную заранее соль водой до 1 л раствора и растворяем при постоянном перемешивании. Предвидя вопрос "а где взять реактивы?" — отвечу цитатой из все того же романа "Девочка и птицелет":
Но вот теперь я мечтала лишь об одном — о реактивах. О химических реактивах. И я, и Витя, и Сережа, и даже Женька Иванов в последнее время не ходили в кино, не ели мороженого. Все деньги мы тратили на реактивы. Когда я закончу школу, я поступлю в университет на химический факультет. Но учиться там я буду заочно. А работать я пойду в магазин химических реактивов. Это моя мечта, и я сделаю все, что нужно, для того чтобы она осуществилась.
Детям этим, в 1966 году было гораздо сложнее чем тебе, %username% :)
Имея на руках какие-то цифры можно в дальнейшем прикинуть что за тип полимера скрывается за исследуемым образцом. В таблице ниже представлены плотности самых распространенных пластмасс.
Плотности полимеров
Помимо плотности, еще одним недеструктивным методом исследования может служить температура плавления.
Температура плавления
Как уже упоминалось выше, плавятся только пластики с линейной структурой макромолекулярных цепей. Сшитые "жесткие" пластики размягчения не наблюдается вплоть до температуры при которой происходит термическая деструкция. Соответственно, этот признак может с некоторыми оговорками подсказать, что перед нами находится отвержденный реактопласт. В целом температуры плавления (и, кстати, температуры стеклования тоже) являются достаточно характерным указателем на конкретный тип полимера. Правда точку стеклования практически нереально определить в домашних условиях, требуется серьезное оборудование (ДТА там всякое, измерение модуля упругости и т.п.). Зато температуру плавления можно более или менее точно измерить, как — смотреть ГОСТ 33454-2015. Один из самых удобных вариантов — т.н. столик Кофлера, который дает точность до 2-3 °C. Если термостола нет и не предвидится — каждый придумывает способы в меру своей изобретательности, есть прецедент с плавлением кусочка пластмассы на стеклянной ампуле со ртутью ртутного же термометра :) (прим. мое — только для сильных духом парней, с крепкой рукой и надежной горелкой, остальным настоятельно не рекомендуется к повторению)

Минусом при температурной идентификации является тот факт, что на показания температуры могут влиять как скорость нагрева, так и наличие определенных добавок, особенно пластификаторов. Наиболее надежными показателями можно считать точки плавления частично кристаллизованных полимеров (например, различные полиамиды). Значения температур для наиболее важных пластиков приведены в таблице ниже
Данные по отстутствующим в таблице полимерам можно попробовать поискать в книге A. Krause, A. Lange, M. Ezrin Plastics Analysis Guide. Если с этим вариантом ничего не получается — пришло время переходит к "тяжелой артиллерии".
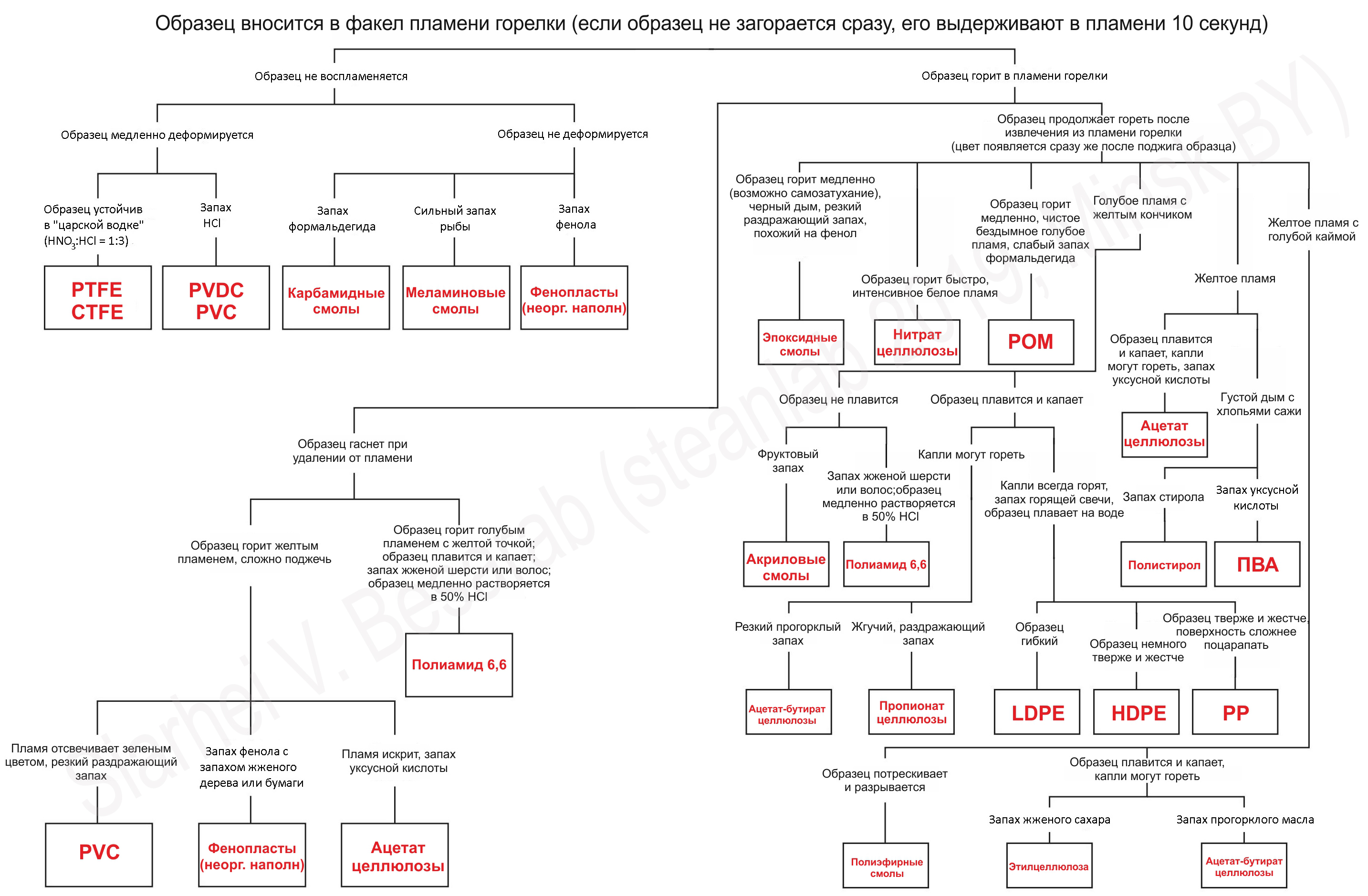
Цвет пламени и запах
Под тяжелой артилерией подразумевается конечно же деструкция, а значит дым, копоть, пламя и неприятные запахи, через которые придется пройти, чтобы определить свой полимер. Традиционно уже призываю все изыскания проводить либо в мастерской оборудованной мощной приточно-вытяжной вентиляцией, либо с полумаской с фильтрующими патронами на "газы и пары".
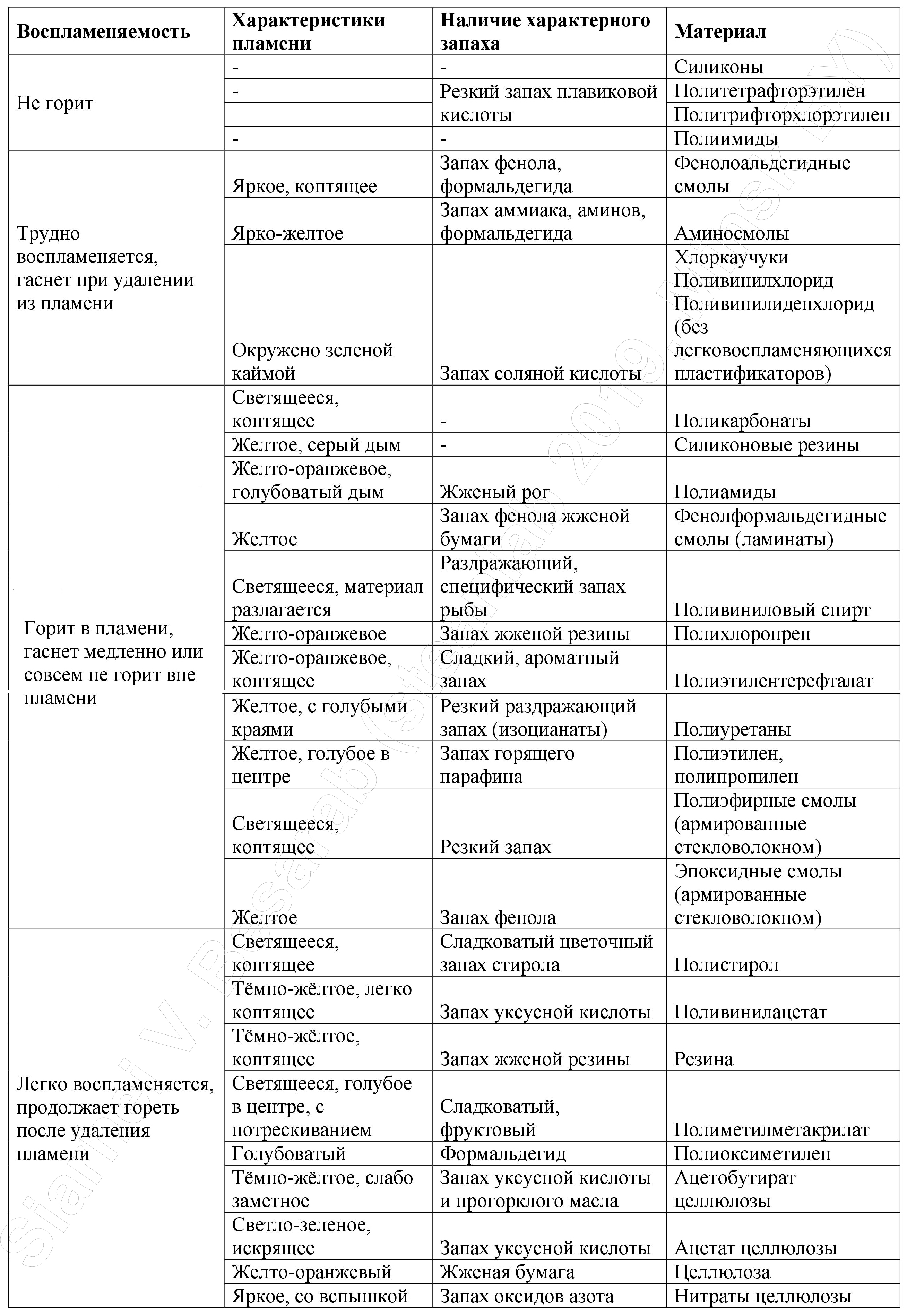
Итак, при нагревании все пластики претерпевают те или иные изменения. По характеру этих изменений можно достаточно точно определить разновидность полимера. Например, желтым, сильно коптящим пламенем горят ароматические полимеры и олигомеры: полистирол, полиэтилентерефталат, эпоксидные смолы и др. Голубое пламя характерно для кислородсодержащих полимеров и олигомеров: поливинилового спирта, полиамидов, полиакрилатов. Зеленое пламя наблюдается при горении хлорсодержащих полимеров: поливинилхлорида, поливинилиденхлорида. Прекрасным дополнением к цвету пламени может стать и запах "горелой пластмассы", под спойлером некоторые примеры.
Что в запахе горелой пластмассы тебе моем...
В представленной ниже таблице можно увидеть характеристики цвет пламени/запах для самых распространенных пластмасс
Пиролиз
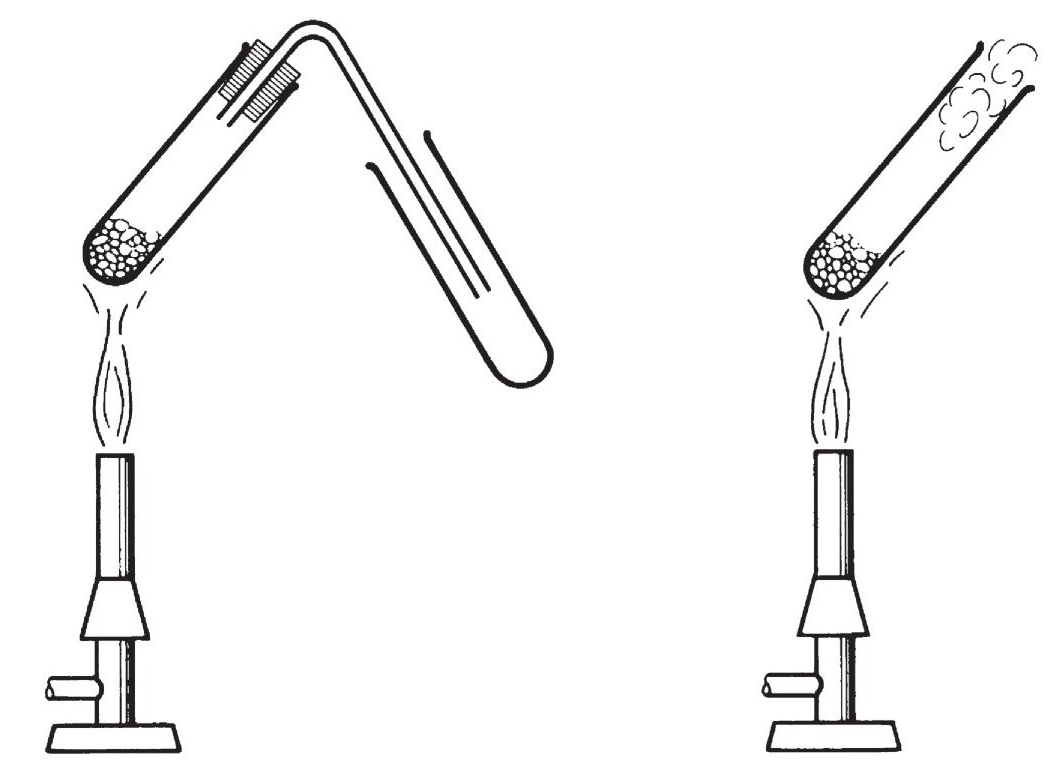
Финальной стадией, доступной для домашнего использования может стать пиролиз (разложение при высокой температуре) пластика без доступа воздуха. Все что для этого нужно — иметь надежную газовую горелку, да пробирку с пробкой (такой приборчик в 1966 году дети собирали из подручных средств — см. в начале статьи).
В пробирку (или какую-то стеклянную трубку) помещается около 0,1 г образца исследуемой пластмассы, закрываем пробкой с газоотводной трубкой и нагреваем в пламени горелки. В некоторых случаях в открытый конец трубки для пиролиза вставляют подушечку рыхлой ваты или стекловаты, которая была увлажнена водой. На открытый конец трубки нужно положить кусочек влажной pH индикаторной бумаги.
Еще один вариант индикаторной бумаги
Пробирку нагреваем медленно, чтобы можно было замечать, как изменяется образец и принюхиваться к образующемуся выхлопу газу. В зависимости от реакции пиролизных газов с влажным индикатором можно выделить три разные группы пластиков: кислотная, нейтральная или щелочная. В таблице ниже представлены пластики и среда, которую образуют газы, возникающие при их разложении, при контакте с водой. В зависимости от состава некоторые пластмассы могут всплывать в пиролизном тесте в разных группах, например, фенолформальдегидные смолы или полиуретаны
Последний экзамен...
И вот наконец, дорогой читатель, если ты дочитал до конца статьи, то можешь смело считать себя прошедшим курс "молодого полимерщика" и запросто пользоваться алгоритмами идентификации пластиков, вроде представленного ниже (картинка кликабельна).
На этом все, разделяйте и властвуйте над своими полимерами! Введение в идентификацию пластмасс закончено, подписывайтесь на мои Facebook/VKontakte заметки, чтобы знать больше и быть в теме последних изысканий (или задать главный вопрос жизни, вселенной и всего такого)!
Cергей Бесараб (Siarhei V. Besarab)
P.S.: при работе с полимерами и поиске информации о свойствах оных я пользуюсь базами MatWeb: Online Materials Information Resource, Polymer Properties Database, AZOM Materials Information, MatMatch и конечно же справочниками, приведенными в списке используемой литературы. Чего и вам желаю! :)
ИСПОЛЬЗОВАННАЯ ЛИТЕРАТУРА
He, J., Chen, J., Hellwich, K., et al. (2014). Abbreviations of polymer names and guidelines for abbreviating polymer names (IUPAC Recommendations 2014). Pure and Applied Chemistry, 86(6), pp. 1003-1015.
Выдрина Т.С. Методы идентификации полимеров Екатеринбург, 2005
A. Krause, A. Lange, M. Ezrin Plastics Analysis Guide. Hanser Publishers, 1983.
Bark, L. S., Allen, N. S. Analysis of Polymer Systems. Applied Science Publishers Ltd., London, 1982.
Compton, T. R. Chemical Analysis of Additives in Plastics, 2 nd ed. Pergamon, Oxford, New York, 1977.
Ullmann's Polymers and Plastics: Products and Processes: Wiley-VCH
Haslam, J., Willis, H. A., Squirrel, D. C. M. Identification and Analysis of Plastics, 2 nd ed. Butterworth, London, 1972
Mitchell, J. Jr. Applied Polymer Analysis and Characterization. Hanser Publishers, Munich, Vienna, 1987.
Dietrich B. Methods for Identification of Plastics. Hanser
Schröder, E., Müller, G., Arndt K.-F. Polymer Characterization. Hanser Publishers, Munich, New York, 1989.
Verleye, G. A. L., Roeges, N. P. G., De Moor, M. O. Easy Identification of Plastics and Rubber. Rapra Technology Ltd., Strawbury, 2001.
Let's block ads! (Why?)





















{kind=link}
{kind=link}