[unable to retrieve full-text content]
суббота, 14 августа 2021 г.
Generic Math: суперфича C#, доступная в .NET 6 Preview 7

10 августа 2021 года Microsoft в блоге опубликовала информацию о свежевыпущенном .NET 6 Preview 7.
Помимо добавления очередной порции синтаксического сахара, расширения функционала библиотек, улучшения поддержки UTF-8 и т.д., в данное обновление была включена демонстрация суперфичи — абстрактные статические методы интерфейсов и реализованная на её основе возможность использования арифметических операторов в дженериках:
T Add<T>(T lhs, T rhs)
where T : INumber<T>
{
return lhs + rhs;
}Введение
До настоящего времени в C# не было возможности абстрагироваться от статических методов и писать обобщённый код. Особенно проблематично это для методов, которые существуют только в виде статических методов, например, для операторов.
Например, в LINQ to objects функции .Max, .Sum, .Average и т.д. реализованы отдельно для каждого из простых типов, а для пользовательских типов предлагается передавать делегат. Это и неудобно, и неэффективно: при многократном дублировании кода есть возможность ошибиться, а вызов делегата не даётся бесплатно (впрочем, уже идут обсуждения о реализации zero-cost делегатов в JIT-компиляторе).
Нововведение добавляет возможность писать обобщённый код относительно, например, числовых типов, на которые наложены ограничения в виде интерфейсов с нужными операторами. Таким образом, алгоритмы могут выражены в следующем виде:
// Interface specifies static properties and operators
interface IAddable<T> where T : IAddable<T>
{
static abstract T Zero { get; }
static abstract T operator +(T t1, T t2);
}
// Classes and structs (including built-ins) can implement interface
struct Int32 : …, IAddable<Int32>
{
static Int32 I.operator +(Int32 x, Int32 y) => x + y; // Explicit
public static int Zero => 0; // Implicit
}
// Generic algorithms can use static members on T
public static T AddAll<T>(T[] ts) where T : IAddable<T>
{
T result = T.Zero; // Call static operator
foreach (T t in ts) { result += t; } // Use `+`
return result;
}
// Generic method can be applied to built-in and user-defined types
int sixtyThree = AddAll(new [] { 1, 2, 4, 8, 16, 32 });Реализация
Синтаксис
Статические члены, которые являются частью контракта интерфейса, объявляются с использованием ключевых слов static и abstract.
Хотя слово static было бы идеально для описания подобных методов, в одном из недавних обновлений была добавлена возможность объявлять вспомогательные статические методы в интерфейсах. Поэтому, чтобы отличать вспомогательные методы от статических членов контракта, было решено использовать модификатор abstract.
В принципе, членами контракта могут быть не только операторы, а любые статические методы, свойства, события. Реализация статических членов интефейса в классе осуществляется естественным образом.
Вызвать статические методы интерфейса можно только через обобщённый тип и только если на тип наложено соответствующее ограничение:
public static T AddAll<T>(T[] ts) where T : IAddable<T>
{
T result = T.Zero; // Correct
T result2 = IAddable<T>.Zero; // Incorrect
}Также стоит понимать, что статические методы не были виртуальным и никогда ими не будут:
interface IStatic
{
static abstract int StaticValue { get; }
int Value { get; }
}
class Impl1 : IStatic
{
public static int StaticValue => 1;
public int Value => 1;
}
class Impl2 : Impl1, IStatic
{
public static int StaticValue => 2;
public int Value => 2;
}
static void Print<T>(T obj)
where T : IStatic
{
Console.WriteLine("{0}, {1}", T.StaticValue, obj.Value);
}
static void Test()
{
Impl1 obj1 = new Impl1();
Impl2 obj2 = new Impl2();
Impl1 obj3 = obj2;
Print(obj1); // 1, 1
Print(obj2); // 2, 2
Print(obj3); // 1, 2
}Вызов статического метода интерфейса определяется на этапе компиляции (на самом деле, JIT-компиляции, а не сборки C# кода). Таким образом, можно утверждать: ура, в C# завезли статический полиморфизм!
Под капотом
Посмотрим на сгенерированный IL-код для простейшей функции, суммирующей два числа:
.method private hidebysig static !!0/*T*/
Sum<(class [System.Runtime]System.INumber`1<!!0/*T*/>) T>(
!!0/*T*/ lhs,
!!0/*T*/ rhs
) cil managed
{
.maxstack 8
// [4903 17 - 4903 34]
IL_0000: ldarg.0 // lhs
IL_0001: ldarg.1 // rhs
IL_0002: constrained. !!0/*T*/
IL_0008: call !2/*T*/ class [System.Runtime]System.IAdditionOperators`3<!!0/*T*/, !!0/*T*/, !!0/*T*/>::op_Addition(!0/*T*/, !1/*T*/)
IL_000d: ret
} // end of method GenericMathTest::SumНичего примечательного: просто невиртуальный вызов статического метода интерфейса для типа T (для виртуальных вызовов используется callvirt). Оно и понятно: как можно сделать виртуальный вызов без объекта?
Поначалу у меня была мысль, что это сахар, сделанный через какие-нибудь магические объекты, создаваемые в единственном экземпляре для каждой пары тип-интерфейс, но нет: это честная реализация новой фичи на уровне JIT-компилятора: для простых типов компилятор генерирует инструкцию соответствующей операции, для остальных типов — вызывает соответствующий метод. Из этого можно сделать вывод, что код, использующий новые возможности, не сможет работать на более старых рантаймах.
Также стоить ожидать, что JIT-компилятор будет компилировать метод для каждой комбинации обобщённых типов, для которых вызываются статические методы интерфейсов. То есть производительность обобщённых методов, вызывающих статические методы интерфейсов, не должна отличаться от производительности частных реализаций.
Статус
Несмотря на то, что есть возможность пощупать эту возможность уже сейчас, она запланирована к релизу только в .NET 7, а после релиза .NET 6 останется в состоянии preview. Сейчас эта фича находится в состоянии активной разработки, детали её реализации могут измениться, поэтому просто брать и использовать её пока нельзя.
Попробовать на практике
Чтобы поиграться с новой возможностью, нужно добавить свойство EnablePreviewFeatures=true в файл проекта и подключить NuGet пакет System.Runtime.Experimental:
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<EnablePreviewFeatures>true</EnablePreviewFeatures>
<LangVersion>preview</LangVersion>
<OutputType>Exe</OutputType>
<TargetFramework>net6.0</TargetFramework>
</PropertyGroup>
<ItemGroup>
<PackageReference Include="System.Runtime.Experimental" Version="6.0.0-preview.7.21377.19" />
</ItemGroup>
</Project>Само собой, должен быть установлен .NET 6 Preview 7 SDK и в качестве целевой платформы указано net6.0.
Мои впечатления
Попробовал — очень понравилось. То, что я давно ждал, потому что раньше проблему приходилось решать через костыли, например, так:
struct IOperationProvider<T>
{
T Sum(T lhs, T rhs)
}
void SomeProcessing<T, TOperation>(...)
where TOperation : IOperationProvider<T>
{
T var1 = ...;
T var2 = ...;
T sum = default(TOperation).Sum(var1, var2); // This is zero cost!
}Альтарнатива такому костылю: реализация типом T интерфейса IOperation и вызов var1.Sum(var2). Но в данном случае теряется производительность из-за виртуальных вызовов, да и банально не во все классы можно залезть и добавить интерфейс.
Ещё один положительный момент — производительность. Я немного позапускал бенчмарки: скорость работы обычного кода и кода с generic арифметикой оказалась одинаковой. То есть мои ранее описанные предположения относительно JIT-компиляции кода оказались верны.
А что вот немного расстроило, так это то, что с типами-перечислениями эта фича не работает. Сравнивать их придётся по-прежнему через EqualityComparer<T>.Default.Equals.
Также не понравилось, что приходится использовать слово-костыль abstract. Похоже, сложность C# достигла уже того уровня, что добавление новых фишек без ущерба для старого функционала становится затруднительным, и фактически приходим к тому, что сейчас происходит с C++.
Кухонный компьютер Honeywell
Кухонный компьютер Honeywell описывается во многих местах, особенно во всемирной паутине, как диковинка - футуристический компьютерный продукт, который практически никогда не продавался. На самом деле то, что рекламировалось как кухонный компьютер, было разработано как серьезный мини компьютер, для более серьёзных целей. H316, производимый Honeywell как часть семейства машин Series 16, никогда не предназначался для продажи даже как коммерческий продукт.
Концерн Honeywell International Inc – это транснациональная компания, которая теперь очень влиятельна и известна во всём мире. Если начать перечислять всю продукцию, которую они выпускают, это займёт просто огромное количество времени и текста. Сама компания существует уже более 100 лет и была основана американским инженером Марком Си Ханиуэллом. 1885 год считается официальным началом компании, которая в итоге получила название Honeywell. Изначально основной специализацией являлось производство теплогенераторов для горячей воды, после того как компания усовершенствовала их в рамках своего водопроводно-отопительного бизнеса.

Уже в 1955 году, будучи на пике успеха, было решено погрузится в мир компьютерных технологий и попытаться обойти IBM. Цифровая техника, как и ожидалось, спросом не пользовалась, маркетологи предприняли меры и создали совершенной новую нишу – ЭВМ для домашнего использования. И вот, спустя 14 лет, представили разработку под названием Honeywell Kitchen Computer H316. Конечно по сравнению с другими ЭВМ кухонный компьютер казался миниатюрным и весил всего примерно 45 кг.

Этот странно выглядящий и почти смехотворный компьютер был выпущен компанией Honeywell под официальным названием H316 Pedestal Model, но был показан на обложках каталога Нимана-Маркуса под его более известным названием «Кухонный компьютер». Кухонный компьютер, скорее всего, является источником классического клише для хранения рецептов, поскольку это было основное использование, рекламируемое для кухонного компьютера. Фактически, хранение рецептов было почти всем, на что был способен аппарат. Рецепты запрограммированы в компьютер, и он будет хранить их для вас. Другими словами, это был ящик для хранения электронных рецептов, не более того.

Предположительно, программировать рецепты на кухонном компьютере было довольно утомительно, в основном потому, что на то, чтобы научиться программировать, потребовалось около двух недель. Тем не менее, кухонный компьютер был отправлен с уже загруженными рецептами. От коробки до ужина всего за 10 минут? Есть определённые сомнения по этому поводу, но мы можем представить, что заранее запрограммированные рецепты были включены, чтобы любой, кто купил кухонный компьютер, мог сразу начать его использовать, вместо того, чтобы мучиться, изучая, как сначала его программировать.
Когда современный человек думает о компьютерном оборудовании, он часто вспоминает про монитор или клавиатуру. Что ж, кухонный компьютер имеет, пожалуй, самое странное «оборудование», о котором мы могли когда-нибудь слышать, - разделочная доска. Да, именно разделочная доска! Эта странность, скорее всего, была добавлена для того, чтобы еду можно было приготовить прямо на компьютере, не отходя от дисплея с рецептами, учитывая, что кухонный компьютер не такой портативный, как старая добрая поваренная книга. Сам же интерфейс представлял собой панель с кучей кнопок. Нажатием, сочетаний которых собственно и осуществлялось управление.
Оригинальная реклама кухонного компьютера:
«Если бы она могла готовить так же хорошо, как Honeywell». Зачем кому-то нужен компьютер дома? До эры персональных компьютеров и их лавины возможных применений постоянный ответ был: «хранить рецепты».

Конечно же ожидалось, что американцы, которые так падки на новинки, просто сметут эту технику с прилавков магазинов. Естественно, ожидания не смогли оправдаться. Тем более из 20 выпущенных машин, продать смогли ровным счётом ничего. Такая проблема заключалась скорее не в стоимость устройства, а в его бесполезности. Если подумать, старая добрая поваренная книга намного практичнее, занимает меньше места и не нужно изучать программирование, которое займёт ровно 2 недели.
Несмотря на такой провал Honeywell не признали своего поражения и остались правы. Бесполезная вычислительная техника привлекла внимание к своему производителю во всём мире. Благодаря Honeywell Kitchen Computer H316 фирма зарекомендовала себя как первый производитель компьютерной бытовой техники.
Сама машина была 16 - битным миникомпьютером классом ниже мэйнфреймов -и ее официальное название, на самом деле, было H316 Pedestal. Он был частью линейки Series 16, основанной на DDP 116. Время выполнения цикла — 1,6 мс.
Кухонный компьютер имел 4 КБ магнитной памяти с возможностью расширения до 16 КБ, в которой было запрограммировано несколько рецептов. Его тактовая частота составляла 2,5 МГц. Для работы потребовалось 475 Вт. Сам дисплей на самом деле был двоичным, а не текстовым. Необходимо было научиться как-то просто это читать!
Его рекламировали как машину для хранения рецептов и помощи домохозяйкам в их повседневных домашних делах. Однако чтение и введение рецепта было сложной, если не невозможной задачей, поскольку у компьютера не было дисплея и клавиатуры.
Кухонный компьютер, очевидно, был ориентирован на домохозяек, которые любили готовить. Однако домохозяйки, которые хотели один из таких кухонных атрибутов, должны были заплатить приличные деньги, учитывая, что кухонный компьютер был продан за 10 600 долларов, когда он был впервые представлен (в 1965 году можно было купить около четырех новых автомобилей за такие большие деньги!). Этот ценник включал в себя встроенные рецепты, упомянутые ранее, а также кулинарную книгу и фартук.
Проект электронного мультитула QUARK. Часть 3

Первая и вторая части.
Два ОЧЕНЬ долгих месяца прошло с момента последней публикации. За это время я превратился в профессионального ждуна. А с платформой Crowdsupply я начал работать аж ТРИ месяца назад! Сейчас это даже писать смешно. Всего лишь несколько месяцев упорной работы, а по ощущениям год. Но мы, таки, запустились! Ииии-хаа!!!!

Всем, кому интересно приглашаю поддержать проект. И напоминаю, это arduino-совместимое устройство с открытым исходным кодом. Пока исходники мы не выкладываем, поскольку некоторые моменты находятся на стадии допиливания и есть нюансы юридического характера. Но об этом в следующий раз.
Итак, что было сделано за эту вечность это время? Регистрация юридического лица, получение УНП, постановка на учет в налоговую, бла-бла-бла, скукатища. Самое интересное это прибор. Еще в прошлых статьях я писал о том, что проект уже находиться на стадии сбора фидбека от потенциальных пользователей.
Для начала, еще в первой статье камрады scorpy27 и holomen предложили заменить торчащую из корпуса подпружиненную иглу, на сменный стандартный наконечник на резьбовом соединении. Что-то вроде такого:

Мысль прям нужная, а значит отправили в работу и реализовали. Иглы можно использовать такие:

Далее, мы немного изменили схемотехнику и увеличили диапазон измерения напряжения до 36 вольт. Предыдущая версия имела верхний предел в 26 вольт. Собственно, в качестве датчика напряжения и тока теперь используется специализированная микросхема ina226, что и определяет диапазоны измерения. Помимо увеличения верхнего предела, увеличилась и точность измерений самим датчиком. Однако важно понимать, что погрешность прибора в целом не определяется только лишь характеристиками ina226 (ошибка: <0.1%. 16 бит), схемотехника так же вносит дополнительную составляющую. Впрочем, позиционирование прибора таково, что это избыточная характеристика. Ну есть так есть. Есть еще существенные качественные изменения, но о них говорить пока преждевременно, поскольку они еще не прошли обкатку «в поле». Но, позже, обязательно все напишу.
Хочу еще сказать пару слов о некоторых особенностях по работе с Crowdsupply. Одно из важных и нужных требований — это еженедельные обновления на странице кампании. Писать можно о чем угодно, если только это «что угодно» обзор вашего устройства. Это могут быть особенности работы с устройством, обзор схемотехники, ответы на часто задаваемые вопросы и так далее. Например, о улучшении характеристик устройства как раз в следующем обновлении и будет сообщено бекерам. А пока, характеристики по-прежнему выглядят вот так:

А теперь снова обращусь к сообществу с целью получить некоторый фидбек по корпусу. Дело в том, что еще на этапе первых переписок с основателем Crowdsupply Фредом Лифтоном, он спросил о том, смогу ли я наклонить дисплей в еще одной плоскости таким образом, чтобы пользователь не смог его поставить на стол на дисплей торчащим щупом вверх. Он переживает за то, что пользователь, поставив его на таким образом, воткнет щуп себе в глаз…. Серьезно? Но, поскольку в тот момент я даже не надеялся, что на мое письмо ответят в принципе, ответил: «Да невопрос! Если надо я еще и собачку вашу выгуляю!». И, таки ладно, особых проблем сделать дополнительный уклон для дисплея нету. Более того, это даже удобнее будет, если дисплей еще больше будет развернут к пользователю. Удобнее для правшей. Не для левшей. Это я понял позже. Отсюда у меня вопрос к левшам: это вообще важный момент? Если да, то дополнительный уклон делать не стану, но увеличится количество одноглазых человеков. Впрочем, меня это не смущает.
Эта статья получилась короткая и немного сумбурная, поскольку стартанули мы ВНЕЗАПНО, а сообщить об этом надо. Но, у меня действительно есть несколько хороших тем, которые не хотелось бы объединять под одной статьей. В частности, я еще в прошлый раз обещал (статья не под моей редакцией) рассказать подробнее про дальнейшую работу по запуску краудфандинговой кампании на CrowdSupply, о чем и пойдет речь в следующий раз. А пока с удовольствием отвечу на вопросы.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Стоит ли делать дополнительный уклон экрана
33.33% Да стоит 4
33.33% Нет не стоит 4
33.33% Мне все равно 4
Проголосовали 12 пользователей. Воздержались 2 пользователя.
Криптомайнинговая фирма купила 223 тысячи видеокарт

Northern Data, один из крупнейших поставщиков инфраструктурных решений для высокопроизводительных вычислений (HPC) и майнинга, покупает 24 000 серверов на базе EPYC вместе с 223 000 графическими процессорами AMD и Nvidia у Block.one, заплатив 195 миллионов евро и еще 170 миллионов евро в акциях. По условиям данной сделки, при приобретении Northern Data компании Decentric Europe BV (одного из подразделений Block.one), которая и владеет вышеперечисленным оборудованием, Block.one станет держателем примерно 18,2% акций Northern Data. Новые графические процессоры и серверы сделают серверную инфраструктуру компании мощнее самого быстрого в мире суперкомпьютера Fugaku.
Northern Data планирует завершить полную установку серверных систем GPU в ряде стран, включая Норвегию, Швецию, Нидерланды и Германию, к 3 кварталу 2021 года. Новое оборудование увеличит вычислительную мощность Northern Data более чем в два раза - с 1,29 экзафлопса FP32-производительности до 2,6 экзафлопса.
Основной целью Northern Data является существенное увеличение операций по добыче HPC и биткоинов с помощью новых видеокарт и процессоров EPYC. Также компания планирует расширить сферу рендеринга, искусственного интеллекта и блокчейн-приложений для своих клиентов.
НАСА не верит в версию о том, что отверстие в корабле «Союз» в 2018 году просверлил американский астронавт
 В 2011 году и позже данный инструмент астронавты НАСА использовали для монтажных работы в открытом космосе.
В 2011 году и позже данный инструмент астронавты НАСА использовали для монтажных работы в открытом космосе.
{kind=link}
По информации "Интерфакс" и "РИА Новости", помощник главы НАСА по пилотируемым полетам опроверг причастность американской стороны к появлению отверстия на «Союзе МС-09» в 2018 году.
Представитель НАСА на брифинге ответил на вопрос журналистов о том, что российские СМИ и неназванные представители Роскосмоса утверждают, что астронавты НАСА могли столкнуться с психологическими и медицинскими проблемами на МКС и что это могло побудить астронавта Серину Ауньон-Чанселлор незаметно просверлить отверстие диаметром 2 мм в стенке бытового отсека корабля «Союз».
«Астронавты НАСА выполняют свои миссии профессионально и честно, они очень уважаемые люди, которые вносят невероятный вклад во имя страны. Я поддерживаю Серину и ее профессиональное поведение, и я не нахожу это обвинение заслуживающим доверия», — заявил представитель НАСА и добавил, что агентство верит астронавтам и полностью им доверяет.
Сегодня СМИ сообщили, что в ходе расследования инцидента 2018 года с появлением отверстия в российском корабле «Союз» специалисты Роскосмоса пришли к выводу, что оно просверлено в условиях невесомости человеком, который не был знаком с устройством корпуса корабля. Эксперты предполагают, что это делал человек в стрессовом состоянии и в ограниченное время. Вероятно, это было сделано намерено для эвакуации с МКС одного из членов экипажа.
Расследование инцидента фактически тормозила американская сторона. Российские космонавты после обнаружения проблем на «Союз МС-09» прошли проверку на полиграфе, а астронавты НАСА от нее отказались. Также Роскосмос не получил возможности исследовать инструменты и сверла, которые имеются на МКС, на предмет остатков металлической стружки с корпуса «Союза МС-09». Вдобавок НАСА отказалось предоставить видеозаписи этого периода времени.
В сентябре 2019 года гендиректор Роскосмоса Дмитрий Рогозин сообщил, что ему известны факты происхождения отверстия, но он не будет раскрывать эту информацию общественности.
30 августа 2018 году в пристыкованном к МКС транспортнику «Союз МС-09» началось утечка воздуха. Виновников инцидента оказалось отверстие диаметром 2 мм в стенке бытового отсека корабля около шпангоута.
 Отверстие располагалось на стенке бытового отсека около шпангоута под обивкой, которую пришлось отогнуть лицу, которое его сделало.
Отверстие располагалось на стенке бытового отсека около шпангоута под обивкой, которую пришлось отогнуть лицу, которое его сделало.
 Внутреннее повреждение корабля после заделки эпоксидной смолой.
Внутреннее повреждение корабля после заделки эпоксидной смолой.
пятница, 13 августа 2021 г.
Понять кубик Рубика

Легко отличить автора гениальной идеи от того, кто её всего лишь понял и пересказал, ведь истинный автор знает предысторию, может показать предшествующие этапы понимания, чувствует границы применимости и особенности.
То же самое со сборкой этой головоломки: миллионы людей умеют делать это по формулам, но сколько из них понимают, что делают? А ведь начать чувствовать кубик Рубика не так сложно!
Но сперва давайте договоримся, зачем нам такая головоломка нужна и чем полезна. Вы же уже слышали шутки про то, что кубик Эрно Рубика – штука многогранная? А видите параллели между кубиком Рубика, шахматами и, например, пианино или гитарой?
Сейчас разберёмся вместе. Но сперва несколько оговорок:
Во-первых, даже если использовать кубик Рубика «неправильно» (например, просто научиться применять какие-то формулы), то далеко не факт, что это плохо. Даже занятия ментальной арифметикой какому-то небольшому проценту детей могут быть полезны, а уж потренировать память и прочую ловкость кистей сборкой кубика почти наверняка не вредно.
Во-вторых, далеко не всем людям, которые в остальных случаях заинтересованы в познании и «расковыривании» мира, именно эта головоломка может дать те самые эндорфины, благодаря которым процесс пойдёт задорно и с удовольствием. Если вам не пошло, то, полагаю, надо просто брать что-то другое, а не пересиливать себя.
И в-третьих, поясню всё же про сходство с пианино и гитарой. Человек, «научившийся» собирать кубик по нескольким формулам, подобен очень начинающему музыканту, освоившему четыре простых аккорда на гитаре или «Собачий вальс» на пианино. Да, уже звучит неплохо и может быть привлекательно для противоположного пола, но всё же это далековато от пользы для развития интеллекта, о которой мы здесь, оказывается, собрались говорить.
Какие же грани пользы даёт нам кубик Кубика?
-
учит быстро принимать решения;
-
тренирует сосредоточенность даже в условиях спешки;
-
развивает память, логику и мелкую моторику пальцев;
-
повышает способность концентрироваться;
-
улучшает скорость реакции;
-
снимает стресс.
Не все из этих пунктов одинаково «прокачиваются» при освоении музыкальных инструментов, но в музыке есть много другого хорошего, так что не будем спорить, что лучше, а перейдём к делу – начнём чувствовать и понимать кубик. Перечислю три ветки «прокачки», прекрасно помня, что есть и другие хорошие подходы, а также совершенно не настаивая на необходимости доходить до любого из перечисленных ниже методов быстрой сборки:
-
Собрать одну грань, не обращая внимания на другие -> Собрать одну грань, согласовав её с центрами четырёх соседних граней -> Аналитический F2L для завершения сборки первых двух слоёв -> Аналитическая сборка третьего слоя -> … -> вероятен переход к методу CFOP (Fridrich).
-
Расставить правильно все 8 углов (т.е. решить кубик 2х2х2) -> Добавить к ним 4 рёберных кубика из любой центральной грани -> Расставить оставшиеся 8 рёберных кубиков -> Расставить центры -> … -> возможен переход к методу ROUX.
-
Собрать правильно блок 2х2х2 (т.е. выбрать один угол и правильно расположить рядом с ним его соседей) -> Расширить его до блока 2х2х3 -> … -> вероятен переход к методу PETRUS.
-
...
Сейчас мы перейдём к деталям, но сперва обращу ваше внимание на то, что обычно хорошим является тот способ исследования кубика, который нравится обучающемуся. Другими словами, рассуждения вида «многие рекорды поставлены методом Джессики Фридрих, поэтому пойду по первому пути» могут помешать, так как тут важнее сконцентрироваться на предпочтениях своего мозга. Наша цель – сперва начать лучше чувствовать кубик, а уже потом решать, хочется ли вообще собирать его быстро.
Иногда бывает удобно, если рядом есть источник собранных кубиков, поскольку это даёт возможность легче проводить эксперименты. Если умеющий восстанавливать кубики человек найдёт время, чтобы поддержать исследовательский порыв обучающегося, то будет здорово. Но даже и без этого всё работает хорошо.
Играем с кубиком
Всё, хватит текста, наконец-то переходим к картинкам. Предлагаю смотреть на кубик сверху большим глазом. Так нам всегда видно пять граней, что очень удобно.

На этой картинке показано, как можно обозначить сборку одной грани. Здесь зелёным отмечены более-менее правильно стоящие элементы, а белым те, которые пока можно игнорировать. Многие начинают знакомиться с кубиком именно с этого, замечали? Кто-то может воскликнуть, что это глупо и неправильно, но я не соглашусь: если мы хотим понять кубик, то даже такое упражнение имеет смысл. А тем, кто интересуется путными подходами к обучению, могу ещё порекомендовать книги Жени Кац (у неё для детей прекрасные рабочие тетради, но и для учителей/родителей тоже всё отлично).
Пройдя этот этап, исследователь может внезапно обнаружить шесть центральных элементов, которые друг относительно друга перемещаться не могут. А это означает, что надо не их согласовать с собранной гранью, а наоборот – научиться собирать первую грань, согласуя её с центрами. Немного повозившись, мы приходим к следующему прорыву:

Да, у нас наконец-то полноценно собран первый слой, причём он согласуется с центральными элементами второго слоя (можно даже сказать, что половина второго слоя тоже собрана). Осталось совсем чуть-чуть, да? И вот тут многим начинают мешать раньше времени поставленные угловые элементы, ведь придумать способ собрать второй слой кубика Рубика с ними оказывается сложнее, чем без них.
Шаг назад, два вперёд
Да, это то, что я предлагаю сделать – откатиться назад. Сейчас нам нужен только собранный «согласованный крест». Опытные люди уже давно хотели это предложить, верно?

Удаление уголков выглядит странно? Возможно, да. Но это не более странно, чем одновременно смотреть на пять граней кубика гигантским глазом, а ведь именно этим мы занимаемся. Ничего, сейчас я всё объясню. Оказывается, если мы не будем дорожить уголками (а зелёным цветом мы отмечаем не столько то, что собрано, сколько то, что нам жалко разломать), то сможем собирать целые столбики из двух элементов (углового и рёберного). И потом мы эту пару сможем поставить сразу на правильное место, перейдя в следующее радостное состояние (опытные люди его ещё называют XCross):
Тут может возникнуть резонный вопрос, а зачем тогда был нужен предыдущий этап (сборка одной грани), если теперь нам достаточно только одного креста без углов?

Ответ может быть следующим: стремясь собрать целую грань, мы многое поняли про устройство кубика, поэтому теперь чувствуем его лучше. Сейчас нам надо собирать и ставить на место целые пары из углового и рёберного кубика, что предполагает умение ставить угол на место. А ведь именно это умение мы развили, пока учились собирать первую грань. Кстати, потом мы начнём так хорошо чувствовать кубик, что будем собирать «крест» не более, чем за 8 движений. А кто-то потом и XCross станет собирать «сразу».
Как же нащупать этот способ аналитически собрать пару? Тут нужно время и терпение. Мастера запомнили десятки формул для разных начальных расположений элементов пары, но мы-то пока хотим каждую пару собирать «методом пристального взгляда». И это вполне возможно, хоть и потребует усилий.
Если будет совсем тяжело, то имеет смысл по запросам вида «F2L для новичков» подсмотреть идеи, но я бы рекомендовал ограничиваться одной «первой мыслью» из обучающих видео, а не впитывать всю методику сразу (дайте обучающемуся как можно больше шансов «придумать самому», потому что это существенно для глубины понимания). Также ниже есть годное видео про первые шаги в F2L (first-two-layers).
Аналогичным образом удастся поставить и три оставшиеся пары, после чего обычно начинается кризис: как только собраны первые два слоя, их очень жалко ломать. Значит, нужно придумать способ собрать третий слой, не испортив первые два. Как же это сделать?
Это чуть сложнее, чем научиться нащупывать пары и собирать их в столбики на предыдущем этапе. Благо, есть несколько подходов к сборке третьего слоя. Я бы рекомендовал выделить как минимум пять-семь часов чистого времени на самостоятельный поиск решений. Если терпение кончится, то рекомендую второе и третье видео ниже.
От углов к центру
А иногда хочется собирать кубик, не начиная с одной какой-то грани, а расставив сперва все углы. Нередко с этого начинают люди, у которых кроме кубика 3х3х3 есть и другой полезный тренажёр – кубик 2х2х2.

После этого можно идти разными путями, но один из самых популярных – сборка четырёх столбиков (т.е. между восемью углами добавляем четыре рёберных кубика, чтобы получить четыре столба). Делать это можно самыми разными способами, формулы не нужны, а ощущение «на кончиках пальцев» возникает.

Ну а дальше почти столь же естественно расставляются оставшиеся восемь рёберных кубиков, после чего придумать перестановку центральных элементов совсем легко. Если на этом пути будут сложности, то по запросу про «Метод Морозова» должны найтись идеи. Ниже вы можете найти видео с пояснениями.
Зачем всё это?
Выше я старался не давать конкретных формул или методов, а стремился показать способы «покачать» свою способность понимать кубик Рубика. Не собирать, а именно понимать. Ведь брать производную функции может почти любой путёвый первоклассник (там же простейшие преобразования строк – можно быстро научить), но не каждый второкурсник понимает, «что конкретно он только что взял».
Так и здесь: подходы выше направлены на то, чтобы начать чувствовать кубик, а только потом думать про быструю/эффективную/... сборку кубика. Кстати, знаете, чем они отличаются?
Напомню, что есть разные дисциплины:
-
Сборка кубика на скорость (с вариациями «двумя руками», «одной рукой», «ногами», «сборка трёх кубиков при жонглировании ими же», ...),
-
Сборка кубика на количество действий (очень интересная дисциплина про понимание; как и в шахматных турнирах, есть сложности из-за попыток применять компьютер),
-
Сборка кубика вслепую (с суровой вариацией «мультиблайнд», в которой мы сперва запоминаем много кубиков, а потом последовательно собираем их, не убирая повязку).
Другими словами, развивать себя даже в контексте кубика Рубика можно в самые разные стороны. А раз так, то выбор этот лучше делать осознанно, чувствуя нюансы снаряда, а не просто так выучивать первые попавшиеся формулы из первого попавшегося видеоролика. Короче, всё как с музыкальными инструментами и теми же шахматами.
Мне в своё время было интересно научиться собирать кубики произвольного размера с открытыми и закрытыми глазами, а вот поиск кратчайшего решения пока не даётся. Могу поделиться неплохим побочным эффектом: дети повторяют за родителями, поэтому тоже осваивают кубики, что скорее хорошо, чем плохо (конечно, главное – не давить, чтобы не вызвать отвращение к любым самостоятельным исследованиям и математике вообще).
Ссылки
Обучающие видео
Выше я обещал четыре полезных ролика:
1) Здесь аккуратно рассказано, как заполнить «столбиками» первые два слоя.
2) Тут автор делится подходами к третьему слою:
3) Этот ролик на английском языке можно было бы ставить первым и единственным. Он близок по духу к предыдущему, но более универсальный и ближе к математике:
4) Про метод Морозова и развитие интуиции есть здесь:
Всё же ещё раз усомнюсь в полезности просмотра всех этих роликов до самостоятельных экспериментов. По-моему, надо сперва много пробовать, а потом чуть-чуть смотреть подобные видео до первого же осознания «Ого, и так можно, оказывается!», после чего сразу выключать ролик и возвращаться к экспериментам.
А как вы осваивали головоломки? Какие считаете самыми полезными? Какие не любите?
Allure. В поисках почти идеальной TMS
")
Введение
Приветствую тебя, мой виртуальный друг! Если ты читаешь эту статью, скорее всего тебе интересен Allure, или ты хочешь разобраться с тем, что это за зверь и как он интегрируется в тестирование без многонедельных плясок с бубном. В этой статье хочу рассказать о том, как мы внедряли один из инструментов, который помогает (или пытается) сделать жизнь инженерам по обеспечению качества продукта немножечко легче: постараюсь рассказать в деталях с чего все начиналось, как шло внедрение, через что прошла команда, что в итоге получили и куда планируем двигаться дальше. А виновником появления этой статьи, как нетрудно догадаться, стал тот самый инструмент — бывший Allure EE, Allure Server и нынешний Allure Testops.
А что было до?
Несколько лет назад я присоединился к одному очень интересному и амбициозному проекту. В команде было шесть разработчиков и два QA-инженера, включая меня. На тот момент тестовым стеком, который уже был внедрен и использовался в компании, являлся:
-
PHP 7.4 и framework Codeception
-
Framework Selenoid
-
В качестве CI/CD системы мы использовали Gitlab
-
Отдельной системы генерации отчетов как такой не было: для авто тестов мы использовали встроенный в codeception простой генератор отчетов (включается при передаче флага --html при запуске самих тестов), а для ручных тестов мы использовали TMS Zephyr
Соответственно приходилось смотреть два разных отчета и делать сопоставление между ручными и автотестами, что, сами понимаете, не очень-то удобно. Кроме неудобства в репортинге, постоянно возникали вопросы вроде "А как же скрестить ежа с попугаем?" Ладно, шучу! "А как же получить отчет в котором будет наглядный список автоматических и ручных тестов?" или "как же получить отчет в котором будет четко показано, что проверяют уже написанные автотесты?" Ответы на эти вопросы очень затягивались и в итоге сам стек для автотестов на тот период времени было принято не менять по причинам плотной интеграции и существующей базы автотестов, но вот касаемо отчетов и полноценной report-системы решили, что пришла пора переменам.
Попытка номер раз
Главным преимуществом системы, которая изначально была у нас в стеке, напомню, это был Zephyr, была глубокая интеграцияс JIRA. Интеграция позволяла вести всю тестовую документацию прямо не выходя из нее, настраивать дэшборды, используя JQL, писать тест кейсы прямо в таске и интегрировать их в "борду". Впрочем, были и минусы. Во-первых, очень сложно и неудобно писать/редактировать тесты в маленьком окошке (да-да, оно умеет настраиваться по размеру, но все равно неудобно, особенно при большом объеме документации). Во-вторых, мы не смогли найти ответ, как слинковать автотесты c ручными и настроить сквозные отчеты для нашей тестовой инфраструктуры (возможно плохо искали). Эти недостатки и отправили нас в путешествие в надежде найти тихую гавань, в которой хочется заниматься тестированием и качеством продукта, а не постоянной рутиной по сборке и допиливанию отчетов. Мы отправились искать другой инструмент.
Попытка номер два
Вторым заходом в бухту стал всем известный TestRail. При первом знакомстве с ним я был в восторге! В одном месте можно удобно хранить тесты, тест планы, делать прогоны ваших тестов и показывать красивые отчеты: тут и история создания тест-кейсов есть, и удобное редактируемое поле для шагов в самом тест-кейсе. Но и без ложки дегтя не обошлось - как с автотестами подружить отчеты и сделать единые прогоны? Да, у TestRail есть API-документация, которую мы использовали, и даже реализовали свою версию (за что отдельное спасибо команде разработчиков,которая нам помогала в этом) интеграции с запуском и проставлением статусов у каждого теста. Просто в определенный момент пришло осознание, что мы уделяем интеграции и ее настройке уйму времени, а конечного результата на горизонте все еще нет. "Тихой гавани" не было видно, поэтому переезд номер три был не загорами.
Попытка номер три
В этот раз у нас не было права на ошибку и мы занялись серьезной подготовкой к выбору следующего инструмента: долгий поиск в интернете, советы с коллегами, жаркие дискуссии и чтение книг, - все это привело нашу команду на одну из конференций по тестированию, на которой выступал Артем Ерошенко. Доклад был посвящен тому самому Allure Testops, что это за инструмент, что он умеет и как это готовить. Впечатлившись выступлением, я пошел разбираться, будет ли все это безобразие работать со стеком на нашем проекте.
Здесь стоит сделать отступление, что наша команда уже запланировала переезд на другой тестовый стек и мы плотно над этим работаем, но об этом в другой раз.
Как выяснилось при внедрении - это оказалось одной из самых больших проблем, с которыми пришлось столкнуться. На момент нашего знакомства с Allure Testops была реализована только часть функций, а адаптер для PHP был сыроват. Несмотря на эти недочеты, уже реализованная функциональность почти полностью покрывала наши требования, и, по сравнению с другими инструментами, которые мы пробовали, это был глоток свежего воздуха и первые попытки интеграции незаставили себя долго ждать.
Первая интеграция и первые результаты
Пятница, поздний вечер… Всей командой сидим на работе? Какого ***?
Ответ прост - мы получили триальный ключик Allure TestOps! Развернув само приложение на отдельном сервере через docker-compose, мы наконец-то увидели форму авторизации залогинившись в которой, получили пустой проект и полное осознание того, что впереди еще долгий путь. Ведь Всю тестовую инфраструктуру надо поднимать и настраивать почти что с нуля, а потом еще и показать коллегам, как это будет работать. Понеслась!

Создали проект в UI Allure TestOps, добавили в composer нашего проекта новую зависимость, создали ветку, пушнули, иии... магии нет :) Что ж, придется почитать документацию и выяснить неочевидный факт - отчет надо загружать через allurectl. С подключением зависимости в composer и описанием yaml-файла проблем не возникло, в репозитории есть пример, а вот как отчет грузить, это прям вопрос? Как я писал выше, у нас используется gilLab в качестве CI/CD системы и определенная пачка тестов бегает в docker контейнерах, а часть тестов - на тестовых стендах. Хорошо... Для начала пытаемся интегрировать allurectl в docker и подружить его с gitlab-ом.
Создаем dockerfile, указываем путь к репозиторию allurectl и делаем этот файл исполняемым. Пример запуска скрипта allurectl (в примере используется файл для x86 архитектуры):
FROM docker/compose:alpine-1.25.5
RUN apk add \
bash \
git \
gettext
ADD https://github.com/allure-framework/allurectl/releases/latest/download/allurectl_linux_386 /bin/allurectl
RUN chmod +x /bin/allurectlУже лучше, дальше описываем логику работы с пайплайном и запускаем скрипт (allurectl) после прохождения тестов на CI. Для того чтобы Allure Testops узнал про наши тесты, нужно описать работу двух джоб: allure-start и allure-stop.
Пример реализации джобы allure-start:
allure-start:
stage: build
image: image вашего проекта
interruptible: true
variables:
GIT_STRATEGY: none
tags:
- если используется
script:
- allurectl job-run start --launch-name "${CI_PROJECT_NAME} / ${CI_COMMIT_REF_NAME} / ${CI_COMMIT_SHORT_SHA} / ${CI_PIPELINE_ID}" || true
- echo "${CI_PROJECT_NAME} / ${CI_COMMIT_REF_NAME} / ${CI_COMMIT_SHORT_SHA} / ${CI_PIPELINE_ID} / ${CI_JOB_NAME}"
rules:
- if: если нужны какие правила для запуска и ниже условия
when: never
- when: always
needs: []
А allure-stop - так:
allure-stop:
stage: test-success-notification
image: ваш образ
interruptible: true
variables:
GIT_STRATEGY: none
tags:
- ваши теги
script:
- ALLURE_JOB_RUN_ID=$(allurectl launch list -p "${ALLURE_PROJECT_ID}" --no-header | grep "${CI_PIPELINE_ID}" | cut -d' ' -f1 || true)
- echo "ALLURE_JOB_RUN_ID=${ALLURE_JOB_RUN_ID}"
- allurectl job-run stop --project-id ${ALLURE_PROJECT_ID} ${ALLURE_JOB_RUN_ID} || true
needs:
- job: allure-start
artifacts: false
- job: acceptance
artifacts: false
rules:
- if: $CI_COMMIT_REF_NAME == "master"
when: neverТут стоит добавить, что Allure TestOps создает папку allure-results в папке {имя вашего проекта}/tests/_output которую формирует сам framework (в нашем случае codeception). И все что нужно сделать - загрузить артефакты, сформированные после прогона тестов в Allure через консольную команду allurectl.
.after_script: &after_script
- echo -e "\e[41mShow Artifacts:\e[0m"
- ls -1 ${CI_PROJECT_DIR}/docker/output/
- allurectl upload ${CI_PROJECT_DIR}/docker/output/allure-results || true
Чтобы отправлять нотификации к примеру об упавших тестах в slack, достаточно передать launch id. Grep-нуть его можно примерно так:
if [[ ${exit_code} -ne 0 ]]; then
# Get Allure launch id for message link
ALLURE_JOB_RUN_ID=$(allurectl launch list -p "${ALLURE_PROJECT_ID}" --no-header | grep "${CI_PIPELINE_ID}" | cut -d' ' -f1 || true)
export ALLURE_JOB_RUN_ID
В итоге получаем результат - тесты начинают бегать в docker, используя локальное окружение. При этом запускается джобаallure-start. Как только allure-start пробежала в самом Allure, создается заглушка, в которую будут загружены тесты после их исполнения.
Вот так может выглядеть пайплайн:

Мы пошли еще чуть дальше и смогли настроить еще одну полезню функцию - это Parent-child pipelines. А понадобилось нам это для того, что бы можно было развернуть бранч на физический стнед и уже на нем запускать ряд тестов. Прокидываем необходимые переменные и убеждаемся, что результаты грузятся в один launch в Allure Testops. ${CI_PIPELINE_ID} и ${PARENT_PIPELINE_ID}
.run-integration: &run-integration
image:
services:
- name: ваш образ
alias: docker
stage: test
variables:
<<: *allure-variables
tags:
- ваши теги
script:
- echo "petya ${CI_PROJECT_NAME} / ${CI_COMMIT_REF_NAME} / ${CI_COMMIT_SHORT_SHA} / ${CI_PIPELINE_ID} / ${PARENT_PIPELINE_ID} / ${CI_JOB_NAME} / {$SUITE}"
- cd ${CI_PROJECT_DIR}/gitlab
- ./gitlab.sh run ${SUITE}
after_script: *after_script
artifacts:
paths:
- docker/output
when: always
reports:
junit: docker/output/${SUITE}.xml
interruptible: trueПервый шаг интеграции готов. Смотрим первые результаты и пытаемся понять, что в итоге загрузилось в Allure ? Есть тесты с шагами и бублик с разными статусами. Значит, запуск тестов на каждой ветке и конкретном sha-ref (коммите) работает, а еще на каждый коммит и создание ветки запускается набор тестов, который по итогам выполнения отправляет результаты в Allure. Allure в свою очередь рисует бублик со статусами выполненных тестов. Успех и маленькая победа!
На этом вечерние посиделки в пятницу были завершены, и мы с радостными мыслями удалились в бар по домам :).
Разочарование
Итак, тесты успешно бегают на бранчах и для каждого sha-ref (коммита) - восторгу нет предела. Впрочем, как известно,эйфория проходит быстро. Именно так и случилось. Мы полезли смотреть на дерево автотестов (к тому моменты они уже успешно бегали в Gitlab) и обнаружили совершенно нечитаемую историю, по которой никак нельзя понять, что в ней проверяется. В этот момент пришло горькое осознание, что мы сделали шаг вперед и два назад. Примерно так выглядел результат после успешной загрузки xml-отчета в Allure Testops:

Само дерево строится по принципу название тестового метода + data set #1 (если он есть в тесте).
Шаги в тестах выглядят примерно так:

Из этих шагов, естественно, ничего не понятно: что за get web driver, что за get helper, зачем мы перезагружаем страницу или зачем мы ждем тот или иной селектор и т.д., - если такие отчеты увидит кто-то из руководства, вопросов будет больше, чем шагов в тесте. И сейчас вы наверняка думаете, что я расскажу, как в два клика мы победили эту "неувязочку" ? Нет!
Тут начинается боль… Боль инженера по обеспечению качества. Ребята из Qameta предлагают решить эту проблему при помощи аннотаций к тестам: определить, где у нас features, где story, а где component и для каждого теста выставить аннотации над методом. Такая разметка позволяет динамически строить красивое дерево.
А что насчет шагов? Аннотировать каждый? Для этого тоже есть решение, которое заключается в создании обертки для каждого метода. Эта обертка будет служить красивым и понятным именем для метода и шага. В целом предложения и подход здравые, нокогда на проекте n^8-тестов, этот процесс может сильно затянуться. По сути, разметка тестов для Allure требует практически полного рефакторинга всего, что есть в проекте! Очень много времени...
Также к минусам можно отнести отсутствие валидации этих аннотаций. Если вполне естественным образом пропустить опечаткув аннотациях, забыть закрыть кавычки или неправильно закрыть фигурные скобки, тест просто упадет со всеми вытекающими последствиями. Особенно болезненно будет тем, кто в проекте недавно и не очень хорошо представляет себе структуру тестового набора, и тем, кто занимается ручным тестированием и сильно далек от мира автоматизации.
Валидация аннотаций
P/s. В качестве решения валидации аннотаций, можно посоветовать установить плагин для phpStoprm: PHP Annotations, который поможет найти подобные ошибки, но конечно же не все.
Доработка напильником
Ну что, дорогие читатели, напильник в руки и начинаем полировать заготовку! Добавляем аннотации к автотестам, по пути рефакторим код тестов, а так же согласуем с аналитиками и ВСЕМИ участниками вашей команды будущую структуру вашего дерева. Давайте посмотрим на то как это может быть выглядеть в коде на примере одного автотеста:
/**
* @Title("Название вашего теста - короткое")
* @Description("Пишем подробное описание")
* @Features({"А что за фича собственно?"})
* @Stories({"Ну про сторю не забываем!"})
* @Issue({А где требования Карл?})
* @Labels({
* @Label(name = "Jira", values = "SA-1111"),
* @Label(name = "component", values = "Наш компонет"),
* @Label(name = "layer", values = "the layer of testing architecture"),
* })
*/ То, что вы видите на скриншоте, это адаптированный стандарт документирования Javadoc для PHP. Теперь посмотрим, как это выглядит в Allure TestOps:

На скриншоте видно, что тесты выстроены в структуре, а именно: Component -> Feature -> Story. Это предварительнонастраивается в самом Allure TestOps.

В любой момент структуру можно отредактировать и дерево пересоберется в соответствии с запросом. Теперь пора навести порядок с шагами в автотестах. Можно использовать метод executeStep как надстройку и красивое описание для нашего метода. В нашем примере в сигнатуру метода первым параметром передаем текст, который будет отображаться как human readable step в UI Allure TestOps для метода addInvite (пример реализации):
public function createInviteCode(User $user, string $scheme): Invite
{
return $this->executeStep(
'Create invite code for ' . $user->username . ' with ' . $scheme,
function () use ($user, $scheme) {
return $this->getHelper()->addInvite(['user' => $user, 'schemeType' => $scheme]);
}
);
}Таким образом, вся внутренняя реализация скрывается под капотом, а шаги в тестах "естественным" образом получаются красивые и понятные названия. В итоге тестовый сценарий в Allure TestOps выглядит примерно вот так:

Важно отметить, что такой рефакторинг занял у команды примерно месяц интенсивной и упорной работы: приходилось даже засиживаться допоздна в надежде, что еще чуть-чуть и финишная прямая...
Финишная прямая
Подведем некий итог, что же в итоге получилось? Напомню, что изначальной задачей было приведение всего набора автотестов порядок, чтобы их можно было спокойно читать и использовать, не забыв при этом про ручные тесты. В нашем случае, на создание разработчиком pull-request в Gitlab создается ветка с названием и sha-ref коммита и заводится пайплайн, в котором запускаются тесты. Так вот, мы хотели понимать, какие тесты запускались на каждой из веток или каждом из коммитов.
Настроив интеграцию, мы получили отдельную страницу со всеми запусками (Launches) в Allure TestOps. Страница Launches показывает эту информацию в структурированном виде, позволяет отфильтровать ее и получить нужный срез данных (запущенные тесты, процент успешно выполненных и упавших тестов и другую схожую информацию) по конкретной ветке.


Если провалиться в конкретный Launch, можно посмотреть на структуру нашего проекта: какие есть компоненты, какие фичи, сколько было перезапусков, какие именно тесты перезапускались, информацию о дереве тест-кейсов, график, который показывает сколько времени бежал самый долгий тест, график с длительностью тестов, - и в конце концов экспортировать этот прогон в JIRA-тикет. Отдельно хочется упомянуть про политики для Live documentation, которая в автоматическом режиме обновляет дерево тест-кейсов по правилам и триггерам, например, только из ветки мастер.
Работает это так: у нас есть автотест, в котором изменили пару шагов и поправили аннотации. Далее этот тест запускается и выполняется с набором тестов на мастере (на пулл-реквест в мастер), после чего можно либо вручную закрыть launch, либо дождаться, когда launch будет закрыт по cron’у, который настраивается в интерфейсе Allure. При закрытии запуска старый автотест обновляется - получаем актуальный тест-кейс. Это позволяет в принципе забыть про актуализацию тестовой документации в интерфейсе. Безумно удобно!

Где ручные кейсы, Карл?
")
Итак, стало понятно, что и где тестируется, какие тесты выполняются, как часто перезапускаются и какие дают результаты по итогам прогонов. Кажется, все! или нет? Ах да! Мы забыли про ручные кейсы. Давайте чуть разберемся в структуре тест-кейсов, которой нам предлагает следовать Allure TestOps - она предполагает, что тест представляет из себя законченный сценарий, а expected result является как бы необязательным элементом теста. А там, где это необходимо, можно описывать “expected result” в виде вложенных шагов. Написав пару-тройку тест-кейсов в таком стиле, становится ясно, что это удобно и практично. Пример такого теста может выглядеть так:

Если такой стиль написания кейсов не устраивает по какой-либо причине, всегда можно включить другую структуру с предусловиями.

Далее мы импортировали ручные тест кейсы из TestRail в Allure TestOps. Механизм импорта тест-кейсов позволяет гибко настроить, что именно импортировать, а что нет, поэтому проблемы были только с самими тестами - много ручных тестов снова пришлось переработать под новую структуру.
Думаете, все? Как бы не так! В конечном итоге мы получили базу с ручными и автоматическими тестами в едином месте и были готовы презентовать результаты работы коллегам, но что-то пошло не так и обнаружилась еще одна неприятная история.

Перед той самой презентацией мы решили настроить все отчеты, фильтры, показать, какие у нас есть ручные тест-кейсы, какие автоматические, как все это прекрасно работает, но, немного перемудрив с настройками Allure TestOps, мы окончательно запутались в нашем дереве и с трудом стали различать, где ручной, а где автоматический тест. Почему так произошло? Потому что мы попытались интегрировать ручные тесты в структуру автоматических тестов. Впрочем, проблема оказалась не фундаментальной, а технической: поскольку структура для автоматических тестов была написана с помощью аннотаций в коде, а ручные тесты создавались/редактировались прямо в интерфейсе Allure, после закрытия каждого прогона с мастер ветки начиналась путаница в статусах всех тест-кейсов. Осознав, где свернули не туда, мы решили удалить текущее дерево и все настроить заново. С автоматическими тестами проблем не возникло, они очень быстро обновили документацию и выстроились в новое дерево на основе аннотаций. Но один важный вопрос остался открытым: что же делать с ручными тестами? Если пойти тем же путем, что и в прошлый раз, получим инструмент, который решает задачи связанные только с автоматизацией, оставим TestRail для ручных тестов и продолжим связывать вручную два разрозненных отчета, как в старые добрые времена.
Решение нашлось неожиданно: как-то вечером перед Гейзенбагом, одной из самых больших конференций по тестированию, я просматривал программу прошлых докладов и обнаружил доклад на тему Тест-кейсы как код. Да, практика не новая, и про нее многие слышали. Ее суть заключается в том, что даже ручные тесты следует писать как метод под будущую автоматизацию: создали тестовый метод, в нем описали сценарий, сделали ветку, сделали merge request, прислали коллегам на ревью. Если коллегам что-то не понравилось в mr, они оставляют комментарий, вы правите, после чего ветка успешно мержится в основную. Что характерно, все это можно делать прямо в вашей CI (напомню, что в нашем случае это gitlab).
Отличная практика, но как ее подружить c Allure TestOps и получить вменяемые отчеты? На помощь снова приходят аннотации. Пишем ручной тест в нужном месте в репозитории, размечаем его с помощью аннотаций, созданных для автотестов, после чего указываем, что тест - ручной. Примерно так:
/*
* @Title("Короткое описание")
* @Description("Чуть понятнее пытаемся расписать")
* @Features({"Наша фича к которой относится тест кейс"})
* @Stories({"Если нужна"})
* @Issues({"Ссылка на требования, к примеру conf"})
* @Labels({
* @Label(name = "Jira", values = "Номер jira тикета"),
* @Label(name = "component", values = "Компонент"),
* @Label(name = "createdBy", values = "автор тест кейса"),
* @Label(name = "ALLURE_MANUAL", values = "true"),
* })
*/
Метод step в данном случае так же как и в случае с автотестами является просто оберткой над встроенным методом Allure TestOps executeStep. Единственное отличие в том, что для такого теста добавляется Label = ALLURE_MANUAL.

Можно пойти немного дальше и создать отдельного актера для ручных тестов, сделать общие методы для повторяющихся шагов и использовать их в ручных кейсах. В коде это может выглядеть примерно так:
/**
* @param string $elementName
* @param string $elementType
* @return $this
*/
public function click(string $elementName, string $elementType = 'button'): self
{
$this->tester->step('Click on "' . $elementName . '" ' . $elementType);
return $this;
}Здесь мы создали некую заглушку для общего метода click, который будем переиспользовать в шагах наших автотестов и на тех страницах где это необходимо.
/**
* @return $this
*/
public function clickCreateFreeAccountButton(): SignupModal
{
$this->click('Create Free Account');
return new SignupModal($this->tester);
}Ну и сам тест выглядит уже таким образом:
/**
* @Title("Successful signup without email")
* @Features({"Signup"})
* @Stories({"Signup without email"})
* @Labels({
* @Label(name="layer", values="manual"),
* @Label(name="ALLURE_MANUAL", values="true")
* })
*
* @param ManualTester $I
* @param Header $header
*/
public function successfulSignupWithoutEmail(ManualTester $I, Header $header): void
{
$I
->amOnPage(IndexPage::URL)
->amAuthenticatedAsGuest();
$header
->clickCreateFreeAccountButton()
->clickSignupWithoutEmailButton()
->fillUsername($I->generateRandomCredentials()['username'])
->fillPassword(AcceptanceTester::STRONG_PASSWORD)
->clickCreateFreeAccountButton();
$I->expectUserAccountCreated();
}Здесь, мы обращаемся к атеку - ManualTester и вызываем его методы, которые предварительно должны написать. Пример:
<?php
/**
* @SuppressWarnings(PHPMD)
*/
class ManualTester extends Actor
{
use StepSupport;
/**
* @param string $url
* @return \Tests\_support\ManualTester
*/
public function amOnPage(string $url): self
{
return $this->step('Am on page ' . $url);
}
/**
* @return $this
*/
public function amAuthenticatedAsGuest(): self
{
return $this->step('Am authenticate as guest');
}
}Стоит ли применять такой подход и является ли он избыточным - вопрос хороший! Одно могу точно сказать, что можно совмещать эти два подхода в написание ручных тест кейсов. Первый можно использовать для быстрых мыслей и ближайшей автоматизации, а второй к примеру для созданиея структурированных и вдумчивых тест кейсов. Да, при этом редактировать и убираться в репозитории приходится чаще, а подходить к созданию тест-кейсов нужно более ответственно. Лично мне почему-то такой подход ближе. Возможно потому, что он избавляет нас от бездумных тест-кейсов в стиле "проверяю то, сам не знаю что", но это мое личное мнение. Теперь о глобальных минусах. Если нужно что-то прикрепить (картинку или файл) к тест-кейсу, сделать это будет довольно сложно, так как в Allure TestOps эта возможность реализована не для всех языков. Для PHP, это пока что в стадии доработки. Еще один минус заключается в том, что такие ручные тесты постоянно запускаются с автотестами и потребляют драгоценно евремя при прогоне всего набора тестов. Конечно время выполнения такого теста очень маленькое, но это может оттолкнуть от идеи использовать такой подход.
Стоит отметить, что сами тесты после запуска прогона на ветке получают статус: in_progress, что достаточно удобно, когда в отчете есть ручные и автоматические тесты. Это означает, что их нужно пройти вручную. Вообще, Allure TestOps умеет назначать тесты на тестировщиков, если вы пропишете правила в настройках запуска. Так же для более удобной работы с такимитестами, есть плагин Allure TestOps Support , который позволяет удобно выгружать результаты прогонов как ручных так и авто тестов в Allure Testops прямо не выходя из IDE.
Одно могу точно сказать: ребята из Qameta сейчас активно работают в этом направлении и я думаю, что со временем предложат более элегантное решение этого вопроса. Как несложно догадаться, наша команда получила то, чего желала, и пока что остается на этом пути.
Dashboards and reports
Что ж, с ручными тестами вроде разобрались, перенесли часть тестов в код, часть удалили, часть по пути автоматизировали, а некоторые тесты вообще расписали как документацию в Confluence, получив внутреннюю базу знаний. Осталось разобраться с отчетами. В Allure TestOps для этого есть отдельная страница, которая так и называется - dashboards. Она представляет из себя набор маленьких дэшбордов и виджетов, на которых можнонайти информацию обо всех тестах, их количестве, запусках (launches) и статистике исполнения.

На виджете “test cases” видно общее количество наших тестов, как ручных, так и автоматических. На виджете launches видны запуски и количество тестов, которые были запущены в каждом из них. Если этой информации покажется недостаточно, можно настроить свои виджеты с помощью встроенного query language (аналог языка в JIRA) и сделать практически любой отчет. К примеру мне очень понравилась идея с отчетом, который называется Test Case Tree Map Chart, показывающий матрицу покрытия.

Представьте себе единый график, на котором можно посмотреть, что для одной фичи у нас 3 ручных и 1 автотест, а для другой — только 5 ручных тестов. Такой график легко позволяет понять, где хромает автоматизация или тестовое покрытие в принципе.
Заключение и планы на будущее
Интеграция на этом этапе была завершена и то, что было реализовано в проекте, на текущий момент времени удовлетворяет наши потребности. В ближайших планах более гибкая настройка запуска тестов из Allure TestOps, т.е подготовка набора шаблонов с тестами, организация их в тест-планы и запуск их по отдельности из Allure TestOps на разных устройствах/браузерах/операционных системах. Еще планируем доработать напильником процесс работы с ручными тест-кейсами, а так же перенести часть старых тестов на новый стек. Самое приятно здесь то, что в случае использовании нового стека, нам не нужно менять TMS! Allure TestOps интегрируется почти со всеми популярными фрэймворками и работает из коробки, разве что с тостером не заведтся :)
Сам процесс рефакторинга, как я писал ранее, занял у команды долгий и тяжелый месяц, зато мы поняли, что на проекте автоматизировано, а что нет. Заодно привели в порядок ручные тесты. Стоило ли это того? Для нас - точно да. В итоге все стало работать понятнее и стабильнее.
В качестве заключения хочется сказать, что Allure TestOps, конечно, не является серебрянной пулей или волшебным инструментом, который в одночасье решит все проблемы на проекте. Но однозначно могу сказать, что этот инструмент очень облегчает жизнь инженеров по обеспечению качества, прививая и как бы невзначай навязывая правильные подходы, а также позволяя ощутить атмосферу безмятежной гавани, в которой можно заниматься качеством и приносить пользу, а не постоянно тушить пожары. :)
Всем спасибо, что уделили внимание этой статье, буду рад любым вопросам и постараюсь на них ответить в комментариях.
«Сбербанк» выкупил акции коммуникационной платформы Jivo
«Сбербанк» сообщил о выкупе 100 % акций платформы Jivo (ООО «Живой Сайт» ), разработанной для переписки с клиентами через сайт компаний. Она уже вошла в экосистему компании. В пресс-релизе указано, что основатели Jivo останутся работать в компании.

Jivo — многофункциональный чат для сайта, объединяющий в себе возможности чат-бота, телефонии и обратных звонков, приёма сообщений из соцсетей, мессенджеров, приложений и e-mail и корпоративного чата. Он также обладает встроенными CRM-возможностями.
Согласно информации на сайте Jivo, чат установлен более чем на 250 тысячах сайтов и интегрирован с 43 тысячами групп «Вконтакте», 73 тысячами страниц на Facebook и 33 тысячами Telegram-каналов. В июне этого года платформа объявила о запуске интеграции с Instagram.
13 августа «Сбербанк» сообщил в своём блоге о покупке Jivo. Как указала компания, основатели платформы продолжут работу в компании. Тимур Валишев станет генеральным директоров в Jivo, Николай Иванников — техническим директором.
Jivo уже стал частью экосистемы «Сбербанка». В начале августа компания установила виджет чата на платформу SmartMarket (developers.sber.ru). Теперь разработчики смогут написать туда и получить консультацию оператора. Компания планирует интегрировать чат в остальные продукты экосистемы и развивать саму платформу.
В ближайшее время Jivo планирует установить партнёрство с SendPulse — провайдером WhatsApp Business API. Также в середине августа в чате должна появиться функция видеозвонков.
Лазер на службе порядка: новые пылесосы Dyson
Компания Dyson представила сразу несколько новинок в своём пылесосном арсенале: 5 циклонных моделей, которые уже появились в продаже. И хоть Хабр не про пылесосы, обойти вниманием эти шедевры инженерной мысли нельзя — всё ж не у каждого стартапа на счету более 10 тысяч патентов. Да и современные пылесосы это скорее гаджеты и компьютеры, чем скучный раздел «бытовая техника».

В целом устройства этой компании не нуждаются в представлении — если вы являетесь владельцем какой-нибудь из моделей, заставить себя взяться за что-то другое будет непросто. Однако инженеры не захотели останавливаться и постарались сделать продукты ещё круче, что в условиях пандемии (когда многие из нас сидят дома) особенно актуально — чистота и порядок в доме стали важны как никогда.
Первая новинка и самая скромная по возможностям модель, но она же и самая доступная. И самая лёгкая — всего 1,5 кг. А значит и самая манёвренная.
Внутри — гипердимовый двигатель (скорость вращения — 105 тысяч оборотов в минуту), 8 циклонов (маленьких да удаленьких — создают силу в 96 000g, что позволяет удалять из воздушного потока даже самую мелкую пыль) и 5-ступенчатая система фильтрации. Вместо уменьшения фильтра инженеры уменьшили размеры байонетных соединений, чтобы осталось достаточно места для фильтрующего материала (его там 1,6 метра, а сложен он 122 раза).
Мощность всасывания составляет 50 аВт (аэроВатт), а время автономной работы на одном заряде аккумулятора — всего 20 минут. По своему опыту могу сказать, что такого времени работы хватит лишь на небольшие объекты (маленькие квартиры, машины и т.д.). Объём контейнера — 0,2 л, но это не так страшно, если помнить о трёх вещах: а) что в отличие от устройств с мешками для пыли, циклонная система работает на полную мощность даже при заполненном контейнере; б) что во время уборки контейнер не так-то быстро заполняется — если совсем не зарастать в пыли; в) что контейнер всегда можно легко и быстро очистить.
Кстати, арифметика примерно такая: контейнера на 0,3 л хватает для помещения площадью около 50 кв.м., в то время как для более крупных помещений (50-100 кв.м.) лучше иметь 0,5–0,6 л.
Для включения устройства используется кнопка, а не привычный курок; зато это должно стать более удобным решением при смене рук во время уборки. В комплекте среди насадок есть облегчённая на 45% версия с мягким валиком.
Более интересная, на мой взгляд, модель, которая оснащена дебютной в отрасли технологией — лазером.
Одна из комплектных насадок пылесоса (с мягким валиком) оснащена зелёным лазером, который во время работы создаёт веерообразный поток света на убираемой поверхности. Как несложно догадаться, такое конструктивное решение позволяет подсвечивать перед щёткой ту пыль, которую обычно не видно. Это позволяет не только убираться более тщательно, но и сократить время уборки.
На этом инновации не заканчиваются. Внутри новинки установили пьезоэлектрический датчик, который отвечает за акустическое распознавание пыли. Антистатические щетинки из углеродного волокна собирают пыль, отправляют датчику на входе в контейнер, где тот вычисляет размер и количество частиц. Всё это происходит 15 000 раз в секунду. Напрашивается вопрос — зачем? Как говорится, «во-первых, это красиво» — качественно-количественная информация о собираемой пыли выводится на встроенный экран (где в прошлых моделях выводился текущий режим и оставшееся время работы).
Ну а во-вторых, и главное, такое решение позволило улучшить режим «Auto»: в зависимости от количества пыли датчик автоматически регулирует мощность. Если раньше пылесосы «усиливались» только на коврах, то сейчас — везде, в зависимости от загрязнения.
Флагманская модель, лучше которой уже вряд ли что-то придумают =) Мощный гипердимовый двигатель (в этой модификации уже 125 000 оборотов), массив из 14 циклонов (создают центробежную силу в 100 000g) и впечатляющая мощность всасывания в 240 аВт. Объём контейнера составляет 0,76 литра, время автономной работы до 60 минут (или до 120 для комплектации Absolute extra, где поставляется второй аккумулятор) — с такими характеристиками можно тщательно убрать даже самую большую квартиру.
Модель также оснащена лазерной щёткой для обнаружения «невидимой» пыли, пьезодатчиком (и экраном), что позволяет ускорить и улучшить процесс уборки. Помочь в этом должны и две новые насадки, которые научились бороться с наматыванием волос и шерсти. У одной щётки (с высоким крутящим моментом) это происходит за счёт 56 поликарбонатных зубчиков (выглядят как расчёска), которые не позволяют волосам накручиваться на вал и счищают их в контейнер; а вторая — мини-турбощётка борется с волосами и шерстью за счёт формы в виде конуса с винтом Архимеда. Такая конструкция скатывает волосы в шарик и отправляет всё туда же, в контейнер. Владельцы длинношерстных животных, ликуйте!
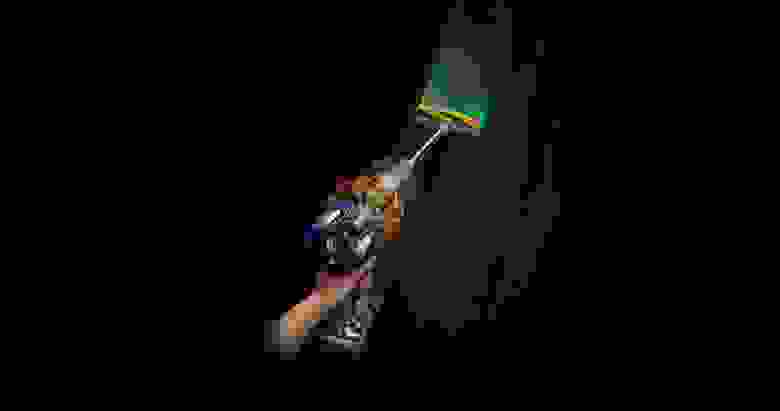
В отличие от представленных выше моделей, V15 оснащён курком, а не кнопкой.
Обновилась и модель Dyson V11, которая получила название Dyson Outsize — с увеличенным на 150% контейнером для пыли и мусора и увеличенной на 25% насадкой с высоким крутящим моментом. 220 аВт, 14 циклонов, лазер, ЖК-дисплей (но без пьезодатчика) и до 120 минут работы — набор для настоящих фанатов чистоты =)
Все модели уже появились в продаже.
В целом устройства этой компании не нуждаются в представлении — если вы являетесь владельцем какой-нибудь из моделей, заставить себя взяться за что-то другое будет непросто. Однако инженеры не захотели останавливаться и постарались сделать продукты ещё круче, что в условиях пандемии (когда многие из нас сидят дома) особенно актуально — чистота и порядок в доме стали важны как никогда.
Dyson Micro
Первая новинка и самая скромная по возможностям модель, но она же и самая доступная. И самая лёгкая — всего 1,5 кг. А значит и самая манёвренная.
Внутри — гипердимовый двигатель (скорость вращения — 105 тысяч оборотов в минуту), 8 циклонов (маленьких да удаленьких — создают силу в 96 000g, что позволяет удалять из воздушного потока даже самую мелкую пыль) и 5-ступенчатая система фильтрации. Вместо уменьшения фильтра инженеры уменьшили размеры байонетных соединений, чтобы осталось достаточно места для фильтрующего материала (его там 1,6 метра, а сложен он 122 раза).
Мощность всасывания составляет 50 аВт (аэроВатт), а время автономной работы на одном заряде аккумулятора — всего 20 минут. По своему опыту могу сказать, что такого времени работы хватит лишь на небольшие объекты (маленькие квартиры, машины и т.д.). Объём контейнера — 0,2 л, но это не так страшно, если помнить о трёх вещах: а) что в отличие от устройств с мешками для пыли, циклонная система работает на полную мощность даже при заполненном контейнере; б) что во время уборки контейнер не так-то быстро заполняется — если совсем не зарастать в пыли; в) что контейнер всегда можно легко и быстро очистить.
Кстати, арифметика примерно такая: контейнера на 0,3 л хватает для помещения площадью около 50 кв.м., в то время как для более крупных помещений (50-100 кв.м.) лучше иметь 0,5–0,6 л.
Для включения устройства используется кнопка, а не привычный курок; зато это должно стать более удобным решением при смене рук во время уборки. В комплекте среди насадок есть облегчённая на 45% версия с мягким валиком.
Dyson V12 Detect Slim
Более интересная, на мой взгляд, модель, которая оснащена дебютной в отрасли технологией — лазером.
Одна из комплектных насадок пылесоса (с мягким валиком) оснащена зелёным лазером, который во время работы создаёт веерообразный поток света на убираемой поверхности. Как несложно догадаться, такое конструктивное решение позволяет подсвечивать перед щёткой ту пыль, которую обычно не видно. Это позволяет не только убираться более тщательно, но и сократить время уборки.
На этом инновации не заканчиваются. Внутри новинки установили пьезоэлектрический датчик, который отвечает за акустическое распознавание пыли. Антистатические щетинки из углеродного волокна собирают пыль, отправляют датчику на входе в контейнер, где тот вычисляет размер и количество частиц. Всё это происходит 15 000 раз в секунду. Напрашивается вопрос — зачем? Как говорится, «во-первых, это красиво» — качественно-количественная информация о собираемой пыли выводится на встроенный экран (где в прошлых моделях выводился текущий режим и оставшееся время работы).

Ну а во-вторых, и главное, такое решение позволило улучшить режим «Auto»: в зависимости от количества пыли датчик автоматически регулирует мощность. Если раньше пылесосы «усиливались» только на коврах, то сейчас — везде, в зависимости от загрязнения.
Количество циклонов внутри — 11, а мощность всасывания втрое больше предыдущей модели — 150 аВт. Втрое больше и время автономной работы — до 60 минут.
Из конструктивных особенностей: более компактные трубки и насадки, кнопка вместо курка, а также съёмный «с завода» аккумулятор: это упрощает замену аккумулятора (если с ним вдруг что-то случится) и позволяет использовать несколько аккумуляторов в случае, когда одного вдруг будет не хватать.
- Вес: 2,2 кг
- Объём контейнера: 0,35 л
- Время работы: до 60 минут
- Мощность всасывания: 150 аВт
Dyson V15 Detect
Флагманская модель, лучше которой уже вряд ли что-то придумают =) Мощный гипердимовый двигатель (в этой модификации уже 125 000 оборотов), массив из 14 циклонов (создают центробежную силу в 100 000g) и впечатляющая мощность всасывания в 240 аВт. Объём контейнера составляет 0,76 литра, время автономной работы до 60 минут (или до 120 для комплектации Absolute extra, где поставляется второй аккумулятор) — с такими характеристиками можно тщательно убрать даже самую большую квартиру.

Модель также оснащена лазерной щёткой для обнаружения «невидимой» пыли, пьезодатчиком (и экраном), что позволяет ускорить и улучшить процесс уборки. Помочь в этом должны и две новые насадки, которые научились бороться с наматыванием волос и шерсти. У одной щётки (с высоким крутящим моментом) это происходит за счёт 56 поликарбонатных зубчиков (выглядят как расчёска), которые не позволяют волосам накручиваться на вал и счищают их в контейнер; а вторая — мини-турбощётка борется с волосами и шерстью за счёт формы в виде конуса с винтом Архимеда. Такая конструкция скатывает волосы в шарик и отправляет всё туда же, в контейнер. Владельцы длинношерстных животных, ликуйте!


В отличие от представленных выше моделей, V15 оснащён курком, а не кнопкой.
- Вес: 3 кг
- Объём контейнера: 0,76 л
- Время работы: до 60 минут
- Мощность всасывания: 240 аВт
Dyson Outsize
Обновилась и модель Dyson V11, которая получила название Dyson Outsize — с увеличенным на 150% контейнером для пыли и мусора и увеличенной на 25% насадкой с высоким крутящим моментом. 220 аВт, 14 циклонов, лазер, ЖК-дисплей (но без пьезодатчика) и до 120 минут работы — набор для настоящих фанатов чистоты =)
Сравнительная таблица
Все модели уже появились в продаже.
Подписаться на:
Сообщения (Atom)