
Однажды в технической документации к
Parallels Desktop нам потребовалось использовать фразу «
жёсткий диск виртуальной машины». На английском языке это звучит:
virtual machine hard disk. Наш прошлый технический писатель ошибся всего в одной букве в одном слове, но смысл получился диаметрально противоположный. Мы этого заметили не сразу и в какой-то момент наша техническая документация, локализованная на многих языках мира, содержала нетленное:
virtual machine hard dick. Был грандиозный скандал, после которого мы ужесточили проверку текстов. Под катом —
рассказ нашего технического писателя Андрея Старовойтова о том, где обитают технические писатели, на что их ловить и как
Parallels документирует и локализует свои продукты.
Возможно, у вас возникнет вопрос — а зачем мне, разработчику/программисту/тестировщику, знать о том, как создаются и локализуются документация и интерфейс? Всё очень просто: жизнь может внезапно повернуться к вам так, что сегодня вы программист, а уже завтра запускаете свой стартап, в котором вы и швец, и жнец, и технический писатель. Также не исключено, что заняв менеджерскую должность вам внезапно придётся контролировать процесс разработки технической документации.

Часть 1: Где найти технического писателя или гуманитарий в тылу у технарей
Технических писателей не готовят в ВУЗах. Если понадобился такой специалист, можно пригласить его из-за рубежа, или «вырастить» в компании. Ниже мы поподробнее остановимся на этих вариантах.
Иностранный специалист
Плюсы:
Если вы планируете продавать продукт за рубежом и вам нужна документация на английском языке, носитель языка более качественно опишет приложение. Нельзя сказать, что отечественный сотрудник со знанием языка сделает это обязательно плохо, но если подходить к вопросу с точки зрения перфекционизма, то по некоторым фразам, оборотам, построению предложений иностранные пользователи могут понять, что документацию писал не носитель.
Минусы:
Во-первых, иностранному специалисту придется больше платить. А во-вторых, не каждый иностранец согласится приехать на работу в Россию. Если же он будет работать удаленно, в отрыве от разработчиков, то возможны опоздания в сроках подготовки документов, и технические неточности, так как удаленно всегда сложнее выяснить технические детали, нежели если поговорить с программистами напрямую.

Писатель «которого вырастили»
Тут встает вопрос, из кого выращивать – технарь или гуманитарий? Конечно, все зависит от конкретной ситуации, но давайте посмотрим на основные моменты.
«Технарь»
Плюсы:
Технарь лучше понимает начинку и технические детали или же ему проще разобраться.
Минусы:
Не каждому технарю захочется возиться с документацией, потому что разработчик чаще сконцентрирован на какой-то узкой области и видит себя Скульптором, а не Евгением Онегиным, «который может коснуться до всего слегка с ученым видом знатока».
«Гуманитарий»
Плюсы:
Все зависит от конкретного случая, но гуманитарий может лучше описать продукт, так как лучше владеет языком. И еще такой момент, разработчик может описать функцию или фичу двумя предложениями, так как с его багажом знаний ему и так все понятно. Для покупателя продукта такого описания может оказаться недостаточно. У гуманитария, как неспециалиста, при описании возникнут разнообразные вопросы. Если он найдет на них ответы и опишет функцию продукта так, чтобы самому было понятно, то такая документация окажется более понятна для пользователя. Хотя опять же, все зависит от конкретной ситуации, если руководство написано для администраторов, будет излишне объяснять им что такое IP адрес.
Минусы:
Минус гуманитария в том, что он меньше знает техническую сторону продукта, и потребуется время, что он овладел терминологией, освоил азы и стал понимать что к чему.
Личный опыт
 — Я попал в Parallels весьма прозаично. После школы учился в педагогическом колледже в городе Серпухове на преподавателя английского языка. После в Московском Государственном Лингвистическом Университете им. Мориса Тореза. Когда на третьем курсе университета встал вопрос серьезной работы, я уже успел побывать курьером по развозу DVD, учетчиком на складе, начальником склада, менеджером по продажам. Все это было хорошо, но желание зарабатывать на жизнь английским языком было крепче. В преподавание не пошел, так как хотелось поработать в какой-нибудь прикладной области – нефтянка или IT.
— Я попал в Parallels весьма прозаично. После школы учился в педагогическом колледже в городе Серпухове на преподавателя английского языка. После в Московском Государственном Лингвистическом Университете им. Мориса Тореза. Когда на третьем курсе университета встал вопрос серьезной работы, я уже успел побывать курьером по развозу DVD, учетчиком на складе, начальником склада, менеджером по продажам. Все это было хорошо, но желание зарабатывать на жизнь английским языком было крепче. В преподавание не пошел, так как хотелось поработать в какой-нибудь прикладной области – нефтянка или IT.
Как-то на одном из сайтов по поиску работы я увидел вакансию – помощник технического писателя в компанию SWsoft с возможность карьерного роста. В объявлении говорилось об участии в создании документации для компьютерных программ. Писать документацию требовалось сразу на английском. Для меня это было что-то совершенно новым и заинтересовало. Я отправил резюме, прошел собеседование, написал сочинение на свободную тему и так стал junior technical writer.
Сначала было непросто. Будучи гуманитарием до мозга костей, при написании первых топиков, казалось, что все вокруг говорят на каком-то птичьем языке. Я совершенно не знал терминов. Разговор с девелоперами первое время выглядел примерно так:
— Здравствуйте, я новый технический писатель. Мне надо описать вот эту функциональность. Не могли бы вы чуть поподробнее рассказать как она работает?
— А, ну тут все просто, клиент «коннектится», если «сервак» не дохлый, все нормально. Если что, можно «попинговать». Бывает «бага стреляет», «контейнер бсодится», но тут «патчик» можно накатить. Возьми вот этот «экзешник», он у тестировщиков на «репе» лежит. Понял? Ну молодец.
или так:
— Мне вот тут надо фичу описать, она связана с Active Directory. Не могли бы вы рассказать что это такое?
— Да это тоже самое что и LDAP на Линуксе.
Поначалу записывал все эти термины в тетрадочку, затем шел «гуглить» значение. После этого опять шел к разработчикам или тестировщикам и спрашивал по-новой. Первые полгода, в свободное от работы и учебы время, изучал терминологию, читал что такое автоматизация, виртуализация, контейнеры, виртуальные машины, оперативная память, процессор, IP адрес, DHCP, и т. д. Потом, неожиданно количество перешло в качество и я стал свободнее себя чувствовать в этой сфере. Если что-то не понимал, мне хватало гугла для того, чтобы схватить основную мысль, а к девелоперам шел уже в основном за деталями.
На данный момент я работаю в компании уже около 8 лет. Вырос до старшего технического писателя. Теперь я занимаюсь не только созданием документации и интерфейса, но и их переводами на поддерживаемые языки.
Часть 2: Как мы создаем техническую документацию
Над созданием документации у нас трудятся 3 человека – двое в России и один сотрудник в США, для которого английский язык родной. Для написания технических книг, мы используем продукт
AuthorIT. В нем довольно удобно работать. Библиотека с книгами лежит на сервере. У каждого писателя на компьютере стоит клиентская часть, с которой он подключается к библиотеке. Это позволяет нескольким писателям работать над одной книгой. Применение вариантов позволяет легко создавать книги для новых версий продуктов на основе старых.
Мне сложно сказать что-либо о других продуктах, в которых можно создавать документацию, поскольку исторически сложилось, что мы работаем в AuthorIT. Нас он пока устраивает, а переходить на другой продукт просто из любопытства может оказаться удовольствием недешевым. Например, та же подписка на AuthorIT на 3 человек обойдется в $375 в месяц и выше.
Так как наш основной рынок сбыта находится за рубежом, мы пишем документацию сразу на английском языке. Поскольку сейчас в мире английский считается универсальным языком, особое внимание стоит уделить тому, чтобы в английской документации проблем не было. Конечно можно было бы писать на русском, а потом переводить на английский, но это вызовет необходимость проверять насколько качественно выполнен перевод.
Мы не хотели бы тратить на это ресурсы, так как у нас есть возможность писать сразу на английском и одновременно проверять, чтобы этот английский был понятен и выглядел так, как будто бы текст написан носителем языка.
Процесс создания документации построен следующим образом:
1) Маркетинг с менеджерами обговаривают список функциональностей и улучшений, которые будут внедрены в новой версии продукта.
2) Для каждой задачи менеджер пишет детальное описание.
3) После того, как программист внедряет функциональность, я ставлю последнюю версию программы на компьютер, читаю описание, пробую как новинка работает, и описываю ее в руководстве. Если возникают какие-либо вопросы, общаюсь с менеджерами или разработчиками.
4) Я описываю новый функционал на английском, после чего отправляю топики нашему иностранному писателю на проверку. Он читает и если есть необходимость вносит какие-либо правки. Вроде бы я неплохо знаю английский, но все равно носитель языка иногда может выразиться более лаконично и емко.
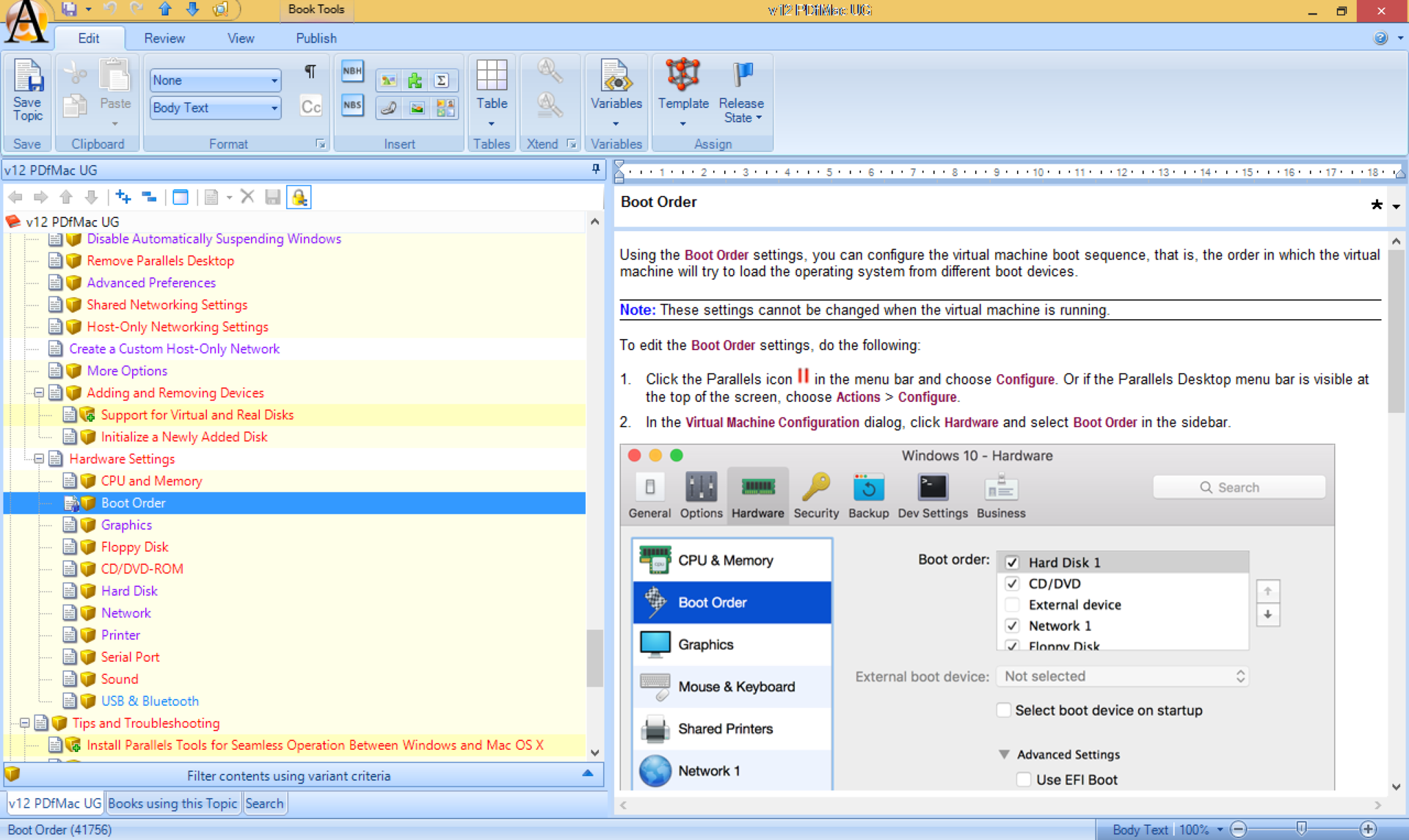
5) После проверки, иностранный писатель присылает топики мне, я заливаю их в базу и публикую документы в необходимые форматы – в основном это PDF и XHTML для контекстной справки (это когда жмешь на экране иконку со знаком вопросы и привязанный к этому скрину хелп топик открывается в браузере).
6) Когда английская документация готова, я отсылаю ее на перевод. О том как и на какие языки мы переводим я расскажу ниже.
Какие документы создаются для продукта:
User’s Guide – это самая большая книга для продукта, в которой описывается весь функционал, хитрости и решения возможных проблем. Ориентирован на большинство пользователей.
Getting Started Guide – это короткий документ, в котором описана процедура установки и основные шаги, необходимые для начала работы с продуктом. Ориентирован на знакомство с продуктом и пользователей, которые обладают неким опытом и хотят побыстрее начать работу с приложением, не внедряясь в дополнительные настройки и тонкости.
Readme – обычно это текстовый файл, который создается для каждого релиза, хотфикса и апдейта. В нем описано то, что было сделано нового, что улучшено и какие проблемы решены.
Knowledgebase articles – это статьи для так называемой базы знаний. В них описаны или какие-то моменты, которые вызывают частые вопросы у пользователей или временные решения известных проблем.
Так же существуют различные другие виды книг, такие как:
— Licensing Guide (описывает как создать аккаунт, управлять своим ключом или подпиской и т. д.)
— Administrators guide (документ для людей с техническим опытом для развертывания продукта в больших компаниях)
— Training manual (документ для людей, которые обучают пользователей как работать с продуктом)
— Command Reference Guide (в нем описаны команды для текстовой строки и даны примеры их применения)
— API Reference Guide (в таких книгах документируют API).
Какие инструменты мы используем для создания документации:
— AuthorIT – программа для создания и работы над книгами.
— Adobe Photoshop – для создания и работы над скриншотами для документации.
— Microsoft Visio — для создания схем.
— Microsoft Word и Adobe Acrobat – для публикации документов в .docx формат и последующей генерации в PDF.
В работе по созданию документации бывают разные курьезы. В основном связанные или с невнимательностью писателя или если что-то делается в спешке и банально упустили. Например, были случаи когда выпускалась готовая документация, в которой остались не удаленные комменты писателя, например «Уточнить у Васи как эта херня работает».
А еще бывает, что сами писатели прикалываются в документации для внутреннего пользования. Некоторые люди считают, что документация никому не нужна, так как ее никто не читает. Иногда писатель в каком-нибудь неофициальном документе для компании может написать в тексте инструкций – «кто первым это прочтет и позвонит мне – выиграет пиво».
Часть 3: Как технический писатель может участвовать в создании GUI
В процессе работы над фичами, разработчикам зачастую надо придумать название опции, меню, дескрипшн под опцией или сообщение об ошибке. Так как мы делаем гуй сразу на английском, девелоперы поручают эту задачу мне. Я читаю описание фичи, спрашиваю девелоперов и менеджеров что нам нужно сказать, выясняю детали и предлагаю свой английский вариант. Если он технически верен, отправляю его на утверждение нашему иностранному писателю и сообщаю ему все детали, которые выяснил у девелоперов. Тот в свою очередь или утверждает мой вариант или предлагает что-то свое. Если финальный вариант всех устраивает, его заливают.
В процессе создания гуя, мы придерживаемся следующих пунктов:
1) Нужно стараться делать названия опций понятными и короткими, чтобы избежать последующих проблем с их локализацией, когда перевод не влезает. Например, у нас есть опция, которая тормозит курсор мыши у границы окна виртуальной машины. Это было сделано, чтобы юзер в Windows 8 мог легче открыть дополнительные меню, которые находятся у границы. Без этой опции юзер зачастую просто выводил курсор за границу и приграничное меню не показывалось. Так вот, долго думали как назвать эту опцию, получалось или слишком длинно или не совсем понятно. В итоге остановились на «Mouse sticks at window edges». Конечно бывают случаи, когда сложно придумать идеальное название для опции, в таких ситуациях приходится выбирать более-менее приемлемый вариант и надеяться на то, что если юзер не поймет, то почитает в документации.
2) Если в сообщении используются сложные термины или описан трудоемкий процесс как решить какую-то проблему, есть смысл дать ссылку на КБ статью или какой-то другой ресурс, где есть более детальное и подробное описание или объяснение.
3) При создании сообщения, надо концентрироваться не на том, что не получилось что-то сделать, а на том, что надо сделать чтобы желаемый результат был достигнут.
Часть 4: Перевод технической документации и GUI
После того, как началась разработка новой версии программы, обычно к Beta 1/Beta 2 накапливается первая партия хелп топиков и фраз гуя, которые можно отсылать на локализацию.
На мой взгляд, очень здорово, если тот самый писатель, который написал топики и помогал делать гуй, и будет управлять переводами и общаться с переводческой конторой. Такой человек грамотно планирует работу, лучше знает сроки когда что будет написано или как скоро что-то надо описать. Он знает значение гуевых фраз и может легче и быстрее ответить на вопросы переводчиков.
Помню мы раньше использовали разделение – есть люди, которые пишут, и есть человек, который занимается только локализацией. В итоге не всегда процессы проходили эффективно. Например, писатели описали фичи, свои таски в Jira закрыли и успокоились. Но забыли отметить все топики, которые были изменены. В итоге менеджер локализации отправил на перевод не все и в результате приходилось в дикой спешке допереводить пропущенное. Или менеджер по локализации отправил гуй на перевод, но он его не создавал, и не может ответить на многочисленные вопросы переводчиков. Начинает дергать разных людей, а их еще надо найти, потому что часть гуя делали сервер тим, часть – девайсы, часть гуевщики, часть – интеграторы, короче потеря времени и не детальные ответы – как результат – недостаточное качество переводов.
Мы переводим документацию и гуй наших продуктов на следующие 12 языков: немецкий, французский, итальянский, испанский, польский, чешский, русский, португальский (бразильская версия), японский, корейский и две версии китайского — упрощённый и традиционный тайваньский.
Далее может появиться вопрос – как лучше, иметь своих собственных переводчиков или пользоваться услугами переводческой компании. Давайте посмотрим плюсы и минусы обоих вариантов.

Собственные переводчики
Плюсы:
Если переводчики есть у вас в штате, то они как правило довольно неплохо знают продукт и благодаря этому способны делать более качественные переводы.
Минусы:
Как правило, наиболее активная стадия разработки продукта, когда надо делать много переводов, длится 3-4 месяца. В такой ситуации необходимо все считать, потому что может оказаться просто экономически невыгодно держать переводчиков на постоянной основе.
Переводческая контора
Плюсы:
Мы отсылаем им задания тогда, когда разработка идет в разгаре, и платим только за выполнение этих заданий. В итоге это получается дешевле, нежели иметь 12 переводчиков в штате.
Минусы:
Зачастую переводческая контора работает не только на вас, и вашим заказом сегодня может заняться один переводчик, а завтра совершенно другой. Он о вашем продукте может абсолютно не иметь никакого понятия. Чтобы не потерять в качестве переводов, приходится писать много объяснений для переводчиков, да бы они имели представление о том, что переводят и на что обратить внимание.
Мы пользуемся услугами одной из европейских компаний. У неё свой корпус переводчиков на разные языки.
Все текстовые материалы отправляются подрядчику. Форматы могут быть самыми разными:
• при локализации GUI — .txt-файлы, .strings-файлы, .xml-файлы, .xliff-файлы,
• при локализации документации — .docx-файлы, .xml-файлы
В первую очередь надо локализовать GUI. К каждой порции гуя на перевод я готовлю подробные комментарии для переводчиков – по каждой фразе. В комментариях описываю что это за фраза, как ее переводить – инфинитивом или императивом, надо ли переводить как можно короче (особенно если это кнопка) и если да, то во сколько символов надо уместиться. Также шлю переводчикам скриншоты, чтобы они могли посмотреть как опция или сообщение выглядит в гуе.
Почему в первую очередь надо переводить гуй
Дело в том, что переведенные фразы попадают в так называемую память переводов – translation memory. Из этой памяти они впоследствии будут браться, если в последующей порции фраз на перевод окажется точно такая же. Например, мы перевели гуй и утрясли опции по длине. После этого я отправляю на перевод документацию, в которой эти же опции описываются. Так вот, перевод этих опций для документации будет взят из translation memory, и таким образом фразы и в гуе и в документации будут переведены одинаково. Если же я сначала переведу документацию, а потом гуй, то если в гуе опция будет слишком длинной, мне придется править и в гуе и в документации, чтобы везде было консистентно, а это лишний геморой.
По мере готовности переводчики присылают мне переведённые материалы, я импортирую их в базы, откуда потом локализованный гуй и документация попадают в билд.
Как работает переводческая контора?
Получив от нас материалы, подрядчик прогоняет их через свою базу уже выполненных переводов — так называемую translation memory. Система ищет, есть ли в новом материале данные, которые были когда-то переведены. По мере нахождения эти готовые фрагменты вставляются в текст. Допустим, если из четырёх присланных абзацев три уже были переведены для предыдущего релиза, то достаточно перевести только четвёртый абзац, а остальные взять их базы данных. Это экономит и время, и деньги. Так что дольше всего переводятся самые первые порции материалов, где больше всего изменений и нового текста.
В работе с локализационными компаниями есть одна особенность: им нужно единовременно присылать как можно больше материала. Если делать слишком маленькие по объёму заказы, то это может оказаться гораздо дороже.
Почему так происходит?
У каждой локализационной компании прописаны свои минимальные объёмы на перевод. Если после прогона через их базу данных окажется, что нужно перевести слишком мало текста, то счета выставляются не за переведённые слова, а за почасовую работу переводчиков. А поскольку с приближением к дате релиза порции текстов, требующих локализации, становятся всё меньше, приходится лавировать, придерживая материалы, чтобы накопить побольше и не переплатить. При этом важно не сорвать сроки, выкатив за неделю до релиза слишком большой заказ на перевод.
Стоимость локализации
Наверное, вас интересует, сколько же компании тратят на локализацию своих продуктов? Это сильно зависит от объёмов и выбранных языков. Например, стоимость перевода одного слова на польский язык — $0,14, на немецкий — $0,23, на французский — $0,21. У нас большие и сложные продукты, с увесистой документацией, которую нужно переводить на 12 языков. Поэтому общая стоимость локализации в среднем составляет $10-60 тыс. Причём сюда не входят расходы на перевод статей из баз знаний (knowledge base), в которых описываются различные методики работы, а также локализацию изменений на сайте.
«Джентльменам верят на слово»
Учитывая разнообразие языков и высокую стоимость работ, как можно оценить качество перевода? А вдруг подрядчик просто прогнал текст через Google Translate и подрихтовал результат?
Дело в том, что в сфере локализации крайне важна репутация. Когда компании ищут подрядчиков для перевода документации и интерфейсов, они подходят к этому очень тщательно. Например, мы выбирали примерно из 15 компаний: всем разослали тестовые задания, а затем проверяли сделанные переводы по своим сотрудникам из разных стран, понимающих эти языки. Также пристальное внимание мы уделяли отчётности о выполненной работе: насколько подробно расписано, сколько слов переведено, сколько обнаружено новых слов, учитываются ли случаи, когда нужно переводить лишь часть предложения, и так далее.
В конце концов мы выбрали своим подрядчиком одну из компаний и начали с ней работать. Но это не означает, что мы с тех пор верим им на слово. Качество переводов регулярно проверяется:
• нашими сотрудниками, понимающими соответствующие языки,
• переводчиками самого подрядчика. Дело в том, что там переводят одни, а вычитывают по нашей просьбе другие.
Наверняка вы скажете, что проверять работу одной компании нужно у специалистов другой. Но дело в том, что локализационные компании отчаянно борются за клиентов. И если мы кому-то пришлём тексты и попросим их оценить, то нам сразу скажут, что переведено из рук вон плохо, давайте мы сделаем гораздо лучше. Собственно, попытки нас переманить не прекращаются до сих пор.
Иногда, когда выходит большой релиз, не всегда получается проверить документацию, локализованную незадолго до дедлайна. Тогда приходится на свой страх и риск выпускать как есть. Но в таких случаях мы тесно работаем с поддержкой: если в документации есть какие-то косяки, на которые поступают жалобы от пользователей, то мы сразу обращаемся к переводчикам и переделываем. К счастью, такое случается редко.
Проблемы с переводами
В процессе работы над переводами, могут встречаться определенные косяки. Их все надо тщательно обговаривать с переводческой конторой, чтобы там разобрались и подобного больше не повторялось.
1) Невнимательный переводчик – если во фразе гуя есть переменная, невнимательный переводчик может пропустить ее часть. Например, у вас переменная (%1)s, а в переводе получите (%1). В итоге фраза будет выглядеть не так, как надо.
2) Переводчик задумался – все мы люди, бывает, что переводчик что-то переведет неправильно, причем что-то довольно простое. Например фраза This file is not valid (Файл недействителен) будет переведена как «Файл не найден».
3) Слишком тщательный переводчик – такой переводчик переводит все, что видит. Тут надо объяснить, что переменную ProductName на надо переводить как «Имя продукта», иначе она ломается и в гуе имена продуктов не подставляются. Или же если он переводит .xml файл с документацией, то не надо переводить теги и , иначе потом такой xml не импортится в базу из-за разломанных тегов.
4) Сложный технический термин или аббревиатура– если в тексте на перевод есть что-то подобное, лучше сразу в комментариях обратить внимание переводчиков на это, описать что это такое и посоветовать погуглить, чтобы узнать как правильно это переводится на их язык. Иначе можно получить что-то далекое от нужно термина.
5) Косяки из-за отсутствия комментариев – если не делать комментарии для переводчиков, они могут задать вопросы не по всем непонятным моментам. В итоге может пострадать качество переводов. Например, у нас есть приложение Parallels Access, которое позволяет получить доступ к удаленным компьютерам с iOS и Android устройств. В другом продукте есть вкладка, которая позволяет скачать это приложение. Эта вкладка называется Access и не должна переводиться. Мы тогда не успели сделать комментарии, в итоге чехи и поляки быстренько ее перевели, где как «доступ», где «приступ».
6) Слишком ответственный переводчик – такой переводчик сам может вставлять знаки препинания, которые не надо вставлять. Например у нас в одном продукте двоеточие и точка в конце предложения вставляется автоматически – так написано в коде. В итоге мы отослали на перевод фразы без точек и двоеточий в конце. Переводчик в переводе сам решил поставить в конце точки, и у нас везде оказались двойные точки. Или переводчик может додумать и дописать текст фразы. Например, есть фраза Unable to save the license file. Я в комментарии объясняю, что она показывается в том случае, когда по каким-то причинам мы не можем сохранить лицензионный файл для продукта Parallels Desktop. Приходит перевод – «Не удалось сохранить лицензию для Parallels Desktop.» Приходится объяснять, что додумывать не надо и лучше ограничиться фразой «Не удалось сохранить лицензию», так как в коде она может быть использована для других продуктов.
7) Слишком длинный перевод – получаешь бывает перед релизом порцию переведенного гуя, заливаешь переводы, а в гуе половина опций не влезает – слишком длинно перевели. Тут надо реагировать по ситуации – или срочно просить переводчиков сократить перевод, или просить девелоперов расширить окно, потому что если длинную фразу сокращать до «тыр.пыр.мыр.», то это получится некрасиво и непонятно.
8) Неправильно рассчитанные сроки – иногда бывают ситуации, когда отсылаешь файлы на перевод и думаешь – ну тут за 3 дня переведут, максимум. А тебе выкатывают срок – неделя, не меньше. Поэтому я взял за правило – к ожидаемому сроку прибавляй 3-4 дня на всякий случай.
9) Праздники в других странах – это тоже связано со сроками. Обычно локализационная компания предупреждает, и об этом надо помнить – где, когда и у кого государственные праздники. А то иной раз надо что-то срочно перевести на китайский, думаешь – ну это я мигом, а тебе говорят, что у них же новый год сейчас. Обещают попробовать найти выход но в результате подобная ситуация может тоже обернуться задержкой.
10) Разработчик – оптимизатор – иногда приходится вести войну с разработчиками. У них оптимизация кода — это идея фикс. Они очень любят многократно использовать одни и те же данные. Например, вставят в одном месте какую-то фразу или слово, а потом ссылаются из самых разных мест. У меня был такой случай. В приложении есть вкладка, на которой можно переназначать клавиатурные сочетания. В частности, там есть шорткат Ctrl+Alt+Delete. И ещё у нас есть менеджер снэпшотов, позволяющий удалять эти снэпшоты. Что характерно, кнопка так и называется — Delete. Разработчик, который писал этот менеджер, вместо того, чтобы назвать шорткат Ctrl+Alt+Delete и отдельно кнопку Delete, придумал оптимизацию: в одном месте кода назвал кнопку Delete, а шорткат назвал Ctrl+Alt+<вот эта кнопка>. И когда мы стали переводить интерфейс, кнопка Delete была переведена на все языки. В русскоязычной версии этот шорткат стал называться Ctrl+Alt+Удалить. Пришлось в коде прописывать отдельно названия кнопки и шортката. Другой пример. Когда мы выпускали Parallels Access, на начальном экране была фраза “Welcome to Parallels Access”. По идее, её нужно было прописать в коде как есть. Но поскольку во фразе использовались три разных шрифта, разработчики разбили её на три части: Welcome, to и Parallels Access. И при выводе на экран фраза собиралась из этих частей. Когда дело дошло до переводов, японцы офигели, но добросовестно перевели все три части по отдельности. Только проблема в том, что в японском языке текст читается справа налево. И вместо «Добро пожаловать в Parallels Access» у них получилось «Parallels Access в добро пожаловать». Пришлось менять код.
Проверка локализации перед релизом
Как бы тщательно не делались комментарии для перевода, а различные косяки все-таки бывают, поэтому перед релизом хорошо бы проверить качество локализации.
Проверять можно одним из следующих способов – или дать переводчикам программу и сценарии, по которым надо осуществить проверку, или предоставить скриншоты продукта и сценарии. Опять же, у каждого из них свои плюсы и минусы.
Проверка на живом билде
Плюсы:
Переводчик получает сценарии, по которым он как обычный пользователь гоняет продукт и отмечает где какое название или сообщение надо изменить или поправить. В таком случае, переводчик выступает еще и как тестировщик и были случаи, когда переводчики находили баги, не связанные с локализацией. Такой тип тестирования проще подготовить, чем по скриншотам, так как надо составить только английские инструкции, и нет необходимости делать кучу скриншотов для 12 языков.
Минусы:
Этот тип тестирования более затратен в финансовом плане. Зачастую у переводчиков нет необходимого оборудования, поэтому надо им заплатить дополнительно, чтобы они его арендовали. Также они потратят больше времени на проверку живого билда, за каждый час надо заплатить. Плюс, когда они начинают, гонять живой билд, у них как правило что-то не получается, а ответить на многочисленные вопросы 12 переводчиков – тоже требуется время.
Проверка по скриншотам
Плюсы:
Менее затратно по финансам. Ты присылаешь переводчикам английские инструкции и скриншоты, а так же локализованные скриншоты в том же порядке, что и английские. В итоге, переводчик читает инструкции и сравнивает английские скриншоты с локализованными, и отмечает что и где хорошо бы поправить. Такую работу тоже надо оплачивать по часам, но она занимает гораздо меньше времени чем проверка живого билда.
Минусы:
К такому типу тестирования надо тщательно подготовиться. Надо не только сделать подробные английские инструкции, но и наснимать такие же скриншоты для каждого языка, а их 12. Приходится потратить порядочно времени.
В финале хочется сказать, что конечно же создать простой, удобный и понятный программный продукт, который бы еще и сам себя продавал – мечта любого разработчика. В реальности же все складывается по-другому. Наряду с разработкой вашего продукта, словно подводная часть айсберга, появляются десятки смежных задач, причем считать их незначительными можно до определенной поры. Искренне надеемся, что данная статья была вам интересна. С удовольствием ответим на дополнительные вопросы в комментариях к материалу.
З.Ы. И лайфхак на последок!

Комментарии (0)