Мы простых путей не ищем.

Предыдущая, она же первая моя публикация вызвала резонанс среди пользователей Хабра. Решил не останавливаться. Продолжаем выжимать невозможное из ATtiny13. Сразу же предупреждаю, описанные решения снова нестандартны, и у кого-то могут вызвать негодование и когнитивный диссонанс («И в чём тогда смысл статьи? Показать, что можно соединять элементы?»). Мало того, такое решение ещё и действительно нецелесообразно, о чём я подробнее напишу ниже. Но так уж повелось, что стандартные решения давно известны, и читать о них не всегда интересно, а писать- неблагодарно.
Очень уж мне нравится этот малыш- ATtiny13. Мозгов у него вполне достаточно для решения многих бытовых задач (включить свет, вентиляцию, в магазин за пивом сбегать). И цена просто смешная. Вот только ножек мало, а ручек и совсем нет. Поэтому приходится идти на всяческие ухищрения, чтобы решить проблему нехватки ног.
В процессе изучения программирования микроконтроллеров (в среде Ардуино, только не говорите никому) я, как многие, прошёл этап подключения ультразвукового датчика расстояния, примерно такого:

Так как способ передачи информации от датчика к контроллеру прост до безобразия, то ATtiny13 справляется с этим запросто. Тогда отображать информацию на семисегментном индикаторе пришлось при помощи сдвиговых регистров. То есть схема отображающей части была в несколько раз больше, чем сам контроллер. На тот момент я поигрался и двинулся дальше.
Недавно я задумался, какую бы ещё непосильную задачу возложить на Тиньку? С чем она ещё не справлялась в описанных примерах. Первым делом я вспомнил об индикации. Некоторое время назад я уже искал информацию на подобную тему. Тогда я нашёл такой интересный вариант.
21 сегмент от 5 ног контроллера. Здорово! Мне столько даже не нужно, хватит и двух знаков, плюс точка, итого 15 сегментов. А если четырьмя ногами? Тогда получится максимум 13 сегментов, не хватает. При виде схемы сразу возникло желание собрать и попробовать, хотя алгоритм работы составить не просто. Но при более внимательном взгляде понимаешь, что собрать не получится, таких семисегментников не существует в природе (скорей всего). Изготовить можно, конечно, но это уже другой уровень. Тогда идея была отложена до лучших времён.
Оффтоп: Почему нет семисегментных индикаторов со встроенной логикой? Куда смотрят разработчики? Насколько удобно в монтаже и управлении- две ножки питания и 3 (1, 2) ноги данных. И ведь были же даже в СССР: 490ИП1, 490ИП2. Внутри самого заурядного индикатора на 2...4 разряда полно места для размещения кристалла микросхемы, а цена сдвигового регистра 0,064 у.е вместе с корпусом. Ну да ладно.
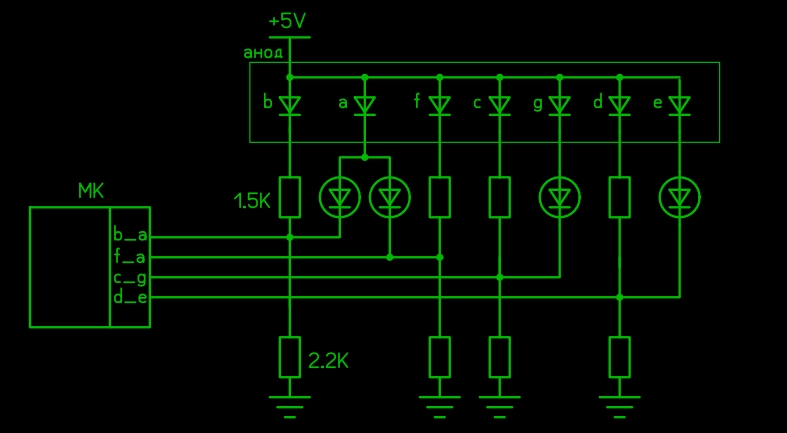
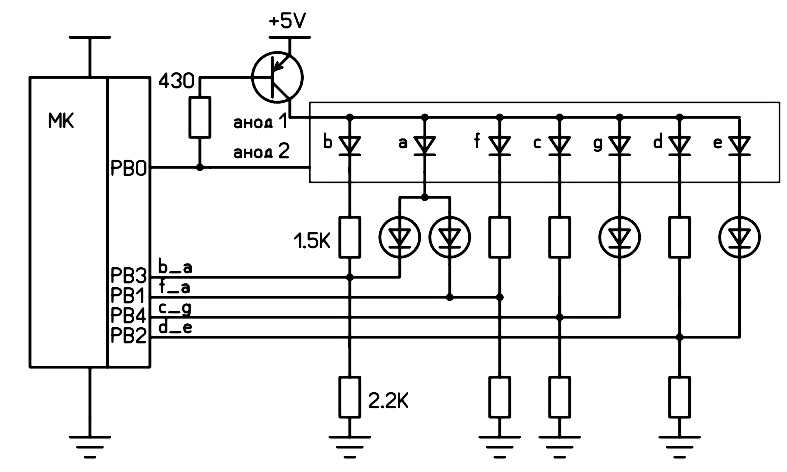
И вот я снова задумался, как же уменьшить количество ног для работы с семисегментным индикатором? Выходы контроллера могут принимать три состояния (на самом деле 4, но сейчас это не важно). Можно ли как-то это использовать? Если два состояния по отношению к светодиоду можно трактовать только как светит-не светит, то с тремя немного интересней. Я ещё не сообразил, как этим пользоваться, но пришла в голову такая схема:

Если выход контроллера в состоянии нуля, светодиоды не светятся (что очевидно).
Если выход в состоянии единицы, то светодиоды светятся, что тоже понятно.
А вот если выход вовсе не выход, а включён на вход, то через цепь из двух резисторов и светодиод HL1 протекает ток, создающий на точке соединения резисторов падение напряжения примерно (5-1,7)/(2,2+1,5)*1,5+1,7=3,0 В. Этого недостаточно для того, чтобы ток пошёл через цепь VD1_R3_HL1 (нужно примерно 3,4 В). VD1- это дополнительный светодиод, используемый в качестве стабилитрона (стабистор правильней), поэтому мы не будем считать его светодиодом, чтобы не путаться. При этом неважно, включён ли подтягивающий резистор внутри микроконтроллера, его сопротивление (20 кОм) практически не влияет на ситуацию. К таким номиналам я пришёл не сразу, до этого пробовал с обычным диодом в качестве VD1, также вполне сносно работает с одинаковыми резисторами R1 и R2. Но лучше, чтоб R2 был примерно в полтора раза больше, чем R1. И чуть не забыл самое главное: всё описанное возможно только при использовании красных светодиодов и в индикаторе, и дополнительных. В крайнем случае или индикатор, или дополнительные светодиоды можно применить зелёные. И при напряжении питания от 4,5 В до 5 В.
Что мы имеем в итоге? Три состояния: не светит ни один светодиод (0), светит HL1 (1), или светят HL1 и HL2 (2). Очень напоминает троичную систему. Но мы не можем засветить HL2 без HL1, об этом нужно помнить. Зато теперь при помощи четырёх ног микроконтроллера можем управлять восемью светодиодами (хотелось так думать).
Дальше я попытался разбить сегменты индикатора на пары (прям как в детском саду: мальчик-девочка). Главное условие- в каждой паре один из сегментов не может светить самостоятельно, такая вот дискриминация. Вот что у меня получилось:
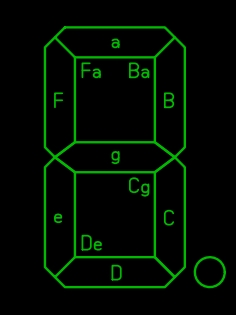
Четыре пары сегментов, в каждой большой буквой обозначен доминирующий сегмент, который может работать сам, второй может только с ним вместе. Можно заметить, что сегмент «а» мутит сразу с двумя, а бедной точке вообще никто не достался. Как это похоже на жизнь!
Зато этими парами можно отобразить (почти) все цифры:
Каждая пара раскрашена своим цветом. Внимательный зритель заметил, что с двойкой что-то не то. Не будем пока акцентировать на этом внимание. Перепробовал ещё несколько вариантов группировки сегментов, лучше не придумал. Может, кто предложит. Возможно, нейросеть справилась бы.
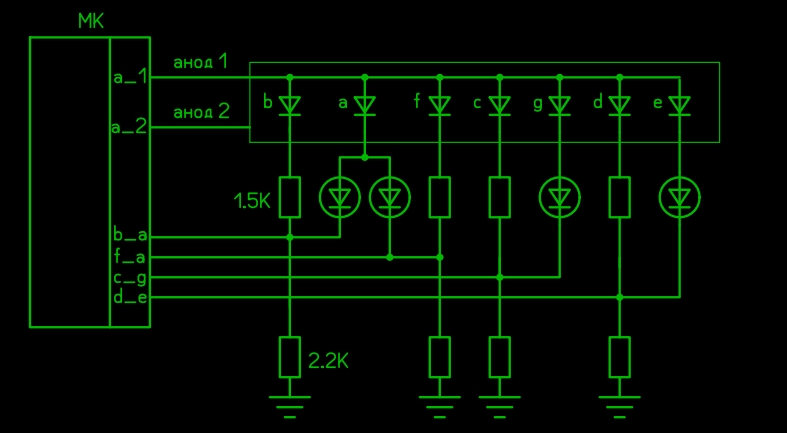
На втором этапе экспериментов мне пришлось применять индикатор с общим анодом. Поэтому итоговая схема получилась такая:
Кто-то может спросить: куда подевались резисторы 100 ом? Давно известно (и активно используется), что при правильно сделанной динамической индикации можно обойтись без токоограничивающих резисторов. Даже если с выхода контроллера на последовательно соединённые два светодиода по ошибке постоянно подавать напряжение, микроконтроллер и светодиоды нормально это выдерживают, ток ограничивается сопротивлением перехода внутри МК. И ещё о резисторах. Максимальный ток через HL1 по предыдущей схеме около 2 мА, а через HL2 достигает 25...40 мА (предположительно, позже я скажу, откуда взялись эти цифры). Значит, и светоотдача у разных сегментов будет разная. Но поскольку будет использоваться динамическая индикация, это легко можно решить за счёт разного времени отображения сегментов.
Все эксперименты я проводил на Arduino Nano в среде Arduino IDE. Отличная плата для прототипирования, хорошо становится в breadboard, прошивается по USB без заморочек. Что-то не получилось? Исправил скетч и через минуту залил новую прошивку. А когда отладил код, можно перейти к прошивке в ATtiny13, это всё-таки занимает чуть больше телодвижений.
Кстати, тоже прошиваю с помощью Arduino и в среде Arduino, это практически исключает возможность залочить МК неправильными фьюзами, да и проще намного.
Вот пример отображения цифры 4 в коде:
pinMode(f_a, INPUT); // ножку подключения сегментов f_a делаем входом
digitalWrite(f_a, 1); // зажёгся сегмент F
pinMode(d_e, OUTPUT); // ножку подключения сегментов d_e делаем выходом
digitalWrite(d_e, 1); // ставим её в состояние 1, при этом не светят D и E
pinMode(b_a, INPUT); // ножку подключения сегментов b_a делаем входом
digitalWrite(b_a, 1); // зажёгся сегмент B
pinMode(c_g, OUTPUT); // ножку подключения сегментов c_g делаем выходом
digitalWrite(c_g, 0); // ставим её в состояние 0, зажглись и C, и G
delayMicroseconds (150); // F, B, C, G cветят ещё 150 микросекунд
pinMode(c_g, INPUT); // ножку подключения сегментов c_g делаем входом
digitalWrite(c_g, 1); // теперь сегмент G потух, светится только сегмент С
delay (time_2); // F, B, C cветят ещё 2 миллисекунды
В принципе, всё должно быть понятно даже тем, кто не знаком с Arduino, но немного понимает в контроллерах. Цифры 150 микросекунд и 2 миллисекунды подобраны экспериментально по яркости сегментов. В окончательном коде их нужно вынести в отдельные переменные, чтобы можно было изменить при отладке. Из этих цифр можно приблизительно определить порядок различия токов через два сегмента в одной паре. Поскольку сегмент G светится примерно в 13 раз меньше времени, чем остальные, и обеспечивает такую же яркость, можно предположить, что ток через этот сегмент в 13 раз больше, чем через другие. На самом деле зависимость яркости от тока нелинейная, поэтому ток может быть больше и в 25 раз, то есть 50 мА. Что при такой скважности вполне безопасно для выхода МК. Кстати, эта разница в токах сыграла на руку при решении проблемы цифры 2. Как я писал выше, сегмент G можно засветить только вместе с сегментом C. Но если подать 0 на ножку МК, отвечающую за C и G, на 150 мксек, а после 2 мсек держать на ней 1, то сегмент G «отработает» на полную яркость, а сегмент С за те же 150 мксек успеет лишь чуть подсветиться. Получаем почти полноценную двойку. Таким образом мне удалось нарушить правило, которое я сам же установил. Что не сделаешь от безысходности.
Итак, цифру четырьмя ножками МК мы зажгли. Собственно, я этот этап для себя пропустил, сразу выводил два знака. Для этого отсоединяем вывод общего анода одного из разрядов индикатора от плюса питания, и подсоединяем к ещё одному выводу МК, и анод другого разряда- к следующему выводу (уже 6 ножек). Теперь по очереди выставляем 1 на аноде младшего разряда, отображаем цифру младшего разряда, дальше 1 на аноде старшего разряда, и отображаем цифру старшего разряда, и так по кругу. Этот эксперимент я проводил с Arduino Nano, у неё ног достаточно. Весь код отлаживал на ней, далеко не с первого раза. И вот всё заработало, как надо.
Поскольку аноды подключаются поочерёдно, при помощи простой доработки можно освободить ещё один вывод МК. Вот итоговая схема:
Итого используем 5 ног МК для отображения двухзначного числа. На этом этапе уже можно попробовать с крошкой ATtiny. Что я и сделал. Но не сразу. Скомпилированный в среде Arduino скетч для ATtiny13 занял примерно 1,7 кБ памяти при 1 кБ доступной. Чтобы уменьшить размер, пришлось обратиться к портам напрямую, что я и так собирался сделать позже. Кстати, на Arduino я использовал те же порты, что собирался использовать на ATtiny, очень удобно. Они уже обозначены на последней схеме. После обработки код похудел на килобайт.
Вот итоговый код для ATtiny13:
Код
#define time_2 2 // время отображения неярких сегментов, миллисекунд
#define time_3 150 // время отображения ярких сегментов, микросекунд
byte in1_;
byte in2_;
int disp_;
int d_ = 0;
void setup()
{
}
void loop()
{
d_ = d_ + 1;
if (d_ > 150) { // просто раз в 150 циклов увеличиваем число на 1
d_ = 0;
disp_ = disp_ + 1;
if (disp_ > 99)(disp_ = 0); // считаем от 0 до 99
}
in2_ = disp_ / 10; // пишем в левый разряд - цифру делёную на 10
in1_ = disp_ % 10; // пишем в правый разряд цифру оставшуюся от деления на 10
}
switch (in1_) {
case 0:
DDRB = B00001111;
PORTB = B00010000;
delayMicroseconds (time_3);
DDRB = B00000001;
delay (time_2);
break;
case 1:
DDRB = B00000111;
PORTB = B00000110;
delay (time_2);
break;
case 2:
DDRB = B00011111;
PORTB = B00000010;
delayMicroseconds (time_3);
DDRB = B00010011;
PORTB = B00010010;
delay (time_2);
break;
case 3:
DDRB = B00011011;
PORTB = B00000110;
delayMicroseconds (time_3);
DDRB = B00000011;
delay (time_2);
break;
case 4:
DDRB = B00010101;
PORTB = B00001110;
delayMicroseconds (time_3);
DDRB = B00000101;
delay (time_2);
break;
case 5:
DDRB = B00011011;
PORTB = B00001100;
delayMicroseconds (time_3);
DDRB = B00001001;
delay (time_2);
break;
case 6:
DDRB = B00011111;
PORTB = B00001000;
delayMicroseconds (time_3);
DDRB = B00001001;
delay (time_2);
break;
case 7:
DDRB = B00001111;
PORTB = B00010110;
delayMicroseconds (time_3);
DDRB = B00000111;
delay (time_2);
break;
case 8:
DDRB = B00011111;
PORTB = B00000000;
delayMicroseconds (time_3);
DDRB = B00000001;
delay (time_2);
break;
case 9:
DDRB = B00011011;
PORTB = B00000100;
delayMicroseconds (time_3);
DDRB = B00000001;
delay (time_2);
break;
}
switch (in2_) {
case 0:
DDRB = B00001111;
PORTB = B00010001;
delayMicroseconds (time_3);
DDRB = B00000001;
delay (time_2);
break;
case 1:
DDRB = B00000111;
PORTB = B00000111;
delay (time_2);
break;
case 2:
DDRB = B00011111;
PORTB = B00000011;
delayMicroseconds (time_3);
DDRB = B00010011;
PORTB = B00010011;
delay (time_2);
break;
case 3:
DDRB = B00011011;
PORTB = B00000111;
delayMicroseconds (time_3);
DDRB = B00000011;
delay (time_2);
break;
case 4:
DDRB = B00010101;
PORTB = B00001111;
delayMicroseconds (time_3);
DDRB = B00000101;
delay (time_2);
break;
case 5:
DDRB = B00011011;
PORTB = B00001101;
delayMicroseconds (time_3);
DDRB = B00001001;
delay (time_2);
break;
case 6:
DDRB = B00011111;
PORTB = B00001001;
delayMicroseconds (time_3);
DDRB = B00001001;
delay (time_2);
break;
case 7:
DDRB = B00001111;
PORTB = B00010111;
delayMicroseconds (time_3);
DDRB = B00000111;
delay (time_2);
break;
case 8:
DDRB = B00011111;
PORTB = B00000001;
delayMicroseconds (time_3);
DDRB = B00000001;
delay (time_2);
break;
case 9:
DDRB = B00011011;
PORTB = B00000101;
delayMicroseconds (time_3);
DDRB = B00000001;
delay (time_2);
break;
}
DDRB = B00011111;//пауза между отображениями
PORTB = B00011110;
delay (5);
}
Приведённый код позволит вашей ATtiny13 считать от 0 до 99. Правильнее было бы предусмотреть возможность переназначения ножек МК. Гуру программирования могли бы уменьшить код в несколько раз (
Где предел минимального Hello World на AVR?).
Вы можете добавить в код нужную функцию, чтобы МК отображал что-то осознанное. Правда, у Тиньки уже все ножки заняты. Есть ещё ножка сброса, которую можно использовать как порт ввода-вывода. Но воспользоваться ней оказалось сложней, чем я думал. Поэтому для себя оставлю «на потом». Но есть интересная особенность, о которой не все знают. На эту же ножку выведен аналоговый вход ADC0, и он работает! Правда, при напряжении на нём менее 1/4 от напряжения питания МК переходит в режим сброса. Зато от 1/4 и до напряжения питания вполне можно измерять напряжение на входе. Этим я и воспользовался:
Код
#define time_2 2 // время отображения неярких сегментов, миллисекунд
#define time_3 150 // время отображения ярких сегментов, микросекунд
byte in1_;
byte in2_;
int disp_;
int d_ = 0;
void setup()
{
}
void loop()
{
d_ = d_ + 1;
if (d_ > 50) { // раз в 50 циклов...
d_ = 0;
disp_ = analogRead(A0) / 10; // ...измеряем напряжение на входе, делим на 10, чтобы вложиться в диапазон.
if (disp_ > 99)(disp_ = 99);
in2_ = disp_ / 10; // пишем в левый разряд - цифру делёную на 10
in1_ = disp_ % 10; // пишем в правый разряд цифру оставшуюся от деления на 10
}
switch (in1_) {
case 0:
DDRB = B00001111;
PORTB = B00010000;
delayMicroseconds (time_3);
DDRB = B00000001;
delay (time_2);
break;
case 1:
DDRB = B00000111;
PORTB = B00000110;
delay (time_2);
break;
case 2:
DDRB = B00011111;
PORTB = B00000010;
delayMicroseconds (time_3);
DDRB = B00010011;
PORTB = B00010010;
delay (time_2);
break;
case 3:
DDRB = B00011011;
PORTB = B00000110;
delayMicroseconds (time_3);
DDRB = B00000011;
delay (time_2);
break;
case 4:
DDRB = B00010101;
PORTB = B00001110;
delayMicroseconds (time_3);
DDRB = B00000101;
delay (time_2);
break;
case 5:
DDRB = B00011011;
PORTB = B00001100;
delayMicroseconds (time_3);
DDRB = B00001001;
delay (time_2);
break;
case 6:
DDRB = B00011111;
PORTB = B00001000;
delayMicroseconds (time_3);
DDRB = B00001001;
delay (time_2);
break;
case 7:
DDRB = B00001111;
PORTB = B00010110;
delayMicroseconds (time_3);
DDRB = B00000111;
delay (time_2);
break;
case 8:
DDRB = B00011111;
PORTB = B00000000;
delayMicroseconds (time_3);
DDRB = B00000001;
delay (time_2);
break;
case 9:
DDRB = B00011011;
PORTB = B00000100;
delayMicroseconds (time_3);
DDRB = B00000001;
delay (time_2);
break;
}
switch (in2_) {
case 0:
DDRB = B00001111;
PORTB = B00010001;
delayMicroseconds (time_3);
DDRB = B00000001;
delay (time_2);
break;
case 1:
DDRB = B00000111;
PORTB = B00000111;
delay (time_2);
break;
case 2:
DDRB = B00011111;
PORTB = B00000011;
delayMicroseconds (time_3);
DDRB = B00010011;
PORTB = B00010011;
delay (time_2);
break;
case 3:
DDRB = B00011011;
PORTB = B00000111;
delayMicroseconds (time_3);
DDRB = B00000011;
delay (time_2);
break;
case 4:
DDRB = B00010101;
PORTB = B00001111;
delayMicroseconds (time_3);
DDRB = B00000101;
delay (time_2);
break;
case 5:
DDRB = B00011011;
PORTB = B00001101;
delayMicroseconds (time_3);
DDRB = B00001001;
delay (time_2);
break;
case 6:
DDRB = B00011111;
PORTB = B00001001;
delayMicroseconds (time_3);
DDRB = B00001001;
delay (time_2);
break;
case 7:
DDRB = B00001111;
PORTB = B00010111;
delayMicroseconds (time_3);
DDRB = B00000111;
delay (time_2);
break;
case 8:
DDRB = B00011111;
PORTB = B00000001;
delayMicroseconds (time_3);
DDRB = B00000001;
delay (time_2);
break;
case 9:
DDRB = B00011011;
PORTB = B00000101;
delayMicroseconds (time_3);
DDRB = B00000001;
delay (time_2);
break;
}
DDRB = B00011111;//пауза между отображениями
PORTB = B00011110;
delay (5);
}
Опыт показывает, что показания индикатора можно уменьшать аж до 21, только потом МК переходит в режим сброса, и начинает работать при возврате примерно до 25 и выше. Так что можно сделать очень неправильный «показометр» для индикации напряжения от 25 до 99 вольт, естественно, с делителем на измерительном входе.
Теперь о практическом применении. Изначальная идея отображать данные с датчика расстояния отложилась до лучших времён из-за нехватки одного цифрового входа. Для чего ещё можно применить схему, пока идеи не приходят. Ещё нюанс: ни о какой экономичности не может быть и речи. Даже если погасить все сегменты, через резистор R2 (по первой схеме) будет протекать ток 2,5 мА, в сумме 10 мА на индикатор, плюс управление транзистором добавляет ещё около 5 мА. Я не упомянул, транзистор практически любой p-n-p современный.
О целесообразности. Самый дешёвый вариант вывода на семисегментник- ATtiny13 плюс 74HC595. Два SMD корпуса обойдутся мне примерно в 0,50 у.е. Самый простой- ATmega8 (и всё, ни резисторов, ничего больше), это 0,68 у.е. И описанный выше вариант- стоимость ATtiny, 9 резисторов, 4 светодиода, транзистор (всё SMD)- это около 0,46 у.е., правда поштучно всё дороже в разы. К тому же собрать всё в кучу сложней, чем в предыдущих вариантах.
Собственно, единственный вариант, что я вижу,- это если у вас полно ATtiny13, а за ATmega ещё в магазин ехать нужно. Ну и, если семисегментный индикатор является главным украшением вашего устройства, я бы не советовал данную схему, отображение не идеально, в некоторых комбинациях слегка подсвечивают ненужные сегменты. Бывает, что индикация нужна изредка при настройке- тогда самое место.
В общем, несколько дней я потратил зря.
Кроме критики, жду предложений по улучшению кода и упрощению схемы. Или улучшению функциональности без усложнения. Больше всего меня интересует, как зажечь точку, это бы расширило область применения. А вот если бы ещё и освободить один вывод из 5 задействованных, то можно было бы разгуляться.
Буду рад, если моё нестандартное решение принесёт пользу кому нибудь, не сейчас, так когда-нибудь.
Let's block ads! (Why?)





































{kind=link}