Расцвет эпохи программируемых калькуляторов в нашей стране пришёлся на середину 80-х годов. Потом на смену относительно сытым и благополучным временам пришла эпоха бандитского капитализма, когда стране стало не до выпуска своей высокотехнологичной продукции бытового назначения, вот уже сменились поколения, но ностальгия по тем временам, когда мы бессонными ночами пытались сократить код программы хотя бы на пару байтов, чтобы уместить задуманную функцию, выискивали всё новые и новые недокументированные возможности, придумывая способы, как их можно использовать на практике, сочиняли целые циклы рассказов в качестве фона для наших игровых программ, не даёт забыть свой МК-61 со 105 байтами программной памяти. Поэтому хочу написать заметку о том, что собой представляли и как работали эти самые программируемые калькуляторы. Даже если эта тема сегодня периодически и поднимается, то не настолько часто, чтобы приесться уважаемому читателю, так что надеюсь поведать что-то новое.
Немного истории

Для начала небольшой экскурс в историю. Программируемый калькулятор отличается от инженерного возможностью задать пользовательскую программу вычислений, имеет увеличенную память и набор операций для управления ходом исполнения программы, т. е. по сути является примитивным портативным компьютером. Отечественные программируемые калькуляторы (ПМК) принято делить на поколения. Первый массовый советский карманный ПМК, получивший обозначение Б3-21, увидел свет в 1977 году, он имел 60 шагов программной памяти, два операционных регистра X и Y, семь регистров памяти, а также двунаправленный кольцевой стек на шесть чисел (объединённый с X, который выводился на индикатор). Вычисления на нём производились в формате обратной (постфиксной) бесскобочной записи, т. е. сперва в операционный стек помещались операнды, затем над ними производилась операция, — это позволяло значительно упростить как сам калькулятор, так иногда и работу с ним. На базе этого ПМК строилось их первое поколение, к нему относятся, например, настольные варианты МК-46 и МК-64. Несмотря на очевидные недостатки, прежде всего заоблачную цену (350 рублей на момент появления в продаже), появление первых ПМК значительно упростило жизнь людям, имеющим дело со сложными вычислениями.
На смену им пришли «ПМК расширяющегося ряда», про них и пойдёт речь в этой статье. Это поколение в 1980 году начал калькулятор Б3-34, он получил новый процессор из серии К145ИК13 (на его базе также создавались и некоторые инженерные калькуляторы). Он по-прежнему работал в обратной бесскобочной нотации, но зато у него появилось место под 98 шагов программы, 14 регистров памяти и стек из 4 ячеек (плюс дополнительный регистр предыдущего результата), была добавлена косвенная адресация и циклы со счётчиком. Этот ПМК содержит два упомянутых процессора с разной прошивкой: один — как управляющее устройство, другой — как математический сопроцессор. Вместе с двумя микросхемами памяти К145ИР2 они соединены однобитной шиной (магистралью) в кольцо, получая сигналы синхронизации от тактового генератора К145ГФ3.
Наконец, в 1984 году был выпущен МК-61. Получив корпус калькулятора из семейства Б3-34 — МК-54, он получил дополнительный, третий процессор — К745ИК1306. Таким образом у нового устройства появились дополнительные функции (модуль, целая и дробная часть, знак числа и другое), семь дополнительных шагов программной памяти — теперь их стало 105, и ещё один регистр. Стоил он 85 рублей — цена внушительная, но при необходимости подъёмная. Именно эта машинка стала самым массовым и популярным ПМК в нашей стране. В следующем году был выпущен МК-61 с энергонезависимой памятью (ППЗУ) объёмом 512 байтов и возможностью подключения блоков расширения памяти с прошитыми в них библиотеками программ (выпускались централизованно) — МК-52.
Следующее поколение представлено микрокомпьютером МК-85 и его «сородичами». С одной стороны это был качественный скачок вперёд, с другой — это были калькуляторы со встроенным интерпретатором морально устаревшего и даже не русифицированного языка BASIC и 16-битным процессором с системой команд компьютеров американской фирмы DEC. С развалом страны и их производство сошло на нет, на этом история отечественных программируемых калькуляторов заканчивается…
Значимость и продолжение истории
Но семейство Б3-34 прочно закрепилось в быту советского человека. До массового распространения персональных компьютеров оставалось ждать пару десятилетий, да и счастливчикам, ставшим обладателями такового ещё тогда, в карман всё равно его было не положить. А ПМК были относительно доступны и практичны, поэтому и обрели заслуженное уважение наших людей. Я бы даже назвал народную любовь к ПМК социально-культурным явлением. Пользовались этими приборами, казалось бы, сугубо инженерного назначения, все категории граждан: от школьников младших классов до пенсионеров преклонных лет, мужчины и женщины самых разнообразных профессий, со всех концов нашей страны — от Западной Украины до Чукотки и от Кольского полуострова до Средней Азии. Весьма полезными ПМК были и для студентов (прежде всего инженерных специальностей) с интеллектом выше среднего, но поскольку дефицит таковых начал наблюдаться уже тогда, основным контингентом пользователей было всё же взрослое население.
Трудно найти сферу человеческой деятельности, где не был применён наш микрокалькулятор. Нужно подсчитать параметры статистического ряда или определить рентабельность производства? Рассчитать параметры электрической цепи, вычислить молярную массу вещества, найти радиус чёрной дыры? Легко. Смоделировать манёвры боевого самолёта, рассчитать курс морского судна или сориентировать орбитальный корабль? Пожалуйста. Известно, например, что МК-52 реально использовался штурманами военно-морского флота, а также, в качестве запасного вычислительного устройства, космонавтами. Выбрать класс трактора или оценить параметры почвы, определить генетическое расстояние между популяциями, рассчитать пропорции в кулинарии, дозу или концентрацию лекарства, сгенерировать узор для вязания? Всё есть. Увлекаетесь нумерологией, биоритмами и прочей лженаукой? Найдутся и для вас программки.
А игры, которые создавались сотнями и целыми сериями с сюжетом, — это вообще отдельная тема. Было всё: от крестиков-ноликов и мини-шашек до симуляций исторических сражений и экономики государства. Были изданы десятки книг, сборников программ, рецептов программирования. В популярнейших журналах, издававшихся многомиллионными тиражами, таких как «Наука и жизнь», «Техника — молодёжи» и др., регулярно печатались рубрики, посвящённые ПМК. Отдельно очень активно шло изучение недокументированных возможностей калькуляторов этой серии, особенностей реализованных функций и т. п., получившее название «еггогология» — от слова, которым обозначалась ошибка при вычислениях, — «ЕГГОГ». Рассматривались также способы аппаратной модификации устройств.
Сегодня об этой занятной науке можно прочитать лишь в отсканированных журналах, например в библиотеке сайта Сергея Тарасова, посвящённого ПМК. Очень рекомендую тем, кто желает погрузиться в атмосферу тех лет. А на сайте Евгения Века собрано более 250 авторских игровых программ — подборка даёт хорошее представление об игровом движении калькуляторщиков и о самом явлении.
Хотя с развалом страны и прекращением выпуска новых моделей калькуляторов интерес к теме в народе стал резко падать, народные умельцы всё же не сидели без дела. В 2003 году программист Евгений Троицкий разработал симулятор отечественных калькуляторов «Калькуляторы 3000» — арифметических, инженерных и программируемых — наверное, единственный в своём роде с таким охватом и точностью симуляции. А «в железе» на это всё можно посмотреть на сайте музея вычислительной техники Сергея Фролова.
Писались статьи, сканировались печатные материалы, принимались и другие попытки воссоздать калькуляторы программно, переводилась на иностранные языки документация. Причём не только русские люди не дают нашим калькуляторам бесследно раствориться в прошлом. Вот, например, очень примечательные случаи: француз Гийом сравнивает быстродействие МК-61 и МК-52 и пишет транслятор BASIC-подобного языка в код ПМК, голландец Альфред исследует недокументированные особенности МК-61 и возможности «синтетического программирования» калькулятора, а канадец Виктор тестирует и сравнивает МК-61 с другими калькуляторами из своей коллекции.
Кто-то даже пытается заработать на приятных воспоминаниях. Так, новосибирская фирма «Семико» собрала из китайских запчастей пару калькуляторов, назвав их в честь отечественных МК-61 и МК-52 и снабдив похожим языком. Понятно, что дальше продвижения на Интернет-помойках вроде Википедии дело не пошло, и рынок ожидаемо проигнорировал это начинание.
И вот в 2012 году инженер из США Феликс Лазарев, вооружившись профессиональным микроскопом, смог при участии Евгения Троицкого и других энтузиастов проанализировать и восстановить содержимое ПЗУ микросхем процессоров МК-61. Так были созданы первые эмуляторы калькуляторов серии Б3-34 (за исключением МК-52, у которого не была отсканирована микросхема, управляющая энергонезависимой памятью).
Вскоре с использованием восстановленного кода был написан эмулятор МК-61 на JavaScript. Сегодня это, по всей видимости, наиболее функциональный и удобный эмулятор из всех. Не требуя скачивания и установки, он позволяет работать как с самим МК-61, так и с калькуляторами-аналогами Б3-34 (без третьего процессора), а также с такими устройствами, как арифмометр «Феликс-М», логарифмическая линейка «НЛ-10М» и русские счёты. Во время работы калькулятора на экране показывается содержимое всех регистров памяти, операционного стека, адресов возврата из подпрограмм и счётчика команд в режиме реального времени. Имеется возможность скопировать и ввести сохранённое состояние или поставить исполнение на паузу. Важной функцией является возможность ввести и прочитать код программы, используя общепринятые мнемоники команд в различных вариантах, т. е. теперь можно просто скопировать код программы, вставить в эмулятор и запустить, не вводя его вручную.
Работа на калькуляторе

Думаю, многим, кого заинтересовала эта тема, захочется опробовать на практике, «на ощупь» этот самый калькулятор. Так что давайте теперь посмотрим, как собственно работать на этих машинках.
Впервые добравшись до МК-61, человек, знакомый с традиционными арифметическими и инженерными калькуляторами, обычно задаётся вопросом: где здесь кнопка «=» или скобки? Попробуем разобраться. Итак, для начала калькулятор нужно включить. В верхней его части находится индикатор, на котором отображается число, с которым в данный момент работает калькулятор. Он также работает и с другими числами, расположенными в ячейках памяти, называемых регистрами, но обычно результат вводится и выводится на индикатор, значение которого также находится в регистре, обозначаемом X. Слева под индикатором находится переключатель, подписанный справа «Вкл», — включаем, на индикаторе загорится «0». Число набирается традиционно, при помощи цифровых кнопок. Можно также ввести дробное число посредством кнопки десятичной запятой (справа от кнопки «0»), поменять его знак («/−/») и ввести порядок («ВП»). Например, нужно ввести число −0,00000123 — для этого последовательно нажимаем: «[1] [2] [3] /−/ ВП [8] /−/».
Как же тут выполнять арифметические операции? Чтобы понять это, необходимо ознакомиться с таким понятием, как операционный стек. Стек нашего калькулятора — это просто четыре регистра, связанные между собой порядком помещения и извлечения из них чисел. Он подобен стопке, колоде карт: верхняя карта (в нашем случае число) лежит в регистре X и отображается на индикаторе. Когда мы кладём число в эту стопку, остальные числа оказываются глубже (под ним), а оно перед нами, на индикаторе. В нашем распоряжении находятся четыре регистра стека (и один дополнительный, в него помещается результат предыдущей операции), обозначаемые буквами X, Y, Z, T (и X1), мы можем производить с ним определённые операции. Вводимое с клавиатуры число оказывается в регистре X. Его можно поднять (скопировать) в следующий за ним регистр Y, при этом содержимое Y переместится в Z, содержимое Z — в T (предыдущее значение T сотрётся). Стек можно вращать, при этом X перемещается в T, T — в Z и т. д. Подъём или спуск значений происходит и при выполнении некоторых действий.
Тут дело в том, что калькулятор, как уже было сказано ранее, принимает выражения в бесскобочной постфиксной нотации, т. е. не в традиционной форме «a + b =», а в форме «a b +», т. е. сначала вводятся числа, после производится операция. А вводятся числа как раз в этот самый стек. Введя число в регистр X, его нужно поднять в Y, для этого используется кнопка [В↑]. После этого можно начинать вводить следующее число, предыдущее значение X при этом сотрётся.
Операции над числами делятся на двухместные (с двумя аргументами: сложение, вычитание, возведение в степень и т. д.) и одноместные (над одним числом: корень, тригонометрия, логарифмы и т. д.). Двухместные операции производятся над регистрами X и Y. Для примера сложим два числа: «[1] [В↑] [2] [+]». Здесь в X вводится число 1, поднимается в Y, в X вводится число 2, после чего Y и X складываются, результат — на индикаторе (в X). При этом значения стека спускаются: T обнуляется, предыдущее значение T перемещается в Z, Z — в Y, в X1 — предыдущее значение X (т. е. 2). В случае с вычитанием выполняется операция (аналогично с делением). Для доступа к функциям, обозначения которых нанесены над кнопками, используются кнопки [F] и [K] соответственно цвету, которым написано обозначение функции. Например, для вычисления натурального логарифма числа нужно нажать «[F] [2]» (над кнопкой «2» находится обозначение «ln»).
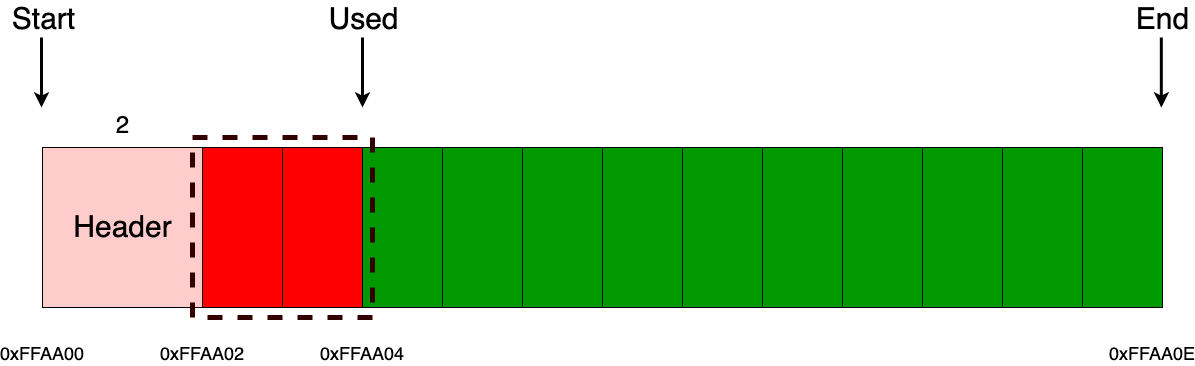
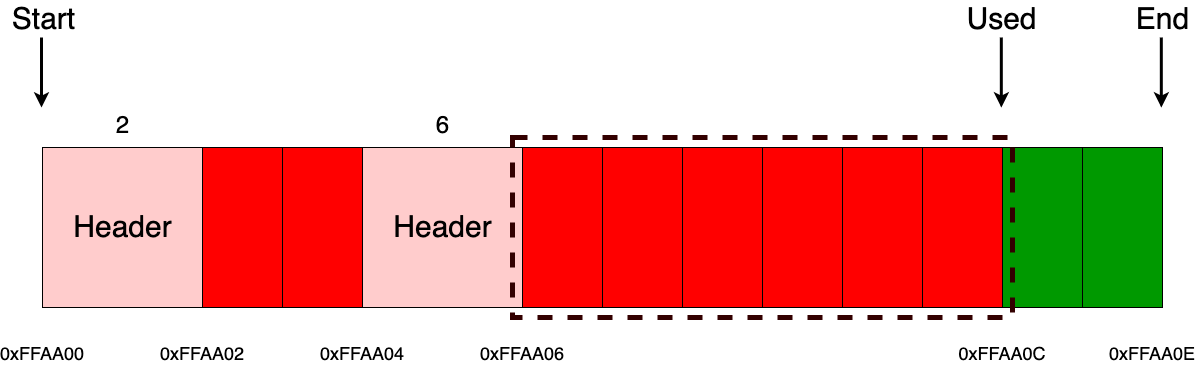
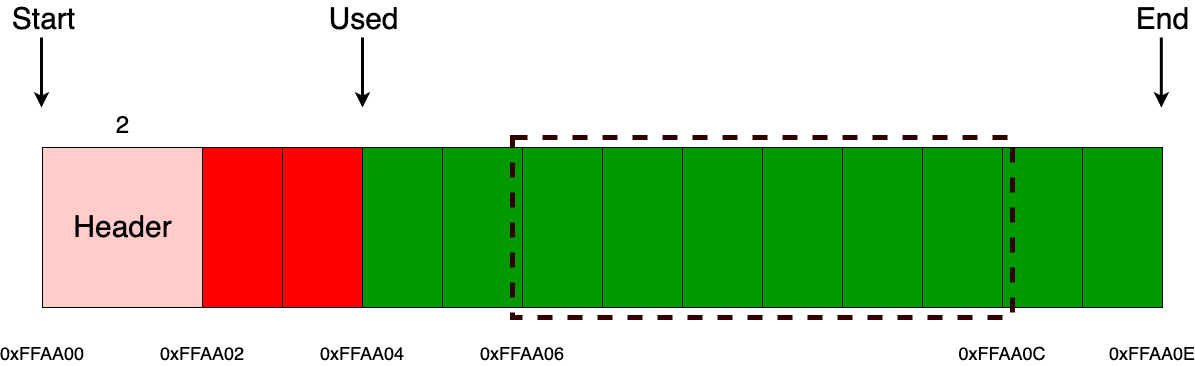
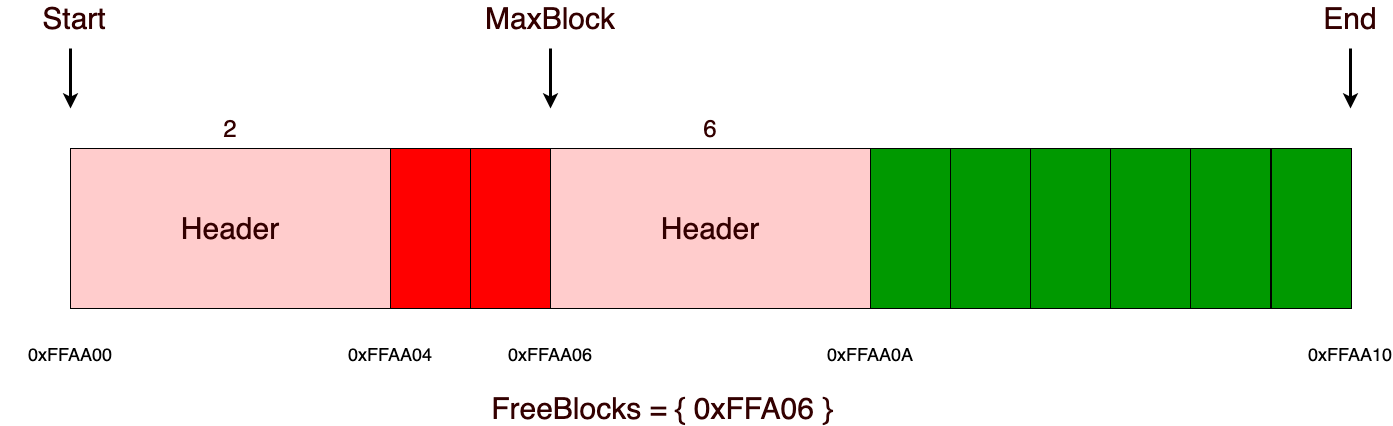
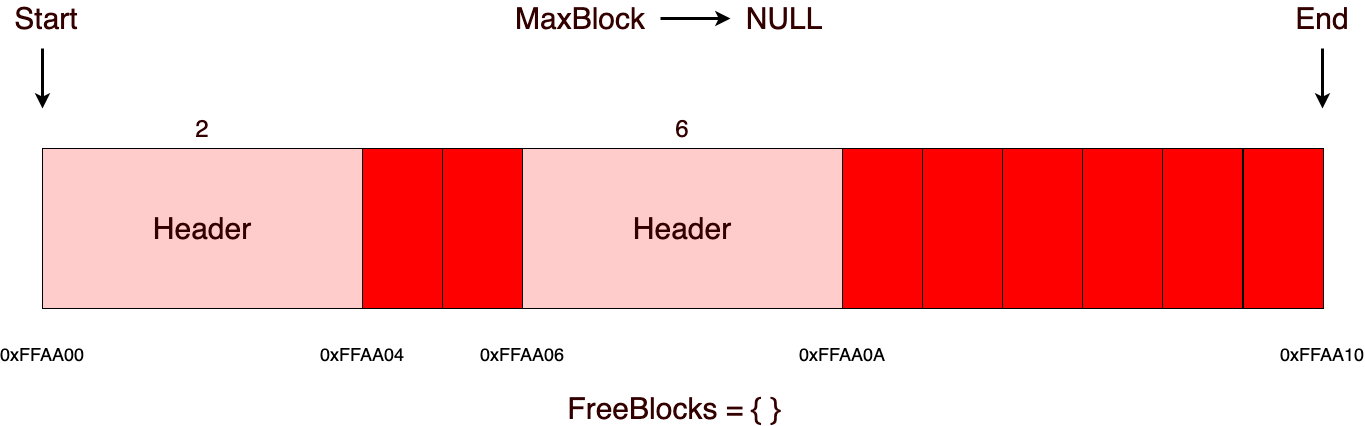
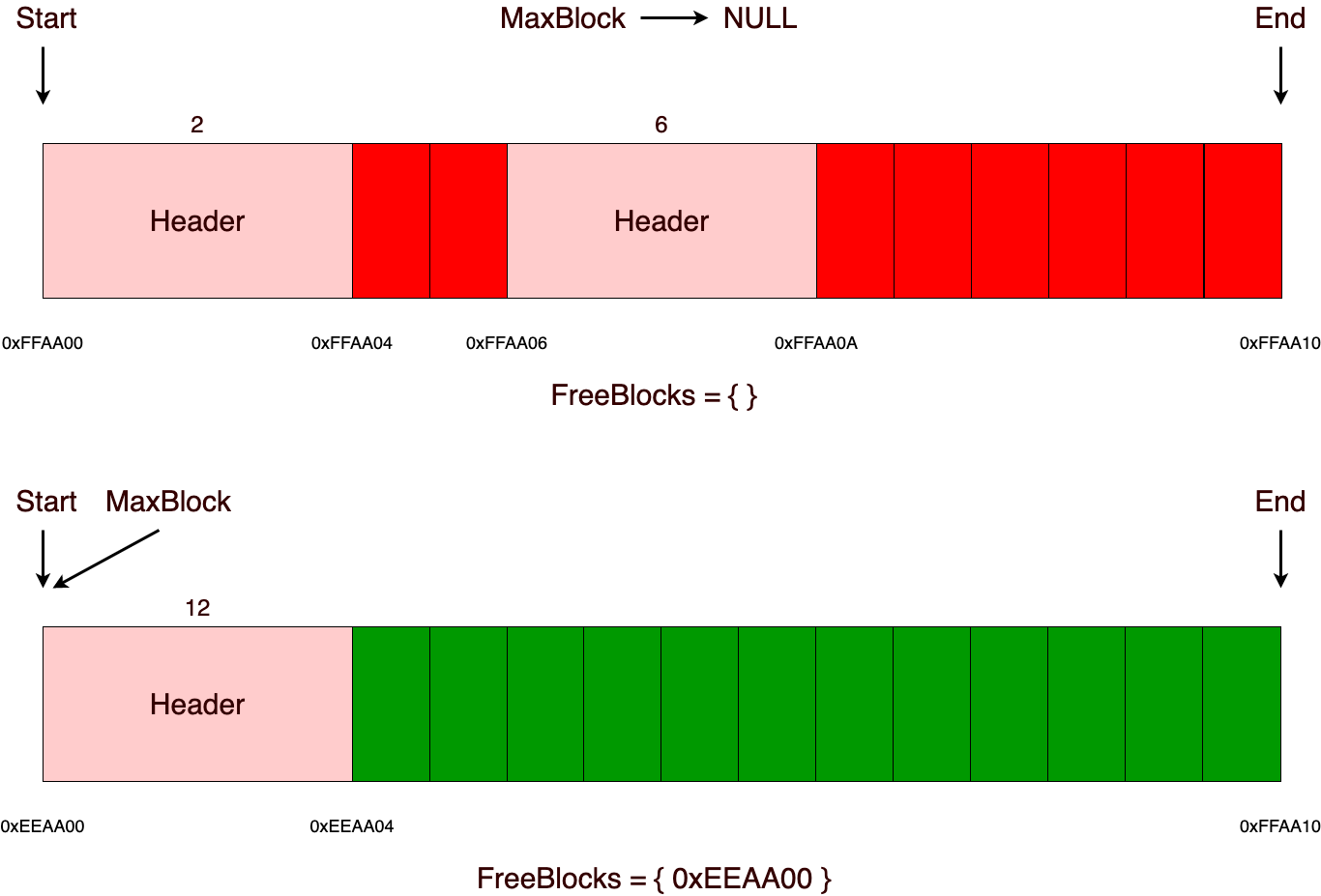
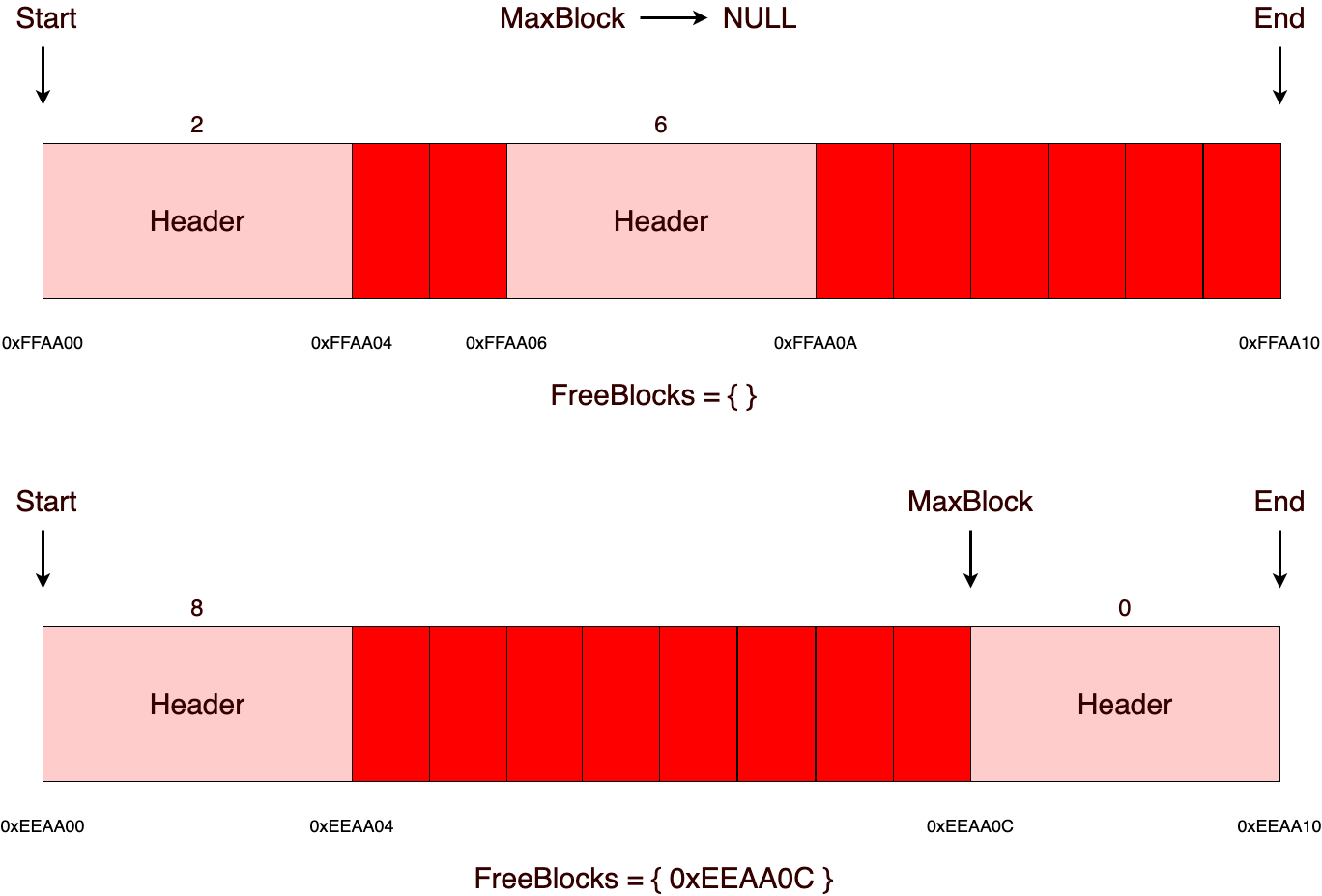
В качестве основной памяти в МК-61 используется 15 регистров общего назначения. Они обозначаются цифрами от 0 до 9 и буквами от A до E (10—15). Для помещения числа в один из регистров используется кнопка «X→П», после нажатия которой нужно нажать соответствующую номеру регистра кнопку на цифровой клавиатуре или кнопку, подписанную нужной буквой снизу/справа от неё. Аналогичным образом число извлекается из регистра посредством кнопки «П→X». При работе на калькуляторе для хранения промежуточных данных зачастую используется стек. При этом необходимо следить, чтобы сохранённое значение не было стёрто в процессе вычислений. В МК-61 существует также косвенная адресация регистров. Так, например, если поместить в регистр №7 число 8, то при помощи последовательного нажатия «[K] [П→X] [7]» на индикаторе появится содержимое регистра №8. Здесь необходимо отметить, что при косвенном обращении через регистры 0—3 ихнее значение предварительно уменьшается на единицу, а через 4—6 — увеличивается. Т. е. если в Р4 было 5, то «[K] [П→X] [4]» выдаст число из Р6.
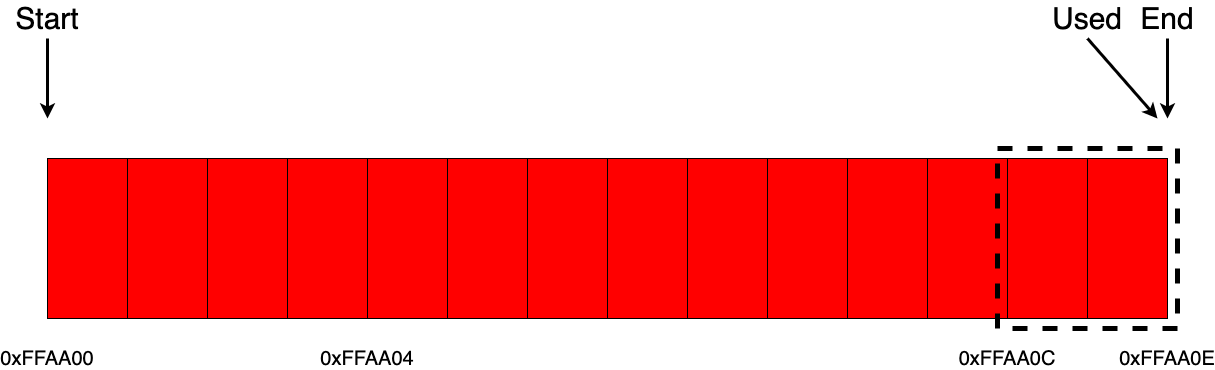
Теперь посмотрим, как вводятся и исполняются программы. Для запуска режима ввода программы необходимо нажать последовательность кнопок «[F] [ВП]» («ПРГ»). Далее вводится программа, аналогично тому, как производятся вычисления в ручном режиме. В правой части индикатора отображается счётчик команд, текущее его значение показывает адрес, по которому будет размещена вводимая инструкция (шаг программы). Максимальная длина программы — 105 шагов. При вводе программы на индикаторе отображаются три последних (предшествующих указываемому адресу) кода инструкции.
Напишем для примера программу, которая умножит вводимое число на 3, прибавит к нему 4 и возведёт полученное значение в квадрат. Для этого последовательно нажимаем: «[В↑] [3] [×] [4] [+] [F] [×] [С/П]». В результате в программной памяти окажется программа: «↑ 3 × 4 + x2 С/П». При оформлении кода программы в текстовом виде указывается не непосредственно клавиша, которую необходимо нажать, а инструкция, которая будет выполнена: в нашем случае — не «F ×», а «x2». Команда «С/П» (стоп/пуск) останавливает выполнение программы.
Теперь выходим из режима программирования нажатием «[F] /−/» («АВТ»). Для запуска программы обнуляем счётчик шагов кнопкой «В/О» (возврат/очистка), вводим начальные данные, например, 5. Запускаем программу — «С/П». После выполнения на индикаторе 361.
Примеры программ
Рассмотрим пример программы, выполняющей реальные вычисления. Этот код вычисляет дату Пасхи по введённому номеру года:
П2 1 9 ПП 86 П3 ИП2 4 ПП 86
П4 ИП2 7 ПП 86 П5 1 9 ИП3 *
1 5 + 3 0 ПП 86 П6 2 ИП4
* 4 ИП5 * + 6 ИП6 * + 6
+ 7 ПП 86 ИП6 + П1 3 П4 ИП2
1 - 2 10^x / [x] ^ ^ 4 /
[x] - 2 0 + ИП1 + П3 3 1
- x>=0 76 П3 КИП4 ИП3 3 0 - x>=0
83 П3 КИП4 ИП3 ИП4 С/П П0 <-> П1 <->
/ [x] ИП0 * ИП1 - /-/ В/О
Чтобы не вводить его вручную, как на реальном устройстве, достаточно просто вставить его в эмуляторе в окошко «Код программы» и нажать кнопку «Ввести в память». Вводим на клавиатуре номер года, нажимаем «С/П» для запуска (если счётчик команд не обнулён, то обнуляем его, нажав перед запуском «В/О»). Примерно через 14 секунд получим результат: на индикаторе (в регистре X) будет номер месяца, в регистре Y — число месяца; нажимаем «⟷», чтобы обменять значения X и Y и увидеть номер дня.
Или вот такая программа, которая переводит числа в троичную симметричную систему счисления:
ЗН П2 Вx |x| П0 0 П3 П4 1 П5
ИП0 /-/ x<0 80 ИП0 ^ ^ 3 / [x]
П0 3 * - П1 ИП3 x#0 54 ИП1 x=0
38 ИП2 ПП 88 0 П3 БП 10 ИП1 1
- x=0 49 ИП2 /-/ ПП 88 БП 10 0
ПП 88 БП 10 ИП1 x=0 62 0 ПП 88
БП 10 ИП1 1 - x=0 72 ИП2 ПП 88
БП 10 ИП2 /-/ ПП 88 1 П3 БП 10
ИП3 x#0 86 ИП2 ПП 88 ИП4 С/П 8 +
ИП5 * ИП4 + П4 ИП5 1 0 * П5
В/О
Вводим число, выполняем — на экране результат. При этом -1, 0 и 1 обозначаются соответственно цифрами 7, 8 и 9. Например, введя 123, получим 977778, т. е. «+----0». Особенно забавно, что такой код, показанный нынешним «кодерам-прогерам» с дипломами ЕГЭ-бакалавров, ввергает их в ступор и экзистенциальный ужас (проверено не раз), не говоря уже о предложении написать что-то самим. Но это далеко не самое сложное, что есть в этих калькуляторах. Попробуем же понять их внутреннее устройство, используя для этого JS-код эмулятора.
Внутреннее устройство
В 1990 году Ярослав Карпович Трохименко выпустил книгу «Программируемые микрокалькуляторы: устройство и пользование», в которой досконально описал работу ПМК «расширяющегося ряда» на всех уровнях организации, аппаратных и программных. Хотя там и не был напечатан весь код ПЗУ калькуляторных процессоров, это сократило путь к программному воспроизведению устройств в разы и дало первые объяснения глубинным причинам эффектов «еггогологии».
Итак, как уже было сказано выше, МК-61 работает под управлением трёх процессоров К745ИК13, отличающихся только прошивкой (серия К745 — бескорпусные варианты К145). Они соединены однобитной шиной, реализующей последовательное соединение процессоров вместе с микросхемами оперативной памяти К745ИР2 в кольцо. Графически схему калькулятора можно изобразить так:
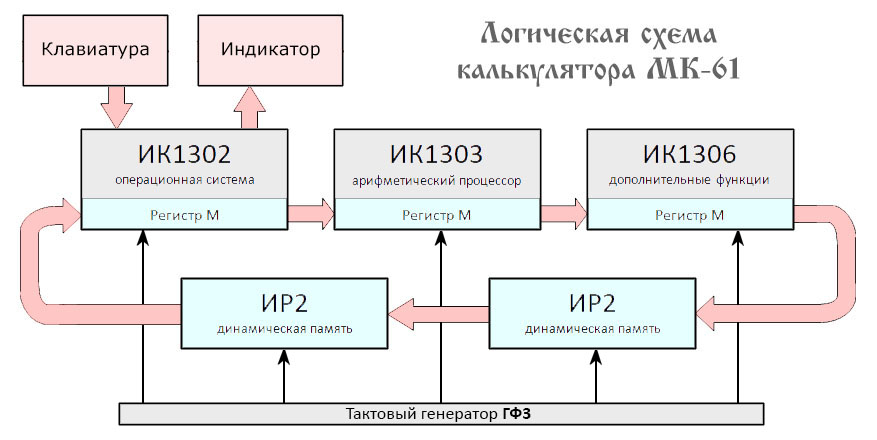
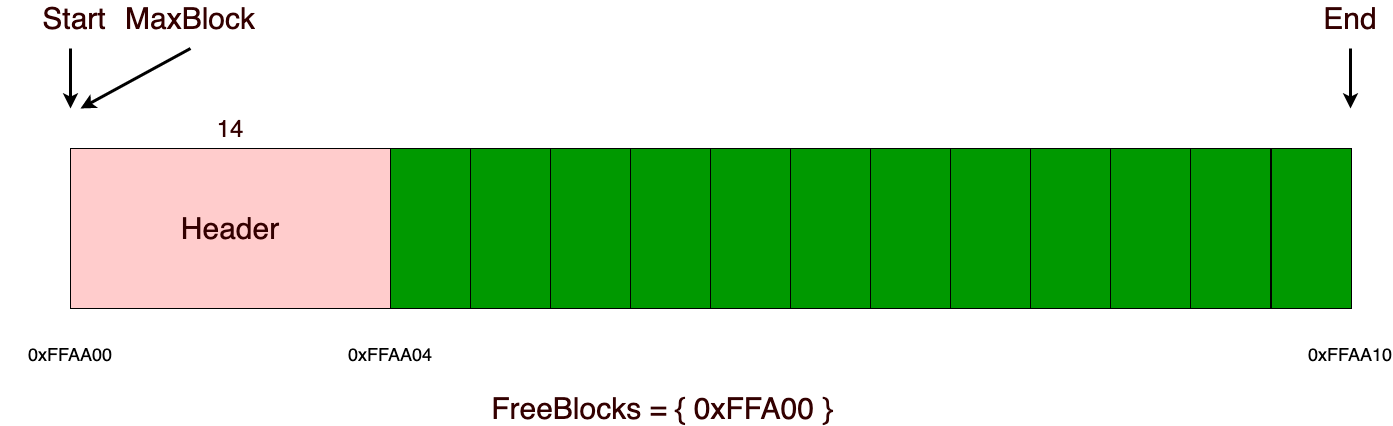
Процессор ИК13 оперирует 4-битными словами. Его динамическая память представлена тремя регистрами M, R и ST объёмом 42 слова каждый, а также регистрами S и S1 размером в одно слово и однобитными ячейками L, T и П. Кроме того, в коде эмулятора имеются переменные для реализации взаимодействия между процессорами, памятью, индикатором, клавиатурой и для сохранения предыдущего состояния.
Память ПЗУ процессора состоит из 256 команд по 23 бита, 128 синхропрограмм, являющихся массивами из девяти шестибитных ячеек, и 68 микрокоманд по 28 битов. Каждая команда содержит три адреса синхропрограмм; ячейки синхропрограммы являются адресами микрокоманд; а биты микрокоманды определяют, какие элементарные операции необходимо выполнить на текущем такте процессора. За один такт выполняется одна микрокоманда и по системной магистрали прогоняется одна тетрада битов, а за 42 такта выполняется одна команда.
constructor(ПЗУ) {
[this.ПЗУ_микрокоманд, this.ПЗУ_синхропрограмм, this.ПЗУ_команд] =
[ПЗУ.микрокоманды, ПЗУ.синхропрограммы, ПЗУ.команды];
this.Сброс();
}
Сброс() {
[this.M, this.R, this.ST] =
[new Array(42).fill(0), new Array(42).fill(0), new Array(42).fill(0)];
[
this.S, this.S1, this.L, this.T, this.П,
this.такт, this.команда, this.АСП,
this.вход, this.выход,
this.клав_x, this.клав_y
] = new Array(12).fill(0);
this.запятые = new Array(14).fill(false);
this.обновить_индикатор = false;
}
Выбор микрокоманды для текущего такта
На первом из 42-х такте определяем адрес новой команды, которую мы начинаем исполнять, взяв 4-битное слово из регистра R по адресу 36 в качестве младших разрядов и по адресу 39 в качестве старших, и берём эту команду из кода ПЗУ. Сама команда состоит из трёх адресов синхропрограмм, под которые отведено дважды по 7 битов и третий раз — 8, а также флага, влияющего на выполнение определённой части микрокоманды. Если биты третьего адреса с третьего по последний равны нулю, то обнуляем ячейку T.
if (this.такт == 0) {
this.команда = this.ПЗУ_команд[this.R[36] + 16 * this.R[39]];
if ((this.команда >>> 16 & 0b111111) == 0) this.T = 0;
}
Определяем, к какой девятке (по порядку) относится номер такта и какое место в ней занимает. Девятка тактов определяет, какой адрес синхропрограммы, записанный в команде, использовать.
const
девятка_тактов = this.такт / 9 | 0,
такт_в_девятке = this.такт - девятка_тактов * 9;
Если это первый такт в девятках с номерами 0, 3 или 4, то следует установить синхропрограмму. Если номер такта относится к первым трём девяткам, то адрес синхропрограммы составляют первые 7 битов команды; если к четвёртой, то вторые 7 битов. А если же к пятой, то берём третьи 8 битов, но в случае, если адрес синхропрограммы больше 31, на первом такте пятой девятки помещаем в регистр R по адресу 37 младшие 4 бита адреса, по адресу 40 — старшие, сам же адрес заменяем на 95 (на любом такте). Таким образом имеется возможность передать два слова в память непосредственно из команды (поэтому поле этого адреса сделано длиннее).
if (такт_в_девятке == 0 && !(девятка_тактов > 0 && девятка_тактов < 3)) {
if (девятка_тактов < 3)
this.АСП = this.команда & 0b1111111;
else if (девятка_тактов == 3)
this.АСП = this.команда >>> 7 & 0b1111111;
else if (девятка_тактов == 4) {
this.АСП = this.команда >>> 14 & 0b11111111;
if (this.АСП > 31) {
if (this.такт == 36) {
this.R[37] = this.АСП & 0b1111;
this.R[40] = this.АСП >>> 4;
}
this.АСП = 95;
}
}
}
Определяем адрес микрокоманды, записанный в синхропрограмме. Последняя представляет собой последовательность из 9 адресов микрокоманд, но в массиве они записаны раздельно. Поэтому умножаем вычисленный адрес синхропрограммы на 9, получив индекс её первого элемента, и добавляем к нему значение по следующему правилу: если номер такта — от 0 до 5, то используем его, если от 6 до 20, то берём остаток от деления его на 3, прибавив к нему 3, а если от от 21 до 41, то номер такта в девятке.
let АМК = this.ПЗУ_синхропрограмм[
this.АСП * 9 +
(this.такт < 6 ? this.такт : this.такт < 21 ? this.такт % 3 + 3 : такт_в_девятке)
];
На всякий случай отсекаем биты старше 6-го (в коде эмулятора все остальные данные из ПЗУ используются только по частям, что позволяет не беспокоиться о некорректных данных), и если адрес микрокоманды — от 60 до 63, то реализуем условный выбор в зависимости от состояния ячейки L: для значения 0 — чётные номера больше 60, для 1 — нечётные. Таким образом, хоть адрес микрокоманды и 6-битный, но самих микрокоманд 68.
АМК &= 0b111111;
if (АМК > 59) {
АМК = (АМК - 60) * 2;
if (this.L == 0) АМК++;
АМК += 60;
}
Вытаскиваем микрокоманду из кода ПЗУ и разбираем её на массив однобитных микроприказов (флагов), которые далее составляют поля микрокоманды — либо поодиночке, либо в совместно, определяя номер выполняемого действия.
let микрокоманда = this.ПЗУ_микрокоманд[АМК], микроприказы = [];
for (let сч = 0; сч < 28; сч++) {
микроприказы.push(микрокоманда & 1);
микрокоманда >>>= 1;
}
Сумматор и клавиатура
На этот раз определяем, к какой уже тройке по порядку относится номер такта и создаём объект сумматора с параметрами α, β, γ и полем суммы Σ. Далее, если микроприказ с номером 25 установлен в 1, используем данные с клавиатуры — параметры x и y, особенные для каждой кнопки (x также используется для передачи меры угла): если следующая за текущей тройка тактов не равна x, то выполняем побитовую дизъюнкцию ячейки S1 с y. После этого проходим по первым 12 микроприказам, выполняя их, если они установлены.
const тройка_тактов = this.такт / 3 | 0;
const сумматор = { альфа: 0, бета: 0, гамма: 0, сигма: 0 };
if (микроприказы[25] == 1 && тройка_тактов != this.клав_x - 1)
this.S1 |= this.клав_y;
for (let сч = 0; сч < 12; сч++)
if (микроприказы[сч] == 1)
this.Выполнить_микроприказ(сч, сумматор);
После этого снова работаем с клавиатурой. Если хотя бы один из битов команды с номерами 18—23 установлен в 1 и y кнопки равен нулю, то обнуляем T. Если же все упомянутые биты нулевые, то устанавливаем значение в массиве запятых на индикаторе равным L, флаг необходимости обновления индикатора, и если при этом следующая тройка тактов равна x, а y больше 0, то записываем y в S1, а в Т — 1. Затем выполняем при необходимости микроприказы с 12, 13 и 14.
if ((this.команда >>> 16 & 0b111111) > 0) {
if (this.клав_y == 0) this.T = 0;
}
else {
if (тройка_тактов == this.клав_x - 1 && this.клав_y > 0) {
this.S1 = this.клав_y;
this.T = 1;
}
this.запятые[тройка_тактов] = this.L > 0;
this.обновить_индикатор = true;
}
for (let сч = 12; сч < 15; сч++)
if (микроприказы[сч] == 1)
this.Выполнить_микроприказ(сч, сумматор);
Теперь складываем входы сумматора, от суммы берём младших 4 бита и кладём в Σ, а 5-й бит (флаг переноса) — в П.
const сумма = сумматор.альфа + сумматор.бета + сумматор.гамма;
сумматор.сигма = сумма & 0b1111;
this.П = сумма >>> 4 & 1;
Поля микрокоманды
Если последний бит команды равен 0 или это последняя девятка тактов (точнее говоря, их в ней всего 6), то определяем значение следующего поля микрокоманды из битов 15, 16 и 17 (в порядке возрастания старшинства). Если полученное значение не равно нулю, то выполняем микроприказ с номером, равным этому полю, увеличенным на 14 (количество уже обработанных микроприказов). Последнее приходится учитывать, поскольку действий предусмотрено 35, а битов в микрокоманде — всего 28, т. е. некоторые биты группируются в поля. При том же условии относительно номера такта или битов 24—31 проходим по микроприказам 18 и 19 (действие определяется номером, увеличенным на четыре — 7 предусмотренных тремя битами действий минус 3 битовых места в микрокоманде).
if ((this.команда >>> 22 & 1) == 0 || девятка_тактов == 4) {
const поле_микрокоманды =
микроприказы[17] << 2 |
микроприказы[16] << 1 |
микроприказы[15];
if (поле_микрокоманды > 0)
this.Выполнить_микроприказ(поле_микрокоманды + 14, сумматор);
for (let сч = 18; сч < 20; сч++)
if (микроприказы[сч] == 1)
this.Выполнить_микроприказ(сч + 4, сумматор);
}
Проходим по микроприказам 20 и 21. Потом следуют три двухбитовых поля, определяющих, соответственно, по три действия (при нулевом значении поля ничего не делается).
for (let сч = 20; сч < 22; сч++)
if (микроприказы[сч] == 1)
this.Выполнить_микроприказ(сч + 4, сумматор);
for (let сч = 0; сч < 3; сч++) {
const поле_микрокоманды =
микроприказы[23 + сч * 2] << 1 |
микроприказы[22 + сч * 2];
if (поле_микрокоманды > 0)
this.Выполнить_микроприказ(поле_микрокоманды + 25 + сч * 3, сумматор);
}
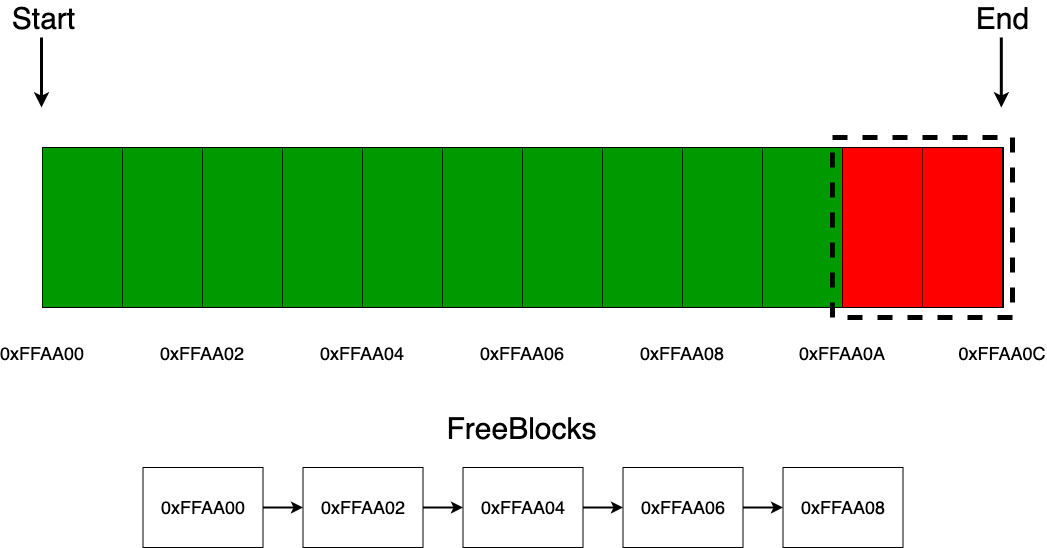
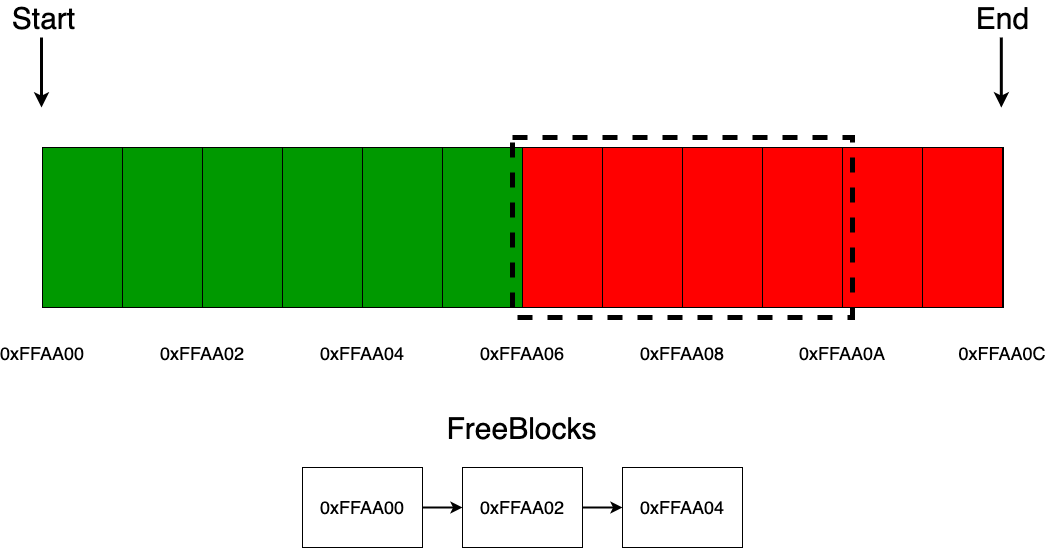
На выход микросхемы подаётся слово из регистра M, соответствующее номеру такта, после чего вместо него записывается слово, поступившее на вход. Такт увеличивается; если становится равным 42, то обнуляется, — приступаем к обработке следующей команды.
this.выход = this.M[this.такт];
this.M[this.такт] = this.вход;
this.такт++;
if (this.такт == 42) this.такт = 0;
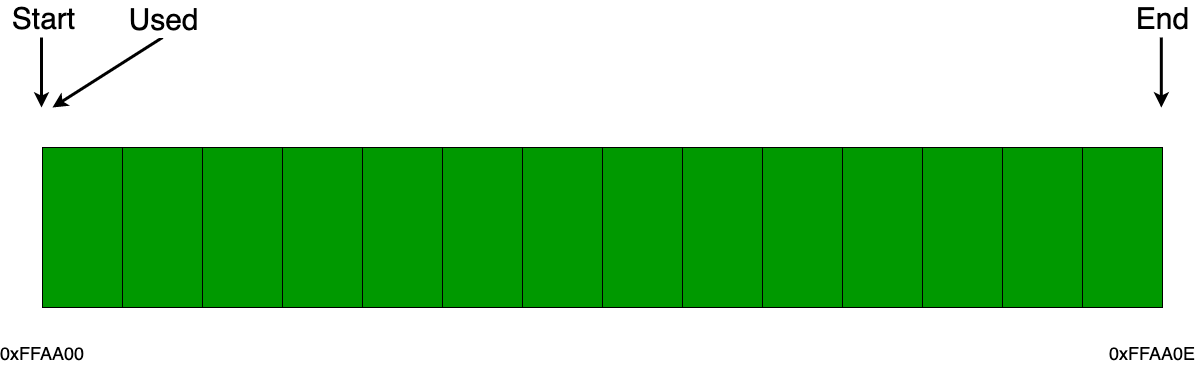
Последний фрагмент собственно составляет также содержание такта памяти ИР2, с той разницей что тактов там 252, как и число слов в единственном регистре M. После выполнения такта одного процессора значение ячейки выхода присваивается ячейке входа следующего процессора или памяти. Чтобы замкнуть кольцо на такте, который был обработан, после прохождения по всем элементам от ИК1302 до второго ИР2 значение выхода последнего передаётся в ячейку первого с номером обработанного только что такта. Память ИР2 вместе с регистрами процессоров ИК13 (не включая сверхоперативные ячейки) можно визуально изобразить так (положение на 84-м такте ИР2):

Микроприказы
А вот и содержание самих микроприказов. Здесь биты микрокоманды с номерами 0—6 влияют на вход сумматора α, 7—11 — на β, 12—14 — на γ. Влияние заключается в побитовой дизъюнкции имеющегося значения входа сумматора с некоторым значением (результат является новым значением входа). Выбор действия с номером от 15 до 21 задаётся трёхбитным полем микрокоманды с битами 15—17, а за действия 22 и 23 отвечают соответственно биты 18 и 19; это всё влияет на регистр R, на слово, задаваемое текущим номером такта, либо на одно из двух предшествующих ему. Предшествующие и следующие адреса берутся по модулю 42, т. е. предыдущим адресом для 0 является 41 (0 — следующим для 41). Биты 20 и 21 задают действия под номерами 24 и 25 соответственно — над регистром M и ячейкой L. Далее идут три двухбитовых поля, отвечающих каждое за три действия — над регистрами S, S1 и ST. В регистре ST операции производятся над тройкой слов, начинающейся с текущего номера такта.
Микроприказы
Выполнить_микроприказ(номер, сумматор) {
switch (номер) {
case 0: сумматор.альфа |= this.R[this.такт]; break;
case 1: сумматор.альфа |= this.M[this.такт]; break;
case 2: сумматор.альфа |= this.ST[this.такт]; break;
case 3: сумматор.альфа |= ~this.R[this.такт] & 0b1111; break;
case 4: if (this.L == 0) сумматор.альфа |= 0xA; break;
case 5: сумматор.альфа |= this.S; break;
case 6: сумматор.альфа |= 4; break;
case 7: сумматор.бета |= this.S; break;
case 8: сумматор.бета |= ~this.S & 0b1111; break;
case 9: сумматор.бета |= this.S1; break;
case 10: сумматор.бета |= 6; break;
case 11: сумматор.бета |= 1; break;
case 12: сумматор.гамма |= this.L & 1; break;
case 13: сумматор.гамма |= ~this.L & 1; break;
case 14: сумматор.гамма |= ~this.T & 1; break;
case 15: this.R[this.такт] = this.R[(this.такт + 3) % 42]; break;
case 16: this.R[this.такт] = сумматор.сигма; break;
case 17: this.R[this.такт] = this.S; break;
case 18: this.R[this.такт] = this.R[this.такт] | this.S | сумматор.сигма; break;
case 19: this.R[this.такт] = this.S | сумматор.сигма; break;
case 20: this.R[this.такт] = this.R[this.такт] | this.S; break;
case 21: this.R[this.такт] = this.R[this.такт] | сумматор.сигма; break;
case 22: this.R[(this.такт + 41) % 42] = сумматор.сигма; break;
case 23: this.R[(this.такт + 40) % 42] = сумматор.сигма; break;
case 24: this.M[this.такт] = this.S; break;
case 25: this.L = this.П; break;
case 26: this.S = this.S1; break;
case 27: this.S = сумматор.сигма; break;
case 28: this.S = this.S1 | сумматор.сигма; break;
case 29: this.S1 = сумматор.сигма; break;
case 30: this.S1 = this.S1; break;
case 31: this.S1 = this.S1 | сумматор.сигма; break;
case 32:
this.ST[(this.такт + 2) % 42] = this.ST[(this.такт + 1) % 42];
this.ST[(this.такт + 1) % 42] = this.ST[this.такт];
this.ST[this.такт] = сумматор.сигма;
break;
case 33: {
const x = this.ST[this.такт];
this.ST[this.такт] = this.ST[(this.такт + 1) % 42];
this.ST[(this.такт + 1) % 42] = this.ST[(this.такт + 2) % 42];
this.ST[(this.такт + 2) % 42] = x;
} break;
case 34: {
const
x = this.ST[this.такт],
y = this.ST[(this.такт + 1) % 42],
z = this.ST[(this.такт + 2) % 42];
this.ST[this.такт] = сумматор.сигма | y;
this.ST[(this.такт + 1) % 42] = x | z;
this.ST[(this.такт + 2) % 42] = y | x;
} break;
}
}
Так работает один процессор, выполняя одну микрокоманду. В режиме исполнения программы реальный калькулятор выполняет около 3–4 шагов пользовательской программы в секунду, примерно на такую же скорость работы настроен и эмулятор. Для прохождения одного шага такт повторяется 23520 раз, выполняя 560 команд, прописанных в коде ПЗУ.
Это обстоятельство и сам довольно нетривиальный алгоритм исполнения кода делают реконструкцию механизмов и алгоритмов работы, запрограммированных в коде микросхем этих калькуляторов, очень и очень затруднительной. Достоверно и детально описать, как это работает, могли лишь причастные к разработке этих устройств; сегодня же любителям советских программируемых калькуляторов, интересующимся этой темой, остаётся лишь тоскливо рассматривать под лупой каждый бит восстановленного кода и пытаться понять, зачем он нужен.
Впрочем, некоторые моменты благодаря эмулятору и книге «Устройство и пользование» всё же удалось прояснить. Например, стало понятно, как возникают числа с порядком больше 99, работа с которыми была одним из основных направлений «еггогологии» – т. н. «электронный океан чисел». Разряды числа в памяти хранятся в двоично-десятичной форме, т. е. одна тетрада битов кодирует одну десятичную цифру (хотя может кодировать и шестнадцатеричную). Сами числа представлены в экспоненциальной форме и занимают 12 ячеек (вообще 14 – треть от длины регистра, но два разряда – служебные), при этом первая ячейка обозначает знак порядка, следующие две – сам порядок, потом ещё одна ячейка – знак мантиссы и восемь – собственно мантисса. Хотя на знак отведено аж четыре бита, используются только два значения – 0 для положительных чисел и нуля и 9 для отрицательных. Так вот, при переполнении следующий разряд порядка записывается в ячейку его знака, т. е. даёт «», но в памяти записан порядок , где единица стоит в ячейке знака. Над этим значением можно производить некоторые операции, как над обычным числом, правда, до тех пор, пока порядок находится в пределах второй сотни – дальше начинаются сложности (причём над «ЕГГОГом», полученным именно таким способом; полученный при делении на 0, например, ничего не даст). Однако глубинные механизмы «числового океана» всё же так и остались невыясненными.
Используя эмулятор, можно, например, изучить содержание памяти калькулятора во время каких-либо манипуляций или же прогонять код по одному такту или команде, можно посмотреть на порядок выполнения команд каждого процессора или попробовать добавлять или убирать устройства с системной магистрали. Но насколько это позволит продвинуться в изучении работы МК-61?..
Завершить эту заметку хочу цитатой, которая, на мой взгляд, хорошо резюмирует написанное выше.
Программирование МК-61 имеет глубокий философский подтекст.
Ограниченность ресурсов и доступного инструментария, добровольно принимаемая программистом, отражает собой многовековой опыт аскетических духовных практик. Сложнейшая многоуровневая иерархия программ управления калькулятором – от кода, вводимого человеком, до микрокоманд и микроприказов — есть отражение необычайной сложности божественного мироздания, всех глубин и уровней материи – от крупномасштабных структур вселенной до элементарных частиц, от сознания до неживой материи, от социума до первозданного хаоса и небытия.
Сам микрокод, прошитый в ПЗУ калькулятора, предстаёт объектом благоговейного созерцания, ибо никто не может в полной мере постичь принципы его работы, структуру или как-либо повлиять на его работу, склоняя нас к агностицизму и мыслям об иллюзорности свободы воли. Тройственность структуры микрокода – команды, синхропрограммы и микрокоманды – и три процессора калькулятора отсылают нас к вытекающей из христианского представления о Боге как о Троице троичности бытия, к естественной (троичной) аристотелевой логике и к концепции триединой русской нации.
Программа, подаваемая человеком калькулятору, представляя собой с одной стороны низкоуровневый автокод, составленный из элементарных команд, с другой же – высокоуровневые инструкции, исполняемые прошивкой ПЗУ, демонстрирует нам диалектический закон единства и борьбы противоположностей. Исполнение же программы, когда, пройдя 105 шагов программной памяти, калькулятор возвращается в начало и продолжает исполнение кода, есть образ колеса сансары, а получение решения задачи становится подобием нирваны, достигнутой в результате правильно написанной и выполненной программы.
Let's block ads! (Why?)