 В данной статье я хочу описать how-to по созданию drbd зеркалирования на Proxmox 3.0 хост-машинах. Объединить машины в proxmox кластер имеет смысл до этих операций – хотя в общем то нет никакой разницы.
В данной статье я хочу описать how-to по созданию drbd зеркалирования на Proxmox 3.0 хост-машинах. Объединить машины в proxmox кластер имеет смысл до этих операций – хотя в общем то нет никакой разницы.Основным отличием данного материала от многих, раскинутых на просторах интернета, то что мы делаем drbd раздел не на новом физическом диске, подключенном вторым, а на lvm разделе в пределах единственного наличествующего диска.
Вопрос целесообразности таких действий достаточно спорный – будет ли быстрее drbd на «сыром» диске или нет, но в любом случае это 100% опробованный вариант. В копилку так сказать. Да и работа с «сырым» диском – это просто частный случай данной инструкции.
Собственно Proxmox 3.0 при установке ( так же как и его предшественник 2.0 ) не напрягает вопросами разбиения на разделы и все разбивает сам учитывая только общие размеры диска и объем памяти. Мы получаем раздел /pve/data занимающий большую часть диска и видимый в Proxmox как хранилище local. Вот за счет него и будут производиться действия.
1. Обновляем пакеты до актуальных#aptitude update && aptitude full-upgrade
2. Устанавливаем необходимые пакеты#aptitude install drbd8-utils
3. Освобождение места под новый раздел.
Отмонтируем /dev/pve/data ( он же /var/lib/vz ). Все следующие действия шага 3 можно делать только на отмонтированном ресурсе – соответственно перед этим гасим все VM которые используют хранилище local на данном узле. Остальное можно не трогать если очень нужно.#umount /dev/pve/data
3.1. Уменьшение /dev/pve/data.
В принципе несколько следующих шагов можно заменить командами#lvresize -L 55G /dev/mapper/pve-data#mkfs.ext3 /dev/pve/data
Ну или чуть более развернуто. И по-моему чуть более корректно.#lvremove /dev/pve/data#lvcreate -n data -l 55G pve#mkfs.ext3 /dev/pve/data
Но при этом мы теряем все что есть на хранилище local. Если Proxmox свежеустановленый (что в общем то рекомендуется для манипуляций такого рода), то на этом все и идем к шагу 4. Если же стоит вопрос все-таки сохранить данные в хранилище local, то действуем иначе.
3.2. Уменьшение /dev/pve/data без потери информации.
Я исхожу из того что занято на local меньше чем 50G. Если у вас другая ситуация то просто поменяйте «новый размер» в командах.
#umount /dev/pve/data
Обязательная проверка, без нее не сработает resize2fs#e2fsck -f /dev/mapper/pve-datae2fsck 1.42.5 (29-Jul-2012)Pass 1: Checking inodes, blocks, and sizesPass 2: Checking directory structurePass 3: Checking directory connectivityPass 4: Checking reference countsPass 5: Checking group summary information/dev/mapper/pve-data: 20/53223424 files (0.0% non-contiguous), 3390724/212865024 blocks
Сжимаем файловую систему до 50G. Если данный шаг пропустить то с вероятностью 90% после lvresize мы получим битую систему. Причем число намеренно немножко меньше чем результирующий раздел. С запасом.#resize2fs /dev/mapper/pve-data 50Gresize2fs 1.42.5 (29-Jul-2012)Resizing the filesystem on /dev/mapper/pve-data to 13107200 (4k) blocks.The filesystem on /dev/mapper/pve-data is now 13107200 blocks long.
#e2fsck -f /dev/mapper/pve-data
Сжимаем непосредственно раздел /pve/data до 55G#lvresize -L 55G /dev/mapper/pve-data WARNING: Reducing active logical volume to 55.00 GiBTHIS MAY DESTROY YOUR DATA (filesystem etc.)Do you really want to reduce data? [y/n]: yReducing logical volume data to 55.00 GiBLogical volume data successfully resized
Занимаем системой все доступное пространство. В принципе если ваш «запас» на предидущем шаге не большой, то этого можно и не делать. Зачем экономить на спичках? ;)#resize2fs /dev/mapper/pve-dataresize2fs 1.42.5 (29-Jul-2012)Resizing the filesystem on /dev/mapper/pve-data to 14417920 (4k) blocks.The filesystem on /dev/mapper/pve-data is now 14417920 blocks long.
Возвращаем /dev/pve/data системе.#mount /dev/pve/data
4. Создание раздела для drbd
Смотрим свободное место. Убеждаемся что все предидущие шаги дали то, что неободимо. Т.е свободное место на разделе /dev/sda2#pvdisplay--- Physical volume ---PV Name /dev/sda2VG Name pvePV Size 931.01 GiB / not usable 0Allocatable yesPE Size 4.00 MiBTotal PE 238339Free PE 197891Allocated PE 40448PV UUID 6ukzQc-D8VO-xqEK-X15T-J2Wi-Adth-dCy9LD
Создаем новый раздел на всё свободное пространство.#lvcreate -n drbd0 -l 100%FREE pveLogical volume "drbd" created
5. Готовим файл конфигурации drbd#nano /etc/drbd.d/r0.res
resource r0 {
startup {
wfc-timeout 120;
degr-wfc-timeout 60;
become-primary-on both;
}
net {
cram-hmac-alg sha1;
shared-secret «proxmox»;
allow-two-primaries;
after-sb-0pri discard-zero-changes;
after-sb-1pri discard-secondary;
after-sb-2pri disconnect;
}
syncer {
rate 30M;
}
on p1 {
device /dev/drbd0;
disk /dev/pve/drbd;
address 10.1.1.1:7788;
meta-disk internal;
}
on p2 {
device /dev/drbd0;
disk /dev/pve/drbd;
address 10.1.1.2:7788;
meta-disk internal;
}
}
Параметр wfc-timeout некоторые рекомендуют ставить в 0. Смысл его – если при старте мы не видим соседа drbd то через wfc-timeout секунд перезагрузится для повторной попытки. 0 – означает отключить подобное действие.
Rate 30M – ограничение передачи между drbd хостами. Значение соответствует 1G соединению. Рекомендовано как 30% от реальной пропускной способности канала между хостами. В примере ниже на «тестовых кроликах» пропускная способность на 100M соединении около 11Mb/s т.е rate надо уменьшить до 3M. При 10G соединении между хостами явно имеет смысл увеличить.
6. Создание мета-данных и запуск drbd раздела.#modprobe drbd
#drbdadm create-md r0md_offset 830015008768al_offset 830014976000bm_offset 829989642240
Found some data
==> This might destroy existing data! <==
Do you want to proceed?[need to type 'yes' to confirm] yes
Writing meta data...initializing activity logNOT initialized bitmapNew drbd meta data block successfully created.Success
#drbdadm up r0
Посмотреть результат можно так:#cat /proc/drbdversion: 8.3.13 (api:88/proto:86-96)GIT-hash: 83ca112086600faacab2f157bc5a9324f7bd7f77 build by root@sighted, 2012-10-09 12:47:510: cs:WFConnection ro:Secondary/Unknown ds:UpToDate/DUnknown C r----sns:0 nr:0 dw:0 dr:0 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:b oos:810536760
7. Подготавливаем второй хост
Шаги 1-6 потворяем на второй хост машине. Важный момент(!). Размер раздела drbd должен быть идентичен на обоих хостах.
8. Синхронизация.
Берем один из хостов ( не имеет значения на какой ). Назовем его до полной синхронизации primary. Второй соответственно secondary. После полной синхронизации они станут равноценными -такой режим мы задали.
#drbdadm -- --overwrite-data-of-peer primary r0
# cat /proc/drbd version: 8.3.13 (api:88/proto:86-96)GIT-hash: 83ca112086600faacab2f157bc5a9324f7bd7f77 build by root@sighted, 2012-10-09 12:47:510: cs:WFConnection ro:Primary/Unknown ds:UpToDate/DUnknown C r----sns:0 nr:0 dw:0 dr:664 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:b oos:810536760
после чего на обоих хостах#drbdadm down r0#service drbd start
На primary результат будет выглядеть так:Starting DRBD resources:[ d(r0) s(r0) n(r0) ]..........***************************************************************DRBD's startup script waits for the peer node(s) to appear.- In case this node was already a degraded cluster before thereboot the timeout is 60 seconds. [degr-wfc-timeout]- If the peer was available before the reboot the timeout willexpire after 120 seconds. [wfc-timeout](These values are for resource 'r0'; 0 sec -> wait forever)To abort waiting enter 'yes' [ 18]:.
На secondary:
Starting DRBD resources:[ d(r0) s(r0) n(r0) ]..........***************************************************************DRBD's startup script waits for the peer node(s) to appear.- In case this node was already a degraded cluster before thereboot the timeout is 60 seconds. [degr-wfc-timeout]- If the peer was available before the reboot the timeout willexpire after 120 seconds. [wfc-timeout](These values are for resource 'r0'; 0 sec -> wait forever)To abort waiting enter 'yes' [ 14]:0: State change failed: (-10) State change was refused by peer nodeCommand '/sbin/drbdsetup 0 primary' terminated with exit code 110: State change failed: (-10) State change was refused by peer nodeCommand '/sbin/drbdsetup 0 primary' terminated with exit code 110: State change failed: (-10) State change was refused by peer nodeCommand '/sbin/drbdsetup 0 primary' terminated with exit code 11.
Ошибки\задержки связаны с тем что мы перезапустили все одновременно. В нормальной ситуации запуск выглядит просто:
#service drbd startStarting DRBD resources:[ d(r0) s(r0) n(r0) ].
# cat /proc/drbdversion: 8.3.13 (api:88/proto:86-96)GIT-hash: 83ca112086600faacab2f157bc5a9324f7bd7f77 build by root@sighted, 2012-10-09 12:47:510: cs:SyncSource ro:Primary/Primary ds:UpToDate/Inconsistent C r-----ns:199172 nr:0 dw:0 dr:207920 al:0 bm:11 lo:1 pe:24 ua:65 ap:0 ep:1 wo:b oos:810340664[>....................] sync'ed: 0.1% (791348/791536)Mfinish: 19:29:01 speed: 11,532 (11,532) K/sec
тут мы видим, что началась синхронизация дисков.
Запустим мониторинг этого процесса и идем погулять. В зависимости от размеров диска и скорости соединения между хостами гулять можем от пары часов до суток…
#watch –n 1 “cat /proc/drbd”
И ждем заветного 100%
cs:SyncSource ro:Primary/Primary ds:UpToDate/ UpToDate
9. Создание lvm volume group
Процесс долог, потому продолжим на primary хосте.#vgcreate drbd-0 /dev/drbd0No physical volume label read from /dev/drbd0Writing physical volume data to disk "/dev/drbd0"Physical volume "/dev/drbd0" successfully createdVolume group "drbd-0" successfully created
10. Подключение группы в Proxmox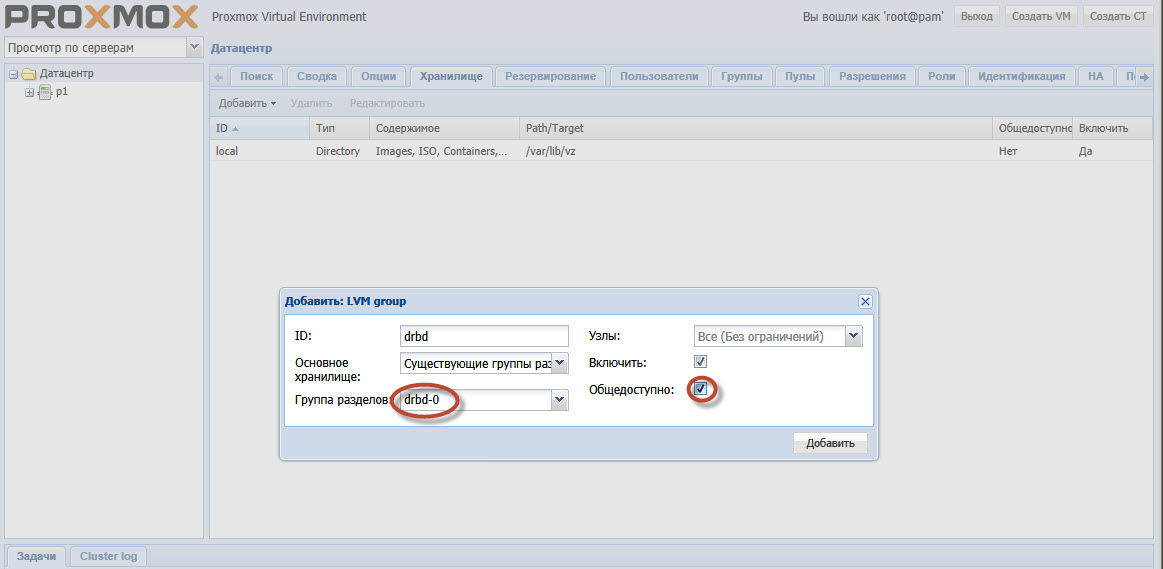
Выбираем раздел Датацентр-Хранилище в GUI Proxmox. Добавить. Тип — LVM, ID произвольно — это просто название. Группа разделов drbd-0, + включить, + общедоступно.
Обратите внимание на выделенные моменты. drbd-0 это группа созданная на шаге 9.
Ну а общедоступность выставляется для того чтоб Proxmox не пытался скопировать сам образы хост-дисков машин в процессе миграции.
11. Все.
Дождавшись окончания синхронизации можно создавать машины выбирая drbd в качестве хранилища image-disk, переносить их с хоста на хост в кластере не теряя связи с виртуальной машиной для обслуживания хост машины. В общем все готово для построения High Availability Cluster — Proxmox
This entry passed through the Full-Text RSS service — if this is your content and you're reading it on someone else's site, please read the FAQ at fivefilters.org/content-only/faq.php#publishers. Five Filters recommends: 'You Say What You Like, Because They Like What You Say' - http://www.medialens.org/index.php/alerts/alert-archive/alerts-2013/731-you-say-what-you-like-because-they-like-what-you-say.html
Комментариев нет:
Отправить комментарий