Как известно, на DVD дисках субтитры представлены в пререндеренном формате, который делает невозможным их редактирование или перевод. Имеющиеся утилиты по автоматизированной конверсии мало того что ориентированы в массе своей на англоязычную аудиторию, в дополнение к этому делают свою работу довольно плохо, в распознанном тексте присутствует масса ошибок. Озаботившись этим вопросом, за один вечер я разработал и успешно протестировал несложную методику и скрипт на Perl, которую и предлагаю вашему вниманию.
Нам потребуются следующие программы :FineReader, SubRip и интерпретатор Perl для выполнения скрипта сборки субтитров из текстовых файлов распознанных FineReader-ом. Где их взять вам подскажет Яндекс или Гугл, все перечисленные программы широкоизвестны.
Итак, мы начинаем.
1. Запустите утилиту SubRib и откройте VOB с суффиксом *_0.VOB файл искомой видеопоследовательности. Выберите нужную вам дорожку субтитров, как показано на скриншоте ниже. Выберите опцию «save subtictures as BMP».
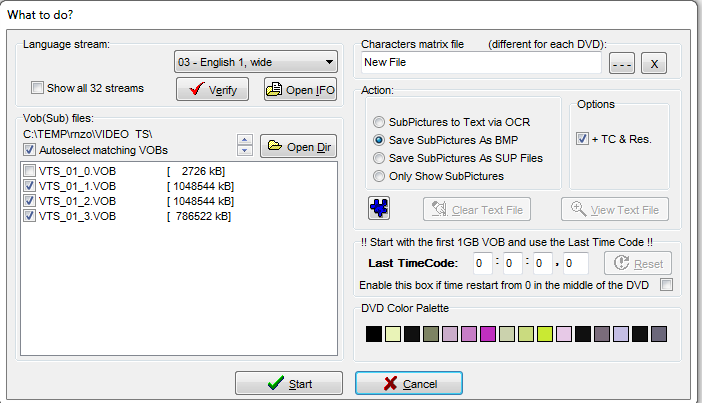
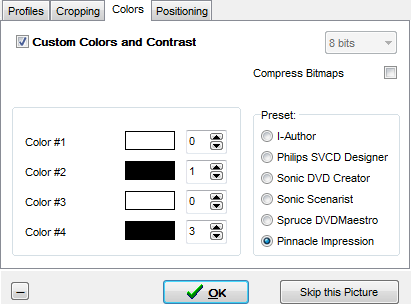
2. Нажмите кнопку Start. Выберите каталог, куда SubRip будет сохранять извлеченные картинки субтитров в формате BMP, затем укажите префикс файла, числовой номер и расширение BMP будут добавлены SubRip автоматически. Затем выберите оформление рендеринга субтитров, как показано ниже. По своему опыту я рекомендую выбрать черно-белую кастомную схему, обнулив значения параметров Color 1 и Color3, и выставив минимальные значения для параметров Color2 и Color4.
3. Подождите пока SubRip извлечет изображения из VOB-файлов и создаст в ранее выбранном вами каталоге картинки в BMP формате. Процесс сохранения будет показываться в новом окне, открытом приложением.
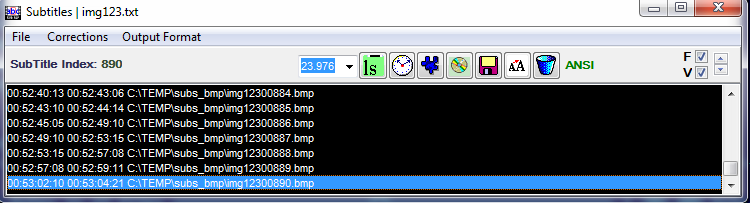
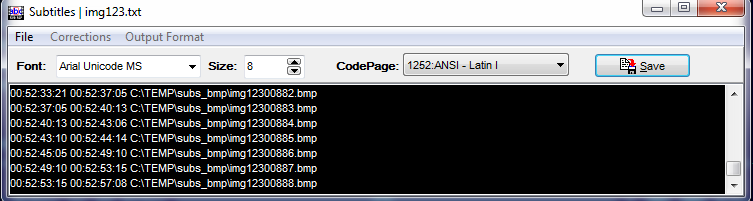
4. После завершения процесса сохраните сгенерированный SubRip файл с таймингами субтитров, он будет виден в новом окне, открывшемся в ходе генерации BMP изображений. Выберите формат ASCII.
5. Все, теперь у нас на руках есть субтитры и файл с таймингом. Время открывать FineReader. Запускаем FineReader, выбирает языки распознавания присутствующие в субтитрах (если их больше одного), выбираем опцию « открыть PDF или изображения », при помощи CTRL-A выбираем в диалоге все изображения из нашего каталога. Перед тем как открыть изображения, указывает опции распознавания. Конфигурация опций показана на двух скриншотах ниже.
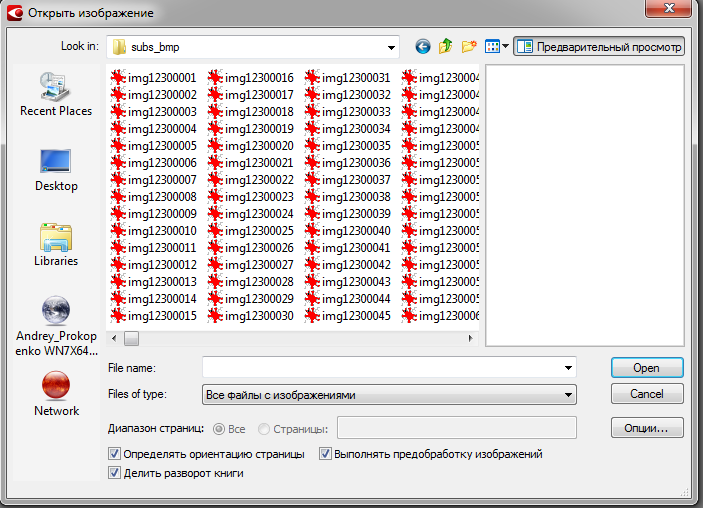
Для упрощения процесса вы можете использовать только встроенные шаблоны либо, но если вы хотите контролировать процесс распознавания с помощью собственных шаблонов, выберите вторую опцию.
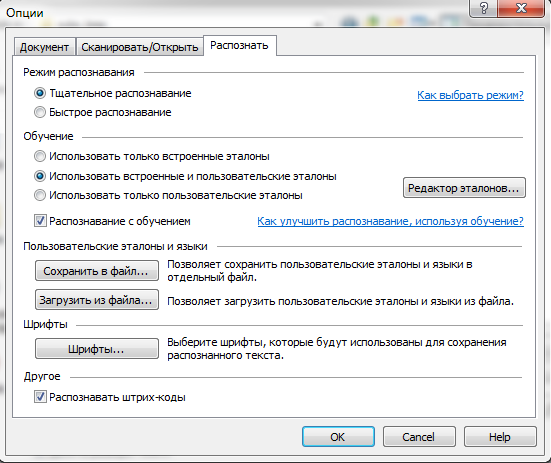
6. После распознавания текста и его проверки нужно сохранить результат. Поскольку FineReader не всегда корректно распознавал конец абзаца в субтитрах, по результатам экспериментов я выбрал опцию сохранять в отдельные файлы.
Тип сохраняемого файла (мы сохраняем в текстовый файл), приведен на скриншоте ниже:

При сохранении выберите каталог, укажите префикс для текстовых файлов, из выпадающего меню выберите пункт « создавать отдельный файл для каждой страницы » после чего дополнительно кликните на кнопке « опции »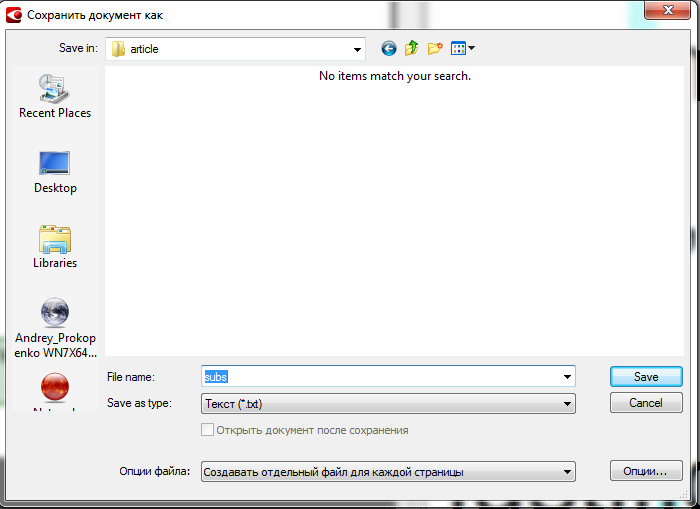
и укажите параметры сохранения как показано ниже.
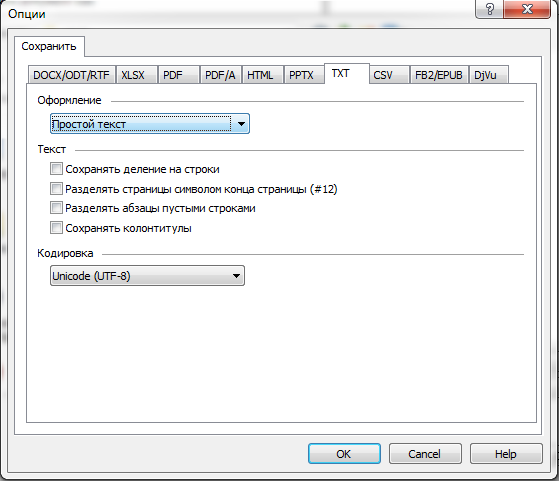
7. В результате всех вышеперечисленных действий у нас получился каталог с множеством текстовый файлов в кодировке UTF-8. Теперь нам нужно их сконвертировать. Для этого я написал небольшой скрипт для сборки субтитров на основе ранее сохраненного на шаге 4 и множества текстовых файлов. Для этого сохраните Perl скрипт показанный ниже или скачайте исполняемый файл скомпилированной версии скрипта и запустите с двумя параметрами,
--subtutles полный путь и имя каталога с текстовыми файлами
--timing полный путь и имя файла тайминга.
#!/usr/bin/perl
use strict;
use warnings;
use Getopt::Long;
use File::GLob;
use utf8;
#perl2exe_include "unicore/Heavy.pl"
#perl2exe_include "overloading.pm"
#perl2exe_include "File/Glob.pm"
#------------------------------------------------------------------
my ($arg_subtitles,$arg_timing);
GetOptions("subtitles=s"=> \$arg_subtitles,
"timing=s"=> \$arg_timing);
usage() if (!$arg_subtitles || !$arg_timing);
$arg_subtitles =~ s#[/\\]#\\\\#g;
$arg_timing =~ s#[/\\]#\\\\#g;
my $buf = "";
my @subs_array;
while (<$arg_subtitles/*.txt>){
my $fname = $_;
my $sub_number = $1 if ($fname =~ /^.*?0{0,5}(\d{1,5})\.txt$/);
local $/;
open (sFILE,$fname) or die "Can't read file $fname [$!]\n";
$buf = <sFILE>; $buf =~ s/\xEF\xBB\xBF//;
close (sFILE);
$subs_array[$sub_number]=$buf;
}
open(tFILE, "<".$arg_timing) or die "Can't read file $arg_timing [$!]\n";
print "\xEF\xBB\xBF";
while (<tFILE>) {
if (m/(\d{2,2}:\d{2,2}:\d{2,2}):(\d{2,2}) (\d{2,2}:\d{2,2}:\d{2,2}):(\d{2,2}) \S+(\d{5,5})\.\w{3,3}/) {
my $start_hms= $1; my $start_mls= $2; my $end_hms=$3; my $end_mls=$4; my $sub_number = $5;
$sub_number =~ s/^0{0,4}//;
print "$sub_number\n$start_hms,$start_mls"."0"." --> $end_hms,$end_mls"."0"."\n".$subs_array[$sub_number]."\n\n";
}
}
close (tFILE);
sub usage
{
die <<"EOT";
Usage: $0 --subtitles path_to_the_subs_folder --timing path_to_the_timing_file
path_to_the_subs_folder is the name of the folder where recognised subtitles are stored
while saving recognised subtitles from BMP images, choose text format and "store one file per page" options
EOT
}
Скрипт выводит созданный файл в формате UTF8 на консоль, поэтому вы можете перенаправить его в файл по вашему выбору.
На этом все, благодарю за внимание.
This entry passed through the Full-Text RSS service — if this is your content and you're reading it on someone else's site, please read the FAQ at fivefilters.org/content-only/faq.php#publishers. Five Filters recommends: 'You Say What You Like, Because They Like What You Say' - http://www.medialens.org/index.php/alerts/alert-archive/alerts-2013/731-you-say-what-you-like-because-they-like-what-you-say.html
Комментариев нет:
Отправить комментарий