Хочу поделиться своим опытом использования HBase, а именно рассказать про bulk loading. Это еще один метод загрузки данных. Он принципиально отличается от обычного подхода (записи в таблицу через клиента). Есть мнение, что с помощью bulk load можно очень быстро загружать огромные массивы данных. Именно в этом я решил разобраться.
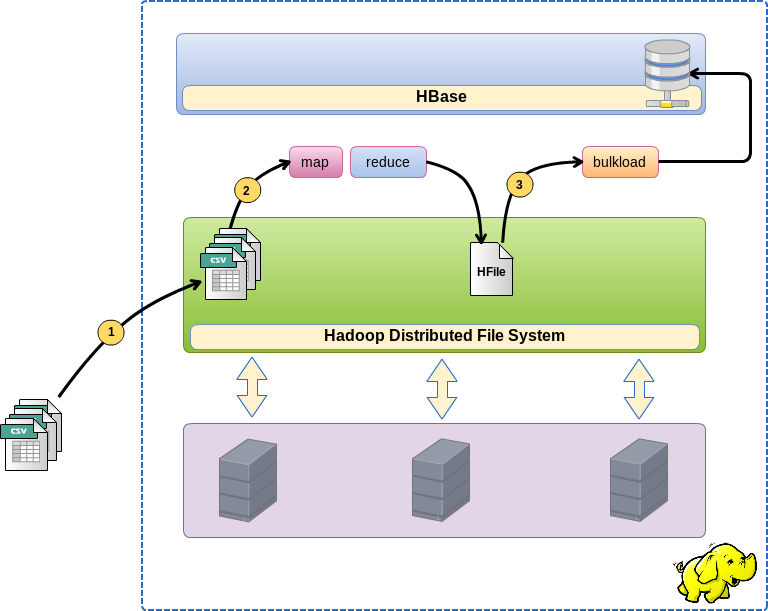
И так, обо всём по порядку. Загрузка через bulk load происходит в три этапа:
- Помещаем файлы с данными в HDFS
- Запускаем MapReduce задачу, которая преобразует исходные данные непосредственно в файлы формата HFile, посути HBase хранит свои данные именно в таких файлах.
- Запускаем bulk load функцию, которая зальёт (привяжет) полученные файлы в таблицу HBase.
В данном случае мне было необходимо прочувствовать эту технологию и понять её в цифрах: чему равна скорость, как она зависит от количества и размера файлов. Эти числа слишком зависимы от внешних условий, но помогают понять порядки между обычной загрузкой и bulk load.
Исходные данные:
Кластер под управлением Cloudera CDH4, HBase 0.94.6-cdh4.3.0.
Три виртуальных хоста (на гипервизоре), в конфигурации CentOS / 4CPU / RAM 8GB / HDD 50GB
Тестовые данные хранились в CSV файлах различных размеров, суммарным объёмом 2GB, 3.5GB, 7.1GB и 14.2GB
Сначала о результатах:
Bulk loading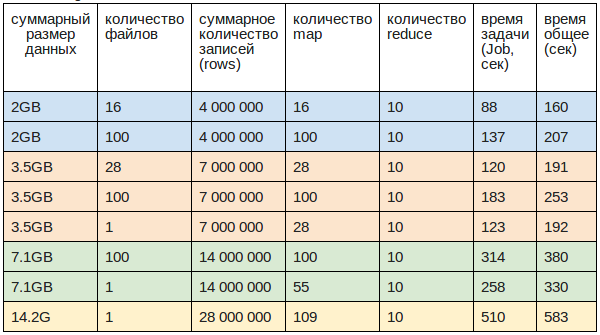
Cкорость:
- Max 29.2 Mb/sec или 58K rec/sec (3.5GB в 28 файлах)
- Average 27 Mb/sec или 54K rec/sec(рабочая скорость, более приближенная к реальности )
- Min 14.5 Mb/sec или 29K rec/sec (2GB в 100 файлах)
- 1 файл загружается на 20% быстрее чем 100
Размер одной записи (row): 0.5Кb
Время инициализации MapReduce Job: 70 sec
Время загрузки файлов в HDFS с локальной файловой системы:
- 3.5GB / 1 файл — 65 sec
- 7.5GB / 100 — 150 sec
- 14.2G / 1 файл — 285 sec
Загрузка через клиенты:
Загрузка осуществлялась с 2-х хостов по 8 потоков на каждом.
Клиенты запускались по крону в одно и тоже время, загрузка CPU не превышала 40%
Размер одной записи (row), как и в предыдущем случае был равен 0.5Кb.
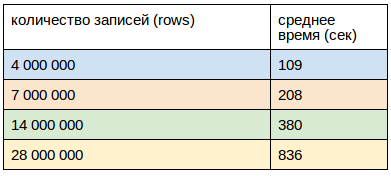
Что в итоге?
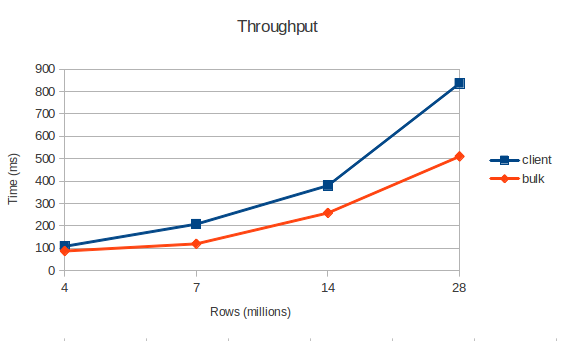
Реализовать этот тест, я решил на волне разговоров о bulk load как о способе сверхбыстрой загрузки данных. Стоит сказать, что в официальной документации речь идет только о снижении нагрузки на сеть и CPU. Как бы там ни было, я не вижу выигрыша в скорости. Тесты показывают что bulk load быстре всего лишь в полтора раза, но не будем забывать что это без учета инициализации m/r джобы. Кроме того, данные надо доставить в HDFS, на это тоже потребуется какое то время.
Думаю, стоит относиться к bulk load просто, как к еще одному способу загрузки данных, архитектурно иному (в некоторых случаях очень даже удобному).
А теперь о реализации
Теоретически всё довольно просто, но на практике возникает несколько технических нюансов.
//Создаём джоб
Job job = new Job(configuration, JOB_NAME);
job.setJarByClass(BulkLoadJob.class);
job.setMapOutputKeyClass(ImmutableBytesWritable.class);
job.setMapOutputValueClass(Put.class);
job.setMapperClass(DataMapper.class);
job.setNumReduceTasks(0);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(HFileOutputFormat.class);
FileInputFormat.setInputPaths(job, inputPath);
HFileOutputFormat.setOutputPath(job, new Path(outputPath));
HTable dataTable = new HTable(jobConfiguration, TABLE_NAME);
HFileOutputFormat.configureIncrementalLoad(job, dataTable);
//Запускаем
ControlledJob controlledJob = new ControlledJob(
job,
null
);
JobControl jobController = new JobControl(JOB_NAME);
jobController.addJob(controlledJob);
Thread thread = new Thread(jobController);
thread.start();
.
.
.
//Даём права на output
setFullPermissions(JOB_OUTPUT_PATH);
//Запускаем функцию bulk-load
LoadIncrementalHFiles loader = new LoadIncrementalHFiles(jobConfiguration);
loader.doBulkLoad(
new Path(JOB_OUTPUT_PATH),
dataTable
);
- MapReduce Job создаёт выходные файлы c правами пользователя, от имени которого он был запущен.
- bulk load всегда запускается от имени пользователя hbase, поэтому не может прочитать подготовленные для него файлы, и валится вот с таким исключением: org.apache.hadoop.security.AccessControlException: Permission denied: user=hbase
Поэтому надо запускать Job от имени пользователя hbase или раздать права на выходные файлы (именно так я сделал).
- Необходимо правильно создать таблицу HBase. По умолчанию она создается с одним Region-ом. Это приводит к тому, что создается только один редьюсер и запись идет только на одну ноду, загружая её на 100% остальные при этом курят.
Поэтому при создании новой таблицы надо сделать pre-split. В моём случае таблица разбивалась на 10 Region-ов равномерно разбросанных по всему кластеру.
//Создаём таблицу и делаем пре-сплит
HTableDescriptor descriptor = new HTableDescriptor(
Bytes.toBytes(tableName)
);
descriptor.addFamily(
new HColumnDescriptor(Constants.COLUMN_FAMILY_NAME)
);
HBaseAdmin admin = new HBaseAdmin(config);
byte[] startKey = new byte[16];
Arrays.fill(startKey, (byte) 0);
byte[] endKey = new byte[16];
Arrays.fill(endKey, (byte)255);
admin.createTable(descriptor, startKey, endKey, REGIONS_COUNT);
admin.close();
- MapReduce Job пишет в выходную директорию, которую мы ему указываем, но при этом создает субдиректории, одноименные с column family. Файлы создаются именно там
В целом, это всё. Хочется сказать, что это довольно грубый тест, без хитрых оптимизаций, поэтому если у вас есть что добавить, буду рад услышать.
Весь код проекта доступен на GitHub: github.com/2anikulin/hbase-bulk-load
This entry passed through the Full-Text RSS service — if this is your content and you're reading it on someone else's site, please read the FAQ at fivefilters.org/content-only/faq.php#publishers. Five Filters recommends:
- Massacres That Matter - Part 1 - 'Responsibility To Protect' In Egypt, Libya And Syria
- Massacres That Matter - Part 2 - The Media Response On Egypt, Libya And Syria
- National demonstration: No attack on Syria - Saturday 31 August, 12 noon, Temple Place, London, UK
Комментариев нет:
Отправить комментарий