Сегодня речь пойдёт о том, как можно попробовать проследить тенденции. Глядя на то, как это делает google появилось желание сделать подобные тренды на основе тегов Хабра. Возможно, не все пользователи добросовестно расставляют теги, но допустив это как истину, можно получить неплохие результаты. Итак, давайте попробуем.
1. Описание
Честно говоря, изначально была мысль только собрать все теги и отсортировать по убыванию, посмотрев, какие чаще всего используются, а какие нет. Но я решил пойти немного дальше — добавив дату появилась возможность смотреть на эту частоту во времени, для наглядности добавив графики. Всё это будет в конце, а пока начнём с самого начала.
Сразу оговорюсь, что далее по тексту встречается слово «тег» — это тоже самое что и тэг, таг, метка. Писать будем под python 3.3.2, так как в нём у меня не возникало проблем с юникодом.
2. Структура и подготовка
Для этой задачи нам необходима база данных. Она будет содержать 2 таблицы post_tags и tags. Поля первой pid — ид поста, tid — ид тега, date — дата поста с тегом. Поля второй rowid — ид тега, tag_title — заголовок тега. Тут всё предельно просто, поэтому создадим класс для работы с базой.
import sqlite3
class Base:
def __init__(self,dbname):
self.con=sqlite3.connect(dbname)
def __del__(self):
self.con.close( )
def maketables(self):
"""
Для создания таблицы
"""
self.con.execute('create table post_tags(pid,tid,date)')
self.con.execute('create table tags(tag_title)')
self.con.commit( )
Так как всё сохранено в файл tags.py, попробуем выполнить:
import tags
extend = tags.Base('tags.db')
extend.maketables()
Теперь у нас есть пустая база, пойдёмте заполним её.
3. Парсинг тегов
Необходимо собрать все теги и записать совместно с датой публикации поста. Для этого используем beautifulsoup и urllib.request.
Добавим в созданный класс функции:
- get_tag — для получения тега из базы
- add_tag — для добавления тега
- add_post — для просмотра и добавления поста
def get_tag(self, name, added = True):
"""
Поиск тега, если есть вернуть tid, иначе создать новый
cur - текущий тег
res - будет получен если тег уже в базе
added - Флаг/ если установлен то будет дописывать, если нет то возвращать false
"""
cur=self.con.execute("select rowid from %s where %s='%s'" % ('tags','tag_title',name))
res=cur.fetchone( )
if res==None:
if added:
cur=self.con.execute("insert into %s (%s) values ('%s')" % ('tags','tag_title',name))
self.con.commit( )
return cur.lastrowid
else:
return False
else:
return res[0]
def add_tag(self, pid, name, date):
"""
Добавление нового тега
pid - ид поста
name - сам тег
date - дата поста
"""
rowid = self.get_tag(name);
print(pid,rowid ,name, date)
self.con.execute("insert into %s (%s,%s,%s) values (%d,%d,'%s')" % ('post_tags','pid','tid','date',pid,rowid,date))
self.con.commit( )
def add_post(self, pid):
"""
Просмотр поста (выборка даты и тегов)
"""
if (self.get_post(pid)):
return
print('-'*10,'http://habrahabr.ru/post/'+str(pid),'-'*10)
cur=self.con.execute("select pid from %s where %s=%d" % ('post_tags','pid',pid))
res=cur.fetchone( )
if res==None:
try:
soup=BeautifulSoup(urllib.request.urlopen('http://habrahabr.ru/post/'+str(pid)).read( ))
except (urllib.request.HTTPError):
self.add_tag(pid,"parse_error_404","")
print("error 404")
else:
published = soup.find("div", { "class" : "published" })
tags = soup.find("ul", { "class" : "tags" })
if tags:
for tag in tags.findAll("a"):
self.add_tag(pid, tag.string, get_date(published.string))
else:
self.add_tag(pid,"parse_access_denied","")
print("access denied")
else:
print("post has already")
Чтобы наполнить базу достаточно запустить цикл по всем постам. Ограничимся 196000 он попадает на 1 октября 2013.
for pid in range(196000):
extend.add_post(pid+1)
Знаю, что способ не идеальный и с мегабитным интернетом работал бы около 170 часов.
Для ускорения процесса было решено добавить ещё одну таблицу post, в которой будет храниться отдельный ид поста, не связанный с логической частью, и использовать его как флаг. Так большую часть времени программа «висит». В ожидании загрузки страницы можно запустить ещё пару таких программ и натравив на одну базу заполнять её параллельно. Возникновение коллизий конечно возможно и в конце концов потеря или частичная запись составила 3% постов, что не так много. После таких действий выяснилось, что параллельно не может работать больше 8 программ, т.к. при запуске 9 Хабр отдает 503 ошибку, что вполне логично. Поэтому, запустив 6 экземпляров (именно такое количество не вызывало ошибок и не конфликтовало между собой), была получена база(17 Mb).
4. Обработка данных
Собственно, теперь основная часть — обработать полученные данные.
Добавим в созданный класс функции:
- get_count_byid — количество по ид тега
- get_graph — получить список кортежей (дата, количество)
- get_image — показать изображение
- get_all_tags_sorted — сортировать по убыванию
- get_all_tag_count — получить список кортежей (ид, тег, количество)
def get_count_byname(self, name, date = ''):
"""
Найти name по tid и получить количество по имени из get_count_byid
name - имя тега
date - (*)дата Формат mm_yyyy
"""
tid = self.get_tag(name, False)
return self.get_count_byid(tid, date)
def get_count_byid(self, tid, date = ''):
"""
Вернуть количество за весь период или за указанную дату
"""
if tid:
if date:
count=self.con.execute("select count(pid) from %s where %s=%d and %s='%s'" % ('post_tags','tid',tid,'date',date))
else:
count=self.con.execute("select count(pid) from %s where %s=%d" % ('post_tags','tid',tid))
res=count.fetchone( )
return res[0]
else:
return False
def get_graph(self, name):
"""
Формирование списка дата - количество
"""
month = ('01','января'),('02','февраля'),('03','марта'),('04','апреля'),('05','мая'),('06','июня'),('07','июля'),('08','августа'),('09','сентября'),('10','октября'),('11','ноября'),('12','декабря')
years = [2006,2007,2008,2009,2010,2011,2012,2013]
graph = []
for Y in years:
for M,M_str in month:
date = str(M)+'_'+str(Y)
graph.append((date, self.get_count_byname(name, date)))
return graph
def get_image(self, name):
"""
Построение графика
m_x - масштаб по X
m_y - масштаб по Y
img_x - ширина рисунка
img_y - высота рисунка
"""
img_x = 960
img_y = 600
img=Image.new('RGB',(img_x,img_y),(255,255,255))
draw=ImageDraw.Draw(img)
graph = self.get_graph(name)
max_y = max(graph,key=lambda item:item[1])[1]
if max_y == 0:
print('tag not found')
return False
m_x, m_y = int(img_x/(len(graph))), int(img_y/max_y)
draw.text((10, 10), str(max_y), (0,0,0))
draw.text((10, 20), name, (0,0,0))
x,prev_y = 0,-1
for x_str, y in graph:
x += 1
if (x%12 == 1): draw.text((x*m_x, img_y - 30), str(x_str[3:]),(0,0,0))
if prev_y >= 0: draw.line(((x-1)*m_x, img_y-prev_y*m_y-1, x*m_x, img_y-y*m_y-1), fill=(255,0,0))
prev_y = y
img.save('graph.png','PNG')
Image.open('graph.png').show()
def get_all_tags_sorted(self, tags):
"""
По убыванию
"""
return sorted(tags, key=lambda tag:tag[2], reverse=True)
def get_all_tag_count(self):
count=self.con.execute("select count(rowid) from %s" % ('tags'))
res=count.fetchone( )
alltag_count = res[0]
tags = []
for tag_id in range(alltag_count-1):
tags.append((tag_id+1,self.get_tag_name(tag_id+1),self.get_count_byid(tag_id+1)))
print (tag_id+1,self.get_tag_name(tag_id+1),self.get_count_byid(tag_id+1))
return tags
5. Итог (для любителей статистики)
Top 25 «тегов лидеров»:
- google — 2611
- android — 2188
- Google — 2024
- linux — 1978
- php — 1947
- javascript — 1877
- microsoft — 1801
- apple — 1668
- социальные сети — 1509
- стартапы — 1484
- стартап — 1317
- программирование — 1229
- Microsoft — 1220
- java — 1180
- игры — 1141
- Apple — 1135
- iphone — 1122
- дизайн — 1110
- python — 1108
- юмор — 1061
- интернет — 1040
- хабрахабр — 983
- видео — 970
- реклама — 968
- Android — 876
Полный список можно посмотреть тут (формат id, title_tag, количество упоминаний).
Теперь, собственно, возвращаемся к мысли о трендах. Ниже приведены пару примеров (кликабельно):
| python | javascript | android |
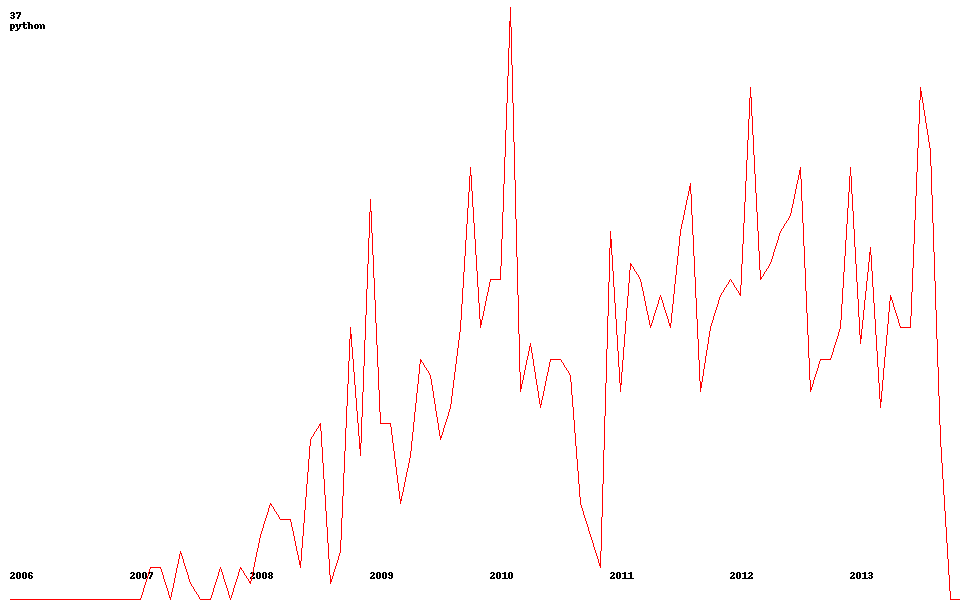 | 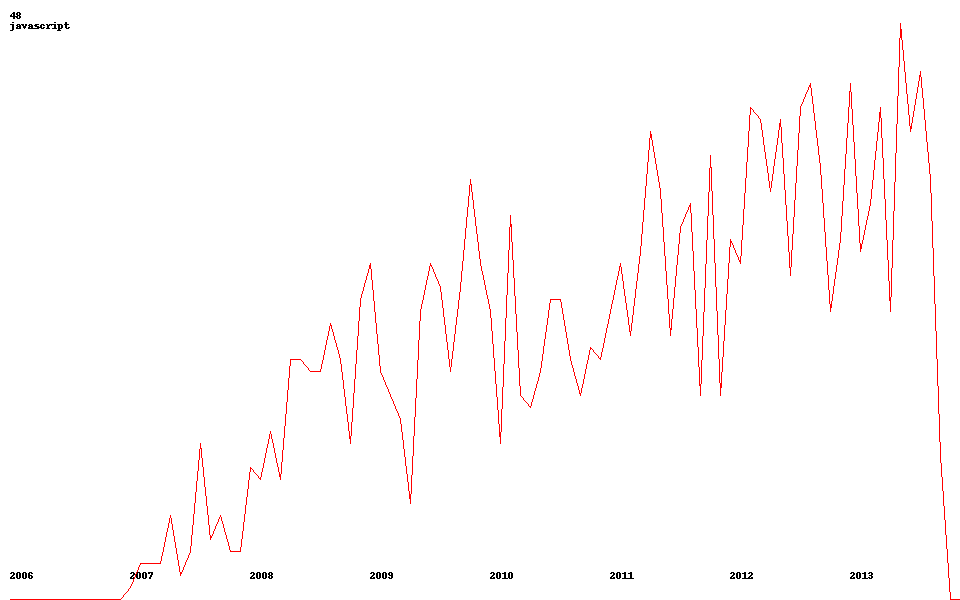 |  |
Получить такие изображения можно из функции get_image(tag_title).
Я уверен, что есть ещё лучшие методы получения подобного результата, но «я не волшебник, а только учусь». Прошу всех в комментарии для обсуждений и улучшений.
В принципе, моя цель была достигнута. Хотя уже появляются мысли о добавлении независимости регистра и морфологии, а также возможности передавать сразу список тегов.
Полный код выложен на github.
Всем спасибо за внимание, буду рад критике.
This entry passed through the Full-Text RSS service — if this is your content and you're reading it on someone else's site, please read the FAQ at fivefilters.org/content-only/faq.php#publishers. Five Filters recommends:
- Massacres That Matter - Part 1 - 'Responsibility To Protect' In Egypt, Libya And Syria
- Massacres That Matter - Part 2 - The Media Response On Egypt, Libya And Syria
- National demonstration: No attack on Syria - Saturday 31 August, 12 noon, Temple Place, London, UK
Комментариев нет:
Отправить комментарий