
Недавно я осознал нехватку вводных обучающих материалов о современной сетевой балансировке и проксировании. Я подумал: «Почему так? Балансировка нагрузки — одна из ключевых концепций для построения надёжных распределённых систем. Ведь должна быть доступна качественная информация об этом?» Я поискал и обнаружил, что информации мало. Статьи в Википедии о балансировке и прокси-серверах содержат обзоры некоторых концепций, но не могут похвастаться последовательным описанием предмета, особенно в том, что касается современных микросервисных архитектур. Поиск в Google информации о балансировке в основном возвращает сайты вендоров, заполненные модными терминами и скупые на подробности.
В этой статье я постараюсь восполнить нехватку постепенного введения в современную сетевую балансировку и проксирование. По правде сказать, это объёмная тема, достойная целой книги. И чтобы статья не получилась безразмерной, я постарался ряд сложных задач подать в виде простого обзора.
Что такое сетевая балансировка и проксирование?
Википедия определяет балансировку нагрузки так:
В вычислительной технике балансировка нагрузки улучшает распределение рабочих нагрузок по нескольким вычислительным ресурсам: компьютерам, компьютерным кластерам, сетевым подключениям, центральным процессорам или дисковым устройствам. Балансировка нагрузки призвана оптимизировать использование ресурсов, максимально увеличить пропускную способность, минимизировать время отклика и избежать перегрузки отдельных ресурсов. Применение вместо одного компонента нескольких компонентов с балансировкой может повысить надёжность и доступность благодаря получившемуся запасу мощностей. Балансировка нагрузки обычно подразумевает использование специального ПО или оборудования вроде многоуровневого коммутатора или DNS-сервера.
Это определение применимо ко всем аспектам обработки данных, а не только к работе с сетью. Операционные системы используют балансировку для диспетчеризации задач среди нескольких физических процессоров. Контейнерные оркестраторы вроде Kubernetes используют балансировку для диспетчеризации задач среди нескольких вычислительных кластеров. А сетевые балансировщики распределяют сетевые задачи среди доступных бэкендов. Эта статья посвящена только сетевой балансировке.

Иллюстрация 1: сетевая балансировка
На иллюстрации 1 показана упрощённая схема сетевой балансировки. Некоторые клиенты запрашивают ресурсы с некоторых бэкендов. Балансировщик находится между клиентами и бэкендами и выполняет несколько важных задач:
- Обнаружение сервисов. Какие бэкенды доступны? Какие у них адреса (т. е. как балансировщику к ним обращаться)?
- Проверка состояния. Какие балансировщики сейчас работают и готовы обрабатывать запросы?
- Балансировка. Какие алгоритмы нужны для балансировки отдельных запросов среди нормально функционирующих бэкендов?
Правильное использование балансировки в распределённой системе даёт несколько преимуществ:
- Абстрактность имён. Вместо того чтобы каждый клиент знал о каждом бэкенде (обнаружение сервисов), клиенты могут обращаться к балансировщику посредством заранее определённого механизма, и тогда процедуру разрешения имён можно делегировать балансировщику. Заранее определённый механизм включает в себя встроенные библиотеки и хорошо известные DNS/IP/порты. Ниже мы рассмотрим это подробнее.
- Устойчивость к отказам. С помощью проверки состояния и разных алгоритмов балансировщик способен эффективно маршрутизировать данные в обход сбойных или перегруженных бэкендов. То есть оператор может починить сбойный бэкенд на досуге, а не экстренно.
- Снижение стоимости и повышение производительности. Сети распределённых систем редко бывают однородными. Обычно система разбита на несколько сетевых зон и регионов. В рамках зоны сети обычно строятся с недоиспользованием пропускной способности, а между зонами нормой становится переиспользование (в данном случае пере- и недоиспользование означает процентное отношение пропускной способности сетевых карт к ширине канала между роутерами). Умный балансировщик может как можно дольше удерживать трафик запросов внутри зоны, что повышает производительность (меньше задержка) и снижает общие расходы в системе (между зонами намного меньше каналов, и они могут быть более узкими).
Балансировщик или прокси?
Термины балансировщик и прокси часто используют как взаимозаменяемые. В этой статье мы тоже в целом будем считать их аналогами (строго говоря, не все прокси — это балансировщики, но первичная функция подавляющего большинства — именно балансировка). Кто-то может возразить, что если балансировка — это часть встроенной клиентской библиотеки, то балансировщик не прокси. Но я отвечу, что такое разделение излишне усложняет и без того непростую тему. Ниже мы подробно рассмотрим типы топологий балансировщиков, но в этой статье топология встроенного балансировщика будет считаться частным случаем проксирования: приложение проксирует с помощью встроенной библиотеки, предлагающей те же абстракции, что и балансировщик вне процесса приложения.
L4 (подключения/сессии)-балансировка
Современные балансировочные решения по большей части можно разделить на две категории: L4 и 7. Они относятся к уровню 4 и уровню 7модели OSI. По причинам, которые станут очевидны в ходе обсуждения L7-балансировки, выбор этих терминов я считаю неудачным. Модель OSI очень слабо отражает сложность балансировочных решений, включающих в себя не только традиционные протоколы четвёртого уровня, такие как TCP и UDP, но зачастую и элементы протоколов других уровней OSI. Например, если L4 TCP-балансировщик предлагает ещё и TLS-прерывание, то он теперь L7-балансировщик?

Иллюстрация 2: прерывающий L4 TCP-балансировщик
Иллюстрация 2 отражает традиционный L4 TCP-балансировщик. В данном случае клиент создаёт TCP-подключение к балансировщику, тот прерывает подключение (т. е. отвечает напрямую SYN), выбирает бэкенд и создаёт новое подключение к этому бэкенду (т. е. отправляет данные новому SYN). Подробности схемы сейчас не так важны, мы обсудим их в разделе, посвящённому L4-балансировке.
Ключевая мысль — L4-балансировщик обычно оперирует только на уровне L4 TCP/UDP-подключений/сессий. Следовательно, балансировщик приблизительно перемешивает байты так, чтобы байты из одной сессии приходили на один бэкенд. Такому балансировщику неважны особенности приложений, чьими байтами он манипулирует. Это могут быть байты HTTP, Redis, MongoDB или любого иного протокола приложений.
L7 (приложения)-балансировка
L4-балансировка проста и широко применяется. Какие же её особенности заставляют вкладываться в L7-балансировку на уровне приложений? Рассмотрим в качестве примера конкретный случай L4:
- Два gRPC/HTTP2-клиента хотят общаться с бэкендом и подключаются через L4-балансировщик.
- L4-балансировщик создаёт одно исходящее TCP-подключение для каждого входящего TCP-подключения, так что получается два входящих и два исходящих.
- Но клиент A отправляет через своё подключение 1 запрос в минуту (RPM), а клиент Б — 50 запросов в секунду (RPS).
Если бэкенд решает обрабатывать трафик клиента А, то он будет обрабатывать нагрузку примерно в 3000 раз меньше, чем если бы обрабатывал трафик клиента Б! Это большая проблема, из-за которой в первую очередь теряется смысл балансировки. Также обратите внимание, что проблема действительна для любого протокола мультиплексирования, поддерживающего постоянные подключения (keep-alive) (мультиплексирование — это отправка конкурентных запросов приложений через одно L4-соединение, а keep-alive — это сохранение подключения в отсутствие активных запросов). Все современные протоколы одновременно и мультиплексирующие, и поддерживающие постоянные подключения, этого требуют соображения эффективности (в целом создавать подключение дорого, особенно если оно шифруется с помощью TLS), так что рассогласование нагрузки в L4-балансировщике со временем усиливается. Эта проблема решается с помощью L7-балансировщика.
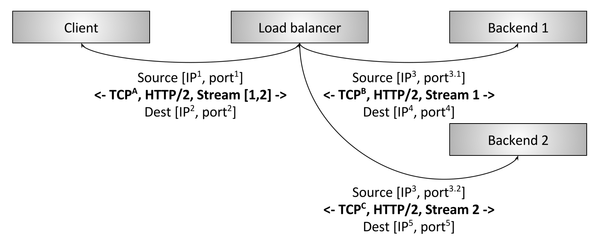
Иллюстрация 3: прерывающий L7 HTTP/2-балансировщик
На иллюстрации 3 показан L7 HTTP/2-балансировщик. В этом случае клиент создаёт одно HTTP/2 TCP- подключение к балансировщику, который затем создаёт два подключения к бэкендам. Когда клиент отправляет в балансировщик два HTTP/2-потока, первый поток уходит в бэкенд 1, а второй — в бэкенд 2. Так что даже мультиплексируемые клиенты с очень разными трафиками по запросам будут эффективно сбалансированы по бэкендам. Поэтому L7-балансировка так важна для современных протоколов (у неё есть ещё куча преимуществ благодаря возможности инспектировать трафик приложений, но об этом мы поговорим ниже).
L7-балансировка и модель OSI
Как уже говорилось выше, проблематично использовать модель OSI для описания свойств балансировки. Причина в том, что L7, как минимум согласно модели OSI, сама по себе охватывает несколько дискретных уровней абстракции балансировки. Например, для HTTP-трафика есть несколько подуровней:
- Опциональный Transport Layer Security (TLS). Обратите внимание, что специалисты по сетям спорят о том, к какому OSI-уровню относится TLS. Здесь мы будем относить TLS к L7.
- Физический HTTP-протокол (HTTP/1 или HTTP/2).
- Логический HTTP-протокол (заголовки, тело и прицепы).
- Протокол сообщений (gRPC, REST и т. д.).
Сложный L7-балансировщик работает со всеми этими подуровнями. Более простой L7-балансировщик может обладать лишь небольшим набором свойств, по которым его относят к L7. Иными словами, свойства L7-балансировщиков варьируются гораздо шире, чем в категории L4. И конечно, здесь мы коснулись лишь HTTP, но Redis, Kafka, MongoDB и другие — всё это примеры L7-протоколов приложений, выигрывающих от использования L7-балансировки.
Свойства балансировщика
Здесь мы кратко рассмотрим основные свойства балансировщиков. Не для всех балансировщиков характерны все упоминаемые свойства.
Определение сервисов
Определение сервисов — это способ определения балансировщиком набора доступных бэкендов. Делать это можно по-разному, например с помощью:
Проверка состояния
Это определение, может ли бэкенд обрабатывать трафик. Проверка состояния бывает:
- Активная: балансировщик регулярно пингует бэкенды (например, шлёт HTTP-запросы на конечную точку
/healthcheck). - Пассивная: балансировщик определяет статус бэкенда по первичному потоку данных. Например, L4-балансировщик может решить, что бэкенд сбоит, после трёх ошибок подключения подряд. А L7-балансировщик посчитает бэкенд сбойным, если было три ответа HTTP 503 подряд.
Балансировка
Да, балансировщики должны ещё балансировать нагрузку! Как будет выбираться бэкенд для обработки конкретного подключения или запроса при наличии рабочих бэкендов? Алгоритмы балансировки — это область активных исследований; они варьируются от таких простых, как случайный выбор и round-robin, до более сложных, учитывающих различия в задержках и нагрузках на бэкенды. Один из самых популярных алгоритмов благодаря производительности и простоте — power of 2.
Sticky-сессии
Для определённых приложений важно, чтобы запросы из одной сессии попадали на один и тот же бэкенд. Это связано с кешированием, временным сложным состоянием и прочими вещами. Есть разные определения термина «сессия», она может включать в себя HTTP-куки, свойства клиентского подключения и прочие атрибуты. Многие L7-балансировщики поддерживают sticky-сессии. Отмечу, что «липкость» сессии по своей сути хрупка (бэкенд, хостящий сессию, может умереть), так что держите ухо востро, проектируя систему, полагающуюся на sticky-сессии.
TLS-прерывание
Тема TLS и его роли в обработке и обеспечении безопасности межсервисного взаимодействия заслуживает отдельной статьи. Многие L7-балансировщики выполняют большой объём TLS-обработки, включая прерывания, проверку и закрепление сертификатов, обслуживание сертификатов с помощью SNI и т. д.
Наблюдаемость
Как я люблю повторять: «Наблюдаемость, наблюдаемость, наблюдаемость». Сети априори ненадёжны, и балансировщик часто отвечает за экспортирование статистики, отслеживание и журналирование: он помогает оператору понять, что происходит, и устранить проблему. У балансировщиков бывают самые разные возможности предоставления результатов наблюдения за системой. Самые продвинутые предоставляют обширные данные, включая числовую статистику, распределённую трассировку и настраиваемое журналирование. Отмечу, что продвинутая наблюдаемость достаётся не бесплатно: балансировщикам приходится выполнять дополнительную работу. Однако выгода от получаемых данных намного перевешивает относительно небольшое снижение производительности.
Безопасность и уменьшение последствий DoS
Балансировщики часто реализуют различные функции безопасности, особенно в краевой топологии развёртывания (см. ниже), включая ограничение скорости, аутентификацию и уменьшение последствий DoS (например, маркирование и идентификацию IP-адресов, tarpitting и пр.).
Конфигурация и уровень управления
Балансировщики нужно конфигурировать. В больших развёртываниях это превращается в важную обязанность. Система, конфигурирующая балансировщики, называется уровнем управления (control plane), её можно реализовать по-разному. За подробностями обращайтесь к статье.
И многое другое
Мы лишь прошлись по поверхности темы функциональности балансировщиков. Мы ещё поговорим об этом в части, посвящённой L7-балансировщикам.
Виды топологий балансировщиков
Теперь перейдём к топологиям распределённых систем, в которых развёртываются балансировщики. Каждая топология применима и к L4, и к L7.
Промежуточный прокси

Иллюстрация 4: топология балансировщика с промежуточным прокси
Топология с промежуточным прокси, показанная на иллюстрации 4, — один из самых известных способов балансировки. К таким балансировщикам относятся аппаратные решения Cisco, Juniper, F5 и др.; облачные программные решения вроде Amazon ALB и NLB, Google Cloud Load Balancer; чисто программные автономные решения вроде HAProxy, NGINX и Envoy. Преимущество схемы с промежуточным прокси заключается в простоте. Пользователи подключаются к балансировщику через DNS и больше ни о чём не беспокоятся. А недостаток схемы в том, что прокси (даже кластеризованный) — это единая точка отказа, а также узкое место при масштабировании. Кроме того, промежуточный прокси часто бывает чёрным ящиком, что затрудняет оперирование. Проблема возникла на клиенте? В физической сети? В самом прокси? В бэкенде? Иногда очень трудно определить.
Оконечный прокси

Иллюстрация 5: топология балансировщика с оконечным прокси
Топология на иллюстрации 5 — вариант топологии с промежуточным прокси, в которой балансировщик доступен через интернет. А в данном случае балансировщик обычно предоставляет дополнительные возможности «API-шлюза» вроде TLS-прерываний, ограничения скорости, аутентификации и продвинутой маршрутизации трафика. Преимущества и недостатки такие же, как у предыдущей топологии. Обычно невозможно избежать использования топологии с оконечным прокси в больших, открытых в интернет распределённых системах. Как правило, клиентам нужен доступ к системе по DNS с использованием различных сетевых библиотек, не контролируемых владельцем сервиса (нецелесообразно использовать прямо на клиентах встроенные клиентские библиотеки или топологии с побочным прокси, описанные в следующих разделах). Кроме того, по соображениям безопасности лучше иметь единый шлюз, через который в систему поступает весь интернет-трафик.
Встроенная клиентская библиотека
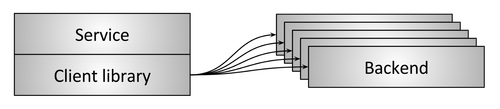
Иллюстрация 6: балансировка через встроенную клиентскую библиотеку
Чтобы избежать единой точки отказа или проблем с масштабированием, свойственных топологиям с промежуточным прокси, в более сложных инфраструктурах применяется встраивание балансировщика посредством библиотеки прямо в сервисы, как показано на иллюстрации 6. Библиотеки поддерживают разные функции, самые известные и продвинутые решения — Finagle, Eureka/Ribbon/Hystrix и gRPC (основанный на внутренней системе Google под названием Stubby). Главное преимущество решения на основе библиотеки в том, что функциональность балансировщика полностью распределяется по всем клиентам, а значит, единой точки отказа и трудностей масштабирования нет. Основной недостаток — библиотека должна быть реализована на каждом языке, используемом организацией. Распределённые архитектуры становятся настоящими полиглотами (многоязычными). В такой среде главное препятствие — стоимость реализации крайне сложной сетевой библиотеки на многих языках. Наконец, развёртывание обновления библиотеки в архитектуре большого сервиса превращается в огромную головную боль, и в результате в продакшен обычно работает куча разных версий библиотеки, что повышает операционную когнитивную нагрузку.
Учитывая сказанное, использовать библиотеки целесообразно в компаниях, которые могут ограничить разнообразие языков программирования и превозмочь трудности обновления библиотеки.
Побочный прокси

Иллюстрация 7: балансировка через побочный прокси
Топология с побочным прокси — вариант топологии со встроенной клиентской библиотекой. В последние годы эта топология была популяризирована в качестве service mesh. Идея в том, что можно получить все преимущества варианта со встроенной библиотекой без заморочек с языками программирования, но за счёт небольшого увеличения задержки при переходе к другому процессу. Сегодня самые популярные балансировщики с побочным прокси — это Envoy, NGINX, HAProxy, и Linkerd. Почитать подробнее о подходе можно в моей статье об Envoy, а также в статье об уровне данных service mesh и уровне управления.
Преимущества и недостатки разных топологий
- Топология с промежуточным прокси обычно проще всего в использовании. Её недостатки: единая точка отказа, трудности масштабирования и работа с чёрным ящиком.
- Топология с оконечным прокси аналогична предыдущей, но обычно именно её приходится применять.
- Топология со встроенной клиентской библиотекой имеет лучшую производительность и масштабируемость, но страдает от необходимости реализовать библиотеку на каждом языке и обновлять библиотеку по всем сервисам.
- Топология с побочным прокси работает не так хорошо, как предыдущая, но не имеет её ограничений.
Я считаю, что топология с побочным прокси (service mesh) в межсервисном взаимодействии постепенно сменит все остальные топологии. Схема с оконечным прокси всегда будет нужна до того, как трафик попадёт в service mesh.
Текущие достижения в L4-балансировке
L4-балансировщики всё ещё актуальны?
Мы уже говорили о преимуществах L7-балансировщиков для современных протоколов, а ниже обсудим их возможности подробнее. Означает ли это, что L4-балансировщики больше не актуальны? Нет! Хотя я считаю, что L7-балансировщики полностью заменят L4 в межсервисном взаимодействии, однако L4-балансировщики всё ещё очень актуальны на концах сети, потому что почти все современные большие распределённые архитектуры используют для интернет-трафика двухуровневую архитектуру L4/L7-балансировки. Вот преимущества размещения выделенных L4-балансировщиков перед L7-балансировщиками на концах:
- Поскольку L7-балансировщики выполняют значительно более сложный анализ, преобразование и маршрутизацию трафика приложений, они могут обрабатывать относительно небольшие объёмы трафика (пакетов в секунду и байтов в секунду) по сравнению с оптимизированным L4-балансировщиком. Поэтому L4 лучше использовать для защиты от определённых видов DoS-атак (например, SYN-потоков, общих атак пакетными потоками и др.).
- L7-балансировщики активнее разрабатываются, чаще развёртываются и имеют больше багов, чем L4-балансировщики. Наличие L4-балансировщика, проверяющего состояние бэкендов и отводящего трафик во время развёртывания L7-балансировщика, гораздо проще, чем механизмы развёртывания в современных L4-балансировщиках, обычно использующих BGP и ECMP (подробнее ниже). И наконец, поскольку у L7-балансировщиков вероятность багов выше из-за сложности, L4-балансировщик, проводящий трафик мимо сбоев и аномалий, повышает стабильность всей системы.
Дальше я опишу несколько разных схем L4-балансировщиков с промежуточным/оконечным прокси. Эти схемы неприменимы для топологий с клиентской библиотекой и побочным прокси.
Прерывающие TCP/UDP-балансировщики

Иллюстрация 8: прерывающий L4-балансировщик
Первый тип L4-балансировщиков, всё ещё используемый. Это тот же балансировщик, что и в ознакомительном разделе об L4-балансировщиках. Здесь два отдельных TCP-подключения: одно между клиентом и балансировщиком, второе между балансировщиком и бэкендом.
Прерывающие L4-балансировщики всё ещё используются по двум причинам:
- Они достаточно просты в реализации.
- Прерывание подключения близко к клиенту (низкая задержка) существенно влияет на производительность. В частности, если прерывающий балансировщик можно поместить близко к клиентам, использующим сети с большим количеством пропадающих пакетов (например, сотовые сети), то ретрансляции наверняка будут выполняться быстрее до того, как данные попадут в надёжный кабельный транзит по маршруту вплоть до пункта назначения. Иными словами, этот тип балансировщика можно использовать в точках присутствия (Point of Presence, POP) для прерывания необработанных TCP-подключений.
Балансировщики с TCP/UDP-транзитом
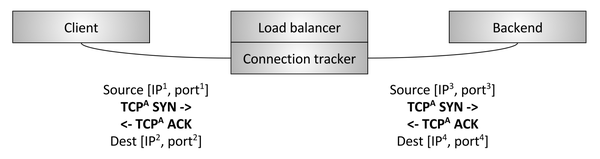
Иллюстрация 9: транзитный L4-балансировщик
Второй тип L4-балансировщика — транзитный — показан на иллюстрации 9. Здесь TCP-подключение балансировщиком не прерывается. Вместо этого после отслеживания подключения и преобразования сетевых адресов (NAT) пакеты для каждого подключения направляются на выбранный бэкенд. Сначала давайте определимся с отслеживанием подключения и NAT:
- Отслеживание подключения — это процесс отслеживания состояния всех активных TCP-подключений: проверка завершённости рукопожатия, был ли получен FIN, как долго простаивало подключение, какой бэкенд был выбран для подключения и т. д.
- NAT — это процесс, использующий данные отслеживания подключения для изменения информации об IP/портах для пакетов, когда они проходят через балансировщик.
С помощью отслеживания подключения и NAT балансировщик может пропускать транзитом в основном необработанный TCP-трафик от клиента к бэкенду. Допустим, клиент обращается на адрес 1.2.3.4:80, а выбранный бэкенд находится на 10.0.0.2:9000. Клиентские TCP-пакеты придут на балансировщик по адресу 1.2.3.4:80. Балансировщик поменяет IP и порт для пакетов на 10.0.0.2:9000, а также поменяет их исходящий IP и порт на свои собственные. Таким образом, когда бэкенд ответит на TCP-подключение, пакеты вернутся в балансировщик, который проведёт отслеживание подключения и NAT в обратном направлении.
Для чего использовать балансировщик этого типа вместо прерывающего, описанного выше? Ведь он более сложен. Есть несколько причин:
- Производительность и использование ресурсов. Поскольку транзитные балансировщики не прерывают TCP-подключения, им не нужно буферизировать его окно. Размер состояния, хранимый для каждого подключения, весьма невелик, и его можно извлечь с помощью эффективных поисков по хеш-таблице. Поэтому транзитные балансировщики обычно способны обработать куда больше активных подключений и пакетов в секунду, чем прерывающие балансировщики.
- Бэкенд может использовать разные алгоритмы управления перегрузками. Управление TCP-перегрузками — это механизм, с помощью которого конечные точки в интернете замедляют отправку данных, чтобы не перегрузить доступный канал и буферы. Поскольку транзитный балансировщик не прерывает TCP-подключение, он не участвует в управлении перегрузками. Это позволяет бэкендам использовать разные алгоритмы управления перегрузками в зависимости от конкретного приложения. Также это упрощает эксперименты с управлением перегрузками (например, недавнее выкатывание BBR).
- Можно использовать прямой возврат с сервера (Direct server return, DSR) и кластеризованную L4-балансировку. Транзитные балансировщики необходимы для более продвинутых схем L4-балансировки, таких как DSR и кластеризация с распределённым консистентным хешированием (рассмотрим ниже).
Прямой возврат с сервера (DSR)

Иллюстрация 10: L4 прямой возврат с сервера (DSR)
На иллюстрации 10 показан балансировщик с прямым возвратом с сервера. Он создаётся на базе транзитного балансировщика. По сути, DSR — это оптимизация, при которой входящие пакеты запросов проходят через балансировщик, а исходящие пакеты ответов обходят его и идут прямо к клиенту. Выгода от использования DSR в том, что при многих видах нагрузок трафик ответов многократно больше трафика запросов (например, это характерно для HTTP-запросов/ответов). Допустим, 10 % трафика — это запросы, а остальные 90 % — ответы, и тогда при использовании DSR будет достаточно балансировщика с производительностью в 1/10 пропускной способности системы. Поскольку балансировщики исторически очень дороги, такая оптимизация сильно снижает стоимость системы и повышает надёжность. DSR-балансировщики — развитие концепции транзитного балансировщика:
- Балансировщик всё ещё частично отслеживает подключение. Поскольку пакеты ответов не идут через балансировщик, его не интересует полное состояние TCP-подключения. Однако балансировщик может делать предположения о его состоянии, оценивая клиентские пакеты и применяя разные виды таймаутов.
- Для инкапсуляции IP-пакетов, идущих от балансировщика к бэкенду, вместо NAT балансировщик обычно использует общую инкапсуляцию маршрутов (GRE). Так что, когда бэкенд получает инкапсулированный пакет, он может декапсулировать его и узнать оригинальный IP и TCP-порт клиента. Это позволяет бэкенду отвечать напрямую, в обход балансировщика.
- Важная особенность DSR — то, что бэкенд участвует в балансировке. Ему нужен правильно сконфигурированный GRE-тоннель, и в зависимости от низкоуровневых особенностей сети могут понадобиться собственное отслеживание подключений, NAT и т. д.
Обратите внимание, что в схемах транзитного и DSR-балансировщика на балансировщике и бэкенде могут быть настроены разные способы отслеживания подключений, организации NAT, GRE и пр. Но это уже выходит за рамки статьи.
Устойчивость к сбоям благодаря высокодоступным парам (high availability pairs)

Иллюстрация 11: L4 устойчивость к сбоям благодаря HA-парам и отслеживанию подключений
Пока что мы рассматривали схему L4-балансировщиков без учёта окружения. Транзитному и DSR-балансировщику необходимо какое-то количество данных отслеживания подключений и состояний. А что, если балансировщик умирает? Если он был один, то все подключения, шедшие через него, оборвутся. В зависимости от ситуации это может сильно повлиять на производительность приложения.
Исторически сложилось, что L4-балансировщики представляли собой аппаратные решения разных производителей (Cisco, Juniper, F5 и пр.). Эти устройства очень дороги и обрабатывают большой объём трафика. Чтобы избежать обрыва всех подключений из-за сбоя единственного балансировщика, обычно делают два балансировщика, объединяя их в высокодоступные пары, как показано на иллюстрации 11. Схема типичной HA-пары устроена так:
- Два высокодоступных оконечных роутера обслуживают некоторое количество виртуальных IP (VIP). Эти роутеры объявляют VIP с помощью протокола граничного шлюза (BGP). У первичного роутера более высокий BGP-вес, чем у запасного, так что в нормальном режиме он обслуживает весь трафик. BGP — крайне сложный протокол, так что для простоты будем считать BGP механизмом, с помощью которого сетевые устройства объявляют о своей доступности, чтобы получать трафик от других устройств. А также будем считать, что каждое соединение имеет вес, который приоритизирует трафик через это соединение.
- Точно так же первичный L4-балансировщик уведомляет оконечные роутеры, что у него более высокий BGP-вес, чем у запасного балансировщика, поэтому в нормальном режиме он тоже обслуживает весь трафик.
- Первичный балансировщик кросс-коммутирован с запасным и делится с ним всеми данными по отслеживанию подключений. Так что, когда первичный умирает, запасной подхватывает обработку всех активных подключений.
- Два оконечных роутера и два балансировщика кросс-коммутированы. Поэтому если один из роутеров или один из балансировщиков умирает либо если BGP-объявление одного из них сбоит по каким-то иным причинам, запасной начинает обслуживать весь трафик.
Эта схема сегодня используется во многих интернет-приложениях с высоким трафиком. Но у неё есть несколько значительных недостатков:
- VIP’ы должны корректно шардиться по всем парам балансировщиков с учётом использования ёмкости. Если какой-то VIP превышает ёмкость одной пары, то этот VIP нужно разбить на несколько VIP’ов.
- Низкая эффективность использования ресурсов системы. 50 % ёмкости в нормальном режиме простаивает. Учитывая огромную стоимость аппаратных балансировщиков, это означает заморозку значительных средств.
- Сегодня в схемах распределённых систем предпочитают более высокую устойчивость к сбоям, чем обеспечивает схема «активный/запасной», т. е. система должна работать даже при многочисленных одновременных сбоях. А схема с высокодоступной парой балансировщиков уязвима к тотальному сбою, когда два балансировщика умирают одновременно.
- Проприетарные большие устройства крайне дороги и приводят к зависимости от производителя. Хотелось бы заменить все эти аппаратные решения горизонтально масштабируемыми программными, построенными на базе обычных серверов.
Устойчивость к сбоям и масштабирование с помощью кластеров с распределённым консистентным хешированием

Иллюстрация 12: L4 устойчивость к сбоям и масштабирование с помощью кластеров с распределённым консистентным хешированием
С середины 2000-х в больших интернет-инфраструктурах начали внедрять новые, сильно распараллеленные L4 балансировочные системы, как на иллюстрации 12. Их задачами были:
- Избавиться от недостатков схемы с высокодоступной парой.
- Перейти с проприетарных аппаратных балансировщиков на программные решения, построенные на основе обычных серверов и сетевых карт.
Такую схему можно описать как устойчивую к сбоям и масштабируемую с помощью кластеризации и распределённого консистентного хеширования. Работает она так:
- N оконечных роутеров присваивают всем Anycast VIP’ам одинаковый BGP-вес. Чтобы все пакеты из одного потока приходили на один оконечный роутер, используется выбор маршрута в зависимости от стоимости (ECMP). Поток — это обычно L4-кортеж из исходного IP/порта и целевого IP/порта. Если вкратце, ECMP — путь прохождения распределённых пакетов по нескольким сетевым соединениям с одинаковым весом с использованием консистентного хеширования. Хотя самим оконечным роутерам не слишком интересно, какие пакеты и куда прибывают, в целом предпочтительно, чтобы все пакеты из одного потока проходили через одну последовательность соединений, чтобы избежать сбоев пакетов, ухудшающих производительность.
- N L4-балансировочных машин сообщают оконечным роутерам обо всех VIP’ах с одинаковым BGP-весом. Снова применяя ECMP, роутеры стараются выбрать для потока какой-то один балансировщик.
- Каждая L4-балансировочная машина обычно частично отслеживает подключения, а затем с помощью консистентного хеширования выбирает для потока бэкенд. Для инкапсулирования пакетов, идущих от балансировщика к бэкенду, используется GRE.
- Затем для отправки пакетов напрямую от бэкенда к клиенту через оконечный роутер используется DSR.
- Сегодня активно разрабатываются более эффективные алгоритмы консистентного хеширования. Есть определённые компромиссы с точки зрения выравнивания нагрузки, минимизации задержки, разрывов при изменении бэкенда и избыточного использования памяти. Подробное рассмотрение этих вопросов выходит за рамки статьи.
Давайте посмотрим, как вышеописанная схема избавляет нас от недостатков, свойственных схеме с высокодоступной парой:
- По мере необходимости можно добавлять новые оконечные роутеры и балансировочные машины. Консистентное хеширование используется на каждом уровне для уменьшения количества потоков, на которые повлияет добавление новых машин.
- Использование ресурсов системы может быть сколь угодно высоким при сохранении достаточного запаса прочности и устойчивости к сбоям.
- Оконечные роутеры и балансировщики можно создавать на основе обычного оборудования, что обходится гораздо дешевле традиционных аппаратных балансировщиков.
Когда заходит речь об этой схеме, то обычно спрашивают: «Почему оконечные роутеры не общаются напрямую с бэкендами через ECMP? Зачем нам вообще нужны балансировщики?» В основном причина в защите от DoS и простоте работы с бэкендами. Без балансировщиков каждый бэкенд вынужден использовать BGP, и к тому же было бы гораздо сложнее проводить развёртывание.
Сегодня все системы L4-балансировки перенимают эту схему (или один из её вариантов). Два самых известных примера — Google Maglev и Amazon Network Load Balancer (NLB). Пока не существует OSS-балансировщика, использующего эту схему, но я знаю, что одна компания планирует выпустить такой в 2018-м. Жду с нетерпением, потому что современный L4-балансировщик — важная часть отсутствующего OSS при работе с сетью.
Текущие достижения в L7-балансировке
Прокси-войны — это практически буквально прокси-войны. Или «войны прокси». Nginx плюс, HAProxy, linkerd, Envoy, все буквально сражаются с этим. И proxy-as-a-service/routing-as-a-service SaaS-вендоры тоже повышают планку. Очень интересные времена!
— @copyconstruct
И действительно, в последние годы мы наблюдали возрождение разработки L7-балансировщиков/прокси. Это очень хорошо согласуется с движением в сторону микросервисных архитектур в распределённых системах. Эффективно управлять сетями, склонными по своей природе к сбоям, становится тем труднее, чем чаще они используются. Более того, расцвет автомасштабирования, контейнерных диспетчеров и прочих инструментов означает, что времена предоставления статичных IP в статичных файлах давно прошли. Системы не только активнее используют сети, они становятся гораздо динамичнее, требуют от балансировщиков больше функций. В этой части мы кратко рассмотрим направления, которым уделяется больше всего внимания при разработке современных L7-балансировщиков.
Поддержка протоколов
Современные L7-балансировщики привносят явную поддержку многочисленных протоколов. Чем больше балансировщик знает о трафике приложения, тем более сложные действия он может с ним выполнять, опираясь на данные наблюдений, продвинутую балансировку и маршрутизацию и т. п. Например, Envoy явно поддерживает парсинг L7-протоколов и маршрутизацию для HTTP/1, HTTP2, gRPC, Redis, MongoDB и DynamoDB. И в будущем наверняка будут добавляться новые протоколы, включая MySQL и Kafka.
Динамическая конфигурация
Как уже говорилось, всё более динамическая природа распределённых систем требует вложений в создание динамических и реактивных систем управления. Один из примеров такой системы — Istio. Подробнее почитать об этом можно здесь.
Продвинутая балансировка
L7-балансировщики сегодня часто имеют встроенные возможности продвинутой балансировки, такие как таймауты, повторные попытки, ограничение скорости, разрыв цепи (circuit breaking), теневое копирование (shadowing), буферизация, маршрутизация в зависимости от содержимого и др.
Наблюдаемость
Развёртываемые сегодня всё более динамические системы становится всё труднее отлаживать. Пожалуй, самая важная функция современных L7-балансировщиков — предоставление надёжных данных наблюдений, характерных для конкретных протоколов. Численная статистика, распределённые трейсы и настраиваемое журналирование сегодня нужны практически любому решению по L7-балансировке.
Расширяемость
Пользователям современных L7-балансировщиков часто нужна возможность легко их расширять и добавлять свою функциональность. Это делается с помощью написания подключаемых фильтров, которые загружаются в балансировщик. Также многие балансировщики поддерживают скрипты, обычно Lua.
Устойчивость к сбоям
Я довольно много написал выше об устойчивости L4-балансировщиков к сбоям. А что насчёт L7-балансировщиков? В целом с ними можно работать как с расширяемыми и не хранящими состояние (stateless). Можно легко горизонтально масштабировать L7-балансировщики с помощью обычного ПО. Более того, обработка и отслеживание состояний, выполняемые L7-балансировщиками, гораздо сложнее, чем это делают L4. Создание высокодоступной пары L7 теоретически возможно, но очень трудоёмко.
В целом в сфере L4 и L7 индустрия переходит от высокодоступных пар к горизонтально масштабируемым системам, объединяемым с помощью консистентного хеширования.
И прочее
L7-балансировщики развиваются ошеломляюще быстро. Например, вот что предлагает Envoy.
Глобальная балансировка и централизованный уровень управления

Иллюстрация 13: глобальная балансировка
В будущем всё больше станут использовать отдельные балансировщики в виде типовых устройств. Я считаю, что все реальные инновации и коммерческие возможности связаны с управлением. На иллюстрации 13 приведён пример системы глобальной балансировки. Здесь происходит несколько важных событий:
- Каждый побочный прокси общается с бэкендами в трёх разных зонах (A, B и C).
- Как видите, 90 % трафика отправляется в зону C, а по 5 % — в A и B.
- Побочный прокси и бэкенды периодически сообщают о своём состоянии глобальному балансировщику. Это позволяет ему принимать решения с учётом задержки, стоимости, нагрузки, текущих сбоев и т. д.
- Глобальный балансировщик периодически конфигурирует каждый побочный прокси на основе текущей информации о маршрутизации.
Глобальный балансировщик сможет решать всё более сложные задачи, не доступные ни одному отдельному балансировщику. Например:
- Автоматически определять и маршрутизировать в обход зональных сбоев.
- Применять глобальные политики безопасности и маршрутизации.
- С помощью машинного обучения и нейросетей определять и снижать влияние аномалий трафика, включая DDoS-атаки.
- Предоставлять централизованный интерфейс и визуализации, позволяющие определять состояние системы и управлять ею в совокупности.
Чтобы глобальная балансировка стала возможна, балансировщик, используемый в качестве уровня передачи данных, должен обладать сложными возможностями динамического конфигурирования. Подробнее читайте об этом в моих статьях: 1 и 2.
Эволюция от аппаратных до программных решений
Пока что я лишь мельком сравнивал аппаратные и программные решения, в основном в контексте высокодоступной пары L4-балансировщиков. Каковы тенденции в этой сфере?
Я пробовал новый OSI-стек из восьми программных уровней. Думаю, это что-то подобное:

— @infosecdad
Конечно, это юмористическое преувеличение, но в этом сообщении как раз и собраны современные тенденции:
- Исторически роутеры и балансировщики представляли собой крайне дорогие проприетарные аппаратные решения.
- Постепенно большинство проприетарных L3/L4 сетевых устройств были заменены обычными серверами, типовыми сетевыми картами и специализированным ПО на основе таких фреймворков, как IPVS, DPDK и fd.io. Современный сервер из дата-центра стоимостью меньше 5 тыс. долларов легко может заполнить сетевую карту на 80 Гбит/с очень маленькими пакетами, если использовать Linux и пользовательское приложение, написанное с помощью DPDK. При этом дешёвые и простые машрутизаторно-коммутаторные ASIC, способные выполнять ECMP-маршрутизацию при поразительной суммарной пропускной способности и скорости передачи пакетов, ставятся в типовые маршрутизаторы.
- Сложные программные L7-балансировщики вроде NGINX, HAProxy и Envoy тоже быстро развиваются и вторгаются в сферы, которые раньше были вотчиной вендоров вроде F5. Так что и L7-балансировщики активно движутся в сторону типовых программных решений.
- В то же время движение самой индустрии в сторону IaaS, CaaS и FaaS, используемых основными облачными провайдерами, означает, что всё меньше инженеров будут разбираться в работе физических сетей (все эти «чёрная магия» и «то, о чём нам больше не нужно знать»).
Заключение и будущее балансировки
Подведём итоги:
- Балансировщики — ключевой компонент современных распределённых систем.
- Балансировщики делятся на две основных категории: L4 и L7.
- Обе категории актуальны для современных архитектур.
- L4-балансировщики мигрируют в сторону горизонтально масштабируемых, распределённых, консистентно хешируемых решений.
- Недавно начали активно разрабатывать L7-балансировщики благодаря распространению динамических микросервисных архитектур.
- Будущее за глобальной балансировкой и разделением на уровни управления и уровни передачи данных, здесь стоит ожидать появления главных инноваций и коммерческих возможностей.
- Индустрия активно движется в сторону типовых OSS-аппаратных и программных решений. Я считаю, что традиционные вендоры вроде F5 в первую очередь окажутся заменены OSS-программными решениями и облачными вендорами. Традиционные производители маршрутизаторов и коммутаторов вроде Arista/Cumulus/и пр. имеют более прочные позиции в on-premise развёртываниях, но в результате тоже будут заменены публичными облачными вендорами и их физическими сетями.
Я считаю, что мы живём в очень увлекательное для сетевой индустрии время! Переход к OSS и программным решениям в большинстве систем на порядки ускоряет циклы итераций. Более того, по мере роста динамичности распределённых систем благодаря «бессерверным» парадигмам в равной степени будут усложняться и лежащие в их основе сети и балансировочные системы.
Комментариев нет:
Отправить комментарий