
Мы продолжаем цикл из 27 статей на основе его лекций:
Тренинг FastTrack. «Сетевые основы». «Понимание архитектуры Cisco». Эдди Мартин. Декабрь, 2012
Тренинг FastTrack. «Сетевые основы». «Свитчи от Cisco». Эдди Мартин. Декабрь, 2012
Тренинг FastTrack. «Сетевые основы». «Основы маршрутизации». Эдди Мартин. Декабрь, 2012
Тренинг FastTrack. «Сетевые основы». «Ценность роутеров Cisco». Эдди Мартин. Декабрь, 2012
Тренинг FastTrack. «Сетевые основы». «Основы дата-центров». Часть 1. Эдди Мартин. Декабрь, 2012
И вот пятнадцатая из них.
Тренинг FastTrack. «Сетевые основы». «Основы дата-центров». Часть 1. Эдди Мартин. Декабрь, 2012
Зачем Cisco дата-центры? Наша компания и дата-центры – это действительно интересная история! И у меня есть воспоминания, которые могут это подтвердить. Я был парнем из IP-телефонии, специалистом в области передачи голоса, «парень-телефонист», как меня называли в моей команде, когда мы начали работать над тем, что я сосбствено называю дата-центром.
Это случилось в 2002 году, состоялось собрание нашей команды, Cisco как раз тогда объявила о приобретении компании Andiamo, и мы собирались начать продавать оптоволоконные свитчи, работающие совсем по другому протоколу, нежели Ethernet. Нас было всего 12 инженеров по программному обеспечению, они обсуждали это всё и я, откровеннно говоря, не очень слушаи их, общаясь с коллегой, и один из них сказал, что ничего не знает об этом волокне. Я повернулся и сказал, что самая важная вещь, которую нужно знать об этом, это та, что оптоволоконный кабель пишется «FIBRE», а не «FIBER». На мои слова тут же отреагировал наш старший инженер, который сказал: «О, ты, видимо, много знаешь об этом, ты настоящий специалист»! Я понял, что лучше мне было держать язык за зубами и не умничать, так как несколько следующих месяцев я выяснял, во что мы попали и как из этого «выкарабкиваться». Я должен был стать небольшим специалистом в этом, до того, как у нас появится готовая модель и все эти другие вещи, одним из тех, кто передаст эти знания своей группе.

Что я сделал. Первая вещь, которая предстояла мне, это узнать о конкурентах. Я отправился в Денвер, штат Колорадо, где собирался принять участие в мастер-классах компании McDATA. Эта компания была провайдером №1 в использовании, как они говорили, больших свитчей класса «директор». Когда я позвонил им и сказал, что я из Cisco, они ответили, что не проводят мастер-классов, в которых я могу принять участие. Вероятно, так как мы уже анонсировали о своих планах и эта компания не была сильно рада этому. Я сообщил об этом моему боссу, на что он сказал: «Я ничего не хочу знать, прояви всю свою креативность, чтобы туда попасть»! Я снова позвонил в McDATA и сказал, что я консультант, но я не могу консультировать клиентов по поводу того, в чём сам не разбираюсь. Мне ответили: «Ну что же, в таком случае у нас есть мастер-класс специально для вас»! Итак, мне пришлось снять с себя все опознавательные знаки Cisco и отправиться туда.
Я узнал там много интересного. Когда я позвонил одному из моих коллег, который занимался оптоволоконной связью, и тот спросил, что я могу сказать об этом всём сейчас, то я сказал ему, что сейчас, в 2002, чувствую себя так, словно вернулся в 1995 год. Эти свитчи имели лишь небольшой спектр опций, но это была очень надёжная и высокоскоростная связь, по меркам того времени, но внутри всех этих коробок не было никаких служб и сервисов! Я прошёл недельный курс обучения, и мы разбирали и собирали свитч серии 6140. Обучение мне очень понравилось, и в субботу я вылетел обратно. Когда я пришёл в воскресенье на работу и увидел наш новый свитч серии MDS 9500, то понял, что с таким оборудованием мы просто убьём весь рынок наших конкурентов!
В то время мы были совершенно другими людьми, мы вели совсем другие дискуссии, оптическое волокно только выходило на рынок, мы реализовывали множество новых проектов в области виртуализации, внедряли VLAN. Как раз тогда Cisco приобрела технологию VSANs (технологию создания виртуальных хранилищ), которую никто не создал до тех пор. Но как это всё мы могли объяснить? Да, мы могли сказать, что мы внедрили VSANs. Но у нас спрашивали: «Какой такой VSANs? Что за VLAN»? Люди, с которыми мы говорили, даже не знали о том, чем занимается Cisco в плане сетей. Большинство из них считало, что Cisco это компания, которая доставляет продукты для построения сетей по тому же принципу, что и компании, занимающиеся доставкой еды из магазинов. Они не знали о наших возможностях, они не знали о том, кто мы есть. И что мы сделали? Мы начали нанимать людей из различных EMS компаний по всему миру, которые занимались со всем другими вещами, и я работал с ними и другими командами, обучая их нашим премудростям. И я узнал ужасно много о дата-центрах, как о нашей будущей перспективе, оказывается, если взять общий IT-бюджет, то 60% этого бюджета тратиться в дата-центрах! Cisco не могла даже представить себе подобного! Наша компания расширялась на 45-50% в год, но мы могли «ловить только половину рыбы» в сфере организации дата-центров, поэтому решили вкладывать средства в это новое перспективное направление рынка, то есть захватить «рыбные места» и принести ценные разработки в них.
Cisco проникла на рынок дата-центров как раз перед созданием технологии виртуальных машин VMware, поэтому мы начали внедрять продукты для использования этой технологии при создании центров обработки информации. Это было наиболее удачное время и наиболее подходящая возможность для использования виртуализации. Но я хочу сказать, что мы поступили не слишком разумно, вкладывая огромные суммы в создание серверов для клиентов на протяжении последних 15 лет. Но перейдём непосредственно к нашей теме. Начнём с приложений – по степени своей важности приложения располагаются на вершине требований, предъявляемых к сетевому оборудованию. Если Вы вице-президент и Вам нужно обеспечить 12% рост своей компании без привлечения дополнительного персонала, Вам необходимо использовать более продуктивные и функциональные приложения. Сегодня Вы можете купить готовый программный продукт, сделанный на основе платформы для самостоятельной разработки приложений salesforce.com, но как поступить, если Вам нужно создать что-то уникальное для своих внутренних потребностей? Вы должны быть готовы к тому, что необходимо будет вложить много денег в разработку того, что нужно именно Вашему бизнес-проекту, но Вы сможете потом им владеть.
Пусть это будет приложение для отдела продаж. И первое, что там должно быть это база данных, в которой будут содержаться данные всех аккаунтов. И мне необходимо будет определить требованию к хранилищу, которое будет хранить и обрабатывать все эти данные, иметь возможность создания резервных копий и т.д. И для этого мне потребуется сеть, 2 свитча, которые соеденят меня с хранилищем SAN. Затем мне понадобятся серверы, которые могут быть с ОС Windows, Linux или Unix, в зависимости от прочего ПО, необходимого для работы приложений.

И если у меня есть серверы, то мне ещё понадобятся два устройства балансировки нагрузки серверов SLB и 2 файервола для защиты. И далее я должен сделать это всё доступным через IP-сеть, где каждый сможет воспользоваться этим приложением. Всё это вам необходимо, и всё это стоит денег.

Теперь поговорим о производстве. Мы собираемся продать больше виджетов, значит мы должны производить больше виджетов. Но мы не собираемся строить больше производственных мощностей для этого. Мы должны сделать более умным текущее производство, оптимизировать его. И опять мы обратимся к приложениям, возможно к тем, которые помогут обеспечить своевременную доставку или каким-либо другим. Но это будет по сути аналогичная инфраструктура рядом с нашей, которая будет включена в нашу IP-сеть.

Обслуживание клиентов, давайте теперь поговорим о нём. Возможно мы захотим развернуть какие-то приложения, которые помогут нам их обслуживать. И мы развернём третью инфраструктуру аналогичным образом и подсоединим её к нашей IP-сети.

Почему мы их делаем разрозненными? Контроль, решение определённой задачи, различные источники финансирования, правильно? И я могу их сделать при помощи оборудования от разных производителей. Потому что опять, тот, кто принимает решение по инфраструктуре для работы какого-то приложения, может решить на чём она будет работать. Разные типы серверов и всего остального могут потребоваться. Всё финансируется по-разному. И разные технические проблемы здесь могут быть.
SAN использует Fiber Channel Adapter Protocol для работы, который работает здесь, в адаптерах главной шины. Это решение продаётся в целостном виде. И было продано множеству производителей — EMC, HP, HDS, NetApp. Оно со временем прошло сертификацию, в нём используются свитчи Brocade или McDATA, которые стоят не больше, чем «налог». Так как стоимость такого решения может составлять 3 миллиона долларов. Никто не переживает о стоимости двух свитчей. SAN как бы заплатили «налог» за использование свитчей сторонних производителей. И применение этих свитчей обуславливалось тем, что они обеспечивали достаточно быстрое соединение серверов и хранилища. Но в хранилище не было никакой интеллектуальности. И потому им заинтересовались EMС, HP, HDS, netApp, так как 80% их дохода — это разработка приложений для существующих аппаратных решений, которые являются для них лишь путём к продаже.
И Cisco решили также принять участие. Но дело в том, что оптоволоконный протокол — «жесткий» протокол, непрощающий, гарантирующий очень быструю транспортировку огромного объёма информации в нужное место, очень крутой протокол, но совсем нетакой, как Ethernet. Когда Вы подключаетесь к оптоволоконному свитчу, происходит трёхступенчатый процесс подключения, называющийся: FLOGI (fabric login), PLOGI (port login), и PRLI (process login). Вы подключаетесь к «фабрике», волоконной сети. И если мне необходимо «представить» новый сервер в хранилище SAN для всех остальных, подключить его, все процессы останавливаются, никто не может воспользоваться сетью, пока осуществляется процесс F логин. Что происходит с приложениями? Они останавливают свою работу. Потому, если я разверну подобную инфраструктуру, я должен быть уверен, что в неё не будут добавляться никакие дополнительные серверы. Я захочу держать их независимо. Вот почему, если решение небольшое — они покупали небольшие свитчи Brocade, а для более крупных — McData. Вот и всё. Они не сильно заморачивались. 80% бизнеса McData было сосредоточено здесь, они обеспечили специальные цены и фактически ими владела EMC.
Вот почему Cisco решили принять участие, так как мы думали, что можем изменить это. Cisco принялось «раскачивать лодку», разрабатывая технологию интеллектуального процесса управления трафиком. Так как все строили эти инфраструктуры по одному типу, множество людей. Люди покупали хранилища для множества задач, подумайте только, я покупаю хранилище на 20 ТБ здесь, на 10 ТБ здесь и на 8 ТБ здесь. И какова моя утилизация этих хранилищ? 40%! Представьте, Вы приходите к CFO и говорите, мы хотим потратить ещё полтора миллиона долларов и купить ещё хранилище, так как нам нужно больше пространства, но мы утилизируем текущее лишь на 40%. Не говорите ему такого, не говорите! Это всё-равно, что купить галлон молока (3,78 литра), выпить 2 больших стакана и сказать, когда осталось более, чем половина бутылки, что нам нужно купить ещё. Нам не хочется этого делать, но это то, как эти люди делают, это неэффективно. Порты на SAN-свитчах заполнены на менее, чем 40%. Мы покупаем их, но мы их не используем.
И худшим, что могло произойти в этом случае, стало появление многоядерных процессоров в серверах. Каждые 3 года люди покупали новые серверы, обновляя старые, но новые серверы имели процессор намного более мощный, а цена оставалась прежней. Получалось, что Ваши приложения не требуют такой мощности для работы, им достаточно производительности старых процессоров, но Вы покупали новые серверы с многоядерными процессорами, которые Вы не способны были загрузить на полную мощность. Что происходило в этом случае с сервером? Его показатель утилизации падал, падала его эффективность. Мы достигли значений 10-15% на некоторых серверах, потому что развёртывали всего 1 приложение на сервере. SLB использовались на 40% мощности, файерволы на 40% мощности и так далее. Но нам нужно было иметь несколько серверов для обеспечения надёжности за счёт избыточности, а также, чтоб получить возможность масштабирования.
В то время, как свитчи LAN были утилизированы на более, чем 80%, так как мы их виртуализировали и использовали для нескольких приложений. У меня есть одно приложение и ему нужен порт, я создаю для него VLAN, потом у меня появляется второе приложение, которое также нуждается в порте и я создаю второй VLAN, преимущество этой технологии в том, что на один порт я могу назначить сколько угодно VLAN. И потому мне не нужно покупать новый свитч каждый раз, когда мне требуется новый VLAN. Мы виртуализировали это много лет назад, в средине 90-х.
Виртуализация случилась и здесь. Мы «пропихнули» эту технологию в сегмент дата-центров и назвали её «консолидацией свитчей путём виртуализации». Мы выпустили на рынок свитчи MDS 9500 и объявили клиентам, что им стоит воздержаться от покупки всей этой «мелочи», обслуживающей по одному порту. Мы предложили им приобрести одно большое устройство, которое могло создавать виртуальные сети любого масштаба, и назвали это технологией VSAN. Я объединю на рисунке три свитча SAN в один свитч VSAN.

Самая большая наша проблема не была технической, а заключалась в том, как объяснить клиентам эти технологии. И первые продажи наших свитчей начались только в декабре 2002 года. Я даже провёл двухдневный мастер-класс по организации хранилищ, чтобы объяснить преимущества использования виртуализации. И тогда VMware начал обретать популярность, некоторые из нас возможно помнят это. Тогда они, достаточно умные и бесстрашные, возможно они даже были пьяны, когда сделали это в первый раз, додумались до того, что можно виртуализировать сервер. Вместо того, чтоб исполнять одно приложение на одном сервере, мы можем загрузить программу на него, которая называется гипервизор и запустить множество приложений на одном сервере независимо друг от друга. Один физический сервер смог одновременно работать с приложениями Microsotf, приложениями Linux и программами других производителей. Раньше для этого потребовался бы отдельный сервер для Microsotf, отдельный для Linux и так далее. Тогда люди вспомнили о многоядерных процессорах и сказали: «О, вот теперь они понадобятся»! Технологию VMware стали использовать для виртуализации серверов.
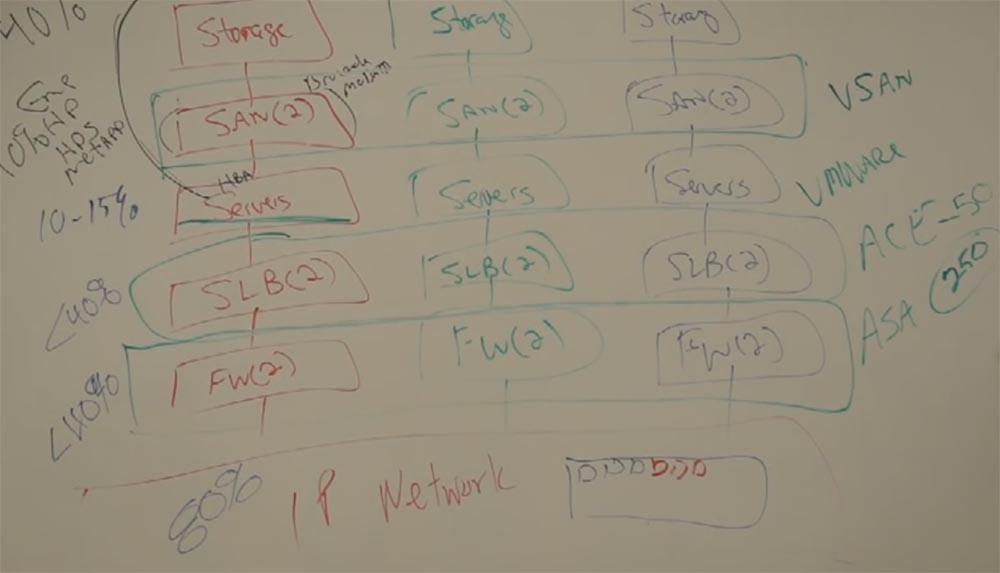
Теперь рассмотрим устройства SLB, которые Cisco решила заменить модулем ACE. Этот модуль, кстати, довольно дорогой, вошёл в состав свитча Catalist 6500 и обеспечивал равномерное распределение нагрузки на сервер. ACE, Application Content Engine, расшифровывается как «движок для содержимого приложений», обеспечил балансировку нагрузки. Мы разместили в 1 свитче 50 независимых виртуальных ACE, 50 независимых балансировщиков нагрузки на одном «лезвии», и клиентам больше не нужно было покупать несколько физических SLB. Файерволы мы заменили одним модулем ASA, каждый из которых содержал до 250 виртуальных файерволов.
Каждый из виртуальных файерволов подчинялся правилам, которые Вы установили для конкретного приложения, то есть можно было защитить разными условиями 250 программ. Ну и производители хранилищ начали заменять его одним общим виртуальным пространством, VD Space.
Такая виртуализация является величайшим мировым изобретением. Мы устранили ситуацию, когда 60% бюджета IT тратилось впустую, на ненужные вещи. Повторю – мы начали с объединения физических устройств на основе виртуальных машин, чтобы затем виртуализировать весь процесс создания дата-центров. Как вы знаете, компания EMC приобрела технологию VMware и создала на её основе отдельную компанию, и Cisco была вынуждена выкупить её на IPO за 150 миллионов $. Знаете, я также вышел на IPO, но я не инвестировал 150 миллионов $, как Cisco. Я инвестировал всего лишь несколько тысяч долларов, купив несколько долей VMware. И само собой, что прийдя к ним и сказав: «Я Эдди, я хочу знать все Ваши секреты». Мне бы просто сказали: «Развернись и выходя от сюда постарайся, чтоб дверь не ударила тебя, проваливай». Вот, чтобы они сказали. Но не Cisco. Cisco пришла и сказала: «Мы инвестировали 150 миллионов $, мы владеем долей и хотим знать всё, что происходи за кулисами». И они покажут им. И потому у Cisco есть преимущество подглянуть то, куда кто идёт.
Cisco выступала «донором» для многих IT-компаний. В руководстве компании всегда были люди, которые мыслили перспективно и расширяли сферу нашего влияния, вкладывая в это средства. Эти 150 миллионов долларов не были критической суммой для Cisco, но всё равно являлись для компании значительными капиталовложениями и составляли примерно от 4 до 6% капитализации.
Внедрение виртуальных технологий проводилось с 2000 по 2003 годы. Это было первой волной создания дата-центров.
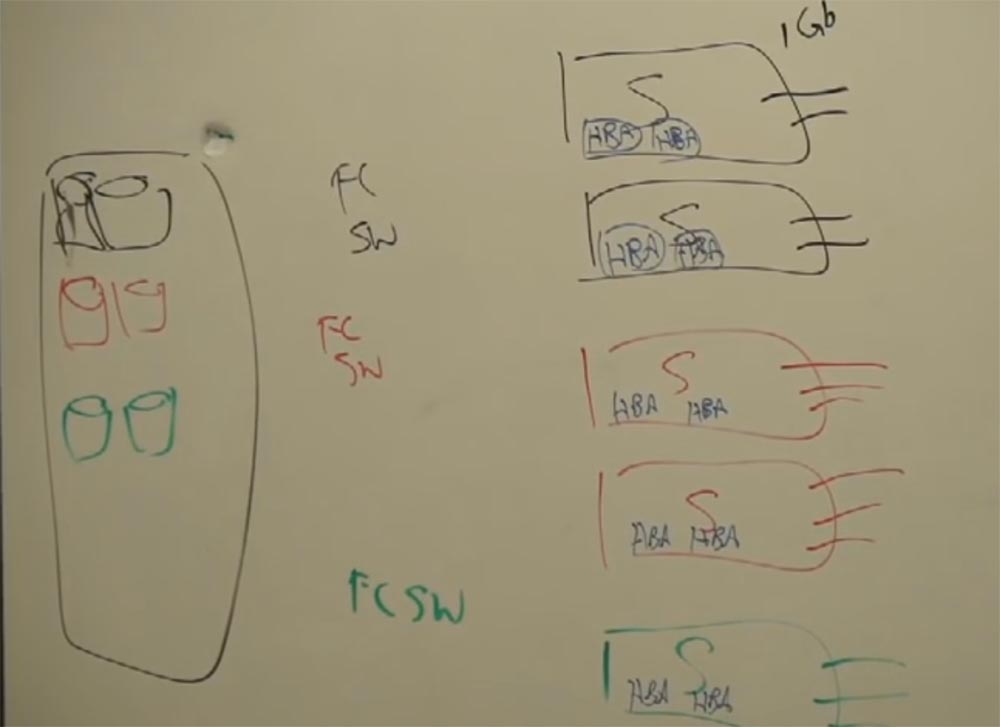
Пришло время подробно поговорить о виртуализации серверов. Я буду рассказывать Вам о вещах, которые важны лично для меня как специалиста. Предположим, у нас есть три группы, в каждой из которых есть по 2 многозадачных сервера для обработки множества приложений. Таких серверов может быть и больше, но мне не хватит доски, чтобы нарисовать их. В правой части доски нарисуем трёх разноцветных пользователей, каждый из которых использует приложения соответствующего цвета – черные, зелёные или красные. Это могут быть провайдеры интернета, компании, другие клиенты, пользующиеся сетью. Между этими людьми и серверами расположены все необходимые устройства – балансировщики трафика (SLB), файерволы и т.д. Каждый из серверов снабжён сетевой картой, которая обеспечивает 1 Гбит / с, и может быть 4, 6 или даже 8 карт в одном сервере.

С левой стороны от серверов расположено пространство сетевого хранилища (SAN). Для соединения с ним сзади наших свитчей расположены специальные сетевые карты, называемые хост-адаптерами, шины HBA, или Host Bus Adapter. Это не дешёвые модули, они стоят от 1500 до 2000 $ за каждый. Что они делают? Они как бы помещают всю поступающую от клиента информацию в капсулу, инкапсулируют её и служат для подключения сети. Такие же хост-адаптеры используют в компьютерах для обмена информацией между жёстким диском и процессором.
Внутри вашего компьютера расположен жёсткий диск, и что делает процессор, желая получить от него информацию? Он «завладевает» этим жёстким диском, подключаясь к нему через шину HBA! То же самое происходит и с сетью. Сервер хочет завладеть информацией, имеющейся в хранилище, и для этого нужны HBA. Они позволяют напрямую соединить сервер и хранилище по протоколу SCSI, которые в этом случае играют роль процессора и жёсткого диска компьютера. Между хранилищем и сервером расположены оптоволоконные свитчи, FCSW. Нарисуем их маркерами зелёного, красного и чёрного цвета.

Внутри хранилища я нарисую разноцветные массивы данных.
Какое преимущество от того, что все данные хранятся на одном массиве, похожего на холодильник с жесткими дисками? Какими свойствами они должны обладать и что обеспечивать? Безопасность и производительность обработки информации! Для этого мы должны продублировать эти массивы где-то далеко, то есть создать резервное хранилище информации. Для этого нужны соответствующие приложения для одновременной репликации и переноса информации отсюда туда.
Каким образом компании EMC удалось получить весь рынок, которым они сегодня обладают? Они придумали приложение SRDF, или «оборудование для удалённой синхронизации данных». Оно гарантирует, что когда данные с сервера поступают в массив нашего хранилища, то они одновременно попадают и в массив удалённого хранилища. То есть у пользователя имеются данные для аварийного восстановления, что обеспечивает непрерывность бизнес-процесса. EMC были первыми, кто смог это сделать.
Итак, наш хост-адаптер HBA «капсулирует» данные и отправляет их в массив хранилища. Cisco были первыми, кто объединил все свитчи FCS в один свитч серии MDS 9500. Мы первыми придумали виртуальный процесс обмена данными между сервером и хранилищем данных, создали VSANs. Итак, Вы покупаете 2 больших свитча и любой порт может быть любым VSAN, мы виртуализировали их. Собрали всё вместе, теперь требовалось меньше устройств.

Виртуализаия началась и люди начали думать, как её применить. Представьте себе, что два верхних сервера, объединённые в «чёрную» группу, загружены всего на 10-15% от своих возможностей. Это значит, что у нас есть достаточно процессорной мощности, которая не используется. Вот тут и появляется «софт» под названием гипервизор. Если Вы загружаете это программное обеспечение VMware в сервер, то оно оптимизирует использование процессоров.
Пусть у нас в каждом сервере имеется 2 процессора по 8 ядер, итого 16 ядер, и 384 ГБ оперативной памяти. При такой загрузке у нас используется всего 4 ядра из 16 и 48 ГБ ОЗУ, а остальные 12 ядер и память простаивают. Их можно использовать для обработки других приложений, и именно этим занимается гипервизор. Я отделяю нужные нам ресурсы в отдельный сервер с 4 ядрами и 16 ГБ ОЗУ и запускаю приложение на нём. Для этого не нужно покупать никакого дополнительного «железа», гипервизор встроен в наш сервер и активируется с помощью лицензии. В этом заключается ещё одно преимущество технологий виртуализации.
Допустим, что серверы красной группы работают с приложениями, которым нужно всего 2 ядра и 64 ГБ ОЗУ, но здесь установлена другая ОС. Что я делаю? Покупаю лицензию для создания ещё одного виртуального сервера и другой операционной системы, и теперь в серверах «чёрной группы» работают 2 операционные системы, с разделёнными каналами, и вторая ОС использует 2 нужных ей ядра и 64 ГБ памяти.
Я использовал простаивающие аппаратные мощности первой группы серверов и создал внутри них виртуальный сервер с другой ОС. И теперь серверы «красной группы» мне больше не нужны – их роль играет виртуальный «чёрный» сервер, который обрабатывает приложения физических «красных» серверов! Поэтому я их просто зачёркиваю.

Примемся за третью группу физических серверов, «зелёную». Здесь занято всего 4 ядра и 32 ГБ ОЗУ. Снова покупаем лицензию, создаём виртуальный сервер внутри первой группы, предаём ему из простаивающих мощностей 4 ядра и 32 ГБ памяти, которые нужны для обработки приложений «зелёной» группы, и отказываемся от неё тоже! «Зелёных» я тоже зачёркиваю.

То, что мы сделали – величайшая вещь в мире! Клиенты имели тысячи и тысячи серверов, которые больше простаивали, чем работали. Наше решение позволило им отказаться от лишнего «железа», они стали пользоваться нашей виртуальной технологией VMware, которая обеспечила работу сервера на полную мощность, и экономили свои деньги!
Вы все знаете о системе супермаркетов Wallmart, так вот они использовали 30000 серверов в своей инфраструктуре, да, это надёжно, но не все эти серверы были распределены, более половины из них находились в одном месте — дата-центре. Представьте, что каждые 3 сервера можно заменить одним при помощи технологии виртуализации. Сколько серверов я смогу отключить? Десять тысяч! Теперь Вы видите, насколько это великая вещь? Это самое великое изобретение десятилетия! В течение многих лет компании тратили 60% бюджета на увеличение количества сетевого «железа», чтобы обрабатывать свои приложения. А сколько приложений имеется в крупных компаниях? Тысячи!
Так мы использовали свой шанс. В середине 2000-х годов мы стали продавать серверы, разработанные специально под виртуализацию. И клиенты, которые были вынуждены обновлять парк своего «железа» каждые три года, получили возможность обновлять только программное обеспечение для VMware.
Мой отец долгое время служил в армии, он прыгал с парашютом и проделывал прочие сумасшедшие вещи, так вот, он часто мне говорил: «Эдди, лучше быть удачливым, чем хорошим»! Cisco были удачливыми. Насколько это было хорошо, я не знаю.
Повторюсь ещё раз – технология виртуализации сделала так, что клиент будто бы платил налоги на IT-сферу, а не делал в неё капиталовложения. То есть финансово это выглядело как очень умеренные затраты по сравнению с тем, что было раньше. Мы продаём клиенту набор «всё в одном», и это для него выгодно.
Когда-то очень давно я работал в компании, где был компактный сервер Compact серии 3000, и он имел два процессора частотой по 600 МГц. Я думал, что у меня есть величайшая вещь на свете, ведь я мог обрабатывать приложения аж двумя процессорами! Но на деле оказалось, что у меня 2 процессора, а приложение не знает, как их использовать. Потребовалось сменить три поколения программ, чтоб это стало возможным. Но это дало мне возможность чувствовать какое-то время себя хорошо. Но позднее увеличилось количество ядер и вот где по-настоящему пригодилась виртуализация.
Теперь же люди смогли экономить электроэнергию и место, занимаемое лишним «железом» в стойках. Раньше клиент хватался за голову и говорил: «О Боже, есть у меня появится ещё 2 новых приложения для моего бизнеса, мне придётся строить дата-центр»! Он даже был вынужден размещать новый дата-центр не в Калифорнии, потому что здесь не было достаточного количества электроэнергии! Это правда! В этом штате летом бывают веерные отключения. Вы не сможете разместить дата-центр здесь. Теперь мы дали возможность сэкономить деньги всем этим клиентам, и это действительно круто. Вот где Cisco были удачливы. Опять же, Вы должны видеть удачу и схватить её и удержать и это сделали в Cisco.
Вернёмся к нашим пользователям в правой части доски. Предположим, «красный» клиент обменивался со своим сервером данными на скорости 6-8 Гбит/с, а теперь напрямую соединяется с нашим «чёрным» сервером. К нему добавляется ещё «зелёный» клиент со своими приложениями, которые тоже требуют своей скорости. В результате этого наш сервер, который обеспечивал 8 Гбит (6-8 линков использовались, 2 из них были для управления) и был загружен на 40%, теперь загружен более чем на 80%! Где произойдёт эффект «бутылочного горлышка»? В пропускной способности подключений. О, это отстой. Отстой для всех, но не для Cisco. Итак, как пишется Ethernet? CISCO. Какой следующий шаг после 1 Gbps Ethernet? 10 Gbps Ethernet. И потому производители серверов начали делать специальные серверы, потому, как они увидели эти узкие места также. И что они сделали? Они не стали ставить ещё больше гигабитных карт, а установили на материнскую плату ещё один модуль, который обеспечивает два 10 Гбит / с подключения, в результате чего стало возможным получить в сумме до 20 Гбит / сек или обеспечить отказоустойчивость. И так, если у нас 10 Гбит / с тут, то где нам нужно ещё обеспечить это? Внутри наших свитчей, которые расположены между этими клиентами и сервером.
А если к нам присоединится ещё один пользователь или даже несколько? Может ли Catalist 6500 выполнить эту задачу? Нет, ему не хватает на это мощности. Что мы должны сделать? Создать лучший свитч, разработать специальный проект для 10 Гбит / с подключений. Мы назвали его Nexus. Вот как появилась эта серия свитчей!

Nexus это «премиальный» сегмент свитчей, но они стоят не намного дороже серии Catalist 6500, однако обладали неоспоримыми преимуществами. Они позволили иметь множество 10 Гбит / с подключений по разумной цене. Мы выпустили Nexus 5000, 7000, но нам потребовалась большая плотность портов и мы предложили расширители «фабрики» называемые двухтысячными.

Но потом мы задумались, Ethernet произносится CISCO, мы сделали 10 Гбит / с Ehternet-подключения, но зачем нам вся эта другая оптоволоконная сеть, FCSW, работающая по другому протоколу? Для чего она нам нужна? Если кто-нибудь помнит, у IBM был такой протокол SNA, немаршрутизируемый протокол. Мы адаптировали его для наших нужд, что позволило пользователям сэкономить ещё больше денег. Cisco поступает так: мы берём один протокол, соединяем его с другим и заставляем работать в наших интересах. Это позволило нам заработать миллиарды долларов на продажах роутеров.

И Cisco сделала «коробку», к одному концу которой можно подсоединить оптоволоконный кабель, а к другому – кабель Ethernet. Нарисуем внизу трубу, или оптоволоконный канал. Она такая широкая, потому что пропускная способность оптоволокна больше, чем у 10 Гбит Ethernet. Мы поместили в неё канал меньшего диаметра, и назвали всё это FCOE, Fibre Channel over Ethernet, оптический канал сквозь эзернет. Это транспортный протокол. Благодаря ему там, где было 12 кабелей, осталось всего 2.
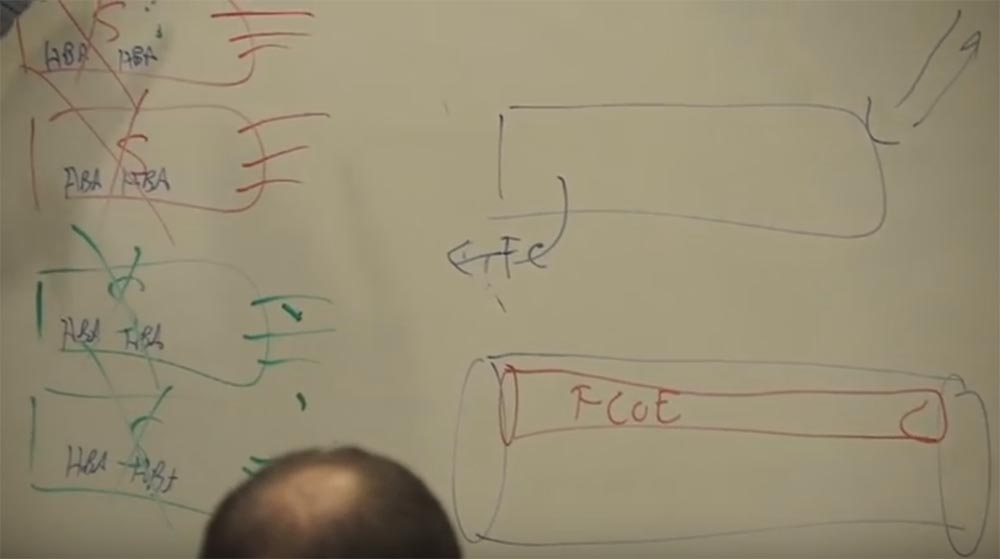
При этом снова произошла та же ситуация, которая возникала с другими нашими разработками. Мы внедрили эту технологию, когда для неё ещё не было стандарта, в полном объёме он был утверждён только в 2009 году. Фактически мы создали совершенно новый тип Ethernet – Эзернет для дата-центров. Это позволило отказаться от использования большей части оптоволоконных кабелей, соединяющих серверы с дата-центрами.
Можно сказать, что Cisco создали многоцелевые стандарты, которые упростили кабельную архитектуру. Почему мы так поступили? Потому, что это выделяет нас на фоне остальных. Вот на что был бы похож совершенный мир, если бы Вы начали в нём также. Мы были новичками в этой среде и мы создали MDS 9500, и мы продали их не очень много, но мы увидели, что у Nexus большие перспективы и начали работать в этом направлении и мы создали Fibre Channel over Ethernet. Который является стандартом уже долгое время. Почему мы это сделали? Потому, что мы могли продать больше Nexus свитчей. Мне это объяснил один парень из Cisco, который проработал там очень и очень долгое время и очень хорошо разбирается в бизнесе. И я попробую объяснить это Вам, использовав ещё одну демонстрационную доску, надеюсь люди в дальнем конце нашей комнаты…
Продолжение следует, ссылка появится здесь после того, как работа над переводом будет завершена.
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас оформив заказ или порекомендовав знакомым, 30% скидка для пользователей Хабра на уникальный аналог entry-level серверов, который был придуман нами для Вас:Вся правда о VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps от $20 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле? Только у нас 2 х Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 ТВ от $249 в Нидерландах и США! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?
Комментариев нет:
Отправить комментарий