 По просьбам трудящихся представляем новый материал из цикла статей об интеграции разнообразных IT-систем в инфраструктуре заказчика. На этот раз более подробно остановимся на таком симбиозе, как система мониторинга и ITSM-система.
По просьбам трудящихся представляем новый материал из цикла статей об интеграции разнообразных IT-систем в инфраструктуре заказчика. На этот раз более подробно остановимся на таком симбиозе, как система мониторинга и ITSM-система.
Что представляют из себя эти системы по отдельности рассказывать можно долго. Правильно настроенная и работающая система мониторинга помогает избежать многих бед или предотвратить их, а ITSM-система позволяет управлять IT-процессами и регистрировать события, случающиеся в инфраструктуре. Мы не будем углубляться в тонкости работы данных систем по отдельности, а изучим, как соединить данные системы на благо заказчика в целом и сервисной компании, обслуживающей IT-инфраструктуру, в частности.
В случае интеграции мониторинга нам, в первую очередь, интересно, чтобы события, зарегистрированные в системе мониторинга, алерты, инициировали создание инцидента в ITSM-системе.
Алерт — событие, зарегистрированное системой мониторинга в момент, когда устройство или сервис достигли установленного порогового значения.
Инцидент — любое событие, которое не является частью стандартных операций сервиса и вызывает или может вызвать прерывание обслуживания или снижение качества сервиса.
Рассматривать интеграцию будем на примере одних из наиболее популярных и востребованных систем на рынке — ServiceNow и Microsoft System Center Operation Manager (SCOM). Однако подход можно реализовать и на других подобных системах.
Есть два основных пути интеграции системы мониторинга и ITSM-системы.
1. Использование коннектора, так называемого MID-сервера. Так как ServiceNow — это облачная платформа, использование промежуточного звена является предпочтительным условием нормального функционирования такой связки.

2. Использование REST API (REpresentational State Transfer Application Program Interface). Большинство современных web-приложений, коим также является и ServiceNow, предоставляют пользователю такой интерфейс.

REST API — это стиль архитектуры программного обеспечения для построения распределенных масштабируемых веб-сервисов.
Каждый путь реализации имеет свои плюсы и минусы. В первом случае требуется установка MID-сервера, открытие определенных портов и так далее. Также требуется взаимодействие двух команд поддержки, что в некоторых случаях может быть затруднительно. Во втором случае нам нужен только аккаунт с определенными правами в ServiceNow и, в принципе, всё. Всю остальную работу можно выполнить силами команды мониторинга.
Взвесив все плюсы и минусы, а также оценив имеющийся опыт, было решено пойти по пути номер два, а именно использовать REST API.
Анализ исходного состояния
Итак, стояла задача автоматизировать поднятие инцидентов по событиям в системе мониторинга. В зависимости от источника события инциденты должны ранжироваться по приоритету и назначаться на определенные ответственные команды.
Для начала были проанализированы события в системе мониторинга. Выявлены некоторые закономерности, которые необходимо было учитывать при построении интеграции. Например, бывают случаи, когда по одному устройству приходит несколько алертов или по одной локации. Как правило, такие события группируются, и создается только один инцидент на всю группу.
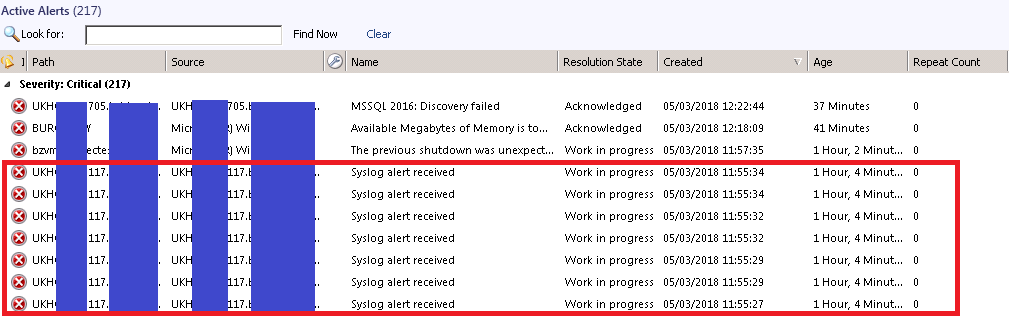
Определен список ответственных команд, а также составлен список приоритетов в зависимости от типа события.
Реализация
Основную часть работы будем проводить на стороне SCOMа, поэтому удобнее использовать PowerShell в связке с модулем OperationsManager, входящим в дистрибутив системы мониторинга. К ServiceNow будем обращаться по средствам REST API за определенными данными, а также для создания непосредственно инцидентов.
ServiceNow обладает довольно развитым программным интерфейсом (API) и позволяет практически полностью управлять системой. Нам же понадобится только метод Table API. Данный метод позволяет создавать, обновлять, читать и удалять записи в ServiceNow. В нашем случае это Table API – GET /api/now/table/, с помощью которого будем читать данные из ServiceNow, и Table API – POST /api/now/table/, с помощью которого собственно и будем добавлять новые инциденты.
Подробнее методы описаны тут docs.servicenow.com/bundle/geneva-servicenow-platform/page/integrate/inbound_rest/concept/c_TableAPI.html. В качестве параметров к методам передается структурированная хеш-таблица с данными, которые нам необходимы. На куске скрипта ниже видно какие параметры используются в нашем случае:
#Define Hash Table
$HashTable = @{
'u_snow_category' = 'Infrastructure';
'u_affected_user' = 'scom';
'caller_id' = 'scom';
'assignment_group' = $record.ResolverGroup;
'cmdb_ci' = $record.CI.name;
‘location' = $record.Location;
'short_description' = [System.Web.HttpUtility]::HtmlEncode($record.ShortDescription);
'description' = [System.Web.HttpUtility]::HtmlEncode($record.Description);
'impact' = $record.Impact;
"contact_type" = "Own Observation";
#Posting new incident
$RaisedIncident = Invoke-RestMethod -uri "$SNOW$SNOWtable`incident" -Headers $PostHeader -Method Post -Body ($HashTable | ConvertTo-Json);
На примере выше строка
$RaisedIncident = Invoke-RestMethod -uri "$SNOW$SNOWtable`incident" -Headers $PostHeader -Method Post -Body ($Body | ConvertTo-Json);
Непосредственно создает инцидент в ServiceNow, где:
"$SNOW$SNOWtable`incident" — адрес программного интерфейса, который в общем случае выглядит следующим образом CustomDomain.service-now.com/api/now/table/incident
$PostHeader — переменная передающая тип контента;
$ HashTable — непосредственно хеш-таблица с необходимыми данными.
Упрощенно алгоритм скрипта выглядит следующим образом:
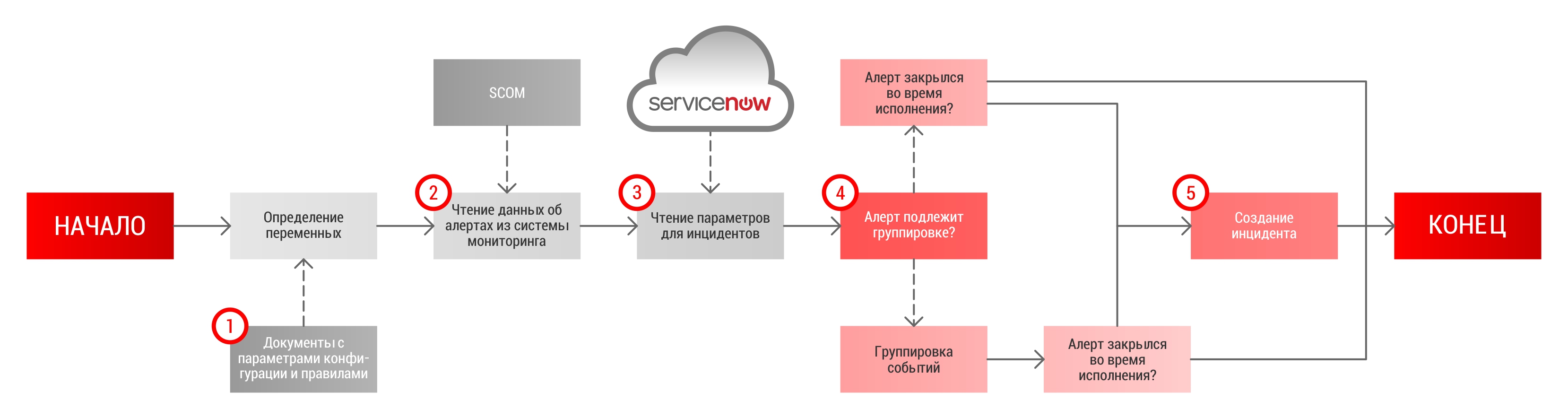
1. Чтение параметров окружения
Все переменные, которые читаем, определяем для всего скопа, чтобы в дальнейшем можно было обращаться к ним из функций.
Пример чтения переменных:
New-Variable -Name ScriptConfiguraion -Value (Get-Content '.\Configuration.txt' -Raw -ErrorAction Stop | ConvertFrom-Json -ErrorAction Stop) -Option AllScope, ReadOnly -ErrorAction Stop;
Помимо файла с конфигурационными настройками, нам понадобятся список правил, по которым мы будем определять принадлежность события к тому или иному приоритету и той или иной ответственной команды:
New-Variable -Name DefaultRules -Value (Import-Csv $ScriptConfiguraion.Configuration.Rules.DefaultRules -ErrorAction Stop) -Option AllScope, ReadOnly -ErrorAction Stop;
Пример файла с правилами в нашем случае выглядит следующим образом:
{
"Parameters":"",
"Properties":"Name",
"Expression":"{0} -match \"http\\://www\\.domainname\\.com/\"",
"ResolverGroup":"Application Team",
"Priority":"2"
},
Настройки для соединения с ServiceNow:
New-Variable -Name SNOW -Value $ScriptConfiguraion.Configuration.SNOW.APIURL -Option AllScope, ReadOnly -ErrorAction Stop;
New-Variable -Name SNOWtable -Value $ScriptConfiguraion.Configuration.SNOW.APITables -Option AllScope, ReadOnly -ErrorAction Stop;
New-Variable -Name GetHeader -Value (@{"Authorization" = "Basic " + [System.Convert]::ToBase64String([System.Text.Encoding]::UTF8.GetBytes($SNOWacc+":"+$SNOWaccPass))}) -Option AllScope, ReadOnly -ErrorAction Stop;
New-Variable -Name PostHeader -Value (@{"Authorization" = "Basic " + [System.Convert]::ToBase64String([System.Text.Encoding]::UTF8.GetBytes($SNOWacc+":"+$SNOWaccPass));"Content-Type" = "application/json"}) -Option AllScope, ReadOnly -ErrorAction Stop;
Если заметили, то пути к файлам, настройки, служебные данные мы берем из основного конфигурационного файла, который прочитали изначально и поместили содержимое в переменную $ScriptConfiguraion.
Далее подгружаем модули для работы с ServiceNow и SCOM:
Add-Type -AssemblyName System.Web -ErrorAction Stop;
Import-Module OperationsManager -ErrorAction Stop;
2. Чтение данных из системы мониторинга
Для выгрузки данных из SCOM необходимо установить подключение:
#Connecting to SCOM API
if(-not(Get-SCOMManagementGroupConnection | ?{$_.IsActive})){
foreach($ManagementServer in $ScriptConfiguraion.Configuration.SCOM.ManagementServers){
New-SCManagementGroupConnection $ManagementServer;
if(Get-SCOMManagementGroupConnection | ?{$_.IsActive}){
break;
}
}
if(-not(Get-SCOMManagementGroupConnection | ?{$_.IsActive})){
Write-CustomLog "Script failed to connect to all SCOM management servers [$($ScriptConfiguraion.Configuration.SCOM.ManagementServers)] supplied in the configuration file. Please review debug log for more info.";
exit;
}
}
И прочитать данные об алертах:
$AlertList = Get-SCOMAlert -Criteria "$($ScriptConfiguraion.Configuration.SCOM.AlertCriteria)";
На выходе в $AlertList у нас будет список всех алертов из SCOM удовлетворяющих критерию $ScriptConfiguraion.Configuration.SCOM.AlertCriteria. Мы задали следующие критерии:
(CustomField2 IS NULL OR CustomField2 = '') AND Severity = 2 AND ResolutionState <> 255
В CustomField2 в нашей инфраструктуре мы храним данные о номере инцидента. Таким образом, в будущем будет легко по номеру инцидента находить необходимый алерт, а также с помощью данного поля мы будем группировать инциденты для однотипных алертов.
3. Чтение данных из ITSM-системы
После того как получили данные об инциденте, необходимо прочитать информацию по CI (Configuration Item) — единице конфигурации в системе ITSM. Это необходимо для того, чтобы сопоставить данные из системы мониторинга с данными из системы ITSM и задать приоритет для создаваемого инцидента.
Кусок скрипта для выгрузки данных о CI выглядит следующим образом:
$CI = (Invoke-RestMethod -uri "$SNOW$SNOWtable`cmdb_ci" -Headers $GetHeader -Method Get -Body @{sysparm_query="nameLIKE$SourceObject";sysparm_fields='name,location,u_environment,u_service_level,sys_updated_on,install_status'}).result;
4. Группировка алертов по локации
Для группировки событий выполняем группировку всех алертов в SCOM по локации:
$Alerts = $Alerts | group Location;
И проверяем, есть ли инцидент по заданной группе в системе ITSM. Так как информацию по инцидентам мы заносим в базу SCOM, то проверять будем тоже на стороне SCOMа.
foreach($entry in ($OperationalData | ?{$_.GroupingType -eq 'LocationAndMonitorID'})){
if($entry.Location -eq $Location -and $entry.MonitorId -eq $MonitorId){
return(@{sysID=$entry.sysID;Number=$entry.Number});
}
}
5. Проверка статуса алерта по прошествии времени и создание инцидента
Последняя проверка перед поднятием инцидента — посмотреть не закрылся ли алерт, пока мы все проверяли.
($record.Alert.ResolutionState -ne 255){}
Ну и когда вся информация получена, поднимает непосредственно сам инцидент, как описано немного выше:
#Define Hash Table
$HashTable = @{
'u_snow_category' = 'Infrastructure';
'u_affected_user' = 'scom';
'caller_id' = 'scom';
'assignment_group' = $record.ResolverGroup;
'cmdb_ci' = $record.CI.name;
‘location' = $record.Location;
'short_description' = [System.Web.HttpUtility]::HtmlEncode($record.ShortDescription);
'description' = [System.Web.HttpUtility]::HtmlEncode($record.Description);
'impact' = $record.Impact;
"contact_type" = "Own Observation";
#Posting new incident
$RaisedIncident = Invoke-RestMethod -uri "$SNOW$SNOWtable`incident" -Headers $PostHeader -Method Post -Body ($HashTable | ConvertTo-Json);
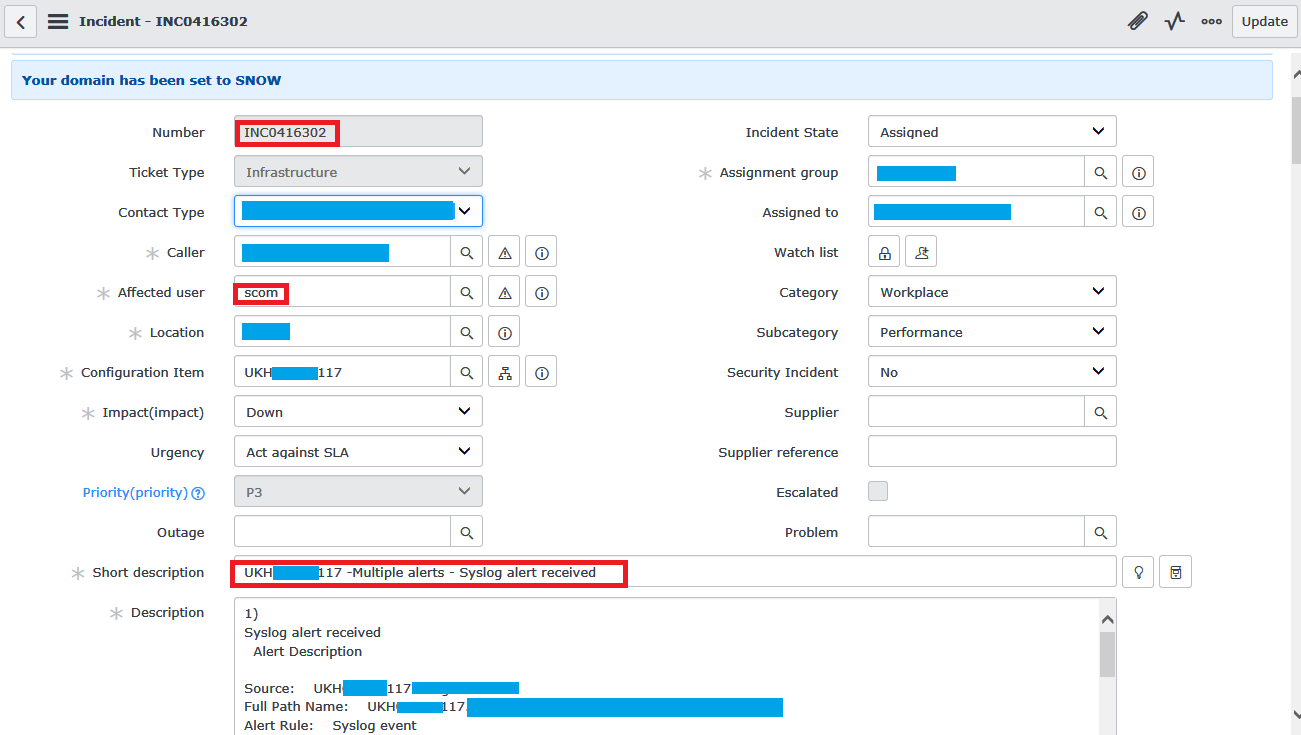
Не забываем обновить CustomField2, чтобы в последующем не лезть в ServiceNow за данной информацией.
$AlertUpdateResult = $Alert | Update-Alert -ParamStr "-CustomField2 'Raised' -CustomField3
'$($result['IncidentNumber'])'

Выводы
Как видите, в простом виде реализовать интеграцию с ServiceNow не так сложно. Если не вдаваться в детали, то вся интеграция сводится к запуску скрипта по расписанию, который выгрузит данные из системы мониторинга и на их основе поднимет инцидент в ITSM-систему. Далее инцидент поступит на обработку в Сервис Деск либо напрямую ответственной команде.
При внедрении интеграции сокращается общее время реакции на события в системе, что позволяет вовремя реагировать на возникшие проблемы и своевременно их устранять. Уменьшаются человеческие ошибки при поднятии инцидента (неправильное назначение другой команде, неверный приоритет инцидента, не заполнение данных необходимых для первоначальной диагностики). Сокращаются общие трудозатраты.
Комментариев нет:
Отправить комментарий