Вот вы запустили множество сервисов в кластере Kubernetes и пожинаете плоды… или хотя бы собираетесь это сделать. Однако, даже несмотря на существование ряда утилит для настройки кластера и управления им, вам всё же интересно, как всё работает «под капотом». Куда смотреть, если что-то сломается? По себе знаю, что это важно.
С Kubernetes достаточно просто начинать работу. Но если посмотреть внутрь, там окажется сложная система. В ней множество «подвижных» компонентов, функционирование и взаимодействие которых необходимо понимать, если вы хотите подготовиться к возможным сбоям. Одной из наиболее сложных и, возможно, наиболее критичных составляющих Kubernetes является сеть.
Поэтому я решил разобраться, как именно она работает: прочитал документацию, послушал доклады и даже просмотрел кодовую базу — и вот что я выяснил…
Сетевая модель Kubernetes
В основе сетевого устройства Kubernetes — важный архитектурный принцип: «У каждого пода свой уникальный IP».
IP пода делится между всеми его контейнерами и является доступным (маршрутизируемым) для всех остальных подов. Замечали когда-нибудь на своих узлах работающие pause-контейнеры? Их ещё называют «контейнерами-песочницами» (sandbox containers), потому что их работа заключается в резервировании и удержании сетевого пространства имён (netns), используемого всеми контейнерами пода. Благодаря этому IP пода не меняется даже в тех случаях, когда контейнер умирает и вместо него создаётся новый. Большим достоинством такой модели — IP для каждого пода (IP-per-pod) — является отсутствие коллизий IP/портов на нижележащем хосте. А нам не нужно беспокоиться о том, какие порты используют приложения.
Поэтому единственное требование Kubernetes — все эти IP-адреса подов должны быть доступны/маршрутизируемы из остальных подов вне зависимости от того, на каком узле они расположены.
Взаимодействие внутри узлов (intra-node)
Первый шаг — удостовериться, что поды одного узла способны общаться между собой. Затем эта идея расширяется до взаимодействия между узлами, с интернетом и т.п.
На каждом узле Kubernetes, которым в данном случае является Linux-машина, существует корневое сетевое пространство имён — root netns. Основной сетевой интерфейс — eth0 — находится в этом root netns:

Аналогичным образом у каждого пода есть свой netns с виртуальным интерфейсом Ethernet, связывающим их с root netns. По сути это виртуальный линк с одним концом в root netns и другим — в netns пода.
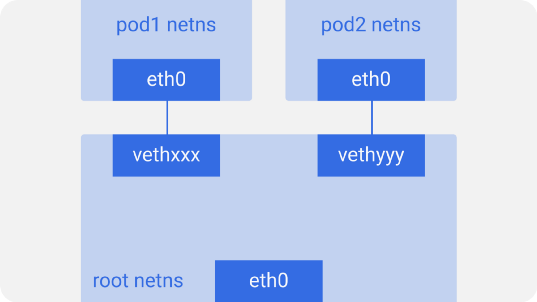
Конец на стороне пода назван eth0, потому что под не знает о нижележащем хосте и думает, что у него своя корневая сетевая конфигурация. Другой конец назван как-нибудь вроде vethxxx. Вы можете увидеть все эти интерфейсы на своём узле Kubernetes, воспользовавшись командой ifconfig или ip a.
Таково устройство всех подов на узле. Для того, чтобы поды могли общаться друг с другом, используется Ethernet-мост Linux — cbr0. Docker использует похожий мост под названием docker0.
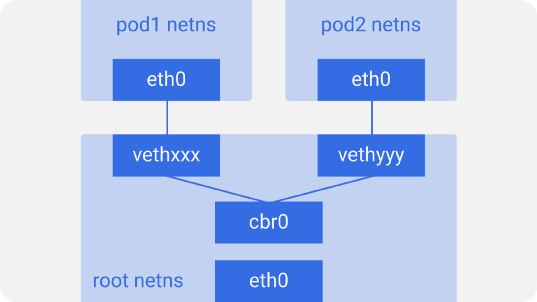
Вывести список мостов можно командой brctl show.
Предположим, пакет отправляется из pod1 в pod2:
- Он через
eth0покидает netns, принадлежащийpod1, и попадает в root netns черезvethxxx. - Попадает в
cbr0, который выдаёт ему точку назначения с помощью ARP-запроса, спрашивающего: «У кого такой IP-адрес?». vethyyyотвечает, что у него нужный IP — так мост узнаёт, куда переслать пакет.- Пакет достигает
vethyyyи, проходя виртуальный линк, попадает в netns, принадлежащийpod2.
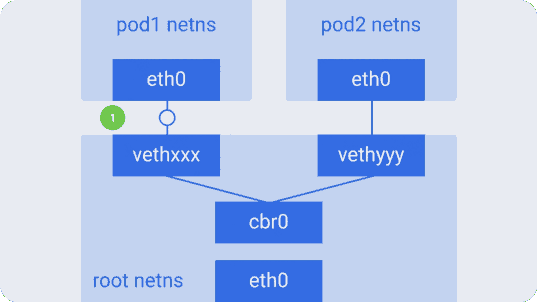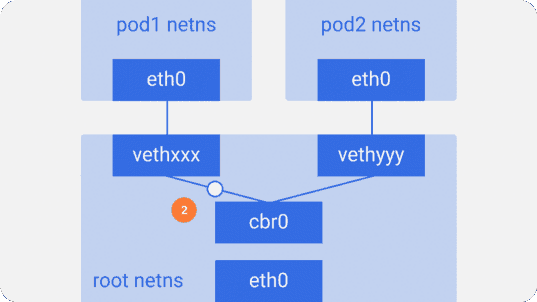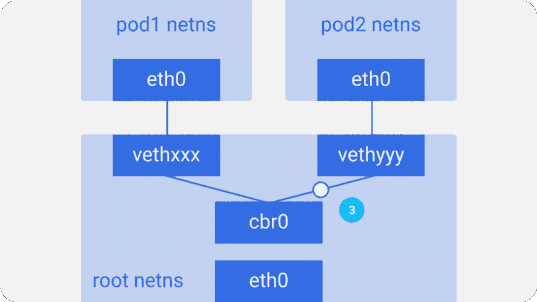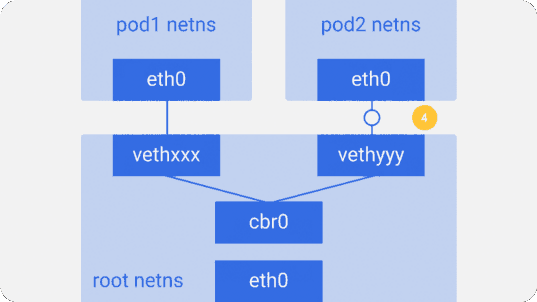
Так контейнеры одного узла общаются между собой. Очевидно, есть и другие способы взаимодействия, но этот, пожалуй, самый простой; его же использует и Docker.
Взаимодействие между узлами (inter-node)
Как упоминалось выше, поды также должны быть доступны из всех узлов. И для Kubernetes вовсе не принципиально, как это реализовано. Посему можно использовать L2 (ARP между узлами), L3 (IP-маршрутизация между узлами — аналогично таблицам роутинга у облачных провайдеров), оверлейные сети и даже почтовых голубей. Каждому узлу назначается уникальный блок CIDR (диапазон IP-адресов) для IP-адресов, выдаваемых подам, так что у каждого пода свой уникальный IP, не конфликтующий с подами других узлов.
В большинстве случаев, особенно в облачных окружениях, облачный провайдер использует таблицы маршрутизации, чтобы гарантировать, что пакеты доходят до корректных получателей. То же самое можно настроить с помощью маршрутов на каждом узле. Также есть множество других сетевых плагинов, решающих свои задачи.
Рассмотрим пример с двумя узлами, аналогичный тому, что был выше. У каждого узла есть различные сетевые пространства имён, сетевые интерфейсы и мост.
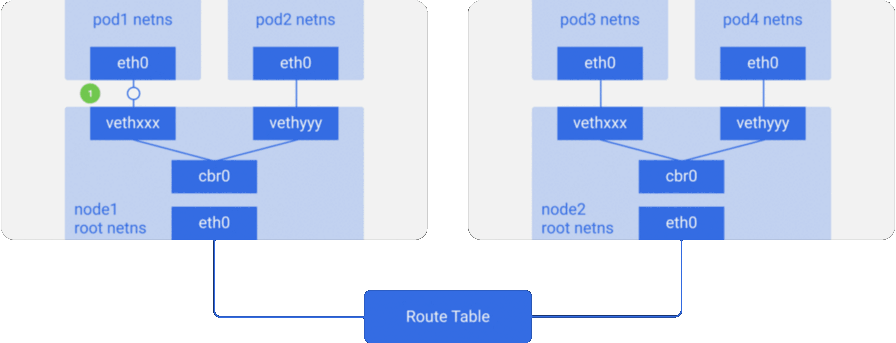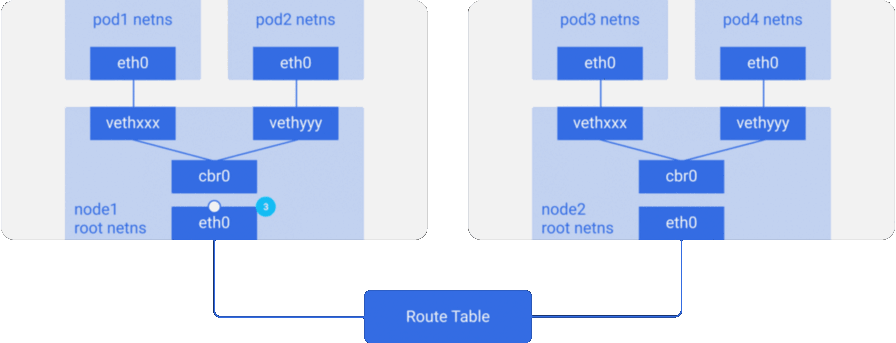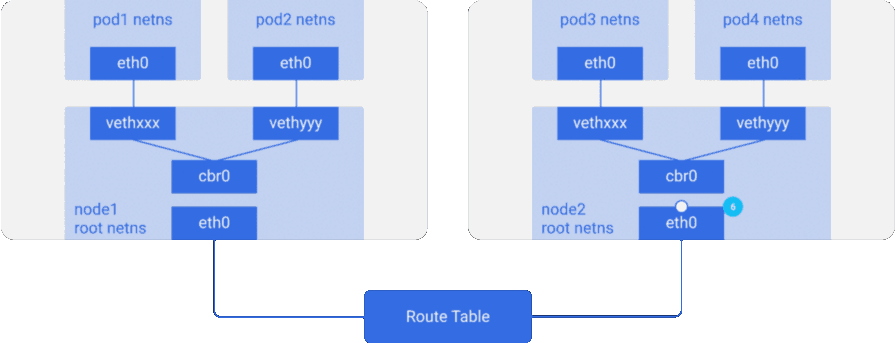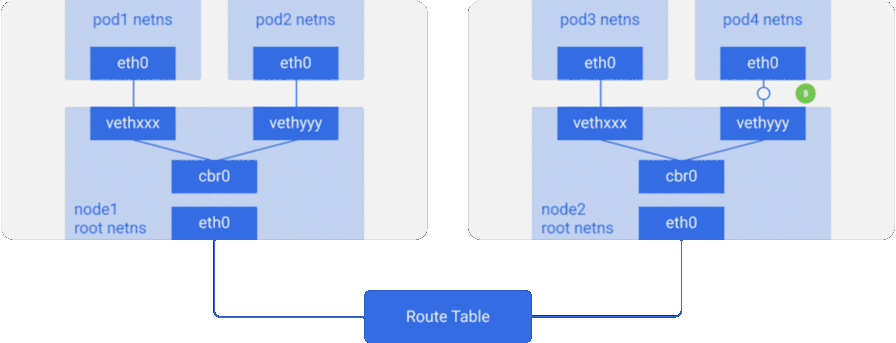
Предположим, пакет следует из pod1 на pod4 (на другом узле):
- Он через
eth0покидает netns, принадлежащийpod1, и попадает в root netns черезvethxxx. - Попадает в
cbr0, который делает ARP-запрос в поисках точки назначения. - Из
cbr0переходит в основной сетевой интерфейсeth0, поскольку ни у кого на этом узле нет IP-адреса, соответствующегоpod4. - Покидает машину
node1, оставаясь в сетевом проводе со значениямиsrc=pod1иdst=pod4. - В таблице маршрутизации настроен роутинг для блоков CIDR каждого узла — согласно ей, пакет отправляет на узел, блок CIDR которого содержит IP-адрес
pod4. - Пакет прибывает на основной сетевой интерфейс узла
node2—eth0. Теперь, хотяpod4и не является IP-адресомeth0, пакет перенаправляется наcbr0, поскольку на узлах включён IP forwarding. Таблица маршрутизации узла просматривается на наличие маршрутов, соответствующих IP-адресуpod4. В ней обнаруживаетсяcbr0как точка назначения для блока CIDR этого узла. Посмотреть таблицу маршрутизации узла можно с помощью командыroute -n— она покажет маршрут дляcbr0вроде такого:
- Мост забирает пакет, делает ARP-запрос и выясняет, что IP принадлежит
vethyyy. - Пакет проходит через виртуальный линк и попадает в
pod4.
Оверлейные сети
Оверлейные сети не требуются по умолчанию, однако они полезны в некоторых ситуациях. Например, когда нам не хватает пространства IP-адресов или сеть не может управлять дополнительными маршрутами. Или когда мы хотим получить дополнительные возможности управления, предоставляемые оверлеями. Частый случай — наличие ограничения на количество маршрутов, поддерживаемых в таблицах роутинга облачного провайдера. Например, для таблицы маршрутизации в AWS заявлена поддержка до 50 маршрутов без влияния на производительность сети. Если нам потребуется более 50 узлов Kubernetes, таблицы маршрутизации AWS перестанет хватать. В таких случаях поможет оверлейная сеть.
Оверлейная сеть инкапсулирует пакеты, проходящие по сети между узлами. Возможно, вы не захотите её использовать из-за того, что инкапсуляция-декапсуляция всех пакетов добавляет небольшую задержку и сложность. Зачастую это не нужно, что стоит учитывать, принимая решение об их использовании.
Чтобы понять, как ходит трафик в оверлейной сети, рассмотрим пример с flannel — Open Source-проектом от CoreOS:
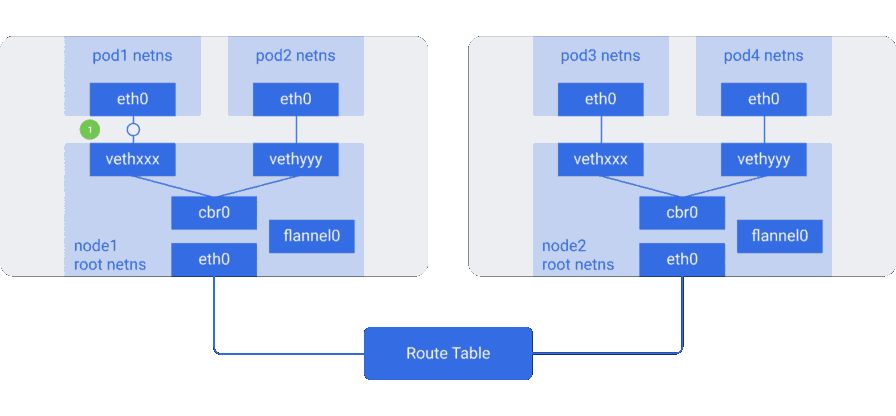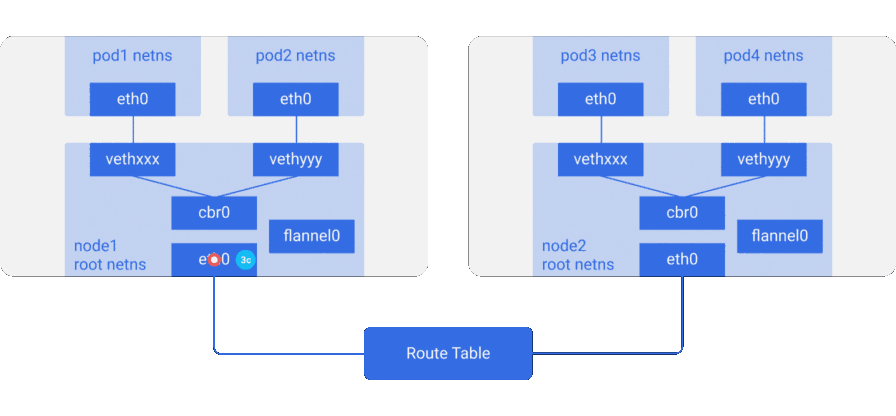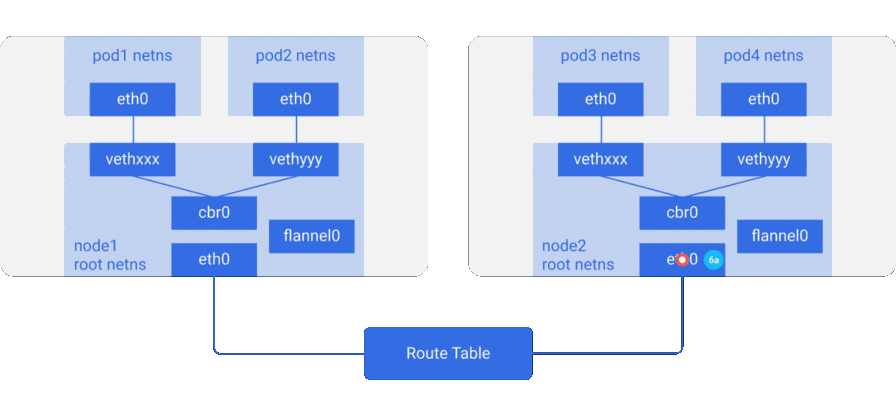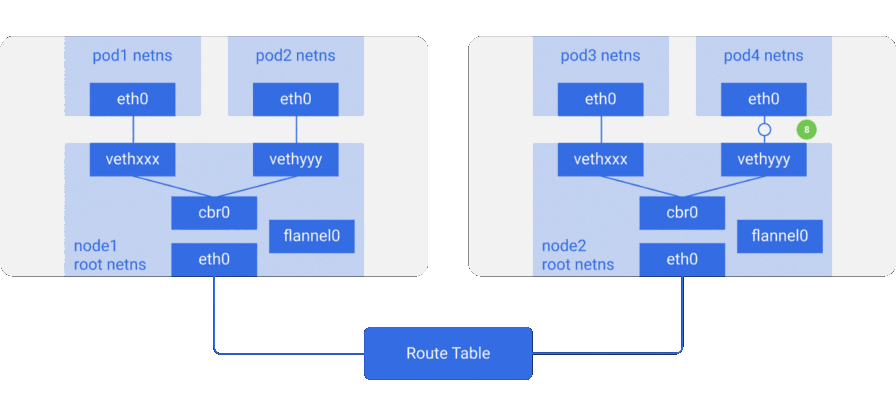
Здесь мы видим конфигурацию, аналогичную предыдущей, однако в ней появилось новое виртуальное Ethernet-устройство под названием flannel0 — оно находится в корневом пространстве имён (root netns). Это реализация Virtual Extensible LAN (VXLAN), которая для Linux — просто ещё один сетевой интерфейс.
Прохождение пакета из pod1 в pod4 (он находится на другом узле) выглядит примерно так:
- Пакет через
eth0покидает netns, принадлежащийpod1, и оказывается в root netns наvethxxx. - Проходит до
cbr0, который делает ARP-запрос для обнаружения точки назначения. -
- Поскольку ни у кого на этом узле нет IP-адреса, соответствующего
pod4, мост отправляет пакет вflannel0— таблица маршрутизации узла настроена на использованиееflannel0в качестве цели для сетевого диапазона пода. - Демон flanneld взаимодействует с Kubernetes apiserver или нижележащим etcd, откуда получает все IP-адреса подов и сведения о том, на каких узлах они расположены. Таким образом, flannel создаёт соответствующие сопоставления (в пользовательском пространстве) для IP-адресов подов и IP-адресов узлов.
flannel0берёт пакет и заворачивает его в UDP-пакет с дополнительными заголовками, изменяющими IP-адреса источника и получателя на соответствующие узлы, отправляет его на специальный порт vxlan (обычно 8472):
Хотя сопоставления находятся в пользовательском пространстве, реальная инкапсуляция и прохождение данных происходит в пространстве ядра, так что это достаточно быстро.
- Инкапсулированный пакет отправляется через
eth0, поскольку он отвечает за роутинг трафика узла.
- Поскольку ни у кого на этом узле нет IP-адреса, соответствующего
- Пакет покидает узел с IP-адресами узлов в качестве источника и назначения.
- Таблица роутинга облачного провайдера уже знает, как маршрутизировать трафик между узлами, поэтому пакет отправляется к узлу-получателю —
node2. -
- Пакет прибывает на
eth0узлаnode2. Поскольку в качестве порта используется специальный vxlan — ядро отправляет пакет наflannel0. flannel0декапсулирует пакет и переносит его обратно в root netns. Пакет покидает узел с IP-адресами узлов в качестве источника и назначения. Дальнейший путь совпадает с тем, что был в случае обычной (неоверлейной) сети.- Поскольку включён IP forwarding, ядро отправляет пакет на
cbr0согласно таблице маршрутизации.
- Пакет прибывает на
- Мост забирает пакет, делает ARP-запрос и выясняет, что нужный IP-адрес принадлежит
vethyyy. - Пакет проходит через виртуальный линк и попадает в
pod4.
У различных реализаций могут быть незначительные отличия, но в целом именно так работают оверлейные сети в Kubernetes. Существует распространенное заблуждение, что их использование в Kubernetes необходимо, однако правда в том, что всё зависит от конкретных случаев. Так что сначала убедитесь, что применяете их только в случае реальной необходимости.
P.S. от переводчика
Читайте также в нашем блоге:
Комментариев нет:
Отправить комментарий