На фоне популярности StatsD и других time-series систем появилась идея «Monitor Everything»: чем больше различных вещей в системе измеряется, тем лучше, потому что в случае неожиданной ситуации будет возможно найти нужную, уже собранную метрику, которая позволит во всем разобраться.
Давайте вообще все, что можно, мониторить — и будет классно!
Но как часто бывает с любой модной технологией, которая изначально сделана с некоторыми ограничениями, при начале использования люди не очень задумываются об этих ограничениях, а делают как написано, как придется.
И так получилось, что есть много проблем со всем этим, про которые, собственно, нам и расскажет Павел Труханов ( tru_pablo ).
В независимости от того, какой программный продукт мы разрабатываем, мобильную игру или банковское ПО, мы хотим, чтобы система обрабатывала приходящие события быстро, без глюков, ничего не ломалось и пользователи были довольны.Для этого нужно постоянно контролировать, что процесс идет так, как нужно. Okmeter делает сервис, призванный позволить тысячам инженеров не повторять в своих сервисах мониторинга одно и то же из раза в раз.
Неудивительно, что директору компании Павлу Труханову (@tru_pablo) приходится много читать про мониторинг, про метрики, про математику, думать, потом еще много читать и много думать. Эта тема у него наболела, и он решил высказаться. Эта статья — расшифровка его доклада на РИТ++ 2017
Системы массового обслуживания
Мы говорим о системах, массового обслуживания (СМО), куда приходят независимые запросы. СМО включают в себя:
- сервис, который их обслуживает;
- тайминги, в том числе service time — время обслуживания и response time — время ожидания в очереди;
- результат обслуживания.
Если говорить про web, то есть access логи, в котором записаны response time и http-статус ответа, из которого можно понять нет ли ошибок и тормозов. Мы хотим, чтобы система обрабатывала приходящие события быстро, без глюков, ничего не «фейлилось» и пользователи были довольны. Для этого нужно постоянно контролировать, что процесс идет так, как мы ожидаем. При этом существует наше представление о том, что все хорошо, а есть реальность, и мы их постоянно сравниваем.
Графики
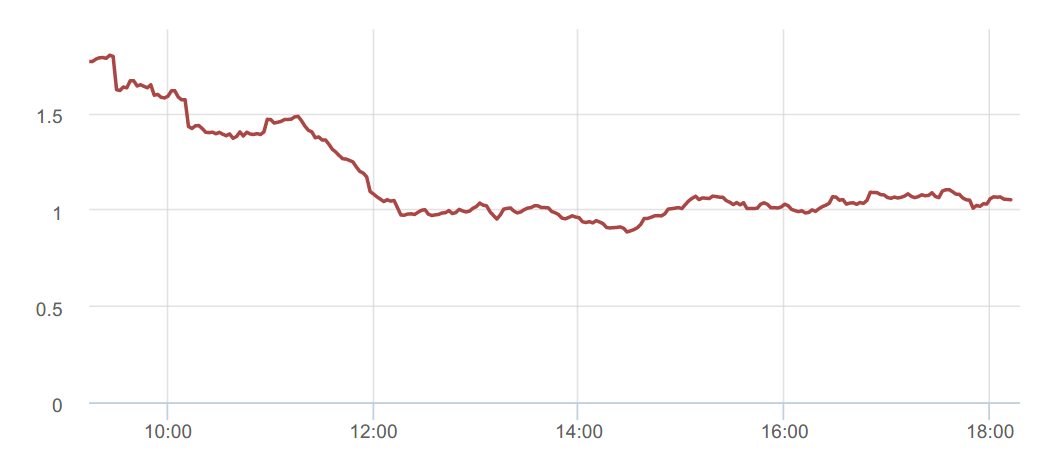
Если процесс не соответствует нашим ожиданиям, тому, как мы задали/определили для себя некую “нормальную” ситуацию, нужно дальше разбираться. Для этого очень удобно использовать time series графики, в которых по горизонтальной шкале откладывается время, а по вертикальной — нужный параметр.
Я считаю такие графики наиболее полезными в ситуациях, когда что-то идет не так, как мы ожидаем, поттому что они наглядно показывают:
- impact, то есть насколько все плохо;
- историю — как выглядит типичное поведение показателя;
- динамику процесса, т.е. можно увидеть, ухудшается или улучшается ситуация.
Все знают, что графики бывают разные, например, bar, scatter (точечные), heatmap и прочие. Но мне нравятся именно time line, и я их рекомендую, потому что наш мозг умеет классно определять, какой из отрезков длиннее =) Это наше эволюционное свойство, которое такой график позволяет напрямую использовать.
Как сделать такой график?
По горизонтальной шкале откладывается время, а для других параметров используется вертикальная шкала. Т.е. для каждого момента времени есть одна вертикальная полоса пикселей, которую можно заполнить информацией. В ней, скажем, 800 или даже 1600 точек, в зависимости от размера вашего монитора.
В единицу времени в системе может происходить разное количество событий, 10, 100, 1000 или больше, если система супер большая. Не важно сколько именно в вашей системе, важно, что это не 1 событие. Кроме того, события могут иметь разные типы, тайминги или результаты.
Несмотря на то, что можно сделать сколько угодно графиков и смотреть разные аспекты на отдельных графиках, все равно, в конечном итоге, для конкретного графика нужно из нескольких событий с многочисленными параметрами построить для отображения одно число.
1000 таймингов — что с ними делать?
Тайминги можно визуализировать в виде плотности распределения: по горизонтали откладывается текущее значение тайминга, по вертикали — количество таймингов с таким значением.
На графике плотности распределения видно, что есть тайминги с неким средним значением, есть быстрые, есть медленные.
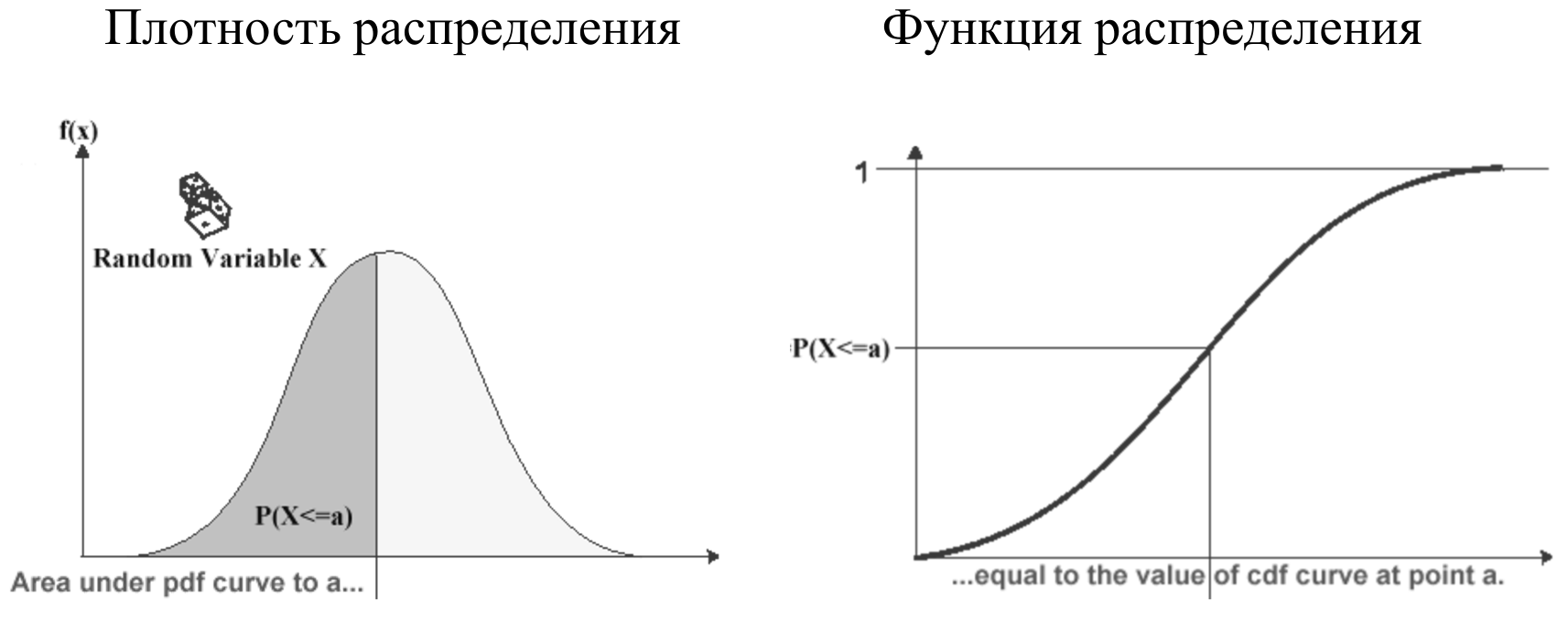
Помимо плотности распределения, удобно бывает смотреть на функцию распределения, которая является просто интегралом от плотности распределения. Она хороша тем, что ее область значений ограничена отрезком от 0 до 1, поэтому позволяет сравнивать совершенно разные параметры между собой без нормировки. Но плотность распределения более привычная и физичная.
В реальности для тех систем, про которые мы говорим, график плотности распределения выглядит не как известный всем Гауссовский колокол нормального распределения. Поскольку, как минимум, тайминги не бывают отрицательными (если только у вас на сервере время назад не пошло, что бывает конечно, но реально редко). Поэтому в большинстве реальных случаев график будет выглядеть примерно, как на следующем рисунке.
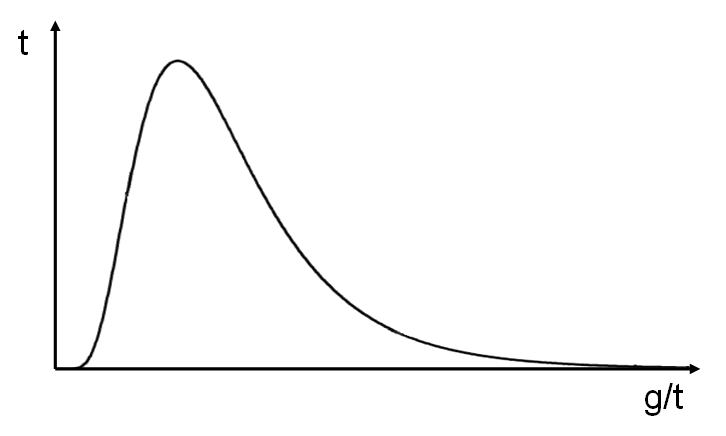
Это тоже некая модель, приближение. Она называется логнормальным распределением, и является экспонентой от функции нормального распределения.
Но реальность, конечно, даже и не такая. Все системы выглядят немного по-разному. Например, человек прикрутил Memcached к своей php, половина запросов попала на Memcached, половина — нет. Соответственно, получилось бимодальное (двухвершинное) распределение.
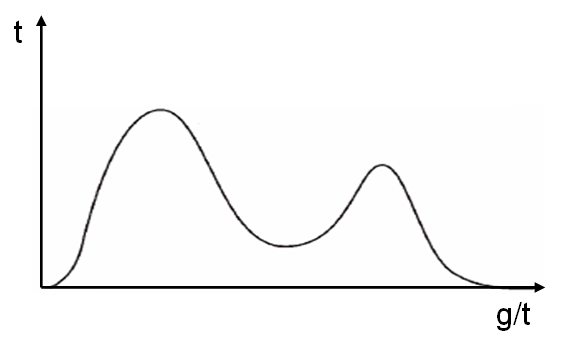
Если совсем по-честному, реальные функции распределения выглядят, как угодно (рисунок ниже). Чем сложнее система, тем более разнообразными они будут. С другой стороны, когда система становится слишком сложной, просто из миллиона деталей, то она наоборот скатывается обратно к нормальному распределению в среднем.
Важно помнить, что эти 1000 таймингов вычисляются постоянно, в каждый интервал времени, например, каждую минуту. То есть у нас за каждый интервал есть какая-то своя плотность распределения.

1000 таймингов — что с ними делать?
Чтобы отложить на графике одно число, вместо 1000, надо взять от измерений какую-то статистику — это означает, по факту, сжать тысячу числе до одного. То есть с потерей данных — это важно.
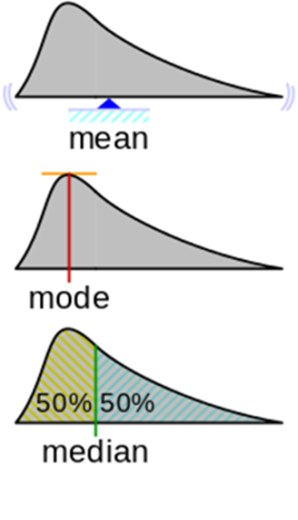
Статистики, которые известны (и распространены):
- Среднее арифметическое — центр масс графика плотности.
- Мода для функции плотности — аргмаксимум плотности распределения, т.е. положение максимума по оси Х. Тут возникает вопрос: что делать, когда есть несколько пиков.
- Медиана — значение Х, при котором площадь фигуры делится пополам.
Кроме медианы есть перцентили и другие статистики, но я хочу подчеркнуть, что какую бы статистику мы ни взяли, это все равно будет одно число, которое не будет полностью описывать тысячу наблюдений.
Допустим, мы взяли какую-то статистику и (ура, наконец-то) у нас появился график:

В данном случае это график среднего арифметического. По нему что-то уже понятно. Понятно, что у среднего есть небольшие колебания, но нет разброса значений на порядки.
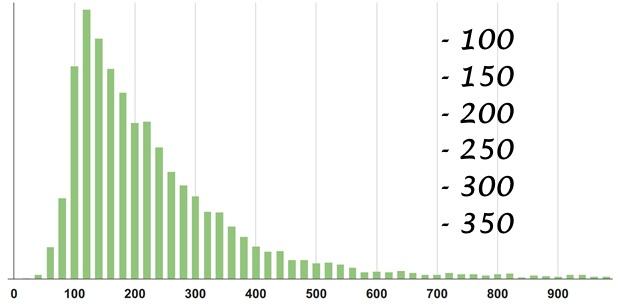
Вот пример: эта плотность распределения взята с конкретного сервиса. Угадайте статистику — выберите один из вариантов, а далее я проведу сеанс черной магии с разоблачением.
Ну этот может быть было не сложно угадать, но вот еще один пример:
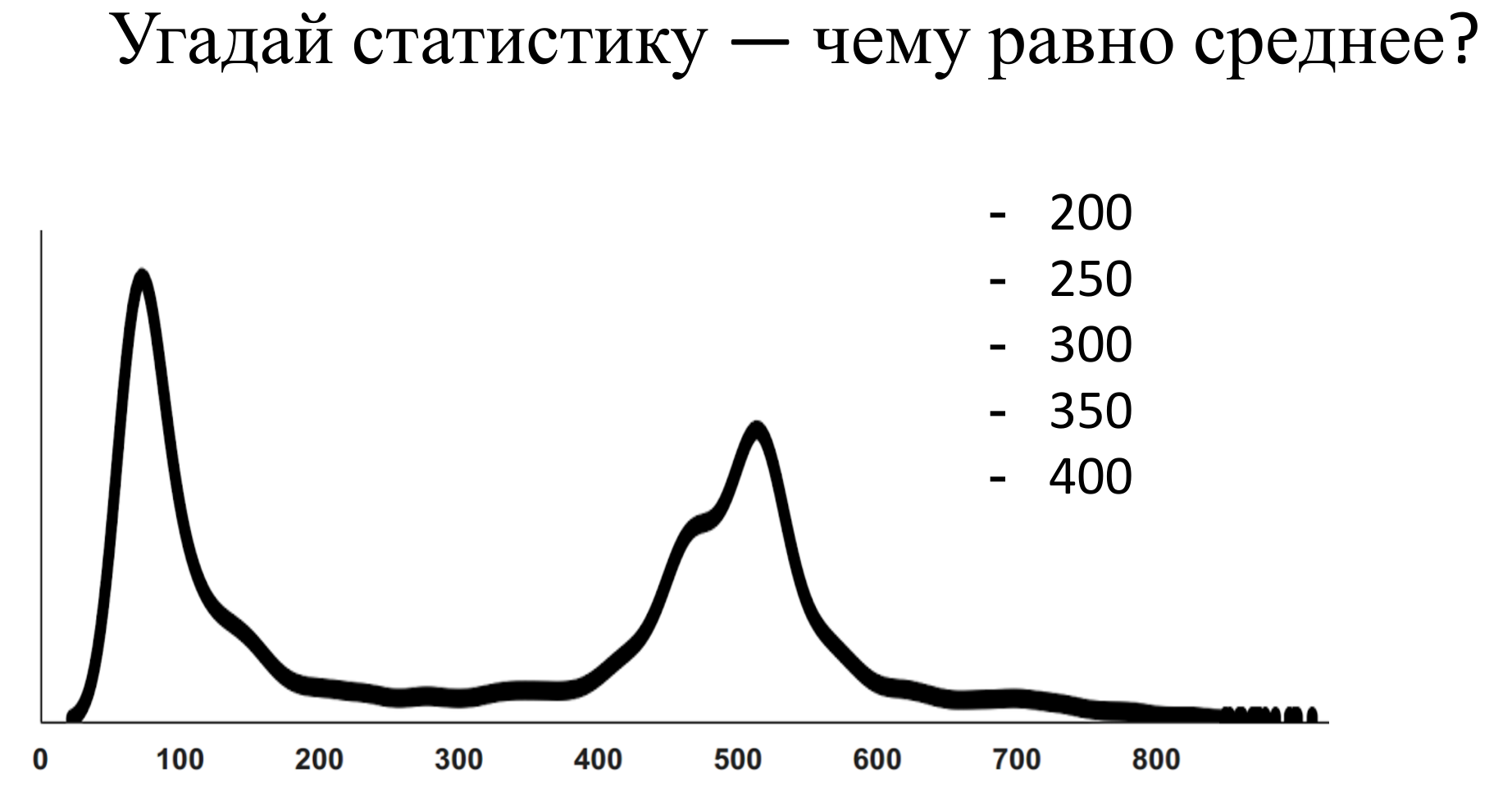
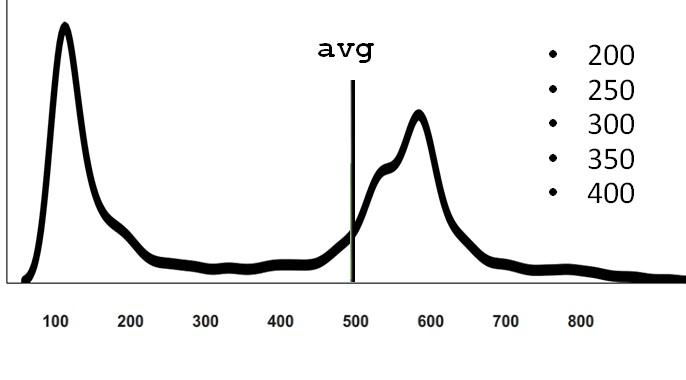
Дело в том, что если мы отзумим этот график, то выяснится, что у него на дальнем хвосте тоже есть наблюдения, которые просто не видны в том масштабе, в котором мы смотрим.
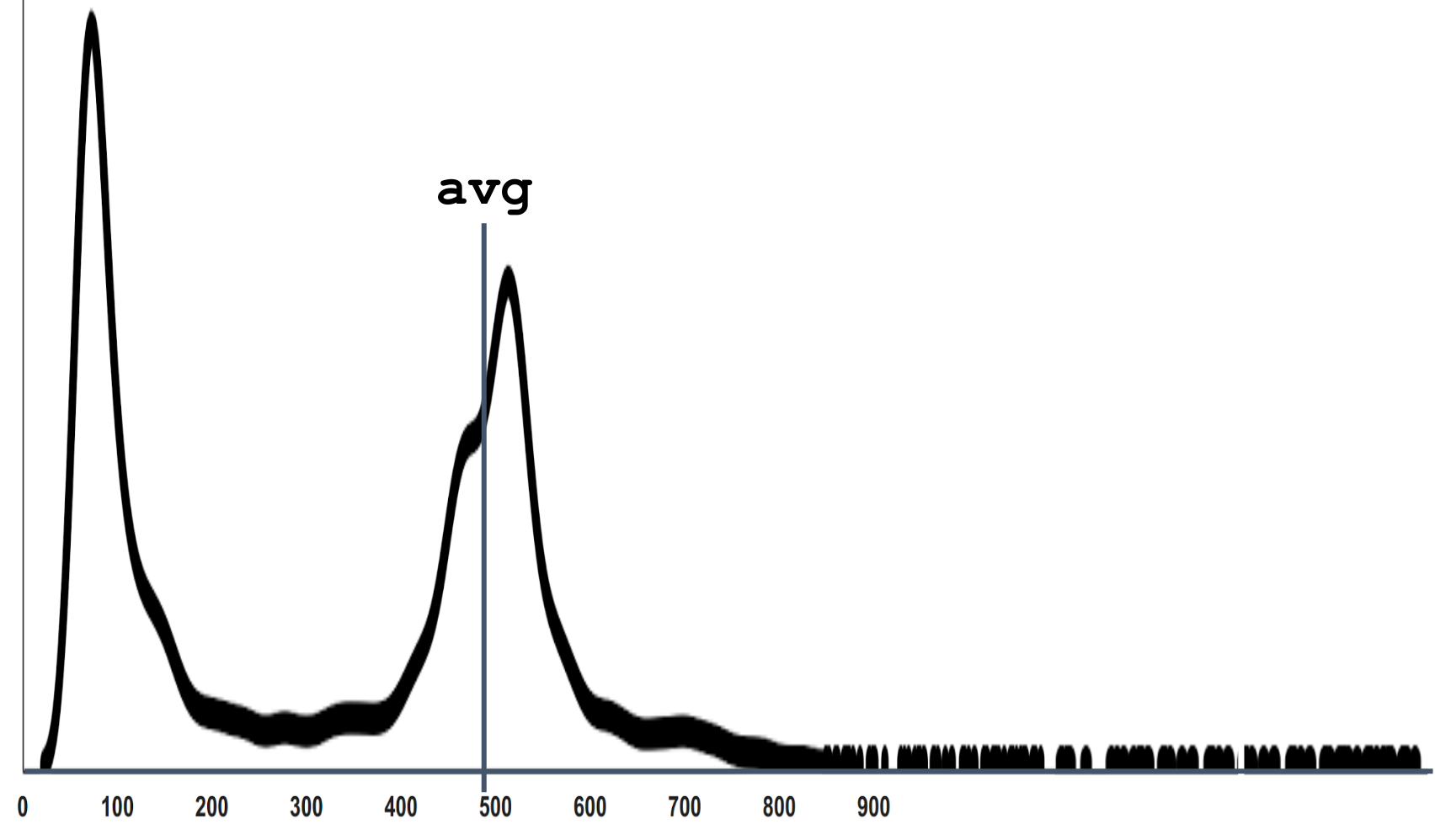
Реальные сложные системы обычно себя так и ведут. У них всегда есть конкуренция за ресурсы, потому что иногда приходит много запросов одновременно, и возникают ситуации, когда для конкретного запроса плохо сошлись звезды и время обработки получилось большое. Если вспомнить, что физический смысл математического ожидания — это центр тяжести плотности распределения, то понятно, что даже немного измерений на дальнем хвосте перевешивает по правилу рычага. Поэтому среднее расположено не там, где ощущается “типичное среднее”.
Мой поинт в том, что распределения могут быть совершенно разными в разных системах и в разных частях вашей системы. И пока вы реально не посчитали среднее, предварительно собрав кучу наблюдений, построив на основе набранной статистики график, на самом деле вы вряд ли правильно угадаете результат. Раз даже с по собранной статистике среднее угадать не легко.
Споры о среднем арифметическом
Есть мнение, что метрику mean/average очень плохо использовать для мониторинга. Фанаты перцентилей кричат с любого угла: «Я видел у тебя в мониторинге среднее — ты плохой человек! Возьми и используй лучше перцентиль!»
Надо заметить, они говорят это не на пустом месте и в этом есть определенный резон:
1. Физический смысл.
Кроме того, что среднее — это центр масс, можно так описать физический смысл: вы делаете ставки на некоторое число, причем результаты ставки (выиграли, или проиграли) накапливаются. Та сумма, которую выиграли, складывая всё в один мешочек с деньгами, и есть суть математическое ожидание, которое равно среднему арифметическому.
Но онлайн систему, типа, например, интернет-магазина, в котором пользователи ожидают очень быстро открыть карточку товара и скорее купить его, невозможно никак сопоставить с таким концептом матожидания и с тем, для чего оно придумано.
2. Робастность к выбросам
Второй аргумент фанатов перцентилей в том, что «среднее не робастно к выбросам». Действительно, мы видели, что на дальнем хвосте даже одно наблюдение перевешивает многочисленные наблюдения, расположенные ближе к началу оси (в нашем случае — с большим и маленькими таймингами соответственно).
Но то, что я хочу тут вам объяснить контринтуитивно: в действительности в мониторинге робастность не нужна! Наоборот, нужна неробастность к выбросам — то есть система, которая будет их явно замечать и показывать. Например, если у вас вообще такого никогда не было, чтобы среднее выходило за какую-то определенную границу. И вдруг, откуда ни возьмись, появился какой-то невиданный далекий выброс, то вы, конечно же, хотите об этом знать. Ведь система начала вести себя так, как никогда ранее — это верный признак что, что-то идет не так. Вы не хотите закрывать на это глазки и говорить: «Нет, мне нужна робастность к выбросам! Это выброс, я про него знать не хочу».
Откуда вообще взялось требование/пожелание про робастность к выбросам? Когда ваша задача не мониторинг, а исследование какой-то системы, например, когда вам досталась «в наследство» некая IT система, и вы хотите изучить какие-то ее свойства, выделить какую-то основную закономерность поведения под нагрузкой. Мы делаем это в каком-то контролируемом окружении/условиях и измеряем поведение. Тогда хорошо бы, чтоб у статистики, которой мы пытаемся охарактеризовать это поведение, была робастность к выбросам. Потому что мы хотели бы отбросить и не учитывать возможное влияние каких-то событий, совершенно не связанных с нашим сетапом исследования и с характерным поведением системы. (Например, вроде лаборанта Васи, который записывал наблюдения и заснул или записал неправильно).
Когда же вы мониторите и контролируете, вам наоборот нужно знать про все эти выбросы — какие из них типичные, а какие вообще из ряда вон.
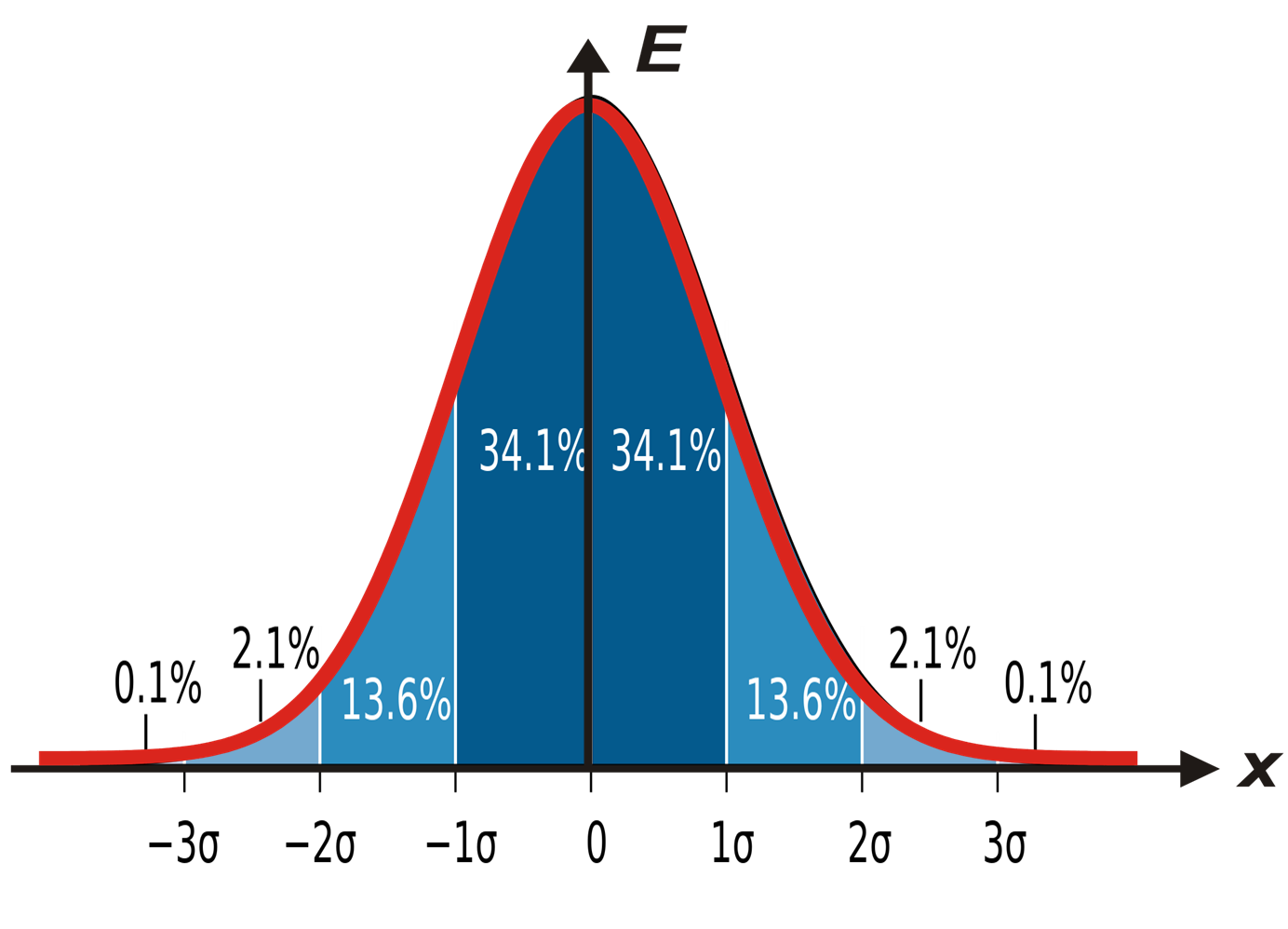
На рисунке выше колокол Гауссианы «порезан» на куски.
Многие знают «правило 3-х σ (сигм)»: если «отступить 3σ» от среднего, то вероятность попадания наблюдения за пределы такого интервала очень мала.
Отсюда бывает следует скоропалительное предложение: «давайте тогда повесим на наши (любые или любимые) метрики проверку, которая будет следить, когда величина вылезла за 3σ от среднего и предупреждать нас». Мол, «раз это редкие события, то если такое уже произошло, то скорее всего что-то не так и надо всех будить и что-то делать».
На рисунке, как вы видите, отход на 3σ дает примерно равно 0,1% вероятность, и кажется, что это действительно жутко редкие события. но на самом деле — нет! 1 раз в 700 наблюдений у вас будет туда что-то вываливаться.
Я хочу показать, что даже при нормальном распределении события, которые выходят за эти пресловутые 3σ, происходят чаще, чем вы ожидаете, чем общее понимание «редкого» и «аномального». И, если это мониторинг, они вам спамят, а не приносят пользу.
Эти две задачи связаны:
- Мы сначала хотим понять, как наша система себя ведет в «норме», и это очень важно, потому что наше априорное представление может никак не соответствовать реальности.
- Потом, когда мы построили распределения, выбрать пороговые значения (ориентируясь на распределение или не слишком), завести на них alert’ы и мониторить.
Что такое «норма»?
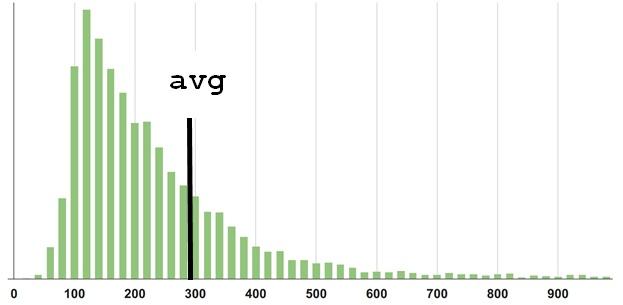
На мой взгляд, значение 300 в нашем первом примере не описывает «среднее» или типичное поведение системы. Медиана (50-й перцентиль), по моему личному ощущению, ближе к тому, что я бы назвал «типичным» для этого распределения.
Перцентиль P90 находится на отметке 550. И чем больше брать перцентилей, тем более подробное будет описание распределения.
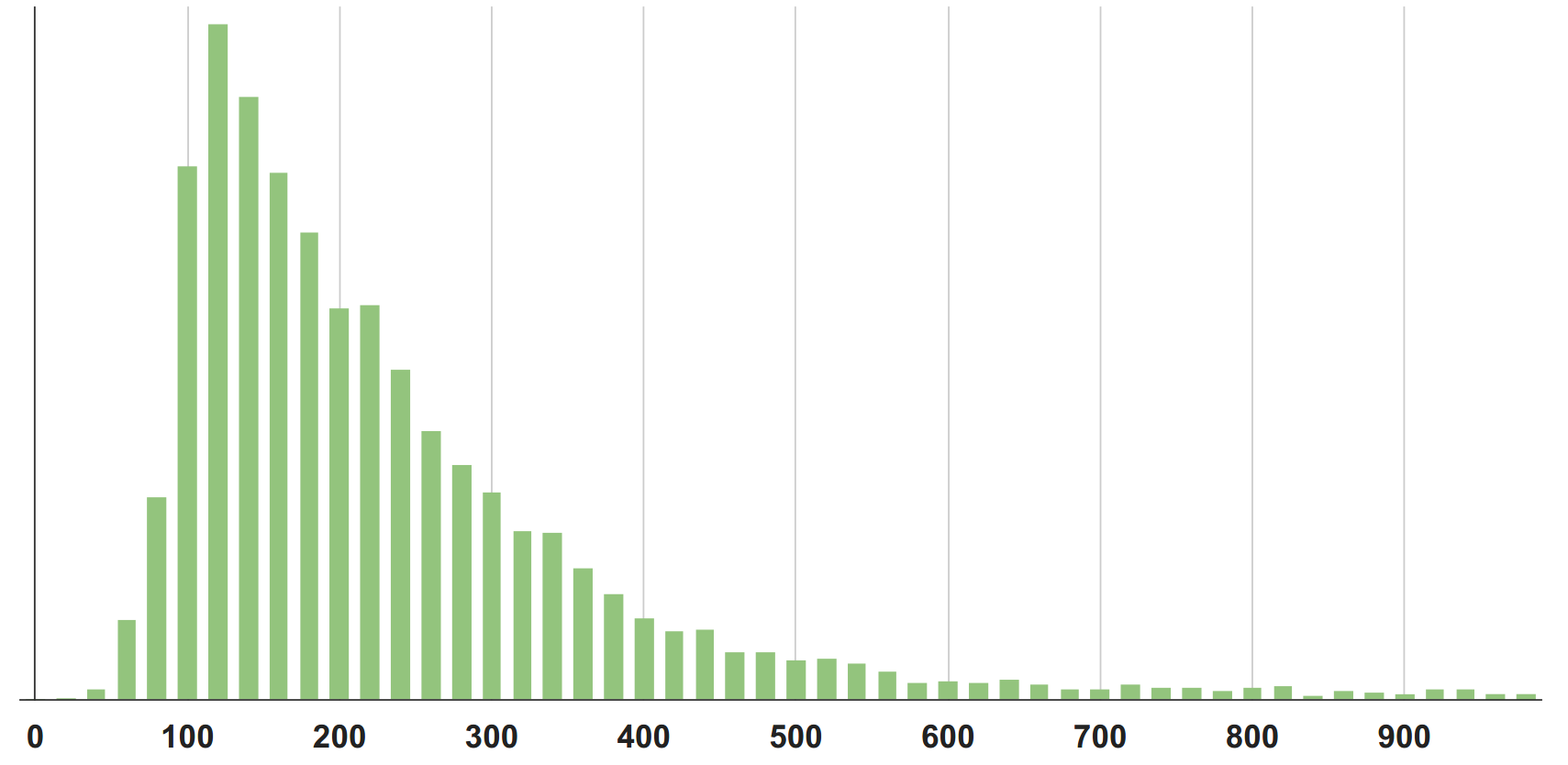
Конечно, можно построить и посмотреть глазами на само распределение, его плотность, но в задачах контроля/мониторинга или оптимизации, все равно нужно оперировать ограниченным количеством параметров, чтобы разные распределения можно было сравнивать.
Давайте посмотрим на еще один пример, еще одно распределение времен ответов сервиса. Оно выглядит, в каком-то смысле, похоже:

Мои ожидания мне говорят: «Чувак, подожди, у тебя почти все наблюдения здесь, до 15 миллисекунд, а 95-я почему где-то там?»
Парадокс.
Ну хорошо, 95-я — классная перцентиль, фанаты нас убедили, что важно смотреть не только на среднее и не на медиану, но и на более высокие перцентили. Давайте заведем мониторинг на P95, раз она заведомо покрывает все предыдущие.
Мониторинг
Мы ставим себе Service Level Objective — или по-русски, цель. Например, чтобы P95
На самом деле есть много пунктов, почему это SLO плохое.
Незаметные деградации
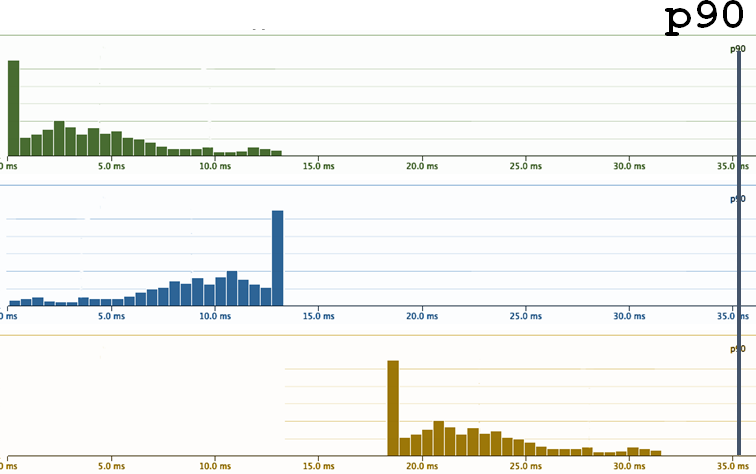
А вы, наверняка, хотели бы знать, что такие изменения произошли в системе. Поэтому подход «давайте смотреть только на Х-перцентиль» снова не работает. ¯\_(ツ)_/¯
Напрашивается решение:
— Хорошо, давай следить за большим количеством перцентилей! Одного 9х-й мало, давай еще на 75-й зададим условие P75 < 15 мс. И еще на какие-нибудь!
Давайте посмотрим, что при этом происходит.
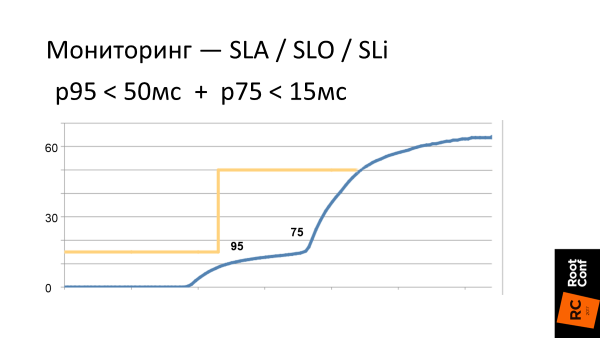
Такие наши текущие требования на поведение системы это желтая граница на графике. А синяя кривая это то, как выглядит latency системы в реальности. Что тут нужно увидеть, что правее p95 (шкала нелинейная), latency сразу начинает расти. В том смысле, что, когда мы зажимам свою систему по порогам, то там, где мы перестаем ее контролировать, она сразу пытается из-под этих порогов выскочить, как только может быстрее. Т. е. если на уровне p95 мы все заоптимизировали, то уже на p96 тайминги значительно растут.
Второй момент
Так как мы — мониторинговая компания, нас все время спрашивают: «Можно у вас отслеживать перцентили? Вы рисуете 95-й перцентиль?»
Мы нехотя отвечаем: «Да, можно…». В нашем мониторинге есть перцентили, но мы их прячем и стараемся не показывать потому, что они вводит в заблуждение пользователей.
Допустим вот есть плотность распределения.
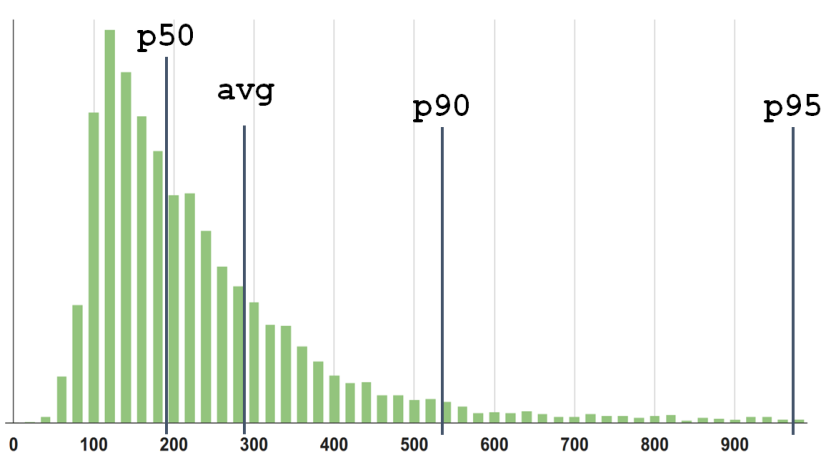
Мы видим 3 перцентиля и среднее. Но что здесь не так? Здесь не так то, что 95 это не просто «95». Это 95 из 100. Значит, где-то есть еще 5? Где эти 5%?
На правом хвосте график уже низенький, и это ощущается, что там правее, уже только очень редкие события. И хотя они есть, но на них можно не смотреть.
Но вот на рисунке я собрал эти 5% и поставил столбиком. И их много! 5% — это каждый 20-й. Это много! И сразу понятно, что неправильно их игнорировать.
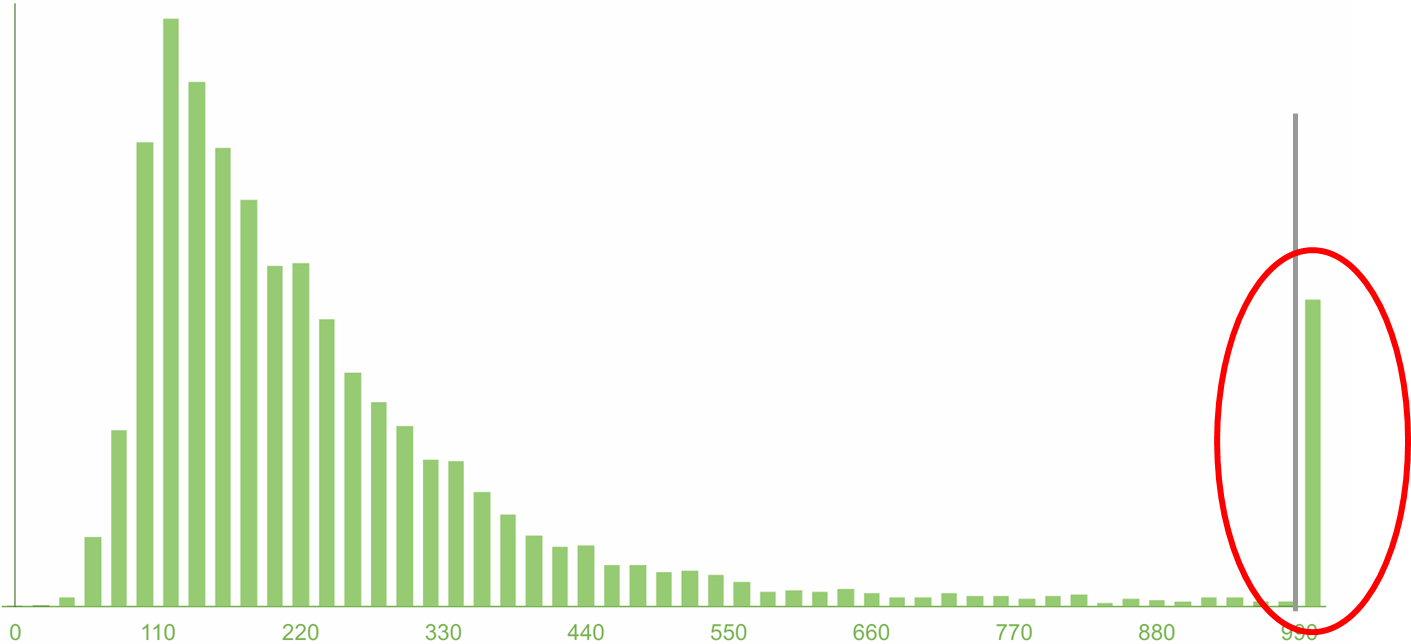
Когда вы смотрите на 95-й перцентиль вашего сервиса, и он классный (допустим около 100 миллисекунд), вы думаете, что все здорово! По сути вы просто сознательно закрыли глаза на 5%: «На тот ужас в том дальнем хвосте распределения я смотреть не буду, потому что страшно и неприятно — я не хочу туда смотреть!» Это, конечно, безответственно.
Понятно, что и тут тоже напрашивается решение: «Ладно, ok, 95 мало, давай возьмем 99! Мы же крутые чуваки, давай даже три девятки возьмем — 99,9%!»
Уже, казалось бы, в 99.9% не попадает реально одна тысячная, которую, наверное, дорого оптимизировать и на уж такую редкость можно забить.
Да?
Но я попытаюсь вас убедить, что 99,9% все еще мало.
Это опять-таки контринтуитивное (и смелое) заявление. Прежде чем его доказывать, я хотел бы поговорить про эти «старшие» перцентили.
Как в жизни часто измеряют перцентили
Сейчас очень много инструментов, начиная со StatsD, заканчивая всем многообразием современных утилит, которые позволяют нам легко получить разные измерения.
— Давай измерим, как наш сервис себя ведет!— Давай!
— Давай воткнем мониторинг — я читал на одном тематическом ресурсе, как это делается — поставил — и все! Графики есть!
И вот мы уже получили графики времени ответа. Посмотрим же на (наши любимые) перцентили.
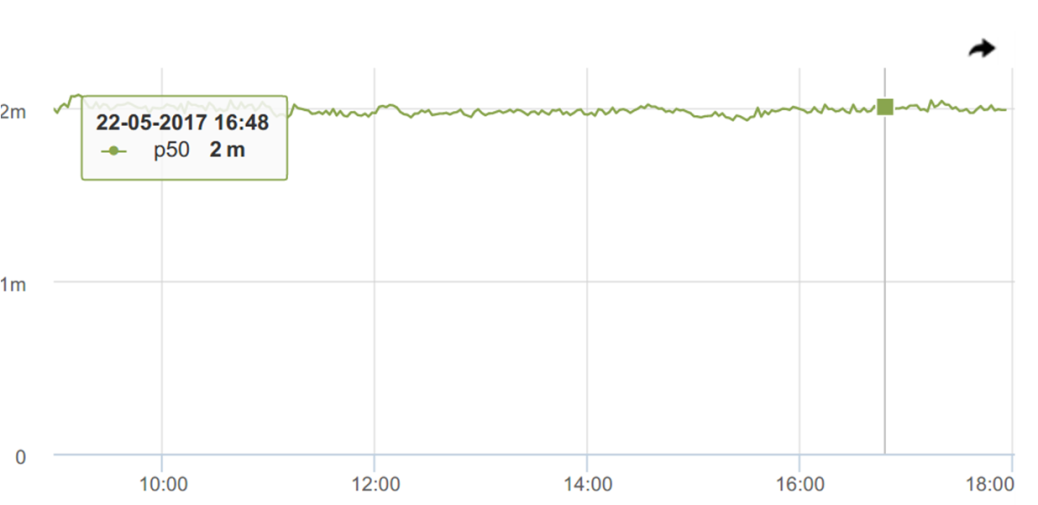
Здесь медиана (p50) — она классная, мне лично супер нравится! Такая суперстабильная — постоянно ~2 миллисекунды. Напрашивается скорее повесить триггер с порогом с небольшим запасом 2.2-3.5 мс и получать уведомления, когда что-то пойдет не так.
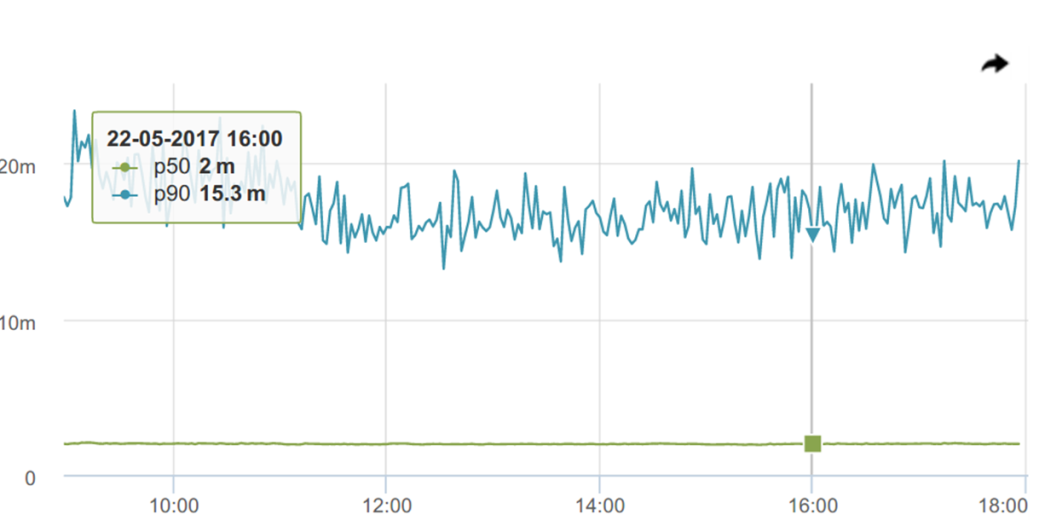
Посмотрим на 90-й перцентиль, а он ведет себя уже не так стабильно
95-й — и вовсе, как расческа.
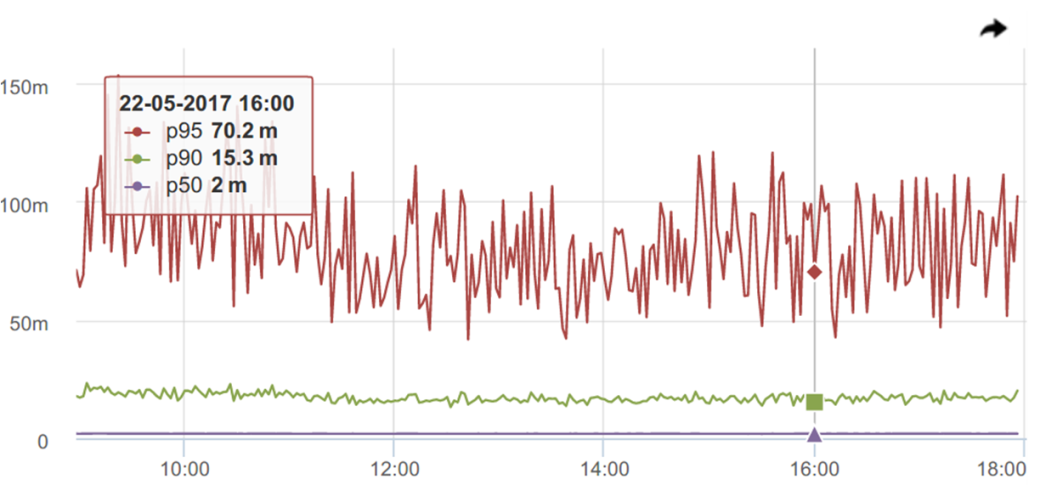
Казалось бы, где обещанная, хваленая робастность к выбросам?! Вот так интуиция нас опять обманывает, подсказывая, что «робастная» значит «ровная», стабильная. Хотя на деле все не так.
Продолжая говорить про (контр)интуитивные ощущения перцентилей, посмотрим на еще один график.
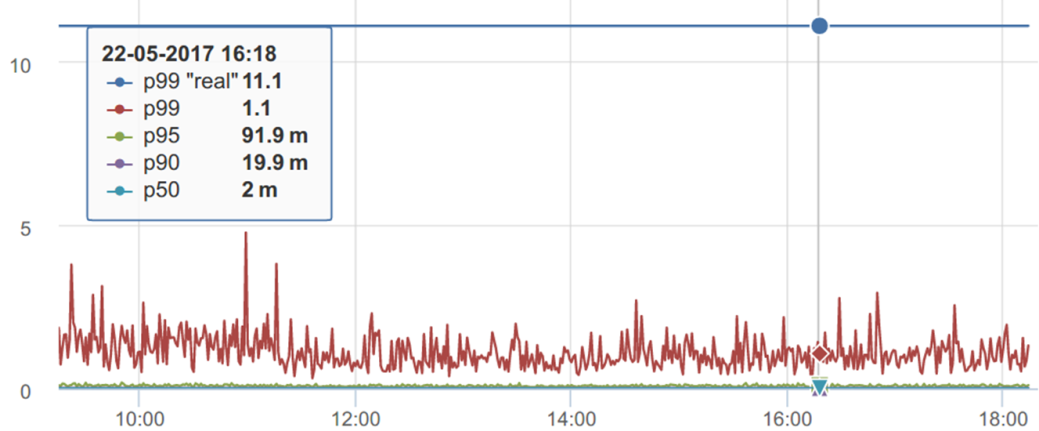
Кажется, что на этом графике p99 лежит в пределах от 1 секунды до ~2-3 секунд. И его №настоящее значение№ должно быть где-то в районе 1,1с
Но если посчитать p99 по всем накопленным за этот период данным, то получается, что p99 «real» совсем в другом месте — отличие в 10 раз. Как так?
Во-первых, мы измеряем перцентиль за интервал — в данном случае за минуту. За день набегает 1440 ежеминутных измерений. Мы нарисовали этот график, а наш мозг автоматом вычисляет для него горизонтальный тренд, если мы видим, что он не плавает. Даже если мы догадались: «Так, это перцентиль — наверное, от него надо брать максимум, получается где-то 5с» — все равно он на самом деле не там.
Если взять это распределение и попытаться набрать статистику, когда перцентиль, который мы вычисляем, перестает меняться (или почти перестанет) от добавления измерений со временем, выяснится, что он все равно не там, где мы ее ожидаем, а в два раза выше.
Наша голова вычисляет некий горизонтальный уровень, а перцентиль ведёт себя по-другому.
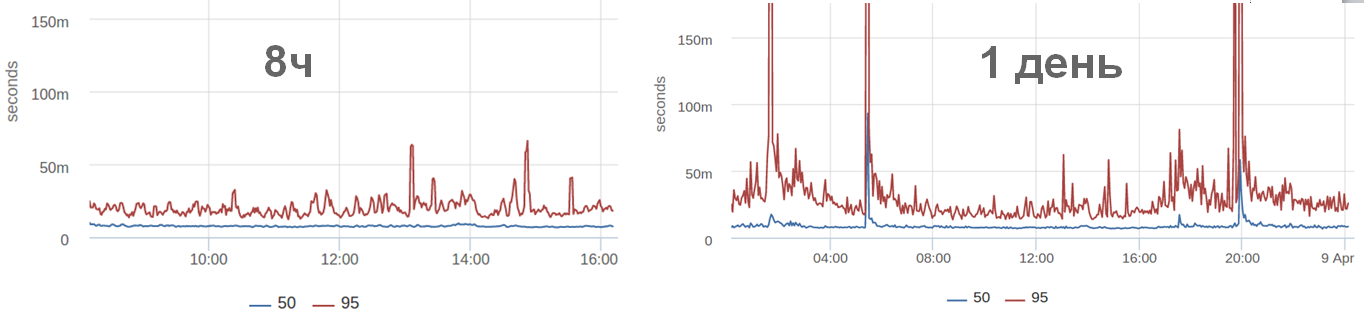
Например, мы смотрим график за 8 часов и ничего особенного не происходит, а ночью произошли выбросы. Часто можно видеть (и в этом конкретном случае) ночью запросов меньше. И вроде всё должно быстрее работать. А с точки зрения перцентилей, все работает не обязательно быстрее, а как угодно. Потому что может быть действительно быстрее, а могут быть, например, холодные кэши, из-за которых медленная отдача.
Вернемся к количеству девяток.
Про что мы забыли, или а как же пользователи?
Пока мы обсуждали системы массового обслуживания, запросы, сервисы, перцентили, мы потеряли реальных пользователей. Пользователи — это не запросы, а люди. Они бродят на сайте (или в мобильном приложении) и хотят там что-то совершить через промежуточные шаги, которых часто больше, чем 1. А статистику мы измеряем по единичным запросам.
- Сессии длятся долго;
- Общее впечатление об отзывчивости сервиса;
- Один плохой response time сильно влияет;
- Важные ajax’ы и прочие ресурсы.
У каждого пользователя на сессии своя глубина просмотра. Но:
- Вероятность одной страницы быть лучше, чем p99, равна 99%;
- Вероятность N страницам быть не хуже p99 равна (0.99N)*100%;
- Число пользователей которые наткнутся на что-то хуже p99 равно (1 — (0.99N))*100%
- Для p99 и N = 10 это 10%;
- Для p99.9 и N = 20 это 2%
Мы считаем, что осталось всего 1% пользователей, на которых мы забиваем, если мониторим 99-й перцентиль. Но опять все не так и это целых 10%!
А когда мы говорим про latency отдельных подзапросов, которые уже идут непосредственно в базу данных, или к какому-то веб-сервису, или application серверу, то соотношение еще больше.
Поэтому 99.9% это зачастую недостаточно «высокий» перцентиль, на который надо ориентироваться.
Заключение
Любой статистик скажет: «Не доверяйте интуиции в статистике!»
Я вам говорю: «Не доверяйте интуиции в мониторинге!»

Контакты
Павел Труханов на хабрахабре — @tru_pablo
Блог компании и сам сервис okmeter.io.
С этим жить вообще никак невозможно. То есть, если поставить 40 секунд, то это не мониторинг, а фигня; если поставить 300 миллисекунд, то получается по 100 алертов в час.
Вопрос в том — как жить?
Во-первых, ура вашему Product Owner’у, что он понимает, что такое перцентиль, потому что мои Product Owner’ы, когда я им говорю: «Такой-то перцентиль, такое-то время», одно число могут понять, два числа — уже финиш!
Возвращаясь к вопросу. Ответ честный и очень простой — не надо было столько времени на это тратить. Вы вырыли себе яму, у вашего Product Owner’а есть возможность посмотреть графики перцентиля (или задать вам этот вопрос). Вы в нее падаете и спрашиваете меня, как вам в нее не падать. Не ройте себе яму — не будете в нее падать.
Не надо следить за перцентилями — это неправильно. Мы в Okmeter рекомендуем выбирать пороги не на поведение перцентили, а на то, что вы считаете нужным. Например, чтобы пользователь хорошо себя чувствовал, когда сайт быстро открылся (или медленно).
Это зависит от миллиона параметров, начиная, естественно, от самого сервиса. Но в то же время есть гайдлайны от лидеров индустрии. Google говорит, что 400 миллисекунд server time — это нормально. Amazon объясняет, что задержка в добавочных 100 миллисекунд поверх 400 приводит к падению conversion rate на 9%, по другим оценкам на 16%. Но на мой взгляд, вы как владелец этой системы должны решить, что в таких ситуациях пользователь должен видеть страницу за такое время, она должна отрабатываться.
Дальше вы не рисуете перцентили. Перцентили в мониторинге — это зло!
Рисуя их, вы, вместо того, чтобы использовать свое внутреннее соображение (или внешнее гугловое) и сказать, что он должен работать до такого-то порога, начинаете смотреть на график:
— Смотри, у нас 50 миллисекунд отвечают страницы вот этого типа!
— Очень хорошо! Давай такой порог поставим!
Нет, не надо так делать! Вы определитесь, что сервер должен отвечать за 400 миллисекунд. Дальше вы рисуете — он отвечал за 400 миллисекунд в таком количестве процентов. Похуже, но еще терпимо, до секунды у нас столько-то процентов. А то, что выше секунды — это все уже не годится!
Тогда вы можете это отслеживать, тогда нет такой проблемы, что у вас спрашивают про гарантированное время.
Да, бывает, что IT система ведет себя похоже на логнормал — блямбу с длинным хвостом. На самом деле, я вижу (у нас много статистики от клиентов), что этот хвост часто толще обычного, и дальше идет, чем у логнормального распределения.
Это типичная реальная ситуация — не у всех, но у многих.
Когда вам задают вопрос: «Вы давно перестали пить коньяк по утрам?» — не надо на него отвечать. Когда вас спрашивают: «Какое у нас гарантированное время ответа сервера?» — нет такого гарантированного времени. Сервер упал, дата-центр сгорел, метеорит свалился — и время ответа сервера два дня, пока его чинят.
Ответ такой — out of the box. В рамках перцентили честно ответить нельзя.
— Вопрос опять про мониторинг. Там есть разные анализы, чтобы понять, что происходит. Классическая модель — можно построить 50-ю, 90-ю, 99-ю перцентиль, и так далее. Вопрос — какой инструмент визуализации вы рекомендуете — open source, не open source? Как делать анализ временных трендов, именно находить матчинги, еще что-то?
Если я правильно понял вопрос. Допустим, если мы действительно говорим про post mortem, в этот момент не нужны графики. Мониторинг — это мониторинг, post mortem — это post mortem. Это разные вещи.
Хочется, конечно, как всегда, silver bullet иметь из какой-то системы, в которой все есть, она все показывает, еще и сохраняет — можно в ней постфактум все это посмотреть. Но это нереально — это просто совершенно разные системы. Такой ответ, если по чесноку.
— Помимо перцентилей и среднего, какие ещё интересные математические метрики и графики можете предложить? Мы, например, в продуктовой компании не считаем отклики с сайта.
Мне подсказывают на ухо — сигма. Но я забыл про это сказать, как водится.
Я уже показывал колокол, который все знают. Эти идеи, что 3 сигмы позволяют отрезать так, чтобы было 0,1, к вашей системе никакого отношения не имеют. Сама идея стандартного отклонения, конечно, применима к любому распределению. Это просто попытка оценить в каком-то смысле ширину вашего распределения.
Есть много разных способов оценки, например, интерквартильные интервалы — это когда вы смотрите, как далеко друг от друга стоят 25-я и 75-я перцентили.
Откройте английскую Википедию — там гигантский список. У каждого способа есть свои ограничения, свои плюсы и минусы. Опять же — нет универсального метода. Все зависит от задачи. Для мониторинга не нужны никакие из них.
Вам нужно другое — спросить своего Product Owner’а, какой тайминг будет плох для нашего пользователя? Вы можете эксперимент провести, как Amazon. Они рапортовали, что задержка в 100 миллисекунд, если они на год ее умножают, стоит нереальных денег. Вы может провести такой же эксперимент сами.
Я хотел показать, что это все неправильный в принципе подход:
— Вот у нас система мониторинга, в нее кто-то со StatsD уже напилил статистику, она там что-то репортует. Давай ее использовать!
— Нет, Паша нам показал — она плохая, давай другую статистику!
Нет, подход к своей задаче должен быть с другого конца.
Но если вы просите интересных метрик, то вот одна. Есть классная наивная штука, перенесенная из биологии: LD50 (lethal dose) — сколько нужно дать яда популяции крыс или лабораторных мышей, чтобы в среднем половина умерла.
Соответственно то же самое можно применить к вашим пользователям — на сколько надо затормозить ваши странички, чтобы половина пользователей отвалилась. Вы будете знать, что туда вы уже не хотите потому, что это половина денег. Если это бизнес, то все в деньгах.
— Я так понимаю, что разговор идет про техническими метрики, тем более, про тайминги. Тут все достаточно просто: мало — хорошо, много — чуть хуже.
А что, если мы хотим мониторить какую-то продуктовую метрику — конверсию, например? Там все чуть сложнее? Например, нужно смотреть корреляции — умеет ли это ваш продукт, и думали вы вообще в этом направлении?
Нет, okmeter не мониторит конверсии, это real-time мониторинг инфраструктуры. Эта информация есть на нашем сайте.
— Я понял, что на самом деле подход, который Вы пропагандируете, мне не очень нравится — что давайте спросим у пользователя, что ему хорошо, а что плохо.
Мне нравится, когда мы оперируем девятками. То есть у нас есть 99,9% пользователей, которым за какое-то время мы гарантированно что-то покажем, ответим или не ответим.
Это немножко про перцентиль, но это не совсем про перцентиль, а про качество. То есть мы не за какое-то конкретное время отвечаем (99,9 или 99,999), а мы гарантируем качество нашего продукта для конкретного сервиса.
Спасибо большое, я очень рад этому вопросу!
У меня есть 2 соображения:
- В первом вопросе прозвучала цифра — 99-й перцентиль — 40 с. Давайте оперировать девятками! Серьезно, это хороший совет! (табличка sarcasm)
- Второй мой point в том, что привычное — оно привычно, и не требует усилий.
Всегда очень сложно впитать что-то новое. Конечно, можно так — послушал “он стройно излагает, наверное, много репетировал, картинки классные! Но на самом деле я останусь при своем”.
Это очень-очень легкий для мозга выход — такие рельсы — я послушал, и буду делать как раньше — смотреть на 99,9-й! Это всегда проще — не учиться новому!
— Я все-таки запутался — хорошая звучала тема по поводу робастности. Если мы все-таки возвращаемся к пользовательским метрикам, чего им нужно, что для них плохая загрузка страницы и так далее, то мы сразу теряем всю историю про робастность.Как здесь быть? Каким образом прийти к клиентским метрикам, но учитывать шум, случайные выбросы.
Какой случайный шум — в этом весь вопрос — что-то страшное и грязное на той стороне, не будем туда смотреть?
Или что у пользователя есть Apdex score, который говорит — давайте возьмем тайминг, в 4 раза больше пользователей еще потерпят, а я дальше уже нет.
Что значит, что дальше нет? Вы готовы жертвовать этим количеством людей? На другой чаше весов, сколько вам, как инжиниринговому департаменту заниматься тем, чтобы этого не было?
— Тут, скорее, вопрос из области того, когда у нас мониторинг на ошибки в логах, причем прикладные на уровне логики.
Про ошибки я буду готовить другой доклад, у меня есть соображения на эту тему.
— Все-таки пытаюсь разобраться — берем 300-400 миллисекунд, ставим порог по нему. Какой же график должен этот порог прорвать?
— Сколько за порогом, сколько до порога. Гистограмму распределения по заранее определенным вами интервалам.
Для обсуждения вопросов мониторинга, наравне с другими аспектами DevOps, на нашем фестивале РИТ++ есть отдельная конференция RootConf. Мы рады новым и старым докладчикам и ждем ваши заявки. Билеты тоже уже в продаже, но пока вслепую — без программы.
Комментариев нет:
Отправить комментарий