
Сегодня, во второй части перевода, Томаш Рудски расскажет о наиболее распространённых SEO-ошибках, которым подвержены сайты, основанные на JavaScript, обсудит последствия грядущего отказа Google от механизма AJAX-сканирования, поговорит о предварительном рендеринге и об изоморфном JavaScript, поделится результатами экспериментов по индексированию. Здесь, кроме того, он затронет тему особенностей ранжирования сайтов различных видов и предложит вспомнить о том, что помимо Google есть и другие поисковики, которым тоже приходится сталкиваться с веб-страницами, основанными на JS.
О ресурсах, необходимых для успешного формирования страницы
Если, по вашему мнению, Googlebot вполне сможет обработать некую страницу, но при этом оказывается, что данная страница не индексируется так, как нужно, проверьте, чтобы внешние и внутренние ресурсы (JS-библиотеки, например), требуемые для формирования страницы, были доступны поисковому роботу. Если он не сможет что-то загрузить и правильно воссоздать страницу, об её индексировании можно и не говорить.
О периодическом использовании Google Search Console
Если вы вдруг столкнулись со значительным падением рейтинга сайта, который до этого работал стабильно и надёжно, рекомендую воспользоваться описанными ранее средствами Fetch и Render для того, чтобы проверить, в состоянии ли Google правильно обработать ваш сайт.
В общем случае, полезно время от времени использовать Fetch и Render на произвольном наборе страниц сайта для того, чтобы проверить возможность его правильной обработки поисковиком.
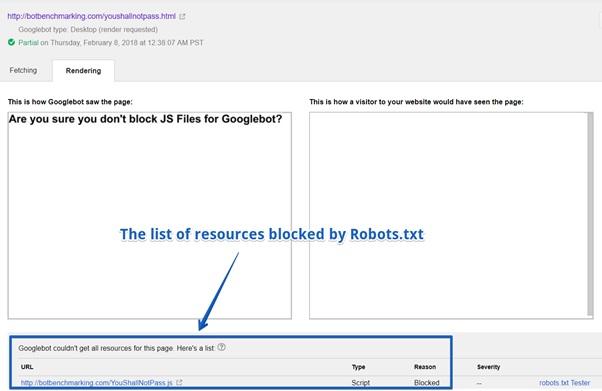
Список ресурсов, заблокированных с помощью Robots.txt
Опасное событие onClick
Помните о том, что Googlebot — это не настоящий пользователь, поэтому примите как должное то, что он не «щёлкает мышью» по ссылкам и кнопкам и не заполняет формы. У этого факта есть немало практических последствий:
- Если у вас имеется интернет-магазин и некие тексты скрыты под кнопками вроде «Подробнее…», но при этом они не присутствуют в DOM до щелчка по соответствующей кнопке, Google эти тексты не прочтёт. Это же имеет отношение и к ссылкам, появляющимся по такому же принципу в меню.
- Все ссылки должны содержать параметр
href. Если вы полагаетесь только на событиеonClick, Google такие ссылки не воспримет.
Это подтверждает и Джон Мюллер:
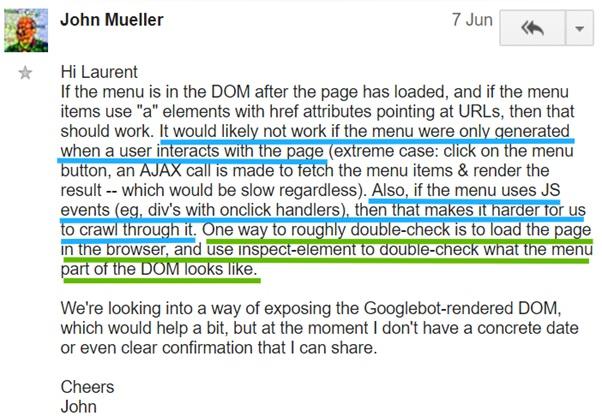
Комментарий Джона Мюллера, подтверждающий вышесказанное
В одном из моих предыдущих материалов, который посвящён использованию Chrome 41 для исследования сайтов, имеется краткое руководство, демонстрирующее процесс проверки меню на предмет доступности его для системы индексирования Google. Советую с этим материалом ознакомиться.
Использование значков # в ссылках
Всё ещё распространена практика, в соответствии с которой JS-фреймворки создают URL-адреса со знаком
#. Существует реальная опасность того, что Googlebot не обработает подобные ссылки.
Вот несколько примеров:
- Плохой URL: example.com/#/crisis-center/
- Плохой URL: example.com#URL
- Хороший URL: example.com/crisis-center/
Обратите внимание на то, что это не относится к URL с последовательностью символов
#! (так называемый hashbang).
Возможно вы решите, что всё это не имеет особого значения. Действительно — большое дело — всего один дополнительный символ в адресе. Однако, это очень важно.
Позволю себе в очередной раз процитировать Джона Мюллера:
«(…) С нашей точки зрения, если мы видим тут нечто вроде знака #, это означает, что то, что идёт за ним, возможно, неважно. По большей части, индексируя содержимое, мы подобные вещи игнорируем (…). Когда вам нужно сделать так, чтобы это содержимое действительно появилось в поиске, важно, чтобы вы использовали ссылки, выглядящие более статично».
В итоге можно сказать, что веб-разработчикам стоит постараться, чтобы их ссылки не выглядели как нечто вроде example.com/resource#dsfsd. При использовании фреймворков, формирующих такие ссылки, стоит обратиться к их документации. Например, Angular 1 по умолчанию, использует адреса, в которых применяются знаки #. Исправить это можно, соответствующим образом настроив$locationProvider. А вот, например, Angular 2 и без дополнительных настроек использует ссылки, которые хорошо понимает Googlebot.
О медленных скриптах и медленных API
Многие сайты, основанные на JavaScript испытывают проблемы с индексированием из-за того, что Google приходится слишком долго ждать результатов работы скриптов (имеется в виду ожидание их загрузки, разбора, выполнения). Медленные скрипты могут означать, что Googlebot быстро исчерпает бюджет сканирования вашего сайта. Добейтесь того, чтобы ваши скрипты были быстрыми, и Google не приходилось бы слишком долго ждать их загрузки. Тем, кто хочет узнать подробности об этом, рекомендую ознакомиться с этим материалом, посвящённым оптимизации процесса визуализации страниц.
Плохая поисковая оптимизация и SEO с учётом особенностей сайтов, основанных на JavaScript
Хочу поднять здесь проблему, которая может повлиять даже самую лучшую поисковую оптимизацию сайтов.

Традиционный подход к SEO и SEO с учётом особенностей JS
Важно помнить, что SEO с учётом особенностей JavaScript выполняется на базе традиционной поисковой оптимизации. Невозможно хорошо оптимизировать сайт с учётом особенностей JS, не добившись достойной оптимизации в обычном смысле этого слова. Иногда, когда вы сталкиваетесь с проблемой SEO, вашим первым ощущением может стать то, что это связано с JS, хотя, на самом деле, проблема — в традиционной поисковой оптимизации.
Не буду вдаваться в подробности подобных ситуаций, так как это уже отлично объяснил Джастин Бриггс в своём материале «Core Principles of SEO for JavaScript», в разделе «Confusing Bad SEO with JavaScript Limitations». Рекомендую почитать эту полезную статью.
Со второго квартала 2018 года Googlebot не будет использовать AJAX-сканирование
Компания Google сообщила о том, что со второго квартала 2018 года она больше не будет использовать AJAX-сканирование (AJAX Crawling Scheme). Значит ли это, что Google прекратит индексировать сайты, используя Ajax (асинхронный JavaScript)? Нет, это не так.
Стоит сказать о том, что AJAX-сканирование появилось в те времена, когда компания Google поняла, что всё больше и больше сайтов использует JS, но не могла правильно обрабатывать такие сайты. Для того, чтобы решить эту проблему, веб-мастерам предложили создавать особые версии страниц, предназначенные для поискового робота и не содержащие JS-скриптов. К адресам этих страниц надо было добавлять _=escaped_fragment_=.
На практике это выглядит так: пользователи работают с полноценным и приятно выглядящим вариантом example.com, а Googlebot посещает не такой симпатичный эквивалент сайта, к которому ведёт ссылка вида example.com?_=escaped_fragment_= (это, кстати сказать, всё ещё очень популярный подход подготовки материалов для ботов).
Вот как это работает (изображение взято из блога Google).
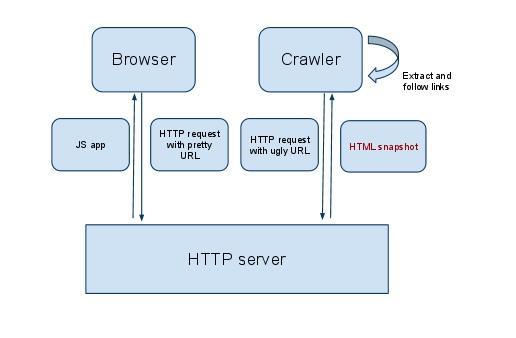
Разные версии сайта для пользователей и для ботов
Благодаря такому подходу веб-мастера получили возможность убить двух зайцев одним выстрелом: и пользователи довольны, и поисковый робот счастлив. Пользователи видят версию сайта, оснащённую возможностями JavaScript, а поисковые системы могут правильно индексировать страницы этого сайта, так как им достаются лишь обычные HTML и CSS.
О проблемах AJAX-сканирования
Проблемы Ajax Crawling Scheme заключаются в том, что так как пользователи и поисковые роботы получают разные версии сайта, очень сложно анализировать неполадки, связанные с индексированием сайтов. Кроме того, у некоторых веб-мастеров возникали проблемы с предварительной подготовкой версий страниц, предназначенных для поискового робота.
Именно поэтому Google сообщила, что начиная со второго квартала 2018 года веб-мастерам больше не нужно создавать две разные версии веб-сайта:

Сообщение об отключении AJAX-сканирования
Как это повлияет на веб-разработчиков?
- Google теперь будет формировать страницы сайтов своими средствами. Это означает, что разработчикам необходимо обеспечить то, чтобы у Google была техническая возможность сделать это.
- Googlebot прекратит посещать ссылки, содержащие
_=escaped_fragment_=и начнёт запрашивать те же материалы, которые предназначены для обычных пользователей.
Кроме того, разработчикам понадобится найти способ сделать свои сайты доступными для Bing и других поисковых систем, которые пока далеко позади Google в деле обработки сайтов, основанных на JavaScript. Среди возможных решений можно отметить серверный рендеринг (универсальный JavaScript), или, как ни странно, продолжение использования старого AJAX-сканирования для Bingbot. Об этом мы поговорим ниже.
Будет ли Google использовать самый современный браузер для обработки страниц?
Сейчас неясно, планирует ли Google обновлять свою службу обработки сайтов с целью поддержки самых свежих технологий. Нам остаётся лишь надеяться на то, что это будет сделано.
Как быть тем, кто не хочет, чтобы Google обрабатывал его страницы, основанные на JS, а довольствовался лишь заранее подготовленными страницами?
Я много об этом думал, и именно поэтому решил спросить Джона Мюллера на форуме, посвящённом JavaScript SEO, о том, могу ли я обнаружить Googlebot по
User-Agent и просто отдать ему заранее подготовленную версию сайта.

Вопрос Джону Мюллеру о версии сайта, подготовленной специально для Googlebot
Вот что он ответил:

Ответ Джона Мюллера
Джон согласен с тем, что разработчик можете узнать, что его сайт сканирует Googlebot, проверяя заголовок User-Agent и отдать ему заранее подготовленный HTML-снимок страницы. Вдобавок к этому он советует регулярно проверять снимки страниц для того, чтобы быть уверенным в том, что предварительный рендеринг страниц работает правильно.
Не забудьте про Bing!
Представим себе, что Googlebot идеально обрабатывает сайты, основанные на JS-фреймворках и с ним у вас нет никаких сложностей. Значит ли это, что можно забыть обо всех проблемах, связанных с индексированием таких сайтов? К сожалению — не значит. Вспомним о поисковике Bing, который, в США, применяет около трети интернет-пользователей.
В настоящее время разумно будет считать, что Bing вообще не занимается обработкой JavaScript (ходят слухи, что Bing обрабатывает JS на страницах с высоким рейтингом, но мне не удалось найти ни одного подтверждения этим слухам).
Позвольте мне рассказать об одном интересном исследовании.
Angular.io — это официальный веб-сайт Angular 2+. Некоторые страницы этого сайта созданы в виде одностраничных приложений. Это означает, что их исходный HTML-код не содержит никакого контента. После загрузки такой страницы подгружается внешний JS-файл, средствами которого и формируется наполнение страниц.

Сайт Angular.io
Возникает такое ощущение, что Bing не видит содержимого этого сайта!
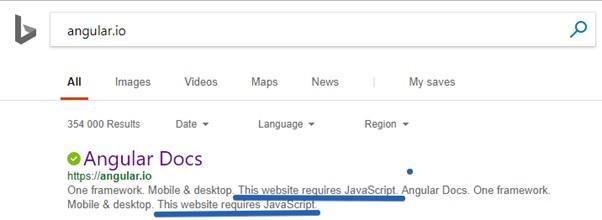
Bing не видит содержимого сайта Angular.io
Этот сайт занимает вторую позицию по ключевому слову «Angular» в Bing.
Как насчёт запроса «Angular 4». Снова — вторая позиция, ниже сайта AngularJS.org (это — официальный сайт Angular 1). По запросу «Angular 5» — опять вторая позиция.
Если вам нужны доказательства того, что Bing не может работать с Angular.io — попытайтесь найти какой-нибудь фрагмент текста с этого сайта, воспользовавшись командой site. У вас ничего не получится.
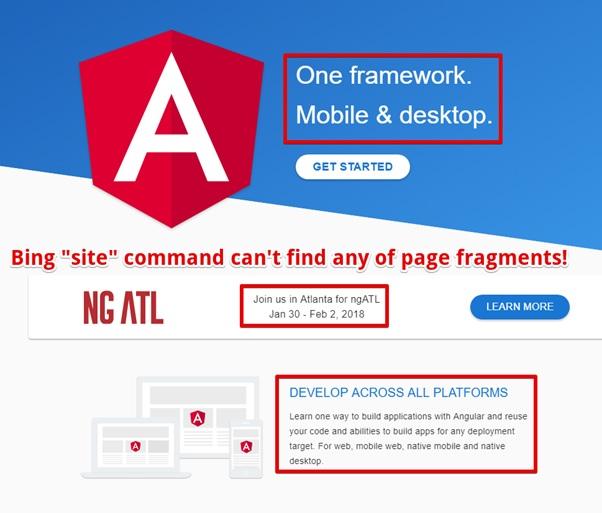
Выбор фрагмента текста для проверки
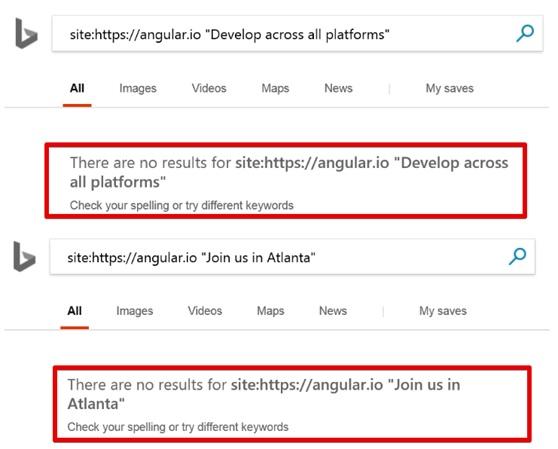
Текст, при поиске по сайту, не найден
По мне, так это странно. Получается, что официальный сайт Angular 2 не может быть нормально просканирован и проиндексирован роботом Bingbot.
А как насчёт Яндекса? Angular.io даже не входит в топ-50 результатов при поиске по слову «Angular» в Яндексе!

Сайт Angular.io в Яндексе
В Твиттере я обратился к команде Angular.io, задал им вопрос о том, планируют ли они что-то делать для того, чтобы их сайт могли индексировать поисковые системы вроде Bing, но они, на момент написания этого материала, пока не ответили мне.
Собственно говоря, из вышесказанного можно сделать вывод о том, что, в стремлении внедрять на свои сайты новые веб-технологии не стоит забывать о Bing и о других поисковиках. Тут можно порекомендовать два подхода: изоморфный JavaScript и предварительный рендеринг.
Предварительный рендеринг и изоморфный JavaScript
Когда вы замечаете, что Google испытывает сложности с индексацией вашего сайта, рендеринг которого выполняется на клиенте, вы можете рассмотреть возможность использования предварительного рендеринга или преобразования сайта в изоморфное JavaScript-приложение.
Какой из подходов лучше?
- Предварительный рендеринг применяется в тех случаях, когда вы замечаете, что поисковые роботы не в состоянии правильно сформировать страницы вашего веб-сайта и вы выполняете эту операцию самостоятельно. Когда робот посещает ваш сайт, вы просто отдаёте ему HTML-копии страниц (они не содержат JS-кода). В то же время, пользователи получают версии страниц, оснащённых возможностями JS. Копии страниц используются лишь ботами, но не обычными пользователями. Для предварительного рендеринга страниц вы можете применять внешние сервисы (вроде prerender.io), или использовать инструменты вроде PhantomJS или Chrome без пользовательского интерфейса на своих серверах.
- Изоморфный JavaScript — это ещё один популярный поход. При его применении и поисковая система, и пользователи, при первой загрузке страницы, получают все необходимые данные. Затем загружаются JS-скрипты, которые работают уже с этими, предварительно загруженными, данными. Это хорошо и для обычных пользователей, и для поисковых систем. Данный вариант рекомендуется к использованию, его поддерживает даже Google.
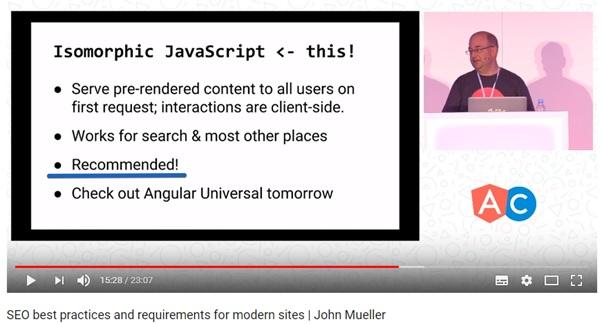
Google рекомендует изоморфный JavaScript
Однако тут есть одна проблема, которая заключается в том, что многие разработчики не могут правильно создавать изоморфные JavaScript-приложения.
Если вас привлекает серверный рендеринг — посмотрите документацию по используемому вами JS-фреймворку. Например, в случае с Angular вы можете применить Angular Universal. Если вы работаете с React — почитайте документацию и посмотрите этот учебный курс на Udemy.
React 16 (он вышел в ноябре) принёс в сферу серверного рендеринга множество улучшений. Одно из таких улучшений — функция RenderToNodeStream, которая упрощает весь процесс серверного рендеринга.
Если говорить об общем подходе к серверному рендерингу, то хотелось бы отметить одну важную рекомендацию. Она заключается в том, что если нужно, чтобы сайт рендерился на сервере, разработчикам следует избегать использования функций, которые напрямую воздействуют на DOM.
Всегда, когда это возможно, дважды подумайте прежде чем работать напрямую с DOM. Если вам нужно взаимодействие с DOM браузера — воспользуйтесь Angular Renderer или абстракцией рендеринга.
Одинаково ли Googlebot обрабатывает HTML и JS-сайты?
Мы, в Elephate, провели некоторые эксперименты для того, чтобы выяснить, насколько глубоко Googlebot может продвинуться в обнаружении ссылок и в переходах по ним в случае сканирования сайтов, использующих лишь HTML, и сайтов, основанных на JavaScript.
Исследование дало поразительные результаты. В случае HTML-сайта Googlebot смог проиндексировать все страницы. Однако, при обработке сайта, основанного на JS, вполне обычной была ситуация, когда Googlebot не добрался даже до его второго уровня. Мы повторили эксперимент на пяти различных доменах, но результат всегда был одним и тем же.

Эксперимент по индексированию HTML-сайтов и сайтов, основанных на JS
Бартош Горалевич обратился к Джону Мюллеру из Google, и задал ему вопрос об источниках проблемы. Джон подтвердил, что Google видит ссылки, сгенерированные средствами JavaScript, но «Googlebot не стремится их сканировать». Он добавил: «Мы не сканируем все URL, или сканируем все их быстро, особенно когда наш алгоритм не уверен в ценности URL. Ценность контента — неоднозначный аспект тестовых сайтов».
Если вы хотите углубиться в эту тему, рекомендую взглянуть на этот материал.
Подробности об эксперименте по индексированию тестовых сайтов
Хочу поделиться некоторыми моими идеями относительно вышеописанного эксперимента. Так, нужно отметить, что хотя исследуемые сайты были созданы лишь в экспериментальных целях, к их наполнению применялся один и тот же подход. А именно, их тексты были созданы средствами Articoolo — интересного генератора контента, основанного на технологиях искусственного интеллекта. Он выдаёт довольно хорошие тексты, которые определённо лучше моей писанины.
Googlebot получал два очень похожих веб-сайта и сканировал лишь один из них, предпочитая HTML-сайт сайту, на котором применяется JS. Почему это так? Выдвину несколько предположений:
- Гипотеза №1. Алгоритмы Google классифицировали оба сайта как тестовые, после чего назначили им фиксированное время выполнения. Скажем, это может быть что-то вроде индексирования 6-ти страниц, или 20 секунд рабочего времени (загрузка всех ресурсов и формирование страниц).
- Гипотеза №2. Googlebot классифицировал оба сайта как тестовые. В случае с JS-сайтом он отметил, что загрузка ресурсов занимает слишком много времени, поэтому просто не стал его сканировать.
На вышеупомянутые веб-сайты имеется множество высококачественных реальных ссылок. Многие люди охотно делились ссылками на них в интернете. Кроме того, на них поступал органический трафик. И тут возникает вопрос о том, как отличить тестовый сайт от реального. Это непростая задача.
Есть немалая вероятность того, что если вы создадите новый сайт, который рендерится на клиенте, вы попадёте в точно такую же ситуацию, как и мы. Googlebot, в таком случае, просто не станет его сканировать. Именно тут заканчивается теория и начинаются реальные проблемы. Кроме того, главная проблема здесь заключается в том, что нет практически ни одного примера из реальной жизни, когда веб-сайт, или интернет-магазин, или страница компании, на которых применяется клиентский рендеринг, занимают высокую позицию в поисковой выдаче. Поэтому я не могу гарантировать того, что ваш сайт, наполненный возможностями JavaScript, получит столь же высокую позицию в поиске, как и его HTML-эквивалент.
Вы можете решить, что, наверняка, большинство SEO-специалистов это и так знают, и большие компании могут направить определённые средства на борьбу с этими проблемами. Однако, как насчёт небольших компаний, у которых нет средств и знаний? Это может представлять реальную опасность для чего-то вроде сайтов маленьких семейных ресторанов, которые используют визуализацию на стороне клиента.
Итоги
Подведём краткие итоги, обобщив в следующем списке выводы и рекомендации:
- Google использует Chrome 41 для рендеринга веб-сайтов. Эта версия Chrome была выпущена в 2015-м году, поэтому она не поддерживает все современные возможности JavaScript. Вы можете использовать Chrome 41 для того, чтобы проверить, сможет ли Google правильно обрабатывать ваши страницы. Подробности об использовании Chrome 41 можно найти здесь.
- Обычно недостаточно анализировать лишь исходный HTML-код страниц сайта. Вместо этого следует взглянуть на DOM.
- Google — это единственная поисковая система, которая широко применяет рендеринг JavaScript.
- Не следует использовать кэш Google для проверки того, как Google индексирует содержимое страниц. Анализируя кэш? можно лишь увидеть то, как ваш браузер интерпретирует HTML-данные, которые собрал Googlebot. Это не имеет отношения к тому, как Google обрабатывает эти данные перед индексированием.
- Регулярно используйте инструменты Fetch и Render. Однако не полагайтесь на их тайм-ауты. При индексировании могут применяться совершенно другие тайм-ауты.
- Освойте команду
site. - Обеспечьте присутствие пунктов меню в DOM ещё до того, как пользователь вызывает это меню щелчком мыши.
- Алгоритмы Google пытаются определить ценность ресурса с точки зрения целесообразности обработки этого ресурса для формирования страницы. Если, по мнению этих алгоритмов, ресурс ценности не представляет, Googlebot, возможно, не станет его загружать.
- Веб-разработчикам стоит стремиться к тому, чтобы обеспечить скорость выполнения скриптов (множество экспериментов указывают на то, что Google вряд ли станет ждать результатов выполнения скрипта, включая этап загрузки, более 5 секунд). Кроме того, постарайтесь оптимизировать скрипты. Как правило, большинство скриптов можно улучшать и улучшать!
- Если Google не может сформировать страницу, используя JavaScript, он может решить проиндексировать изначально загруженный HTML. Это может очень плохо сказаться на одностраничных приложениях, так как Google, при таком подходе, проиндексирует пустую страницу.
- Нет практически ни одного реального примера сайта, применяющего рендеринг средствами клиента, который занимает высокие позиции в поисковой выдаче. Как вы думаете, почему?
С точки зрения SEO неясно, обрабатывает ли (и ранжирует ли!) Google страницы, основанные на JavaScript так же, как страницы, где используется только HTML. Зная это, очевидно то, что SEO-специалисты и разработчики только начинают подходить к пониманию того, как сделать современные JS-фреймворки такими, чтобы сайты, построенные на их основе, нормально обрабатывались бы поисковыми роботами. Поэтому важно помнить о том, что в сфере SEO для JavaScript-сайтов нет некоего универсального свода правил. Каждый веб-сайт своеобразен. В итоге же можно сказать, что если вы хотите создать сайт, вовсю использующий возможности современного JavaScript, убедитесь в том, что ваши разработчики и специалисты в области SEO знают свою работу.
Уважаемые читатели! Сталкивались ли вы, в личной практике, с проблемами индексации сайтов, основанных на JS-фреймворках?

Комментариев нет:
Отправить комментарий