Язык программирования Python в последнее время все чаще используется для анализа данных, как в науке, так и коммерческой сфере. Этому способствует простота языка, а также большое разнообразие открытых библиотек.
В этой статье разберем простой пример исследования и классификации данных с использованием некоторых библиотек на Python. Для исследования, нам понадобится выбрать интересующий нас набор данных (DataSet). Разнообразные наборы Dataset'ы можно скачать с сайта. DataSet обычно представляет собой файл с таблицей в формате JSON или CSV. Для демонстрации возможностей исследуем простой набор данных с информацией о наблюдениях НЛО. Наша цель будет не получить исчерпывающие ответы на главный вопрос жизни, вселенной и всего такого, а показать простоту обработки достаточно большого объема данных средствами Python. Собственно, на месте НЛО могла быть любая таблица.
И так, таблица с наблюдениями имеет следующие столбцы:
Для тех, кто хочет пробовать нуля, подготовим рабочее место. У меня на домашнем ПК стоит Ubuntu, поэтому покажу для нее. Для начала нужно установить сам интерпретатор Python3 с библиотеками. В убунту подобном дистрибутиве это будет:
sudo apt-get install python3
sudo apt-get install python3-pip
pip — это система управления пакетами, которая используется для установки и управления программными пакетами, написанными на Python. С её помощью устанавливаем библиотеки, которые будем использовать:
-
sklearn — библиотека, алгоритмов машинного обучения, она понадобится нам в дальнейшем для классификации исследуемых данных,
-
matplotlib — библиотека для построения графиков,
-
pandas — библиотека для обработки и анализа данных. Будем использовать для первичной обработки данных,
-
numpy — математическая библиотека с поддержкой многомерных массивов,
-
yandex-translate — библиотека для перевода текста, через yandex API (для использования нужно получить API ключ в яндексе),
-
pycountry — библиотека, которую будем использовать для преобразования кода страны в полное название страны,
Используя pip пакеты ставятся просто:
pip3 install sklearn
pip3 install matplotlib
pip3 install pandas
pip3 install numpy
pip3 install yandex-translate
pip3 install pycountry
Файл DataSet — scrubbed.csv должен лежать в рабочей директории, где создается файл программы.
Итак приступим. Подключаем модули, которые используются нашей программой. Модуль подключается с помощью инструкции:
import <название модуля>
Если название модуля слишком длинное, и/или не нравится по соображениям удобства или политическим убеждениямм, то с помощью ключевого слова as для него можно создать псевдоним:
import <название модуля> as <псевдоним>
Тогда, чтобы обратиться к определенному атрибуту, который определен в модуле
<название модуля>.<Атрибут>
или
<псевдоним>.<Атрибут>
Для подключения определенных атрибутов модуля используется инструкция from. Для удобства, чтобы не писать названия модуля, при обращении к атрибуту, можно подключить нужный атрибут отдельно.
from <Название модуля> import <Атрибут>
Подключение нужных нам модулей:
import pandas as pd
import numpy as np
import pycountry
import matplotlib.pyplot as plt
from matplotlib import cm
from mpl_toolkits.mplot3d import Axes3D
from yandex_translate import YandexTranslate # Используем класс YandexTranslate из модуля yandex_translate
from yandex_translate import YandexTranslateException # Используем класс YandexTranslateException из модуля yandex_translate
Для того, что бы улучшить наглядность графиков, напишем вспомогательную функцию для генерации цветовой схемы. На входе функция принимает количество цветов, которое необходимо сгенерировать. Функция возвращает связный список с цветами.
# Генерация цветовой схемы
# Возвращает список цветов
def getColors(n):
COLORS = []
cm = plt.cm.get_cmap('hsv', n)
for i in np.arange(n):
COLORS.append(cm(i))
return COLORS
Для перевода некоторых названий с англиского на русский язык создадим функцию translate. И да, нам понадобится интернет, чтобы воспользоваться API переводчика от Яндекс.
Функция принимает на вход аргументы:
- string — строка, которую нужно перевести,
- translator_obj — объект в котором реализован переводчик, если равен None, то строка не переводится.
и возвращает переведенную на русский язык строку.
def translate(string, translator_obj=None):
if translator_class == None:
return string
t = translator_class.translate(string, 'en-ru')
return t['text'][0]
Инициализация объекта переводчика должна быть в начале кода.
YANDEX_API_KEY = 'Здесь должен быть определен API ключ !!!!!'
try:
translate_obj = YandexTranslate(YANDEX_API_KEY)
except YandexTranslateException:
translate_obj = None
YANDEX_API_KEY — это ключ доступа к API Yandex, его следует получить в Яндексе. Если он пустой, то объект translate_obj инициализируется значением None и перевод будет игнорироваться.
Напишем еще одну вспомогательную функцию для сортировки объектов dict.
dict — представляет собой встроенный тип Python, где данные хранятся в виде пары ключ-значения. Функция сортирует словарь по значениям в убывающем порядке и возвращает отсортированные список ключей и соответсвуюущий ему по порядку следования элементов список значений. Эта функция будет полезна при построении гистограмм.
def dict_sort(my_dict):
keys = []
values = []
my_dict = sorted(my_dict.items(), key=lambda x:x[1], reverse=True)
for k, v in my_dict:
keys.append(k)
values.append(v)
return (keys,values)
Мы добрались до непосредственно данных. Для чтения файла с таблицей используем метод read_csv модуля pd. На вход функции подаем имя csv файла, и чтобы подавить предупреждения при чтении файла, задаем параметры escapechar и low_memory.
- escapechar — символы, которые следует игнорировать
- low_memory — настройка обработки файла. Задаем False для считывание файла целиком, а не частями.
df = pd.read_csv('./scrubbed.csv', escapechar='`', low_memory=False)
В некоторых полях таблицы есть поля со значением None. Этот встроенный тип, обозначающий неопределенность, поэтому некоторые алгоритмы анализа могут работать некорректно с этим значением, поэтому произведем замену None на строку 'unknown' в полях таблицы. Эта процедура называется импутацией.
df = df.replace({'shape':None}, 'unknown')
Поменяем коды стран на названия на русском языке с помощью библиотеки pycountry и yandex-translate.
country_label_count = pd.value_counts(df['country'].values) # Получить из таблицы список всех меток country с их количеством
for label in list(country_label_count.keys()):
c = pycountry.countries.get(alpha_2=str(label).upper()) # Перевести код страны в полное название
t = translate(c.name, translate_obj) # Перевести название страны на русский язык
df = df.replace({'country':str(label)}, t)
Переведем все названия видов объектов на небе на русский язык.
shapes_label_count = pd.value_counts(df['shape'].values)
for label in list(shapes_label_count.keys()):
t = translate(str(label), translate_obj) # Перевести название формы объекта на русский язык
df = df.replace({'shape':str(label)}, t)
Первичную обработку данных на этом завершаем.
Постороим график наблюдений по странам. Для построения графиков используется библиотека pyplot. Примеры построения простого графика можно найти на официальном сайте https://matplotlib.org/users/pyplot_tutorial.html. Для построения гистограммы можно использовать метод bar.
country_count = pd.value_counts(df['country'].values, sort=True)
country_count_keys, country_count_values = dict_sort(dict(country_count))
TOP_COUNTRY = len(country_count_keys)
plt.title('Страны, где больше всего наблюдений', fontsize=PLOT_LABEL_FONT_SIZE)
plt.bar(np.arange(TOP_COUNTRY), country_count_values, color=getColors(TOP_COUNTRY))
plt.xticks(np.arange(TOP_COUNTRY), country_count_keys, rotation=0, fontsize=12)
plt.yticks(fontsize=PLOT_LABEL_FONT_SIZE)
plt.ylabel('Количество наблюдений', fontsize=PLOT_LABEL_FONT_SIZE)
plt.show()
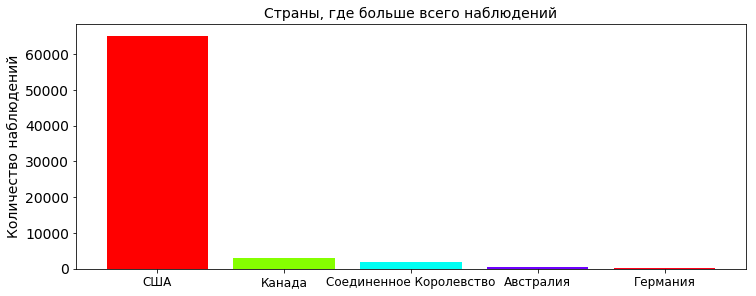
Больше всего наблюдений естественно в США. Тут ведь оно как, все гики, которые следят за НЛО живут в США (о версии, что таблица составлялась гражданами США, лукаво умолчим). Судя по количеству американских фильмов скорее всего второе. От Кэпа: если инопланетяне действительно посещали землю в открытую, то вряд ли бы их заинтересовала одна страна, сообщение об НЛО появлялись бы из разных стран.
Интересно еще посмотреть в какое время года наблюдали больше всего объектов. Есть резонное предположение, что больше всего наблюдений в весеннее время.
MONTH_COUNT = [0,0,0,0,0,0,0,0,0,0,0,0]
MONTH_LABEL = ['Январь', 'Февраль', 'Март', 'Апрель', 'Май', 'Июнь',
'Июль', 'Август', 'Сентябрь' ,'Октябрь' ,'Ноябрь' ,'Декабрь']
for i in df['datetime']:
m,d,y_t = i.split('/')
MONTH_COUNT[int(m)-1] = MONTH_COUNT[int(m)-1] + 1
plt.bar(np.arange(12), MONTH_COUNT, color=getColors(12))
plt.xticks(np.arange(12), MONTH_LABEL, rotation=90, fontsize=PLOT_LABEL_FONT_SIZE)
plt.ylabel('Частота появления', fontsize=PLOT_LABEL_FONT_SIZE)
plt.yticks(fontsize=PLOT_LABEL_FONT_SIZE)
plt.title('Частота появления объектов по месяцам', fontsize=PLOT_LABEL_FONT_SIZE)
plt.show()

Ожидалось весеннее обострение, но предположение не подтвердилось. Кажется теплые летние ночи и период отпусков дают о себе знать сильнее.
Посмотрим какие формы объектов на небе видели и сколько раз.
shapes_type_count = pd.value_counts(df['shape'].values)
shapes_type_count_keys, shapes_count_values = dict_sort(dict(shapes_type_count))
OBJECT_COUNT = len(shapes_type_count_keys)
plt.title('Типы объектов', fontsize=PLOT_LABEL_FONT_SIZE)
bar = plt.bar(np.arange(OBJECT_COUNT), shapes_type_count_values, color=getColors(OBJECT_COUNT))
plt.xticks(np.arange(OBJECT_COUNT), shapes_type_count_keys, rotation=90, fontsize=PLOT_LABEL_FONT_SIZE)
plt.yticks(fontsize=PLOT_LABEL_FONT_SIZE)
plt.ylabel('Сколько раз видели', fontsize=PLOT_LABEL_FONT_SIZE)
plt.show()
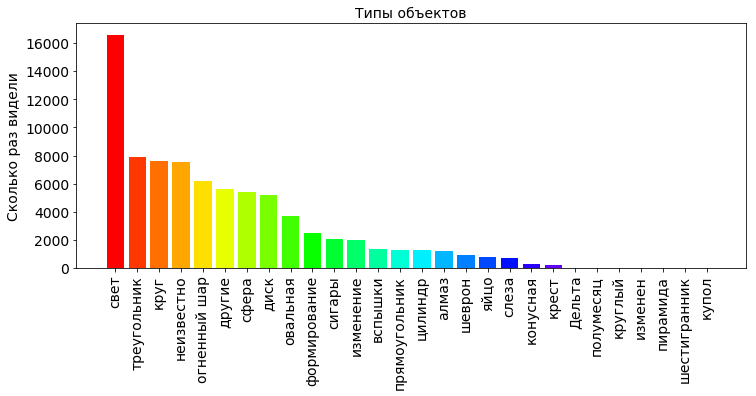
Из графика мы видим, что больше всего на небе видели просто свет, который в принципе необязательно является НЛО. Этому явлению существует внятное объяснение, например, ночное небо отражает свет от прожекторов, как в фильмах про Бэтмена. Также это вполне может быть северным сиянием, которое появляется не только в полярной зоне, но и в средних широтах, а изредка даже и в близи эвкватора. Вообще атмосфера земли пронизана множеством излучений различной природы, электрическими и магнитными полями.
Вообще, атмосфера Земли пронизана множеством излучений различной природы, электрическими и магнитными полями.
Подробнее см.: https://www.nkj.ru/archive/articles/19196/ (Наука и жизнь, Что светится на небе?)
Интересно еще посмотреть среднее время, на которое в небе появлялся каждый из объектов.
shapes_durations_dict = {}
for i in shapes_type_count_keys:
dfs = df[['duration (seconds)', 'shape']].loc[df['shape'] == i]
shapes_durations_dict[i] = dfs['duration (seconds)'].mean(axis=0)/60.0/60.0
shapes_durations_dict_keys = []
shapes_durations_dict_values = []
for k in shapes_type_count_keys:
shapes_durations_dict_keys.append(k)
shapes_durations_dict_values.append(shapes_durations_dict[k])
plt.title('Среднее время появление каждого объекта', fontsize=12)
plt.bar(np.arange(OBJECT_COUNT), shapes_durations_dict_values, color=getColors(OBJECT_COUNT))
plt.xticks(np.arange(OBJECT_COUNT), shapes_durations_dict_keys, rotation=90, fontsize=16)
plt.ylabel('Среднее время появления в часах', fontsize=12)
plt.show()
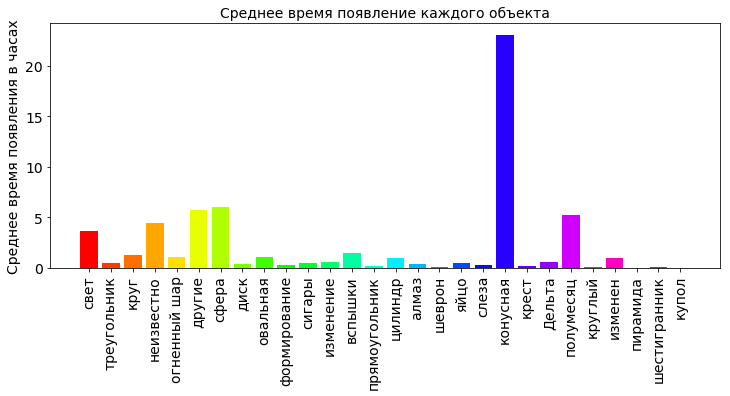
Из диаграммы видими, что больше всего в небе в среднем висел конус (более 20 часов). Если покопаться в интернетах, то ясно, что конусы в небе, это тоже свечение, только в виде конуса (неожиданно, да?). Вероятнее всего это свет от падающих комет. Среднее время больше 20 часов — это какая-то нереальная величина. В исследуемых данных большой разброс, и вполне могла вкраться ошибка. Несколько очень больших, неверных значений времени появления могут существенно исказить расчет среднего значения. Поэтому при больших отклонениях, считают не среднее значение, а медиану.
Медиана — это некоторое число, характеризующее выборку, одна половина в выборке меньше этого числа, другая больше. Для расчета медианы используем функцию median.
Заменим в коде выше:
shapes_durations_dict[i] = dfs['duration (seconds)'].mean(axis=0)/60.0/60.0
на:
shapes_durations_dict[i] = dfs['duration (seconds)'].median(axis=0)/60.0/60.0
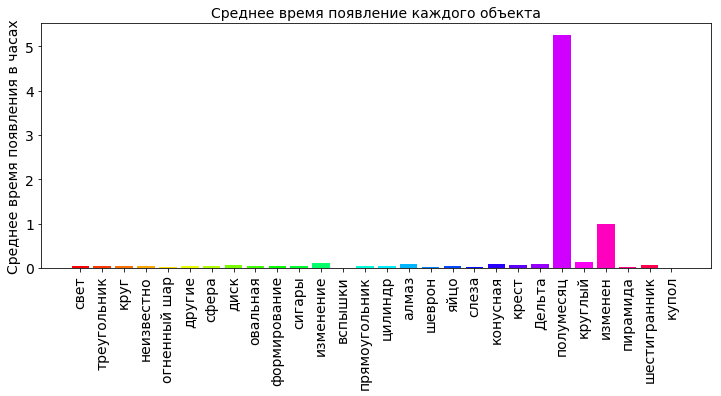
Полумесяц видели в небе чуть больше 5-ти часов. Другие объекты не надолго промелькнули в небе. Это уже наиболее достоверно.
Для первого знакомства с методологией обработки данных на Pyton, думаю, достаточно. В следующих публикациях займемся статистическим анализом, и постараемся выбрать другой не менее актуальный пример.
Полезные ссылки:
Библиотека для предварительной обработки данных
Библиотека алгоритмов машинного обучения
Комментариев нет:
Отправить комментарий