
Сегодня мы затрагиваем такую интересную тему, как естественные языки. Сейчас в эту область вкладываются очень большие деньги и в ней решают немало разнообразных задач. Она привлекает внимание не только индустрии, но и научного сообщества.
Может ли машина думать?
Исследователи связывают анализ естественных языков с принципиальным вопросом: может ли машина мыслить? Известный философ Рене Декарт давал однозначно отрицательный ответ. Неудивительно, учитывая уровень развития техники XVII века. Декарт полагал, что машина не умеет и никогда не научится думать. Машина никогда не сможет общаться с человеком с помощью естественной речи. Даже если мы объясним ей, как использовать и произносить слова, это всё равно будут заученные фразы, стандартные ответы — машина за их рамки не выйдет.
Тест Тьюринга
С тех пор прошло много лет, техника достаточно сильно изменилась, и в XX веке этот вопрос снова обрёл актуальность. Известный учёный Алан Тьюринг в 1950 году усомнился в том, что машина не может мыслить, и для проверки предложил свой знаменитый тест.
Идея теста, по легенде, основана на игре, которую практиковали на студенческих вечеринках. Два человека из компании — парень и девушка — уходили в разные комнаты, а оставшиеся люди общались с ними с помощью записок. Задача игроков заключалась в том, чтобы угадать, с кем же они имеют дело: с мужчиной или с женщиной. А парень с девушкой притворялись друг другом, чтобы ввести остальных игроков в заблуждение. Тьюринг сделал достаточно простую модификацию. Он заменил одного из скрытых игроков компьютером и предложил участникам распознать, с кем они взаимодействуют: с человеком или с машиной.
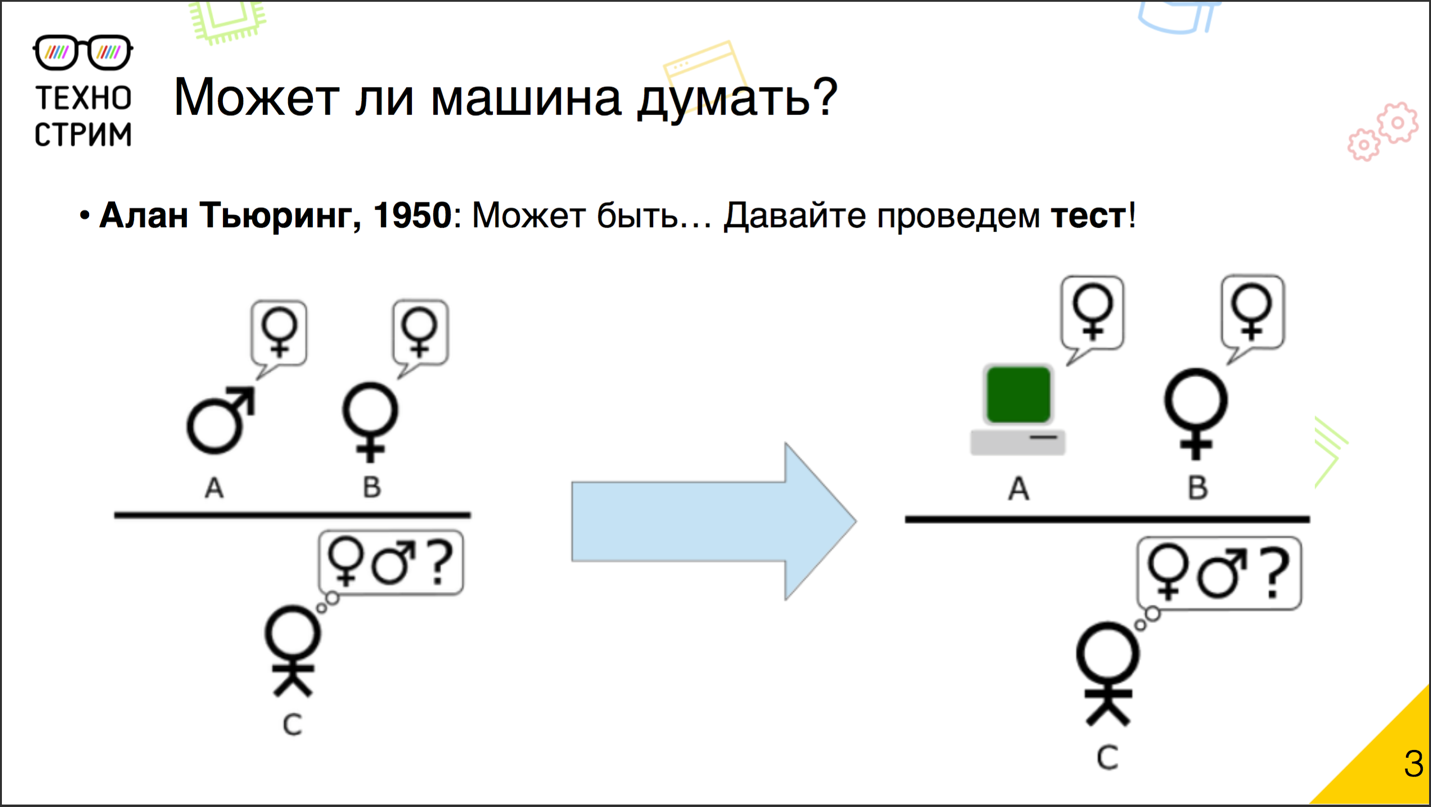
Тест Тьюринга был придуман уже больше полувека назад. Программисты не раз заявляли, что их детище прошло тест. Каждый раз возникали спорные требования и вопросы, действительно ли это так. Официальной достоверной версии, справился ли кто-то с основным тестом Тьюринга, нет. Некоторые из его вариаций на самом деле были успешно пройдены.
Джорджтаунский эксперимент
В 1954 году прошёл Джорджтаунский эксперимент. В его рамках демонстрировалась система, которая автоматически перевела 60 предложений с русского языка на французский. Организаторы были уверены, что всего за три года достигнут глобальной цели: полностью решат проблему машинного перевода. И с треском провалились. Через 12 лет программу закрыли. Никто и близко не смог подойти к решению этой задачи.
С современной позиции можно сказать: основная проблема состояла в малом количестве предложений. В таком варианте задачу решить почти невозможно. А если бы экспериментаторы проводили опыт на 60 тысячах или, может быть, даже на 6 миллионах предложений, тогда у них был бы шанс.
Первые чат-боты
В 1960-е годы появились первые чат-боты, очень примитивные: в основном они перефразировали то, что говорил им собеседник-человек. Современные чат-боты недалеко ушли от своих прародителей. Даже знаменитый чат-бот Женя Густман, который, как считается, прошёл одну из версий теста Тьюринга, сделал это не благодаря хитрым алгоритмам. Куда больше помогло актёрское мастерство: авторы хорошо продумали его личность.
Формальные онтологии, теория грамматик Хомского
Дальше наступила эпоха формальных методов. Это был глобальный тренд. Учёные пытались всё формализовать, построить формальную модель, онтологию, понятия, связи, общие правила синтаксического разбора и универсальную грамматику. Тогда возникла теория грамматик Хомского. Всё это выглядело очень красиво, но так и не дошло до адекватного практического применения, потому что требовало много кропотливой ручной работы. Поэтому в 1980-е годы внимание переключилось на систему другого класса: на алгоритмы машинного обучения и так называемую корпусную лингвистику.
Машинное обучение и корпусная лингвистика
В чём основная идея корпусной лингвистики? Мы собираем корпус — коллекцию документов, достаточно крупную, и затем с помощью методов машинного обучения и статистического анализа пытаемся построить систему, которая будет решать нашу задачу.
В 1990-е годы эта область получила очень мощный толчок благодаря развитию Всемирной паутины с большим количеством слабоструктурированного текста, по которому нужно было искать, его требовалось каталогизировать. В 2000-е анализ естественных языков начал применяться уже не только для поиска в Интернете, но и для решения разнообразных задач. Появились крупные датасеты с текстом, много разнообразных инструментов, компании стали вкладывать в это большие деньги.
Современные тренды
Что происходит сейчас? Основные тренды, которые можно выделить в анализе естественных языков, — это активное использование моделей обучения без учителя. Они позволяют выявить структуру текста, некоторого корпуса без заранее заданных правил. В открытом доступе появилось много больших доступных корпусов разного качества, размеченные и нет. Возникли модели, основанные на краудсорсинге: мы не только пытаемся что-то понять с помощью машины, а подключаем людей, которые за небольшую плату определяют, на каком языке написан текст. В некотором смысле начали возрождаться идеи использования формальных онтологий, но теперь онтологии крутятся вокруг краудсорсинговых баз знаний, в частности баз на основе Linked Open Data. Это целый набор баз знаний, его центр — машиночитаемый вариант «Википедии» DBpedia, который тоже наполняется по краудсорсинговой модели. Люди во всём мире могут туда что-то добавлять.
Лет шесть назад NLP (natural language processing, обработка естественных языков) в основном вбирала в себя техники и методы из других областей, но со временем она стала экспортировать их. Методы, которые развились в области анализа естественных языков, начали с успехом применяться и в других областях. И конечно, куда же без deep learning? Сейчас при анализе естественных языков тоже начинают применять глубокие нейросети, пока что с переменным успехом.
Что же такое NLP? Нельзя сказать, что NLP — это конкретная задача. NLP — это огромный спектр задач разного уровня. По уровню детализации, например, можно разбить их так.

На уровне сигнала нам нужно преобразовать входной сигнал. Это может быть речь, рукопись, печатный отсканированный текст. Требуется преобразовать его в запись, состоящую из символов, с которыми сможет работать машина.
Дальше идёт уровень слова. Наша задача — понять, что здесь вообще есть слово, провести его морфологический анализ, исправить ошибки, если они есть. Чуть выше — уровень словосочетаний. На нём появляются части речи, которые нужно уметь определять, возникает задача распознавать именованные сущности. В некоторых языках даже задача выделения слов нетривиальна. Например, в немецком языке между словами необязательно стоит пробел, и нам нужно уметь вычленить слова из длинной записи.
Из словосочетаний формируются предложения. Надо их выделить, иногда — провести синтаксический разбор, попробовать сформулировать ответ, если предложение вопросительное, устранить двусмысленность слов, если требуется.
Надо заметить, что эти задачи идут в две стороны: связанные с разбором и с генерацией. В частности, если мы нашли ответ на вопрос, нам нужно создать предложение, которое будет адекватно выглядеть с точки зрения человека, который его прочитает, и отвечать на вопрос.
Предложения группируются в абзацы, и здесь уже возникает вопрос разрешения ссылок и установления отношений между объектами, упомянутыми в разных предложениях.
С абзацами мы можем решать новые задачи: проанализировать эмоциональную окраску текста, определить, на каком языке он написан.
Абзацы формируют документ. На этом уровне работают самые интересные задачи. В частности, семантический анализ (о чём документ?), генерация автоматической аннотации и автоматического summary, перевод и создание документов. Все наверняка слышали об известном генераторе научных статей SCIgen, который создал статью «Корчеватель: Алгоритм типичной унификации точек доступа и избыточности». SCIgen регулярно подвергает испытаниям редакционные коллегии научных журналов.
Но есть задачи, связанные с корпусом в целом. В частности, дедублицировать огромный корпус документов, искать в нём информацию и т. д.
Пример задачи: кому показать пост на OK.RU?
Например, в нашем проекте OK.RU, более известном как «Одноклассники», есть задача ранжирования контента в ленте. Кто-то из ваших друзей или групп делает пост, причём таких постов, как правило, достаточно много, особенно если учесть записи, лайкнутые друзьями. Нам нужно выбрать из множества записей те, что больше всего вам подходят. Какие здесь сложности и возможности?
У нас есть крупный датасет, там уже больше 2 миллиардов постов, за день может появиться несколько миллионов новых. В записях встречается около 40 языков, в том числе достаточно слабо изученные: узбекский, таджикский. В документах очень много шума. Это не новостные и не научные статьи, их пишут простые люди — там есть ошибки, опечатки, сленг, спам, копипаста и дубликаты. Казалось бы, зачем вообще пытаться анализировать контент, если уже есть много методов на основе коллаборативной фильтрации? Но в случае с лентой такие рекомендации работают плохо: здесь постоянно возникает ситуация холодного старта. У нас появился новый объект. Мы ещё почти не знаем, кто и как с ним взаимодействовал, но уже должны решить, кому его показывать, а кому нет. Поэтому применим классический воркэраунд для задачи холодного старта и построим систему контентных рекомендаций: попробуем научить машину понимать, о чём написан пост.
Проблема издалека
Взглянув на проблему с высоты птичьего полёта, выделим основные блоки. Во-первых, корпус многоязыковой, поэтому для начала выясним язык документа. Пользовательский текст содержит опечатки. Соответственно, нужен какой-то корректор опечаток для приведения текста к канонической форме. Чтобы работать с документами дальше, нужно уметь их векторизовать. Поскольку в корпусе много дубликатов, не обойтись без дедубликации. Но самое интересное — мы хотим узнать, о чём этот пост. Соответственно, требуется метод семантического анализа. И мы хотим понять отношение автора к объекту и теме. Тут поможет анализ эмоциональной окраски.
Определение языка
Начнём по порядку. Определение языка. Здесь используются стандартные техники машинного обучения с учителем. Мы делаем некий размеченный корпус по языкам и тренируем классификатор. Как правило, простые статистические классификаторы работают достаточно хорошо. В качестве признаков для этих классификаторов обычно берут N-граммы, т. е. последовательности из N (допустим, трёх) подряд идущих символов. Строят гистограмму распределения последовательностей в документе и на её основании определяют язык. В более продвинутых моделях могут использовать N-граммы другой размерности, а из последних разработок отметим N-граммы переменной длины, или, как назвали их авторы, инфинитиграммы.
Поскольку задача довольно старая, есть немало готовых работающих инструментов. В частности, это Apache Tika, японская библиотека language-detection и одна из последних разработок — питоновский пакет Ldig, который как раз работает на инфинитиграммах.
Эти методы хороши для достаточно крупных текстов. Если есть абзац или хотя бы пятёрка предложений, язык определится с точностью более 99 %. Но если текст короткий, из одного предложения или нескольких слов, то классический подход, основанный на триграммах, очень часто ошибается. Исправить ситуацию могут инфинитиграммы, но это новая область, далеко не для всех языков уже есть обученные и готовые классификаторы.
Приведение к канонической форме
Мы определили язык текста. Нужно привести его к канонической форме. Зачем? Один из ключевых объектов при анализе текста — словарь, и сложность алгоритмов часто зависит от его размеров. Возьмём все слова, которые использовались в вашем корпусе. Скорее всего, это будут десятки, а то и сотни миллионов слов. Если мы посмотрим на них более пристально, то увидим, что на самом деле это не всегда отдельные слова, порой встречаются словоформы или слова, написанные с ошибками. Чтобы уменьшить размер словаря (и вычислительную сложность) и улучшить качество работы многих моделей, приведём слова к канонической форме.
Сначала исправим ошибки и опечатки. В этой области есть два подхода. Первый основан на так называемом фонетическом матчинге. Вот его основная идея. Почему человек ошибается? Потому что пишет слово так, как его слышит. Если мы возьмём верное слово и слово с ошибкой, а потом запишем, как оба слышатся и произносятся, то получим один и тот же вариант. Соответственно, ошибка уже не будет влиять на анализ.
Альтернативный подход — так называемое редакционное расстояние, с помощью которого мы ищем в словаре максимально похожие слова-аналоги. Редакционное расстояние определяет, сколько операций изменения нужно, чтобы кратчайшим образом превратить одно слово в другое. Чем меньше операций требуется, тем больше слова похожи.
Итак, мы исправили ошибки. Но всё равно в том же русском языке у слова может быть огромное количество корректных словоформ с разнообразными окончаниями, приставками, суффиксами. Это словарь достаточно сильно взрывает. Нужно привести слово к основной форме. И здесь есть две концепции.
Первая концепция — стемминг, мы пытаемся найти основу слова. Можно сказать, что это корень, хотя лингвисты могут поспорить. Здесь используется подход affix stripping. Основная идея в том, что мы отрезаем от слова по кусочку и с конца, и с начала. Удаляем окончания, приставки, суффиксы, и в итоге как раз остаётся основная часть. Есть известная реализация, так называемый стеммер Портера, или проект Snowball. Основная проблема подхода: правила для стеммера устанавливают лингвисты, и это достаточно тяжёлый труд. Перед подключением нового языка нужны лингвистические исследования.
Есть разновидности подхода. Мы можем или просто делать lookup по словарю, или строить supervised-модели без учителя, опять же — вероятностные модели на основе скрытых цепей Маркова, или обучать нейросети, которые приведут слова в редуцированную форму.
Стемминг используется достаточно давно. В Google — с начала 2000-х. Самый распространённый, наверное, инструмент — реализация в пакете Apache Lucene. Но у стемминга есть недостаток. Когда мы урезаем слово до основы, мы лишаемся части информации. Потому что у нас остаётся лишь корень, и мы можем потерять данные о том, было ли это прилагательное или существительное. И иногда это важно для постановки дальнейших задач.
Вторая концепция, альтернатива стемминга — лемматизация. Она пытается привести слово не к основе или корню, а к базовой, словарной форме — т. е. лемме. К примеру, глагол — к инфинитиву. Существует множество реализаций, и тема очень хорошо проработана именно для user generated текстов, пользовательски зашумлённых текстов. Однако приведение в каноническую форму по-прежнему остаётся сложной и до конца не решённой задачей.
Векторизация
Привели к канонической форме. Теперь отобразим это в векторном пространстве, потому что почти все математические модели работают в векторных пространствах больших размерностей. Базовый подход, который используют многие модели, — метод "мешка слов". Мы формируем для документа вектор в пространстве, размерность которого равна размеру нашего словаря. Для каждого слова выделена своя размерность, и для документа мы записываем признак, насколько часто это слово в нём использовалось. Получаем вектор. Есть много подходов к тому, как его выяснить. Доминирует так называемый TF-IDF. Частоту слова (term frequency, TF) определяют по-разному. Это может быть счётчик вхождения слова. Или флаг, видели мы слово либо нет. Или что-то чуть более хитрое, например логарифмически сглаженное количество упоминаний слова. И вот что самое интересное. Определив TF в документе, мы перемножаем её с обратной частотой документа (inverse document frequency, IDF). IDF обычно вычисляют как логарифм от числа документов в корпусе, разделённый на количество документов, где это слово представлено. Вот пример. У нас встретилось слово, которое употреблялось во всех-всех-всех документах корпуса. Очевидно, логарифм даст нам ноль. Такое слово мы никуда не добавим: оно не несёт никакой информации, оно есть во всех документах.
В чём преимущество подхода мешка слов? Его просто реализовать. Но он теряет часть информации, в том числе сведения о порядке слов. И сейчас продолжают ломать много копий на тему того, насколько важен порядок слов. У нас есть один известный пример — магистр Йода. Он расставляет слова в предложении хаотично. Речь Йоды необычна, но мы её свободно понимаем: т. е. человеческий мозг достаточно легко восстанавливает информацию даже при потерянном порядке.
Но иногда эта информация значима. Например, при анализе эмоциональной окраски очень важно, к чему относилось, условно говоря, слово «хороший» или «нет». Тогда наряду с мешком слов поможет мешок N-грамм: мы добавляем в словарь не только слова, но и словосочетания. Мы не будем вносить все словосочетания, потому что это приведёт к комбинаторному взрыву, но часто используемые статистически значимые пары или пары, соответствующие именованным сущностям, можно добавить, и это повысит качество работы итоговой модели.
Другой пример ситуации, когда «мешок слов» может терять или искажать информацию — слова синонимы или слова со несколькими различными смыслами (например, замок). Отчасти эти ситуации позволяют обработать методы построения "векторных представлений слов", например, знаменитый word2vec или более модные skip-gramm.
Дедубликация
Векторизовали. Теперь почистим корпус от дубликатов. Принцип понятен. У нас есть векторы в векторном пространстве, мы можем определить их близость, взять косинус, можем другие метрики близости, но обычно используют именно косинус. Объединим в общую группу документы, где косинус близок к единице.
Казалось бы, всё просто, понятно, но есть одно но: у нас 2 миллиарда документов. Если мы умножим 2 миллиарда на 2 миллиарда, то никогда не закончим считать косинусы. Нужна оптимизация, которая позволит быстро выбрать кандидатов для расчета косинуса, избавившись от полного перебора. И здесь поможет локально-чувствительный хеш. Стандартные хеш-функции равномерно размазывают данные по пространству хешей. Локально-чувствительный хеш похожие объекты поместит в пространстве объектов близко. С какой-то вероятностью он вообще может дать им один и тот же хеш.
Есть много техник подсчёта локально-чувствительного хеша под разные метрики похожести. Если речь идёт о косинусе, то часто используется метод случайных проекций. Мы выбираем случайный базис из случайных векторов. Считаем косинус нашего документа с одним из векторов базиса. Если он больше нуля, то ставим единичку. Меньше нуля или равен ему — ставим ноль. Дальше сравниваем со вторым вектором базиса, получаем ещё один нолик или единичку. Сколько у нас векторов в базисе — столько мы в итоге получаем битов, и это наш хеш.
В чём преимущество, почему это вообще работает? Если два документа близки по косинусу друг с другом, то с высокой вероятностью они окажутся по одну и ту же сторону от вектора базиса. Поэтому у похожих документов хеш с высокой вероятностью окажется один. Тем не менее выбросы будут. Чтобы их исправить, мы просто повторим процедуру. На практике мы обычно используем два прогона. На первом вычисляем 24-битный хеш и удаляем много почти идентичных документов. Дальше считаем ещё один хеш на другом базисе, но уже в 16 бит и довычищаем дубликаты. После этого копий не остаётся — либо же их настолько мало, что они не могут значимо отразиться на качестве работы моделей.
Семантический анализ
И потихоньку переходим к самому интересному. Как же нам понять, о чём документ? Задача семантического анализа достаточно старая. Олдскульный подход такой: делаем заранее описанную онтологию, строгий синтаксический разбор, мепим узлы синтаксического дерева к понятиям в нашей онтологии, делаем много рукописных правил — и т. д., в итоге получаем семантику. Всё это красиво теоретически, но на практике не действует: там, где рукописных правил множество, работать тяжело.
Современный подход — анализ семантики без учителя, поэтому его называют анализом скрытой (латентной) семантики. Этот метод (или даже семейство методов) хорошо работает на крупных корпусах — запускать поиск скрытой семантики имеет смысл только на большом корпусе. Там, как правило, относительно мало параметров, которые можно потюнить, в отличие от простыней с правилами в олдскульных подходах, и есть готовые инструменты: бери и пользуйся.
Латентно-семантический индекс
Исторически первый подход к латентно-семантическому анализу — это латентно-семантическое индексирование. Идея очень простая. Мы уже использовали для решения задач коллаборативных рекомендаций хорошо зарекомендовавшие себя техники факторизации матриц.
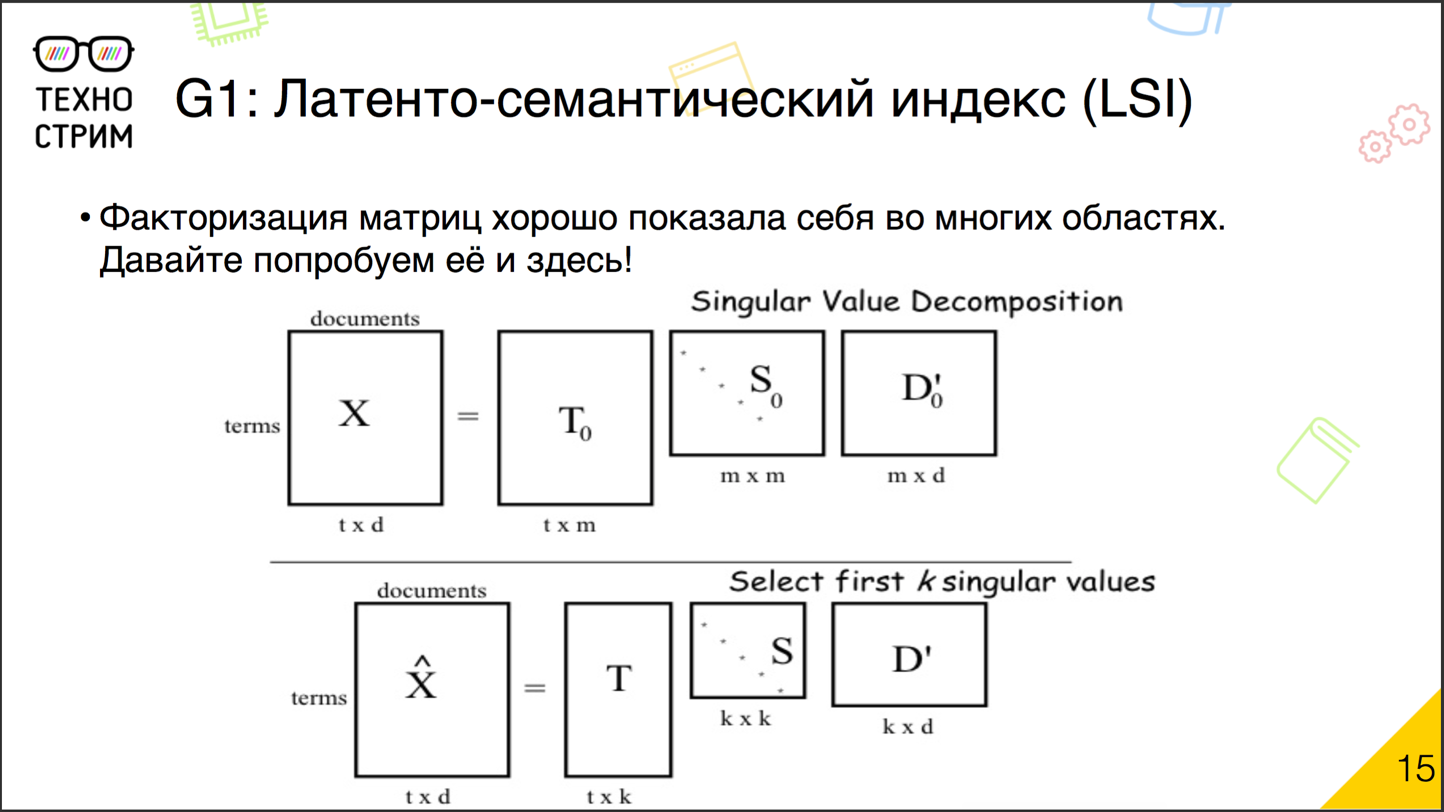
В чём суть факторизации? У нас есть большая матрица, в рекомендациях это user — item (насколько юзеру нравится айтем). Мы её разбиваем на произведения маленьких матриц. Теперь у нас получилась матрица факторов юзеров и факторов айтемов. Потом мы берём эти две матрицы (user — factor и factor — item) и перемножаем. Получаем новую матрицу user — item. Она, если мы правильно провели факторизацию, максимально точно соответствует матрице, которую мы изначально раскладывали. То же самое можно сделать и с документами. Берём матрицу «документ — слово» или «слово — документ» и раскладываем на произведение двух матриц: «документ — фактор» и «фактор — слово». Всё просто, есть готовые инструменты. При таком подходе мы автоматически учитываем слова с разнообразными смыслами, синонимы. Если в корпусе много опечаток, мы всё равно поймём, что неправильно написанное слово относится к такому-то скрытому фактору. Минимум параметров, готовые инструменты. Уже с начала 1990-х этими техниками пользовались. Есть только одно но: полученная семантика слишком скрытая. По векторам факторов документов и факторов слов очень сложно что-нибудь сказать о корпусе. Если в задачах коллаборативных рекомендаций эта проблема не настолько важна, то при анализе естественных языков во многих задачах дело обстоит иначе. Математическая модель, которую мы не в силах интерпретировать, не даёт нам новых знаний. Поэтому начали искать альтернативы.
Вероятностный латентно-семантический индекс
Одной из альтернатив стал так называемый вероятностный латентно-семантический индекс. В основе техники лежала очень простая идея.
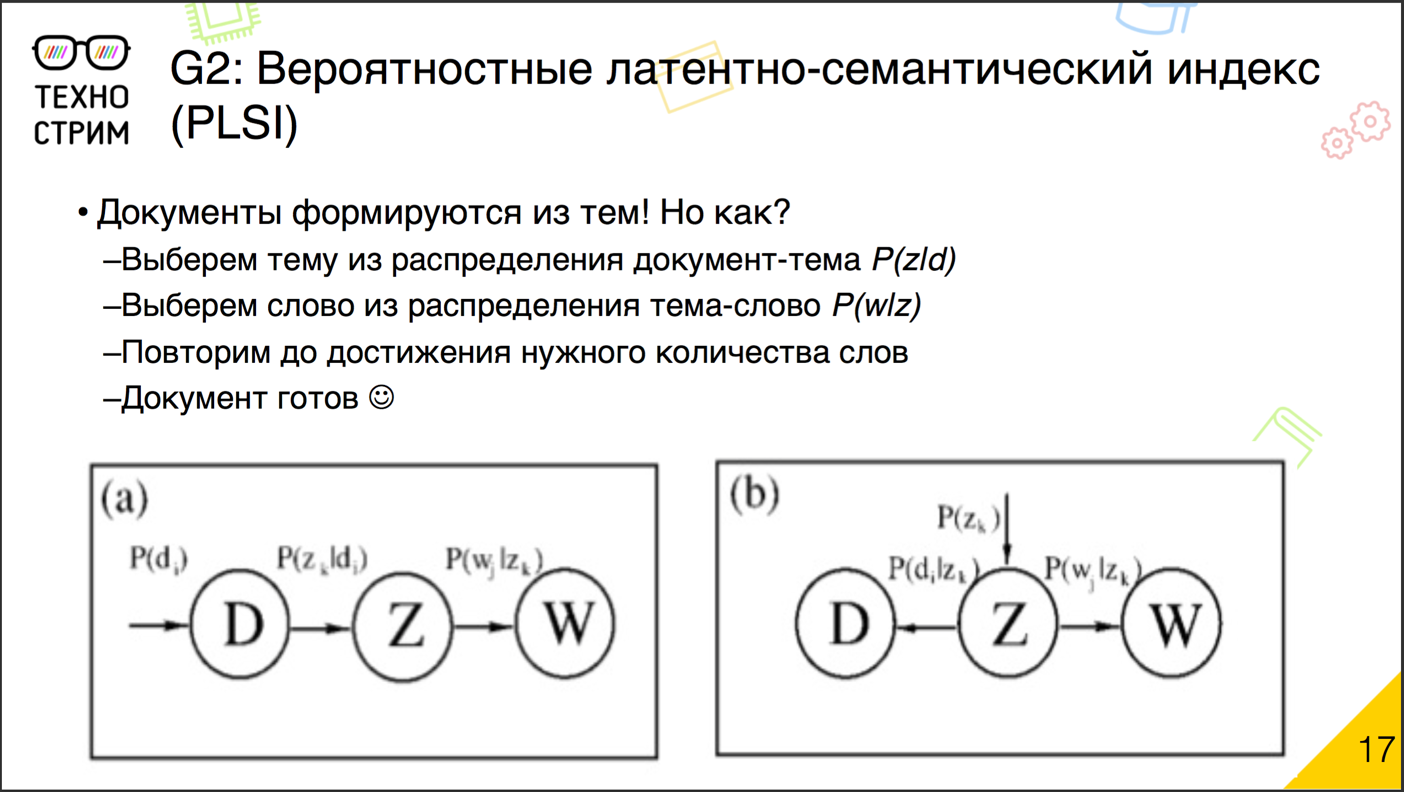
У нас есть документы. Предположим, что они созданы не просто так, а на основе тем, которые мы ещё не знаем. Попробуем симулировать, как эти документы могли бы быть написаны. У нас есть корпус. Мы выбираем случайный документ, дальше из распределения его тем случайно выбираем тему. Дальше из распределения слов по теме выбираем слово. И вот мы получили одно слово в документе. Потом повторяем (выбрали документ, выбрали тему, сгенерировали слово), пока не сгенерируем все слова в корпусе, во всех документах корпуса.
Чтобы всё функционировало, нужно всего лишь правильно работающее распределение: тем по документу и слов по теме.
Что это, почему оно работает? Важно понять, что техника вероятностного латентно-семантического индекса — это техника факторизации матрицы. От большой матрицы «документ — слово» мы переходим к двум меньшим: «документ — тема» и «тема — слово». После перемножения они генерируют наш корпус, вернее вероятности того, что в корпус что-то попадёт. По сравнению с классической факторизацией на основе сингулярного разложения у вероятностной генерирующей модели есть важное преимущество. Скрытые факторы темы стали интерпретируемыми. Теперь у них есть понятный физический смысл, теперь это часть генерирующего документ процесса, и понять, что за темой стоит, мы, как правило, можем относительно легко: посмотрев, какие слова она генерирует.
Важное отличие техники генерирующей модели — она должна работать уже на голых TF-матрицах. Если натравить её на TF-IDF матрицу, то результат факторизации может быть бессмысленным.
Как мы оценим, насколько модель хороша? Мы получили две матрицы. В стандартной факторизации мы оценивали среднее квадратичное отклонение. Здесь у нас вероятностная модель, и мы пытаемся понять, насколько вероятно, что наблюдаемый нами реально корпус мог быть получен в той модели, которую мы построили. Для этого используется перплексия.

Вдаваться в метрику не будем. Лучше обратим внимание на нижнюю строку: как мы определяем, какова вероятность увидеть конкретное слово в конкретном документе. По сути, это как раз и есть сумма по всем темам произведения вероятности. Выбрать тему для документа и выбрать слово для темы. Вот эти две матрицы нам и нужно подобрать. Распределение «тема — документ» и распределение «слово — тема». Как мы это сделаем? Конечно же, итеративно.
Есть так называемый EM-алгоритм. Он итеративно строит модель, которая оптимизирует перплексию, т. е. увеличивает вероятность того, что наш корпус будет построен нашей моделью. В его основе лежит число γijk: вероятность того, что данное слово в данном документе сгенерировано данной темой.

И мы итеративно обновляем счётчики. Это счётчик представленности слова в теме, так называемый Nik, по сути сумма по всем документам γijk, умноженная на представленность слова в документе — Nij. Это представленность темы в документе Njk, которая считается как сумма по всем словам документов, представленность γijk, умноженная на представленность слова в документе. И это мощность темы Nk — сумма по всем словам представленности слова в этой теме. То есть у нас есть вариант, который мы случайно инициализируем. Затем мы на основе ijk строим, считаем счётчики Nik, Njk и Nk и на основе счётчиков обновляем γijk. То есть мы умножаем представленность слова в теме на представленность темы в документе — и делим на общую силу темы. Получаем некоторую новую γijk, все γijk мы нормируем по документу по темам, чтобы в сумме они давали единицу, чтобы это было распределение вероятностей. Получаем новое значение γijk. Можем запускать новую итерацию. С новыми γijk мы посчитали новые счётчики, с новыми счётчиками — новые γijk, и т. д., пока результат нас не удовлетворит.
На что стоит обратить внимание? Во-первых, здесь мы видим только суммы. Суммы — это очень хорошо: они легко параллелятся. И этот процесс можно запускать распределённо. Более того, если приглядеться к формулам и логике расчёта, видно, что на самом деле нет необходимости целиком материализовывать трёхмерную матрицу γijk. Процесс можно организовать так, что мы последовательно проходим документы, для каждого документа вычисляем его обновлённые γijk, обновляем счётчики с учётом вклада этого документа. И всё. Дальше γijk не нужны. Нам нужно сагрегировать все наши счётчики по документам и потом пересчитать обновления. То есть процесс очень хорошо распределяется и параллелится.
Что мы получаем на выходе? Как раз счётчики «представленность слова в теме», «представленность темы в документе» и «общая сила темы». Искомые матрицы вероятностей распределения тем в документе и распределения слов в теме мы находим с помощью простого деления. Как узнать вероятность увидеть тему в документе? Разделить силу темы в документе на количество слов в документе. Как вычислить вероятность сгенерировать слово в теме? Разделить силу слова в теме на силу темы. Нетрудно заметить, что всё это вероятности, что все эти распределения в сумме будут давать единичку.
Латентное размещение Дирихле
Вычислить легко, формулы простые, хорошо распределяются. О чём ещё мечтать? Слишком скучно. Хочется немножко разнообразия. И математики предложили: а давайте мы не просто будем подбирать распределения «документ — тема» и «тема — слово», а предположим, что они должны походить на распределение Дирихле.

Зачем и почему Дирихле? У исходной модели вероятностного семантического индекса есть серьёзный недостаток. Если в неё попадает неизвестное слово (которое мы ни разу не наблюдали в корпусе, когда тренировали модель), то по своим формулам мы получаем деление на ноль. То есть такого слова вообще не могло быть. То есть мы вообще не можем с помощью модели получить документ, который наблюдаем. Перплексия уходит в бесконечность, и всё разваливается.
Математиков такие ситуации сильно напрягают, поэтому они решили добавить регуляризатор. Априорные распределения Дирихле в данном случае играют роль регуляризирующего параметра.

Латентное размещение Дирихле (Latent Dirichlet Allocation, LDA) сейчас — одна из самых распространённых моделей. Лингвисты против неё возражают, потому что с лингвистической точки зрения нет видимых причин, почему распределения должны быть близкими к распределению Дирихле.
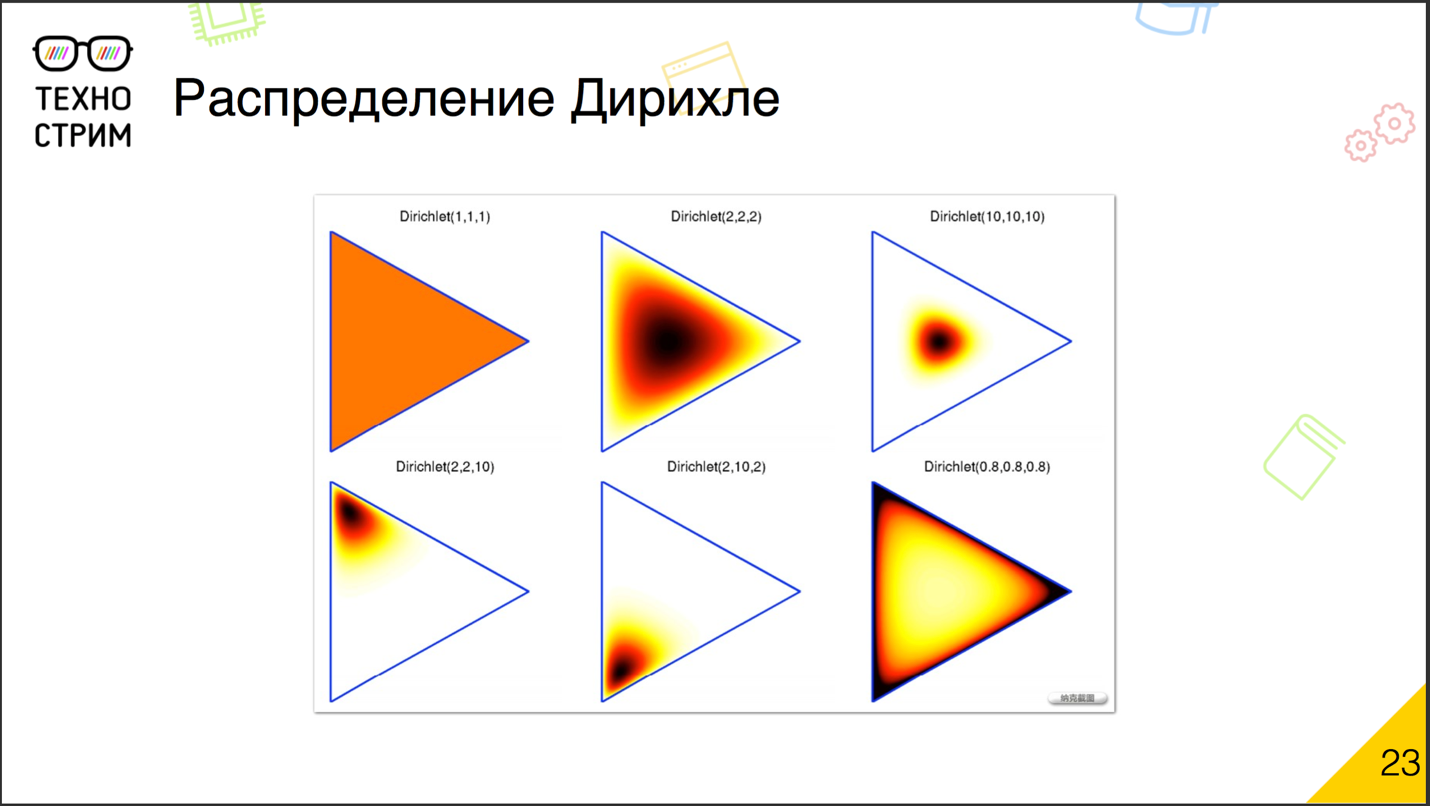
Что такое распределение Дирихле? Выглядит оно примерно так: многомерное распределение с гиперпараметром в виде вектора. В чём идея? Если мы задаём гиперпараметр выше единицы, то получаем скученность значений к центру. Если же он меньше единицы, то значения, наоборот, разъезжаются ближе к границам и узлам распределения. Интуитивно ситуация, когда гиперпараметры меньше единицы, на самом деле близка к реальности, потому что тем в каждом документе должно быть немного. Если мы для каждого документа предскажем равномерную вероятность по всем темам — наверное, получится не очень хорошая модель. А если мы построим модель так, чтобы для каждого документа она предсказывала одну-две наиболее вероятные темы, а остальные были практически в нуле, это уже интересно. Поэтому, как правило, используют априорное распределение Дирихле с небольшими значениями гиперпараметра: сильно меньше единицы и чуть-чуть выше нуля.
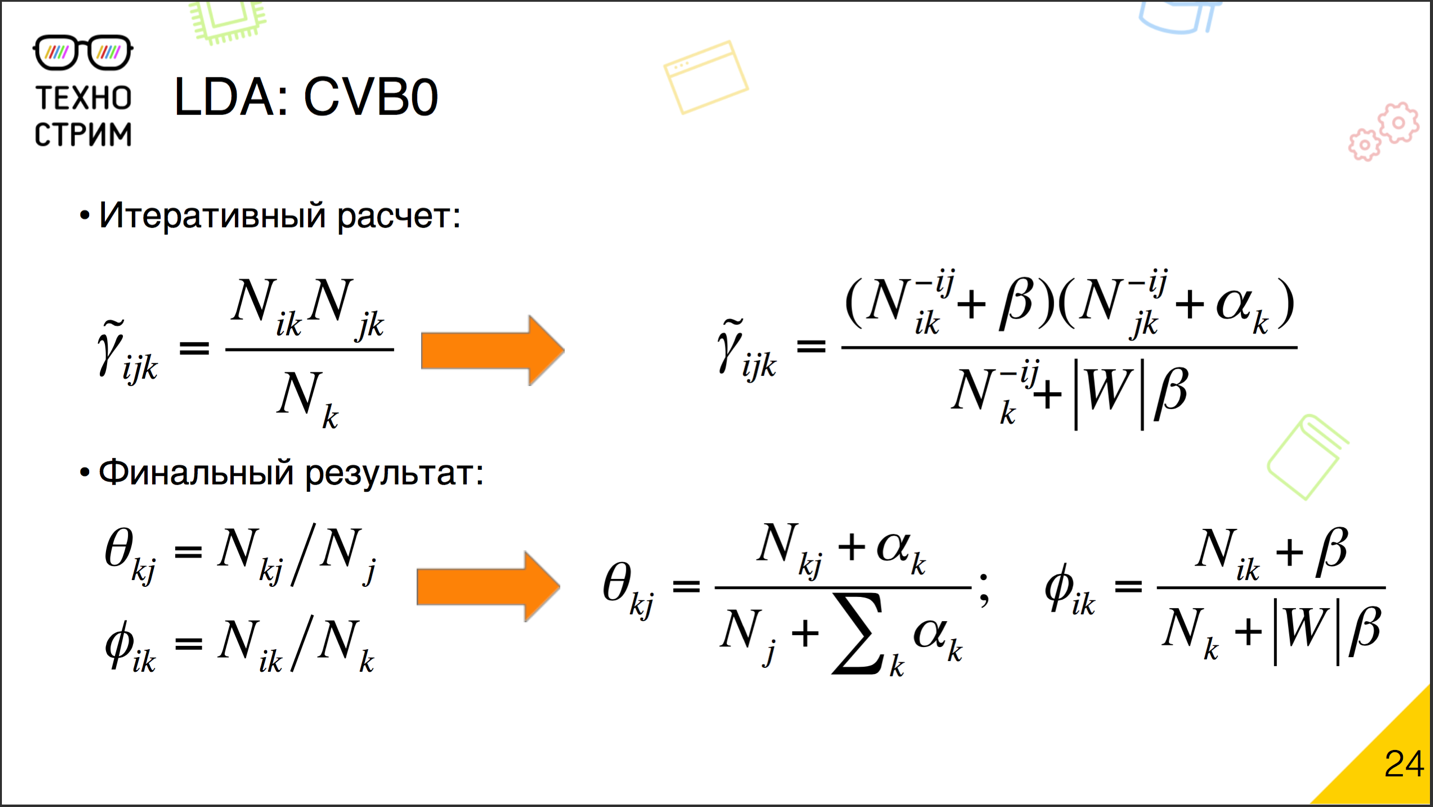
Как это отражается на расчёте? Очень просто. Есть известный алгоритм подбора параметров как раз для матриц вероятностей с учётом априорных распределений Дирихле, и разница в небольшой приписке. Если изначально γijk мы обновляли просто как силу слова в теме умножить на силу темы в документе и разделить на силу темы, то теперь мы добавим приписки. К силе слова в теме добавим β, к силе темы в документе — α, исключим из рассмотрения вес, который привносит само по себе слово, и откорректируем нашу нормировку. Что хорошо? Благодаря небольшим припискам в виде α и β
мы уже никогда не получим ноль: число всегда будет хоть чуть-чуть, но выше нуля. Соответственно, есть вероятность сгенерировать любое слово, даже если мы его раньше не видели. Деление на ноль пропадает, математики счастливы.
Финальный результат строится по похожим формулам. К силе темы в документе добавляем α и корректируем нашу нормировку на сумму всех α, к вероятности слова в теме добавляем β и корректируем нормировку, добавляя β, помноженную на размер словаря.
Отметим, что β, как правило, берут в виде скалярного параметра; хотя на самом деле это гиперпараметр размерности, равный размеру словаря, но мы просто устанавливаем константный вектор, где все элементы равны β. А α часто пытаются подбирать. α — это тоже гиперпараметр, его размерность — количество тем в корпусе, и мы можем его изменять. Для некоторых тем α можно поднять. Для специфических тем, так называемых domain specific themes, α опустим, чтобы они были реже представлены.
В организации расчётов не меняется ничего. У нас есть те же самые суммы и то же самое распределение и распараллеливание. Просто к суммам мы добавляем небольшие приписки. Всё замечательно, просто считается, быстро работает. Деления на ноль нет, распределение получается куда более интересным.
Слишком просто. Хочется ещё что-то добавить.
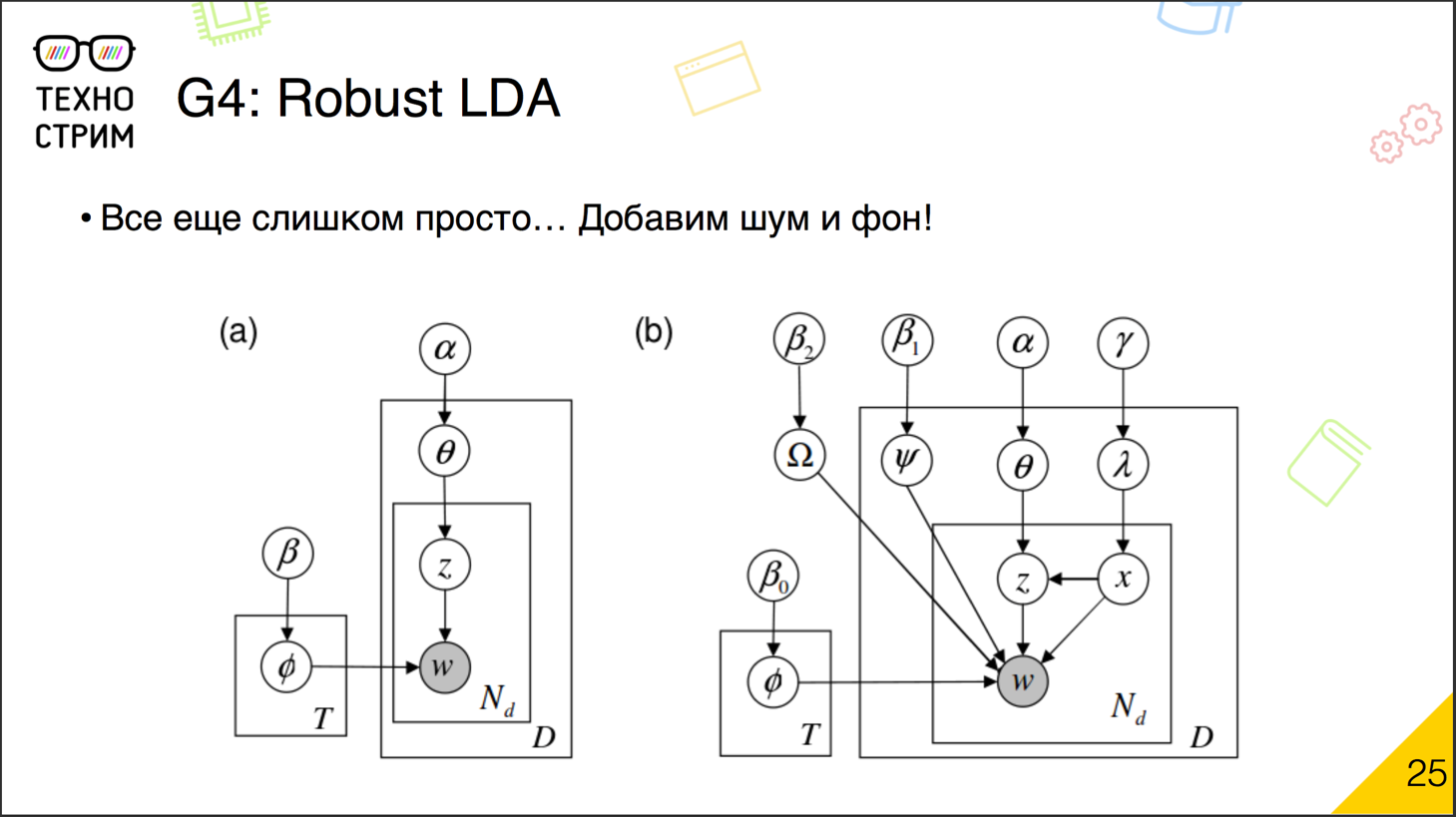
Давайте добавим ещё две вещи: шумовую компоненту и фоновую компоненту.
Вернёмся к генерации документов. Изначально у нас были документы, в документах — темы, вероятностное распределение темы могли привнести слова. На самом деле далеко не все слова в документе обязательно привносятся темами, этой семантической частью. Ведь есть общие слова, слова-паразиты, они часто употребляются в корпусе и не относятся ни к какой теме. А могут встречаться индивидуальные особенности: слова, которые используются именно в этом документе в специфическом значении.
Итак, слово приходит к нам не только обычным путём — через генерацию, через темы. Теперь его может сгенерировать фон или шум. Фон — это общий параметр, связанный с корпусом в целом. Шум — это вероятностное распределение, связанное именно с нашим документом.
Зачем такие сложности? Здесь есть пример, как это работает. Посмотрите на английский текст. Слова, которые пришли как фон, мы выделили серым цветом, как шум — голубым маркером.

И здесь мы видим, что в нижней части речь идёт о некоем John Snow. Snow — это снег, но в данном документе Snow — фамилия. Поэтому мы пытаемся описать snow не тематической моделью. Текст не о зиме, не о лыжах, не о снежных бабах, а о бизнесмене, который занимается транспортом. Поэтому snow у нас уходит в шумовую компоненту.
В верхнем тексте журналисты экспериментируют с формами написания фамилии бизнесмена, и все хитрые формы уходят в шум и позволяют не терять основную тему. Видно, что слова, которые остались чёрными, гораздо лучше относятся именно к теме документа.
Что это значит? Мы добавили шум — и теперь можем описать слова, которые не видели раньше, без α и β. Если в документе встречается такое слово, то мы не просто говорим, что вероятность его увидеть — ноль, а пытаемся объяснить слово шумовой компонентой и получаем ненулевую вероятность. После добавления шума и фона мы можем эту регуляризацию, априорное требование по распределению Дирихле либо отключить, либо сильно занизить. Шум и фон позволят обыграть всё это не хуже.

Как это считать? На самом деле всё почти то же самое. Тот же процесс, распределение и распараллеливание, те же суммы. Раньше мы крутились вокруг γijk, которые описывали вероятность увидеть слово на основе темы документа, его семантики. Теперь γijk уходят в семантический компонент Z, но появляются фоновая и шумовая компоненты со своим весом. Теперь вероятность увидеть слово в документе объясняется не только темой, но и шумом с фоном. Причём, что интересно, если мы вес шума и фона зададим как ноль, то они автоматически пропадут из формулы и не будут ни на что влиять.
То, что у нас появились две новые компоненты, нужно учесть при всех нормировках. А сами компоненты мы обновляем также итеративно в том же самом процессе — на основании счётчиков γij в данном случае. И то же самое: обновили γij, пересчитали новые веса в компоненте фона и шума. Пробежались снова по корпусу, получили новые γij на основе новых компонент, обновили компоненты. Пробежались, обновили, пробежались, обновили, пробежались, обновили — пока не сойдёмся.
Получение финального результата наших матриц «документ — тема» и «тема — слово» не меняется, формулы остаются такими же.
Что важно отметить? Здесь чётко прослеживается преемственность. Если мы задаём шум и фон как ноль, они исчезают из формулы, мы получаем обычное LDA. Если мы задаём как ноль α и β, они все исчезают из формул, мы получаем обратно PLSA. Можем α и β убрать, оставить шум и фон — тогда получаем робастную PLSA-модель. То есть на самом деле мы видим вариации одного и того же метода.
И это далеко не всё. Но прежде чем рассуждать об альтернативах, посмотрим несколько примеров. Вот наш корпус. Мы пытались найти в нём тысячу тем, используя классический LDA-подход. Взяли десять первых тем.

Мы, конечно, можем интерпретировать некоторые темы, но часть из них выглядит достаточно странно. Попробуем добавить шумовую и фоновую компоненты. Результат меняется разительно.

Все первые десять тем хорошо интерпретируемы. Кладбище, поиск работы, зеркала и травма от режущих предметов, рекламное объявление, цвета, анекдоты про Вовочку, новости, телефонные звонки, Масленица и зомби. Почему в корпусе так много тем о зомби? У нас на портале популярны зомби-игры, поэтому достаточно много идёт оттуда.
Часто спрашивают, насколько много тем нужно. Вот пример — та же робастная последовательность, но не для 1000, а для 250 тем. Чуть-чуть похуже, но всё ещё более-менее интерпретируемо.

Китайская история, вязание на спицах, заработок в Интернете, что-то непонятное и нехорошее, что-то понятное и приятное, дни недели, адреса, инструкция по нажатию на кнопки… И в конце опять — ужас, крик, зомби и т. д. Видно, что вся математика на самом деле работает. Темы интерпретируемы. И, глядя на распределение тем по документам, мы можем делать вполне разумные выводы о том, к какой теме относится документ.
И это ещё не всё?
Естественно. Есть много вариантов развития. В частности, сейчас в России двигается тема «Аддитивные регуляризаторы». В формулы, по которым мы считаем в рамках итеративного апдейта, мы добавляем новые приписки, и каждая из них моделирует процессы. Какая-то убирает часть топиков, чей вес стал слишком мал. Какая-то размывает бэкграунд-топики или, наоборот, сплющивает домейн-топики.
Есть подходы, направленные не только на добавление регуляризаторов, но и на усложнение генерирующей модели. Например, добавим новые сущности, теги, авторов, читателей документа, у них могут быть свои тематические распределения, и мы попытаемся построить общее по ним.
Есть попытки скрестить эту unsupervised-технику LDA с размеченными корпусами, когда у нас в качестве априорного распределения, которое мы хотим сохранить, выбирается не абстрактное распределение Дирихле, а распределение тем на размеченном корпусе.
Что интересно, все эти вероятности генерирующей модели — это, по сути, техники факторизации матриц. Но, в отличие от факторизации в лоб по сингулярному разложению, эти техники поддерживают некоторую форму интерпретации. И поэтому LDA начали использовать в других областях: факторизуют матрицы изображений, строят на них коллаборативные рекомендации. В области анализа социальных сетей и графов есть тема stochastic block modeling. Насколько я понимаю, она развивалась более-менее независимо, но, по сути, она тоже о факторизации матриц через вероятностную генерирующую модель. То есть LDA и всё, что от него пляшет, — это то, что экспортируется из анализа естественных языков в другие области.
Немножко о технологиях, чтобы разгрузиться от цифр. Процесс простой, но, чтобы построить тематическую модель на большом корпусе, требуется время. А времени у нас нет. Нужно понять тему документа, который появился прямо сейчас.

Мы используем такой подход: тематическую модель готовим заранее. В основе модели лежит матрица «топик — слово». С готовой закешированной матрицей «топик — слово» мы можем подогнать распределение «документ — топик» для конкретного поста, когда его увидим. Есть регулярно обновляемая общая тематическая модель, которая обсчитывается стандартным map reduce, и есть непрерывный поток новых постов. Мы обрабатываем их с помощью инструментов потокового анализа и определяем их тему на лету — на основе заранее подготовленной матрицы «топик — слово». Это типичная схема. Все алгоритмы машинного обучения в продакшене обычно так и работают: сложная часть — подготовка офлайн, более простая часть — онлайн.
Мы ещё не поговорили об анализе эмоциональной окраски. Хорошо: мы поняли, о чём текст, определили вероятностное распределение тем. Но как понять, положительно или отрицательно относится к теме автор?
Как правило, здесь пока доминируют методы, основанные на работе с учителем. Нужен размеченный корпус текстов с положительными и отрицательными эмоциями, и на нём мы обучаем классификатор. Подход на основе мешка слов нередко приводит к неудачным результатам. Эмоции порой выражаются одними и теми же словами, важен именно контекст. Поэтому вместо мешка слов часто используют мешки N-грамм. По стандартным словам или частицам (например, по «не») пытаются понять, что это. Изучая слово, рассматривают флажок, была ли перед ним частица «не» и на каком расстоянии. Кроме того, обращают внимание на дополнительные признаки того, что человек предположительно нервничал, или злился, или радовался, когда писал текст. Много восклицательных знаков, капса, непечатных символов внутри слов (потенциально это экранирование нецензурной брани) и т. д. И на всём этом тренируют классификатор.
Иногда получается неплохо, особенно если классификатор надо тренировать под конкретную предметную область. Если у нас есть корпус рецензий на фильмы, то вполне реально натренировать на нём классификатор по эмоциям. Проблема в том, что этот классификатор, скорее всего, уже не станет работать на отзывах к ресторанам. Там будут другие слова, которые часто выражают отношение к ресторану. Пока удачные решения анализа эмоциональной окраски в основном ориентированы конкретно.
Достаточно важен размер текста, потому что эмоции часто меняются. У нас может быть абзац или несколько предложений с одним эмоциональным месседжем, а другие — с иным. Например, в отзывах мы иногда пишем, что понравилось, а что нет. Поэтому стоит разделять документ на такие области.
В итоге лучше всего определяются эмоции для средних текстов. Слишком маленькие — есть риск, что не хватит информации, а слишком длинные — результат бывает чересчур размытым.
У достаточно популярной библиотеки SentiStrength есть веб-сервис, где можно повбивать предложения и тексты и поопределять, какая эмоция в них содержится. Но надо сказать, что здесь задача классификации небинарная: как правило, эти методы говорят не просто «положительный» или «отрицательный», а «положительный с такой-то силой». Пожалуй, это одна из наименее решённых задач в этом стеке, и здесь ещё многое можно развивать.
Под конец ещё немного пробегусь по задачам, которые пока не решены.
Для начала это приведение пользовательских текстов к канонической форме. Мы можем исправить опечатки и стеммировать. Когда пытаемся это всё совмещать — часто получается плохо. Для коротких текстов нужен подход, связанный с инфинитиграммами: у него ещё нет нормальных промышленных реализаций, и непонятно, заработает ли он. Тематическое моделирование для коротких текстов тоже затруднено. Чем меньше слов, тем сложнее нам понять, какой же там смысл.
Ещё одна задача, о которой я пока не говорил. Хорошо, мы поняли, к какой теме относится документ. Но ещё у нас есть пользователь. Цель: попробовать построить его семантический профиль. Соединить семантику с эмоциями. Мало понять, что здесь есть такие-то темы и эмоции. Нужно выяснить, какая тема какие чувства вызвала.
Любопытно исследовать тематические модели во времени: как они трансформируются, как возникают новые темы и меняется словарь существующих. Дедубликация хорошо работает на текстах, которые содержат копии, но может забуксовать на текстах, где эти копии намеренно искажены: я говорю об антиспаме. То есть это огромная область, где есть много разных решений, но ещё больше нерешённых задач. Так что, если кому-то интересны machine learning и работа с реальными практическими задачами, — welcome.
Заключение
В последнее время в области анализа текстов большое внимание уделяется внедрению методов на основе искусственных нейронных сетей. Ошеломляющего успеха, как в области анализа изображений, добиться не удалось, в первую очередь — из-за низкой интерпретируемости моделей, что для текстов гораздо важнее. Но всё же успехи есть. Рассмотрим несколько популярных подходов.
«Векторы смыслов». В работе исследователей Google 2013 года предлагалось с помощью двухслойной нейросети предсказывать слова по контексту (позднее появился и обратный вариант: предсказание контекста по слову). При этом основным результатом был не сам прогноз, а полученные для слов векторные представления. По утверждению авторов, они содержали информацию о смысле слова. В векторных представлениях можно было найти интересные примеры «алгебраических операций» над словами. Например, «король – мужчина + женщина ≈ королева». Кроме того, векторизованные слова стали удобной формой передачи данных о тексте другим алгоритмам машинного обучения, что во многом обеспечило популярность модели word2vec.
Одно из важных ограничений подхода с векторами смыслов слов состоит в том, что смысл определялся для слова, но не документа. Для коротких текстов адекватный «агрегированный» смысл часто можно было получить усреднением векторов входящих в текст слов, однако для длинных текстов этот подход уже оказывался неэффективен. Для обхода ограничения предлагались разные модификации (sentence2vec, paragraph2vec, doc2vec), однако они не распространились так, как базовая модель.
Рекуррентные нейронные сети. Многие «классические» методы работы с текстами основываются на подходе мешка слов. Он приводит к потере информации о порядке слов в предложении. Во многих задачах это не так критично (например, в семантическом анализе), но в некоторых, наоборот, существенно ухудшает результат (например, в анализе эмоциональной окраски и машинном переводе). Подходы на основе рекуррентных нейронных сетей (РНС) позволяют обойти это ограничение. РНС может учесть порядок слов, рассматривая информацию и о текущем слове, и о выходе этой же сети с предыдущего слова (а иногда и в обратную сторону — от последующего).
Одной из наиболее успешных РНС-архитектур стала архитектура на базе блоков LSTM (Long Short Term Memory). Подобные блоки способны запомнить единицу информации на «длительное» время, а затем, при поступлении нового сигнала, выдать ответ с учётом запомненной информации. Подход постепенно модифицировался, и в 2014-м была предложена модель GRU (Gated Recurrent Units), которая при меньшем количестве параметров позволяет во многих случаях добиться того же (а иногда и большего) качества работы.
Рассмотрение текста как последовательности слов, каждое из которых представлено вектором (как правило, word2vec-вектором), оказалось очень удачным решением для задач классификации коротких текстов, машинного перевода (подход sequence-to-sequence), разработки чат-ботов. Однако на длинных текстах часто не хватает памяти рекуррентных блоков, и «вывод» нейросети нередко обуславливается в первую очередь концовкой текста.
Сети-генераторы. Как и в случае с изображениями, нейронные сети используют для генерации новых текстов. Пока результаты работы таких сетей — по большей части «фан», но они развиваются с каждым годом. Прогресс в этой области можно отследить, например, посмотрев на систему Яндекс.Автопоэт (разработка 2013 года), послушав альбом групп «Нейронная оборона» (2016 год) или «Neurona» (2017-й).
Сети на базе N-грамм и символов. Построение входа нейронной сети на базе слов сопряжено с рядом сложностей — слов может быть много, в них порой содержатся ошибки и опечатки. Векторные представления слов в итоге бывают зашумлены. В связи с этим в последнее время всё большую популярность набирают подходы с символами и/или N-граммами (последовательностями из нескольких, как правило, трёх символов).
Например, рекуррентные сети на базе символов (Char-RNN) довольно успешно справляются с генерированием и слов (например, имён), и предложений. При этом на достаточно большом объёме данных можно добиться того, что сеть не только «выучит» слова и части речи, но и «запомнит» базовые правила склонения и спряжения.
Для коротких текстов неплохих результатов во многих задачах можно добиться с помощью подхода «мешок триграмм». В этом случае документу сопоставляется разрежённый вектор размерности 20—40 тысяч (каждой возможной триграмме выделяется своя позиция), который далее многослойно обрабатывается плотной сетью, как правило, с постепенным снижением размерности. В таком представлении система может обеспечить устойчивость ко многим типам ошибок и опечаток и успешно решать задачи классификации и поиска соответствия (например, в вопросно-ответных системах).
Сети на уровне работы с сигналами. Нельзя не отметить исключительную роль нейросетей при разборе сырого сигнала. Речь в современных системах, как правило, распознаётся с использованием рекуррентных сетей. В анализе рукописного текста для распознавания отдельных символов успешно применяются свёрточные сети, а для сегментации символов в потоке — рекуррентные сети.
Вопросы и ответы
Вопрос: Есть ли инструмент Ldig для русского языка?
Ответ: По-моему, русского нет. Это питоновский пакет, там очень ограниченная подборка. Его разрабатывали в Cybozu Labs. Авторы переключились на тематические модели и сказали: «Всё, языки нам больше не интересны». Поэтому Ldig сейчас никто не развивает. Какие-то шаги мы пытаемся делать сами, но всё упирается в подготовку хороших размеченных корпусов. Может быть, если у нас будут результаты, мы их выложим. Но пока инфинитиграммы и Ldig, там очень мало языков. В отличие от LangDetect, в котором 90 языков.
Вопрос: Есть ли открытый инструмент для PLSA?
Ответ: Если корпус относительно небольшой, есть библиотека BigARTM, её делают в Москве под руководством как раз отца-основателя направления робастного LDA Константина Воронцова. Её можно скачать, она открытая, на осях, быстрая, параллельная.
Есть несколько реализаций, построенных на распределённых системах, вроде Mr. LDA. Там в разных пакетах есть свои реализации. В Spark есть Vowpal Wabbit. Что-то, по-моему, даже было в Mahout. Если хочется делать что-то на корпусе, который влезает в память на одной машине, то можно взять BigARTM или питоновские модули. В Python тоже есть LDA, насколько я знаю.
Вопрос: Ещё вопрос о PLSA. Есть ли гарантии сходимости у ML-алгоритма?
Ответ: Есть математический анализ сходимости, и по ней гарантии есть. На практике мы никогда не видели, что он не сходится. Вернее, он не то чтобы сходится, он может осциллировать вокруг распределения, которое более-менее описывает то, что мы видим. То есть документы способны начать осциллировать, но словарь фиксированный. Мы обычно прекращаем итерации, после того, как перплексия перестаёт уменьшаться.
Вопрос: Как определяется вхождение тем в документе?
Ответ: На основе итеративного процесса. У нас есть счётчики вероятности, что конкретное слово в конкретный документ привнесено данной темой. На основании этого мы обновляем силу темы в документе, пересчитываем всё заново, получаем новые значения счётчика слова документа по теме, и так одно с другим, одно с другим, одно с другим. И в итоге получаем распределение.
Вопрос: Применяются ли модели deep learning для изучения информации из текста?
Ответ: Применяются. Но тут есть такой момент. Очень часто за deep learning принимают эту известную штуку word2vec, doc2vec, sentence2vec. Если подходить строго формально, это на самом деле ни фига не deep learning, но сейчас есть действительно настоящие глубокие сети, их пытаются применять. У меня с такими сетями опыт неоднозначный. От них много шума, а когда пробуешь решить реальную, практическую задачу, получается, что игра не стоит свеч. Но это моё личное мнение. Люди пытаются.
Вопрос: Есть ли хорошо зарекомендовавшие себя open source библиотеки для определения тем документа и эмоциональной окраски?
Ответ: Советую BigARTM и публикации Воронцова о нём. А те, кто в Москве, наверное, могут и на семинары к нему сходить. Это что касается семантики. С эмоциями сложнее. В частности, есть SentiStrength, под академическую лицензию они исходные коды могут дать. Но, как правило, в таких задачах основная ценность — не код, а размеченный корпус. На нём вы можете экспериментировать, тренироваться. А если нет корпуса, то и код ни к чему. Тогда нужно либо брать уже натренированную, готовую модель (такие есть), либо делать корпус.
Вопрос: Какие книги об NLP вы посоветуете?
Ответ: О тематических моделях имеет смысл читать статьи Воронцова. Они дают очень хороший обзор. Об NLP в целом есть Natural Language Processing Handbook. Там достаточно обзорно, но почти все темы раскрыты.
Вопрос: Какие есть интересные продукты или компании в сфере NLP?
Ответ: Я вопрос не исследовал, но наверняка такие есть. Те, кто используют техники в работе? Это в первую очередь поисковики (Google, к примеру) и компании с большими текстовыми корпусами. Думаю, Facebook наверняка к ним относится.
Вопрос: Реально ли создавать конкурентные программы небольшими командами?
Ответ: Реально. Открытых вопросов осталось много. Даже если вы посмотрите на решения, которые сейчас есть, особенно по новым направлениям, они часто не технологичны. Этим занимаются исследовательские лаборатории, студенты. Решения полны костылей и банально неэффективны. Если взять просто хорошего инженера и посадить на оптимизацию готового академического продукта, можно получить офигенную штуку. Но академическая экспертиза и хорошие инженерные навыки соседствуют редко.
Вопрос: Как язык ограничивает мысль?
Ответ: Там, где он не выражает её. Если язык не может выразить мысль, то обычно он расширяется. Язык — он же живой. Почему я назвал нерешённой задачей эволюцию тематических моделей со временем? Мы часто наблюдаем, как для новых социальных явлений появляются слова. Язык — это инструмент коммуникации. Если он перестаёт решать задачу коммуникации, он совершенствуется.
Комментариев нет:
Отправить комментарий