Часть 1: Постановка задачи
Привет, Хабр! Я архитектор решений в компании CleverData. Сегодня я расскажу про то, как мы классифицируем большие объемы данных с использованием моделей, построенных с применением практически любой доступной библиотеки машинного обучения. В этой серии из двух статей мы рассмотрим следующие вопросы.
- Как представить модель машинного обучения в виде сервиса (Model as a Service)?
- Как физически выполняются задачи распределенной обработки больших объемов данных при помощи Apache Spark?
- Какие проблемы возникают при взаимодействии Apache Spark с внешними сервисами?
- Как при помощи библиотек akka-streams и akka-http, а также подхода Reactive Streams можно организовать эффективное взаимодействие Apache Spark с внешними сервисами?
Изначально я планировал написать одну статью, но так как объем материала оказался достаточно большим, я решил разбить ее на две части. Сегодня в первой части мы рассмотрим общую постановку задачи, а также основные проблемы, которые необходимо решить при реализации. Во второй части мы поговорим о практической реализации решения данной задачи с использованием подхода Reactive Streams.
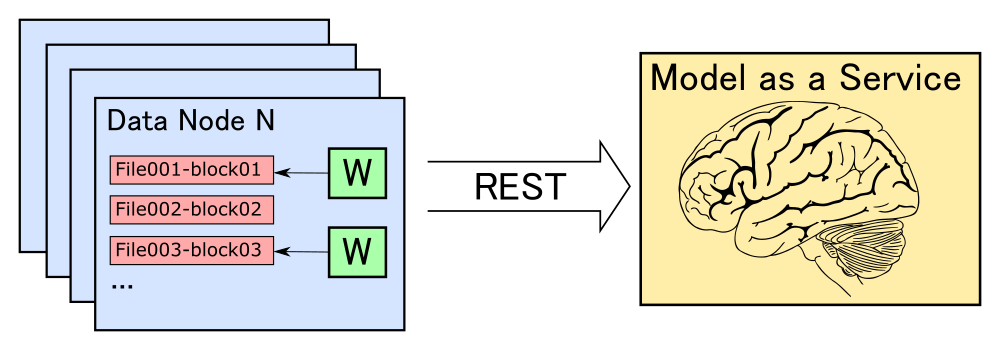
В нашей компании CleverData есть команда аналитиков данных, которые при помощи широкого набора инструментов (таких, как scikit-learn, facebook fastText, xgboost, tensorFlow и т.д) занимаются тренировкой моделей машинного обучения. Де-факто основным языком программирования, который используют аналитики, является Python. Практически все библиотеки для машинного обучения, даже изначально реализованные на других языках, имеют интерфейс на Python и интегрированы с основными Python-библиотеками (в первую очередь с NumPy).
С другой стороны, для хранения и обработки больших массивов неструктурированных данных широко используется экосистема Hadoop. В ней данные хранятся на файловой системе HDFS в виде распределенных реплицируемых блоков определенного размера (как правило, 128 МБ, но есть возможность настроить). Наиболее эффективные алгоритмы обработки распределенных данных стараются минимизировать сетевое взаимодействие между машинами кластера. Для этого данные нужно обрабатывать на тех же машинах, где они хранятся.
Конечно, во многих случаях сетевого взаимодействия полностью избежать невозможно, но, тем не менее, нужно стараться выполнять все задачи локально и максимально уменьшать объем данных, которые необходимо будет передавать по сети.
Такой принцип обработки распределенных данных называется “перенос вычислений к данным” (move computations close to data). Все основные фреймворки, главным образом, Hadoop MapReduce и Apache Spark, придерживаются этого принципа. Они определяют состав и последовательность конкретных операций, которые нужно будет запускать на машинах, где хранятся нужные блоки данных.
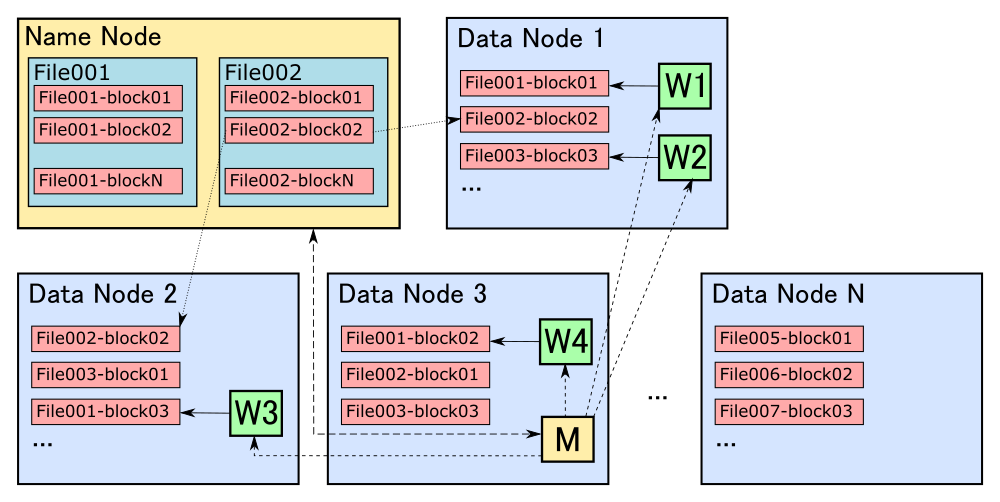
Практически все компоненты экосистемы Hadoop запускаются при помощи виртуальной машины Java (Java Virtual Machine, JVM) и тесно интегрированы между собой. Например, для запуска задач, написанных при помощи Apache Spark для работы с данными, хранящимися на HDFS, не требуется практически никаких дополнительных манипуляций: фреймворк предоставляет данный функционал из коробки.
К сожалению, основная масса библиотек, предназначенных для машинного обучения, предполагает, что данные хранятся и обрабатываются локально. В то же время существуют и такие библиотеки, которые тесно интегрированы с Hadoop-экосистемой, например, Spark ML или Apache Mahout. Однако у них есть ряд существенных недостатков. Во-первых, они предоставляют гораздо меньше реализаций алгоритмов машинного обучения. Во-вторых, далеко не все аналитики данных умеют работать с ними. К преимуществам данных библиотек можно отнести то, что с их помощью можно тренировать модели на больших объемах данных с использованием распределенных вычислений.
Тем не менее, аналитики данных часто используют альтернативные методы для тренировки моделей, в частности, библиотеки, позволяющие задействовать GPU. Рассматривать вопросы тренировки моделей я в этой статье не буду, так как хочу сосредоточиться на применении готовых моделей, построенных при помощи любой доступной библиотеки машинного обучения для классификации больших объемов данных.
Итак, основная задача, которую мы пытаемся здесь решить, – это применение моделей машинного обучения к большим объемам данных, хранящимся на HDFS. Если бы мы могли использовать модуль SparkML из библиотеки Apache Spark, который реализует основные алгоритмы машинного обучения, то классификация больших объемов данных была бы тривиальной задачей:
val model: LogisticRegressionModel = LogisticRegressionModel.load("/path/to/model")
val dataset = spark.read.parquet("/path/to/data")
val result = model.transform(dataset)
К сожалению, данный подход работает только для алгоритмов, реализованных в модуле SparkML (полный список можно найти здесь). В случае использования других библиотек, да к тому же реализованных не на JVM, всё становится гораздо сложнее.
Для решения данной задачи мы решили обернуть модель в REST-сервис. Соответственно, при запуске задачи по классификации данных, хранящихся на HDFS, необходимо организовать взаимодействие между машинами, на которых хранятся данные, и машиной (или кластером машин), на которых запущен сервис классификации.
Описание сервиса классификации на python
Для того, чтобы представить модель в виде сервиса, необходимо решить следующие задачи:
- реализовать эффективный доступ к модели через HTTP;
- обеспечить максимально эффективное использование ресурсов машины (в первую очередь всех ядер процессора и памяти);
- обеспечить устойчивость к высоким нагрузкам;
- обеспечить возможность горизонтального масштабирования.
Доступ к модели по HTTP реализовать достаточно просто: для Python разработано большое количество библиотек, позволяющих реализовать REST точку доступа, используя небольшое количество кода. Одним из таких микрофреймворков является Flask. Реализация сервиса классификации на Flask выглядит следующим образом:
from flask import Flask, request, Response
model = load_model()
n_features = 100
app = Flask(__name__)
@app.route("/score", methods=['PUT'])
def score():
inp = np.frombuffer(request.data, dtype='float32').reshape(-1, n_features)
result = model.predict(inp)
return Response(result.tobytes(), mimetype='application/octet-stream')
if __name__ == "__main__":
app.run()
Здесь мы при старте сервиса загружаем модель в память, и затем используем ее при вызове метода классификации. Функция load_model загружает модель из некоторого внешнего источника, будь то файловая система, key-value хранилище и т.д.
Модель представляет собой некий объект, имеющий метод predict. В случае классификации он принимает на вход некоторый feature вектор определенного размера и выдает либо булево значение, показывающее, подходит ли указанный вектор для данной модели, либо некоторое значение от 0 до 1, к которому потом можно применить порог отсечки: все, что выше порога, является положительным результатом классификации, остальное — нет.
Feature-вектор, который нам необходимо проклассифицировать, мы передаем в бинарном виде и десериализуем в numpy array. Было бы накладным делать HTTP-запрос для каждого вектора. Например, в случае 100-размерного вектора и использования для значений типа float32 полный HTTP-запрос, включая заголовки, выглядел бы примерно следующим образом:
PUT /score HTTP/1.1
Host: score-node-1:8099
User-Agent: curl/7.58.0
Accept: */*
Content-Type: application/binary
Content-Length: 400
[400 bytes of data]
Как видим, КПД такого запроса очень низкий (400 байт полезной нагрузки / (133 байта заголовок + 400 байт тело) = 75%). К счастью, почти во всех библиотеках метод predict позволяет принимать на вход не [1 x n] вектор, а [m x n] матрицу, и, соответственно, выдавать результат сразу же для m входных значений.
Кроме того, библиотека numpy оптимизирована для работы с большими матрицами, позволяя эффективно задействовать все доступные ресурсы машины. Таким образом, мы можем отправить в одном запросе не один, а достаточно большое количество feature векторов, десериализовать их в numpy матрицу размером [m x n], проклассифицировать, и вернуть вектор [m x 1] из булевых или float32 значений. В итоге КПД HTTP взаимодействия при использовании матрицы из 1000 строк становится практически равным 100%. Размером HTTP заголовков в данном случае можно пренебречь.
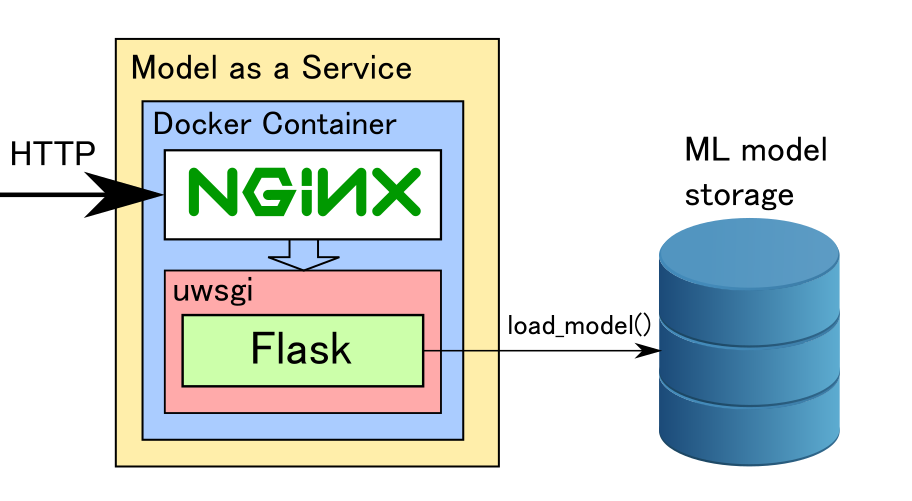
Для тестирования Flask сервиса на локальной машине его можно запустить из командной строки. Однако такой способ совершенно не подходит для промышленной эксплуатации. Дело в том, что Flask является однопоточным и, если мы посмотрим на диаграмму нагрузки процессора во время работы сервиса, то увидим, что одно ядро у нас загружено на 100%, а остальные бездействуют. К счастью, существуют способы задействовать все ядра машины: для этого Flask нужно запускать через сервер веб-приложений uwsgi. Он позволяет оптимально настроить количество процессов и потоков так, чтобы обеспечить равномерную нагрузку на все ядра процессора. Более подробно со всеми опциями по настройке uwsgi можно ознакомится здесь.
В качестве точки входа по HTTP лучше использовать nginx, так как uwsgi в случае высоких нагрузок может работать нестабильно. Nginx же принимает весь входной поток запросов на себя, отфильтровывает некорректные запросы, и дозирует нагрузку на uwsgi. Nginx взаимодействует с uwsgi через linux-сокеты с использованием файла процесса. Примерная конфигурация nginx приведена ниже:
server {
listen 80;
server_name 127.0.0.1;
location / {
try_files $uri @score;
}
location @score {
include uwsgi_params;
uwsgi_pass unix:/tmp/score.sock;
}
}
Как мы видим, получилась достаточно непростая конфигурация для одной машины. Если нам нужно проклассифицировать большие объемы данных, на этот сервис будет приходить высокое количество запросов, и он может стать узким местом. Решением данной проблемы является горизонтальное масштабирование.
Для удобства мы упаковываем сервис в Docker контейнер и затем разворачиваем его на требуемом количестве машин. При желании можно использовать средства автоматизированного развёртывания типа Kubernetes. Примерная структура Dockerfile для создания контейнера с сервисом приведена ниже.
FROM ubuntu
#Installing required ubuntu and python modules
RUN apt-get update
RUN apt-get -y install python3 python3-pip nginx
RUN update-alternatives --install /usr/bin/python python /usr/bin/python3 1
RUN update-alternatives --install /usr/bin/pip pip /usr/bin/pip3 1
RUN pip install uwsgi flask scipy scikit-learn
#copying script files
WORKDIR /etc/score
COPY score.py .
COPY score.ini .
COPY start.sh .
RUN chmod +x start.sh
RUN rm /etc/nginx/sites-enabled/default
COPY score.nginx /etc/nginx/sites-enabled/
EXPOSE 80
ENTRYPOINT ["./start.sh"]
Итак, структура сервиса для классификации выглядит следующим образом:
Краткое описание работы Apache Spark в экосистеме Hadoop
Теперь рассмотрим процесс обработки данных, хранящихся на HDFS. Как я уже ранее отмечал, для этого используется принцип переноса вычислений к данным. Для запуска задач по обработке необходимо знать, на каких машинах хранятся нужные нам блоки данных, чтобы запускать на них процессы, занимающиеся непосредственно обработкой. Также необходимо координировать запуск этих процессов, перезапускать их в случае возникновения нештатных ситуаций, при необходимости агрегировать результаты выполнения различных подзадач и т.д.
Все эти задачи решаются множеством фреймворков, работающих с экосистемой Hadoop. Одним из самых популярных и удобных является Apache Spark. Главным понятием, вокруг которого строится весь фреймворк, является RDD (Resilient Distributed Dataset). В общем случае RDD можно рассматривать как распределенную коллекцию, устойчивую к падениям. RDD можно получить двумя основными способами:
- созданием из внешнего источника, такого как коллекция в памяти, файл или директория на файловой системе и т.д.;
- преобразованием из другого RDD путем применения операций трансформации. RDD поддерживает все основные операции по работе с коллекциями, такие как map, flatMap, filter, groupBy, join и т.д.
Важно понимать, что RDD, в отличие от коллекций, представляет собой не непосредственно данные, а последовательность операций, которые необходимо выполнить над данными. Поэтому при вызове операций трансформации никакой работы фактически не происходит, а мы просто получаем новый RDD, в котором будет содержаться на одну операцию больше, чем в предыдущем. Сама же работа запускается при вызове так называемых терминальных операций, или действий (actions). К ним относятся сохранение в файл, сохранение в коллекцию в памяти, подсчет количества элементов и т.д.
При запуске терминальной операции Spark на основе итогового RDD строит ациклический граф операций (DAG, Directed Acyclic Graph) и последовательно запускает их на кластере согласно полученному графу. При построении DAG на основе RDD Spark проводит ряд оптимизаций, например, по возможности объединяет несколько последовательных трансформаций в одну операцию.
RDD был основной единицей взаимодействия с API Spark в версиях Spark 1.x. В Spark 2.x разработчики заявили, что теперь основным понятием для взаимодействия является Dataset. Dataset представляет собой надстройку над RDD с поддержкой SQL-like взаимодействия. При использовании Dataset API Spark позволяет задействовать широкий спектр оптимизаций, в том числе достаточно низкоуровневых. Но в целом, основные принципы, применимые к RDD, применимы также и к Dataset.
Более подробно о работе Spark можно ознакомиться в документации на официальном сайте.
Рассмотрим пример простейшей классификации на Spark без использования внешних сервисов. Здесь реализован достаточно бессмысленный алгоритм, считающий долю каждой из латинских букв в тексте, а затем считающий стандартное отклонение. Тут в первую очередь важно обратить внимание непосредственно на основные шаги, используемые при работе со Spark.
case class Data(id: String, text: String)
case class Features(id: String, vector: Array[Float])
case class Score(id: String, score: Float) //(1)
def std(vector: Array[Float]): Float = ??? //(2)
val ds: Dataset[Data] = spark.read.parquet("/path/to/data").as[Data] //(3)
val result: Dataset[Score] = ds.map {d: Data => //(4)
val filteredText = data.text.toLowerCase.filter { letter =>
'a' <= letter && letter <= 'z'
}
val featureVector = new Array[Float](26)
val aLetter = 'a'
if (filteredText.nonEmpty) {
filteredText.foreach(letter => featureVector(letter) += 1)
featureVector.indicies.foreach { i =>
featureVector(i) = featureVector(i) / filteredText.length()
}
}
Features(d.id, featureVector)
}.map {f: Features =>
Score(f.id, std(f.vector)) //(5)
}
result.write.parquet("/path/to/result") //(6)
В данном примере мы:
- определяем структуру входных, промежуточных и выходных данных (входные данные у нас определены как некий текст, с которым связан определенный идентификатор, промежуточные данные сопоставляют идентификатор с feature вектором, а выходные сопоставляют идентификатор с некоторым числовым значением);
- определяем функцию для расчета результирующего значения по feature-вектору (например, стандартное отклонение, реализация не приведена);
- определяем исходный Dataset как данные, хранящиеся на HDFS в формате parquet по пути /path/to/data;
- определяем промежуточный Dataset как поэлементное преобразование (map) из исходного Dataset;
- аналогично определяем результирующий Dataset через поэлементное преобразование из промежуточного;
- сохраняем результирующий Dataset на HDFS в формате parquet по пути /path/to/result. Так как сохранение в файл является терминальной операцией, непосредственно сами вычисления запускаются именно на этом этапе.
Apache Spark работает по принципу master-worker. При старте приложения запускается главный процесс, называемый драйвером. В нем исполняется код, ответственный за формирование RDD, на основе которого будут проводиться вычисления.
При вызове терминальной операции драйвер формирует DAG на основе итогового RDD. Затем драйвер инициирует запуск рабочих процессов, называемых исполнителями (executor), в которых будет производиться непосредственно обработка данных. После запуска рабочих процессов драйвер передает им исполняемый блок, который нужно выполнить, а также указывает, к какой части данных его нужно применить.
Ниже приведен код нашего примера, в котором выделены участки кода, выполняемые на исполнителе (между строками executor part begin и executor part end). Остальной код выполняется на драйвере.
case class Data(id: String, text: String)
case class Features(id: String, vector: Array[Float])
case class Score(id: String, score: Float)
def std(vector: Array[Float]): Float = ???
val ds: Dataset[Data] = spark.read.parquet("/path/to/data").as[Data]
val result: Dataset[Score] = ds.map {
// --------------- EXECUTOR PART BEGIN -----------------------
d: Data =>
val filteredText = data.text.toLowerCase.filter { letter =>
'a' <= letter && letter <= 'z'
}
val featureVector = new Array[Float](26)
val aLetter = 'a'
if (filteredText.nonEmpty) {
filteredText.foreach(letter => featureVector(letter) += 1)
featureVector.indicies.foreach { i =>
featureVector(i) = featureVector(i) / filteredText.length()
}
}
Features(d.id, featureVector)
// --------------- EXECUTOR PART END -----------------------
}.map {
// --------------- EXECUTOR PART BEGIN -----------------------
f: Features => Score(f.id, std(f.vector))
// --------------- EXECUTOR PART END -----------------------
}
result.write.parquet(“/path/to/result”)
В экосистеме Hadoop все приложения запускаются в контейнерах. Контейнер представляет собой некоторый процесс, запущенный на одной из машин кластера, которому выделено определенное количество ресурсов. Запуском контейнеров занимается менеджер ресурсов YARN. Он определяет, на какой из машин имеется достаточное количество ядер процессора и оперативной памяти, а также имеются ли на ней необходимые блоки данных для обработки.
При запуске Spark-приложения YARN создает и запускает контейнер на одной из машин кластера, в котором запускает драйвер. Затем, когда драйвер подготовит DAG из операций, которые нужно запускать на исполнителях, YARN запускает дополнительные контейнеры на нужных машинах.
Как правило, для драйвера достаточно выделить одно ядро и небольшое количество памяти (если, конечно, потом результат вычислений не будет агрегироваться на драйвере в память). Для исполнителей в целях оптимизации ресурсов и уменьшения общего количества процессов в системе можно выделить и больше одного ядра: в этом случае исполнитель сможет выполнять несколько задач одновременно.
Но тут важно понимать, что в случае падения одной из выполняющихся в контейнере задач или в случае нехватки ресурсов YARN может принять решение остановить контейнер, и тогда все задачи, которые в нем исполнялись, придется перезапускать заново на другом исполнителе. Кроме того, если мы выделяем достаточно большое количество ядер на контейнер, то есть вероятность, что YARN не сможет его запустить. Например, если у нас есть две машины, на которых осталось незадействованными по два ядра, то мы сможем запустить на каждой по контейнеру, требующем два ядра, но не сможем запустить один контейнер, требующий четыре ядра.
Теперь рассмотрим, как код из нашего примера будет выполняться непосредственно на кластере. Представим, что размер исходных данных равен 2 Терабайт. Соответственно, если размер блока на HDFS равен 128 Мегабайт, то всего будет 16384 блоков. Каждый блок реплицируется на несколько машин для обеспечения надежности. Для простоты возьмем фактор репликации, равный двум, то есть всего будет 32768 доступных блоков. Предположим, что для хранения у нас используется кластер из 16 машин. Соответственно, на каждой из машин в случае равномерного распределения будет примерно по 2048 блоков, или 256 Гигабайт на машину. На каждой из машин у нас по 8 ядер процессора и по 64 Гигабайт оперативной памяти.
Для нашей задачи драйверу не требуется много ресурсов, поэтому выделим для него 1 ядро и 1 ГБ памяти. Исполнителям дадим по 2 ядра и 4 ГБ памяти. Предположим, что мы хотим максимально задействовать ресурсы кластера. Таким образом, у нас получается 64 контейнера: один для драйвера, и 63 – для исполнителей.
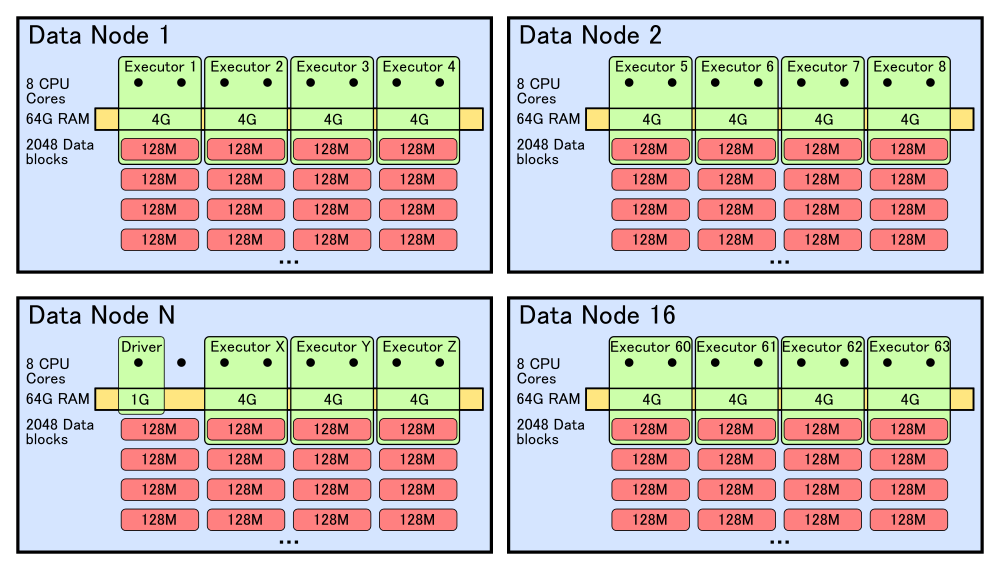
Так как в нашем случае мы используем только операции map, то наш DAG будет состоять из одной операции. Она состоит из следующих действий:
- взять один блок данных с локального жесткого диска,
- преобразовать данные,
- сохранить полученный результат в новый блок на свой же локальный диск.
Всего нам нужно обработать 16384 блока, поэтому каждый исполнитель должен выполнить 16384 / (63 исполнителя * 2 ядра) = 130 операций. Таким образом, жизненный цикл исполнителя как отдельного процесса (в случае, если все происходит без падений) будет выглядеть следующим образом.
- Запуск контейнера.
- Получение от драйвера задачи, в которой будут идентификатор блока и необходимая операция. Так как мы выделили контейнеру два ядра, то исполнитель получает сразу две задачи.
- Выполнение задачи и отправка результата выполнения драйверу.
- Получение от драйвера следующей задачи и повторение п. 2 и 3 до тех пор, пока все блоки для данной локальной машины не будут обработаны.
- Остановка контейнера.
Примечание: более сложные DAG получаются в случае необходимости перераспределения промежуточных данных между машинами, как правило для операций группировки (groupBy, reduceByKey и.т.д) и соединений (join), рассмотрение которых выходит за рамки данной статьи.
Основные проблемы взаимодействия Apache Spark с внешними сервисами
В случае, если в рамках операции map нам нужно обращаться к некоторому внешнему сервису, задача становится менее тривиальной. Предположим, что за взаимодействие с внешним сервисом отвечает некоторый объект класса ExternalServiceClient. В общем случае, перед началом работы нам необходимо его проинициализировать, а затем вызывать по необходимости:
val client = ExternalServiceClient.create() //Инициализация
val score = client.score(featureVector) //Вызов сервиса.
Обычно инициализация клиента занимает некоторое время, поэтому, как правило, его инициализируют при старте приложения, и затем используют, получая экземпляр клиента из некоторого глобального контекста, либо пула. Поэтому, когда контейнер со Spark исполнителем получает задачу, в которой требуется взаимодействие с внешним сервисом, было бы неплохо получить уже инициализированный клиент перед началом работы над массивом данных, и затем его переиспользовать для каждого элемента.
В Spark это можно сделать двумя способами. Во-первых, если клиент является сериализуемым (сам клиент и все его поля должны расширять интерфейс java.io.Serializable), то его можно проинициализировать на драйвере и затем передать исполнителям через механизм broadcast-переменных.
val client = ExternalServiceClient.create()
val clientBroadcast = sparkContext.broadcast(client)
ds.map { f: Features =>
val score = clientBroadcast.value.score(f.vector)
Score(f.id, score)
}
В случае, если клиент не является сериализуемым, либо инициализация клиента является процессом, зависящим от настроек конкретной машины, на которой он запускается (например, для балансировки запросы с одной части машин должны идти на первую машину сервиса, а для другой – на вторую), то клиент можно инициализировать непосредственно на исполнителе.
Для этого у RDD (и у Dataset) есть операция mapPartitions, которая является обобщенной версией операции map (если посмотреть исходный код класса RDD, то там операция map реализована через mapPartitions). Функция, передаваемая операции mapPartitions, запускается один раз для каждого блока. На вход этой функции подается итератор для данных, которые мы будем читать из блока, а на выходе она должна вернуть итератор для выходных данных, соответствующих входному блоку:
ds.mapPartitions {fi: Iterator[Features] =>
val client = ExternalServiceClient.create()
fi.map { f: Features =>
val score = client.score(f.vector)
Score(f.id, score)
}
}
В данном коде клиент к внешнему сервису создается для каждого блока исходных данных. Это, конечно, лучше, чем каждый раз создавать клиент для обработки каждого элемента, и во многих случаях это является вполне приемлемым решением. Однако чуть дальше я покажу, как можно создать объект, который будет инициализироваться один раз при старте контейнера и затем использоваться при запуске всех задач, приходящих в данный контейнер.
Операция обработки результирующего итератора является однопоточной. Напомню, что основной паттерн доступа к структуре типа итератор является последовательный вызов методов hasNext и next:
while (i.hasNext()) {
val item = i.next()
…
}
Если у нас для исполнителя выделено два ядра, то в них будут всего два основных рабочих потока, которые занимаются обработкой данных. Напомню, что если на машине у нас 8 ядер, то YARN не позволит на ней запустить больше 4 процессов исполнителей по 2 ядра, соответственно, у нас будет всего 8 потоков на машину. Для локальных вычислений это является оптимальным выбором, так как это обеспечит максимальную загрузку вычислительных мощностей при минимальных накладных расходах на управление потоками. Однако в случае взаимодействия с внешними сервисами картина меняется.
При использовании внешних сервисов одним из важнейших вопросов является производительность. Простейшим способом реализации является использование синхронного клиента, в котором мы для каждого элемента обращаемся к сервису, и, получив от него ответ, формируем результирующее значение. Однако у этого подхода есть один существенный недостаток: при синхронном взаимодействии поток, синхронно вызывающий внешний сервис, блокируется на время взаимодействия с этим сервисом. Дело в том, что при вызове метода hasNext мы ожидаем получить однозначный ответ на вопрос, есть ли еще элементы для обработки. В случае неопределенности (например, когда мы послали запрос на внешний сервис и не знаем, вернет ли он пустой или непустой ответ) нам не остается ничего другого, как дождаться ответа, заблокировав таким образом поток, который вызвал данный метод. Следовательно, итератор является блокирующей структурой данных.
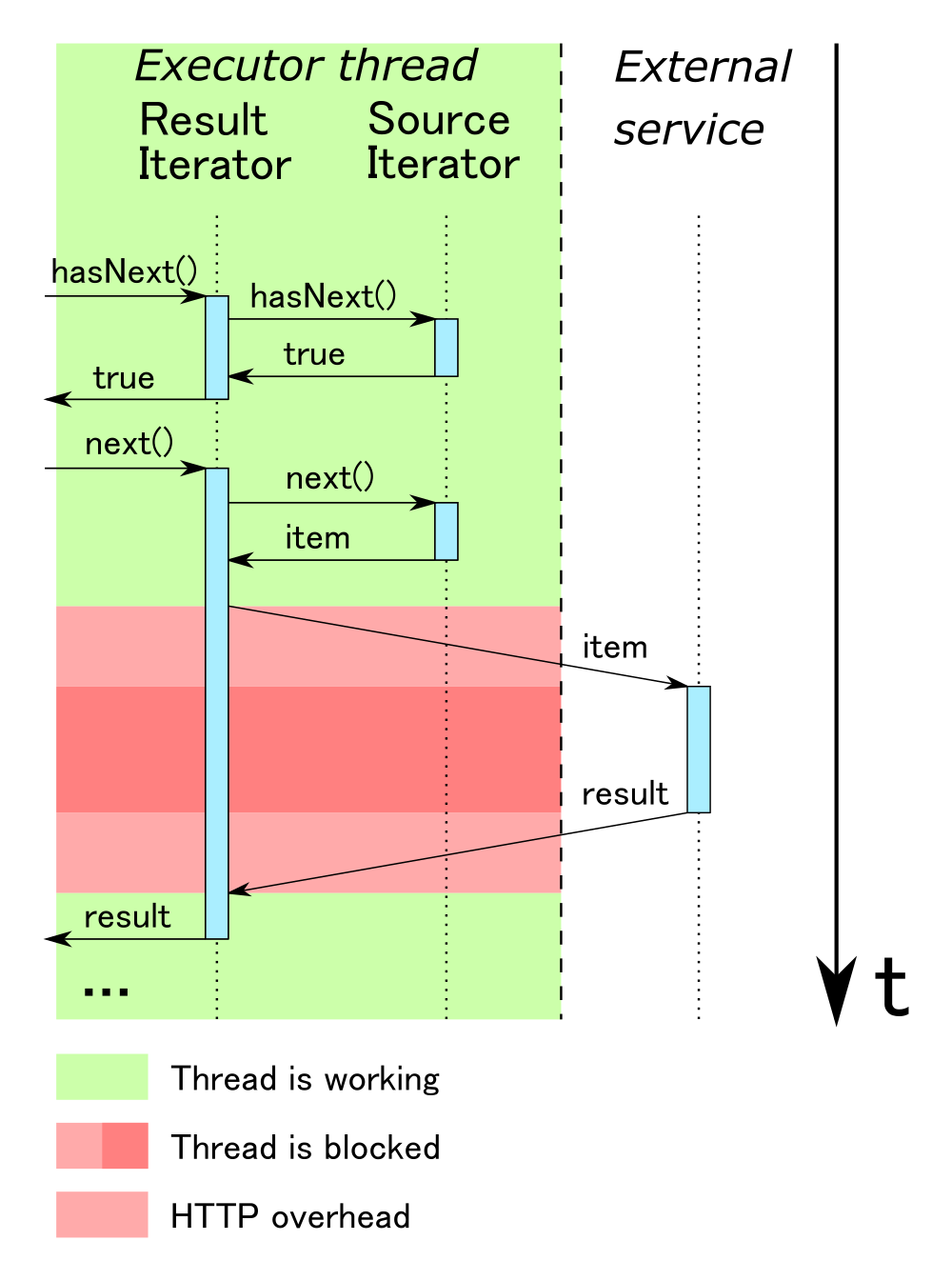
Как вы помните, мы оптимизировали наш сервис классификации таким образом, чтобы он позволял обрабатывать несколько запросов одновременно. Соответственно, нам нужно из исходного итератора собрать необходимое количество запросов, отправить их в сервис, получить ответ и выдать их результирующему итератору.
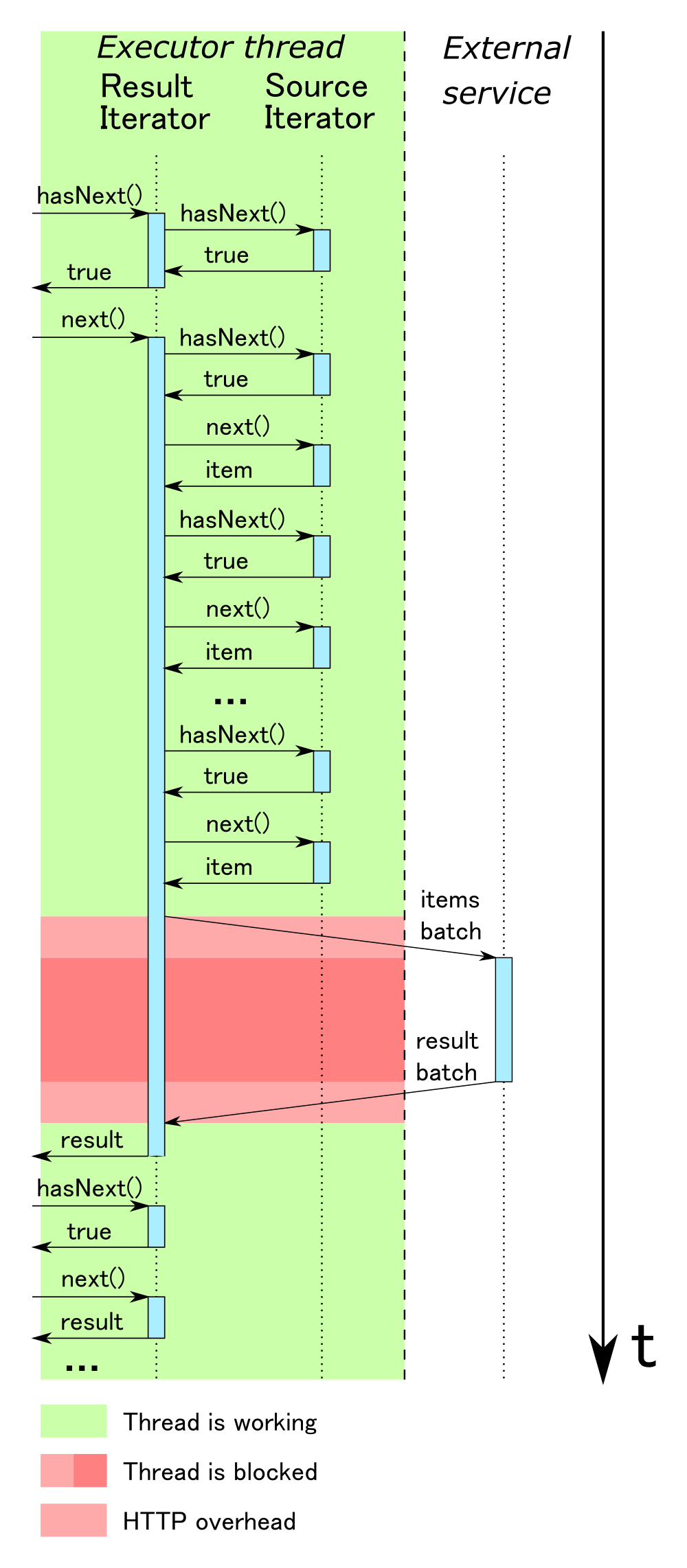
На самом деле, в этом случае производительность будет ненамного лучше, потому что, во-первых, мы вынуждены держать основной поток в заблокированном состоянии, пока происходит взаимодействие с внешним сервисом, и, во-вторых, внешний сервис бездействует в то время, пока мы работаем с результатом.
Окончательная формулировка задачи
Таким образом, при использовании внешнего сервиса мы должны решить проблему синхронного доступа. В идеале, было бы удобно вынести взаимодействие с внешними сервисами в отдельный пул потоков. В этом случае запросы к внешним сервисам выполнялись бы одновременно с обработкой результатов предыдущих запросов, и таким образом можно было бы более эффективно использовать ресурсы машины. Для взаимодействия между потоками можно было бы использовать блокирующую очередь, которая служила бы коммуникационным буфером. Потоки, отвечающие за взаимодействие с внешними сервисами, клали бы данные в очередь, а поток, занимающийся обработкой результирующего итератора, соответственно, забирал бы их оттуда.
Однако такая асинхронная обработка сопряжена с рядом дополнительных проблем.
- В случае, если скорость обработки результирующего итератора будет ниже, чем скорость получения ответов от внешних сервисов, то размер буфера будет расти и может возникнуть переполнение буфера.
- В случае, если в процессе обработки одного из запросов к внешним сервисам произошла ошибка, необходимо принять соответствующие меры. При синхронной обработке всё взаимодействие происходит в рамках одного потока, поэтому достаточно просто бросить исключение. При асинхронной же обработке нужно будет передать информацию об исключении из вспомогательных потоков в основной и при необходимости прекратить как вычитывание данных из исходного итератора, так и выдачу данных в результирующий.
- Для того, чтобы в результирующем итераторе метод hasNext вернул false, необходимо убедиться в том, что на все запросы были получены ответы, и сигнализировать о том, что больше данных в буфере не будет. При синхронной обработке это достаточно просто: если после обработки очередного ответа исходный итератор вернул hasNext = false, то, соответственно, больше элементов не будет. В случае асинхронной обработки, особенно если мы отправляем несколько запросов одновременно, нужно дополнительно координировать получение ответов, и только после получения последнего ответа отправлять сигнал о завершении обработки.
О том, как нам удалось эффективно решить эти проблемы я расскажу в следующей части. Stay tuned!
Комментариев нет:
Отправить комментарий