Тем не менее, этот «уже не стик, но еще и не ноутбук» своего потребителя всё же найдет. Залог тому – четыре ядра простенького, казалось бы, CPU. Стоит возлагать на них надежды?
В предыдущей статье мы анализировали результаты тестов кэш-памяти выполненные в одном потоке, что дает представление об «изолированной» производительность отдельно взятого ядра. Какой будет интегральная оценка многоядерного процессора? Итак, устанавливаем чекбокс Use parallel operations в утилите NCRB и выполняем аналогичную серию измерений.
Многопоточный тест L1-кэш
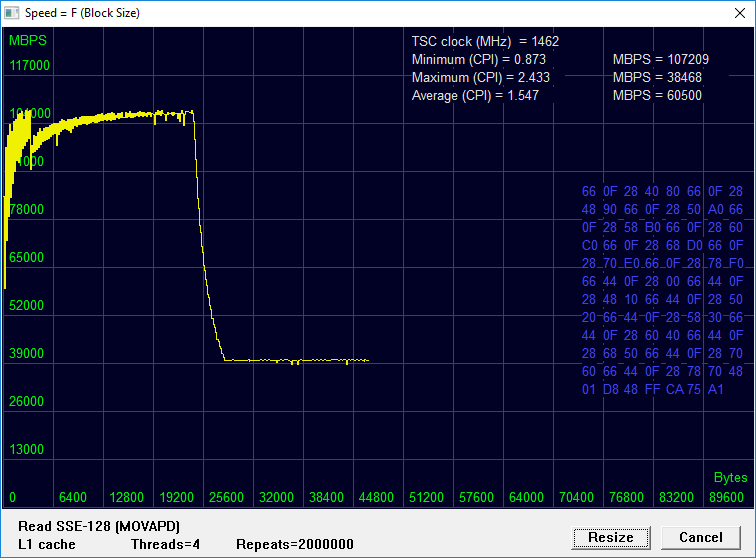
В процессоре Intel Atom x5-Z8350 кэш-память первого уровня является приватным ресурсом каждого из четырех ядер. Это означает, что при обработке блока данных, размер которого меньше размера L1 (в нашем примере это 24 килобайта), каждое из ядер использует собственную кэш-память, конкуренция при доступе практически отсутствует, значит, мы вправе ожидать кратного прироста производительности в соответствии с количеством ядер. Расхожая фраза «а вот и не подеретесь» достаточно точно характеризует данный измерительный сценарий.
Контраргументами могут стать такие факторы, как уменьшение верхнего лимита динамического оверклокинга при реализации заданного сценария энергопотребления и термального режима, а также ограничение процессорного времени, выделяемого операционной системой приложению в рамках многозадачной среды.
Напомним, пиковая производительность в однопоточном тесте (см. «Biostar Racing P1: холодный выхлоп») составляла чуть более 30 GBPS. Задействовав 4 ядра, получаем результат около 107 GBPS, который довольно близок к теоретическому значению 120 GBPS.
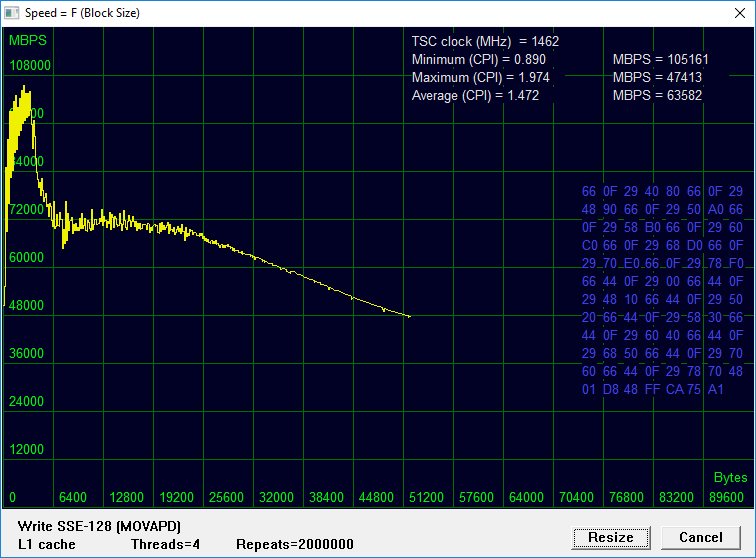
При исследовании L1 важен левый участок графика, соответствующий блоку размером до 24KB. Здесь мы видим две фракции производительности: быстрый участок на малоразмерных транзакциях (более 105 GBPS), и медленный участок для данных, размер которых превышает 6.4KB, но еще «влезающих» в игольное ушко L1-кэш. С первым все понятно: он, как и в случае с тестом чтения, близок к учетверенному для одного ядра значению 120 GBPS. Почему с записью данных в L1 снова «провал»? Об этом можно только догадываться.
Вероятно, инженеры Intel, проектируя эконом-вариант процессора, сместили акцент кэширования данных с L1 на L2. Кэширование инструкций на первом уровне по-прежнему остается эффективным, и с этим у Atom x5-Z8350 все в порядке. В условиях дефицита ресурсов процессор скупится бесшабашно расходовать статическую память для обслуживания потоков данных, более полагаясь на возможности второго кэш-уровня.
Здесь приходит на ум общепринятый подход по формированию профиля нагрузок для обработки транзакций в реальном времени. Общепринятым стандартом считается соотношение чтения к записи в пропорции 70% к 30%. Приблизительно так и соотносится объем, выделенный для «быстрой» записи, к оставшемуся месту в кэш-памяти L1. Можно ли на основании этого предполагать, что Intel нацеливает процессоры Atom в частности на обработку потоковой информации, например, медиаконтента?
Очевидно же, что сдержанность процессора в кэшировании записи приносит пользу в том случае, если к только что записанной информации не будет повторного доступа: кэширование «ненужных» данных засоряет память, вытесняя из нее «нужные» данные. Запись в память, выполняемая при распаковке медиаконтента, на первый взгляд, является операцией, кэшировать которую не выгодно. Обращение к ранее записанным данным при отказе от кэширования, напротив, проиграет.
Многопоточный тест L2-кэш
Кэш-память второго уровня, общим объемом 2 Мегабайта, разделена на две равные части по 1 MB, каждая из которых обслуживает группу из двух ядер. Это означает, что в многопоточном тесте на каждое ядро приходится 512 килобайт кэш-памяти L2 в отличие от 1 Мегабайта в однопоточном. Следовательно, на графике зависимости скорости обработки блока от его размера, точку перегиба следует ожидать в окрестности X=512 KB, а не X=1024 KB, как это имело место в однопоточном тесте (см. «Biostar Racing P1: холодный выхлоп»). Рассмотренные топологические особенности кэш-памяти L2 также оказывают влияние на масштабирование скорости доступа к ней.
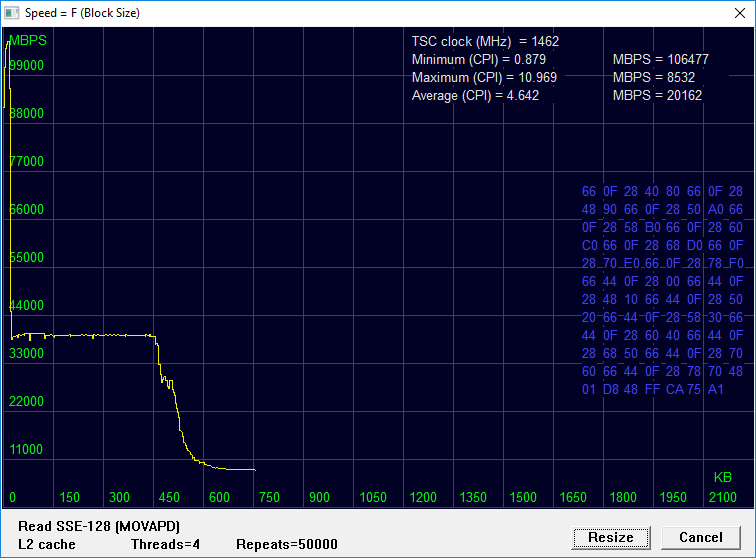
Производительность L2 характеризует участок графика, удовлетворяющий двойному неравенству 24 KB < X < 512 KB, что соответствует блоку данных, который уже не помещается в L1, но еще помещается в L2.
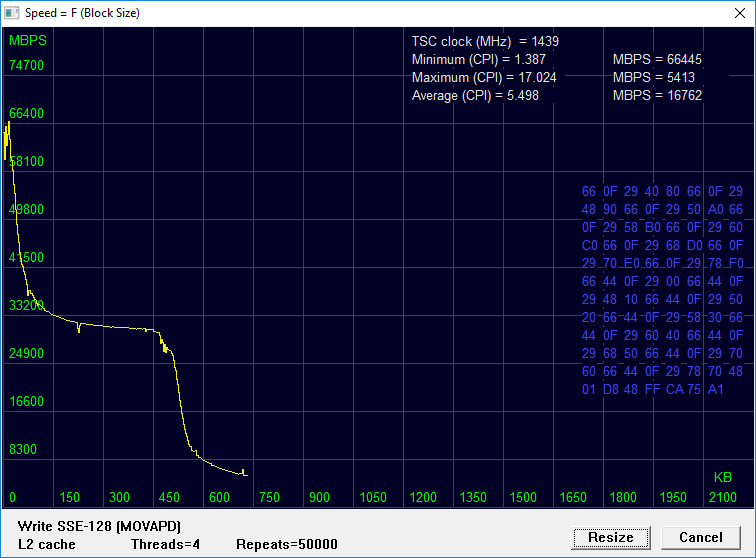
Напомним, скорость чтения L2 в однопоточном тесте составляет около 11.5 GBPS. Результат масштабирования — около 39 GBPS. Очень неплохо! Скорость записи L2 в однопоточном тесте составляет около 12 GBPS. Результат масштабирования — около 31 GBPS.
Вместо резюме
Можно констатировать неплохой уровень многопоточной производительности исследуемой платформы. Архитектура процессора Intel Atom x5-Z8350, определяющая приватную кэш-память L1 и частично-разделяемую L2, ожидаемо отразилась на результатах бенчмарок.
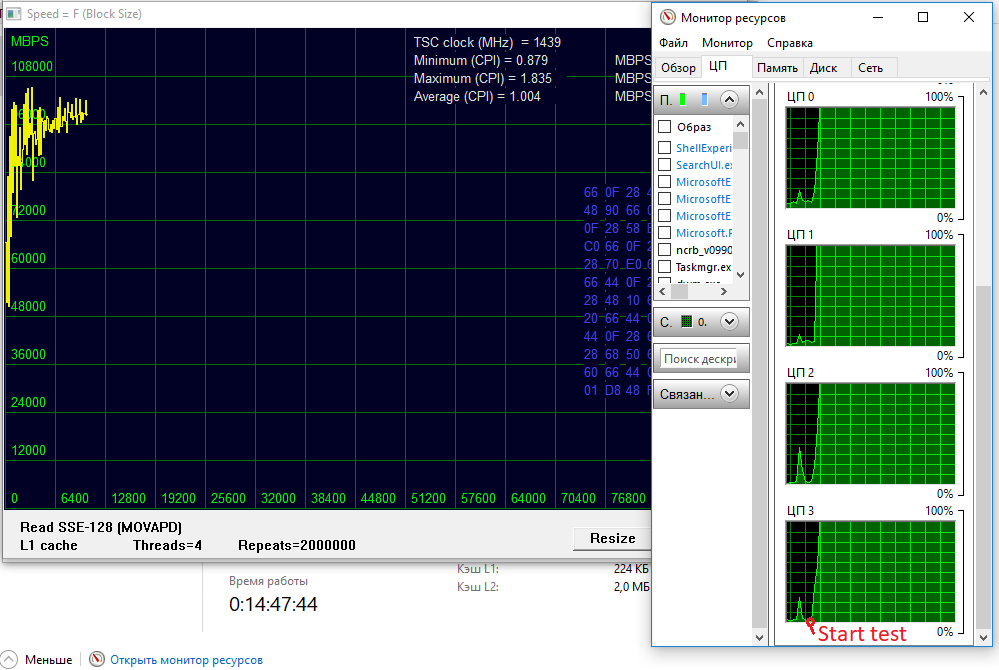
При запуске многопоточного теста, загрузка каждого из четырех ядер процессора возрастает до 100 процентов. А что при этом происходит с температурами и потребляемой мощностью?
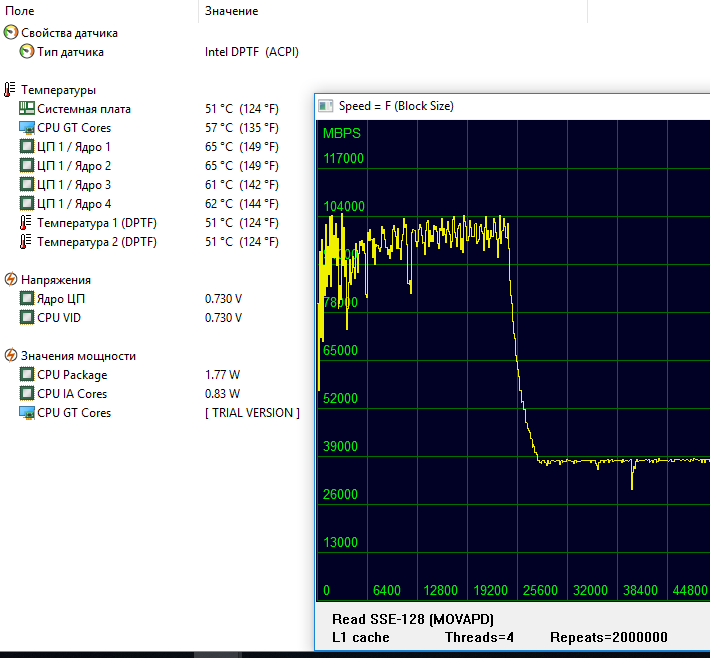
Результат получен с помощью популярной информационно-диагностической утилиты AIDA64 по прошествии примерно 20 минут после запуска многопоточного теста NCRB.
Важное предостережение
Пытаясь повторить выше описанные опыты на своем компьютере, необходимо выполнить резервное копирование данных, убедиться в эффективности системы охлаждения процессора, надежности блока питания и импульсного регулятора Vcore. Стресс-тест может повредить разогнанную или нестабильную систему.
Комментариев нет:
Отправить комментарий