
Скорее всего, вы уже слышали о языке программирования Go, популярность его постоянно растет, что вполне обоснованно. Этот язык простой, быстрый и опирается на прекрасное сообщество. Один из самых любопытных аспектов языка — это модель многопоточного программирования. Примитивы, положенные в ее основу, позволяют создавать многопоточные программы легко и просто. Эта статья предназначена для тех, кто хочет изучить эти примитивы: горутины и каналы. И, через иллюстрации, я покажу, как с ними работать. Надеюсь, это будет для вас хорошим подспорьем в дальнейшем изучении.
Однопоточные и многопоточные программы
Однопоточные программы вы, скорее всего, уже писали. Обычно это выглядит так: есть набор функций для выполнения различных задач, каждая функция вызывается только тогда, когда предыдущая подготовила для нее данные. Таким образом, программа работает последовательно.
Именно таким будет наш первый пример — программа добывающая руду. Наши функции будут искать, добывать и перерабатывать руду. Руда в шахте в нашем примере представлена списками строк, функции принимают их в качестве параметров и возвращают список «обработанных» строк. Для однопоточной программы наше приложение будет спроектировано следующим образом:
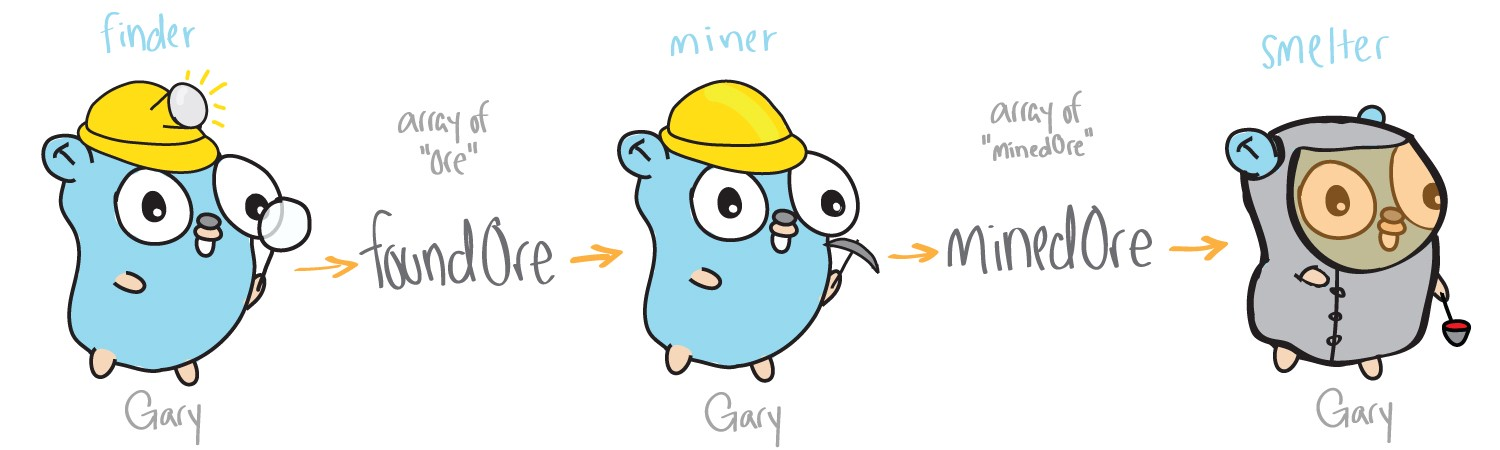
В этом примере всю работу выполняет один поток(гофер Гари). Три основные функции: поиск, добыча и обработка выполняются последовательно друг за другом.
func main() {
theMine := [5]string{"rock", "ore", "ore", "rock", "ore"}
foundOre := finder(theMine)
minedOre := miner(foundOre)
smelter(minedOre)
}
Если напечатать результат работы каждой функции, мы получим следующее:
From Finder: [ore ore ore]
From Miner: [minedOre minedOre minedOre]
From Smelter: [smeltedOre smeltedOre smeltedOre]
Простой дизайн и реализация является плюсом однопоточного подхода. Но что делать, если вы хотите запускать и выполнять функции независимо друг от друга? Тут вам на помощь приходит многопоточное программирование.
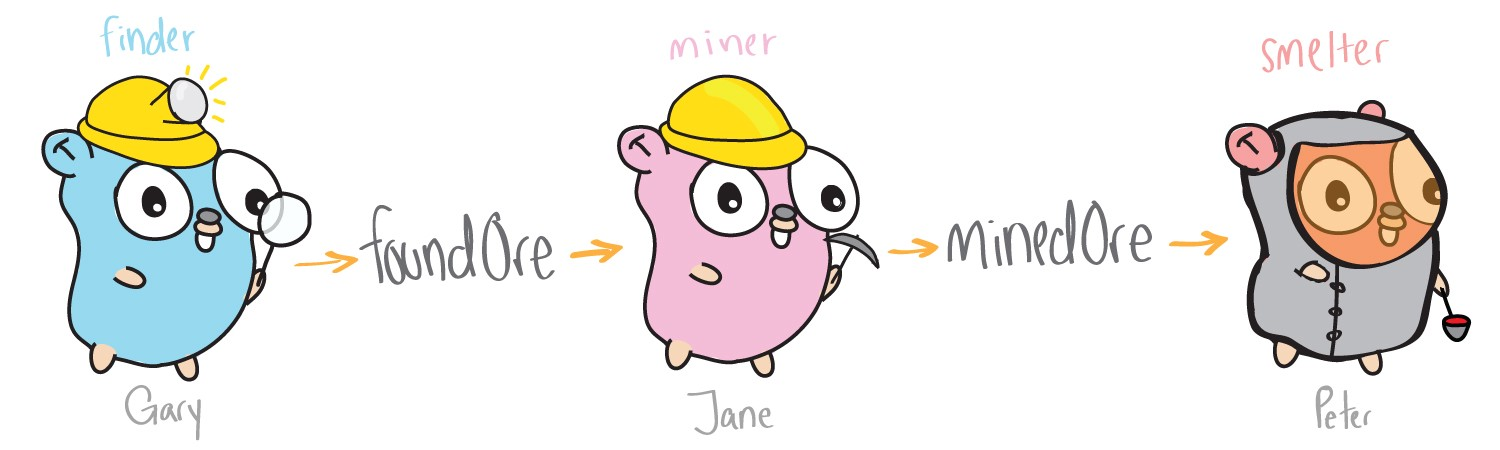
Такой подход к добыче руды гораздо эффективнее. Теперь несколько потоков(гоферов) работают независимо, и Гари делает только часть работы. Один гофер ищет руду, другой добывает, а третий переплавляет, и все это потенциально одновременно. Для того чтобы реализовать такой подход, в коде нам нужны две вещи: создавать гоферов-обработчиков независимо друг от друга и передавать между ними руду. В Go для этого существуют горутины и каналы.
Горутины
Горутины можно представлять себе как «легковесные потоки», чтобы создать горутину нужно просто поставить ключевое слово go пред кодом вызова функции. Чтобы продемонстрировать насколько это просто, давайте создадим две функции поиска, вызовем их с ключевым слово go и будем печатать сообщение каждый раз когда они найдут «руду» в своем руднике.

func main() {
theMine := [5]string{"rock", "ore", "ore", "rock", "ore"}
go finder1(theMine)
go finder2(theMine)
<-time.After(time.Second * 5) //пока не обращайте внимания на этот код
}
Вывод нашей программы будет таким:
Finder 1 found ore!
Finder 2 found ore!
Finder 1 found ore!
Finder 1 found ore!
Finder 2 found ore!
Finder 2 found ore!
Как можно видеть, нет никакого порядка в том, какая функция первой «найдет руду»; функции поиска работают одновременно. Если запускать пример несколько раз, то порядок будет отличаться. Теперь мы можем запускать многопоточные (многогоферные) программы, и это серьезный прогресс. Но что делать, когда нам нужно наладить связь между независимыми горутинами? Наступает время для магии каналов.
Каналы
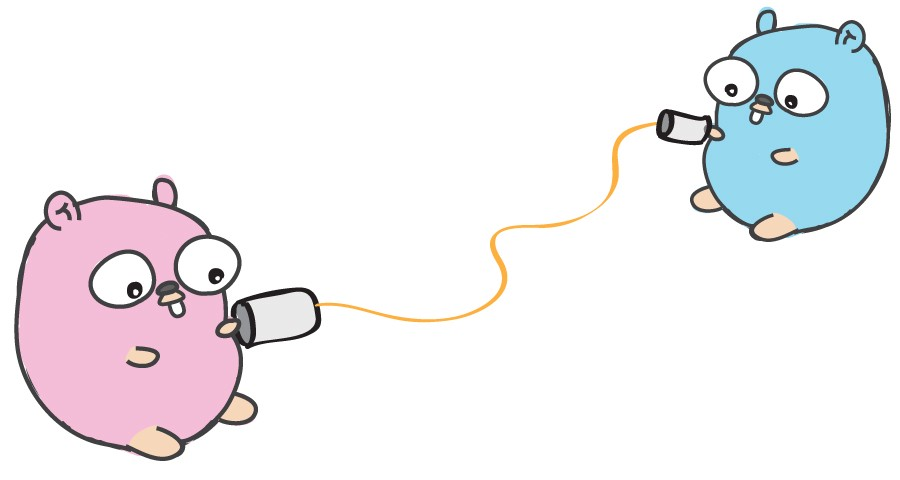
Каналы позволяют горутинам обмениваться данными. Это своеобразная труба, через которую горутины могут посылать и принимать информацию от других горутин.
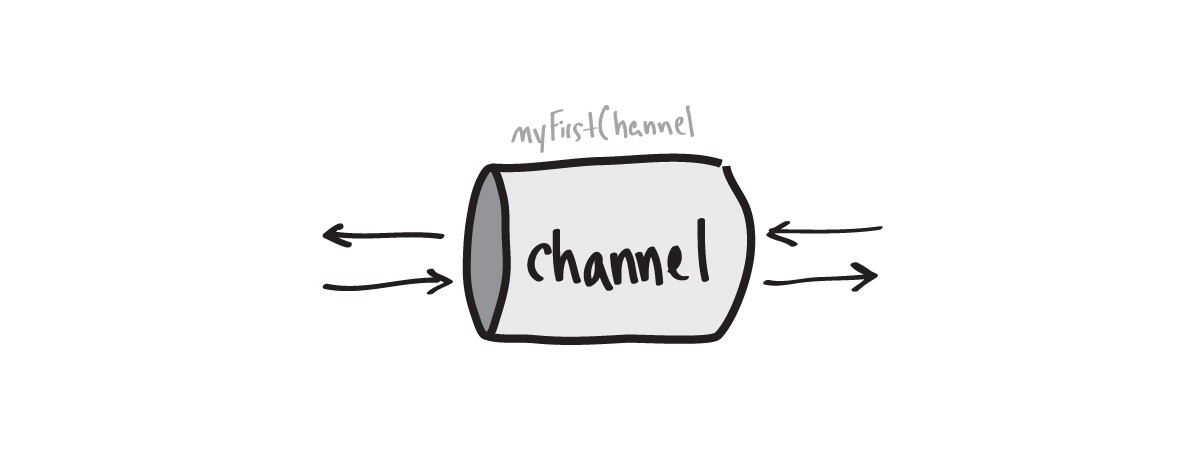
Чтение и запись в канал осуществляется при помощи оператора-стрелочки (<-), который указывает направление движения данных.

myFirstChannel := make(chan string)
myFirstChannel <- "hello" // Записать в канал
myVariable := <- myFirstChannel // Прочитать из канала
Теперь нашему гоферу-разведчику не нужно накапливать руду, он может сразу передать ее дальше, используя каналы.
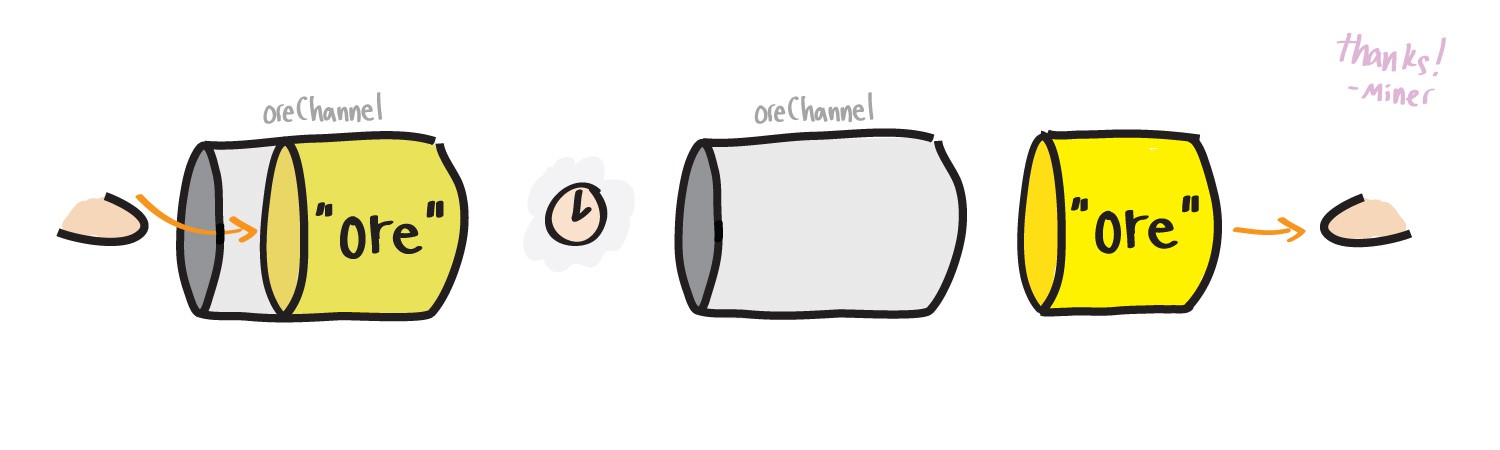
Я обновил пример, теперь код искателя и добытчика руды — анонимные функции. Не слишком заморачивайтесь, если раньше не сталкивались с ними, просто имейте ввиду, что каждая из них вызывается с ключевым словом go, следовательно, будет выполнятся в собственной горутине. Самое важное здесь то, что горутины передают данные между собой используя канал oreChan. А с анонимными функциями мы разберемся ближе к концу.
func main() {
theMine := [5]string{“ore1”, “ore2”, “ore3”}
oreChan := make(chan string)
// Искатель руды
go func(mine [5]string) {
for _, item := range mine {
oreChan <- item //отправка
}
}(theMine)
// Добытчик руды
go func() {
for i := 0; i < 3; i++ {
foundOre := <-oreChan //получение
fmt.Println(“Miner: Received “ + foundOre + “ from finder”)
}
}()
<-time.After(time.Second * 5) // снова не обращайте внимания
}
Вывод ниже наглядно демонстрирует, что наш Добытчик трижды получает из канала руду по одной порции за раз.
Miner: Received ore1 from finder
Miner: Received ore2 from finder
Miner: Received ore3 from finder
Итак, теперь мы умеем пересылать данные между разными горутинами(гоферами), но прежде чем начать писать сложную программу, давайте разберемся с некоторыми важными свойствами каналов.
Блокировки
В некоторых ситуациях при работе с каналами горутина может быть заблокирована. Это необходимо, чтобы горутины могли синхронизироваться друг с другом прежде чем они начнут или продолжат работу.
Блокировка при записи
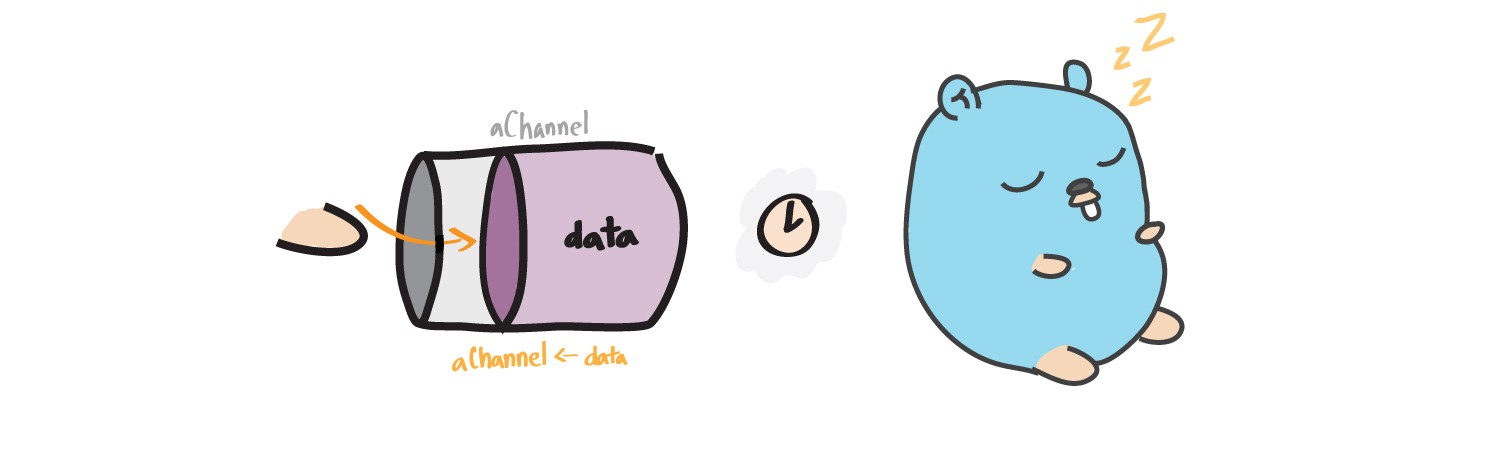
Когда горутина (гофер) посылает данные в канал, она блокируется до тех пор, пока другая горутина не прочитает данные из канала.
Блокировка при чтении
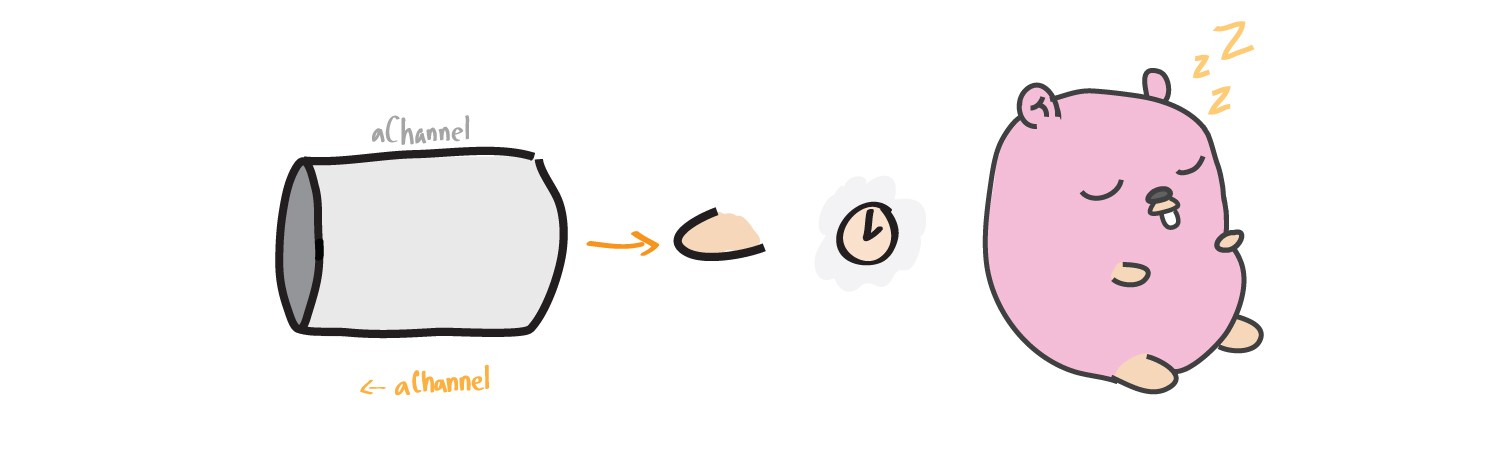
Аналогично блокировке при записи в канал, горутина может быть заблокирована при чтении из канала до тех пор, пока в него ничего не запишут.
Если блокировки, на первый взгляд, кажутся вам чем-то сложным, можно представить их как «передачу денег» между двумя горутинами (гоферами). Когда один гофер хочет передать или получить деньги, то ему приходится ждать второго участника сделки.
Разобравшись с блокировками горутин на каналах, давайте обсудим два разных типа каналов: буферизованные и небуферизованные. Выбирая тот или иной тип, мы во многом определяем поведение программы.
Небуферизованные каналы
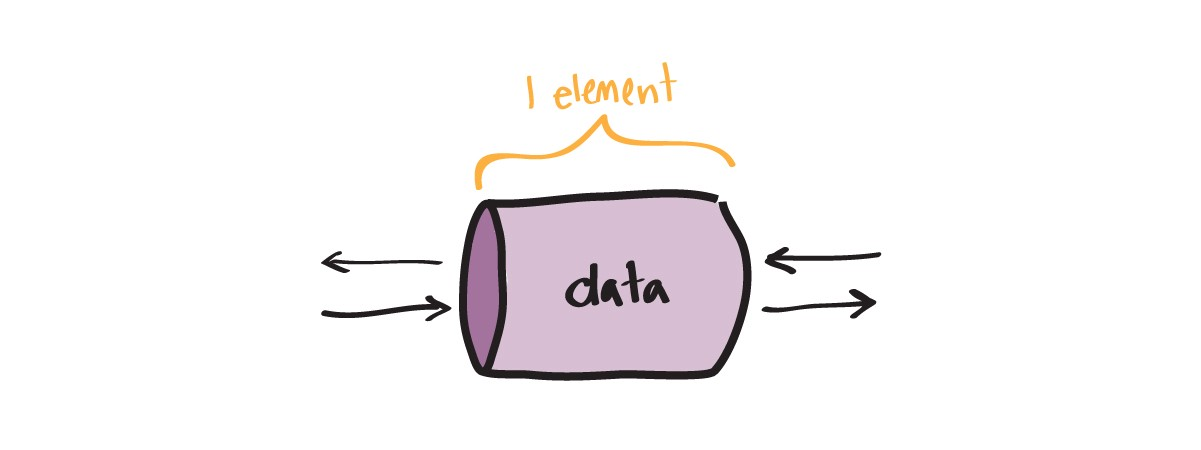
Во всех предыдущих примерах мы использовали именно такие каналы. По таким каналам можно передать только один фрагмент данных за раз (с блокировкой, как описано выше).
Буферизованные каналы

Потоки в программе не всегда могут быть идеально синхронизированы. Допустим, в нашем пример случилось так, что гофер-разведчик нашел три части руды, а гофер-шахтер за то же время успел добыть всего одну часть из найденных запасов. Вот для того, чтобы гофер-разведчик не тратил большую часть своего времени, ожидая когда шахтер закончит свою работу, мы будем использовать буферизованные каналы. Давайте начнем с создания канала емкостью 3.
bufferedChan := make(chan string, 3)
В буферизоваванный канал мы можем послать несколько фрагментов данных, без необходимости чтения их другой горутиной. Это основное отличие от небуферизованных каналов.

bufferedChan := make(chan string, 3)
go func() {
bufferedChan <- "first"
fmt.Println("Sent 1st")
bufferedChan <- "second"
fmt.Println("Sent 2nd")
bufferedChan <- "third"
fmt.Println("Sent 3rd")
}()
<-time.After(time.Second * 1)
go func() {
firstRead := <- bufferedChan
fmt.Println("Receiving..")
fmt.Println(firstRead)
secondRead := <- bufferedChan
fmt.Println(secondRead)
thirdRead := <- bufferedChan
fmt.Println(thirdRead)
}()
Порядок вывода в такой программе будет следующий:
Sent 1st
Sent 2nd
Sent 3rd
Receiving..
first
second
third
Чтобы избежать лишних усложнений, мы не будет использовать буферизованные каналы в нашей программе. Но важно помнить, такие типы каналов тоже доступны для использования.
Также важно отметить, что буферизованные каналы не всегда избавляют вас от блокировок. Например, если гофер-разведчик в десять раз быстрее, чем гофер-шахтер, и они связаны чрез буферизованные канал емкостью 2, то гофер-разведчик будет каждый раз заблокирован при отправке, если в канале уже есть два фрагмента данных.
Собираем все вместе
Итак, вооружившись горутинами и каналами, мы можем написать программу, используя все преимущества многопоточного программирования в Go.
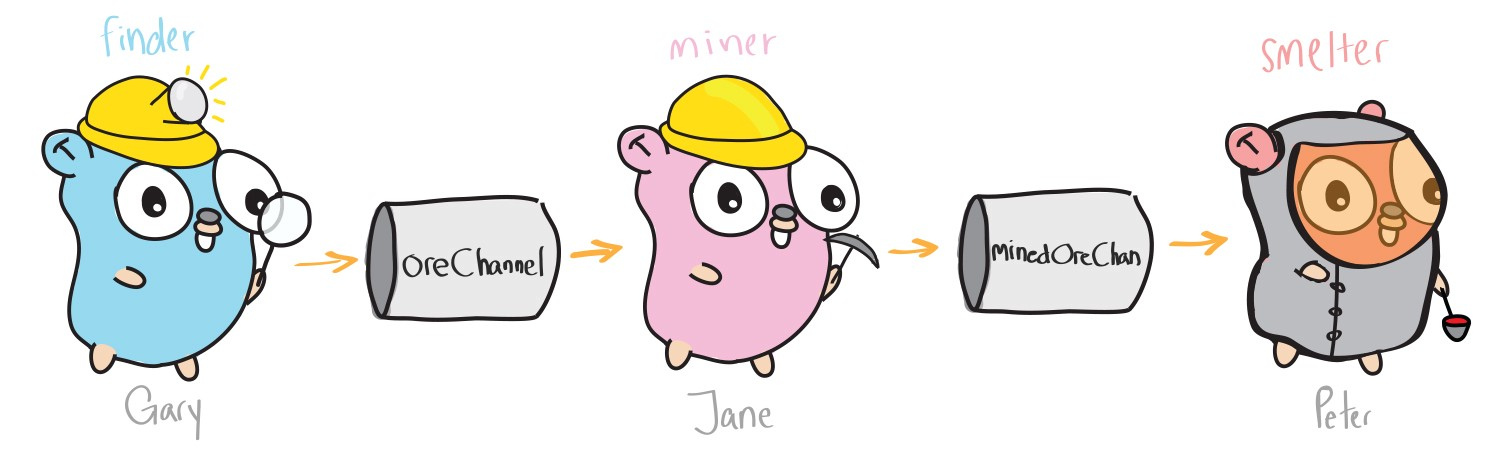
theMine := [5]string{"rock", "ore", "ore", "rock", "ore"}
oreChannel := make(chan string)
minedOreChan := make(chan string)
// Разведчик
go func(mine [5]string) {
for _, item := range mine {
if item == "ore" {
oreChannel <- item //передаем данные в oreChannel
}
}
}(theMine)
// Добытчик
go func() {
for i := 0; i < 3; i++ {
foundOre := <-oreChannel //чтение из канала oreChannel
fmt.Println("From Finder: ", foundOre)
minedOreChan <- "minedOre" //передаем данные в minedOreChan
}
}()
// Переработчик
go func() {
for i := 0; i < 3; i++ {
minedOre := <-minedOreChan //чтение данных из minedOreChan
fmt.Println("From Miner: ", minedOre)
fmt.Println("From Smelter: Ore is smelted")
}
}()
<-time.After(time.Second * 5) // Все еще можете игнорировать
Такая программа выведет следующее:
From Finder: ore
From Finder: ore
From Miner: minedOre
From Smelter: Ore is smelted
From Miner: minedOre
From Smelter: Ore is smelted
From Finder: ore
From Miner: minedOre
From Smelter: Ore is smelted
По сравнению с нашим первым примером это серьезное улучшение, теперь все функции выполняются независимо, каждая в своей горутине. А также у нас появился конвеер из каналов, по которому передается руда сразу после обработки. Для сохранения фокуса на базовом понимании работы каналов и горутин я опустил некоторые моменты, что может привести к сложностям с запуском программы. В завершении, я хочу подробнее остновиться на этих особенностях языка, так как они помогают в работе с горутинами и каналами.
Анонимные горутины

Подобно тому, как мы запускаем обычную функцию в горутине, мы можем объявить анонимную функцию сразу после ключевого слова go и вызвать ее, используя следующий синтаксис:
// Анонимная горутина
go func() {
fmt.Println("I'm running in my own go routine")
}()
Таким образом, если нам нужно вызывать функцию только в одном месте, мы можем запустить ее в отдельной горутине, не заботясь заранне о ее декларации.
Функция main это горутина

Да, фунция main действительно работает в своей собственной горутине. И, что более важно, после ее завершения все остальные горутины так же завершаются. Именно по этой причине мы поместили вызов таймера в конце нашей функции main. Этот вызов создает канал и посылает в него данные спустя 5 секунд.
<-time.After(time.Second * 5) //Через пять секунд из канала придут данные
Помните, что горутина заблокируется при чтении из канала, пока в него что-нибудь не пошлют? Это в точности то, что происходит при добавлении указанного кода. Основная горутина заблокируется, давая другим горутиам 5 секунд времени на работу. Такой способ хорошо работает, но, обычно, для проверки завершения работы всех горутин используют другой подход. Для передачи сигнала о завершении работы создается специальной канал, основная горутина блокируется на чтении из него и, как только дочерняя горутина завершает свою работу, она делает запись в этот канал; основная горутина разблокируется и программа завершится.

func main() {
doneChan := make(chan string)
go func() {
// Сделать что-нибудь полезное
doneChan <- “I’m all done!”
}()
<-doneChan // чтение блокируется до сигнала о завершении работы
}
Чтение из канала в цикле for-range
В нашем примере в функции гофера-добытчика мы использовали цикл for, чтобы выбрать из канала три элемента. Но что делать, если заранее не известно сколько, данных может быть в канале? В таких случаях вы можете использовать канал, как аргумент для цикла for-range, так же как с коллекциями. Обновленная функция может выглядеть так:
// Добытчик
go func() {
for foundOre := range oreChan {
fmt.Println(“Miner: Received “ + foundOre + “ from finder”)
}
}()
Таким образом, добытчик руды прочитает все, что разведчик ему пошлет, использование кнала в цикле это гарантирует. Обратите внимание, что после того, как все данные из канала обработаны, цикл заблокируется на чтении; чтобы избежать блокировки, нужно закрыть канал вызовом close(channel).
Неблокирующе чтение из канала
Используя конструкцию select-case, можно избежать блокирующего чтения из канала. Ниже приведен пример использования этой конструкции: горутина прочитает из канала данные, если только они там есть, в противном случае выполняется блок default:
myChan := make(chan string)
go func(){
myChan <- “Message!”
}()
select {
case msg := <- myChan:
fmt.Println(msg)
default:
fmt.Println(“No Msg”)
}
<-time.After(time.Second * 1)
select {
case msg := <- myChan:
fmt.Println(msg)
default:
fmt.Println(“No Msg”)
}
После запуска этот код выведет следующее:
No Msg
Message!
Неблокирующая запись в канал
Блокировки при записи в канал можно избежать, используя ту же самую конструкцию select-case. Внесем небольшую правку в предыдущий пример:
select {
case myChan <- “message”:
fmt.Println(“sent the message”)
default:
fmt.Println(“no message sent”)
}
Что изучать дальше

Есть большое количество статей и докладов, которые гораздо подробнее освещают работу с каналами и горутинам. И теперь, кода у вас есть четкое представление о том, для чего и как используются эти инструменты, вы можете получить максимальную отдачу от следующих материалов:
Спасибо, что потратили время на чтение. Я надеюсь, что помог вам разобраться c каналами, горутинами и преимуществами, которые вам дают многопоточные программы.
Комментариев нет:
Отправить комментарий