Небольшая предыстория о том, как мы пришли к идее нейрописателя и в чем именно она заключалась. В 2017 году мы сделали проект для одного паблика “Вконтакте”, название и скрины из которого модераторы Хабрахабра запретили публиковать, посчитав его упоминание «само»пиаром. Паблик существует с 2013 года и объединяет посты общей идеей разложения юмора через строчку и разделения строк символом “@”:
СЕТАП
@
РАЗВИТИЕ СЕТАПА
@
ПАНЧЛАЙН
Количество строк может меняться, сюжет может быть любой. Чаще всего это юмор или острые социальные заметки о бесящих фактах реальности. В целом такая конструкция называется «бугуртом».
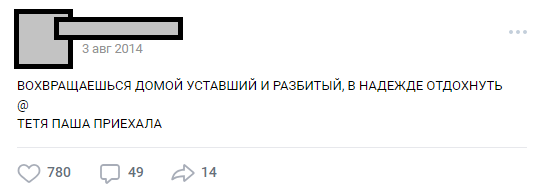
Один из типичных бугуртов
За годы существования паблик оброс внутренним лором (персонажи, сюжеты, локации), а количество постов перевалило за 30 000. На момент их парсинга для нужд проекта количество исходных строк текста превышало полмиллиона.
Часть 0. Появление идеи и команды
На волне массовой популярности нейронных сетей идея обучить ИНС на наших текстах витала в воздухе где-то на протяжении полугода, но была окончательно сформулирована с помощью E7su в декабре 2016. Тогда же было придумано название (“Нейробугурт”). На тот момент команда заинтересованных в проекте состояла всего из трех человек. Все мы были студентами без практического опыта в алгоритмах и нейронных сетях. Хуже того — у нас даже не было ни одной подходящей GPU для обучения. Всё что у нас было — это энтузиазм и уверенность, что эта история может быть интересной.
Часть 1. Формулировка гипотезы и задачи
Нашей гипотезой оказалось предположение, что если смешать все опубликованные за три с половиной года тексты и обучить на этом корпусе нейронную сеть, то может получится:
а) креативнее, чем у людей
б) смешно
Даже если в бугурте слова или буквы окажутся машинно перепутаны и расположены хаотично — мы верили, что это может сработать как фансервис и всё равно будет радовать читателей.
Задачу сильно упрощало то, что формат бугуртов, по сути, текстовый. А значит, нам не нужно было погружаться в машинное зрение и другие сложные вещи. Ещё одна хорошая новость состояла в том, что весь корпус текстов очень однотипный. Это давало возможность не использовать обучение с подкреплением — по крайней мере, на первых этапах. В тоже время мы четко понимали, что создать нейросеть-писателя с читаемым выводом больше чем на один раз не так то легко. Риск родить монстра, который будет хаотично швырять буквами, был очень велик.
Часть 2. Подготовка корпуса текстов
Считается, что этап подготовки может занять очень много времени, так как связан со сбором и очисткой данных. В нашем случае он оказался достаточно коротким: был написан небольшой парсер, который выкачал около 30к постов со стены сообщества и сложил их в txt-файл.
Очистку данных перед первым обучением мы не проводили. В дальнейшем это сыграло с нами злую шутку, потому что из-за ошибки, закравшейся на данном этапе, мы долго не могли привести результаты в читаемый вид. Но об этом чуть дальше.
Скрин файлика с бургерами
Часть 3. Анонсирование, уточнение гипотезы, выбор алгоритма
Мы использовали доступный ресурс — огромное количество подписчиков паблика. Предположение состояло в том, что среди 300 000 читателей найдутся несколько энтузиастов, которые владеют нейросетями на достаточном уровне, чтобы заполнить пробелы в знаниях нашей команды. Мы отталкивались от идеи широко анонсировать конкурс и привлечь энтузиастов машинного обучения к обсуждению сформулированной задачи. Написав тексты, мы рассказали людям о нашей идее и надеялись на отклик.
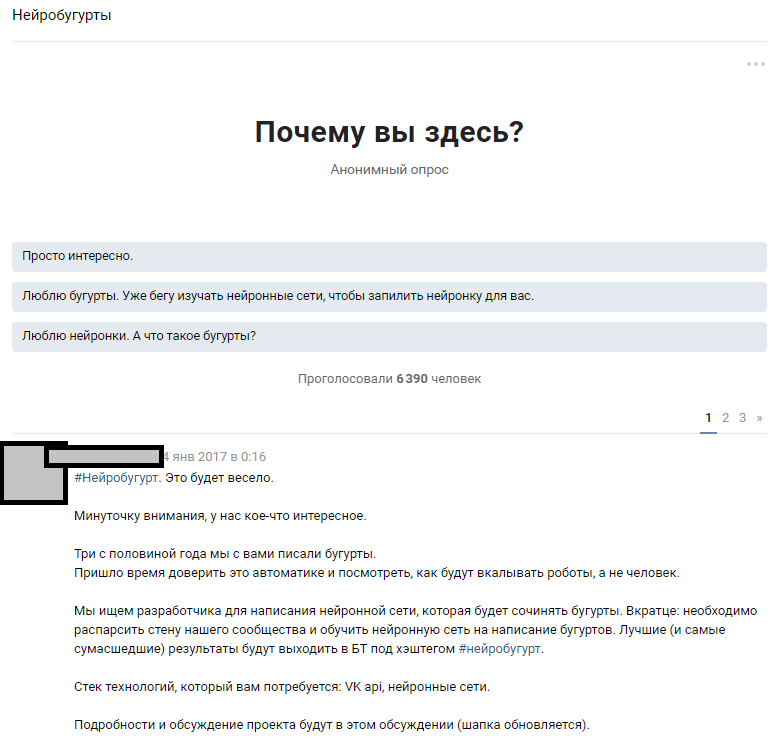
Анонс в тематическом обсуждении
Реакция людей превзошла наши самые смелые ожидания. Обсуждение самого факта, что мы собираемся обучить нейронную сеть, развело холивар почти на 1000 комментариев. Бóльшая часть читателей просто угарали и пытались представить, как будет выглядеть результат. В тематическое обсуждение заглянуло порядка 6000 человек, а комментарии оставили больше 50 заинтересованных любителей, которым мы выдали тестовый сет из 814 строчек бугуртов для проведения первичных тестов и обучения. Каждый заинтересованный мог взять датасет и обучить тот алгоритм, который ему наиболее интересен, а потом обсудить с нами и с другими энтузиастами. Мы заранее объявили, что продолжим работу с теми участниками, чьи результаты будут наиболее читаемы.
Работа завертелась: кто-то молча собирал генератор на цепях Маркова, кто-то пробовал различные реализации с гитхаб, а большинство просто угарало в обсуждении и с пеной у рта убеждало нас, что из этой затеи ничего не получится. С этого началась техническая часть реализации проекта.
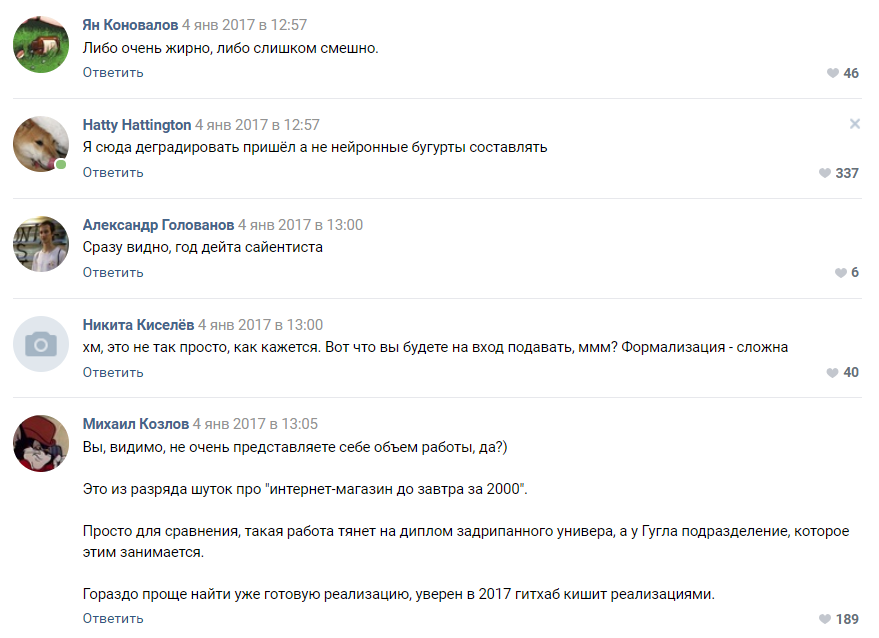
Некоторые предложения энтузиастов
Люди предлагали десятки вариантов по реализации:
- Цепи Маркова.
- Найти готовую реализацию чего-то похожего на GitHub и обучить её.
- Генератор рандомных фраз, написанный на Паскале.
- Завести литературного негра, который будет писать рандомный бред, а мы будем выдавать это за вывод нейросети.
Оценка сложности проекта от одного из подписчиков
Бóльшая часть комментаторов сходились во мнении, что наш проект обречен на провал и мы не дойдем даже до стадии прототипа. Как мы поняли позднее — люди до сих пор склонны воспринимать нейронные сети как какую-то черную магию, которая происходит в “голове у Цукерберга” и секретных подразделениях Google.
Часть 4. Выбор алгоритма, обучение и расширение команды
Через какое-то время запущенная нами кампания по краудсорсингу идей для алгоритма начала давать первые плоды. Мы получили около 30 работающих прототипов, бóльшая часть из которых выдавала абсолютно нечитаемый бред.
На этом этапе мы впервые столкнулись с демотивацией команды. Все результаты были очень слабо похожи на бугурты и чаще всего представляли собой абракадабру из букв и символов. Труды десятков энтузиастов шли прахом и это демотивировало как их, так и нас.
Лучше других себя показал алгоритм на базе pyTorch. Было принято решение взять за основу эту реализацию и алгоритм LSTM. Мы признали подписчика, который его предложил, победителем и начали работать над улучшением алгоритма совместно с ним. Наша распределенная команда увеличилась до четырех человек. Забавным фактом здесь является то, что победителю конкурса, как оказалось, было всего 16 лет. Победа стала его первым реальным призом в области Data Science.
Для первого обучения был арендован кластер из 7 графических карточек GXT1080

Консоль управления кластером карточек
Оригинальный репозиторий и все мануалы проекта Torch-rnn находится здесь:
github.com/jcjohnson/torch-rnn. Позже на её основе мы опубликовали свой репозиторий, в котором есть наши исходники, ReadMe по установке, а также сами готовые нейробугурты.
Первые несколько раз мы обучались при помощи преднастроенной конфигурации на платном кластере GPU. Настроить его оказалось не так сложно — достаточно инструкции от разработчика Torch и помощи администрации хостинга, которая входит в оплату.
Однако очень быстро мы столкнулись с трудностью: каждое обучение стоило времени аренды GPU — а значит, денег, которых в проекте попросту не было. Из-за этого в январе-феврале 2017 обучение мы проводили на купленных мощностях, а генерацию пытались запустить на своих локальных машинах.
Для обучения модели подходит любой текст. Перед обучением его необходимо препроцессить, для чего в Torch есть специальный алгоритм preprocess.py, который преобразует ваш my_data.txt в два файла: HDF5 и JSON:
Скрипт препроцессинга запускается так:
python scripts/preprocess.py \
--input_txt my_data.txt \
--output_h5 my_data.h5 \
--output_json my_data.json
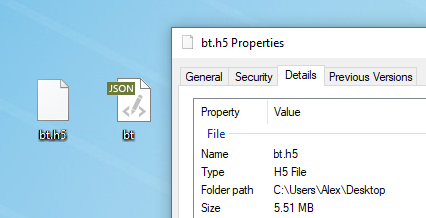
После препроцессинга появляются два файла, на которых в дальнейшем будет обучаться нейронная сеть
Различные флаги, которые можно менять на стадии препроцессинга, описаны здесь. Также есть возможность запускать Torch из Docker, но автор статьи её не проверял.
Обучение нейронной сети
После препроцессинга можно переходить к обучению модели. В папке с HDF5 и JSON нужно запустить утилиту th, которая появилась у вас, если вы правильно установили Torch:
th train.lua -input_h5 my_data.h5 -input_json my_data.json
Обучение занимает огромное количество времени и генерирует файлы вида cv/checkpoint_1000.t7, которые и являются “весами” нашей нейронной сети. Эти файлы весят впечатляющее количество мегабайт и содержат значения силы связей между конкретными буквами в вашем исходном датасете.
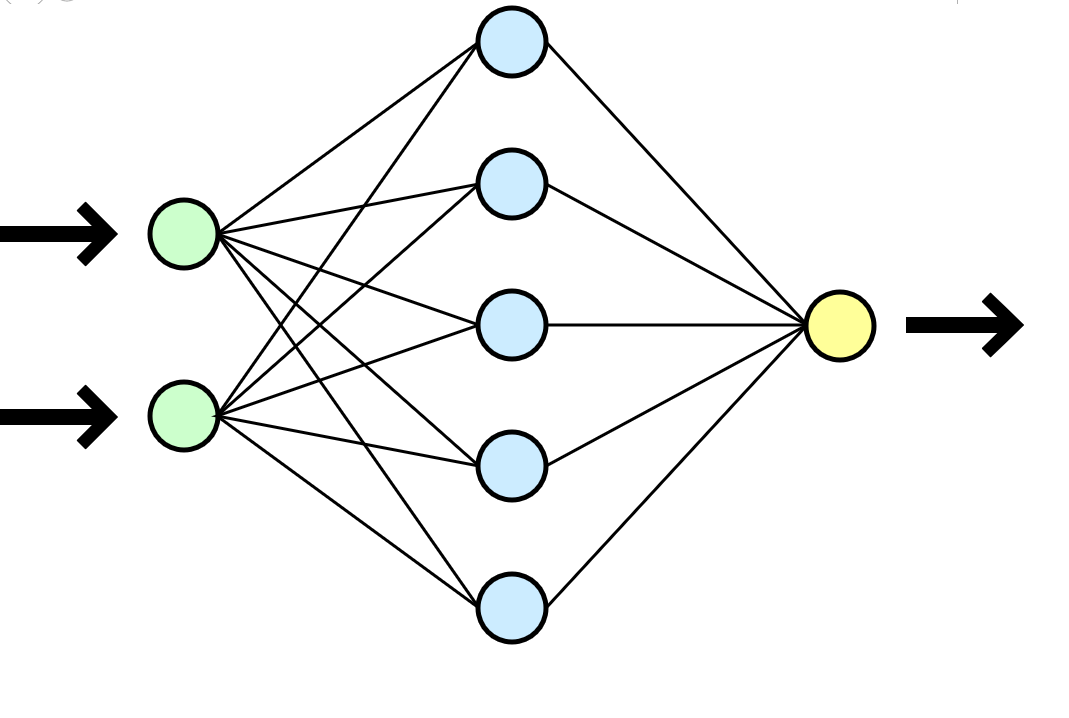
Нейронную сеть часто сравнивают с человеческим мозгом, но мне кажется гораздо более понятной аналогия с математической функцией, которая принимает параметры на входе (ваш датасет) и выдает результат (новые данные) на выходе.
В нашем случае каждое обучение на кластере из 7 GTX 1080 в дата-сете из 500 000 строк занимало около часа-двух, а аналогичное обучение на видавшем виды CPU i3-2120 занимало порядка 80-100 часов. В случае более долгих обучений нейросеть начинала жестко переобучаться — символы слишком часто повторяли друг друга, впадая в длиннющие циклы из предлогов, союзов и вводных слов.
Удобно, что можно выбрать частоту расстановки чекпоинтов и в ходе одного обучения сразу получить много моделей: от наименее обученных (checkpoint_1000) до переобученных (checkpoint_1000000). Хватило бы только места.
Генерация новых текстов
Получив хотя бы один готовый файлик с весами (checkpoint_*******) можно переходить к следующему и самому интересному этапу: начать генерировать тексты. Для нас это был настоящий момент истины, потому что впервые мы получили какой-то ощутимый результат — бугурт, написанный машиной.
К этому моменту мы окончательно перестали пользоваться кластером и все генерации проводили на своих маломощных машинах. Однако при попытке запуститься локально, просто пройти по инструкции и установить Torch у нас не получилось. Первым барьером стало использование виртуальных машин. На виртуальной Ubuntu 16 торч просто не взлетает — забудьте. На помощь часто приходил StackOverflow, но некоторые ошибки были настолько нетривиальны, что ответ удавалось найти только с огромным трудом.
Установка Torch на локальную машину застопорила проект на добрые пару недель: мы сталкивались со всевозможными ошибками установки многочисленных необходимых пакетов, а также боролись с виртуализацией (virtualenv .env) и в конечном итоге не стали её использовать. Несколько раз стенд сносился до уровня sudo rm -rf и просто устанавливался заново.
Использовав получившийся файл с весами мы смогли начать генерацию текстов на своей локальной машине:

Один из первых выводов
Часть 5. Очистка текстов
Еще одной очевидной трудностью стало то, что тематика постов очень сильно отличается, а наш алгоритм не предполагает никакого деления и рассматривает все 500 000 строк как единый текст. Мы рассматривали разные варианты по кластеризации датасета и даже были готовы вручную разбить корпус текстов по тематике или расставить теги в нескольких тысячах бугуртов (необходимый человеческий ресурс для этого был), но постоянно сталкивались с техническими трудностями подачи кластеров при обучении LSTM. Менять алгоритм и проводить конкурс заново показалось не самой здравой идеей с точки зрения тайминга проекта и мотивации участников.
Казалось, что мы в тупике — кластеризовать бугурты мы не можем, а обучения на едином огромном датасете давали сомнительный результат. Делать шаг назад и менять почти взлетевший алгоритм и реализацию тоже не хотелось — проект мог просто впасть в кому. В команде отчаянно не хватало знаний, чтобы решить ситуацию нормально, но на помощь пришла старая добрая СМЕ-КАЛ-ОЧК-А. Итоговое решение костыль оказалось до гениальности простым: в исходном датасете отделить имеющиеся бугурты друг от друга пустыми строками и обучить LSTM заново.
Мы расставили отбивки в 10 вертикальных пробелов после каждого бугурта, повторно провели обучение, а при генерации выставили ограничение на объем вывода в 500 символов (средняя длина одного “сюжетного” бугурта в исходном датасете).
Как было. Интервалы между текстами минимальны.
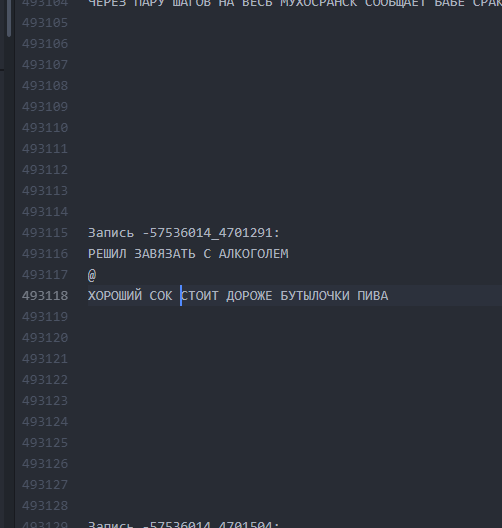
Как стало. Интервалы в 10 строк дают LSTM “понять”, что один бугурт закончился и начался другой.
Таким образом, удалось добиться того, что около 60% всех сгенерированных бугуртов стали обладать читаемым (хотя зачастую очень бредовым) сюжетом на всей длине бугурта от начала до конца. Длина одного сюжета составляла, в среднем, от 9 до 13 строк.
Часть 6. Повторное обучение
Прикинув экономику проекта, мы решили больше не тратить деньги на аренду кластера, а вложиться в покупку собственных карточек. Время на обучение бы выросло, но купив карточку один раз, мы могли бы генерировать новые бугурты постоянно. В тоже время часто проводить обучения постоянно уже не было необходимости.
Борьба с настройками на локальной машине
Часть 7. Балансировка результатов
На рубеже март-апрель 2017 мы повторно обучили нейронную сеть, уточнив параметры температуры и количество эпох обучения. В результате качество выходных текстов незначительно выросло.
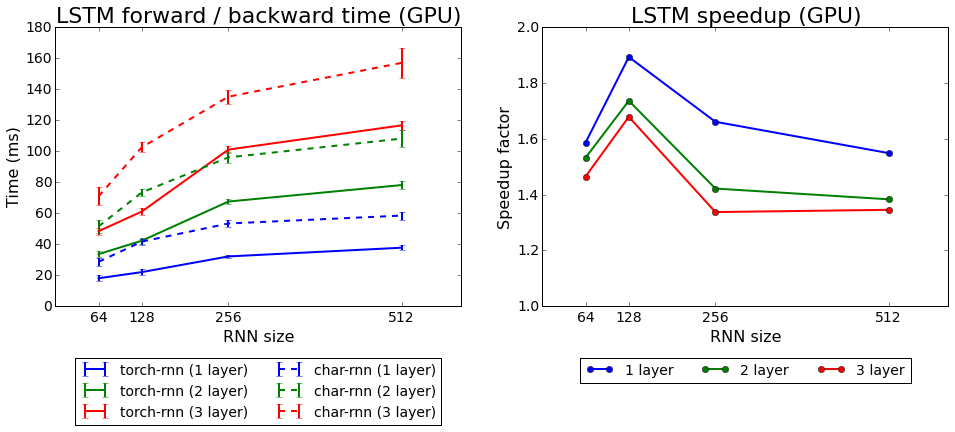
Скорость обучения torch-rnn в сравнении с char-rnn
Мы протестировали оба алгоритма, которые идут в комплекте с Torch: rnn и LSTM. Второй показал себя лучше.
Часть 8. Чего мы добились?
Первый нейробугурт был опубликован 17 января 2017 года — сразу после обучения на кластере — и в первый же день собрали больше 1000 комментариев.

Один из первых нейробугуртов
Нейробугурты так хорошо зашли аудитории, что стали отдельной рубрикой, которая на протяжении года выходила под хэштегом #нейробугурт и веселила подписчиков. В общей сложности в 2017 и начале 2018 года мы сгенерировали больше 18 000 нейробугуртов, в среднем по 500 символов в каждом. Кроме этого, появилось целое движение пабликов-пародий, участники которых изображали нейробугурты, рандомно переставляя фразы местами.

Часть 9. Вместо заключения
Этой статьей я хотел показать, что даже если у вас нет опыта в нейронных сетях, это горе не беда. Вам не нужно работать в Стэнфорде, чтобы делать простые, но интересные вещи с нейронными сетями. Все участники нашего проекта были обычными студентами со своими текущими задачами, дипломами, работами, но общее дело позволило нам довести проект до финала. Благодаря продуманной идее, планированию и энергии участников нам удалось получить первые вменяемые результаты меньше чем через месяц после окончательного формулирования идеи (большая часть технических и организационных работ пришлась на зимние каникулы 2017).
Более 18 000 бугуртов, сгенерированных машиной
Надеюсь, эта статья поможет кому-то спланировать свой собственный амбициозный проект с нейросетями. Прошу не судить строго, так как это моя первая статья на Хабре. Если вы, как и я, энтузиаст ML — давайте дружить.
Комментариев нет:
Отправить комментарий