Шучу. Главный страх админа при переводе инфраструктуры в облако — это потеря собственной важности. Почти все боятся, что перестанут быть незаменимыми. Это иллюзия. Важно не знание технологий, а знание компании и её устройства. Технологии быстро доучиваются.
Мы часто общаемся с админами наших клиентов. Вот что интересно: «сетевики» совершенно спокойно воспринимают новую инфраструктуру, а те, у кого акцент в работе был на железе, переучиваются долго. Точнее, дольше.
Потому что с момента начала виртуализации надо забыть половину того, что ты знаешь, и начать ботать сеть.
Если вы читали на ночь Олифера «Компьютерные сети» или книгу с таким же названием Таненбаума, то проблем не будет почти точно. Это когда-то было классикой админов в свитерах, а теперь стало классикой админов в галстуках.
Что случается при переезде
К админу приходит CIO или финдиректор (а иногда и учредитель) и говорит: так, дорогой друг, было приятно с тобой работать, но денег на апгрейд железа не дадим. Потому что это капитальные затраты, которые нашему бизнесу совершенно не нужны. Надо сделать так, чтобы деньги тратились по мере потребления ресурсов и в зависимости от количества этого потребления. Чтобы в высокий сезон можно было платить много, а в низкий — мало. Чтобы ничего не простаивало просто так.
Дальше в плохом случае админ прячется и дрожит, потому что масштаб изменений пугает. Во-первых, надо переехать чёрт знает куда и чёрт знает зачем со старой доброй инфраструктуры. Во-вторых, это всё — новые знания, которых часто нет. Всё вокруг непонятно, а в зоне ответственности — вообще работоспособность инфраструктуры.
Понятное дело, чаще случается чуть иначе. Опытные админы уже попробовали какую-то виртуализацию, имеют несколько развёрнутых инстансов в облаках (как правило, разных под разные задачи), но полный перенос делается медленно, поэтапно и с большим тестированием и чтением форумов. Собираются отзывы об облачном провайдере. Проходят переговоры, в ходе которых обе стороны пытаются понять, где подвох.
Потом наступает переезд. С учётом современных реалий, скорее всего, он неизбежен, хотя ряд компаний (например, оборонка) от этого застрахованы.
Что можно забыть
- Совместимость и «зоопарки». IaaS призвана облегчить жизнь админу. Ему не нужно заморачиваться по поводу выбора железа, совместимости. Как у него вот это железо от одного производителя будет работать с железом другого производителя. Не будет проблем. Все эти вопросы решает облако. Оператор облака берёт на себя все вопросы по совместимости. Работать будет оптимально.
- Апгрейд. Не нужно брать инфраструктуру с запасом, не нужно долго согласовывать счета, не надо сильно заранее (за год) думать про устаревание железа. Не нужно дружить старые куски инфраструктуры с новыми.
- Управление серверным железом. Всё это переходит на программный уровень и управляется из консоли. Не надо думать про прошивки сетевых устройств. Не нужна диагностика аппаратных сбоев: проблемы решаются оператором. Обычно админ имеет эникейщика для работы с железом на рабочих станциях, но сам занимается серверным парком. Эникея менять память в сервере пускать крайне опасно. Поддержка облачного провайдера забирает всё это на себя.
- При частичных переездах часто предоставляется услуга «сделайте мне мои сети, только в облаке». Можно сделать так, что часть серверов останется аппаратной, часть виртуальной и они будут в одной сети. Как физически, только не совсем физически.
- Ещё одна масштабная вещь — это обучение. Если у вас не ноунейм, а что-то вроде HP или Dell, то надо либо покупать поддержку, либо обучаться у вендоров. Либо искать спецов, когда приспичит.
- Можно почти забыть про резервное копирование и его особенности в организации. Все виртуальные машины в облаке могут быть скопированы по расписанию, которое задаёт админ. Главное — не забыть создать это расписание. Можно копировать ВМ целиком, можно определённые элементы типа баз данных.
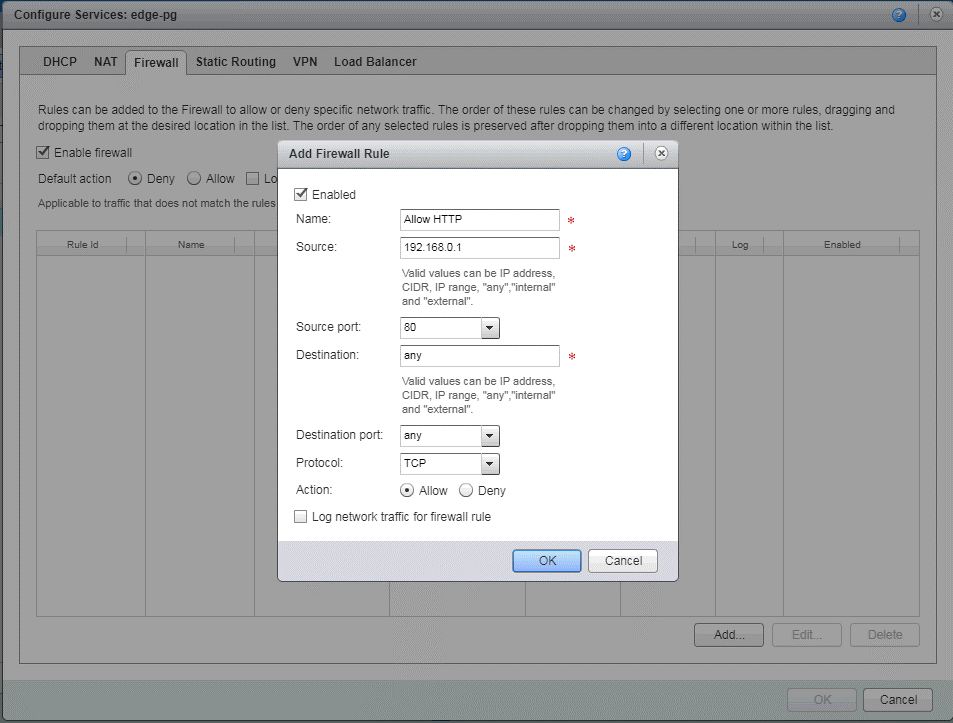
- Нет проблем с аппаратными файрволлами. Появляются программные (у нас — NSX Edge), а они по сложности настройки сравнимы с домашним роутером. При этом, несмотря на низкий порог входа, умеют они много: несколько видов VPN, NSX EDGE может через себя балансировать нагрузку внутри сети. Умеет BGP, OSPF и так далее.
- Не надо гонять в магазин за дисками. От одного из новых клиентов слышали такую историю: когда у них кончалось дисковое пространство, они бегали в магазин с наличкой покупать адаптеры и диски. А это всё делается за неделю, потому что нужно техническое окно на даунтайм в выходные. В IaaS такие задачи решаются без выключения машины за несколько секунд. «Вот этот диск на терабайт больше» — клик, и всё, раздвигаешь партицию.
- Не надо держать запчасти и расходники (для серверного парка).
- Можно забыть о проблемах с коммутацией оборудования. Переключение серверов в стойке в разные сети руками уже не надо.
- Нет проблемы с питанием в здании и его резервированием. Нет проблем с охлаждением. Контролем физического доступа. В общем, все плюшки дата-центров вы и так знаете.
Что придётся учить
- Сеть. Стандартные вещи, в целом сегодня этого достаточно. Просто кто такой IP, зачем нужна маска подсети, как работает маршрутизация в сети, как примерно работает DNS, что есть DHCP… Облако — это сетевой сервис. По опыту, примерно половине переезжающих к нам из среднего бизнеса не хватает основ. Вот книги сверху поста идеально решают задачу. Углубляться не надо: если понять хотя бы 20%, будет уже хорошо для первых шагов. DHCP ставится «одной галочкой». А ещё *nix-админы пару раз попадались на том, что наши политики не позволяют подменять MAC-адреса на виртуальных машинах.
- Безопасность. Здесь наболевшее — просто мало кто выделяет DMZ для серверов. Часто бывают косо настроены файрволлы, мы проводим регулярные ликбезы. Если админ знает стек TCP/IP, проблемы нет.
- Интерфейс облака. Придётся с ним подружиться. Проблемы реже возникают у хардкорных *nix-админов, чаще — у тех, кто живёт в стеке Windows. Нет, тот же EDGE, конечно, Linux. Но он там теперь по-настоящему user frienly. It's just picky about who its friends are. Сегодня выглядит так: создаёшь виртуальную машину, подключаешь сети, назначаешь адреса, пишешь правила сетевого экрана для доступа виртуальной машины наружу и для доступа извне к виртуальной машине. Всё.
- Очень много придётся учить СХД. И не физическое обслуживание, а именно логическое. До этого чаще всего у админа был опыт по полкам с RAID-массивами. Возможно, был какой-то SAN, но это вообще отдельный мир. Не зря стораджисты уходят в отдельную ветку прокачки: в крупных организациях почти всегда есть отдельный стораджист. Называется «администратор систем хранения данных» — он админит сеть и сами системы хранения. В среднем и малом бизнесе часто приходит человек, который настроил у себя NetApp, HP 3Par или вообще гордый бренд Noname. Что досталось, то и изучили: это вторичный рынок железок после апгрейдов из больших компаний. А каждая СХД — это свой интерфейс, свои системы управления, свой мониторинг. Админы заранее сильно думают, куда и что размещать: какие данные на SSD, какие на медленные диски. В случае, если он сразу запланировал неверно, потом будет плохо. Миграция данных с одного типа носителей на другой — это настоящая боль. В физике — это всегда остановка связи. А в облаке — перевод данных с одного типа носителя на другой в три клика. В момент копирования сервис предоставляется. Занимает процесс чуть больше, чем время на само копирование.
В целом в облачном хранении всё происходит относительно элементарно. Всё, что админ знал на уровне дисков и ОС, остаётся. Как в организации используют диски внутри ОС, так и будут. А аппаратная часть — представление дисков внутрь ВМ — задача провайдера.

С другими устройствами хранения в облаке тоже обычно нет проблем. Часто беспокоятся про подключение флешек с USB-ключами., USB-хаб обеспечивает проброс ключей до ВМ. Машина может быть на любом узле, и ключ будет направлен к ней.
- Нужно очень хорошо понимать, как работают объектные хранилища, например S3. Хорошо знать про распределённые файловые системы. Потренироваться на кошках — можем дать тест у нас, можно учиться на Амазоне, но S3 — это уже промышленный стандарт, и почти все его поддерживают.
- Надо немного разобраться с гипервизором. Глубоко лезть не надо. Современные версии накладывают оверхед около 1% на производительность: и софт виртуализации эти годы менялся, и ОС, и железо под требования облачности. Результат — прослойка гипервизора почти не чувствуется. Какой именно гипервизор используется, по большому счёту важно только провайдеру.
- Подучить лицензирование. При переезде надо учитывать особенности лицензий прикладного ПО.
- Подучить способы переезда. Чаще всего мы помогаем, но разбираться не помешает. Оптимальная ситуация — мы забираем всё через сеть, у нас каналы широкие. Реже случается — если у клиента проблемы, — что надо везти на дисках в офис или ЦОД, мы обеспечим доступность в облаке.
- Мониторинг — акцент не на инфраструктуре, а на доступности приложений. Как правило, первый достаточный уровень — это просто перезапуск ВМ при проблемах с приложением, дальше уже собственный опыт.
Ещё особенности
Нас часто спрашивают про резерв по мощностям, нужно ли это делать. В нашем видении мира это полностью задача облачного провайдера. Например, мы никогда не загружаем серверы больше определённого процента, иначе при потере серверов не сможем гарантировать перезапуск ВМ на оставшихся. Мы можем вывести из эксплуатации не меньше двух серверов в каждом кластере. И при этом сохраним полную отказоустойчивость.
Второй частый вопрос — про переезд легаси. Win95 можно запустить, даже, скорее всего, софт заработает. Хотя она не поддерживается MS. И Win98 не поддерживается MS. И WinXP не поддерживается. Но в теории запускается, правда, есть особенности со специфическим ПО — вначале надо всегда тестировать. Менее популярные ОС, такие как FreeBSD и Solaris, через гипервизор работают. У нас даже получалось запуститься, причём часто проще, чем с несвежими дистрибутивами Linux. Кстати, возможно, админу надо будет почитать и подумать про другой вопрос: операционка может вносить в среде виртуализации задержки, если она старая и не оптимизированная для виртуализации. Был проект, который с Дебиана старого переехал на Убунту новую, заработало. Физические машины на популярных ОС можно отконвертировать в виртуальные машины при помощи конвертера.
Что ещё прочитать
Моё личное мнение — стоит посмотреть:
- Эндрю Таненбаум, Дэвид Уэзеролл. Компьютерные сети.
- Виктор Олифер, Наталия Олифер. Компьютерные сети. Принципы, технологии, протоколы.
- Михаил Михеев. Администрирование VMware vSphere 5.
- vCloud Director User's Guide.
Плюс вот это: про тех, кому вообще не надо переезжать в облако, про типичные ошибки переезда, ну и про ликбезы.
Комментариев нет:
Отправить комментарий