
Свойства простых чисел редко позволяют работать с ними иначе, чем в виде заранее вычисленного массива — и желательно как можно более объемного. Естественный формат хранения в виде целых чисел той или иной разрядности страдает при этом некоторыми недостатками, которые становятся существенными при росте объема данных.
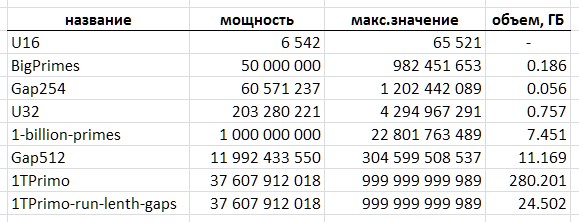
Так, формат 16-разрядных беззнаковых целых при размере такой таблицы около 13 килобайт вмещает всего лишь 6542 простых числа: вслед за числом 65531 идут значения более высокой разрядности. Такая таблица годится разве что в качестве игрушки.
Наиболее ходовой в программировании формат 32-разрядных целых выглядит значительно солиднее — он позволяет хранить около 203 млн простых. Но такая таблица занимает уже около 775 мегабайт.
Еще больше перспектив у 64-разрядного формата. Однако при теоретической мощности порядка 1e+19 значений, таблица имела бы размер 64 экзабайта.
Не очень-то верится, что наше прогрессивное человечество когда-либо в обозримом будущем рассчитает таблицу простых чисел такого объема. И дело тут не столько в объемах даже, сколько в счетном времени алгоритмов, которые имеются в наличии. Скажем, если таблицу всех 32-разрядных простых еще можно рассчитать самостоятельно за несколько часов (рис. 1), то для таблицы хотя бы на порядок большей уйдет уже несколько дней. А ведь такие объемы нынче — это лишь начальный уровень.
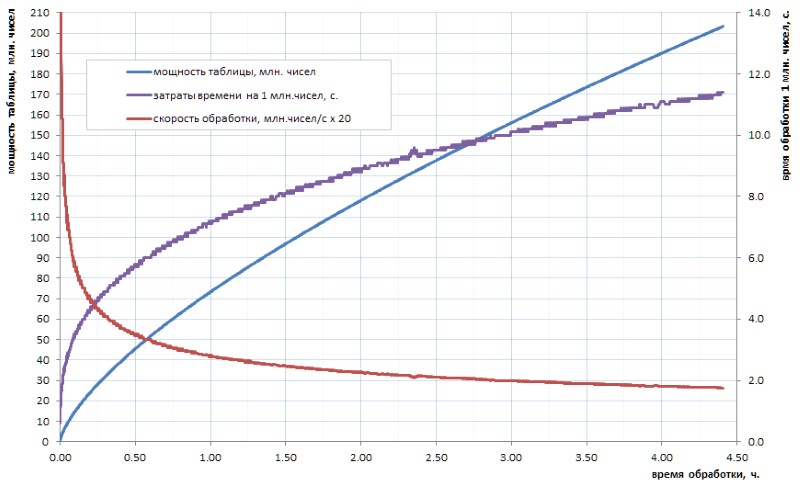
Как видно из диаграммы, удельное время вычисления после стартового рывка плавно переходит в асимптотический рост. Он довольно медленный. но это — рост, а значит майнинг каждой очередной порции данных с течением времени будет даваться все труднее и труднее. При желании осуществить какой-то существенный прорыв, придется распараллеливать работу по ядрам (а она неплохо распараллеливается) и вешать ее на суперкомпьютеры. С перспективой получить первые 10 миллиардов простых через неделю, а 100 миллиардов — лишь через год. Безусловно, есть более скоростные алгоритмы расчета простых, нежели тривиальный перебор, использованный в моей домашней заготовке, но, по существу, дела это не меняет: через два-три порядка ситуация становится сходной.
Стало быть, неплохо было бы, однажды проведя счетную работу, хранить ее результат в уже готовом табличном виде, и использовать по мере надобности.
Ввиду очевидности идеи в сети попадается множество ссылок на готовые списки простых чисел, уже кем-то предварительно вычисленные. Увы, в большинстве они годятся они разве что для студенческих поделок: один такой, к примеру, кочует с сайта на сайт и включает 50 млн. простых. Это количество может поразить воображение только непосвященных: выше уже упоминалось, что на домашнем компьютере за несколько часов можно самостоятельно рассчитать таблицу всех 32-разрядных простых, а она в четыре раза больше. Наверно лет 15-20 назад такой список действительно был героическим достижением для непрофессионального сообщества. Нынче, в век многоядерных многогигагерцовых и многогигабайтных девайсов, это уже не впечатляет.
Мне повезло получить по знакомству доступ к куда более представительной таблице простых, которую я далее буду использовать в качестве иллюстрации и жертвы для своих натурных экспериментов. В целях конспирации назову ее 1TPrimo. В ней представлены все простые числа меньше триллиона.
На примере 1TPrimo легко увидеть, с какими объемами приходится иметь дело. При мощности около 37.6 миллиардов значений в формате 64-разрядных целых этот список занимает 280 гигабайт. Кстати — на ту его часть, что могла бы уложиться в 32 разрядах, приходится всего лишь 0.5% количества представленных в нем чисел. Откуда абсолютно становится понятно, что любые серьезные работы с простыми числами с неизбежностью стремятся к тотальной 64-битовой (и более) разрядности.
Таким образом, мрачная тенденция очевидна: сколь-нибудь серьезная таблица простых чисел неизбежно имеет титанический объем. И с этим надо как-то бороться.
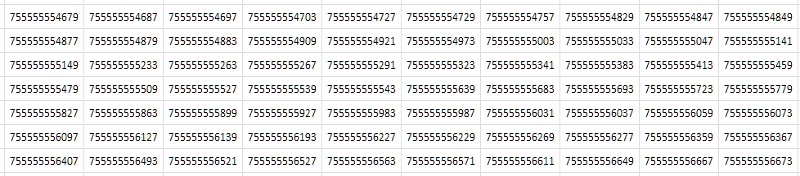
Первое, что приходит в голову при разглядывании таблицы (рис.2) — что она состоит из почти одинаковых подряд идущих значений, различающихся лишь в одном-двух последних десятичных разрядах:
Просто, из самых общих, отвлеченных соображений: если в файле много повторяющихся данных, то он должен хорошо сжиматься архиватором. Действительно, компрессия таблицы 1TPrimo популярной утилитой 7-zip при стандартных настройках дало довольно высокий коэффициент компрессии: 8.5. Правда, время обработки — при огромном размере исходной таблицы — на 8-ядерном сервере, при средней загрузке всех ядер порядка 80-90% составило 14 часов 12 минут. Универсальные алгоритмы компрессии рассчитаны на некие абстрактные, обобщенные представления о данных. В некоторых частных случаях специализированные алгоритмы компрессии, построенные на известных особенностях входящего набора данных, могут продемонстрировать гораздо более эффективные показатели, чему и посвящена данная работа. А насколько эффективные — станет понятно ниже.
Близкие численные значения соседних простых чисел напрашиваются на решение хранить не сами эти значения, а интервалы (разности) между ними. При этом можно получить существенную экономию за счет того, что разрядность интервалов гораздо ниже разрядности исходных данных (рис.3).
И вроде бы она никак не зависит от разрядности генерирующих интервал простых. Перебор «на глазок» демонстрирует, что типичные значения интервалов для простых чисел, взятых из самых разных мест таблицы 1TPrimo, лежат в пределах единиц, десятков, изредка сотен, и — в качестве первого рабочего предложения — вероятно могли бы уложиться в диапазон 8-битных беззнаковых целых, т.е., байтов. Это было бы очень удобно, а в сравнении с 64-разрядным форматом это разом привело бы к 8-кратной компрессии данных — как раз где-то на уровне, продемонстрированном архиватором 7-zip. Причем простота алгоритмов компрессии и декомпрессии по идее должна капитально сказаться на скорости как сжатия, так и доступа к данным по сравнению с 7-zip. Звучит заманчиво.
При этом абсолютно понятно, что данные, преобразованные из своих абсолютных значений в относительные интервалы между ними, пригодны только для восстановления серий значений, идущих подряд от самого начала таблицы простых чисел. Зато если к такой таблице интервалов добавить минимальную блочно-индексную структуру, то при незначительных дополнительных накладных расходах это позволит восстанавливать — но уже поблочно — и элемент таблицы по его номеру, и ближайший элемент по произвольно заданному значению, а эти операции — вкупе с основной операцией выборки последовательностей — в общем-то исчерпывает львиную долю возможных запросов к таким данным. Статистическая обработка, безусловно, усложнится, но все же и она останется достаточно прозрачной, т.к. никакой особой хитрости в том, чтобы при обращении к требуемому блоку данных восстанавливать его «на лету» из имеющихся интервалов, нет.
Но увы. Простой численный эксперимент над данными 1TPrimo показывает, что уже в конце третьего десятка миллионов (это менее сотой процента объема 1TPrimo) — и далее везде — интервалы между соседними простыми регулярно выходят за пределы диапазона 0..255.
Тем не менее, чуть усложненный численный эксперимент выявляет, что рост максимального интервала между соседними простыми с ростом самой таблицы идет очень и очень медленно — а значит идея все-таки в чем-то хороша.
Второй, более пристальный взгляд на таблицу интервалов подсказывает, что можно хранить не саму разность, а ее половину. Поскольку все простые числа больше 2 заведомо нечетные, соответственно их разности — заведомо четные. Соответственно, разности могут быть без потери значения сокращены на 2; а для полноты из полученного частного можно еще единицу вычесть, чтобы с пользой утилизировать невостребованное в ином случае нулевое значение (рис.4). Такое приведение интервалов буду называть в дальнейшем монолитным, в отличие от рыхлого, пористого начального вида, в котором оказались невостребованными все нечетные значения и ноль.
Следует отметить, что поскольку интервал между первыми двумя простыми (2 и 3) не вписывается в эту схему, то 2 придется из таблицы интервалов исключить и все время держать этот факт в уме.
Этот нехитрый прием позволяет в диапазоне значений 0..255 закодировать интервалы от 2 до 512. Вновь оживает надежда, что метод разностей таки позволит упаковать гораздо более мощную последовательность простых чисел. И верно: прогон 37.6 миллиардов значений, представленных в списке 1TPrimo, выявил всего лишь 6 (шесть!) интервалов, которые не входят в диапазон 2..512.
Но это была хорошая новость; плохая же состоит в том, что эти шесть интервалов рассеяны по списку весьма привольно, и первый из них встречается уже в конце первой трети списка, обращая остальные две трети в непригодный для данного метода компрессии балласт (рис.5):
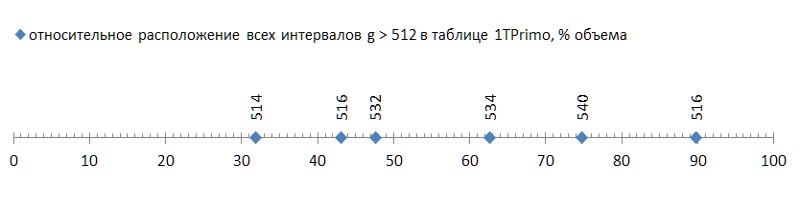
Такую заподлянку (каких-то несчастных шесть штук на почти сорок миллиардов! — и на тебе...) даже с ложкой дегтя сравнить — честь дегтю выказать. Но увы, это — закономерность, а не несчастный случай. Если проследить первое появление интервалов между простыми в зависимости от разрядности данных, становится ясно, что это явление кроется в генетике простых чисел, хотя прогрессирует оно крайне медленно (рис.6 *).
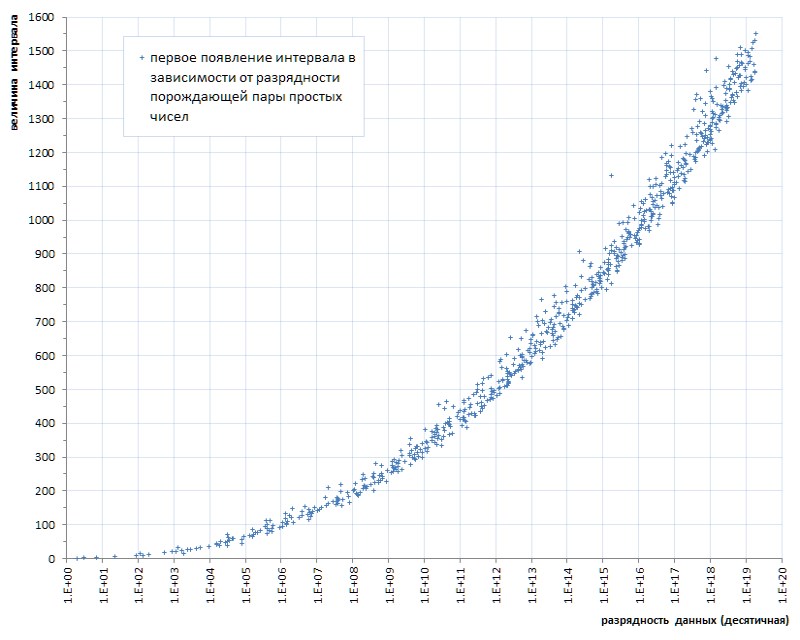
* График составлен по данным тематического сайта Томаса Р. Найсли,
которые на несколько порядков превосходят мощность списка 1TPrimo
Но и этот весьма медленный прогресс однозначно намекает: ограничиться какой-то наперед заданной разрядностью интервала можно только на некоторой наперед заданной мощности списка. То есть, не годится в качестве универсального решения.
Впрочем, и то, что предложенный метод компрессии последовательности простых чисел позволяет реализовать несложную компактную таблицу мощностью почти в 12 млрд. значений — уже вполне себе результат. Такая таблица занимает объем 11.1 гигабайт — против 89.4 гигабайт в тривиальном 64-разрядном формате. Наверняка для ряда приложений такое решение может оказаться достаточным.
И что интересно: процедура трансляции 64-разрядной таблицы 1TPrimo в формат 8-разрядных интервалов с блочной структурой, при использовании только одного процессорного ядра (для распараллеливания пришлось бы прибегнуть к существенному усложнению программы, и оно абсолютно того не стоило) и не более чем 5% нагрузки процессора (основное время уходило на файловые операции) заняло всего лишь 19 минут Против — напомню — 14 часов на восьми ядрах при 80-90% загрузке, затраченных архиватором 7-zip.
Разумеется, данной трансляции была подвергнута только первая треть таблицы, в которой диапазон интервалов не превосходит значение 512. Поэтому, если привести полные 14 часов к той же трети, то 19 минут надо сравнивать против почти 5 часов работы архиватора 7-zip. При сопоставимой величине компрессии (8 и 8.5) разница — примерно в 15 раз. С учетом, что львиную долю рабочего времени программы трансляции заняли файловые операции, на более быстрой дисковой системе разница была бы еще круче. А по уму время работы 7-zip на восьми ядрах следовало бы еще пересчитать на один поток, и тогда сравнение станет действительно адекватным.
Выборка же из такой базы данных очень мало отличается по времени от выборки из таблицы неупакованных данных и почти целиком определяется временем файловых операций. Конкретные цифры сильно зависят от конкретного железа, на моем сервере в среднем на доступ к произвольному блоку данных уходило 37.8 мкс, при последовательном чтении блоков — 4.2 мкс на блок, на полную распаковку блока — менее 1 мкс. То есть, сравнивать распаковку данных с работой стандартного архиватора вообще не имеет смысла. И это — большой плюс.
И, наконец, проведенные наблюдения предлагают еще одно, третье решение, снимающее любые ограничения по мощности данных: кодирование интервалов значениями переменной длины. Этот прием давно и широко используется в приложениях, связанных с компрессией. Его смысл в том, что если во входных данных обнаруживается, что какие-то значения попадаются часто, какие-то — реже, а какие-то — совсем редко, то мы можем закодировать первые — короткими кодами, вторые — кодами подлиннее, а третьи — совсем длинными (возможно даже очень длинными, т.к. это неважно: все равно такие данные встречаются совсем редко). В результате суммарная длина полученных кодов может оказаться значительно короче входных данных.
Уже глядя на график появления интервалов на рис.7 можно сделать предположение, что коли уж интервалы 2, 4, 6 и т.д. появляются раньше интервалов, скажем, 100, 102, 104 и т.д., то и дальше первые должны встречаться значительно чаще вторых. И наоборот — если интервалы 514 попадаются лишь начиная с 11.99 миллиардного значения, 516 — начиная с 16.2 миллиардного, а 518 — вообще начиная лишь с 87.7 миллиардного значения, то и дальше они будут попадаться очень редко. То есть, априори можно предположить обратную зависимость между величиной интервала и его частотностью в последовательности простых чисел. А значит — можно сконструировать простую структуру, реализующую для них коды переменной длины.
Определяющим для выбора конкретного способа кодирования должна стать, естественно, статистика частотности интервалов. Благо, в отличие от произвольных данных, частотность интервалов между простыми числами — которые и сами-то по себе являются жестко детерминированной, раз и навсегда заданной последовательностью — также является жестко детерминированной, раз и навсегда определенной характеристикой.
На рис.7 приведена частотная характеристика интервалов для всего списка 1TPrimo:
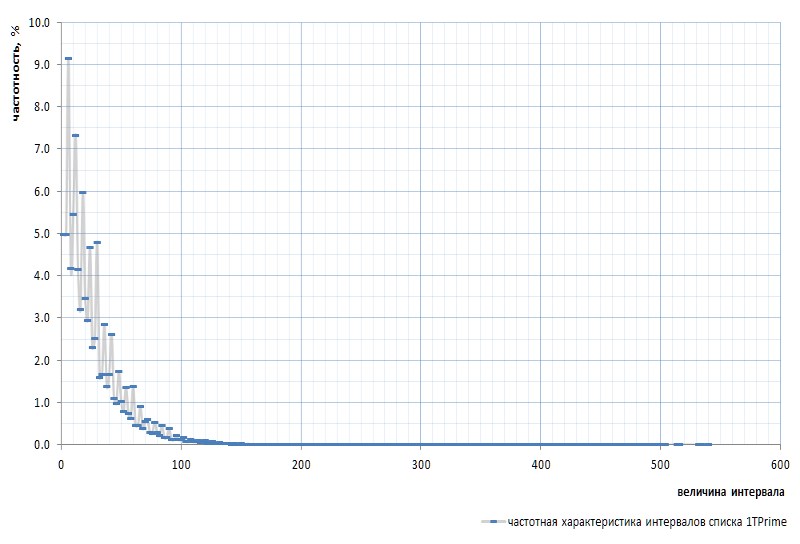
Здесь надо снова упомянуть, что из графика исключен интервал между самыми первыми простыми 2 и 3: этот интервал равен 1 и встречается в последовательности простых ровно один раз, независимо от мощности списка. Этот интервал настолько своеобычен, что проще убрать 2 из списка простых, чем постоянно сбиваться на оговорки. Сим объявляется, что число 2 является виртуальным простым: в списках его не видно, но оно там есть. Как тот суслик.
На первый взгляд график частотности полностью подтверждает априорное предположение, приведенное парой абзацев выше. На нем хорошо видна статистическая неоднородность интервалов и высокая частотность малых значений по сравнению с большими. Однако на второй, более выпуклый взгляд, график оказывается куда интереснее (рис.8):
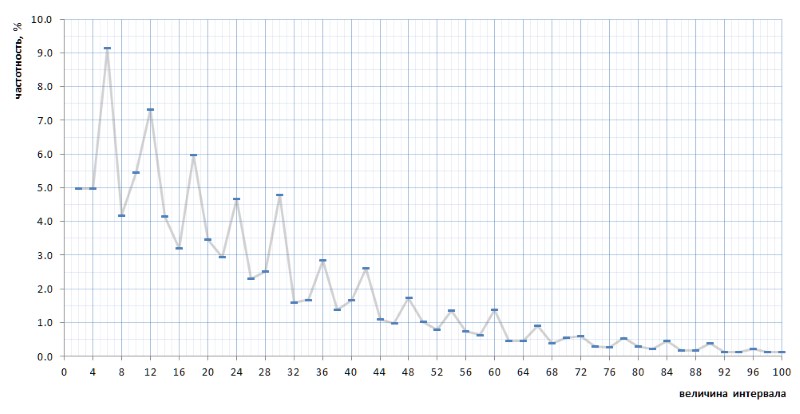
Довольно неожиданно оказывается, что самыми часто встречающимися интервалами являются не 2 и 4, как это вроде бы представлялось из общих соображений, а 6, 12 и 18, за ними 10 — и только потом 2 и 4 с практически равной частотностью (различие в 7 знаке после запятой). Причем и далее кратность пиковых значений числу 6 прослеживается на протяжении всего графика.
Еще интереснее то, что этот нечаянно выявленный характер графика является универсальным — причем, во всех подробностях, со всеми его изломами — по всей последовательности интервалов простых, представленных списком 1TPrimo, и есть вероятность, что он универсален вообще для любой последовательности интервалов простых (конечно, столь смелое утверждение нуждается в доказательствах, кои я с огромным удовольствием перелагаю на плечи специалистов в теории чисел). На рис.10 представлено сравнение полной статистики интервалов (линия алого цвета) с ограниченными выборками интервалов, взятыми в нескольких произвольных местах списка 1TPrimo (линии других цветов):
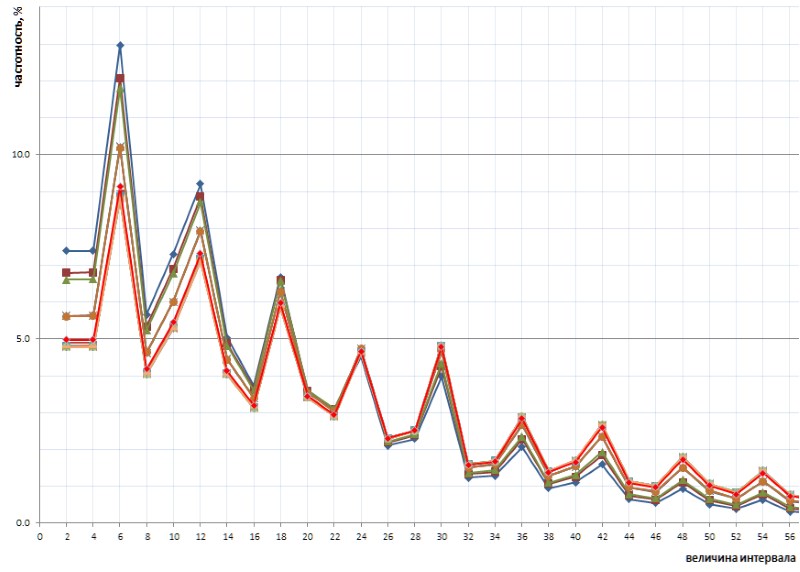
Из этого графика видно, что все эти выборки повторяют друг друга в точности, с небольшим лишь различием в левой и правой частях рисунка: они словно слегка повернуты против часовой вокруг точки интервала с значением 24. Этот поворот вероятно объясняется тем, что более высокие в левой части графики построены на выборках с меньшей разрядностью. В таких выборках еще нет вовсе, или редки большие интервалы, которые становятся частыми в выборках с большей разрядностью. Соответственно, их отсутствие сказывается в пользу частотности интервалов с меньшими значениями. В выборках с большей разрядностью появляется много новых интервалов с большими значениями, поэтому частотность меньших интервалов несколько снижается. Вероятнее всего и точка поворота, при увеличении мощности списка, будет смещаться в сторону больших значений. Где-то там же рядышком находится и точка равновесия графика, где сумма всех значений справа примерно равна сумме всех значений слева.
Этот занятный характер частотности интервалов предлагает отказаться от тривиальной структуры кодов переменной длины. Обычно такая структура состоит из пакета битов различной длины и назначения. К примеру сначала идет какое-то количество бит префикса, установленных в определенное значение, например, в 0. За ними идет стоповый бит, который должен обозначить завершение префикса, и, соответственно, должен отличаться от префикса: 1 в данном случае. Префикс может не иметь никакой длины, то есть, раз за разом выборка может начинаться сразу со стопового бита, определяя таким образом самую короткую последовательность. За стоповым битом обычно идет суффикс, длина которого каким-либо заранее оговоренным образом определяется длиной префикса. Он может быть равен длине префикса, может быть в заданное число раз длиннее, либо зависимость может быть прогрессивной — выбор определяется как раз частотными характеристиками входных данных. Поскольку длина суффикса уже определена префиксом, биты суффикса могут иметь любое значение и что-то собою обозначать. Тем самым суффикс каким-то заранее заданным образом (табличным, расчетным, каким-то другим) определяет значение, которое следует восстановить из разобранного по частям пакета битовых последовательностей.
В нашем случае выявленная цикличность частотной характеристики позволяет дополнить вышеописанную структуру еще одним довеском, отражающим данную цикличность.
И здесь следует заявить еще одну важную вещь. На первый взгляд наблюдаемая цикличность подразумевает деление интервалов на тройки: {2,4,6}, {8,10,12}, {14,16,18} и так далее (жирным шрифтом выделены значения, имеющие максимальную частотность в каждой тройке). Однако на самом деле цикличность здесь чуть иная.
Не стану приводить весь ход рассуждений, коих, собственно, и нет: это была интуитивная догадка, дополненная методом тупого перебора вариантов, вычислений и проб, занявших с перерывами несколько дней. Выявленная в итоге цикличность состоит из шестерок интервалов {2,4,6,8,10,12}, {14,16,18,20,22,24}, {26,28,30,32,34,36} и так далее (жирным снова выделены интервалы максимальной частотности).
В двух словах предлагаемый алгоритм упаковки состоит в следующем.
Деление интервалов на шестерки четных чисел позволяет представить любой интервал g в виде g = i * 12 + t, где i — индекс шестерки, в которую входит данный интервал (i = {0,1,2,3, ...}) а t — охвосток, представляющий одно из значений из жестко заданного, ограниченного и одинакового для любой шестерки множества {2,4,6,8,10,12}. Частотная характеристика выделенного выше индекса практически в точности обратно пропорциональна его значению, поэтому индекс шестерки логично преобразовать в тривиальную структуру кода переменной длины, пример которой приведен выше. Частотные характеристики охвостка позволяют разделить его на две группы, которые можно кодировать битовыми цепочками разной длины: значения 6 и 12, которые встречаются чаще всего, кодировать одним битом, значения 2, 4, 8 и 10, которые встречаются существенно реже, кодировать двумя битами. Разумеется понадобится и еще один бит, позволяющий различать эти два варианта.
Массив, содержащий битовые пакеты дополняется фиксированными полями, задающими стартовые значения данных, представленных в блоке, и другие величины, требующиеся для восстановления произвольного простого или последовательности простых из хранимых в блоке интервалов.
Помимо этой блочно-индексной структуры, использование кодов переменной длины осложняется дополнительными издержками по сравнению с интервалами фиксированной разрядности.
При использовании интервалов фиксированного размера определение блока, в котором следует искать простое число по его порядковому номеру, достаточно простая задача, поскольку наперед известно количество интервалов, приходящихся на каждый блок. А вот поиск простого по ближайшему значению прямого решения не имеет. Как вариант можно использовать какую-либо эмпирическую формулу, позволяющую найти приблизительный номер блока с требуемым интервалом, после чего придется выполнить поиск нужного блока путем перебора.
Для таблицы с кодами переменной длины такой же подход требуется для обеих задач: и для выборки значения по номеру, и для поиска по значению. Поскольку длина кодов меняется, никогда наперед не известно, сколько разностей хранится в любом конкретном блоке, и в каком блоке лежит нужное значение. Опытным путем было определено, что при размере блока 512 байт (в которые входит и сколько-то байт заголовка) емкость блока может гулять на 10-12 процентов от средней величины. Блоки меньшего размера дают еще больший относительный разброс. При этом и сама средняя величина емкости блока имеет тенденцию к медленному снижению по мере роста таблицы. Подбор эмпирических формул для неточного определения начального блока для поиска нужного значения как по номеру, так и по величине, является нетривиальной задачей. Как вариант можно использовать более сложную и изощренную индексацию.
Вот, собственно, и все.
Ниже тонкости компрессии таблицы простых чисел с использованием кодов переменной длины и связанные с ней структуры описаны более формально и подробно, приведен код функций упаковки и распаковки интервалов на языке Си.
Итог.
Объем данных, транслированных из таблицы 1TPrimo в коды переменной длины, дополненные блочно-индексной структурой, также описанной ниже, составил 26,309,295,104 байт (24.5Гб), то есть, коэффициент компрессии достигает значения 11.4. Очевидно, что с ростом разрядности данных коэффициент компрессии будет расти.
Время трансляции 280 Гб таблицы 1TPrimo в новый формат составило 1 час. Это ожидаемый результат после экспериментов с упаковкой интервалов в однобайтные целые. В обоих случаях трансляция исходной таблицы состоит преимущественно из файловых операций и почти не загружает процессор (во втором случае нагрузка все-таки выше в силу более высокой счетной сложности алгоритма). Время доступа к данным также не сильно отличается от однобайтных интервалов, но время распаковки полного блока такого же размера заняло 1.5 мкс, в силу более высокой сложности алгоритма извлечения кодов переменной длины.
В таблице (рис.10) сведены объемные характеристики упомянутых в данном тексте таблиц простых чисел.
Описание алгоритма компрессии
Термины и обозначения
P (prime): P1=3, P2=5, P3=7 ... Pn, Pn1 — простые числа по их порядковым номерам. Еще раз (и в последний раз) подчеркну, что P0=2 является виртуальным простым числом; ради формального единообразия физически из списка простых это число исключено.
G (gap) — интервал между двумя последовательными простыми числами Gn = Pn1 - Pn; G={2,4,6,8 ...}.
D (dense) — приведенный к монолитному виду интервал: D = G/2 -1; D={0,1,2,3 ...}. Шестерки интервалов в приведенном к монолитному виду выглядят как {0,1,2,3,4,5}, {6,7,8,9,10,11}, {12,13,14,15,16,17} и т.д.
Q (quotient) — индекс приведенной к монолитному виду шестерки, Q = D div 6; Q={0,1,2,3 ...}
R (remainder) — остаток монолитной шестерки R = D mod 6. R всегда имеет значение в интервале {0,1,2,3,4,5}.
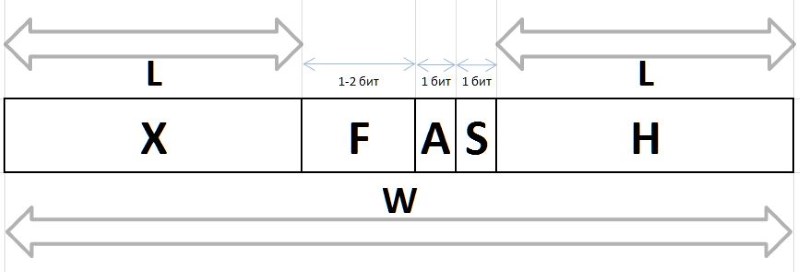
Значения Q и R, получаемые вышеприведенным способом из любого произвольного интервала G, в силу своих стабильных частотных характеристик подлежат компрессии и хранению в виде битовых пакетов переменной длины, описываемых ниже. Битовые цепочки, кодирующие в пакете величины Q и R, создаются различающимися способами: для кодирования индекса Q используется битовая цепочка префикса H, флюксии F и вспомогательного бита S, а для кодирования остатка R используется битовая группа инфикса X и вспомогательный бит A.
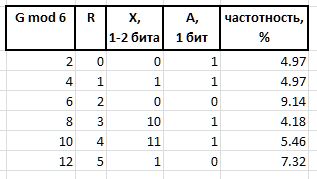
A (arbiter) — бит, определяющий размер инфикса X: 0 — однобитный инфикс, 1 — двухбитный.
X (infix) — 1- или 2-битовый инфикс, совместно с битом арбитра А, взаимообратно определяющий значение R табличным способом (в таблице для справки приведена также частотность первой шестерки с такими инфиксами):
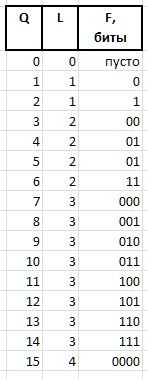
F (fluxion) — флюксия, производная индекса Q переменной длины L={0,1,2...}, предназначенная различать семантику битовых цепочек (пусто), 0, 00, 000, или 1, 01, 001, и т.д.
Битовая цепочка из единиц длиной L выражается значением 2^L - 1 (знак ^ означает возведение в степень). В нотации языка Си ту же самую величину можно получить выражением 1<<L - 1. Тогда значение флюксии длиной L можно получить из Q выражением
F = Q - (1<<L - 1),
а восстановить Q из флюксии выражением
Q = (1<<L - 1) + F.
В качестве примера для величин Q = {0..15} будут получены следующие битовые цепочки флюксии:
Последними двумя битовыми полями, необходимыми для упаковки/восстановления значений, являются:
H (header) — префикс, цепочка битов, установленных в 0.
S (stop) — стоп-бит, установленный в 1, завершающий префикс.
На самом деле эти биты обрабатываются в битовых цепочках первыми, они позволяют определить при распаковке или задать при упаковке размер флюксии и начало полей арбитра и флюксии — сразу за стоповым битом.
W (width) — ширина всего кода в битах.
Полная структура битового пакета приведена на рис.11:
Восстановленные из этих цепочек значения Q и R позволяют восстановить исходное значение интервала:
D = Q * 6 + R, G = (D+1) * 2,
а последовательность восстановленных интервалов позволяет восстановить и исходные простые числа из заданного базового значения блока (затравка блока интервалов) прибавлением к нему последовательно всех интервалов данного блока.
Для работы с битовыми цепочками используется 32-разрядная целая переменная, в которой обрабатываются младшие биты и после их использования биты сдвигаются влево при упаковке или вправо при распаковке.
Структура блока
Помимо битовых цепочек в блоке содержится информация, необходимая для выборки или для добавления бит, а также для определения содержимого блока.
// эстетические определения используемых целых типов
// и булевых констант
typedef unsigned char BYTE;
typedef unsigned short WORD;
typedef unsigned int LONG;
typedef unsigned long long HUGE;
typedef int BOOL;
#define TRUE 1
#define FALSE 0
#define BLOCKSIZE (256) // размеры: блока в байтах,
#define HEADSIZE (8+8+2+2+2) // заголовочной части блока,
#define BODYSIZE (BLOCKSIZE-HEADSIZE) // содержательной части блока.
// блок упакованных интервалов с индексными данными для поиска в БД
typedef struct
{
HUGE base; // затравка блока, стартовое простое число в блоке
HUGE card; // глобальный порядковый номер затравки в таблице простых
WORD count; // число упакованных в блок интервалов
WORD delta; // base+delta = значение наибольшего простого в блоке
WORD offset; // смещение первого неиспользованного бита в битовом теле
BYTE body[BODYSIZE]; // биты упакованных интервалов
} crunch_block;
// рабочий блок упакованных интервалов, используемых функциями put() и get()
crunch_block block;
// таблица трансляции шестерок в инфикс и обратно.
// N.B.: пары len/val и rev/rel структурно друг с другом
// не связаны, взаимно обратны по смыслу, и расположены
// в не связанном порядке.
static struct tail_t
{
BYTE len; // длина инфикса вместе с битами S и A
BYTE val; // его значение, включая арбитр A и бит-стоп S
BYTE rev; // значение для восстановления
BYTE rel; // длина для восстановления
}
tails[6] =
{
{ 4, 3, 2, 3 },
{ 4, 7, 5, 3 },
{ 3, 1, 0, 4 },
{ 4,11, 1, 4 },
{ 4,15, 3, 4 },
{ 3, 5, 4, 4 }
};
// функция упаковки интервала в битовый пакет и закладка пакета в массив бит
BOOL put(int gap)
{
// 1. вычисление значений для битового набора
int Q, R, L; // индекс шестерки (частное), шестерка (остаток), длина флюксии
int val = gap / 2 - 1;
Q = val / 6;
R = val % 6;
L = -1; // т.е., 0 - 1
val = Q + 1;
while (val) { val >>= 1; L++; } // вычисление длины флюксии L
val = Q - (1 << L) + 1; // флюксия
val <<= tails[R].len;
val += tails[R].val; // код остатка и стоповый бит
val <<= L; // биты префикса
L += L + tails[R].len; // длина битового поля
// 2. упаковка битов val длины L в массив buffer со смещением put_index
if (block.offset + L > BODYSIZE * 8) // ошибка! в буфере больше нет места
return FALSE;
Q = (block.offset / 8); // следующий байт, включая возможный хвост предыдущей упаковки
R = block.offset % 8; // смещение внутри этого байта
block.offset += L; // указатель на следующий незанятый бит
block.count++; // количество упаковок в буфере
block.delta += gap;
if (R > 0) // подгрузка уже использованных битов того же байта
{
val <<= R;
val |= block.body[Q];
L += R;
}
// втискивание результата в массив
L = L / 8 + ((L % 8) > 0 ? 1 : 0); // сколько байт для упаковки
while (L-- > 0)
{
block.body[Q++] = (char)val;
val >>= 8;
}
return TRUE;
}
// битовый указатель в блок интервалов для последовательного извлечения интервалов
int get_index; // требует инициализации нулем при переходе к другому блоку
// восстановление интервала из выдранной упаковки
int get()
{
if (get_index >= BODYSIZE * 8)
return 0; // в блоке больше нет упаковок
int val = *((int*)&block.body[get_index / 8]) >> get_index % 8; // выбираются 4 байта подряд
if (val == 0)
return -1; // ошибка! предотвращение зацикливания на не инициированном блоке
int Q, R, L, F, M, len; // частное, остаток, длина, флюксия, маска и ее длина
L = 0;
while (!(val & 1)) { val >>= 1; L++; } // поиск стоп-бита и вычисление длины флюксии
if ((val & 3) == 1) // определение размера инфикса с кодом инфикса
R = (val >> 2) & 1; // однобитный инфикс
else
R = ((val >> 2) & 3) + 2; // двухбитный инфикс
len = tails[R].rel;
get_index += 2 * L + len;
val >>= len;
M = ((1 << L) - 1); // маска флюксии
F = val & M; // и сама флюксия
Q = F + M; // восстановление частного
return 2 * (1 + (6 * Q + tails[R].rev)); // сложение с остатком и восстановление интервала из монолита
}
Усовершенствования
Если скормить полученную базу интервалов тому же самому архиватору 7-zip, то за полтора часа интенсивной работы на 8-ядерном сервере он умудряется сжать входной файл еще почти на 5%. То есть, в базе данных интервалов переменной длины с точки зрения архиватора все-таки присутствует некоторая избыточность. А значит есть повод немножко поспекулировать (в хорошем смысле этого слова) на тему дальнейшего снижения избыточности данных.
Принципиальная детерминированность последовательности интервалов между простыми числами позволяет делать точные калькуляции эффективности кодирования тем или иным методом. В частности, небольшие (и довольно хаотические) наброски позволили сделать принципиальный вывод о преимуществах кодирования шестерок перед тройками, и о преимуществах предложенного метода перед тривиальными кодами переменной длины (рис.12):
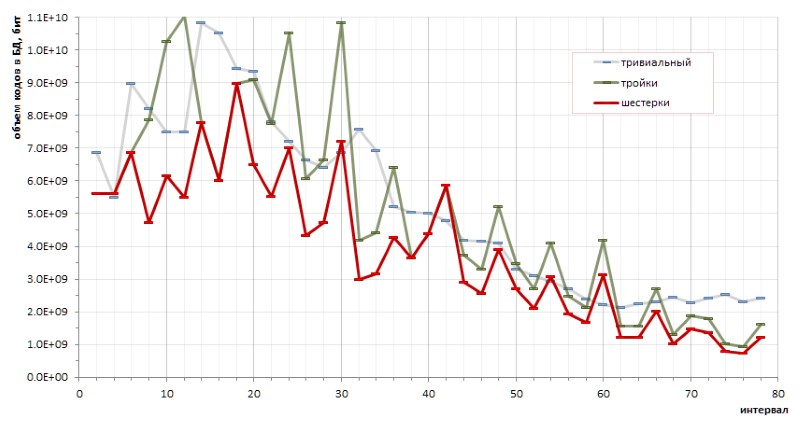
Однако досадные максимумы графика красного цвета прозрачно намекает, что могут существовать и другие методы кодирования, которые бы позволили сделать график еще более пологим.
Другое направление подсказывает проверка частотности подряд идущих интервалов. Из общих соображений: коль скоро наиболее распространенными в популяции простых чисел являются интервалы 6, 12 и 18, то, вероятно, они же будут чаще других встречаться в парах (дуплетах), тройках (триплетах) и тому подобных комбинациях интервалов. Если повторяемость дуплетов (а может даже и триплетов… ну, вдруг!) окажется статистически значимой в общей массе интервалов, то появится смысл транслировать их в какой-нибудь отдельный код.
Натурный эксперимент действительно выявляет некоторое преобладание отдельных дуплетов над другими. Однако, если абсолютное лидерство ожидаемо оказывается у пары (6,6) — 1.37% из всех дуплетов — то остальные призеры этого рейтинга куда как менее очевидны:
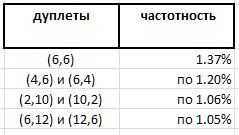
И, поскольку дуплет (6,6) симметричен, а все остальные отметившиеся дуплеты несимметричны и встречаются в рейтинге зеркальными двойниками с одинаковой частотностью, то, похоже, рекордную запись дуплета (6,6) в этом ряду следует поделить пополам между неразличимыми двойниками (6,6) и (6,6), что выводит с их 0.68% далеко вниз, за границу призового списка. И это в очередной раз подтверждает наблюдение, что никакие верные догадки в отношении простых чисел не бывают без сюрпризов.
Статистика триплетов также демонстрирует лидерство таких троек интервалов, которые не совсем вписываются в умозрительное предположение, исходящее из наивысшей частотности интервалов 6, 12, 18. В порядке убывания популярности лидеры частотности среди триплетов выглядят следующим образом:

и т.д.
Боюсь, однако, что результаты моих спекуляций будут интересны не столь программистам, сколь, может быть, математикам — в силу неожиданности корректур, внесенных практикой в интуитивные догадки. Выжать из упомянутых процентов частотности какой-либо существенный дивиденд в пользу дальнейшего повышения коэффициента компрессии вряд ли получится, в то время как сложность алгоритма грозит вырасти при этом весьма значительно.
Ограничения
Выше уже было отмечено, что рост максимальной величины интервалов в связи с разрядностью простых чисел идет очень и очень медленно. В частности, из рис.6 видно, что интервал между любыми простыми числами, которые могут быть представлены в формате 64-разрядного беззнакового целого, будет заведомо меньше значения 1600.
Описанная реализация позволяет корректно упаковывать и распаковывать любые 18-битные значения интервалов (фактически первая ошибка упаковки возникает с входным интервалом 442358). У меня не хватает фантазии предположить, что база данных интервалов простых чисел способна дорасти до подобных значений: навскидку это где-то примерно 100-битные целые, а посчитать точнее лень. В пожарном случае расширить диапазон интервалов в разы будет несложно.
Спасибо, что дочитали до этого места :)
Комментариев нет:
Отправить комментарий