По ходу статьи мы разберем все основные инструменты из арсенала разработчика и то, как их можно комбинировать для решения задач тестирования. Мы с вами проделаем путь от проектирования Идеального Теста до запуска максимально приближенного, чистого и понятного теста для системы планирования ресурсов на основе Kotlin.
Статья будет полезна практикующим инженерам, тем, кто рассматривает Kotlin как язык для комфортного написания компактных тестов, и тем, кто хочет улучшить процесс тестирования в своем проекте.
Статья основана на докладе Ивана Осипова (i_osipov) на конференции JPoint. Дальнейшее повествование ведется от его лица. Иван работает программистом в компании Haulmont. Основной продукт компании – CUBA, платформа для разработки энтерпрайза и различных веб-приложений. В том числе на этой платформе делаются и аутсорсинговые проекты, среди которых недавно был проект в области образования, в котором Иван занимался построением расписания для образовательного учреждения. Так сложилось, что последние три года Иван так или иначе работает с планировщиками, и конкретно в Haulmont в течение года они этот самый планировщик тестируют.
Для желающих позапускать примеры — держите ссылку на GitHub. По ссылке вы найдете весь код, который сегодня мы с вами будем разбирать, запускать и писать. Открывайте код и вперед!

Сегодня мы обсудим:
- что такое проблемно-ориентированные языки;
- встроенные проблемно-ориентированные языки;
- построение расписания для образовательного учреждения;
- как это все тестируется вместе с Kotlin.
Сегодня я подробно расскажу об инструментах, которые у нас есть в языке, покажу вам несколько демок, и мы напишем целиком тест от начала и до конца. При этом я хотел бы быть более объективным, поэтому расскажу о каких-то минусах, которые я для себя обозначил при разработке.
Начнем с разговора о модуле построения расписания. Итак, построение расписания происходит в несколько этапов. Каждый из этих этапов нужно тестировать отдельно. Нужно понимать, что несмотря на то, что этапы разные, модель данных у нас общая.

Этот процесс можно представить следующим образом: на входе имеются какие-то данные с общей моделью, на выходе – расписание. Данные проходят валидацию, фильтрацию, затем строятся учебные группы. Имеется в виду предметная область расписания для учебного учреждения. На основе построенных групп и на основе каких-то других данных мы размещаем занятие. Сегодня мы будем говорить только про последний этап – про размещение занятий.

Немного про тестирование планировщика.
Во-первых, как вы уже поняли, разные этапы должны тестироваться по отдельности. Можно выделить более-менее стандартный процесс запуска тестирования: есть инициализация данных, есть запуск планировщика, есть проверка результатов этого самого планировщика. Есть огромное количество различных бизнес-кейсов, которые нужно покрыть и разных ситуаций, которые нужно учитывать, чтобы при построении расписания эти ситуации также сохранялись.
Модель порой бывает развесистой, и для того, чтобы создать одну-единственную сущность, необходимо проинициализировать пять дополнительных сущностей, а то и больше. Таким образом, суммарно получается большое количество кода, который мы пишем снова и снова для каждого теста. Поддержка таких тестов занимает значительное количество времени. Если захочется обновить модель, а такое иногда происходит, то масштаб изменений затрагивает и тесты.
Напишем тест:

Давайте напишем самый простой тест для того, чтобы вы в общем понимали картину.
Что первое приходит на ум, когда думаешь про тестирование? Возможно, это несколько примитивные тесты такого вида: создаешь класс, в нем создаешь метод, помечаешь его аннотацией Test. В итоге, мы пользуемся возможностями JUnit, и инициализируем какие-то данные, значения по умолчанию, затем специфические для теста значения, делаем все то же самое для остальной части модели, и, наконец, создаем объект-планировщик, передаем в него наши данные, запускаем, получаем результаты и проверяем их. Более-менее стандартный процесс. Но в нем, очевидно, есть дублирование кода. Первое, что приходит на ум, это возможность все вынести в статические методы. Раз есть куча значений по умолчанию, почему бы это не скрыть?

Это хороший первый шаг по пути уменьшения дублирования.

Глядя на это, ты понимаешь, что хотелось бы модель держать более компактно. Тут у нас появляется паттерн-строитель, в котором где-то под капотом инициализируется значение по умолчанию, и тут же инициализируются специфичные для теста значения. Становится уже лучше, однако, мы все еще пишем boilerplate-код, и пишем его мы каждый раз заново. Представьте 200 тестов – 200 раз придется написать эти три строчки. Очевидно, хотелось бы от этого как-то избавиться. Развивая идею, мы приходим к некоторому пределу. Так, например, мы можем создать паттерн-билдер вообще для всего.

Можно создавать планировщик с нуля и до конца, задавать все нужные нам значения, запускать планирование и все здорово. Если взглянуть подробно на этот пример и детально его разобрать, то окажется, что пишется большое количество ненужного кода. Хотелось бы сделать тесты более читаемыми, чтобы можно было взглянуть и сразу понять, не вникая в паттерны и так далее.
Итак, у нас есть какое-то количество ненужного кода. Несложная математика подсказывает, что тут на 55% больше букв, чем нам необходимо, и хотелось бы как-то от них уйти.

Спустя некоторое время поддержка наших тестов оказывается дороже, потому что кода поддерживать нужно больше. Иногда, если мы не предпринимаем каких-то усилий, читаемость либо оставляет желать лучшего, либо получается приемлемо, но нам бы хотелось еще лучше. Возможно, впоследствии мы начнем добавлять какие-то фреймворки, библиотеки, чтобы тесты писать было проще. Благодаря этому, мы повышаем уровень вхождения в тестирование нашего приложения. Здесь у нас и так сложное приложение, уровень вхождения в его тестирование значителен, а мы его еще сильней повышаем.
Идеальный тест
Здорово говорить, как все плохо, но давайте подумаем, как бы было очень хорошо. Идеальный пример, который мы хотели бы получить в результате:

Представим, что есть некоторая декларация, в которой мы скажем, что это тест с определенным названием, и хочется использовать пробел для разделения слов в названии, а не CamelCase. Мы строим расписание, у нас есть какие-то данные, и результаты планировщика проверяются. Так как мы работаем в основном с Java, и весь код основного приложения написан на этом языке, хочется иметь еще и совместимые возможности в тестировании. Инициализировать данные хотелось бы максимально очевидно для читателя. Хочется инициализировать некоторые общие данные и часть модели, которая нам необходима. Например, создавать студентов, преподавателей, и описывать, когда они доступны. Вот это — наш идеальный пример.
Domain Specific Language

Глядя на это все, начинает казаться, что это похоже на некоторый проблемно-ориентированный язык. Нужно понять, что это такое и в чем разница. Языки можно разделить на два типа: языки общего назначения (то, на чем мы с вами пишем постоянно, решаем абсолютно любые задачи и справляемся абсолютно со всем) и языки проблемно-ориентированные. Так, например, SQL нам помогает отлично вытаскивать данные из базы, а какие-то другие языки также помогают решать другие специфичные проблемы.

Один из способов реализации проблемно-ориентированных языков — встраиваемые языки, или внутренние. Такие языки реализуются на основе языка общего назначения. То есть, несколько конструкций нашего языка общего назначения, образуют что-то вроде базиса – то, чем мы пользуемся при работе с проблемно-ориентированным языком. При этом, конечно, у появляется возможность в проблемно-ориентированном языке использовать все фичи и особенности, которые к приходят из языка общего назначения.

Снова взглянем на наш идеальный пример и подумаем, какой язык выбрать. Варианта у нас три.

Первый вариант – Groovy. Замечательный, динамичный язык, который отлично показал себя в построении проблемно-ориентированных языков. Снова можно привести пример build файла в Gradle, которым многие из нас пользуются. Eще есть Scala, которая имеет огромное количество возможностей для реализации чего-то своего. И наконец, есть Kotlin, который нам также помогает строить проблемно-ориентированный язык, и сегодня именно о нем пойдет речь. Я бы не хотел разводить войн и сравнивать Kotlin с чем-то другим, скорее, это остается на вашей совести. Сегодня я покажу вам то, что есть в Kotlin для разработки проблемно-ориентированных языков. Когда вы захотите сравнить это и сказать, что какой-то язык лучше, вы сможете вернуться к этой статье и легко увидеть разницу.

Что дает нам Kotlin для разработки проблемно-ориентированного языка?
Во-первых, это статическая типизация, и все отсюда вытекающие. На этапе компиляции обнаруживается большое количество проблем, и это очень сильно спасает, особенно в том случае, когда не хочется в тестах получать проблемы, связанные с синтаксисом и написанием.
Затем, есть отличная система вывода типов, которая приходит из Kotlin. Это замечательно, потому что нет потребности снова и снова писать какие-то типы, все выводится компилятором на ура.
В-третьих, есть отличная поддержка среды разработки, и это неудивительно, ведь та же компания, делает основную на сегодня среду разработки, и она же делает Kotlin.
Наконец, внутри DSL, очевидно, мы можем использовать Kotlin. На мой субъективный взгляд, поддерживать DSL намного проще, чем поддерживать утилитные классы. Как вы увидите далее, читаемость оказывается немного лучше билдеров. Что я понимаю под «лучше»: у вас получается несколько меньше синтаксиса, который вам необходимо писать, — тот, кто будет читать ваш проблемно-ориентированный язык, будет быстрее это воспринимать. Наконец, написать свой велосипед намного веселее! Но на самом деле, реализовать проблемно-ориентированный язык намного проще, чем изучить какой-то новый фреймворк.
Я напомню еще раз ссылку на GitHub, если вы захотите писать демки дальше, то вы можете зайти и забрать код по ссылке.
Проектирование идеала на Kotlin
Перейдем к проектированию нашего идеала, но уже на Kotlin. Взглянем на наш пример:

И поэтапно начнем его отстраивать.
У нас есть тест, который превращается в функцию в Kotlin, которую можно именовать, используя пробелы.

Пометим с помощью аннотации Test, которая нам доступна из JUnit. В Kotlin можно пользоваться сокращенной формой записи функций и через = избавиться от лишних фигурных скобок для самой функции.
Schedule у нас превращается в блок. То же самое происходит с большим количеством конструкций, так как мы все-таки работаем в Kotlin.

Перейдем к оставшейся части. Опять появляются фигурные скобки, от них мы никак не избавимся, но, по крайней мере, попытаемся приблизиться к нашему примеру. Производя конструкции с пробелами, мы могли бы как-то изощриться и сделать их как-то по-другому, но мне кажется, что лучше все-таки сделать обычные методы, которые будут в себя инкапсулировать обработку, но в целом это будет очевидно для пользователя.

Наш student превращается в некоторый блок, в котором идет работа со свойствами, с методами, и это мы дальше с вами будем разбирать.

Наконец, преподаватели. Здесь у нас появляются некоторые вложенные блоки.

В коде ниже мы переходим к проверкам. Нам нужны проверки на совместимость с Java-языками – и да, Kotlin совместим с Java.

Арсенал разработки DSL на Kotlin

Перейдем к перечню инструментов, которые у нас есть. Здесь я привел табличку может быть, в ней перечислено все, что необходимо для разработки проблемно-ориентированных языков в Kotlin. Можно время от времени к ней возвращаться и освежать память.
В таблице приведено некоторое сравнение проблемно-ориентированного синтаксиса и обычного синтаксиса, который имеется в языке.
Лямбды в Kotlin
val lambda: () -> Unit = { }
Начнем с самого базового кирпичика, который у нас есть в Kotlin – это лямбды.
Сегодня под типом лямбды я буду подразумевать просто функциональный тип. Лямбды обозначаются следующим образом: (типы параметров) -> возвращаемый тип.
Саму лямбду мы инициализируем с помощью фигурных скобок, внутри них мы можем записать какой-то код, который будет вызван. То есть лямбда, по сути, просто в себя прячет этот код. Запуск такой лямбды выглядит как вызов функции, просто круглые скобки.

Если мы хотим передать какой-то параметр, во-первых, мы должны описать это в типе.
Во-вторых, мы имеем доступ к идентификатору по умолчанию it, которым мы можем пользоваться, однако, если нас это как-то не устраивает, можно задать своё имя параметра и пользоваться ими.

При этом, мы можем пропустить использование этого параметра и воспользоваться знаком нижнего подчеркивания для того, чтобы не плодить идентификаторы. В этом случае для игнорирования идентификатора можно было бы вообще ничего не писать, но в общем случае для нескольких параметров есть упомянутый "_".

Если мы захотим передать больше одного параметра, нужно явно определить их идентификаторы.

Наконец, что будет, если мы попробуем передать лямбду в какую-то функцию и запустить ее там. Выглядит это в начальном каком-то приближении следующим образом: у нас есть функция, в которую мы передаем лямбду в фигурных скобках, и, если в Kotlin лямбда написана в качестве последнего параметра, мы ее можем как бы вынести за эти скобки.

Если в скобках не осталось ничего, скобки мы можем упразднить. Тем, кто знаком с Groovy, это должно быть знакомо.

Где это применяется? Абсолютно везде. То есть те самые фигурные скобки, про которые мы с вами уже говорили, их мы и используем, это и есть те самые лямбды.

Теперь посмотрим на одну из разновидностей лямбд, я их называю лямбды с контекстом. Вы встретите какие-то другие названия, например, lambda with receiver, и отличаются они от обычных лямбд при объявлении типа следующим образом: слева мы дописываем какой-то класс контекста, это может быть любой класс.

Для чего это нужно? Это нужно для того, чтобы внутри лямбды мы имели доступ к ключевому слову this – это самое ключевое слово, указывает нам на наш контекст, то есть на некоторый объект, который мы связали с нашей лямбдой. Так, например, мы можем создать лямбду, которая будет выводить некоторую строку, естественно, мы воспользуемся классом строки для объявления контекста и вызов такой лямбды будет выглядеть вот так:



Если вам хочется передать контекст в качестве параметра, вы можете это точно также сделать. Однако, совсем передать контекст мы не можем, то есть лямбда с контекстом требует – внимание! – контекста, да. Что будет, если мы начнем передавать лямбду с контекстом в какой-то метод? Вот посмотрим снова на наш метод exec:

Переименуем его в метод student – ничего не изменилось:

Так мы постепенно движемся к нашей конструкции, конструкции student, которая под фигурными скобками скрывает всю инициализацию.

Давайте в ней разберемся. У нас есть какая-то функция student, которая принимает лямбду с контекстом Student.

Очевидно, нам нужен контекст.

Здесь мы создаем объект и на нем же запускаем эту лямбду.

В результате, также мы можем перед запуском лямбды проинициализировать какие-то дефолтные значения, таким образом под функцию мы инкапсулируем все, что нам необходимо.

Благодаря этому, внутри лямбды мы получаем доступ к ключевому слову this – то, ради чего, наверное, и существуют лямбды с контекстом.

Естественно, мы можем от этого ключевого слова избавиться и у нас получается возможность писать вот такие конструкции.

Опять же, если у нас есть не только проперти, а еще есть какие-то методы, мы можем их также вызывать, это выглядит довольно естественно.

Применение
Все эти лямбды в коде – это лямбды с контекстом. Существует огромное количество контекстов, они так или иначе пересекаются и позволяют выстраивать наш проблемно-ориентированный язык.

Резюмируя по лямбдам – у нас есть лямбды обычные, есть с контекстом, и теми, и другими можно пользоваться.

Операторы
В Kotlin есть ограниченный набор операторов, который вы можете переопределять, используя соглашения и ключевое слово operator.
Посмотрим на преподавателя и на его доступность. Допустим, мы говорим, что преподаватель работает по понедельникам с 8 утра в течение 1 часа. Еще мы хотим сказать, что, кроме этого одного часа, он работает с 13.00 в течение 1 часа. Хочется выразить это с помощью оператора +. Как это можно сделать?

Имеется некоторый метод availability, который принимает лямбду с контекстом AvailabilityTable. Это значит, что есть некоторый класс, который так и называется, и в этом классе объявлен метод monday. Этот метод возвращает DayPointer, т.к. нужно к чему-то прикрепить наш оператор.

Давайте разберемся в том, что такое DayPointer. Это указатель на таблицу доступности некоторого преподавателя, и день в его же расписании. Также у нас есть функция time, которая будет так или иначе превращать какие-то строки в целочисленные индексы: в Kotlin у нас для этого есть класс IntRange.
Слева есть DayPointer, справа есть time, и нам хотелось бы их объединить оператором +. Для этого в классе DayPointer можно создать наш оператор. Он будет принимать диапазон значений типа Int и возвращать DayPointer для того, чтобы мы цепочкой могли снова и снова склеивать наш DSL.
Теперь взглянем на ключевую конструкцию, с которой все начинается, с которой начинается наш DSL. Ее реализация немного отличается, и сейчас мы в этом разберемся.
В Kotlin есть понятие синглтона, встроенное прямо в язык. Для этого вместо ключевого слова class используется ключевое слово object. Если мы создаем метод внутри синглтона, то можно обращаться к нему так, что нет необходимости снова создавать инстанс этого класса. Мы просто обращаемся к нему как к статическому методу в классе.

Если взглянуть на результат декомпиляции (то есть, в среде разработки прокликать Tools –> Kotlin –> Show Kotlin Bytecode –> Decompile), то можно увидеть следующую реализацию синглтона:

Это всего лишь обычный класс, и ничего сверхъестественного здесь не происходит.
Имеется еще один интересный инструмент – это оператор invoke. Представим, что у нас есть некоторый класс А, у нас есть его инстанс, и мы хотели бы словно запускать этот инстанс, то есть вызывать круглые скобки у объекта этого класса, и мы можем это сделать благодаря оператору invoke.

По сути, круглые скобки позволяют нам вызывать метод invoke и имеет модификатор operator. Если же мы передадим в этот оператор лямбду с контекстом, то у нас получится вот такая конструкция.

Создавать каждый раз инстансы то еще занятие, поэтому мы можем совместить предыдущие знания и текущие.
Сделаем синглтон, назовем его schedule, внутри него мы объявим оператор invoke, внутри создадим контекст, а принимать он будет лямбду с контекстом вот тем самым, который мы здесь же и создаем. Получается единая точка входа в наш DSL, и, как следствие, получается та же самая конструкция – schedule с фигурными скобками.

Отлично, про schedule мы поговорили, давайте взглянем на наши проверки.
У нас есть преподаватели, мы построили какое-то расписание, и хотим проверить, что в расписании этого преподавателя в определенный день в определенном занятии есть какой-то объект, с которым мы будем работать.

Хотелось бы использовать квадратные скобки и обращаться к нашему расписанию способом, визуально похожим на доступ к массивам.

Сделать это можно с помощью оператора: get / set:

Здесь мы не делаем ничего нового, просто следуем соглашениям. В случае оператора set нужно дополнительно передать значения в наш метод:

Итак, квадратные скобки для чтения превращаются в get, а квадратные скобки, через которые мы присваиваем, превращаются в set.
Демо: object, operators
Дальнейший текст можно или читать, или смотреть видео по ссылке. У видео есть четкое время начало, но не указано времени окончания — в принципе, однажды начав, можно досмотреть его до конца статьи.
Для удобства я кратко изложу суть видео прямо в тексте.
Давайте напишем тест. У нас есть некоторый объект schedule, и если мы через ctrl+b перейдем к его реализации, то мы увидим все, о чем я перед этим говорил.

Внутри объекта schedule мы хотим проинициализировать данные, затем выполнить какие-то проверки, и в рамках данных мы хотели бы сказать, что:
- наше учебное заведение работает с 8 утра;
- есть некоторый набор предметов, для которых мы будем строить расписание;
- есть некоторые преподаватели, у которых описана какая-то доступность;
- есть студент;
- в принципе для студента нам нужно сказать только то, что он изучает какой-то определенный предмет.

И здесь проявляется один из минусов Kotlin и проблемно-ориентированных языков в принципе: довольно сложно адресовать какие-то объекты, которые мы создали раньше. В этом демо я буду указывать все в качестве индексов, то есть rus – это индекс 0, математика – это индекс 2. И преподаватель естественно, тоже что-то ведет. Он не просто на работу ходит, а чем-то занимается. Для читателей этой статьи я хотел бы предложить еще один вариант адресации, вы можете завести уникальные теги и по ним сохранять сущности в Map, а когда нужно обратиться к какой-то из них, то по тегу вы всегда можете её найти. Продолжим разбирать DSL.
Здесь что нужно отметить: во-первых, у нас есть оператор +, к реализации которого мы также можем перейти и увидеть, что у нас на самом деле есть класс DayPointer, который помогает нам связывать это все с помощью оператора.
И благодаря тому, что у нас есть доступ к контексту, среда разработки нам подсказывает, что у нас в контексте через ключевое слово this, нам доступна некоторая коллекция, и ей мы будем пользоваться.

То есть у нас это коллекция ивентов. Ивент в себя инкапсулирует набор свойств, например: что имеется студент, преподаватель, в какой день на какой урок они встречаются.

Продолжим писать тест дальше.

Здесь, опять же, мы пользуемся оператором get, перейти к его реализации не так просто, но мы можем это сделать.

По сути, мы просто следуем соглашению, благодаря чему и получаем доступ к этой конструкции.
Давайте вернемся к презентации и продолжим разговор про Kotlin. Мы хотели проверки, реализованные на Kotlin, и мы перебирали эти вот ивенты:

Ивент – это, по сути, инкапсулированный набор из 4 свойств. Хочется раскладывать этот ивент на набор свойств, словно кортеж. В русском языке такая конструкция называется мульти-декларации (я нашел только такой перевод), или destructuring declaration, и работает это следующим образом:

Если кто-то из вас не знаком с этой фичей она работает так: можно взять ивент, и на месте, где он используется, воспользовавшись круглыми скобками, разложить его на набор свойств.

Работает это потому, что у нас есть метод componentN, то есть это метод, который генерируется компилятором благодаря модификатору data, который мы пишем перед классом.

Вместе с этим нам прилетает большое количество других методов. Нас интересует именно метод componentN, генерируется на основе перечисленных в списке параметров primary-конструктора свойств.

Если бы у нас не было модификатора data, необходимо было бы вручную написать оператор, который будет делать все то же самое.


Итак, у нас какие-то методы componentN, и они, раскладываются вот в такой вызов:

По сути, это синтаксический сахар над вызовом нескольких методов.
Мы с вами уже говорили про некоторую таблицу доступности, и, на самом деле, я вас обманул. Так бывает. Никакого avaiabilityTable не существует, нет его в природе, а есть матрица булевских значений.

Не нужно никакого дополнительного класса: можно взять матрицу булевских значений и переименовать для большей очевидности. Это можно сделать с помощью так называемого typealias или псевдонима типа. К сожалению, никаких дополнительных бонусов мы от этого не получаем, это просто переименование. Если вы возьмете и availability переименуете обратно в матрицу булевских значений, вообще ничего не изменится. Код как работал, так и будет работать.
Давайте взглянем на преподавателя, вот как раз на эту самую доступность, и поговорим о нем:
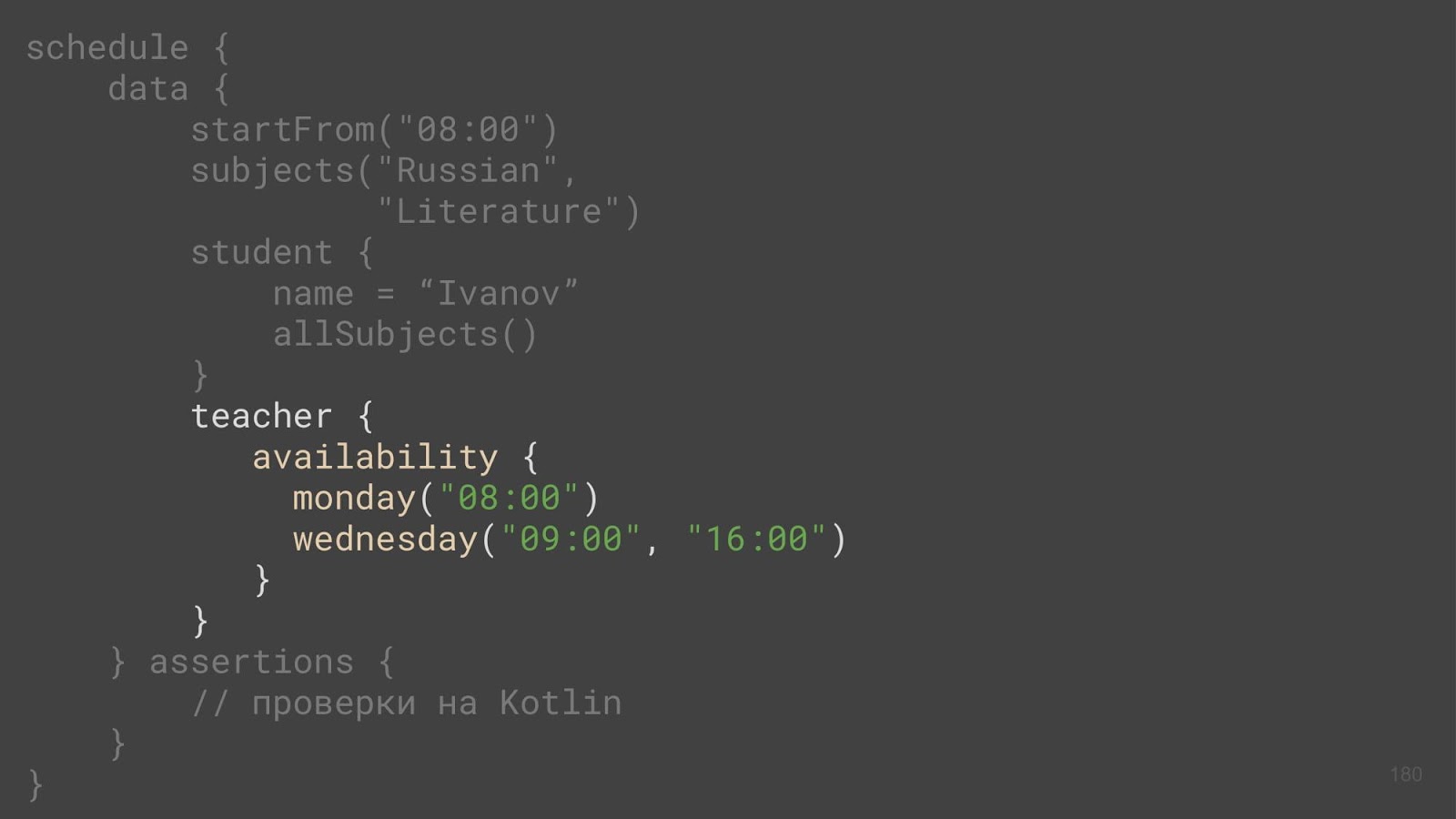
У нас есть преподаватель, и у него вызывается метод availability (вы еще не потеряли нить рассуждений? :-). Откуда он взялся? То есть, преподаватель — это какая-то entity, у которой есть класс, и это — бизнес-код. И не может там быть никакого дополнительного метода.

Этот метод появляется благодаря extension-функциям. Берем и прикручиваем к нашему классу какому-то еще одну функцию, которую можем запускать на объектах этого класса.
Если мы передадим этой функции некоторую лямбду, а затем запустим ее на существующем свойстве, то все отлично — метод availability в своей реализации инициализирует свойство availability. От этого можно избавиться. Мы уже знаем про оператор invoke, который может и крепиться к типу, и быть одновременно extension-функцией. Если в этот оператор передавать лямбду, то тут же, на ключевом слове this, мы можем эту лямбду запускать. В результате, когда мы работаем с преподавателем, доступность – свойство преподавателя, а не какой-то дополнительный метод, и тут никакого рассинхрона не происходит.

В качестве бонуса, extension-функции можно создавать для nullable типов. Это хорошо, так как если будет переменная с nullable типом, содержащим значение null, наша функция к этому уже готова, и не упадет с NullPointer. Внутри этой функции this может быть равен null, и это нужно обработать.

Резюмируя по extension-функциям: необходимо понимать, что имеется доступ только к публичному API класса, а сам класс никак не модифицируется. Extension-функция определяется по типу переменной, а не по фактическому типу. Более того, член класса с той же сигнатурой окажется приоритетней. Можно создавать extension-функцию для одного класса, но написать ее в совершенно другом классе, и внутри этой extension-функции будет доступ к одновременно двум контекстам. Получается пересечение контекстов. Ну и наконец, это отличная возможность взять и прикрутить операторы вообще в любое место, где мы хотим.

Следующий инструмент — инфиксные функции. Очередной опасный молоток в руках разработчика. Почему опасный? То, что вы видите – это код. Такой код можно написать в Kotlin, и не надо так делать! Пожалуйста, не делайте так. Но тем не менее, подход хороший. Благодаря этому есть возможность избавляться от точек, скобочек — от всего того шумного синтаксиса, от которого мы пытаемся уйти как можно дальше и сделать наш код немного чище.

Как это работает? Давайте возьмем более простой пример — переменную типа integer. Создадим для нее extension-функцию, назовем ее shouldBeEqual, она что-то будет делать, но это уже неинтересно. Если мы допишем слева от нее модификатор infix – все, этого достаточно. Можно избавляться от точек и скобочек, но есть парочка нюансов.

На основе этого реализована как раз конструкция data и assertions, скрепленные вместе.

Давайте в ней разберемся. У нас есть SchedulingContext — общий контекст запуска планирования. Есть функция data, которая возвращает результат этого планирования. При этом мы создаем extension-функцию и одновременно инфикс-функцию assertions, которая будет запускать лямбду, проверяющую наши значения.

Имеется субъект, объект и действие, и нужно их как-то связать. В этом случае результат выполнения data с фигурными скобками – это субъект. Лямбда, которую мы передаем в метод assertions – объект, а сам метод assertions – действие. Все это как бы склеивается.

Говоря про инфикс функции, важно понимать, что это шаг по избавлению от шумного синтаксиса. Однако, у нас обязательно должен существовать субъект и объект этого действия, и нужно воспользоваться модификатором infix. Может быть точно один параметр — то есть ноль параметров не может быть, два не может быть, три – ну вы поняли. Можно передавать в эту функцию, например, лямбды, и таким образом получаются конструкции, которые вы раньше не видели.
Перейдем к следующей демке. Ее лучше смотреть на видео, а не читать текстом.
Теперь все выглядит готовым: инфикс функции вы увидели, extension функции увидели, destructuring declaration готов.
Вернемся к нашей презентации, и здесь мы перейдем к одному довольно важному моменту при построении проблемно ориентированных языков – то, о чем стоит задумываться – это контроль контекста.

Бывают ситуации, когда мы можем взять DSL и переиспользовать его прям внутри него же, а мы этого делать не хотим. Наш пользователь (возможно, неопытный пользователь), пишет data внутри data, и это не имеет никакого смысла. Нам хотелось бы как-то запретить ему это делать.
До Kotlin версии 1.1 мы должны были сделать следующее: в ответ на то, что у нас в SchedulingContext есть метод data, мы должны были в DataContext создать еще один метод data, в который принимаем лямбду (пускай без реализации), должны были пометить этот метод аннотацией @Deprecated и сказать компилятору не компилировать такое. Видишь, что такой метод запускается – не компилируй. Используя такой подход, мы получим даже некоторое осмысленное сообщение, когда будем писать неосмысленный код.

После версии Kotlin 1.1, появилась замечательная аннотация @DslMarker. Эта аннотация нужна, чтобы помечать производные аннотации. Ими, в свою очередь, мы будем размечать проблемно-ориентированные языки. Для каждого проблемно-ориентированного языка вы можете создать одну аннотацию, которую пометите @DslMarker и будете её вешать на каждый контекст, который необходим. Больше нет потребности в том, чтобы писать дополнительные методы, которые нужно запрещать компилировать — оно все просто работает. Не компилируется.
Тем не менее, есть один такой специальный случай, когда мы работаем с нашей бизнес-моделью. Обычно она написана на Java. Есть контекст, есть аннотация, которой нужно пометить контекст. Как думаете, какой контекст внутри метода студент? Класс Student. Это – кусок нашей бизнес-модели, там Kotlin нет.


Нам хотелось бы как-то эту ситуацию тоже контролировать, ведь в этом случае есть доступ к следующей конструкции: создать студента внутри студентов. Не хочу вызывать у вас никаких неправильных ассоциаций, но мы хотим это запретить, это неправильно.

Варианта у нас есть три.
- Создать целый контекст, который отвечает за нашего студента. Назовем его StudentContext. Опишем там все свойства, и потом будем на основе него создавать студента. Некоторое такое безумие – пишется куча кода, наверное, больше, чем для продакшена.
- Второй вариант – можем взять и создать некоторый интерфейс, который отражает нашего студента, то есть просто перечисляет свойства. Но переиспользуем этот же интерфейс в наших тестах. Возьмем StudentContext и скажем, что он реализует некоторый интерфейс IStudent посредством делегирования реализации этого интерфейса другому объекту. То есть, создается тут же на месте объект Student, и от него берется вся реализация интерфейса IStudent для StudentContext. Помечаем аннотацией DslMarker и прекрасно, все работает.
- Любимый способ: воспользуемся аннотацией deprecated и запретим компилировать неправильный код. Просто перечислим то, что нам необходимо. Обычно в иерархии сущностей находится такая сущность, которая содержит идентификатор. На эту сущность мы можем повесить extension-функцию, которую мы и запретим вызывать. В том числе и студента внутри студента.

Таким образом, даже на этом уровне можно контролировать контекст, но с некоторыми ограничениями, которые нужно уметь обходить.

Резюмируя про контроль контекста. Защищайте ваших пользователей от ошибок. Понятно, что некоторые ошибки пользователи делать не будут, ведь это очевидно, но контролировать это все равно желательно. Тем более, что реализация такого контроля занимает не так много средств и времени. Пользуйтесь аннотацией @DslMarker, которой вы помечаете ваши собственные аннотации. В тех ситуациях, когда вы не можете пользоваться аннотацией @DslMarker, воспользуйтесь аннотацией @Deprecated, это поможет вам обойти те случаи, которые пока не работают.
Итак, демка контроля контекста:

Минусы и проблемы
Во-первых, переиспользование частей DSL. Сегодня вы уже видели, что адресовать созданные с помощью DSL сущности может быть проблематично. Есть способы, как это обойти, но об этом желательно подумать заранее, чтобы на этот случай иметь план.
Представим, что у вас есть какой-то кусочек кода, и вы хотите его просто повторять, например, в цикле иметь возможность создавать студентов, много-много раз одинаковых студентов, или любые другие сущности. Как это сделать? Можно воспользоваться циклом for — не самый лучший вариант. Можно создать дополнительный метод внутри вашего DSL, и это будет уже более хорошим решением, однако, решать такие проблемы придется прямо на уровне DSL. Следите за ключевым словом this и дефолтным именованием параметра it. К счастью, с версии Kotlin плагина 1.2.20 у нас есть хинты, которые видны прямо в среде разработки. Серенький код нам подсказывает, с каким контекстом мы работаем или что такое it.
Вложенность может стать проблемой. Вы выстроили прекрасный DSL, но инициализация модели уходит вглубь-вглубь-вглубь, и в итоге вы чаще пользуетесь горизонтальным скроллом, чем вертикальным. Желательно, скрывать под дефолтной реализацией дефолтные значения. Пользователь, которому нужен просто студент, не хочет знать ни про какую программу обучения, ни про что-то еще, он просто хочет создать студента без подробностей, даже не хочет имя обозначать. Старайтесь сократить синтаксис. Например, какие-то значения по умолчанию указать, лямбду пустую передать и т.д.
Наконец, документация. На мой субъективный взгляд, лучшая документация для вашего проблемно-ориентированного языка – это больше количество примеров этого DSL. Здорово, когда у вас есть Kotlin-доки, это хороший бонус. Однако, если пользователь DSL понятия не имеет, какие конструкции имеются, ему и Kotlin-доки смотреть негде. Чувствовали такое когда-нибудь? Когда вы приходите писать Gradle-файл, в самом начале, вы не понимаете, что в нем есть, и нужны какие-то примеры. Вам наплевать на какие-то контексты, вы хотите примеры, и вот это – та самая лучшая документация, которой можно пользоваться новым юзерам вашего DSL.

Не суйте DSL’и во все щели, пожалуйста. Это очень хочется делать, когда вы владеете этим инструментом. Хочется сказать, давайте создадим DSL сюда, может быть, сюда и сюда. Во-первых – это неблагодарная работа. Во-вторых, все-таки желательно применять это по месту назначения. Там, где вам это действительно помогает решать какую-то проблему.
Наконец, изучайте Kotlin. Изучайте возможности, которые приходят в этот язык, новые функции, благодаря чему ваш код будет все чище, короче, компактнее, читать его будет намного проще. И когда вы будете снова возвращаться к тестированию (например, что-то дописали, на это нужно сделать тест), вам будет намного приятнее это делать, потому что DSL максимально компактный, комфортный, и у вас нет проблем с тем, чтобы создать с десяток студентов. Просто в пару строчек это делается.
Тренируйтесь на «кошках», как герой одного известного фильма. На мой взгляд, сначала проще привнести в ваш проект Kotlin в качестве тестирования. Это хорошая возможность проверить язык, попробовать его, посмотреть на его фичи. Это такое поле боя, на котором даже если ничего не получится — ничего страшного, все еще можно этим пользоваться.
Наконец, предварительно проектируйте DSL. Сегодня я показал некоторый идеальный пример, и мы прошли поэтапно до построения проблемно-ориентированного языка. Если заранее спроектировать DSL, в конечном итоге будет намного проще, вы не будете по 10 раз переделывать его, вы не будете париться о том, что контексты каким-то образом пересекаются и логически сильно связаны. Просто предварительно спроектируйте DSL – это довольно легко сделать на бумажке, когда вы знаете набор конструкций, которые я вам сегодня рассказал.
И наконец, контакты для связи. Меня зовут Иван Осипов, Telegram: @ivan_osipov, Twitter: @_osipov_, Хабр: i_osipov. Буду ждать ваших комментариев.
Минутка рекламы. Если вам понравился этот доклад с конференции JPoint — обратите внимание, что 19-20 октября в Санкт-Петербурге пройдет Joker 2018 — крупнейшая в России Java-конференция. В его программе тоже будет много интересного. Конференция анонсирована совсем недавно, но на сайте уже есть первые спикеры и доклады.
Комментариев нет:
Отправить комментарий