Руководитель группы СУБД общего назначения Дмитрий Сарафанников рассказал об эволюции хранилища данных в Яндексе: о том, как мы решили делать S3-совместимый интерфейс, почему выбрали PostgreSQL, на какие грабли наступили и как с ними справились.
— Всем привет! Меня зовут Дима, в Яндексе я занимаюсь базами данных. Расскажу, как мы делали S3, как пришли к тому, чтобы делать именно S3, и какие хранилища были раньше. Первое из них — Elliptics, оно выложено в опенсорсе, доступно на GitHub. Многие, возможно, сталкивались с ним.

Это, по сути, распределенная хэш-таблица с 512-битным ключом, результат SHA-512. Оно образует такое кольцо ключей, которое случайным образом делится между машинами. Если вы хотите добавить туда машин, ключи перераспределяются, происходит ребалансировка. У этого хранилища есть свои проблемы, связанные, в частности, с ребалансировкой. Если у вас достаточно большое количество ключей, то при постоянно растущих объемах вам нужно постоянно туда докидывать машин, и на очень большом количестве ключей ребалансировка может просто не сходиться. Это было достаточно большой проблемой.
Но в то же время это хранилище отлично подходит для более-менее статических данных, когда вы разово большой объем заливаете, и потом гоняете на них read-only-нагрузку. Для таких решений это подходит отлично.
Едем дальше. Проблемы с ребалансировкой были достаточно серьезные, поэтому появился следующий storage.

В чем его суть? Это не key-value-хранилище, это value-хранилище. Когда вы заливаете туда какой-то объект или файл, он вам отвечает ключом, по которому потом можно забрать этот файл. Что это дает? Теоретически — стопроцентную доступность на запись, если у вас в хранилище есть свободное место. Если у вас лежат одни машинки, вы просто пишете в другие, которые не лежат, на которых есть свободное место, получаете другие ключи и по ним спокойно забираете свои данные.
Этот storage очень легко масштабируется, можно закидывать его железом, он будет работать. Он очень простой, надежный. Его единственный недостаток: клиент не управляет ключом и все клиенты должны хранить где-то у себя ключи, хранить маппинг своих ключей. Всем это неудобно. По сути, это очень похожая для всех клиентов задача, и каждый решает ее по своему в своих метабазах и т. д. Это неудобно. Но в то же время не хочется потерять надежность и простоту этого storage, по сути оно работает со скоростью сети.
Тогда мы начали смотреть на S3. Это key-value storage, клиент управляет ключом, все хранилище делится на так называемые бакеты. В каждом бакете пространство ключей от минус бесконечности до плюс бесконечности. Ключ — это какая-то текстовая строка. И мы на нем остановились, на этом варианте. Почему S3?
Все достаточно просто. К этому моменту уже написано много готовых клиентов для всевозможных языков программирования, уже написано много готовых инструментов для хранения чего-нибудь в S3, скажем, бэкапов баз данных. Андрей рассказывал про один из примеров. Там уже достаточно продуманное API, которое годами обкатывалось на клиентах, и ничего там придумывать не надо. API имеет много удобных фич типа листингов, мультипарт-аплоадов и так далее. Поэтому решили остановиться на нем.
Как из нашего storage сделать S3? Что приходит в голову? Так как клиенты сами хранят у себя маппинг ключей, мы просто возьмем, поставим рядом БД, и будем в ней хранить маппинг этих ключей. При чтении просто будем находить ключи и storage в нашей базе данных, и отдавать клиенту то, что он хочет. Если изобразить это схематически, как происходит заливка?

Есть некая сущность, здесь она называется Proxy, так называемый бэкенд. Он принимает файл, заливает его в storage, получает оттуда ключ и сохраняет его в БД, Все достаточно просто.
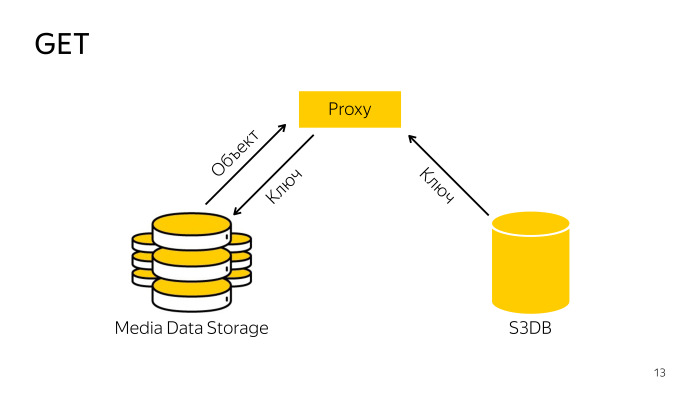
Как происходит получение? Прокси находит в базе нужный ключ, идет с ключом в storage, скачивает оттуда объект, отдает его клиенту. Все тоже просто.
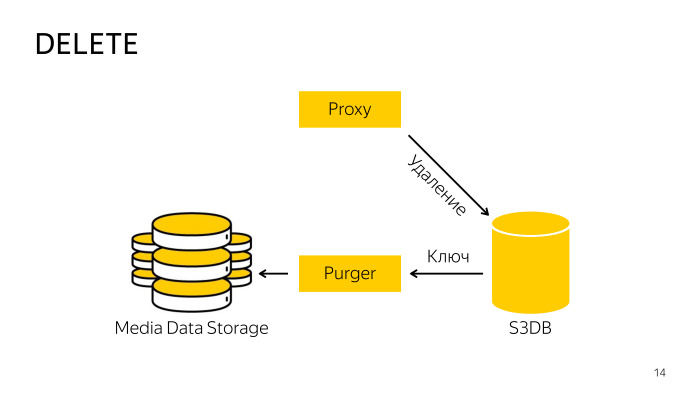
Как происходит удаление? Прокси при удалении напрямую со storage не работает, так как тут трудно координировать базу и storage, поэтому он просто идет в БД, говорит ей, что этот объект удален, там объект перемещается в очередь на удаление, и потом в фоновом режиме специально обученный профессионал-робот забирает эти ключи, удаляет их из storage и из базы. Тут все тоже достаточно просто.
В качестве БД для этой метабазы мы выбрали PostgreSQL.
Вы уже знаете, что мы его очень любим. С переездом Яндекс.Почты у нас накопилась достаточная экспертиза по PostgreSQL, и когда переезжали разные почтовые сервисы, у нас выработалось несколько так называемых шаблонов шардирования. На один из них хорошо лег S3 с небольшими изменениями, но он хорошо туда подошел.
Какие есть варианты шардирования? Это большое хранилище, в масштабах Яндекс сразу надо думать, что объектов будет много, надо сразу продумывать, как это все шардировать. Можно шардировать по хэшу от имени объекта, это самый надежный способ, но он здесь не будет работать, потому что S3 имеет, например, листинги, которые должны показывать список ключей в отсортированном порядке, когда вы захэшируете, у вас все сортировки пропадут, надо вынимать все объекты, чтобы выдача соответствовала спецификации API.
Следующий вариант, можно шардироваться по хэшу от имени или id бакета. Один бакет может жить внутри одного шарда БД.
Еще вариант — шардировать по диапазонам ключей. Внутри бакета пространство от минус бесконечности до плюс бесконечности, мы можем его разбить на сколько угодно диапазонов, этот диапазон мы называем чанк, он может жить только в одном шарде.

Мы выбрали третий вариант, шардирование по чанкам, потому что чисто теоретически в одном бакете может быть бесконечное количество объектов, и он тупо не влезет в одну железку. Тут будут большие проблемы, так мы разрежем и разложим по шардам так, как нам угодно. Здесь все.

Что получилось? Вся БД состоит из трех компонентов. S3 Proxy — группа хостов, там тоже БД. PL/Proxy стоят под балансером, туда летят запросы от того бэкенда. Дальше S3Meta, такая группа бас, в которой хранится информация про бакеты и про чанки. И S3DB, шарды, где хранятся объекты, очередь на удаление. Если изобразить схематически, то выглядит так.
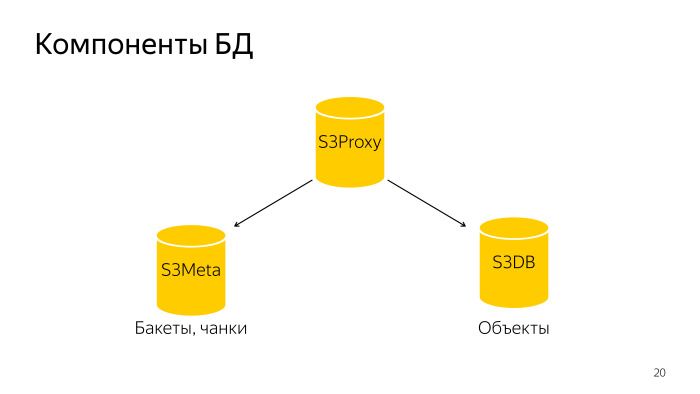
В S3Proxy приходит запрос, он ходит в S3Meta и в S3DB и выдает наверх информацию.

Рассмотрим подробнее. S3Proxy, внутри него созданы функции на процедурном языке PLProxy, это такой язык, который позволяет вам выполнять удаленно хранимые процедуры или запросы. Вот так примерно выглядит код функции ObjectInfo, по сути, Get запрос.
Кластер по LProxy имеет оператор Cluster, в данном случае это db_ro. Что это значит?

Если типичная конфигурация шарда БД, есть мастер и две реплики. Master входит в кластер db_rw, все три хоста входят в db-ro, это куда можно послать read only запрос, а в db_rw посылается запрос на запись. В кластер db_rw входят все мастера всех шардов.
Следующий оператор RUN ON, он принимает либо значение all, значит, выполнить на всех шардах, либо массив, либо какой-то шард. В данном случае он принимает на вход результат функции get_object_shard, это номер шарда, на котором лежит данный объект.
И target — какую функцию вызывать на удаленном шарде. Он вызовет эту функцию и подставит туда аргументы, которые прилетели в эту функцию.

Функция get_object_shard тоже написана на PLProxy, уже кластер meta_ro, запрос полетит на шард S3Meta, который вернет эту функцию get_bucket_meta_shard.
S3Meta может тоже шардироваться, мы тоже это заложили, пока это неактуально, но возможность есть. И вызовет функцию get_object_shard на S3Meta.

get_bucket_meta_shard — это просто хэш текста от имени бакета, S3Meta мы пошардировали просто по хэшу от имени бакета.

Рассмотрим S3Meta, что в ней происходит. Самая важная информация, которая там есть, это таблица с чанками. Я немного вырезал ненужную информацию, самое главное осталось — это bucket_id, начальный ключ, конечный и шард, в котором лежит этот чанк.

Как по такой таблице мог бы выглядеть запрос, который нам вернет чанк, в котором лежит, например, объект test? Примерно вот так. Минус бесконечность в текстовом виде, мы представили ее в качестве значения null, здесь есть такие тонкие моменты, что нужно проверять start_key и end_key на is Null.

Запрос выглядит не очень, а план выглядит еще хуже. Как один из вариантов плана такого запроса, BitmapOr. И 6000 костов такой план стоит.

Как можно по-другому? Есть такая замечательная штука в PostgreSQL как gist index, который умеет индексировать range тип, диапазон по сути, то что нам нужно. Мы сделали такой тип, функция s3.to_keyrange нам возвращает нам, по сути, диапазон. Мы можем оператором contains проверить, найти чанк, в который входит наш ключ. И по такому здесь построен exclude constrain, который обеспечивает непересечение этих чанков. Нам нужно допустить, желательно на уровне БД, каким-либо constraint сделать так, чтобы чанки не могли пересекаться между собой, чтобы только одна строка возвращалась в ответ на запрос. Иначе это будет уже не то, что мы хотели. Так выглядит план такого запроса, обычный index_scan. Это условие полностью влазит в index condition, и такой план имеет всего 700 костов, в 10 раз меньше.

Что такое Exclude Constraint?

Давайте создадим тестовую таблицу с двумя колонками, и повестим на нее два constraint, один уникальный, который все знают, и один exclude constraint, у которого есть параметры равно, такие операторы. Зададим с двумя операторами равно, построилась такая табличка.

Дальше пытаемся вставить две одинаковые строки, получаем ошибку нарушения уникальности ключа на первом constraint. Если мы дропнем его, то мы нарушили уже exclusion constraint. Это общий случай уникального constraint.

На самом деле, уникальный constraint — это тот же exclude constraint с операторами равно, но в случае exclude constraint можно построить какие-то более общие случаи.

У нас есть такие индексы. Если присмотритесь, увидите, что это оба gist index, и вообще они одинаковые. Вы, наверное, спросите, зачем вообще дублировать это дело. Я вам расскажу.

Индексы — такая штука, особенно gist index, что таблица живет своей жизнью, происходят апдейты, делиты и так далее, index там портится, перестает быть оптимальным. И есть такая практика, в частности расширение pg repack, индексы перестраивают периодически, раз в какое-то время их перестраивают.
Как перестроить индекс под уникальным constraint? Создать create index currently, такой же индекс создать спокойно рядом без блокировки, и дальше выражением alter table от constraint user_index такой-то. И все, здесь все четко и хорошо, это работает.
В случае exclude constraint, перестроить его можно только через reindex блокировкой, точнее у вас индекс эксклюзивно заблокируется, и на самом деле у вас останутся все запросы. Это неприемлемо, gist index может строиться достаточно долго. Поэтому мы держим рядом второй индекс, который меньше по объему, занимает меньше места, планер использует его, и тот индекс мы можем перестраивать конкурентно без блокировки.
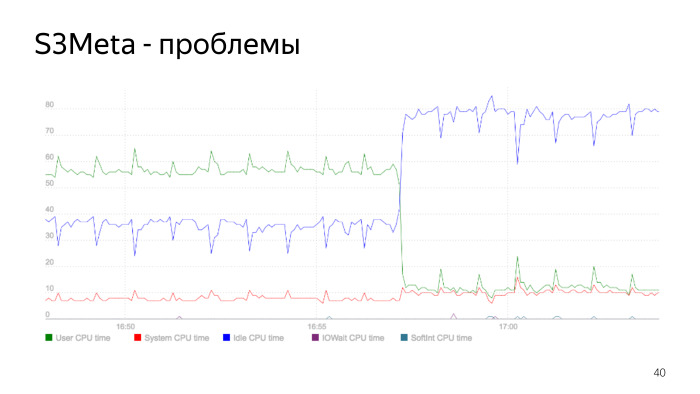
Здесь график потребления процессора. Зеленая линия — потребление процессора в user_space, она скачет от 50% до 60%. В этот момент потребление резко падает, это момент, когда перестраивается индекс. Мы индекс перестроили, старый удалили, у нас потребление процессора резко упало. Это проблема gist index, она есть, и это наглядный пример, как такое может быть.
Когда мы все это делали, мы начинали на версии 9.5 S3DB, по плану планировали укладывать по 10 млрд объектов в каждый шард. Как вы знаете, больше 1 млрд и еще раньше начинаются проблемы, когда в таблице много строк, все становится гораздо хуже. Есть практика партционирования. На тот момент было два варианта, либо стандартный через наследование, но это работает не очень, так как там линейная скорость выбора партиции. А судя по количеству объектов, партиций нам нужно много. Ребята из PostgreSQLPro тогда активно пилили расширение pg_pathman.

Мы выбрали pg_pathman, у нас не было другого выбора. Даже версия 1.4. И как видите, мы используем 256 партиций. Разбили всю таблицу объектов на 256 партиций.
Что делает pg_pathman? Таким выражением можно создать 256 партиций, которые партиционируются по хэшу от колонки bid.

Как работает pg_pathman?
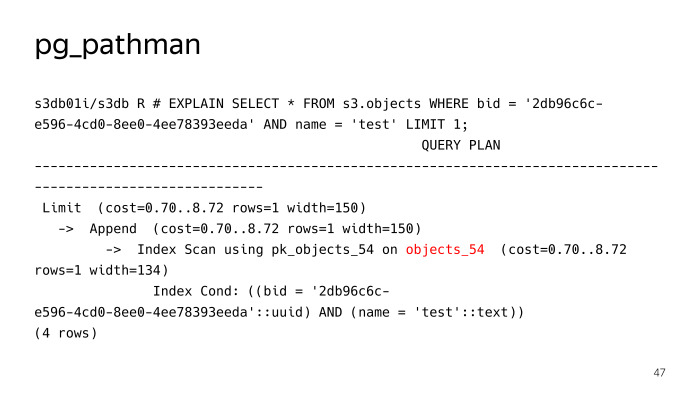
Регистрирует в планере свои хуки, и дальше на запросах подменяет, по сути, план. Мы видим, что на обычный запрос поиска объекта с именем test он не искал по 256 партициям, а сразу определили, что нужно в таблицу objects_54 лезть, но тут было не все гладко, у pg_pathman есть свои проблемы. Во-первых, там было достаточно много багов в начале, пока он пилился, но спасибо ребятам из PostgreSQLPro, они их оперативно чинили и фиксили.
Первая проблема — сложность его обновления. Вторая проблема — prepared statements.
Рассмотрим подробнее. В частности обновление. Из чего состоит pg_pathman?

Он состоит, по сути, из С-кода, который пакуется в библиотеку. И состоит из SQL-части, всякие функции создания партиций и так далее. Плюс еще интерфейсы к сишным функциям, которые лежат в библиотеке. Вот эти две части нельзя обновить одновременно.
Отсюда вытекают сложности, примерно такой алгоритм обновления версии pg_pathman, мы сначала катим новый пакет с новой версией, но у PostgreSQL загружены еще в памяти старые версии, он использует ее. Это уже сразу же в любом случае базу надо рестартить.
Дальше вызываем функцию set_enable_parent, она включает функцию в родительской таблице, которая по умолчанию выключена. Дальше выключаем pathman, перезапускаем базу, говорим ALTER EXTENSION UPDATE, в это время у нас падает все в родительскую таблицу.
Дальше включаем pathman, и запускаем функцию, которая есть в extension, которая перекладывает объекты из родительской таблицы, которые за этот короткий промежуток времени туда нападали, перекладывает обратно в таблицы, где они должны лежать. И дальше выключаем использование родительской таблицы, поиск в нем.

Следующая проблема — prepared statements.

Если мы запрепарим такой же обычный запрос, поиск по bid и ключу, попробуем его повыполнять. Выполняем пять раз — все хорошо. Выполняем шестой — видим такой план. И в этом плане видим все 256 партиций. Если посмотреть внимательно на эти условия, мы здесь видим доллар 1, доллар 2, это так называемый генерик план, общий план. Первые пять запросов планы строились индивидуально, использовались индивидуальные планы для этих параметров, pg_pathman мог сразу определить, потому что параметр заранее известен, мог сразу определить таблицу, куда надо идти. В этом случае он этого сделать не может. Соответственно, в плане должны быть все 256 партиций, а когда экзекьютор пойдет такое исполнять, он пойдет и будет брать shared log на все 256 партиций, и производительность такого решения сразу же не годится. Она просто теряет все свои преимущества, и любой запрос выполняется безумно долго.

Как мы вышли из этого положения? Пришлось все завернуть внутри хранимых процедур в execute, в динамическую SQL, чтобы не использовались prepared statements и план каждый раз строился. Так все работает.
Минус в том, что вам придется весь код запихивать в такие конструкции, которые трогают эти таблицы. Здесь такое сложнее читать.

Как происходит распределение объектов? В каждом шарде S3DB хранятся счетчики чанков, там тоже есть информация о том, какие чанки в этом шарде лежат, и для них хранятся счетчики. На каждую мутирующую операцию над объектом — добавление, удаление, изменение, перезапись — изменяются эти счетчики для чанка. Чтобы не апдейтить одну и ту же строчку, когда в этот чанк идет активная заливка, мы используем достаточно стандартный прием, когда мы делаем insert дельта-счетчика в отдельную таблицу, и раз в минуту специальный робот проходит и агрегирует все это, апдейтит счетчики у чанка.

Дальше эти счетчики с некоторой задержкой доставляются на S3Meta, там уже есть полная картина о том, сколько в каком чанке счетчиков, дальше это можно смотреть распределение по шардам, сколько в каком шарде объектов, и на основании этого принимается решение, куда попадает новый чанк. Когда вы создаете бакет, для бакета по умолчанию создается единственный чанк от минус бесконечности до плюс бесконечности, в зависимости от текущего распределения объектов, которое знает S3Meta, он попадает в какой-либо шард.
Когда вы заливаете в этот бакет данные, все эти данные льются в этот чанк, при достижении определенного размера приходит специальный робот и делит этот чанк.

Мы делаем так, чтобы эти чанки были небольшие. Делаем это для того, чтобы в случае чего этот небольшой чанк можно было перетащить в другой шард. Как происходит сплит чанка? Вот обычный робот, он идет и двухфазным коммитом сплитит этот чанк в S3DB и обновляет информацию в S3Meta.
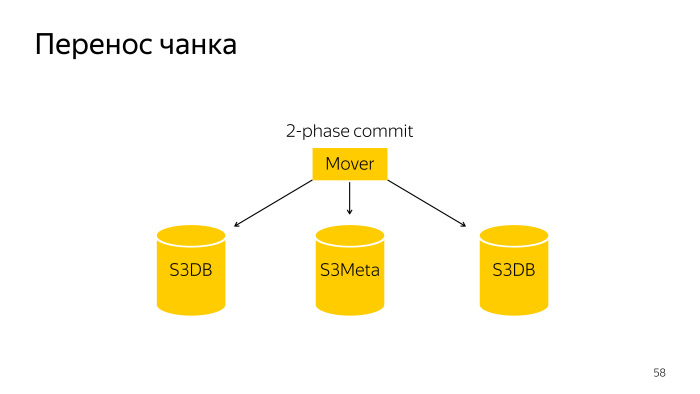
Перенос чанка — это чуть более сложная операция, это двухфазный коммит над тремя базами, S3Meta и двумя шардами, S3DB, из одного тащится, в другой складывается.

В S3 есть такая фича, как листинги, это самая сложная штука, и с ней тоже возникли проблемы. По сути, листинги, это вы говорите S3 — покажи мне объекты, которые у меня лежат. Красным выделен параметр, который сейчас имеет значение Null. Этот параметр, делиметр, разделитель, вы можете указать, листинги с каким разделителем вы хотите.
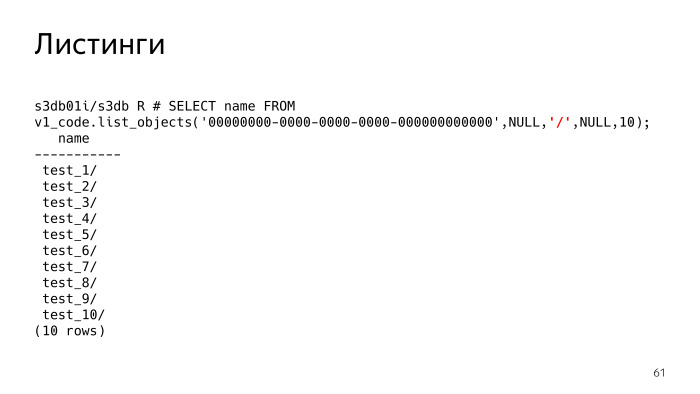
Что это значит? Если делиметр не задан — мы видим, что нам просто отдается список файлов. Если мы задаем делиметр, по сути, S3 должно нам показать папки. Должно сообразить, что здесь есть такие папки, и по сути, показывает все папки и файлы в текущей папке. Текущая папка задается префиксом, этот параметр здесь Null. Мы видим, что там лежит 10 папок.
Все ключи не хранятся в какой-то иерархической структуре древовидной, как в файловой системе. Каждый объект хранится строкой, и у них простой общий префикс. S3 должно само понять, что это попка.

Такая логика достаточно плохо ложится на декларативной SQL, ее достаточно легко описать императивным кодом. Первый вариант был сделан именно так, просто хранимые процедуры на PL/pgSQL. Он императивно обрабатывал эту логику в цикле, требовал уровня repeatable read. Мы должны видеть только один снимок, все запросы исполнять с одним снапшотом. Иначе, если кто-то после первого запроса туда что-то зальет, мы получим неконсистентные листинги.
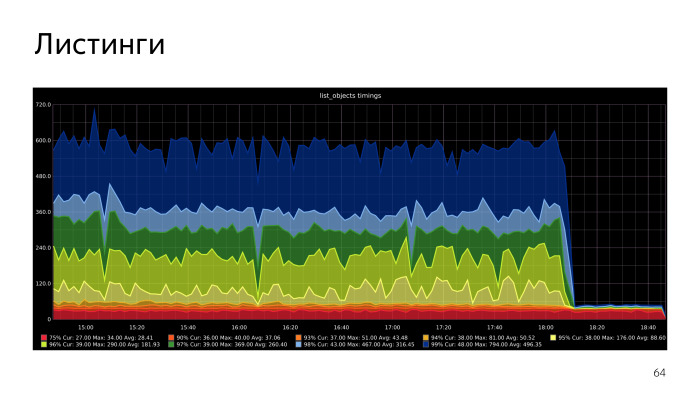
Потом нам удалось переписать все это на Recursive CTE, он получился очень громоздкий со сложной логикой, там без пол-литра не разберешься, а еще все это обернуто в execute внутри PL/pgSQL. Зато получили ускорение, в некоторых случаях до ста раз. Здесь приведены, например, графики перцентилей, таймингов ответа функции list objects. То, что было до и после.
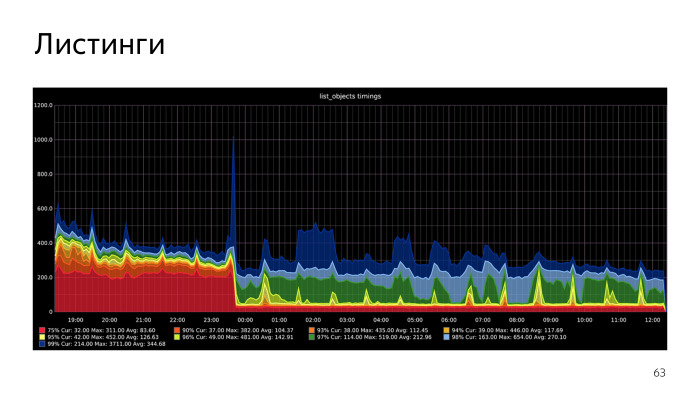
Эффект визуально ощутимый, и по нагрузке тоже.
Мы проводили оптимизацию в несколько этапов. Вот еще один график еще одной оптимизации, когда у нас высокие квантили просто упали до низких.
Для тестирования мы используем Docker, про Behave и тестирование Behave есть замечательный доклад Александра Клюева. Обязательно посмотрите, все очень удобно, понятно, тесты писать теперь счастье.
У нас есть что еще пооптимизировать. Самая острая проблема, как я вам показывал, это потребление CPU на S3Meta. Gist index съедает очень много CPU, особенно когда он становится неоптимально построенным после многочисленных апдейтов, делитов. CPU на S3Meta явно не хватает. Можно штамповать реплики, но это будет неэффективная утилизация железа. У нас есть группа хостов с PLProxy под балансером, которые стоят и удаленно вызывают функции на S3Meta и S3DB. По сути, там процессор можно заставить сжечь прокси. Для этого нужно организовать логическую репликацию этих чанков с S3Meta на все прокси. В принципе, мы этим планируем заняться.
В логической репликации есть ряд проблем, которые мы решим, попробуем это дотолкать до апстрима. Второй вариант — можно отказаться от гиста, попробовать положить этот текстовый range в btree. Это не одномерный тип, а btree работает только с одномерными типами. Но условие того, что чанки у нас не должны пересекаться, позволит наш кейс положить в btree. Мы буквально вчера сделали прототип, который работает. Он реализован на PL/pgSQL-функциях. Мы получили заметное ускорение, будем оптимизировать в этом направлении.
Комментариев нет:
Отправить комментарий