
Фотография: Brian Evans, CC BY-SA 2.0
Умение быстро отбрасывать пакеты очень важно в противостоянии DDoS-атакам.
Отбрасывание пакетов, достигающих наших серверов, может быть выполнено на нескольких уровнях. Каждый способ имеет свои плюсы и минусы. Под катом мы рассмотрим всё, что мы опробовали.
Примечание переводчика: в выводе некоторых представленных команд были удалены лишние пробелы для сохранения читаемости.
Для удобства сравнения способов мы предоставим вам немного цифр, однако, не стоит воспринимать их слишком буквально, ввиду искусственности тестов. Мы воспользуемся одним из наших Intel-серверов с 10Гбит/с сетевой картой. Остальные характеристики сервера не так важны, потому что мы хотим акцентировать внимание на ограничениях системы, а не железа.
Наши тесты будут выглядеть следующим следующим образом:
- Мы создаём нагрузку из огромного количества маленьких UDP-пакетов, достигая значения 14 миллионов пакетов в секунду;
- Весь этот трафик направляется на одно ядро процессора выбранного сервера;
- Мы замеряем количество обработанных ядром пакетов на одном ядре процессоре.
Искусственный трафик генерируется таким образом, чтобы создать максимальную нагрузку: используются случайные IP-адрес и порт отправителя. Вот примерно так это выглядит в tcpdump:
$ tcpdump -ni vlan100 -c 10 -t udp and dst port 1234
IP 198.18.40.55.32059 > 198.18.0.12.1234: UDP, length 16
IP 198.18.51.16.30852 > 198.18.0.12.1234: UDP, length 16
IP 198.18.35.51.61823 > 198.18.0.12.1234: UDP, length 16
IP 198.18.44.42.30344 > 198.18.0.12.1234: UDP, length 16
IP 198.18.106.227.38592 > 198.18.0.12.1234: UDP, length 16
IP 198.18.48.67.19533 > 198.18.0.12.1234: UDP, length 16
IP 198.18.49.38.40566 > 198.18.0.12.1234: UDP, length 16
IP 198.18.50.73.22989 > 198.18.0.12.1234: UDP, length 16
IP 198.18.43.204.37895 > 198.18.0.12.1234: UDP, length 16
IP 198.18.104.128.1543 > 198.18.0.12.1234: UDP, length 16
На выбранном сервере все пакеты будут становиться в одну RX-очередь и, следовательно, обрабатываться одним ядром. Мы добиваемся этого с помощью аппаратного управления потоком:
ethtool -N ext0 flow-type udp4 dst-ip 198.18.0.12 dst-port 1234 action 2
Тестирование производительности — сложный процесс. Когда мы готовили тесты, мы заметили, что наличие активных raw-сокетов негативно влияет на производительность, поэтому перед запуском тестов необходимо удостовериться, что ни один
tcpdump не запущен. Есть простой способ проверить наличие плохих процессов:
$ ss -A raw,packet_raw -l -p|cat
Netid State Recv-Q Send-Q Local Address:Port
p_raw UNCONN 525157 0 *:vlan100 users:(("tcpdump",pid=23683,fd=3))
Ну и наконец мы отключаем Intel Turbo Boost на нашем сервере:
echo 1 | sudo tee /sys/devices/system/cpu/intel_pstate/no_turbo
Несмотря на то, что Turbo Boost — прекрасная штука и увеличивает пропускную способность по крайней мере на 20%, он значительно портит стандартное отклонение в наших тестах. Со включенным turbo отклонение достигают ±1.5%, в то время как без него всего 0.25%.
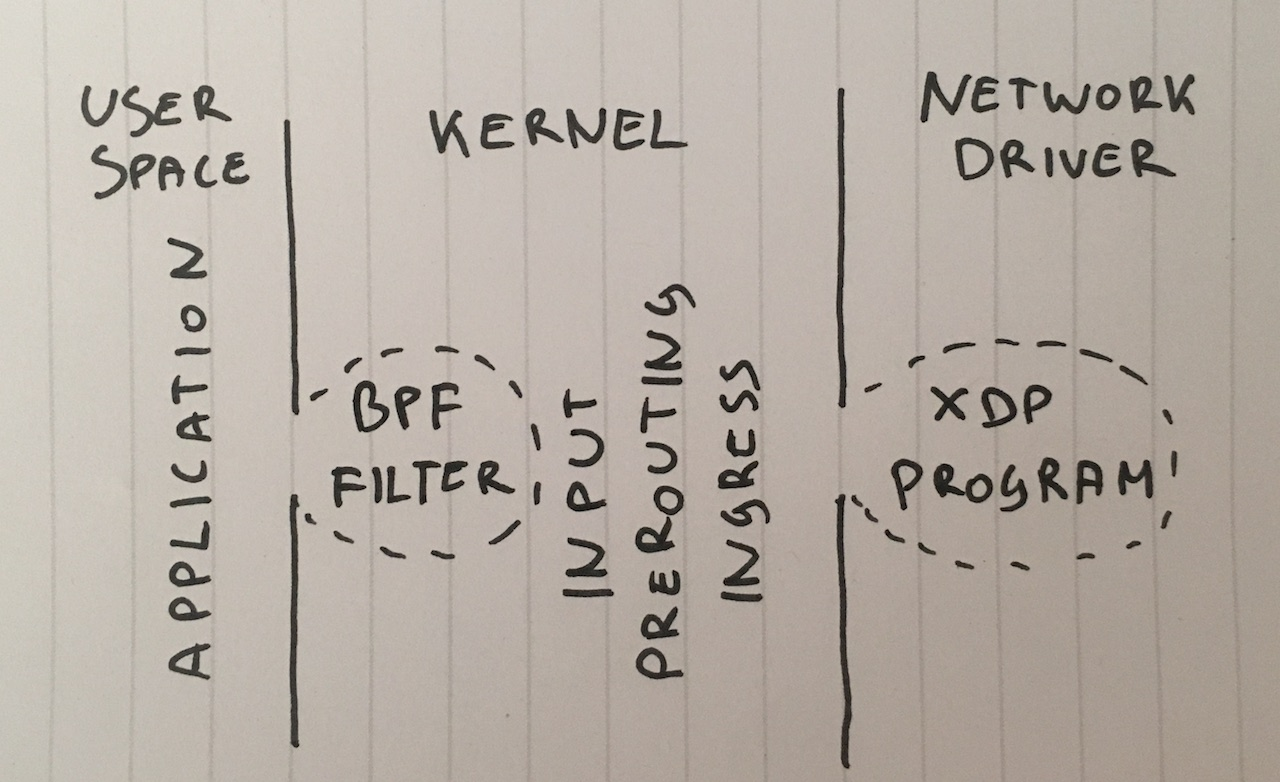
Шаг 1. Отбрасывание пакетов в приложении
Начнём с идеи доставлять все пакеты в приложение и игнорировать их там. Для честности эксперимента убедимся, что iptables никак не влияют на производительность:
iptables -I PREROUTING -t mangle -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT
iptables -I PREROUTING -t raw -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT
iptables -I INPUT -t filter -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT
Приложение — простой цикл, в котором пришедшие данные тут же выбрасываются:
s = socket.socket(AF_INET, SOCK_DGRAM)
s.bind(("0.0.0.0", 1234))
while True:
s.recvmmsg([...])
Мы уже подготовили код, запускаем:
$ ./dropping-packets/recvmmsg-loop
packets=171261 bytes=1940176
Такое решение позволяет ядру забирать всего 175 тысяч пакетов из очереди аппаратного обеспечения, как и было измерено утилитами
ethtool и нашей mmwatch:
$ mmwatch 'ethtool -S ext0|grep rx_2'
rx2_packets: 174.0k/s
Технически, на сервер приходит 14 миллионов пакетов в секунду, однако, одно ядро процессора не справляется с таким объёмом.
mpstat подтверждает это:
$ watch 'mpstat -u -I SUM -P ALL 1 1|egrep -v Aver'
01:32:05 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
01:32:06 PM 0 0.00 0.00 0.00 2.94 0.00 3.92 0.00 0.00 0.00 93.14
01:32:06 PM 1 2.17 0.00 27.17 0.00 0.00 0.00 0.00 0.00 0.00 70.65
01:32:06 PM 2 0.00 0.00 0.00 0.00 0.00 100.00 0.00 0.00 0.00 0.00
01:32:06 PM 3 0.95 0.00 1.90 0.95 0.00 3.81 0.00 0.00 0.00 92.38
Как мы можем видеть, приложение не является узким местом: CPU#1 используется на 27.17% + 2.17%, в то время как обработка прерываний занимает 100% на CPU#2.
Использование recvmessagge(2) играет важную роль. После обнаружения уязвимости Spectre системные вызовы стали ещё более дорогими из-за используемых в ядре KPTI и retpoline
$ tail -n +1 /sys/devices/system/cpu/vulnerabilities/*
==> /sys/devices/system/cpu/vulnerabilities/meltdown <==
Mitigation: PTI
==> /sys/devices/system/cpu/vulnerabilities/spectre_v1 <==
Mitigation: __user pointer sanitization
==> /sys/devices/system/cpu/vulnerabilities/spectre_v2 <==
Mitigation: Full generic retpoline, IBPB, IBRS_FW
Шаг 2. Убийство conntrack
Мы специально сделали такую нагрузку с разными IP и портом отправителя, чтобы как можно сильнее нагрузить conntrack. Количество записей в conntrack во время теста стремится к максимально возможному и мы можем в этом убедиться:
$ conntrack -C
2095202
$ sysctl net.netfilter.nf_conntrack_max
net.netfilter.nf_conntrack_max = 2097152
Более того, в
dmesg так же можно увидеть крики conntrack:
[4029612.456673] nf_conntrack: nf_conntrack: table full, dropping packet
[4029612.465787] nf_conntrack: nf_conntrack: table full, dropping packet
[4029617.175957] net_ratelimit: 5731 callbacks suppressed
Так давайте отключим его:
iptables -t raw -I PREROUTING -d 198.18.0.12 -p udp -m udp --dport 1234 -j NOTRACK
И перезапустим тесты:
$ ./dropping-packets/recvmmsg-loop
packets=331008 bytes=5296128
Это позволило дойти нам до отметки в 333 тысячи пакетов в секунду. Ура!
P.S. С использованием SO_BUSY_POLL мы можем достичь целых 470 тысяч в секунду, однако, это тема для отдельного поста.
Шаг 3. Пакетный фильтр Беркли
Идём дальше. Зачем нам доставлять пакеты в приложение? Хотя это не является распространённым решением, мы можем привязать классический пакетный фильтр Беркли к сокету вызовом
setsockopt(SO_ATTACH_FILTER) и настроить фильтр отбрасывать пакеты ещё в ядре.Подготовим код, запускаем:
$ ./bpf-drop
packets=0 bytes=0
С использованием пакетного фильтра (классический и расширенный фильтры Беркли дают примерно схожую производительность) мы добираемся до примерно 512 тысяч пакетов в секунду. Более того, отбрасывание пакета во время прерывания освобождает процессор от необходимости будить приложение.
Шаг 4. iptables DROP после маршрутизации
Теперь мы можем отбрасывать пакеты, добавив в iptables в цепочку INPUT такое правило:
iptables -I INPUT -d 198.18.0.12 -p udp --dport 1234 -j DROP
Напомню, что мы уже отключили conntrack правилом
-j NOTRACK. Эти два правила дают нам 608 тысяч пакетов в секунду.
Посмотрим на числа в iptables:
$ mmwatch 'iptables -L -v -n -x | head'
Chain INPUT (policy DROP 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
605.9k/s 26.7m/s DROP udp -- * * 0.0.0.0/0 198.18.0.12 udp dpt:1234
Ну что ж, неплохо, но мы можем лучше.
Шаг 5. iptabes DROP в PREROUTING
Более быстрая техника — отбрасывать пакеты ещё до маршрутизации с помощью такого правила:
iptables -I PREROUTING -t raw -d 198.18.0.12 -p udp --dport 1234 -j DROP
Это позволяет нам отбрасывать солидные 1.688 миллиона пакетов в секунду.
На самом деле, это немного удивительный скачок в производительности. Я так и не понял причин, возможно наша маршрутизация сложная, а может просто баг в конфигурации сервера.
В любом случае, «сырые» iptables работают значительно быстрее.
Шаг 6. nftables DROP
Сейчас утилита iptables уже немного старая. Ей на смену пришла nftables. Ознакомьтесь с этим видео-объяснением, почему nftables — топ. Nftables обещается быть быстрее, чем поседевшая iptables по множеству причин, среди которых слух, что retpoline'ы сильно замедляют iptables.
Но наша статья всё же не о сравнении iptables и nftables, так что давайте просто попробуем самое быстрое, что я смог сделать:
nft add table netdev filter
nft -- add chain netdev filter input { type filter hook ingress device vlan100 priority -500 \; policy accept \; }
nft add rule netdev filter input ip daddr 198.18.0.0/24 udp dport 1234 counter drop
nft add rule netdev filter input ip6 daddr fd00::/64 udp dport 1234 counter drop
Счётчики можно увидеть так:
$ mmwatch 'nft --handle list chain netdev filter input'
table netdev filter {
chain input {
type filter hook ingress device vlan100 priority -500; policy accept;
ip daddr 198.18.0.0/24 udp dport 1234 counter packets 1.6m/s bytes 69.6m/s drop # handle 2
ip6 daddr fd00::/64 udp dport 1234 counter packets 0 bytes 0 drop # handle 3
}
}
Входной хук nftables показал значения около 1.53 миллиона пакетов. Это немногим меньше, чем PREROUTING цепочка в iptables. Но в этом есть и загадка: теоретически, хук nftables идёт раньше, чем PREROUTING iptables и, следовательно, должен обрабатываться быстрее.
В нашем тесте nftables чуть-чуть медленнее чем iptables, но всё равно nftables круче. :P
Шаг 7. tc DROP
Несколько неожиданно, что tc (traffic control) хук происходит раньше, чем iptables PREROUTING. tc позволяет нам отбирать пакеты по простым критериям и, конечно же, отбрасывать их. Синтаксис немного необычный, поэтому для настройки предлагаем использовать этот скрипт. А нам нужно достаточно сложное правило, которое выглядит так:
tc qdisc add dev vlan100 ingress
tc filter add dev vlan100 parent ffff: prio 4 protocol ip u32 match ip protocol 17 0xff match ip dport 1234 0xffff match ip dst 198.18.0.0/24 flowid 1:1 action drop
tc filter add dev vlan100 parent ffff: protocol ipv6 u32 match ip6 dport 1234 0xffff match ip6 dst fd00::/64 flowid 1:1 action drop
И мы можем проверить его в действии:
$ mmwatch 'tc -s filter show dev vlan100 ingress'
filter parent ffff: protocol ip pref 4 u32
filter parent ffff: protocol ip pref 4 u32 fh 800: ht divisor 1
filter parent ffff: protocol ip pref 4 u32 fh 800::800 order 2048 key ht 800 bkt 0 flowid 1:1 (rule hit 1.8m/s success 1.8m/s)
match 00110000/00ff0000 at 8 (success 1.8m/s )
match 000004d2/0000ffff at 20 (success 1.8m/s )
match c612000c/ffffffff at 16 (success 1.8m/s )
action order 1: gact action drop
random type none pass val 0
index 1 ref 1 bind 1 installed 1.0/s sec
Action statistics:
Sent 79.7m/s bytes 1.8m/s pkt (dropped 1.8m/s, overlimits 0 requeues 0)
Хук tc позволил нам отбрасывать до 1.8 миллионов пакетов в секунду на одном ядре. Это прекрасно!
Но мы можем ещё быстрее…
Шаг 8. XDP_DROP
И наконец, наше сильнейшее оружие: XDP — eXpress Data Path. C помощью XDP мы можем запускать код расширенного пакетного фильтра Беркли (extended Berkley Packet Filterm eBPF) прямо в контексте сетевого драйвера и, что самое важное, ещё до выделения памяти под
skbuff, что обещает нам прирост в скорости.
Обычно XDP-проект состоит из двух частей:
- загружаемый код eBPF
- загрузчик, который помещает код в правильный сетевой интерфейс
Написание своего загрузчика — сложное занятие, поэтому просто воспользуемся новой фишкой iproute2 и загрузим код простой командой:
ip link set dev ext0 xdp obj xdp-drop-ebpf.o
Та-дам!
Исходный код загружаемой eBPF-программы доступен здесь. Программа смотрит на такие характеристики IP-пакетов, как UDP-протокол, подсеть отправителя и порт назначения:
if (h_proto == htons(ETH_P_IP)) {
if (iph->protocol == IPPROTO_UDP
&& (htonl(iph->daddr) & 0xFFFFFF00) == 0xC6120000 // 198.18.0.0/24
&& udph->dest == htons(1234)) {
return XDP_DROP;
}
}
XDP-программа должна быть собрана с помощью современного clang, который умеет генерировать BPF-байткод. После этого мы можем загрузить и проверить работоспособность BFP-программы:
$ ip link show dev ext0
4: ext0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 xdp qdisc fq state UP mode DEFAULT group default qlen 1000
link/ether 24:8a:07:8a:59:8e brd ff:ff:ff:ff:ff:ff
prog/xdp id 5 tag aedc195cc0471f51 jited
А после посмотреть статистику в
ethtool:
$ mmwatch 'ethtool -S ext0|egrep "rx"|egrep -v ": 0"|egrep -v "cache|csum"'
rx_out_of_buffer: 4.4m/s
rx_xdp_drop: 10.1m/s
rx2_xdp_drop: 10.1m/s
Ю-ху! С помощью XDP мы можем отбрасывать до 10 миллионов пакетов за секунду!

Фотография: Andrew Filer, CC BY-SA 2.0
Выводы
Мы повторили эксперимент для IPv4 и для IPv6 и подготовили эту диаграмму:
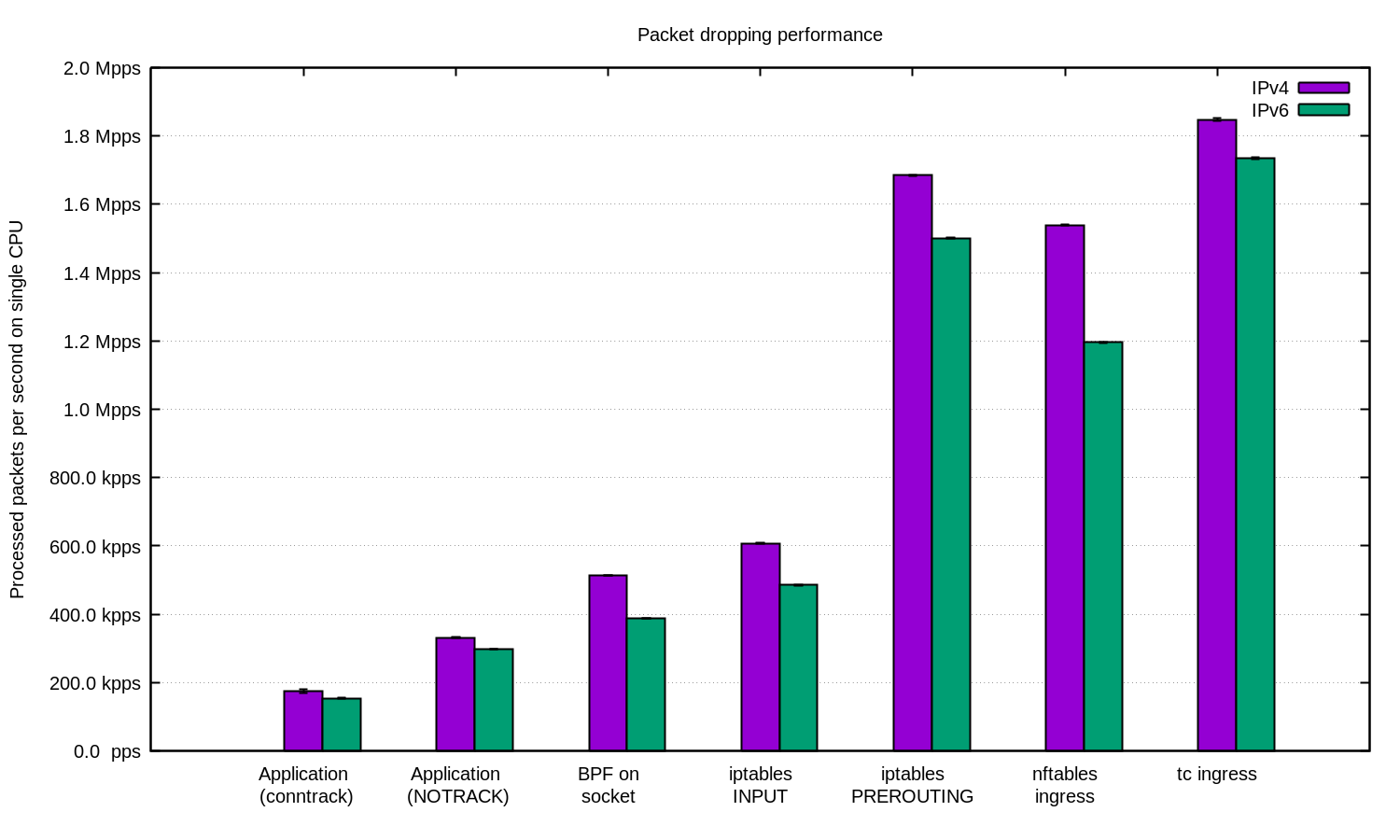
В общем случае можно утверждать, что наша настройка для IPv6 чуть-чуть медленнее. Но так как пакеты IPv6 несколько больше, то и разница в быстродействии ожидаема.
В Linux есть множество способов фильтровать пакеты, каждый со своими быстродействием и сложностью настройки.
Для защиты от DDoS вполне разумно отдавать пакеты в приложение и обрабатывать их там. Хорошо настроенное приложение может показывать хорошие результаты.
Для DDoS-атак со случайным или подменённым IP может быть полезно отключать conntrack, чтобы получить небольшой прирост в скорости, однако осторожно: существуют атаки, против которых conntrack очень полезен.
В остальных случаях есть смысл добавить firewall Linux'а как один из способов смягчения DDoS-атаки. В некоторых случаях лучше пользоваться таблицей "-t raw PREROUTING", так как она значительно быстрее, чем таблица filter.
Для наиболее запущенных случаев мы всегда используем XDP. И да, это очень мощная штука. Вот вам график как выше, только с XDP:
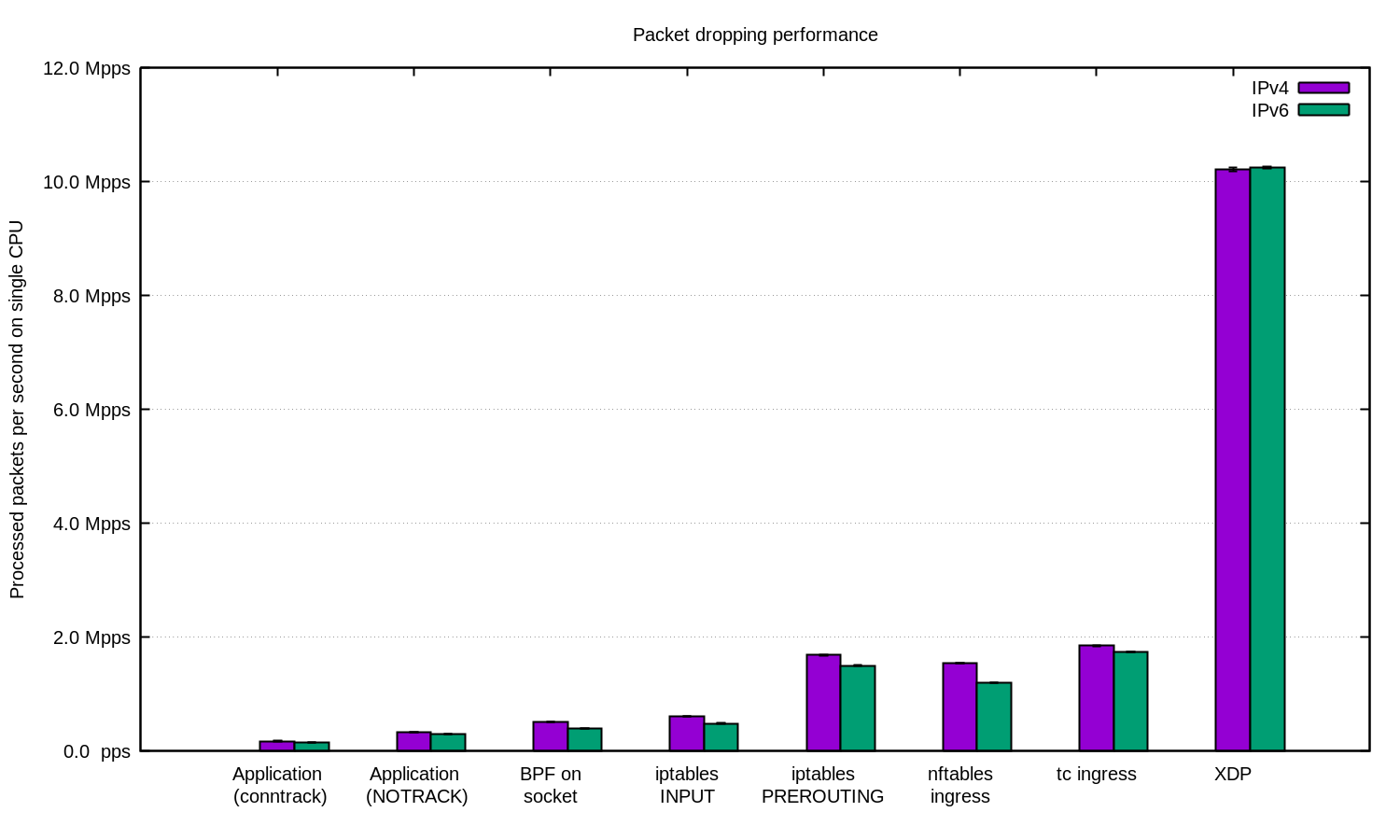
Если вы хотите повторить эксперимент, то вот вам README, в котором мы всё задокументровали.
Мы в CloudFlare используем… почти все из этих техник. Некоторые трюки в пространстве пользователя интегрированы в наши приложения. Техника с iptables встречается в нашем Gatebot. Ну и наконец мы заменяем наш собственное решение в ядре на XDP.
Большое спасибо Jesper Dangaard Brouer за помощь в работе.
Комментариев нет:
Отправить комментарий