
Автоматическое распознавание спутниковых или аэро-снимков — это наиболее перспективный способ получения информации о расположении различных объектов на местности. Отказ от ручной сегментации снимков особенно актуален, когда речь заходит о обработке больших участков земной поверхности в сжатые сроки.
Недавно у меня появилась возможность применить теоретические навыки и попробовать себя в области машинного обучения на реальном проекте сегментации изображений. Цель проекта — распознавание лесных насаждений, а именно крон деревьев на спутниковых снимках высокого разрешения. Под катом я поделюсь полученным опытом и результатами.
Когда речь идёт об обработке изображений, то сегментации можно дать следующее определение — это нахождение на изображении характерных областей, которые одинаково описываются в данном пространстве признаков.
Различают яркостную, контурную, текстурную и семантическую сегментацию.
Семантическая (или смысловая) сегментация изображений заключается в выделении на изображении областей, каждая из которых соответствует определённому признаку. В общем виде задачи семантической сегментации трудно алгоритмизируются, поэтому для сегментации изображений в настоящее время широко используются свёрточные нейронные сети, которые показывают хорошие результаты.
Постановка задачи
Решается задача бинарной сегментации — на вход нейронной сети подаются цветные изображения (спутниковые снимки высокого разрешения), на которых необходимо выделить области пикселей, относящихся к одному классу — деревья.
Исходные данные
В моём распоряжении имелся набор тайлов спутниковых снимков прямоугольной области в которую вписывается полигон. Внутри него и нужно искать деревья. Полигон или мультиполигон представлен в виде GeoJSON файла. В моём случае тайлы были в png формате размером 256 на 256 пикселей в истинном цвете. (увы без ик) Нумерация тайлов в виде /zoom/x/y.png
Гарантируется, что все тайлы в наборе получены из спутниковых снимков, сделанных примерно в одно и то же время года (конец весны – начало осени в зависимости от климата конкретного региона) и суток под схожим углом к поверхности, где допускалось присутствие незначительной рассеянной облачности.
Подготовка данных
Так как площадь нужного полигона может быть меньше данной прямоугольной области, то первым делом необходимо исключить те тайлы, которые выходят за границы полигона. Для этого был написан простой скрипт, которые по полигону из GeoJSON файла выбирает нужные тайлы. Работает он следующим образом. Для начала координаты всех вершин полигона преобразуются в номера тайлов и складываются в массив. Тут же находится смещение относительно начала координат. Для визуального контроля генерируется изображение, где один пиксель равен одному тайлу. Полигон на изображении заливается уже с учётом смещения при помощи PIL. После чего изображение переводится в массив, откуда выбираются нужные тайлы, попавшие внутрь полигона.
from PIL import Image, ImageDraw
# . . .
# Ширина и высота находится из разности номеров правого нижнего и левого верхнего тайлов.
img = Image.new("L", (x, y), 0)
draw = ImageDraw.Draw(img)
# Один пиксель равен тайлу. Пусть нужные тайлы будут белыми. points — вершины полигона.
draw.polygon(points, fill=255)
img.show()
mask = numpy.array(img)
# . . .

Наглядный результат преобразования полигона в набор тайлов
Модель сети
Для решения задач сегментации изображений существует некоторое количество моделей свёрточных нейронных сетей. Я решил использовать U-Net, которая хорошо зарекомендовала себя в задачах бинарной сегментации изображений. Архитектура U-Net состоит из так называемых сжимающих и разжимающих путей (contracting and an expansive path), которые соединены пробросами на соответствующих по размеру стадиях, и сперва уменьшают разрешение картинки, а потом увеличивают его, предварительно объединив с данными картинки и пропустив через другие слои свёртки. Таким образом, сеть выполняет роль своеобразного фильтра. Сжимающий и разжимающий блоки представлены в виде набора блоков определённой размерности. А каждый блок состоит из базовых операций: свёртка, ReLu и max pooling. Существуют реализации модели U-Net на Keras, Tensorflow, Caffe и PyTorch. Я использовал Keras.
Создание обучающей выборки
Для обучения данной модели Unet необходимы изображения. Первым делом в голове возникла идея брать данные OpenStreetMap и генерировать на их основе маски для обучения. Но как оказалось в моём случае, точность нужных мне полигонов оставляет желать лучшего. Так же мне было необходимо наличие единичных деревьев, которые не всегда наносятся на карту. Поэтому от такой затеи пришлось отказаться. Но стоит сказать, для других объектов, например дорог или зданий, такой подход может быть эффективен.

Так как от идеи автоматической генерации обучающей выборки на основе данных OSM пришлось отказаться, я решил вручную разметить небольшой участок местности. Для этого использовал редактор JSOM, где в качестве подложки использовал имеющиеся снимки местности, которые разместил на локальном сервере. Тут всплыла другая проблема — я не нашёл возможности включить отображение сетки тайлов штатными средствами JOSM. Поэтому парой нехитрых строчек в .htaccess на том же сервере с другой директории начал выдавать на любой запрос вида grid_tile/z/x/y.png пустой тайл с пиксельной рамкой и добавил такой импровизированный слой в JOSM. Такой вот велосипед.
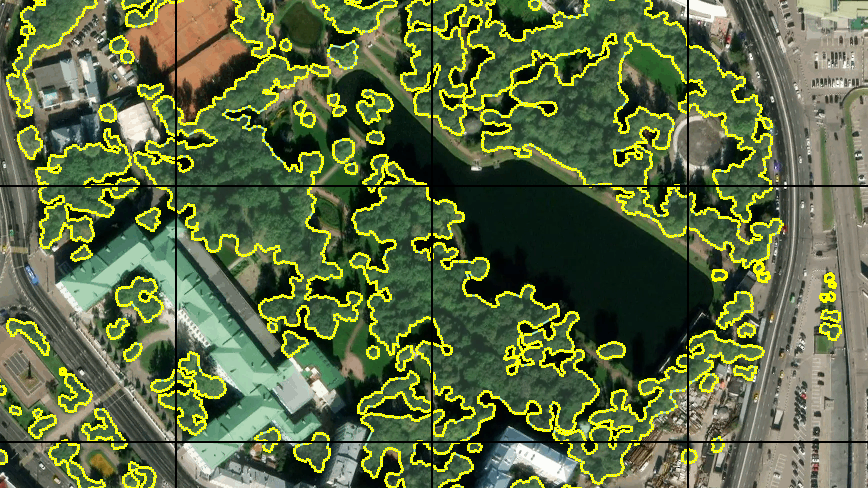
Сперва я разметил около 30 тайлов. С графическим планшетом и «режимом быстрого рисования» в JOSM это не заняло много времени. Я понимал, что этого мало для полноценного обучения, но решил попробовать начать с этого. Тем более обучение на таком количестве данных пройдёт достаточно быстро.
Обучение и первый результат
Сеть обучалась в течение 15 эпох без предварительной аугментации данных. На графике представлены значения потерь и точности на тестовой выборке:
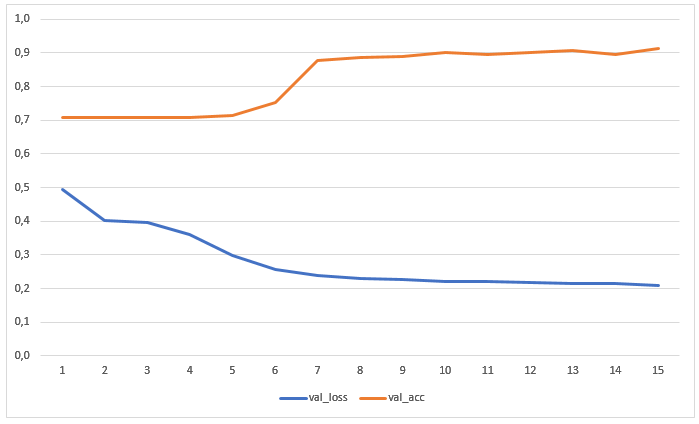
Результат распознавания изображений, которых не было ни в обучающей, ни в тестовой выборке, оказался вполне вменяемым:

После более тщательного изучения результатов выяснились некоторое проблемы. Множество промахов было на теневых участках снимков — сеть либо находила деревья в тени, где их не было, либо в точности наоборот. Это было ожидаемым, так как в обучающей выборке таких примеров было мало. А вот того, что некоторые куски водной поверхности и тёмных крыш из металлопрофиля(предположительно) будут распознаны как деревья, я не ожидал. Так же были неточности с газонами. Было решено улучшить выборку, добавив в неё большее количество изображений со спорными участками, таким образом обучающаяся выборка увеличилась почти в два раза.
Аугментация данных
Дальше увеличивать объём данных я решил поворачивая изображения на произвольный угол. Первым делом я попробовал стандартный модуль keras.preprocessing.image.ImageDataGenerator. При повороте с сохранением маштаба по краям изображений остаются пустые области, заливка которых настраивается параметром fill_mode. Можно просто залить эти области цветом, указав его в cval, но я захотел полноценный поворот, надеясь, что так выборка будет более полной, и реализовал генератор самостоятельно. Это позволило увеличить размер более чем в десять раз.

fill_mode=nearest
Мой генератор данных склеивает четыре соседних тайла в один исходный размером 512x512 px. Угол поворота выбирается случайно, с учётом него вычисляются допустимые интервалы по x и y для центра результирующего тайла, находясь в которых он не выйдет за пределы исходного тайла. Координаты центра выбираются случайно с учётом допустимых интервалов. Конечно же все эти трансформации применяются к паре тайл-маска. Всё это повторяется для различных групп соседних тайлов. С одной группы можно получить более десятка тайлов с разными участками местности повёрнутых под различным углом.
# Поворот изображения и вырезка нужной области
# image — исходное изображение, center (x, y) — центр необходимой области, a — угол в градусах, width и height — размеры результирующего изображения.
shape = image.shape[:2]
matrix = cv2.getRotationMatrix2D( center=center, angle=a, scale=1 )
image = cv2.warpAffine( src=image, M=matrix, dsize=shape )
x = int( center[0] - width/2 )
y = int( center[1] - height/2 )
image = image[ y:y+height, x:x+width ] # результат

Пример результата работы генератора
Обучение на большем объёме данных
В итоге размер обучающей выборки составил 1881 изображений, так же я увеличил число эпох до 30:
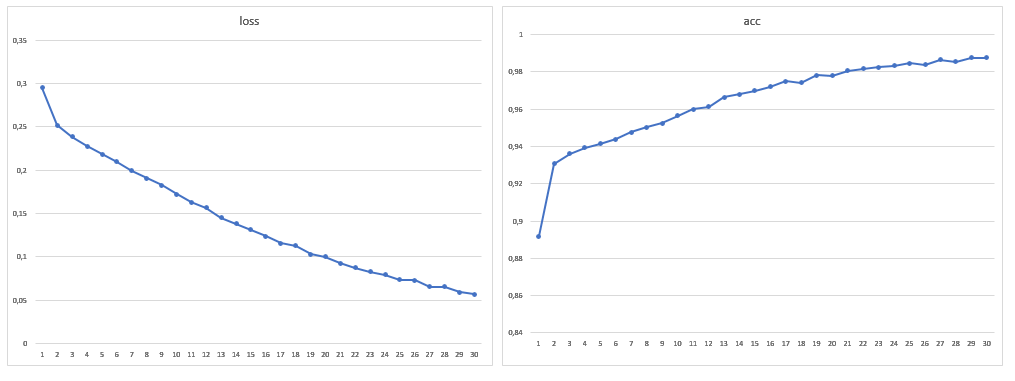
После обучения модели на новом объёме данных проблемы с ошибочной сегментацией крыш и воды больше не обнаруживалось. От ошибок в тени не удалось избавиться совсем, но на глаз их стало меньше, так же как и ошибок с газонами. Нужно заметить, что в общем подавляющее большинство ошибок заключается в том, что сеть видит деревья там, где их нет, а не наоборот. Достигнутая точность может быть улучшена за счёт использования спутниковых снимков с большим количеством каналов и модификации архитектуры сети под конкретную задачу.

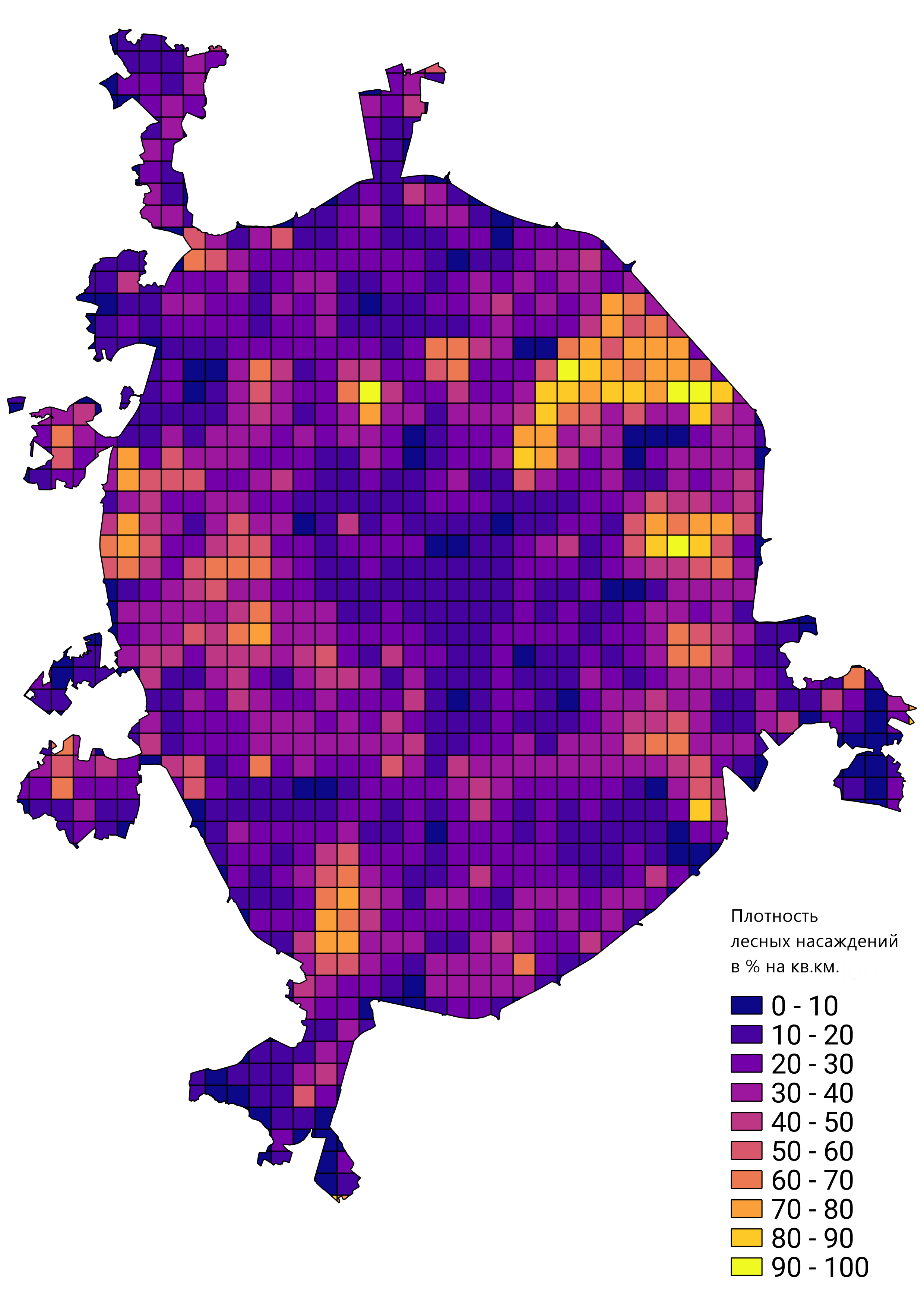
В целом, меня устроил результат проделанной работы, а обученный прототип сети был применён для решения реальных задач. Например, подсчёта плотности лестных насаждений в Москве:
Комментариев нет:
Отправить комментарий