А у нас тут запускается, можно сказать, почти новый курс — Data Scientist. Почему почти? Просто вырос он из курса по BigData, но теперь с куда большим упором в работу с данными, обучением, сети и вот это всё. Новые преподаватели, немного (примерно процентов двадцать) новой программы курсы и доработанной старой, ну и как всегда — статьи, которые нам показались интересными в рамках курса и открытые уроки по этим же темам.
Поехали!

Фотография Lisha Li
Мне очень понравился этот слайд из доклада Andrej Karpathy на Train AI. Он хорошо подчеркивает разницу между deep learning исследованиями и производством. Академические статьи почти целиком посвящены новым и улучшенным моделям, и наборы данных обычно выбираются из небольшого количества доступных публично. Но все мои знакомые, применяющие глубокое обучение как часть приложения, вместо этого тратят большую часть своего времени на проблемы с тренировочными данными.
Для такой фиксации на архитектуре моделей есть много причин, но это значит, что ресурсов, способных помочь людям с машинным обучением в продакшне, очень мало. Мой доклад на конференции был как раз посвящен теме “непомерной эффективности тренировочных данных”, и я хочу развить её в этой статье, объяснить, почему данные настолько важны, и дать несколько полезных советов по их улучшению.
В рамках моей работы я тесно сотрудничаю со многими исследователями и производственными командами. Моя вера в важность улучшения данных основана на больших успехах, достигнутых ими после концентрации на этой стороне создания модели. Большим препятствием в использовании глубокого обучения является получение высокой точности в реальном мире, а улучшение тренировочных данных — самый быстрый путь для повышения точности. Даже если вам мешает что-то ещё (например, латентность, размер хранилища), увеличение точности модели позволяет частично уменьшить проблемы производительности за счет меньшей архитектуры.
Речевые команды
Я не могу поделиться большинством своих наблюдений производственных систем, но есть подходящий открытый пример. В прошлом году я создавал простой пример распознавания речи для TensorFlow и обнаружил полное отсутствие датасетов, которые подошли бы в качестве тренировочных моделей. Благодаря щедрой помощи добровольцев и сайту Open Speech Recording, мне удалось собрать 60 000 односекундных аудиоклипов людей, произносящих короткие слова. Полученная модель оказалось пригодной для использования, но недостаточно точной. Чтобы понять, было ли это проблемой моих ограниченных возможностей как дизайнера модели, я запустил соревнование Kaggle с этим датасетом. Конкурсанты справились гораздо лучше моих наивных моделей, и, несмотря на различие подходов, только нескольким командам удалось достичь точности почти в 91%. Для меня это значило, что в данных есть фундаментальная проблема, и конкурсанты действительно обнаружили много ошибок, например, неправильные метки и обрезанный звук. Это дало мне толчок сосредоточиться на новой версии датасета с исправленными ошибками и большим количеством образцов.
Я посмотрел на метрики ошибок, чтобы понять, какие слова вызвали наибольшее количество проблем у моделей, и оказалось, что категория “Прочее” (когда речь распознавалась, но слова не укладывались в ограничения словаря модели) была особенно проблемной. Я решил увеличить количество уникальных собираемых слов, чтобы обеспечить большее разнообразие тренировочных данных.
Поскольку участники Kaggle сообщали об ошибках в метках, силами краудсорсинга я провел дополнительную верификацию, попросив людей прослушать каждую запись и убедиться, что она соответствует ожидаемой маркировке. Kaggle также выявил тихие и обрезанные файлы, поэтому я написал простую утилиту для аудио-анализа, чтобы автоматически избавиться от особенно плохих образцов. Наконец, даже несмотря на удаление плохих файлов, я увеличил общее количество реплик до 100.000, все благодаря усилиям волонтеров и платного краудсорсинга.
Чтобы помочь другим использовать датасет (и поучиться на моих ошибках!) я описал все в Arxiv статье, добавив обновленные результаты точности. Главный результат — без изменения модели или тестовых данных точность увеличилась более чем на 4%, c 85,4% до 89,7%. Это резкое улучшение отразилось и на гораздо более высоком уровне удовлетворенности людей, использующих модель в демо-приложениях на Android и Raspberry Pi. Уверен, что я бы добился меньшего прогресса, если бы потратил время на правки модели, пусть в настоящий момент я и использую архитектуру, далекую от произведения искусства.
Этот процесс неоднократно обеспечивал отличный результат в настройке продакшна, но иногда бывает сложно понять, с чего начать для достижения того же результата. Некоторые вещи можно понять из того подхода, что я использовал с данными речи, но для большей прозрачности, вот несколько методов, которые я считаю полезными.
Во-первых, посмотрите на свои данные
Это может показаться очевидным, но для начала произвольно посмотрите на тренировочные данные, с которых вы начинаете. Скопируйте пачку файлов на ваш локальный компьютер, потратьте несколько часов на их предпросмотр. Если вы работаете с изображениями, используйте что-то вроде Finder на MacOS для прокрутки миниатюр, так вам удастся быстро отсмотреть тысячи изображений. Для аудио, используйте файловый менеджер для проигрывания превью, а для текстов — сбросьте рандомные их части в терминал. Я не потратил на этого достаточного количества времени при работе с первой версией речевых команд, и поэтому было большинство проблем было выявлено участниками Kaggle.
Каждый раз я чувствую себя немного глупо, выполняя этот процесс, но ни разу еще не пожалел о нем. Всегда находилось что-то критически важное, будь то несбалансированные число примеров в разных категориях, битые данные (например PNG с меткой расширения JPG файла), неправильные метки или просто странные комбинации. Tom White совершил удивительные открытия в ImageNet с помощью инспекции, включая метку “Солнечные очки” для древнего устройства усиливающего солнечный свет, гламурные снимки для “мусоровоза” и предвзятость в отношении женщин-нежити для “плащ”. Andrej вручную проклассифицировал изображения ImageNet и это многому научило меня относительно датасетов, включая, как сложно различать породы собак, даже если ты человек.

Ваши действия зависят от того, что удастся найти, но такую инспекцию необходимо проводить в любом случае перед тем, как начать любую другую зачистку данных. Интуитивное знание содержимого сетов поможет принимать решения на следующих этапах.
Выбирайте модель быстро
Не тратьте много времени на выбор модели. Если вы занимаетесь классификацией изображений, посмотрите AutoML, иначе обратите внимание на что-то вроде репозитария модели TenserFlow или коллекцию примеров Fast.AI, чтобы найти модель, решающую проблему, похожую на вашу. Важно начать итерировать как можно быстрее, чтобы сразу опробовать модель на реальных пользователях и делать это как можно чаще. В процессе вы всегда сможете заменить модель на более совершенную и получить улучшенные результаты, но для начала нужно получить правильные данные. Глубокое обучение до сих пор подчиняется фундаментальным законам вычислений “мусор на входе — мусор на выходе”, поэтому даже лучшие модели будут ограничены недостатками тренировочных данных. Выбрав модель и протестировав ее, вы сможете лучше понять, в чем заключаются эти недостатки и как их исправить.
Чтобы увеличить скорость итерирования, попробуйте взять модель, которая уже была обучена на большом датасете, и используйте transfer learning для ее точной настройки с (скорее всего гораздо меньшим) сетом данных. Обычно это дает лучшие результаты, чем тренировка на маленьком датасете, и вы гораздо быстрее поймете, как улучшить стратегию сбора данных. Самое важное — вам сможете включить фидбэк, полученный из этих результатов, в сам процесс сбора и адаптировать его по мере обучения, а не запускать коллекцию отдельной фазой перед обучением.
Притворяйтесь, пока это не станет правдой
Наибольшая разница между созданием моделей для исследований и производства заключается в том, что исследование в самом начале уже имеет четкую постановку проблемы, а требования для настоящего приложения спрятаны в головах пользователей и могут быть извлечены только с течением времени. Например, для Jetpac мы хотели найти хорошие фотографии для автоматического гида по городам. Мы попросили оценщиков добавить фотографии метку, если они считали ее “Хорошей”, но в итоге получили тонну фотографий улыбающихся людей. Мы использовали эти фотографии в шаблонах продукта, чтобы посмотреть на реакцию тестовых пользователей, и они не были впечатлены или воодушевлены. Чтобы решить проблему, мы уточнили вопрос — “Это фото мотивирует вас отправиться в путешествие сюда?”. Такой подход сработал гораздо лучше, но оказалось, что большая часть работников была из стран Южной Азии, и они очень любят фотографии конференций в больших отелях, с людьми в костюмах и бокалами вина. Это несоответствие стало отрезвляющим напоминанием пузыря, в котором мы живем, а также практической проблемой — наша целевая аудитория из США посчитала те же фотографии депрессивными и невдохновляющими. В конце концов, шесть членов команды Jetpac вручную оценили более двух миллионов фотографий, осознав, что мы знаем критерий как никто другой.
Это экстремальный пример, но хорошо показывает, как процесс маркировки зависит от требований приложения. Для большинства случаев в продакшне, период нахождения правильных вопросов для модели оказывается очень продолжительным и крайне важным. Если модель отвечает на неправильные вопросы, вам никогда не удастся построить надежный пользовательский опыт на таком шатком фундаменте.

Единственный способ понять, задаете ли вы верные вопросы — сделать шаблон приложения, но вместо модели машинного обучения использовать человека-в-цикле. Иногда это называют экспериментом “Wizard-of-Oz”, так как за занавесом находится человек. В случае с Jetpac, вместо тренировки модели мы попросили людей вручную отобрать фотографии для туристического гида, и использовали фидбек тестовых пользователей для настройки критерия, используемого при выборе изображений. Получив убедительно положительную обратную связь после тестов, мы перенесли правила выбора фото в маркировочный учебник для прогона миллионов фотографий тестового сета. Это помогло обучить модель предсказывать качество миллиардов фотографий, но само ДНК было получено с помощью правил установленных вручную.
Обучайте на реалистичных данных
В случае с Jetpac для обучения модели мы использовали изображения из того же источника (по большей части Facebook и Instagram), откуда планировали брать изображения для применения на модели. Проблема такого подхода в том, что тренировочный датасет по многим критериям отличается от входных данных, которые получит модель после запуска. Например, я часто вижу команды, которые обучали модель на ImageNet, и сталкивались с проблемами при попытке использовать ее в дроне или роботе. Все потому что большинство фотографий ImageNet сделана людьми, поэтому они обладают общими свойствами. Они сняты на телефон или неподвижную камеру, с нейтральной линзой, примерно на высоте головы человека, в дневном или искусственном освещении, снимаемый объект находится в центре и на первом плане. Роботы и дроны используют видеокамеры, часто с широким углом обзора, обычно на уровне пола или наоборот с большой высоты, при плохом освещении и без постановки кадра, поэтому объекты обычно обрезаны. Такие различия означают, что вы получите низкую точность при попытке использовать модель, обученную на фотографиях из ImageNet, на одном из таким устройств.
Данные, которые увидит финальное приложение, могут отличаться от тренировочных менее очевидными способами. Представьте, что вы создаете камеру, которая будет узнавать диких животных, и для обучения вы использовали датасет животных со всего мира. Если приложение в итоге должно работать в джунглях Борнео, вероятность корректной отработки метки “пингвин” крайне мала. Наличие антарктических фотографий в тренировочных данных только повысила бы вероятность перепутать кого-то с пингвином, а значит общий уровень ошибок был бы выше, чем если бы вы исключили эти фотографии из обучения.
Существуют способы калибровки результата на основе приоритетов (например, значительно снизить вероятность пингвина в джунглях), но гораздо проще и эффективней использовать тренировочный набор данных, отражающих реальность. Лучший способ для этого — использовать данные, собранные непосредственно приложением, что отлично сочетается с подходом “Wizard of Oz”, который я предложил выше. Ваш человек-в-цикле становится маркировщиком изначального набора данных, и даже если количество собранных меток довольно невелико, они отражают реальное использование и, надеюсь, этого будет достаточно для начальных экспериментов с transfer learning.
Следуйте метрикам
Когда я работал над примером речевых команд, один из основных отчетов, на который я обращал внимание во время обучения, был матрицей ошибок. Вот пример того, как это отображается в консоли:
[[258 0 0 0 0 0 0 0 0 0 0 0]
[ 7 6 26 94 7 49 1 15 40 2 0 11]
[ 10 1 107 80 13 22 0 13 10 1 0 4]
[ 1 3 16 163 6 48 0 5 10 1 0 17]
[ 15 1 17 114 55 13 0 9 22 5 0 9]
[ 1 1 6 97 3 87 1 12 46 0 0 10]
[ 8 6 86 84 13 24 1 9 9 1 0 6]
[ 9 3 32 112 9 26 1 36 19 0 0 9]
[ 8 2 12 94 9 52 0 6 72 0 0 2]
[ 16 1 39 74 29 42 0 6 37 9 0 3]
[ 15 6 17 71 50 37 0 6 32 2 1 9]
[ 11 1 6 151 5 42 0 8 16 0 0 20]]
Может показаться пугающим, но на самом деле таблица показывает детали ошибок, которые совершает сеть. Вот версия с обозначениям, которая выглядит чуть симпатичней:
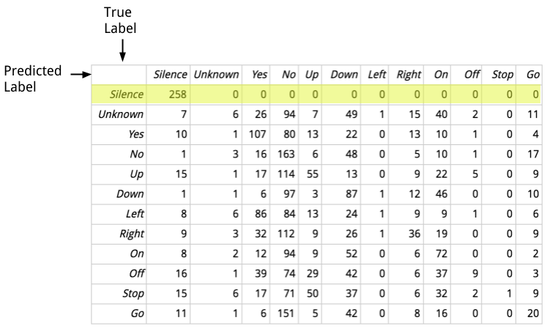
Каждая строка в таблице представляет собой набор образцов, у которых фактическая метка совпадает. Каждый столбец показывает количество прогнозируемых меток. Например, выделенная строка показывает все аудио фрагменты, оказавшиеся беззвучными, и если читать слева направо, можно увидеть что все предсказанные метки оказались корректны и попали в столбец с предсказанной тишиной. Это показывает, что модель хорошо распознает настоящую тишину, не совершая ошибок второго рода. Но если посмотреть на весь столбец, показывающий сколько клипов были ошибочно предсказаны беззвучны, можно заметить много ошибок первого рода. Было полезно это узнать, так я смог обратить особое внимание на эти клипы и обнаружить, что они были действительно слишком тихими. Их удаление помогло улучшить качество данных, чего не случилось бы без помощи матрицы ошибок.
Почти любая сводка результатов может быть полезной, но матрица ошибок, на мой взгляд, наилучший компромисс, который дает больше информации, чем само значение точности, но не перегружает лишними деталями. Полезно наблюдать за изменением значений в процессе обучения, так вы узнаете, какие категории вызывают у модели наибольшие сложности в изучении, и на каких областях нужно сфокусироваться при чистке и расширении датасета.
Одного поля ягоды
Один из моих любимых способов понять, как мои сети интерпретируют тренировочные данные — визуализация кластеров. TensorBoards обладает фантастической поддержкой этого вида исследований, и хотя он обычно используется для просмотра векторных представлений (embedding) слов, я считаю его крайне полезным для любого слоя, работающего схожим образом. Например, сети классификации изображений часто имеют слой перед финальным, полносвязным или softmax модулем, который может быть использован в качестве embedding (именно так работает transfer learning в примере TensorFlow для Poets). Это не embedding, строго говоря, потому что во время обучения усилия не тратятся на получение желаемых пространственных свойств. Но кластеризация их векторов действительно дает интересный результат.
Приведу практический пример — команда, с которой я работал, была озадачена высоким уровнем ошибок среди определенных животных в их модели классификации изображений. Они применили кластерную визуализацию, чтобы посмотреть на распределение тренировочных данных по разным категориям, и, посмотрев на “Ягуар”, обнаружили, что данные сортируются в две отдельные группы.

Фото djblock99 и Dave Adams
Вот схема того, что они увидели. После просмотра фотографий из обоих кластеров, стало очевидно, что многие автомобили марки “Jaguar” были некорректно промаркированы тем же именем, что и животное “Ягуар”. Эта информация помогла заново взглянуть на процесс маркировки и найти недостатки в указаниях и пользовательском интерфейсе, сбивающих работников с толку. Благодаря этому они смогли улучшить процесс обучения маркировщиков и исправить инструмент, тем самым избавившись от изображений автомобилей в категории “ягуар” и получив более точную модель для этого класса.
Преимущества кластеризации похожи на те, что вы получаете при самостоятельном просмотре — тесное знакомство с содержанием тренировочных данных. Но сеть сама управляет вашим исследованием, сортируя входные данные в группы на основании полученных знаний. Мы как люди хорошо замечает визуальные аномалии, поэтому совокупность нашей интуиции и способностей компьютера обрабатывать большие массивы данных предоставляет масштабируемое решение для отслеживания качества датасета. Полный туториал по использованию TensorBoard в этих целях несколько выходит за рамки этого поста (он и так уже слишком длинный, спасибо, что продолжаете читать!), но если вы серьезно настроены на улучшение результата, настоятельно рекомендую познакомиться с этим инструментом.
Всегда собирайте
Ни разу не сталкивался, чтобы сбор дополнительных данных не улучшил точность модели. И, оказывается, многие исследования подтверждают мой опыт.
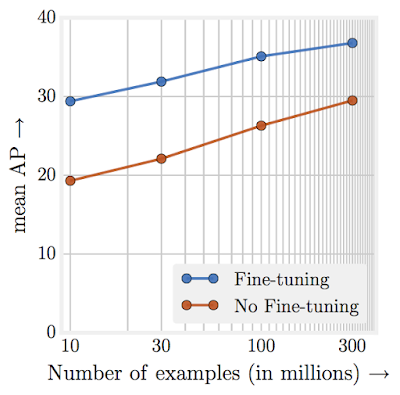
Эта диаграмма взята из “Повторения непомерной эффективности данных” и показывает как точность модели классификации изображений увеличивается, даже когда тренировочный датасет разрастается до сотен миллионов. Недавно Facebook поднял это на новый уровень, и использовал миллиарды фотографий с хэштегами из Instagram, чтобы достичь рекорда точности классификации ImageNet. Это показывает, что увеличение количества тренировочных данных улучшает результаты модели, даже в случае с большим, высококачественным датасетом.
Это значит, что вам нужна стратегия непрерывного улучшения датасета до тех пор, пока в точности модели есть пользовательская выгода. Использование хэштегов Instagram в случае Facebook — отличный пример. Другой подход заключается в увеличении “интеллектуальности” пайплайна маркировки, например, путем внедрения инструментария, предлагающего метки, предсказанные изначальной версией вашей модели. Это поможет маркировщикам быстрее принимать решения. Есть опасность укоренения предвзятости, но на практике выгода перевешивает этот риск. Можно вложиться в большее количество людей для маркировки тренировочных данных, но это такой подход может быть затруднителен для компаний, не обладающих бюджетом для подобного расширения. Если ваш проект некоммерческий, можно попробовать упростить процесс добровольного пожертвования данных через какой-то публичный инструмент. Это поможет увеличить объем данных без головокружительных затрат.
Конечно, Святой Грааль для любой организации — иметь продукт, самостоятельно генерирующий промаркированные данные по мере его использования. Я бы сильно не цеплялся за эту идею, так как она не подходит для многих реалистичных случаев, когда люди пытаются получить ответы, как можно скорее и без сложностей маркировки. Это отличный инвестиционный питч, если вы стартап — почти вечный двигатель улучшения модели. Но всегда находятся затраты на зачистку или внедрение полученных данных, поэтому в итоге получается что-то больше похожее на дешевую версию коммерческого краудсорсинга, чем на что-то действительно бесплатное.
Highway to the Danger Zone
Почти всегда в модели находятся ошибки, оказывающие на пользователей приложения больше влияние, чем может быть сразу замечено. Вам нужно заранее подумать о наихудших возможных результатах и попытаться защитить модель от них. Это может быть черный список категорий, которые вы не хотите предсказывать, потому что стоимость ошибки первого рода слишком высока, или простой алгоритмический набор правил, гарантирующий, что совершенные действия не выходят за заданные рамки. Например, завести список ругательств, которые текстовый генератор никогда не должен выводить, даже если они есть в тренировочном наборе, потому что это не уместно для вашего продукта.
Негативные исходы не всегда очевидны, поэтому важно начать учиться на своих ошибках в реальном мире. Один из простейших способов — начать использовать баг-репорты, как только продукт начнет выглядеть пристойно. Если людям, использующим ваше приложение, был выдан результат, который им не понравился, сделайте форму обратной связи как можно проще. По возможности, получите полную информацию о вводимых пользователем данных, но если они конфиденциальны, достаточно информации о данных вывода. Эти категории могут быть использованы для выбора области сбора новых данных или исследования классов для понимания текущего состояния их маркировок. После получения новой версии модели используйте вводные данные, ранее вызвавшие плохие результаты, и проведите на них отдельную оценку в дополнении к стандартному набору тестов. Это немного напоминает регрессионное тестирование и показывает, насколько был улучшен ux. Единичные метрики точности модели не в состоянии полностью отразить все, что волнует людей. Изучив небольшое количество примеров, вызвавших сильную реакцию в прошлом, вы получите независимые доказательства того, что вы действительно улучшили пользовательский опыт. Если невозможно собрать вводные данные в силу их конфиденциальности, используйте dogfooding или проведите внутренние эксперименты, чтобы понять какие вводные данные у вас есть для воспроизведения этих ошибок, и используйте их в регрессионном сете.
What’s the Story, Morning Glory?
Надеюсь, мне удалось убедить вас потратить больше времени на данные и дать несколько инвестиционных идей для их улучшения. Этой теме уделено гораздо меньше внимания, чем она того заслуживает, и кажется, мои советы — только верхушка айсберга. Я благодарен всем, кто поделился со мной своими стратегиями, и надеюсь узнать еще больше удачных подходов. Думаю, количество организаций, выделяющих команды инженеров специально для улучшения датасетов (а не сваливая эту задачу на исследователей машинного обучения), будет увеличиваться. И я очень жду улучшений во все сфере благодаря этому. Я постоянно удивляюсь хорошей работе моделей даже с проблемными обучающими данными, и не могу дождаться увидеть, чего мы сможем достичь при улучшении наших сетов!
THE END
Как всегда ждём комментарии-вопросы тут или заходите на открытый урок, посвященный классификации и спрашивайте преподавателя там :)
Комментариев нет:
Отправить комментарий