INET Framework – “библиотека” сетевых моделей для

{kind=link}
В предыдущих частях…
0. Автоматическое определение топологии сети и неуправляемые коммутаторы. Миссия невыполнима? (+ classic Habrahabr UserCSS)
В этой части:
- создадим “свой первый” протокол (на примере LLTR Basic);
- выберем подходящий симулятор сити для отладки протокола (и создания его модели);
- познаем тонкости настройки окружения для симулятора и его IDE (конфигурирование, компиляция, линковка, тюнинг, патчинг, игнорирование устаревшей документации; и другие англицизмы в большом количестве);
- столкнемся со всем, с чем можно столкнуться, при создании своей первой модели своего первого протокола в
не своемнезнакомом симуляторе сети; - пройдем весь путь вместе:
- от счастья, принесенного успешной (наконец!) компиляции первого проекта с пустой сетью,
- до полного погружения в эксперименты с функционирующей моделью протокола;
- tutorial, все описано в виде tutorial – мы будем учиться на ошибках – будем совершать их, и будем понимать их (природу), дабы элегантно/эффективно с ними справится;
- репозиторий (git
 ), в коммитах и тегах которого сохранены все шаги (
), в коммитах и тегах которого сохранены все шаги (“Add …” ,“Fix …” ,“Fix …” ,“Modify …” ,“Correct …” , …), от начала и до конца.
Note: дополнительная информация для читателей хаба “Mesh-сети”.
{ объем изображений: 2.2+(2.1) MiB; текста: 484 KiB; смайликов: 22 шт. }
Note: [про используемую структуру разделов] структура разделов tutorial/how‑to обычно отличается от структуры разделов в справочнике: в справочнике – структура разделов позволяет за минимальное количество шагов дойти до искомой информации (сбалансированное дерево); в tutorial/how‑to, где разделы сильно связаны логически, а отдельный раздел, по сути, является одним из шагов в последовательности шагов, структура представляет собой иерархию закладок (якорей), которая позволяет в любом месте tutorial/how‑to напомнить (сослаться) о фрагменте описанном ранее.
Как хорошо, что в HTML5 появился тег <section>, с его помощью стало возможным напрямую задавать уровень вложенности раздела (при помощи манипуляции вложенностью тегов <section> друг в друга). Структуру текста теперь можно было явно отразить во вложенности (иерархии) тегов.
Это повлияло и на теги заголовков <h#>, т.к. теперь вложенность разделов определяется вложенностью тега <section>, то для указания названия раздела – достаточно было использовать всего лишь один тег <h1> в виде: “<section><h1>название раздела</h1>текст раздела</section>”.
Я этим пользовался уже давно (с самого появления <section>), но создавая эту статью, увидел еще одно достоинство использования <section>.
Хорошее название раздела должно точно отражать его суть, однако бывают случаи, когда нужно придержать (не раскрывать) суть до середины раздела. То есть, такой раздел должен вначале притворится “рутинным”, а в середине создать “wow/wtf‑эффект”. Логически это все – один раздел, но если раскрыть его название в самом начале раздела, то само название будет являться спойлером. Представьте книгу (детектив), на обложке которой будет вся информация о “убийце”.
Здесь “на сцену выходит” тег <section>. Он позволяет определить название раздела в любом месте внутри себя, т.е. не обязательно в самом начале. Пример: “<section>текст раздела<h1>название раздела</h1>продолжение текста раздела</section>”. Получается, мы можем одновременно сохранить логическую структуру текста, и показать название раздела в нужный момент. Можно даже сделать так, чтобы название раздела визуально появлялось в его начале, после того как читатель дойдет до определенного момента (до тега <h1> в html).
Вот только более чем за 9 лет существования <section>, браузеры так и не научились правильно строить “HTML5 document outline” для обеспечения доступности.
Почему не научились? В документе со сложной структурой трудно* определить, начиная с какого тега (section, article, …) следует начать нумерацию заголовков (h1, h2, h3, …). А теперь представьте, что сам документ размещен на странице подобной этой (с множеством дополнительных блоков, не имеющих отношение к самому документу, но имеющих заголовки), причем везде для заголовков используется h1. А если на одной странице не один документ, а несколько? Тем не менее, визуально все выглядит хорошо (пример документа).
* – на самом деле это не трудно, в стандарте все описано, но в реальности это не работает (объяснение см. ниже).
Почему визуально все выглядит хорошо? Здесь, благодаря стилям, появилась дополнительная информация – соответствие между иерархией section и уровнями заголовков (h#). Так может при построении “HTML5 document outline” следует воспользоваться информацией из CSS? Для этого потребуется добавить в CSS дополнительное свойство для элемента заголовка, указывающее его уровень, например:
body>section>h2 { heading-level: 1; font-size: 1.8em; }
body>section>section>h2 { heading-level: 2; font-size: 1.4em; }
body>section>section>section>h2 { heading-level: 3; font-size: 1.17em; }
body>section>section>section>section>h2 { heading-level: 4; font-size: 1em; }
body>section>section>section>section>section>h2 { heading-level: 5; font-size: 0.83em; }
Либо более строгий вариант – в одной секции допускается использовать только один заголовок. В этом случае уровень заголовка задает сама секция:
body>section { heading-level: 1; }
body>section>section { heading-level: 2; }
body>section>section>section { heading-level: 3; }
body>section>section>section>section { heading-level: 4; }
body>section>section>section>section>section { heading-level: 5; }
, и неважно, какой в итоге будет использоваться тег заголовка: h1 или h5.
Однако, если раньше для создания “heading-level outline” достаточно было иметь только разметку (HTML), то теперь нужны еще и стили (CSS). Может можно ограничиться только разметкой (HTML)? Этим вопросом мы вплотную подошли к проблеме алгоритма построения “heading-level outline”, описанного в стандарте. Так вот, проблема не в самом алгоритме, а в том, что в качестве “sectioning root” элемента может выступать только ограниченный (фиксированный) набор тегов. Но у людей часто возникают “нестандартные желания”: “я хочу, чтобы на моей странице со списком статей тег article являлся ‘sectioning root’ элементом”, “а я хочу, чтобы произвольная секция стала ‘sectioning root’ элементом”. Раньше им достаточно было для этого использовать несколько тегов h1 на одной странице (и они это делали). Так может сделать так, чтобы любая секция (теги: section, article, …) становилась “sectioning root” элементом, если заголовок в ней задан при помощи тега h1?..
# Первые шаги: “перед моделированием” / “мозговой штурм”

НЛОприлетелоиоставилоэтотпробелздесь? Обратная сторона листочка из предыдущей статьи.
# Детализация протокола
В начале определим, что нам нужно включить в протокол. На примере LLTR Basic.
Основа LLTR – это итерации сбора статистики на множестве хостов во время сканирования сети. Итераций в LLTR много
В каждой итерации есть свой unicast src хост и unicast dst хост, поэтому следующее, что нужно включить – способ назначения для каждой итерации unicast src и dst. То есть в каждой итерации один из хостов должен “осознавать” себя unicast src хостом, цель которого посылать трафик на unicast dst хост.
И последнее. По завершению всех итераций, всю собранную статистику со всех хостов нужно отправить на один хост для обработки. Этот хост проанализирует собранную статистику, и построит топологию сети.
Также, на этом шаге, можно подумать про некоторые детали реализации (ограничения) протокола. Например, мы хотим, чтобы программа, использующая LLTR, смогла работать без root прав, и из пространства пользователя (т.е. без установки в систему специального драйвера), значит, LLTR должен работать, например, поверх TCP и UDP.
Все остальные делали реализации, определятся сами, в процессе создания модели. То есть, конечно, можно сразу же продумать все до мелочей, но при этом есть риск “скатится в локальный оптимум”, и не заметить “более лучший” вариант реализации. Хорошо, когда моделей будет несколько – если для каждого варианта реализации будет своя модель, то появится возможность комбинировать модели, и шаг за шагом приходить к лучшей реализации. Вспоминая генетический алгоритм ;). Например, в одной реализации/модели может быть централизованное управление, в другой – децентрализованное, в третей – комбинация лучших частей из предыдущих двух вариантов.
# Выбор симулятора сети
Теперь настало время определится с симулятором сети, в котором будем создавать модели и ставить эксперименты.
В основном, от симулятора сети нам нужна возможность реализации “своего” протокола. Не все симуляторы позволяют легко это сделать.
А вот присутствие эмуляторов ОС реального сетевого оборудования “мировых брендов”, наоборот – не нужно. Скорее всего, эмуляторы создадут множество ограничений, которые будут только мешать в ходе экспериментов.
С выбором симулятора мне помогла статья Evaluating Network Simulation Tools (наши требования к симулятору во многом совпадали) и
# Установка OMNeT++ и INET
И так как
Установка в *nix и в Windows мало чем отличается. Продолжу на примере Windows.
Распаковываем
$. setenv
$ ./configure
$ make
Но не спешите это делать!
Во‑первых, обратите внимание на первую команду “. setenv”. В директории “omnetpp-5.0” нет файла “setenv” (в версии 5.0b1 он был). Он и не нужен (для Windows), поэтому просто запускаем “mingwenv.bat” (советую перед запуском посмотреть, что он делает… во избежание внезапного rm ). По окончании отколется терминал (mintty).
Во‑вторых, советую немного подправить файл “configure.user” (если упомянутый параметр закомментирован в файле, то его нужно раскомментировать):
- Если хотите использовать Clang (по умолчанию), то оставьте
PREFER_CLANG=yes
и настройте:- CFLAGS_RELEASE (опции компилятора):
CFLAGS_RELEASE='-O2 -march=native -DNDEBUG=1'
- CFLAGS_RELEASE (опции компилятора):
- Если хотите использовать GCC вместо Clang (а вы, скорее всего, захотите использовать именно GCC, увидев, что написано в 398 строчке файла “configure.in”), то установите
PREFER_CLANG=no
и настройте:- CFLAGS_RELEASE (опции компилятора). Можно выбрать или
CFLAGS_RELEASE='-O2 -mfpmath=sse,387 -ffast-math -fpredictive-commoning -ftree-vectorize -march=native -freorder-blocks-and-partition -pipe -DNDEBUG=1'
или
CFLAGS_RELEASE='-O2 -fpredictive-commoning -march=native -freorder-blocks-and-partition -pipe -DNDEBUG=1'
или
CFLAGS_RELEASE='-O2 -march=native -freorder-blocks-and-partition -pipe -DNDEBUG=1'
(расположено в порядке уменьшения вероятности возникновения глюков). - Также стоит добавить CXXFLAGS в виде '
-std=c++11'+CFLAGS_RELEASE. Например:
CXXFLAGS='-std=c++11 -O2 -fpredictive-commoning -march=native -freorder-blocks-and-partition -pipe -DNDEBUG=1' - JAVA_CFLAGS (просто раскомментируем):
JAVA_CFLAGS=-fno-strict-aliasing
- CFLAGS_RELEASE (опции компилятора). Можно выбрать или
PREFER_QTENV=yes- Отключаем 3D визуализацию:
WITH_OSG=no
Она конечно красивая, но нам не понадобится. - Параллельное (на множестве CPU) выполнение симуляции (WITH_PARSIM), к сожалению, тоже стоит отключить, однако без него компоновка (linker) завершается неудачей, поэтому оставим включенным:
WITH_PARSIM=yes
Если его явно не использовать, то он не нужен (в теории). Подробнее в разделе 16.1, 16.3, и 16.3.2 “Parallel Simulation Example” в “doc/InstallGuide.pdf”, или тут.
Теперь в терминале (mintty) можно выполнить:
./configure && make clean MODE=release
make MODE=release –j17
Note: “17” следует заменить на количество ядер
В директории “tools/win32” находится MSYS2 его пакеты компиляторов можно обновлять:
А
Но index либо можно оставить 32bit (заменить на int32_t), либо сделать 64bit и модифицировать все битовые_маски+описания+(возможно)немного_логики. Поэтому часть long переменных нужно будет оставить 32bit, а другую часть сделать 64bit. В общем, для корректной работы, нужно проделать все пункты из:
Причем то же самое надо проделать и с многочисленными библиотеками для
В общем, предостерегаю от попыток сделать 64bit сборку
Под *nix я также рекомендую использовать 32bit сборку (по крайне мере с версией 5.0 и меньше).
Возможно, когда‑нибудь Andrey2008 возьмется проверить код FIXME”/“Fix” в коде ;).
P.S. упоминания о том, что код
При первом запуске Eclipse предлагает поместить workspace в директорию “samples”, однако лучше расположить ее в любой другой удобной вам директории вне “%ProgramData%”. Главное, чтобы в пути к новой директории использовались только латинские буквы (+ символы), и не было пробелов.
После закрытия Welcome, IDE предложит установить INET (как было написано выше), и импортировать примеры – откажитесь от обоих пунктов.
Опции JVM. Добавить в файл “ide/omnetpp.ini” (для правки подойдет любой редактор, понимающий LF перевод строки; notepad не подойдет), сохранив пустую последнюю строку:
-XX:+UseParNewGC
-XX:+UseConcMarkSweepGC
-XX:+AggressiveOpts
-XX:+TieredCompilation
-XX:CompileThreshold=100
{kind=link}
![Eclipse tuning (un[7z]me)](https://habrastorage.org/getpro/habr/post_images/fde/6a8/849/fde6a8849916c8492004d78db6efe5ea.png)
Чтобы сделать Eclipse, таким как на картинке – загляни внутрь картинки.
Настало время установить INET. Директорию “inet” из скаченного ранее архива (inet-3.4.0-src.tgz) нужно перенести в workspace. В директории есть файл “INSTALL” с пошаговым описанием установки. Можно воспользоваться им (раздел “If you are using the IDE”), но только не собирайте (Build) проект!
Импортируем INET:
- В Eclipse открыть:
File > Import. - Выбрать: General / Existing Projects to the Workspace.
- В качестве “root directory” выбрать местоположение workspace.
- Удостоверьтесь, что опция “Copy projects into workspace” выключена.
- После нажатия на кнопку “Finish”, дождитесь окончания индексации проекта (% выполнения см. внизу, в строке статуса – “
C/C++ Indexer”).
Настроим проект:
- A. отключим ненужные для LLTR компоненты;
- B. переключим сборку на релиз;
- C. избавимся от глюков “
OMNeT++ Make Builder” (opp_makemake) – раньше, при его выборе, часто происходила перегенерирация Makefile, даже когда этого не требовалось; - D. включим параллельную компиляцию;
- E. включим оптимизации;
- F. включим подсветку синтаксиса для
c++11 , в нескольких местах; - G. подправить баг связанный с “
#include” (случается, если несколько раз менять “Current builder”; может случиться и в других случаях).
Перед настройкой {A} надо подправить один из файлов проекта. В файле “inet/.oppfeatures” есть строка “inet.examples.visualization” нужно добавить после нее пустую строку, в которой написать “inet.tutorials.visualization”, желательно сохранив отступ слева (по аналогии с другими параметрами “nedPackages” в файле). Если это не сделать, то ничего страшного не случится, просто после настройки в “Problems” (Alt+Shift+Q,X) будут всегда висеть ошибки, связанные с “inet.tutorials.visualization”. Можно вначале сделать {A}, и посмотреть на ошибки, а затем подправить файл “inet/.oppfeatures” – при этом Eclipse предупредит о нарушении целостности в настройках, и предложит профиксить их (соглашаемся на это).
Приступим (панель
- Раздел
“OMNeT++” > подраздел “Project Features”- {A} убираем все, кроме:
- TCP Common
- TCP (INET)
- IPv4 protocol
- UDP protocol
- Ethernet
- кнопка “Apply”.
- {A} убираем все, кроме:
- Раздел “С/С++ Build”:
- кнопка
“Manage Configurations…” > сделать активным “gcc-release” {B}; - выбрать конфигурацию “gcc-release [ Active ]” {B}.
- Подраздел “Tool Chain Editor”:
- в качестве “Current builder” выбрать “GNU Make Builder” для обеих конфигураций: “gcc-debug” и “gcc-release” {C}, внимание: если в будущем изменить “Current builder”, то все придется перенастраивать заново!
- кнопка “Apply”.
- Вкладка “Behavior” (вернутся в корень раздела “С/С++ Build”):
- установить “Use parallel jobs” равным N (в качестве N можно выбрать либо число ядер
CPU + 1 , либо 1.5×ядер) – это позволит использовать все ядра CPU для компиляции {D} (настраиваем для “gcc-debug” и “gcc-release”).
- установить “Use parallel jobs” равным N (в качестве N можно выбрать либо число ядер
- Вкладка “Build Settings”:
- отключить “Use default build command”;
- строку “Build command” заменить на “
make MODE=release CONFIGNAME=${ConfigName} -j17” (“17” заменить на предыдущее значение в строке, т.е. на выбранный N) {E}, то же самое можно сделать и для конфигурации “gcc-debug”, заменив в строке “MODE=release” на “MODE=debug”, после этого не забудь переключиться обратно на “gcc-release [ Active ]”.
- кнопка “Apply”.
- кнопка
- Раздел “С/С++ General”:
- Подраздел “Paths and Symbols”:
- Вкладка “Includes”:
- кнопка Add: добавить директорию “
../src” с выбранными “Add to all configurations” и “Add to all languages” {G} – изначально “../src” есть в языке “GNUC++ ”, но, в неопределенный момент, он может стереться из списка; - кнопка “Apply”, и проверь, что “
../src” появилось во всех языках и конфигурациях.
- кнопка Add: добавить директорию “
- Вкладка “Symbols”:
- кнопка Add: добавить символ “
__cplusplus” со значением “201103L” и выбранными “Add to all configurations” и “Add to all languages” – {F} подробнее; - кнопка “Apply”, и проверь, что в конфигурации “gcc-debug” у “
__cplusplus” значение “201103L”.
- кнопка Add: добавить символ “
- Вкладка “Source Location”:
- Проверь, что в списке один пункт, и он указывает на “
/inet/src” {G}, если там что‑то другое (например, просто “/inet”), то удаляй то, что есть и добавь (“Add Folder…”) “/inet/src”. Затем кнопка “Apply”, и возвращение к {A}, т.к. все фильтры при удалении были стерты. Кстати, “/inet” на самом деле можно оставить – с ним тоже все нормально собирается, но лучше сузить до оригинального “/inet/src”.
- Проверь, что в списке один пункт, и он указывает на “
- Вкладка “Includes”:
- Подраздел
“Preprocessor Include Paths, Marcos etc.” > вкладка “Providers”:- Выбрать “CDT GCC Build-in Compiler Settings”:
- В группе “Language Settings Provider Options” нажать на ссылку “Workspace Settings”:
- вкладка “Discovery”: опять выбрать “CDT GCC Build-in Compiler Settings”, и добавить “
-std=c++11” перед “${FLAGS}” в “Command to get compiler specs”, должно получится примерно так `${COMMAND} -std=c++11 ${FLAGS} -E -P -v -dD "${INPUTS}"` {F}, подробнее здесь и здесь; - кнопка “Apply”, “Ok” (закрываем окно).
- вкладка “Discovery”: опять выбрать “CDT GCC Build-in Compiler Settings”, и добавить “
- переместить “CDT GCC Build-in Compiler Settings” выше “CDT Managed Build System Entries” (для обеих конфигураций: “gcc-release” и “gcc-debug”) {F}, подробнее – после этого мы потеряем возможность переопределять символы “CDT GCC Build-in Compiler Settings” через “CDT Managed Build System Entries” (
“С/С++ General” > “Paths and Symbols” > “Symbols”), переопределить можно будет только через добавление значений в “CDT User Settings Entries” во вкладке “Entries” для каждого языка по отдельности (альтернатива: не меняем порядок, т.к. в “CDT Managed Build System Entries” уже исправили значение “__cplusplus”; не меняем порядок, удаляем все упоминания “__cplusplus” из “CDT Managed Build System Entries”, и следим, чтобы он там не появлялся в будущем); - кнопка “Apply”, и проверить, что во вкладке “Entries” у языка “GNU
C++ ” в “CDT GCC Build-in Compiler Settings” (чекбокс [в нижней части окна] “Show build-in values” должен быть включен) есть запись “__cplusplus=201103L” (она будет ближе к концу).
- В группе “Language Settings Provider Options” нажать на ссылку “Workspace Settings”:
- Выбрать “CDT GCC Build-in Compiler Settings”:
- Подраздел “Indexer”:
- в качестве “Build configuration for indexer” выбрать “gcc-release” {B};
- кнопка “Apply”.
- Подраздел “Paths and Symbols”:
Некоторые проблемы могут возникнуть с {E}. Поясню. Если все нормально, то Eclipse должен подхватить те настройки, которые были заданы в “configure.user” перед конфигурированием --just-print” или “--trace”, и, запустив сборку (панель g++ -c -std=c++11 -O2 -fpredictive-commoning -march=native -freorder-blocks-and-partition -pipe -DNDEBUG=1 …”. Если этого нет, то можно последовать совету из уже упомянутой статьи.
Опять открываем настройки проекта (панель
- Раздел “С/С++ Build”:
- Подраздел “Build Variables” (проверь, что текущая конфигурация “gcc-release [ Active ]”):
- кнопка “Add…”, имя “
CFLAGS”, тип “String”, значение “-O2 -fpredictive-commoning -march=native -freorder-blocks-and-partition -pipe”; - кнопка “Add…”, имя “
CXXFLAGS”, тип “String”, значение “-std=c++11 -O2 -fpredictive-commoning -march=native -freorder-blocks-and-partition -pipe”; - кнопка “Apply”.
- кнопка “Add…”, имя “
- Подраздел “Environment”:
- кнопка “Add…”, имя “
CFLAGS”, значение “${CFLAGS}”; - кнопка “Add…”, имя “
CXXFLAGS”, значение “${CXXFLAGS}”; - кнопка “Apply”.
- кнопка “Add…”, имя “
- Подраздел “Build Variables” (проверь, что текущая конфигурация “gcc-release [ Active ]”):
Кстати, при некоторой сноровке, параметры запуска g++ можно было посмотреть, не используя флаги “--just-print” и “--trace”, а используя Process Explorer. В Process Explorer также можно посмотреть, во что раскрывается “-march=native” при передаче в “cc1plus.exe”.
Теперь, наконец, можно собрать INET! Проверьте, что сейчас активна конфигурация “gcc-release” {B}, и если добавляли ранее флаги “--just-print” или “--trace” для проверки {E}, то их нужно убрать. Собираем (панель
Если все прошло хорошо, то рекомендую закрыть Eclipse, и сделать бекап файла “.cproject” и директории “.settings” с настройками проекта {B-G}, а также файлов: “.oppfeatures”, “.oppfeaturestate”, “.nedexclusions” – {A}.
Наконец, настройка завершена, и можно перейти к самому интересному.
# Создание первого проекта
Note: Первое, что я сделал после настройки окружения – стал изучать содержимое директории “doc” у
Note: Для тех, кто еще не успел установить себе
Перед созданием своего проекта хорошо бы посмотреть на уже готовые модели в INET, посмотреть, как они устроены. Может в нем уже реализовано то, что нам нужно?
После непродолжительного блуждания по дереву INET в “Project Explorer”, можно наткнуться на директорию “inet/src/inet/applications”, и обнаружить в ней “udpapp” (UDP Application). UDP пригодится нам для broadcast рассылки. Внутри директории лежат несколько моделей, и, судя по названию и размеру исходников, самый простой из них, это “UDPEchoApp”. Там есть еще и “UDPBasicApp”, но он оказался не таким уж и “Basic”. Каждая модель состоит из “.cc”, “.h” и “.ned” файлов. Пока не ясно, зачем нужны “.ned” файлы, но судя по их содержанию (наличию строчки “parameters:”) в них могут описываться параметры модели.
Продолжим поиски интересных моделей. Посмотрим, какие примеры (inet/examples) есть в INET. И нам повезло, в нем есть пример с названием “broadcast” (inet/examples/inet/broadcast)! Этот пример помимо файлов “.cc”, “.h” и “.ned”, содержит еще “.ini” и “.xml” файлы. Пора разобраться, зачем эти файлы нужны:
- .ned – файл/язык, описывающий либо модель сети (Network), либо простейшие блоки (Simple modules) “кирпичики”, из которых можно собирать модули (Compound module). В целом это выглядит так (картинка), т.е. можно собрать модель сети, и провести несколько экспериментов не написав ни одной строчки на
C++ . - omnetpp.ini – файл, в котором можно задать/переопределить параметры модели. Если нужно провести несколько экспериментов с разными параметрами, то всех их можно перечислить (Named Configurations) в этом же файле.
- .xml – просто файл с настройками, которые считывает один из используемых модулей (IPv4NetworkConfigurator).
К сожалению, этот пример (“broadcast”) нам не подойдет, т.к. в его сеть включены маршрутизаторы. Однако, по аналогии с ним, можно создать свой проект.
Note: Далее я продолжу ссылаться на разные разделы Simulation Manual. Как видите, он достаточно большой, браузеру требуется время (и RAM) для его открытия. Для решения этой проблемы я сделал небольшой JS‑bookmarklet. После его запуска все ссылки, ведущие на разделы Simulation Manual, перестанут плодить вкладки (пожирая ресурсы), и начнут переключать разделы в одной единственной дополнительной вкладке (на самом деле он просто прописывает target для каждой ссылки на Simulation Manual). Bookmarklet расположен в первом комментарии к этой статье. И, для того, чтобы отличить ссылки на Simulation Manual от остальных ссылок, bookmarklet изменяет их цвет.
При повторном открытии статьи bookmarklet придется запускать заново. На Хабре авторы статей могут в любой момент изменить содержимое статьи. Содержимое комментария можно изменить только в течение первых 5-и минут. При первом запуске bookmarklet вы наверняка проверили, что он делает.
⇒ запускать bookmarklet из тела статьи потенциально не безопасно – они могут в любой момент изменится; если же bookmarklet размещен в комментарии, то достаточно проверить его всего один раз (по истечении 5-и минут с момента публикации комментария) – в будущем он не изменится.
# Создаем проект
Пустой проект “LLTR”, с директориями “src” и “simulations”, и единственной конфигурацией “gcc-release” (File → New →
{kind=link}

Осталось настроить проект также как и “inet”, и можно будет двигаться дальше. В основном, настройка будет отличаться отсутствием необходимости настраивать “gcc-debug” (т.к. он отсутствует в “LLTR”), и добавлением в зависимости “inet”. Более конкретно: вместо {A,B,G} надо открыть раздел “Project References”, и включить зависимость от “inet”.
# Структура проекта
Если посмотрите на файлы, которые создал Wizard, то увидите, что файл “package.ned” встречается дважды: в директории “src”, и в “simulations”. Содержимое тоже отличается – “package lltr;” и “package lltr.simulations;” соответственно. Один из этих файлов нам не понадобится.
Если провести аналогию со структурой проекта INET, то директория “inet/src” – это “LLTR/src”, а “inet/examples” – это “LLTR/simulations”. То есть в “LLTR/simulations” лучше размещать файлы “.ned” c Network, а в “LLTR/src” – составные части сети (модули).
Существует еще один нюанс – в INET очень хорошая внутренняя структура директорий, и если в будущем нам потребуется изменить один из стандартных модулей в INET, то лучше будет создать новый модуль, и положить его рядом с оригиналом в INET. То же самое можно применить и к модулю, созданному с нуля – найти ему подходящее место в INET.
В свете вышеописанного, “.ned” в директории “LLTR/src” нам не нужен (все будет в “inet/src”), также как и не нужен дополнительный подпакет “package lltr.simulations;” в “LLTR/simulations”. Поэтому переносим “package.ned” из “LLTR/src” в “LLTR/simulations”.
# Пробный запуск
Попробуйте запустить LLTR. Для этого достаточно открыть файл “LLTR/simulations/omnetpp.ini”, и нажать (
При этом Eclipse предложит создать новую конфигурацию “simulations” для запуска симулятора. Соглашаемся, и сразу же сталкиваемся с проблемой: “LLTR/src/LLTR.exe” не был найден. Все верно, ведь “LLTR.exe” никто не собирал, поэтому вначале собираем проект (меню Project → Build Project), а затем опять запускаем симулятор (тем же самым способом).
После запуска симулятора появилось предупреждение “No network specified in the configuration.”, его можно исправить, добавив строку “network = lltr.Network” в секцию “[General]” файла “omnetpp.ini”, и добавив строку “network Network {}” в конец файла “package.ned”. Этим мы создали пустую сеть (в “.ned” файле), и настроили (в “.ini” файле) симулятор на загрузку этой сети (Network – имя сети) при запуске.
Теперь можно попробовать опять запустить симулятор (
Note: Есть различие между запуском через (
Note: (или можно форкнуть – тег a1_v0.1.0 (“a” – article) “git checkout -b ‹my_branch› tags/a1_v0.1.0”) ![]()
# Рекомендации по использованию репозитория
Репозиторий я создавал таким образом, чтобы:
- каждый шажок из tutorial совпадал с коммитом в git;
- можно было легко сослаться из tutorial на конкретный коммит – для этого каждый значимый коммит имеет свой тег;
- можно было клонировать (скачать) к себе только коммиты, относящиеся к текущей части (article) – для этого каждая часть имеет свою ветку (формат имени: “article_#”), указывающую на последний коммит/тэг части;
- любой смог легко создавать свою версию исходного кода из репозитория, “шагая” по tutorial.
Note: без веток “article_#” можно было бы обойтись, и указывать, при клонировании, название последнего тега части (которое еще надо найти), но с веткой проще/быстрее.
Как забрать репозиторий “к себе”? Лучше всего, вначале его форкнуть на GitHub, а затем свой форк:
Далее, для создания личной ветки на основе конкретного тега, можно использовать “git checkout -b ‹my_branch› tags/‹tag_name›”.
Как создавать свою версию кода, т.е. изменять код? Если в будущем не возникнет желания сделать Pull Request, то ничего вам не мешает делать с форком что хотите >:-), однако я советую, при появлении изменений, которые хочется сохранить, делать так):
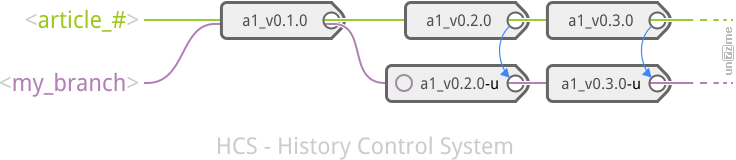
Одинаковая схема наименования тегов поможет в будущем избежать коллизий, даже не смотря на то, что теги при Pull Request не переносятся.
Note: Если я в будущем буду вносить изменения в репозиторий, то я поступлю также: оригинальный код сохранится, а измененный будет идти параллельно оригинальному (с “накатанными” всеми изменениями из остальных (будущих) тегов, и с новыми именами тегов). Только вместо добавления “-u” к именам новых тегов тегам, я буду увеличивать номер. Например, теги оригинального кода “a1_v0.1.0”, “a1_v0.2.0”, … – теги измененного кода “a1_v0.1.1”, “a1_v0.2.1”, … При следующем изменении, номер еще раз увеличится: “a1_v0.1.2”, “a1_v0.2.2”, …
Note: в tutorial все места, завершающие очередной “шажок”, помечены значком git ![]() , и рядом с ним будет ссылка на соответствующий git tag.
, и рядом с ним будет ссылка на соответствующий git tag.
Note: git diff использовался стандартный, патчи генерировались автоматически, и они редко будут показывать логической связи в произошедших изменениях (в частности, при добавлении нового кода и изменении уровня вложенности / форматирования существующего кода) (здесь бы пригодилось отслеживание изменений на уровне AST), похожее на этот проект для Java.
# Создание первой модели (Link Layer Topology Reveal)
# Шаг −1: собираем сеть
Откроем “package.ned” в режиме графического редактирования схемы (вкладка “Design” снизу), и попробуем набросать сеть из КДПВ:
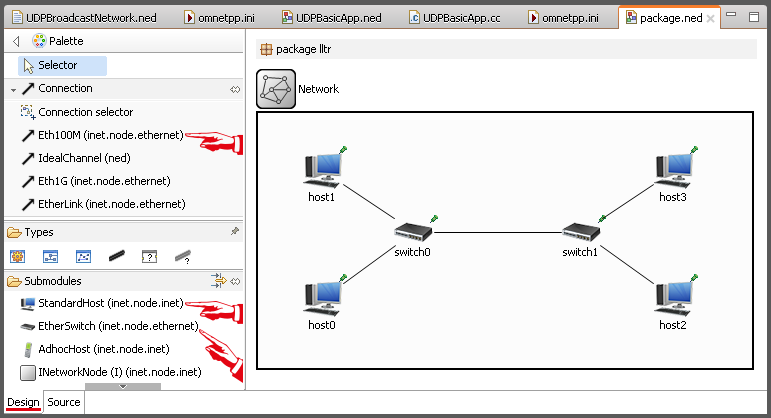
Сеть построена из тех же модулей, которые были использованы в примере broadcast:
- хосты – StandardHost;
- свитчи – EtherSwitch.
А вот в качестве “провода” (канала связи) выбран Eth100M (скорость: 100 Mbps; длина: 10 метров). Кстати, почему именно 10 метров, где они задаются, и можно ли поменять это значение? (ответ чуть ниже)
Если переключится в режим редактирования кода (вкладка “Source” снизу), то вы должны увидеть примерно это (git tag a1_v0.2.0) ![]() . Пояснение структуры:
. Пояснение структуры:
package ‹<a href="https://omnetpp.org/doc/omnetpp/manual/#sec:ned-ref:packages">имя пакета</a>›; //<a href="https://omnetpp.org/doc/omnetpp/manual/#sec:ned-ref:directory-structure">особенности наименования</a>
import ‹<a href="https://omnetpp.org/doc/omnetpp/manual/#sec:ned-lang:imports-and-name-resolution">имя подключаемого пакета</a>›;
network ‹<a href="https://omnetpp.org/doc/omnetpp/manual/#sec:ned-lang:warmup:network">название описываемой сети</a>›
{
@display(‹визуальные параметры сети, например, размер области›);
<a href="https://omnetpp.org/doc/omnetpp/manual/#sec:ned-ref:submodules">submodules</a>:
‹<a href="https://omnetpp.org/doc/omnetpp/manual/#sec:ned-lang:submodules">название узла</a>›: ‹тип узла› { @display(‹визуальные параметры узла, например, местоположение›); }
<a href="https://omnetpp.org/doc/omnetpp/manual/#sec:ned-ref:connections">connections</a>:
‹название узла›.‹<a href="https://omnetpp.org/doc/omnetpp/manual/#sec:ned-lang:gates">точка соединения</a>› <--> ‹тип канала связи› <--> ‹название узла›.‹точка соединения›;
}
Warning: К сожалению Хабр пока не поддерживает вставку ссылок при помощи тега <a>...</a> – вместо ссылок сейчас в код “вставляются” сами теги. И так происходит не только с этим блоком кода, но и со всеми ниже, в которых использовалась вставка ссылок, либо выделение частей кода при помощи тегов (<strong>...</strong>, <em>...</em>).
Отдельно стоит сказать про “точки соединения” (Gates) и каналы связи:
- Gates могут быть объявлены как векторы, в этом случае подключатся к ним можно явно, указав номер gate “
‹название узла›.‹gate›[‹номер›]”, либо автоматически – инкрементально “‹название узла›.‹gate›++”. - Параметры канала либо могут быть заданы в месте использования (например: “
… <--> { delay = 100ms; } <--> …”), либо могут иметь имя/тип, на которое можно ссылаться (как в примере broadcast: “… <--> C <--> …”), либо могут иметь тип и быть переопределены на месте (например: “… <--> FastEthernet {per = 1e-6;} <--> …”), либо… - Gates могут быть однонаправленными (тип при объявлении:
output/input; соединители при подключении:-->/<--), и двунаправленными (тип при объявлении:inout; соединитель при подключении:<-->). Двунаправленные состоят из двух однонаправленных, к которым можно обратиться напрямую,дописав суффикс “$i” либо “$o”.
Warning: К сожалению парсер Хабра пока смог обработать только 1⁄3 публикации за отведенные ему 20 секунд (приходит ошибка 504 “Gateway Time-out”). Но даже эти 1⁄3 позволили обнаружить еще один баг в парсере. Небольшой пример (исходная разметка):
Выполните в точности эту <a href="#set">команду: “<code>set: p=1.87548</code>”</a> в терминале своего портативного ядерного реактора.
После парсера:
Выполните в точности эту <a href="#set"><code>команду: “set: p=1.87548</code>”</a> в терминале своего портативного ядерного реактора.
Увидеть этот баг в действии можно, взглянув на конец 3‑го пункта в списке выше. Его оригинальная разметка выглядела так:
можно обратиться напрямую, <a href="https://omnetpp.org/doc/omnetpp/manual/#sec:ned-ref:inout-gates">дописав суффикс “<strong><code>$i</code></strong>” либо “<strong><code>$o</code></strong>”</a>.
Хорошая новость в том, что парсер сейчас переписывают. И, чтобы не ждать окончания этого процесса, я разместил полную версию публикации на GitHub Pages:
Note: В полной версии я упростил активацию target у ссылок на Simulation Manual – вместо запуска bookmarklet'а, достаточно нажать на кнопку здесь. К тому же при открытии полной версии через кнопку
Note: Разметка, CSS и JS этой страницы могут показаться странными – все дело в том, что процесс подготовки публикации у меня разбит на 3 этапа, и в GitHub Pages находится немного измененный результат 2‑го этапа (обычный HTML, пригодный для просмотра в браузере, и, при этом, максимально близкий к хабра‑разметке). 3‑й этап – это модификация разметки под Хабр.
# В следующих частях / To be continued…
- 2. Алгоритм определения топологии сети по собранной статистике
- 3.
OMNeT++ продолжение - 4. Математика
- 5.
OMNeT++ продолжение 2 - 6. Реализация
- 7. Эксперимент (название‑спойлер: “в конце Джон умрет”)
# Обратная связь
Небольшой опрос. Первый вопрос поможет мне лучше определить время для публикации следующей части. Второй – улучшить статью. Остальные вопросы – чистое любопытство.
Комментариев нет:
Отправить комментарий