Но блин… Сегодня я превзошёл сам себя. Мы сами себе полностью снесли сайт и биллинг, со всеми транзакциями, данными клиентов об услугах и прочим и в этом виноват был я, я сам сказал «удаляй». Некоторые из Вас уже заметили это. Это случилось сегодня, в пятницу в 11:20 по восточному североамериканскому времени (EST). Причём наш сайт и биллинг размещены были не на одном сервере, и даже не в облаке, мы ушли из облака дата-центра 2 месяца назад в пользу нашего собственного решения. Всё это размещалось на отказоустойчивом гео-кластере из двух виртуальных серверов — нашего нового продукта, VPS (KVM) c выделенными накопителями, НЕЗАВИСИМЫХ VPS, которые располагались на двух континентах — в Европе и в США. Один в Амстердаме, а другой в Манассасе, под Вашингтоном, тем, что D.C. В двух надёжнейших дата-центрах. Контент на которых постоянно и в реальном времени дублировался, а отказоустойчивость основана на обычном кластере DNS, запросы могли приходить на любой из серверов, любой выполнял роль MASTER, и в случае недоступности брал на себя задачи второго.
Я думал, что это может убить только метеорит, ну или ещё что-то подобное глобальное, что может вывести из строя два дата-центра одновременно. Но всё оказалось проще.
Это можем быть мы сами, мы, если мы — идиоты. В мире существует только две безграничных вещи — Вселенная и человеческая тупость, и если первое спорно, то второе стало очевидным.
Я всегда придерживался принципа здравого резервирования, я не из тех людей, кто будет кричать «я теряю $1000 за час простоя», но при этом плачу $15 за всю свою инфраструктуру. Нет, я конечно не теряю столько. Хотя, возможно, иногда и теряю. Большинство идиотов, кричащих это, даже не задумываются о том, что порой простой в секунду может стоить $1000, $10 000 или даже миллиона долларов прибыли в долгосрочной перспективе. Каким образом? Очень просто, в эту секунду может зайти клиент, который сделает свой первый заказ, а в перспективе принесёт Вам эти миллионы долларов, ведь Вы всегда имеете возможность доказать ему свою уникальность и заслужить его рекомендации. И если он увидит ошибку 504 или «извините, но сервер сейчас недоступен», сделка может и не состояться. У нас такое случалось, нет, не 504 ошибка во время захода важного посетителя, а первое. Чисто по вселенской случайности я оказывался в нужном месте и в нужное время, когда на наш сайт заходили крупные заказчики, такие как Дмитрий Суханов, создатель «Кинопоиск», хотя это и не очень удачный пример, ведь он проработал с нами только 2 года, пока его не выкупил Яндекс за $60 млн или сколько там. Так что миллионы тут скорее получил Дмитрий, а не мы, но мы были рады сотрудничать со столь интересным и полезным проектом и это, в свою очередь, сделало нам рекламу и обеспечило много новых и довольных заказчиков.
В общем, к чему я это всё. Убытки и нужную избыточность нужно оценивать здраво. Хотя и существует риск потерять миллион+ долларов, но нужно смотреть на вероятность такого события. Скорее всего, если бы Дмитрий увидел 1 раз ошибку 504 ничего критичного не произошло бы, и он вернулся к нам ещё раз. Почему? В то время мы, наверное, были одними из немногих, кто мог предложить коннективность 1+ Гбит / с по Украине с высоким качеством и минимальной latency за недорого, что было крайне важно для их ресурса в то время, чтоб обеспечить качественный доступ украинской аудитории к порталу, так как зарубежный трафик был низкого качества и всё ещё дорогим. Так что важно обеспечивать ещё и уникальность решения, тогда аптайм Вам не будет сильно критичным. А так как мы уникальны — мы вполне можем допустить для себя (даже сейчас), имея тысячи клиентов серверов, простой в несколько часов или даже более. Нам не нужны мегаотказоустойчивые облака, обеспечивающие 99,9999% аптайм за уйму денег, ибо даже они падают, а если падают, то как показала практика — очень надолго, так как проблема, вызвавшая недоступность, вероятно, нерядовая. И они не помогут в случае уязвимости. Никакак не помогут.
Вот и мы строили своё решение для себя очень просто. Взяли две VPS (KVM) на нодах Dell R730xd, такие же VPS (KVM), как предлагаем клиентам, ведь это наш изначальный принцип — давать людям то, чем пользуемся сами:
VPS (KVM) — 2 x Intel Dodeca-Core Xeon E5-2650 v4 (24 Cores) / 40GB / 4х240GB SSD RAID10 / Datatraffic — 40TB — от $99 / месяц, и можно получить скидку 30% на первый платёж, если найти промо-код в нашей рекламной статье.
Одну в Нидерландах, а другую в США. Да, на этих нодах, помимо нашего сайта и биллинга, ещё по 2 реальных клиента, которые могут оказывать влияние на работу нашего сайта в теории и не могут сделать это на практике. Почему — написано в рекламной статье, вдаваться здесь в подробности второй раз не буду. Сейчас речь не об этом. В общем решение не хуже выделенных серверов начального уровня и может обрабатывать очень большую нагрузку.
Помимо прочего оно отказоустойчиво, данные постоянно реплицируются в реальном времени. И в случае недоступности одного сервера, роль MASTER возьмет второй. В идеале можно сделать ещё так, что трафик с американского континента будет обрабатывать американский сервер, а с Европы, РФ и Азии — сервер в Нидерландах.
Серверы мы подвязали в свой аккаунт в нашем биллинге WHMCS, публичного лицензионного продукта, но адаптированного под нас, которым пользуется множество хостинг-провайдеров по всему миру, в том числе и мы, так как писать собственную систему учёта — откровенный дебилизм (в нашем случае). В особенности в тех случаях, когда нужная функция реализуется написанием собственного модуля к существующему биллингу, что повышает Вашу отказоусточивость, так как снижает риск наличия критичных уязвимостей. Ведь в одиночку или даже небольшой командой Вы не сможете написать более надёжную систему, нежели существующая, которая писалась годами туевой кучей разрабов, где уже выпилены тысячи багов и за которую теперь разработчики просят всего лишь от $30 / месяц за лицензию и получают миллионы долларов в год, которые могут расходоваться в том числе на дальнейшие улучшения.
К слову о критических уязвимостях, недавно наш программист допустил ошибку при написании одного из сервисных модулей, который имел доступ к базе биллинга только на чтение, которую обнаружил независимый пентестер и обратился к нам с предложением заплатить $550 за найденный баг, так как это была уязвимость SQL-injection:
SQL-injection находиться в топ 10 OWASP, я вам написал про сумму в $550, это минимальная сумма, поскольку страдает БД, тем самым возможна компрометация данных пользователей.Но некоторые суммы доходят до $10 000 в качестве вознаграждения, как пример в случае vk.com.
Разумеется, мы поддержали такое начало и выплатили вознаграждение без вопросов. Так как наш программист изучил предоставленные данные и подтвердил наличие проблемы, обоснование пентестера. Ведь мы не содержим пока собственного пентестера в штате, а эта работа требует немалых знаний и времени, так как включает целую серию исследований:
Аудит безопасности всего ресурса, а это проверка по следующим параметрам, и наш отчет по окончанию аудита, включает:•A1 Внедрение кода
•A2 Некорректная аутентификация и управление сессией
•A3 Межсайтовый скриптинг
•A4 Нарушение контроля доступа
•A5 Небезопасная конфигурация
•A6 Утечка чувствительных данных
•A7 Недостаточная защита от атак
•A8 Подделка межсайтовых запросов
•A9 Использование компонентов с известными уязвимостями
•A10 Недостаточное журналирование и мониторинг
Потому да, решение было принято однозначно и быстро. Тем более, что как отметил пентестер, подобные изыскания увеличивают безопасность веба в целом:
Это моё хобби, если каждый разработчик, как Вы, вели бы диалог с баг-хантерами, Интернет был бы безопасен на 80%.
Потому в целом мы заплатили довольно немного, особенно, если разделить сумму на то количество месяцев, которое сотрудник, отвечающий за тестирование на проникновение, не содержался в штате. Спасибо огромное пентестеру за найденный баг и то что он уделил нам время, мы правда ему очень благодарны. Если кому требуются его услуги — обращайтесь, предоставим с его разрешения контакты.
Но в этот раз нас убила не уязвимость. Это были мы и особенность работы продукта WHMCS. На каждой ноде у нас установлен удобный продукт управления виртуальными контейнерами — VM Manager, доступ к которому есть у WHMCS для создания, приостановки, и удаления, а также у клиентов — для управления созданным виртуальным контейнером.
Каждый день в WHMCS мы получаем десятки и даже сотни заказов, которые нужно акцептировать (принять), удалить, или пометить, как Fraud, если клиент пытается оплатить заказ с ворованной кредитки. Порой бывает бум таких заказов и мы не сразу можем определить, какой статус ему присвоить, так как проводим свою внутреннюю проверку или требуем пользователя идентифицировать себя должным образом, если нам его заказ показался подозрительным, а такие пользователи, понятное дело, не всегда отвечают или проходят идентификацию успешно. Потому, время от времени накапливается тысяча-другая не активированных заказов или заказов с неизвестным статусом, которые проще удалить, нежели обрабатывать. Кому реально нужно — перезакажет.
Два месяц назад мы решили полностью отказаться от облачного продукта дата-центра, так как начали предоставлять собственное решение с VM Manager, которое позволяет ставить систему в один клик или даже со своего образа:

И даже предложили его на накопителях NVMe PCIe SSD, которые на порядок быстрее обычных SSD на чтение и до 3-х раз на запись, решение, как и облачное, подлежит апгрейду, серверы стоят от $15 и включают удобную панель управления VM Manager и ISP Manager 5 по запросу бесплатно, поддерживают апгрейд с минимальным шагом 5GB DDR4 RAM, 60GB NVMe PCIe SSD и 3 ядра E5-2650 v4до большего тарифного плана в Амстердаме, Манассасе и Лондоне:
VPS (KVM) — E5-2650 v4 (3 Cores) / 5GB DDR4 / 60GB NVMe SSD / 1Gbps 5TB — $15 / month
VPS (KVM) — E5-2650 v4 (6 Cores) / 10GB DDR4 / 120GB NVMe SSD / 1Gbps 10TB — $30 / month
VPS (KVM) — E5-2650 v4 (9 Cores) / 15GB DDR4 / 180GB NVMe SSD / 1Gbps 15TB — $45 / month
…
VPS (KVM) — E5-2650 v4 (24 Cores) / 40GB DDR4 / 480GB NVMe SSD / 1Gbps 40TB — $120 / month
…
VPS (KVM) — E5-2650 v4 (24 Cores) / 65GB DDR4 / 780GB NVMe SSD / 1Gbps 65TB — $195 / month
VPS (KVM) — E5-2650 v4 (24 Cores) / 70GB DDR4 / 840GB NVMe SSD / 1Gbps 70TB — $210 / month
VPS (KVM) — E5-2650 v4 (24 Cores) / 75GB DDR4 / 900GB NVMe SSD / 1Gbps 75TB — $225 / month
Потому какой-либо смысл арендовать огромную часть облака дата-центра и предлагать клиентам старые процессоры Е3-1230, хоть и от $3,99 в месяц для нас иссяк. Мы верим в то, что клиенты должны получать максимальное качество и максимум производительности, за минимальную цену, да, мы не можем предложить продукт за $3,99 и возможно не покрываем потребности некоторых разработчиков, которым достаточно минимальных ресурсов и любой производительности, но нода стоит свыше 7000 евро и мы не можем себе позволить, во всяком случае пока, размещать на ней более 15 клиентов, так как готовы гарантировать качество. И качество подразумевает не только стабильность, но и максимальное соотношение производительность / цена, то cost-эффективность.
На радостях мы отменили всю облачную инфраструктуру (а это тысячи VPS), заказали себе у себя же 2 независимых виртуальных сервера (да, мы платим сами себе же за свои серверы), развернули 2 месяца назад сайт и биллинг на новом решении, как описывали всё выше, занесли в протект-группу, чтоб система не остановила сама себя, если вдруг забыли проплатить вовремя… Вроде бы сделали всё.
А сегодня, спустя 2 месяца, мы решили «Отменить» (не удалить, такая кнопка там также есть, но мы стараемся никогда ничего не удалять, чтоб всегда была история) 1000+ ожидающих заказов, которым всё ещё не был присвоен статус в биллинге WHMCS. Догадались? Да, это оно. У меня спросили — можно отменять? Я подтвердил «удаляй».
Порой, несмотря на большое количество ресурсов, так как выборка данных большая и какой-то процесс не укладывается в отведённый лимит времени, WHMCS выдаёт 504 ошибку, при этом всё выполняется и биллинг продолжает работать, но тут мы получили недоступность. Биллинг и сайт перестали быть доступными. Мы не сразу поняли причину. Но потом осознали. Заказ на наши 2 VPS не был акцептирован (да, мы не приняли свой же заказ!) и как следствие «Отменён» системой, что привело к запуску модуля и удалению сразу двух контейнеров, якобы не созданных, но всё же созданных виртуалок, при помощи нашей любимой VM Manager. Зайдя на одну из нод, как и предполагалось, наши администраторы увидели картину «Прощай»:
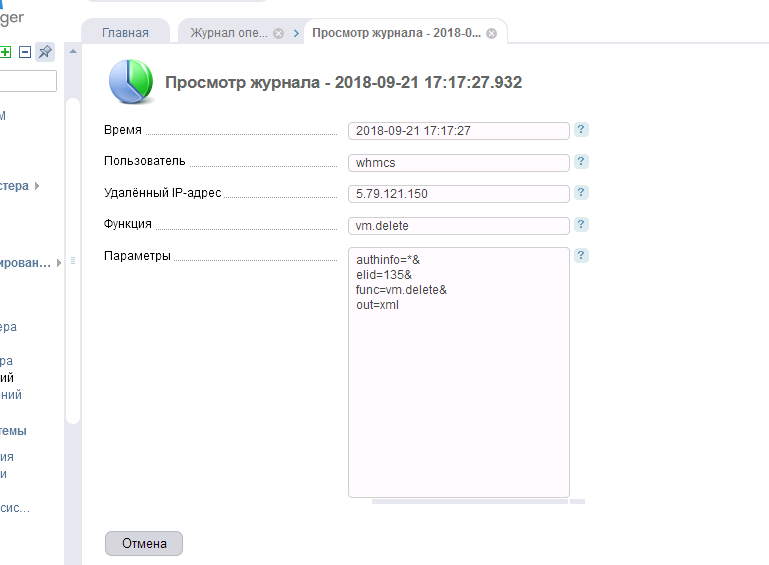
Что это — недочёт разработчиков WHMCS, который приводит к удалению неакцептированных заказов, и реально созданных с их ID VPS, при их отмене, или наша тупость (отдела продаж) — уже не важно. Результат был один — «Прощай сайт с биллингом». Панель их просто затёрла. А у администраторов к нам (продажам), был только один вопрос:
Нахера создавать услугу со своим главным сайтом и биллингом.
А потом ещё и убить ее к чертям.
И хотя у нас были бекапы, также в двух географически распределённых регионах, мне стало не по себе. Так как я не был уверен за свежесть резервных копий, не уверен был в том, что наши администраторы сделали всё верно, как было прописано изначально в тех. задании, что база резервировалась реально каждый час или даже чаще, а данные обновлялись и хранилось несколько предыдущих версий файлов. Что бэкапы по какой-то программной ошибке не перестали делаться вообще (ведь я лично это не котролировал, почему я должен быть уверен, что о наших данных будут беспокоится наши администраторы, если я на этот контроль забил?). Куча негативных мыслей… Не дай Вселенная Вам пережить такое!
Я уже собрался с мыслями, что как минимум за 1 час, а то и хуже, транзакций не будет, и придётся восстанавливать платежи клиентов вручную, сопоставлять данные по предидущим транзакциям и писать владельцам аккаунтов на счёт того, что мы повторно создали счёт и оплатили его, показать себя с ненаилучшей стороны, разослать уведомление, что мы дураки и допустили такой программный сбой… А если нет свежего бэкапа — так это вообще труба, пришлось бы очень долго и муторно восстанавливать всё…
На этот случай у нас есть внутренняя таблица, где многие основные данные дублированы вручную и которая актуализируется нами, что исключает программный сбой и переписывание некорректных данных. Несмотря на наличие бэкапов — мы до сих пор используем и этот метод. Ведь никто не отменяет возможность глобального звиздеца.
Благо, всё оказалось не столь плохо, и даже у тех. специалиста, которому пришлось решать проблему и который в начале огласил:
Вечер удался, всем спасибо.
Пошел поднимать.
Всё же вечер удался. Так как изначально решение предусматривало использование lvm и новый виртуальный контейнер ещё не успел быть создан — получилось восстановить актуальные данные, хотя и с танцем с бубном:
Всё через lvm утилиту, с помощью её команд восстановили виртуальных группу томов, потом виртуальный, далее активировали раздел, смаунтили на левую папку, создали сервер и туда засинкали данные. Можно было и другими способами, но этот вариант в нашем случае был самым быстрым + специфика настроек виртуальных серверов, что каждому свой рейд.
Какие выводы сделаны? Резервирование и избыточность должны включать учёт уязвимостей и самый тупой сценарий развития, когда всё, даже бэкапы, может быть уничтожено. Мы не пострадали и не понесли больших потерь только за счёт того, что данные не были удалены полностью. В случае необходимости восстановления из резервных копий — была бы утеря транзакций за период в час и значительная потеря рабочего времени. Нам казалось, что вероятность, когда нам могут пригодиться резервные копии при использовании геокластера минимальна — мы были не правы. Мы не учли, что возможно удалить оба сервера сразу и что удалим серверы не кто-то, а мы.
Необходимо всегда иметь внешнее независимое от Вашей системы хранилище, с доступом, желательно только по какому-то коду, которое также резервировано, чтоб уж точно гарантировать то, что данные не будут утеряны. В данный момент, несмотря на наличие бэкапов в нашей инфраструктуре в двух регионах, я в серьез рассматриваю возможность использования что-то типа Amazon Glacier, хотя последний очень дорог. По словам администраторов там всё хорошо только в маркетинговом плане, но когда начинаешь пользоваться — сталкиваешься с тем, что решение стоит довольно дорого, так как приходится платить за каждый запрос и каждый файл, который очень интересно считается их приложением aws-cli, особенно, если данные нужно восстанавливать. Недавно один клиент из Британии просил настроить резервирование там, по итогам через несколько месяцев пользования отказался — оказалось очень дорого. Но всё же, нам нужно определится с тем, что дороже. И если бюджет на резервирование там не превысит суммы возможного ущерба в результате потери части данных — мы обязательно воспользуемся. Если же нет — начнём искать другое, лучшее по цене, но всё же независимое от нас решение. Чтоб обеспечить дополнительную надёжность и уверенность в том, что данные не будут утеряны.
Ну, а что касается аптайма — он не на столько важен, любые потери от простоев восполнимы, в особенности, если Вы предлагаете уникальный продукт. Потому не следует концентрироваться на излишней отказоустойчивости, лучше, добавить избыточности, в частности избыточности, в хранении резервных копий ибо в случае утери данных, никакой даунтайм не покажется Вам очень страшным.
P.S. События произошли сегодня, в пятницу (публикуется в пятницу, по EST времени). Извините за много букв, решил отписать, пока свежо в воспоминаниях. Надеюсь, мой опыт будет кому-то полезен и убережет от подобной беды. И в пятницу Вы будете наслаждаться вечером перед выходными, а не писать статью об ошибках, как это делал я. Хотя, что не есть — то к лучшему, всё могло быть гораздо хуже. Не стесняйтесь делиться своими факапами в комментариях. Всем приятных наступающих и уже наступивших выходных!
На правах рекламы.
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps в Нидерландах до декабря бесплатно при оплате на срок от полугода, заказать можно тут, скидка 30% на первую оплату VPS в Нидерландах, США, Англии тут.
Dell R730xd в 2 раза дешевле? Только у нас 2 х Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 ТВ от $249 в Нидерландах и США! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?
Комментариев нет:
Отправить комментарий