
/ libreshot / PD
Типы архитектур ПО
Многоуровневая архитектура
Это одна из самых распространенных архитектур. На её основе построено множество крупных фреймворков — Java EE, Drupal, Express. Пожалуй, самый известный пример этой архитектуры — это сетевая модель OSI.
Система делится на уровни, каждый из которых взаимодействует лишь с двумя соседними. Поэтому запросы к БД, которая обычно располагается в самом конце цепочки взаимодействия, проходят последовательно сквозь каждый «слой».
Архитектура не подразумевает какое-то обязательное количество уровней — их может быть три, четыре, пять и больше. Чаще всего используют трехзвенные системы: с уровнем представления (клиентом), уровнем логики и уровнем данных.

О многоуровневой архитектуре написано бесчисленное количество книг и статей. И сложились разные мнения о ее достоинствах и недостатках.
Плюсы:
Каждый уровень этой архитектуры выполняет строго ограниченный набор функций (которые не повторяются от слоя к слою) и не знает о том, как устроены остальные уровни. Поэтому «содержимое» уровней можно изменять без риска глобальных конфликтов между слоями.
В целом многоуровневые приложения настолько распространены, что для их разработки создаются специальные генераторы шаблонов. Например, LASG для Visual Studio предлагает несколько методов генерации кода, которые автоматизируют рутинные задачи и помогают выстраивать уровни приложения.
Недостатки:
В программировании есть присказка, что любую проблему можно решить добавлением еще одного уровня абстракции. Однако такой подход в конечном счете может привести к плохой организации кода и запутать разработчиков.
Отсюда вытекает еще одна проблема — низкая скорость работы. Очень много информации начинает бесполезно проходить от слоя к слою, не используя бизнес-логику. Иногда эту проблему называют sinkhole anti-pattern — шаблон проектирования, когда количество бесполезных операций начинает преобладать над полезными.
Поиск багов в многоуровневых системах также может быть затруднен. Прежде чем попасть в базу данных, информация проходит через все уровни (так как БД является конечным компонентом). Если по какой-то причине эта информация повреждается (или теряется по пути), то для поиска ошибки приходится анализировать каждый уровень по отдельности.
Хорошо подходит:
- Для создания новых приложений, которые нужно развернуть по-быстрому. Это своеобразный «шаблон общего назначения».
Когда мы в 1cloud начинали работу над внутренними системами нашего провайдера виртуальной инфраструктуры, то использовали именно этот тип архитектуры. На старте перед нами не стояла задача сделать IaaS-сервис, способный обработать трафик десятков или сотен тысяч пользователей. Мы решили оперативно выпустить продукт на рынок и начать нарабатывать клиентскую базу, а проблемы масштабирования решать по мере их поступления (и сейчас мы переводим все системы на микросервисную архитектуру, о которой далее).
Среди разработчиков есть мнение, что не нужно с первых же дней проекта готовить его к колоссальным нагрузкам (писать future proof программное обеспечение). Реальные требования к приложению или сервису могут отличаться от ожидаемых, а бизнес-цели могут измениться. Потому код, написанный с прицелом на далекое будущее, рискует превратиться в технический долг. - Как пишет O’Reilly, многоуровневая архитектура — естественный выбор для многих корпоративных приложений. Так как в компаниях (особенно крупных) часто происходит разделение компетенций: есть команда, ответственная за фронтенд, есть люди, которые отвечают за бэкенд, и так далее. Отсюда вытекает естественное деление приложений на уровни: одни разработчики трудятся над клиентом, другие — над логикой.
Подобная взаимосвязь, между структурой организации и подходами к разработке приложений также продиктована законом Конвея, сформулированном еще в 1967 году. Он гласит: «Разрабатывая какую-либо систему, организации вынуждены придерживаться схемы, которая бы повторяла структуру коммуникаций внутри компании».
Событийно-ориентированная архитектура
В этом случае разработчик прописывает для программы поведение (реакции) при возникновении каких-либо событий. Событием в системе считается существенное изменение её состояния.
Можно провести аналогию с покупкой автомобиля в салоне. Когда автомобиль находит нового владельца, его состояние меняется с «продается» на «продано». Это событие запускает процесс предпродажной подготовки — установку дополнительного оборудования, проверку технического состояния, мойку и др.
Система, управляемая событиями, обычно содержит два компонента: источники событий (агенты) и их потребители (стоки). Типов событий обычно тоже два: инициализирующее событие и событие, на которое реагируют потребители.
Примером реализации такой архитектуры может служить библиотека Java Swing. Если классу нужно оповещение о каком-либо событии, разработчик реализует так называемого слушателя — ActionListener (он «ловит» соответствующий эвент), и дописывает его к объекту, который это событие может сгенерировать.
На Wiki приводится следующий код реализации этого механизма:
public class FooPanel extends JPanel implements ActionListener {
public FooPanel() {
super();
JButton btn = new JButton("Click Me!");
btn.addActionListener(this);
this.add(btn);
}
@Override
public void actionPerformed(ActionEvent ae) {
System.out.println("Button has been clicked!");
}
}
Достоинства архитектуры:
Так как приложения состоят из большого количества асинхронных модулей (у которых нет информации о реализации друг друга), их легко масштабировать. Такие системы собираются как конструктор — прописывать зависимости не нужно, достаточно реализовать новый модуль. Дополнительно асинхронная модель позволяет добиться высокой производительности приложений.
Недостатки:
Асинхронная натура таких приложений усложняет отладку. Одно событие может запускать сразу несколько цепочек действий. Если таких цепочек будет много, то понять, что именно вызвало сбой, может быть затруднительно. Для решения проблемы приходится прорабатывать сложные условия обработки ошибок. Отсюда же вытекает проблема с журналированием — логи трудно структурировать.
Подходит для:
- Создания асинхронных систем. Это очевидно, поскольку сама архитектура состоит из большого количества асинхронных модулей.
- Можно применить для создания UI. Веб-страница выступает в роли контейнера, в котором каждый её компонент изолирован и реагирует на определённые действия пользователя.
- Для организации обмена сообщениями между различными информационными системами.
Микроядерная архитектура
Этот тип архитектуры состоит из двух компонентов: ядра системы и плагинов. Плагины отвечают за бизнес-логику, а ядро руководит их загрузкой и выгрузкой.
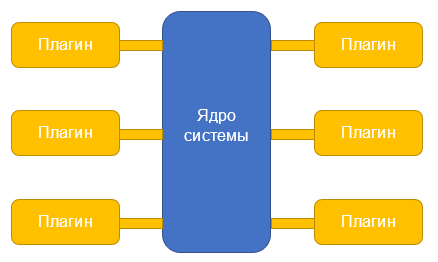
Как пример микроядерной архитектуры в книге O’Reilly приводится Eclipse IDE. Это простой редактор, который открывает файлы, дает их править и запускает фоновые процессы. Но с добавлением плагинов (например, компилятора Java) его функциональность расширяется.
Микроядерную архитектуру в свое время использовала операционная система Symbian для мобильных устройств (разработку прекратили в 2012 году). В её микроядре находился планировщик задач, системы управления памятью и драйверы, а файловая система и компоненты, отвечающие за телефонную связь, выступали в роли плагинов.
Достоинства архитектуры:
Легко портировать приложение из одной среды в другую, поскольку модифицировать нужно только микроядро. Разделение высокоуровневых политик и низкоуровневых механизмов упрощает поддержку системы и обеспечивает её расширяемость.
Недостатки:
Производительность приложения снижается, если подключать слишком много модулей. Однако бывает проблематично найти баланс между количеством плагинов и числом задач микроядра (обычно оно содержит лишь часто используемой код).
Также сложно определить заранее (до начала разработки приложения) оптимальную степень дробления кода микроядра. А поменять подход позднее практически невозможно.
Хорошо подходит для:
- Создания расширяемых приложений, которыми пользуется большое количество людей. Например, ОС для iPhone имеет «микроядерные» корни — её разработчики черпали вдохновение в Mach (это один из самых первых примеров микроядра).
- Создания приложений с четким разделением базовых методов и высокоуровневых правил.
- Разработки систем с динамически меняющимся набором правил, которые приходится часто обновлять.
Микросервисы
Похожи на архитектуру, управляемую событиями, и микроядро. Но используются тогда, когда отдельные задачи приложения можно легко разделить на небольшие функции — независимые сервисы. Эти сервисы могут быть написаны на разных языках программирования, поскольку общаются друг с другом при помощи REST API (например, с использованием JSON или Thrift).
В каких пропорциях делить код, решает разработчик, но Сэм Ньюмен (Sam Newman), автор книги «Создание микросервисов», рекомендует выделять на микросервис столько строк кода, сколько команда сможет воспроизвести за две недели. По его словам, это позволит избежать излишнего «раздувания» архитектуры.
Чаще всего микросервисы запускаются в так называемых контейнерах. Эти контейнеры доступны по сети другим микросервисами и приложениям, а управляет ими всеми система оркестровки: примерами могут быть Kubernetes, Docker Swarm и др.
Достоинства:
Микросервисная архитектура упрощает масштабирование приложений. Чтобы внедрить новую функцию достаточно написать новый сервис. Если функция стала не нужна, микросервис можно отключить. Каждый микросервис — это отдельный проект, потому работу над ними легко распределить между командами разработчиков.
Подробнее о механизмах масштабирования микросервисных систем можно почитать в книге Мартина Эббота (Martin L. Abbott) «Искусство масштабирования» (The Art of Scalability).
Недостатки:
Сложно искать ошибки. В отличие от монолитных систем (когда все функции находятся в одном ядре), бывает сложно определить, почему «упал» запрос. За деталями приходится идти в логи «виновного» процесса (если их несколько, то проблема усугубляется).
При этом появляются дополнительные накладные расходы на передачу сообщений между микросервисами. По нашим оценкам, рост сетевых издержек может достигать 25%.
Еще один недостаток — необходимость мириться с концепцией eventual consistency (согласованность в конечном счёте). У микросервисов есть собственные хранилища данных, к которым обращаются другие микросервисы. Информация об изменении этих данных распространяется по системе не мгновенно. Потому возникают ситуации, когда у некоторых микросервисов (пусть и на крайне короткий промежуток времени) оказываются устаревшие данные.
Где использовать:
- В крупных проектах с высокой нагрузкой. Например, микросервисы используются стриминговыми платформами. Системы доставки контента и иные вспомогательные сервисы можно масштабировать независимо друг от друга, подстраиваясь под изменения нагрузки.
- В системах, использующих «разномастные» ресурсы. Если одной части приложения нужно больше процессорного времени, а второй — памяти, то имеет смысл разделить их на микросервисы. После чего их можно захостить на разных машинах — с мощным CPU или большим объемом памяти соответственно.
- Когда нужна безопасность. Так как микросервисы изолированы и общаются по API, можно гарантировать, что передаваться будет только та информация, которая нужна тому или иному сервису. Это важно при работе с паролями или данными платёжных карт.
Почему мы в 1cloud переходим на микросервисы
Как мы уже говорили, в основе предоставляемых нами сервисов (частное облако, виртуальные серверы, объектное облачное хранилище и др.) лежит многоуровневая архитектура. Она показала себя с хорошей стороны, но теперь её возможности по масштабированию начали иссякать.
У нас становится все больше партнеров, которые предоставляют свои решения на базе нашей платформы по франшизе. Появляются удаленные площадки и сервисы, которыми становится сложно управлять из единой точки (в частности, наше оборудование находится в нескольких дата-центрах в России, Казахстане и Беларуси).
Чтобы было проще масштабировать существующие функции и внедрять новые фичи, мы в 1cloud переводим всю нашу инфраструктуру на микросервисы.

Мы хотим выделить их в отдельные модули и вместо одной сложной базы данных получить N простых. Таким образом, в новой архитектуре каждой фиче будет соответствовать отдельная БД. Это гораздо удобнее и эффективнее в поддержке и разработке.
Мы сможем разделить работу над сервисами между несколькими разработчиками (выделить специализации в компании) и эффективно масштабироваться горизонтально — когда нужно, будем просто подключать новые микросервисы.
Наши клиенты тоже получат ряд преимуществ. Поскольку микросервисы не связаны друг с другом, то при выходе из строя конкретной услуги будет недоступна только она, все остальные продолжат функционировать в штатном режиме. При этом даже если произойдет глобальное падение нашего сервиса, то панель управления продолжит работать.
Клиенты из Казахстана и Беларуси (и других стран, где мы откроем представительства) заметят существенное увеличение скорости и отзывчивости интерфейсов, так как панели управления будут размещаться локально.
Что уже сделано
Пока мы реализовали только первый пилот: «Услугу Мониторинг». Остальные сервисы переведем на новые рельсы в конце 2018 — начале 2019 года.
При этом новая архитектура закладывает технологическую основу для следующего этапа — миграции на контейнеры. Сейчас мы используем Windows-инфраструктуру, и для перехода в контейнеры нужно переписать весь накопившийся код на .NetCore и перевести его под управление Linux.
Начать новый переход планируем в начале 2019 года и закончить его в конце следующего года.
- Многоуровневая архитектура — приложение делится на уровни, каждый из которых выполняет строго определенный набор функций. Каждый уровень можно модифицировать по отдельности. Из недостатков — низкая скорость работы кода и сложность поиска багов.
Подходит для разработки приложений, которые нужно оперативно вывести на рынок. Часто используется для создания корпоративных сервисов.
- Событийно-ориентированная архитектура — здесь разработчик прописывает реакции системы на какие-либо события. Например, если поступили данные, записать их в файл. Приложения на базе событийно-ориентированной архитектуры просто масштабировать, так как все обработчики событий ничего не знают о реализации друг друга. Однако отладка таких систем затруднена — одно действие может вызывать сразу несколько цепочек действий (сложно понять, какая из них вызвала сбой).
Используют для создания асинхронных систем, организации графических интерфейсов и систем обмена сообщениями.
- Микроядерная архитектура — состоит из двух ключевых компонентов: плагинов и ядра. Плагины отвечают за бизнес-логику, а ядро — за их загрузку и выгрузку. Такое разделение обязанностей упрощает поддержку системы. Однако может сказаться на производительности — она напрямую зависит от количества подключенных и активных модулей.
Подходит для разработки расширяемых приложений, которыми пользуется большое количество людей, и систем с набором правил, которые приходится часто обновлять (простоту обновления гарантируют плагины).
- Микросервисная архитектура — приложения делятся на функции — микросервисы. Каждый микросервис — это независимый компонент со своей бизнес-логикой. Эти компоненты общаются друг с другом при помощи API. Такие приложения просто разрабатывать (есть возможность распределить работу между командами разработчиков), но сложно отлаживать.
Используют в крупных проектах с высокой нагрузкой, которым требуется повышенная безопасность.
Комментариев нет:
Отправить комментарий