
Материал подготовлен на основе выступления Николая на осенней конференции DevOops 2017. Под катом — видео и текстовая расшифровка доклада.
В данный момент Николай Рыжиков работает в Health-IT секторе над созданием медицинских информационных систем. Член питерского сообщества функциональных программистов FPROG. Активный участник Online Clojure community, member стандарта по обмену медицинской информацией HL7 FHIR. Занимается программированием 15 лет.
Каким боком мы относимся к DevOps? Наша формула DevOps уже на протяжении 10 лет достаточно проста: разработчики отвечают за operations, разработчики деплоят, разработчики мейнтейнят. При такой расстановке, которая выглядит немного жестковато, вы в любом случае станете DevOps. Если хотите быстро и болезненно внедрить DevOps — заставьте разработчиков отвечать за ваш продакшн. Если ребята смышленые, то начнут выкручиваться и всё поймут.

Наша история: давно, когда еще не было никаких Chef и автоматизации, мы уже деплоили автоматический Capistrano. Потом начали его растачивать, чтобы он провижинил моды. Но потом появился Chef. Мы перешли на него и уехали в облако: нам надоели свои дата-центры. Потом появился Ansible, возник Docker. После этого мы переехали на Terraform с собственноручно-написанным супервизором докеров Condo на Camel. И вот теперь мы переезжаем на Kubernetes.

Что самое страшное в operations? Очень мало кто удовлетворен уровнем автоматизации своего operations. Это страшно, я подтверждаю: мы затратили очень много ресурсов и усилий, чтобы все эти стеки собирать для себя, а результат неудовлетворительный.
Есть ощущение, что с приходом Kubernetes что-то может измениться. Я приверженец бережливого производства и, с его точки зрения, operations вообще не приносит пользы. Идеальный operations — это отсутствие или минимум operations в проекте. Ценность создается тогда, когда разработчик делает продукт. Когда он уже готов, доставка не добавляет ценность. А ведь нужно сокращать издержки.

Для меня идеалом всегда являлся heroku. Мы его использовали для простых приложений, где разработчику, чтобы развернуть свой сервис, достаточно было сказать git push и настроить heroku. Это занимает минуту.

Как быть? Можно купить NoOps — тоже heroku. И советую купить, иначе есть шанс потратить больше денег на разработку нормального operations.
Есть ребята Deis, они пытаются сделать что-то типа heroku на Kubernetes. Есть cloud foundry, который тоже дает платформу, на которой можно работать.

Но если заморачиваться на что-то более сложное или крупное, можно сделать самому. Теперь вместе с Docker и Kubernetes это становится задачей, выполнимой за разумные сроки с разумными затратами. Когда-то это было слишком жестко.

Немного о Docker и Kubernetes
Одна из проблем operations — это повторяемость. Прекрасная вещь, которую привнес докер — две фазы. У нас есть фаза билда.
Второй момент, который радует в докере — универсальный интерфейс для запуска произвольных сервисов. Кто-то собрал Docker, что-то внутрь положил, а operations достаточно сказать Docker run и запустить.

Что такое Kubernetes? Вот мы сделали Docker и нам нужно его где-то запускать, объединять, конфигурировать и связывать с другими. Kubernetes позволяет это делать. Он вводит ряд абстракций, которые называются «ресурс». Мы быстро по ним пройдемся и даже попытаемся создать.
Абстракции
Первая абстракция — POD или набор контейнеров. Грамотно сделано, что именно набор контейнеров, а не один. Наборы могут шарить между собой volumes, которые видят друг друга через localhost. Это позволяет использовать такой паттерн, как sidecar (это когда мы запускаем основной контейнер, а рядом есть вспомогательные контейнеры, которые ему помогают).
Например, подход ambassador. Это когда вы не хотите, чтобы контейнер думал, где находятся какие-то сервисы. Вы ставите рядом контейнер, который знает, где эти сервисы лежат. И они становятся доступны главному контейнеру по localhost. Таким образом environment начинает выглядеть так, как будто вы работаете локально.

Давайте поднимем POD и посмотрим, как он описывается. Локально можно разрабатывать minikube. Он сжирает кучу CPU, но позволяет на virtualbox поднять маленький Kubernetes-кластер и с ним работать.
Давайте задеплоим POD. Я сказал Kubernetes apply и залил POD. Могу посмотреть какие у меня есть POD-ы: вижу, что задеплоен один POD. Это означает, что Kubernetes у себя запустил эти контейнеры.
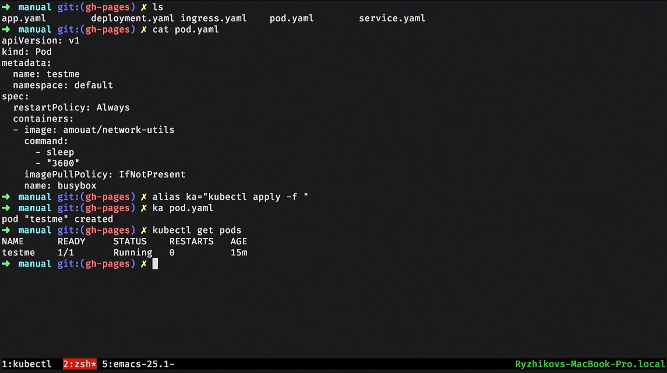
Я могу даже зайти в этот контейнер.
С этой точки зрения Kubernetes сделан для людей. Действительно, то, что мы постоянно делаем в operations, в обвязке Kubernetes, например, с помощью утилиты kubectl, можно делать легко.
Но POD — он смертный. Он запускается как Docker run: если его кто-то остановит, никто его не переподнимет. Поверх этой абстракции Kubernetes начинает строить следующую — например, replicaset. Это такой супервизор, который следит за POD-ом, следит за их количеством, и если POD-ы падают, он их переподнимает. Это важная концепция самоизлечения в Kubernetes, которая позволяет спокойно спать по ночам.
Поверх replicaset есть абстракция deployment — тоже ресурс, который позволяет сделать zero time deployment. Например, работает один replicaset. Когда мы делаем deploy и меняем версию контейнера, например, нашего, внутри деплоймента, то поднимается другой replicaset. Мы дожидаемся, когда эти контейнеры стартанут, пройдут свои health-чеки, и потом мы быстро переключаемся на новый replicaset. Тоже классическая и хорошая практика.

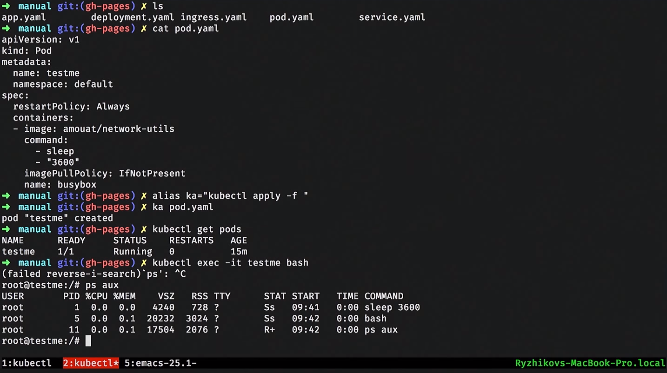
Давайте поднимем простенький сервис. Например, у нас есть deployment. Внутри он описывает шаблон POD-ов, которые он будет поднимать. Можем применить этот deployment, посмотреть, что у нас есть. Крутая фича Kubernetes — все лежит в базе данных, и мы можем смотреть, что происходит в системе.
Вот мы видим один deployment. Если мы попробуем посмотреть на POD-ы, то мы видим, что поднялся какой-то POD. Можем взять и удалить этот POD. Что происходит с POD-ами? Один уничтожается, а второй сразу поднимается. Это replicaset-контроллер не нашел нужный POD и запустил другой.
Далее, если это какой-то веб-сервис, или внутри наши сервисы должны связываться, нужен service discovery. Надо дать сервису имя и точку входа. Для этого Kubernetes предлагает ресурс, который называется service. Он может заниматься load balancing и отвечать за service discovery.

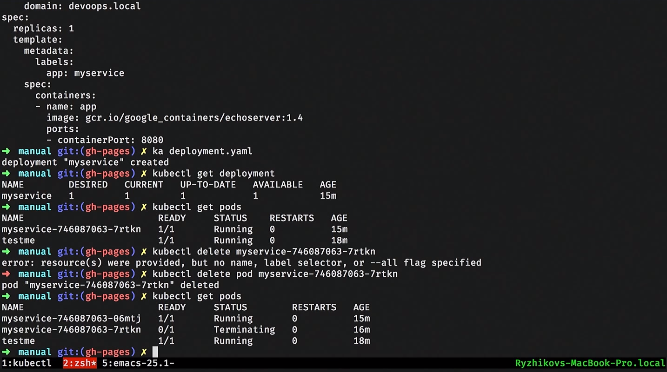
Давайте посмотрим простенький service. Мы связываем его с деплойментом и POD-ами через лейблы: такое динамическое связывание. Очень важная концепция в Kubernetes: система динамическая. Неважно, в каком порядке все это будет создано. Service будет пытаться найти POD-ы с такими лейблами и начать их load balance.

Апплаим service, смотрим, какие у нас есть сервисы. Заходим в наш тестовый POD, который был поднят, и делаем nslookup. Kubernetes нам дает DNS-ку, через которую сервисы могут друг друга видеть и обнаруживать.

Service — это скорее некий интерфейс. Там есть несколько разных реализаций, потому что задачи load balancing и service достаточно сложные: одним способом работаем с обычными базами данных, другим — с нагруженными, а какие-то простые делаем совсем по-простому. Это тоже важная концепция в Kubernetes: некоторые вещи скорее можно назвать интерфейсами, а не реализациями. Они закреплены не жестко, и разные, например, облачные провайдеры дают разные реализации. Т.е., например, есть ресурс persistent volume, который уже в каждом конкретном облаке реализуется своими штатными средствами.
Дальше мы обычно веб-сервис хотим вывести куда-нибудь наружу. В Kubernetes есть абстракция ingress. Обычно там же добавляют SSL.

Самый простой ingress выглядит как-то так. Там мы пишем правила: по каким url-ам, по каким хостам, к какому внутреннему сервису перенаправлять запрос. Точно так же можем поднять и наш ingress.
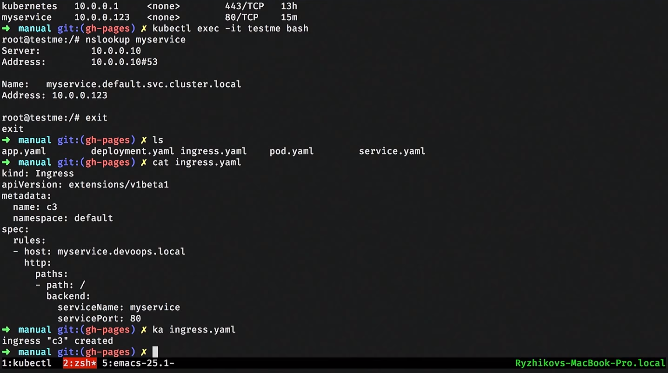
После чего, прописав локально в хостах, можно этот сервис увидеть отсюда.

Это такая штатная задача: мы развернули некий веб-сервис, чуть-чуть познакомились с Kubernetes.
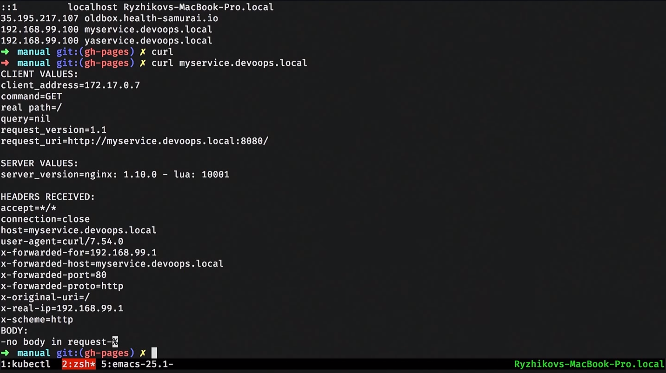
Зачистим все это, удалим ingress и посмотрим на все ресурсы.
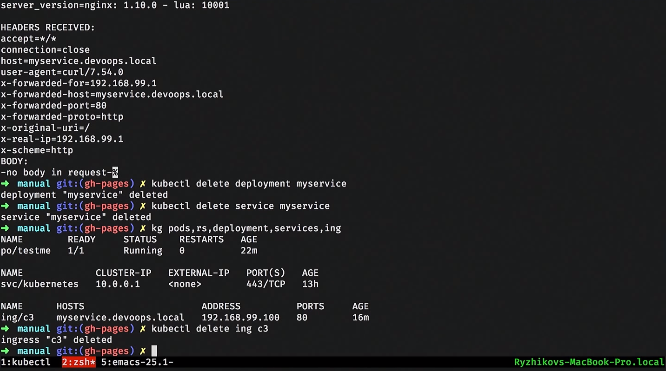
Есть еще ряд ресурсов, например configmap и secret. Это чисто информационные ресурсы, которые вы можете замаунтить в контейнер и передать туда, например, пароль от postgres. Можете это связать с environment variables, которые будут инжектиться в контейнере во время запуска. Можете замаунтить файловую систему. Все достаточно удобно: стандартные задачи, симпатичные решения.
Есть persistent volume — интерфейс, который реализуется по разному у разных клауд-провайдеров. Он разбит на две части: есть persistent volume claim (запрос), и потом создается какая-нибудь EBS-ка, которая тащится к контейнеру. Можно работать со stateful-сервисом.

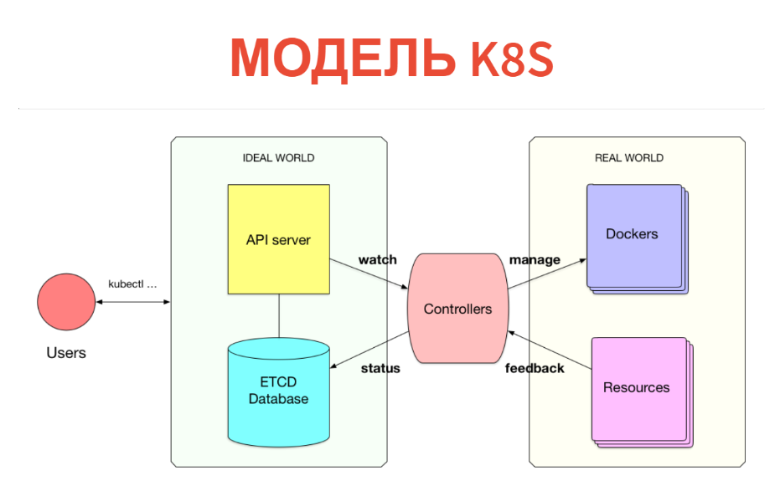
Но как это работает внутри? Сама концепция очень проста и прозрачна. Kubernetes состоит из двух частей. Одна — это просто база данных, в которой у нас лежат все эти ресурсы. Ресурсы можете представлять как таблички: конкретно эти инстансы — просто записи в табличках. Поверх Kubernetes настроен API-server. То есть когда у вас есть Kubernetes cluster, вы обычно общаетесь с API-сервером (точнее, с ним общается клиент).
Соответственно, то, что мы создавали (POD-ы, сервисы и т.д.), просто пишется в базу данных. Эта база данных реализована ETCD, т.е. так, чтобы она была устойчива на уровне high-available.
Что делается дальше? Дальше под каждый тип ресурсов есть некий контроллер. Это просто сервис, который следит за своим типом ресурса и что-то делает во внешнем мире. Например, делает Docker run. Если у нас есть POD, на каждый Node есть kubelet-сервис, который следит за POD-ами, которые зашедулены на эту ноду. И все, что он делает, — это Docker run после очередной периодической проверки, если этого POD-а нет.
Дальше, что очень важно — все происходит в реальном времени, поэтому мощность этого контроллера выше минимальной. Зачастую контроллер еще снимает метрики и смотрит за тем, что он запустил. Т.е. снимает фидбек из реального мира и его же записывает в базу, чтобы вы или другие контроллеры это видели. Например, тот же статус POD-а будет записан обратно в ETCD.
Таким образом, в Kubernetes реализовано все. Очень прикольно, что отделена информационная модель от операционной. В базе данных через обычный CRUD-интерфейс мы декларируем то, что должно быть. Потом набор контроллеров пытается сделать так, чтобы все было правильно. Правда, так получается не всегда.
Это — кибернетическая модель. У нас есть некий пресет, есть какая-то машина, которая пытается направить реальный мир или автомат в то место, которое нужно. Не всегда так получается: у нас должна быть петля обратной связи. Иногда машина этого сделать не может и должна обращаться к человеку.
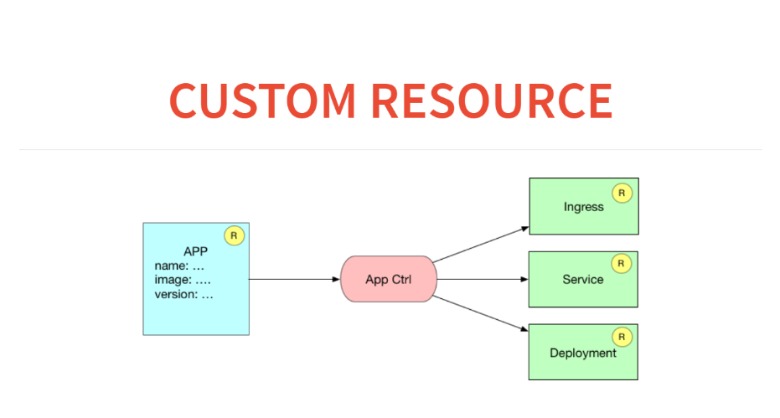
В реальных системах мы мыслим абстракциями следующего уровня: у нас есть некие сервисы, базы данных, и мы все это связываем. Мы не мыслим POD-ами и Ingress-ами, и нам хочется построить некий следующий уровень абстракции.

Так, чтобы разработчику было максимально легко: чтобы он просто говорил «Хочу запустить такой-то сервис», а все остальное произошло внутри.
Есть такая вещь как HELM. Это неправильный путь — темплейтинг в стиле ansible, где мы просто пытаемся породить набор сконфигурированных ресурсов и закинуть их в кластер Kubernetes.
Проблема, во-первых, в том, что это выполняется только в момент накатывания. То есть много логики он не может реализовывать. Во-вторых, в рантайме эта абстракция исчезает. Когда я иду смотреть на мой кластер, я вижу просто POD-ы и сервисы. Я не вижу, что задеплоен такой-то сервис, что там поднята такая-то база с репликацией. Я просто вижу там десятки подов. Абстракция исчезает как в матрице.

Внутренняя модель решения
С другой стороны, сам Kubernetes уже внутри дает очень интересную и простую модель расширения. Мы можем объявлять новые типы ресурсов, например deployment. Это ресурс, построенный поверх POD-ов или replicaset. Мы можем написать контроллер к этому ресурсу, положить этот ресурс в базу и запустить нашу кибернетическую петлю так, чтобы все работало. Это звучит интересно, и, мне кажется, это правильный путь расширять Kubernetes.

Хотелось бы иметь возможность просто писать некий manifest для своего сервиса в стиле heroku. Очень простой пример: я хочу задеплоить какое-то приложение в своем реальном окружении. Уже есть соглашения, SSL, куплены домены. Я просто хотел бы дать разработчикам максимально простой интерфейс. Manifest мне говорит, какой контейнер поднять, какие ресурсы еще нужны этому контейнеру. Он закидывает в кластер это объявление, и все начинает работать.

Как это будет выглядеть с точки зрения кастомных ресурсов и контроллеров? Вот у нас будет лежать в базе resource application. И application controller будет порождать три ресурса. То есть он будет прописывать в ingress правила о том, как роутить к этому сервису, запустит service для load balancing и запустит deployment с какой-то конфигурацией.
Прежде чем мы создадим кастомный ресурс в Kubernetes, нам нужно его объявить. Для этого у есть мета-ресурс, который называется CustomResourceDefinition.
Для того, чтобы объявить новый ресурс в Kubernetes, нам достаточно зааплаить вот такое объявление. Считайте это create table.

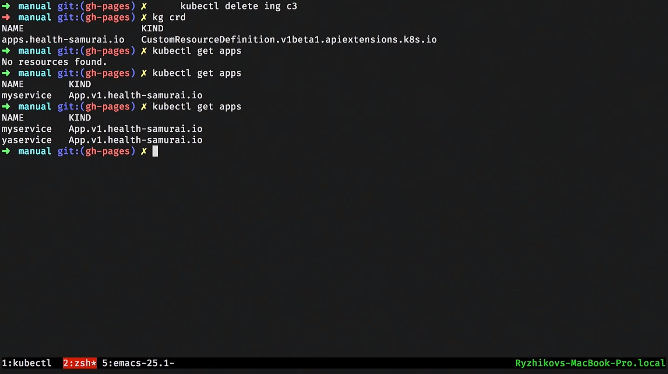
Создали таблицу. После этого мы можем посмотреть через kubectl get на те third-party ресурсы, которые у нас есть. Как только мы его объявили, у нас еще и апишка появилась. Мы можем делать, например, kubeclt get apps. Но пока никаких аппов нет.

Давайте какой-нибудь апп запишем. После этого мы можем сделать кастомный resource instance. Посмотрим на него в YAML и создадим его постом на определенный URL.

Если мы побежим и через kubectl посмотрим, то появился один апп. Но пока ничего не происходит, он просто лежит в базе данных. Можно, например, взять и запросить все апп ресурсы.

Можем создать второй такой ресурс из того же темплейта, просто поменяв имя. Вот появился второй ресурс.
Дальше наш контроллер должен делать темплейтинг, похожий на то, что делает HELM. То есть получив описание нашего аппа, я должен сгенерить resource deployment и resource service, а также сделать запись в ingress. Это самая простая часть: здесь в clojure — это erlmacro. Я передаю структуру данных, она дергает функцию deployment, передает в debug, который pipeline. И это — чистая функция: простой темплейтинг. Соответственно, в самом наивном виде я мог бы тут же это создать, превратить в консольную утилиту и начать распространять.

То же самое делаем для сервиса: функция service принимает декларацию и генерит нам ресурс Kubernetes.
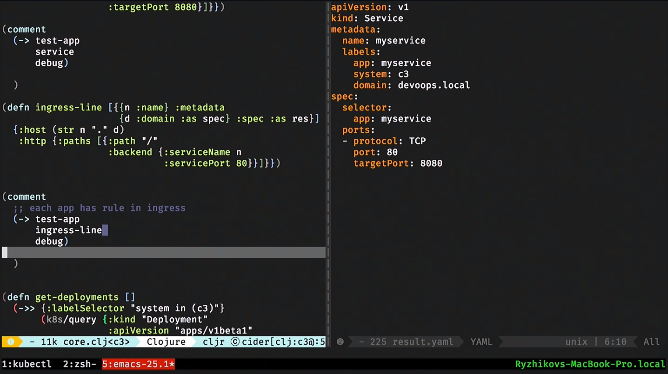
То же самое мы делаем и для строчки в ingress.

Как это все будет работать? Будет что-то в реальном мире и будет то, что мы хотим. То что мы хотим — мы берем application resource и генерим по нему то, что должно быть. И теперь нам нужно посмотреть, что есть. Что есть мы запрашиваем через REST API. Мы можем получить все сервисы, все деплойменты.
Как будет работать наш кастомный контроллер? Он будет получать то, что мы хотим и то что есть, брать от этого div и применять к Kubernetes. Это похоже на React. Придумал виртуальный DOM, когда какие-то функции просто генерят дерево JS-объектов. А потом некий алгоритм вычисляет патч и применяет к реальному DOM-у.
То же самое мы сделаем и здесь. Это делается в 50 строк кода. Захотите — все есть на Гитхабе. В итоге мы должны получить функцию reconcile-actions.
У нас есть функция reconcile-actions, которая ничего не делает и просто вычисляет этот div. Она берет то, что есть, плюс то, что нужно. И потом выдает то, что нужно сделать, чтобы привести первое ко второму.
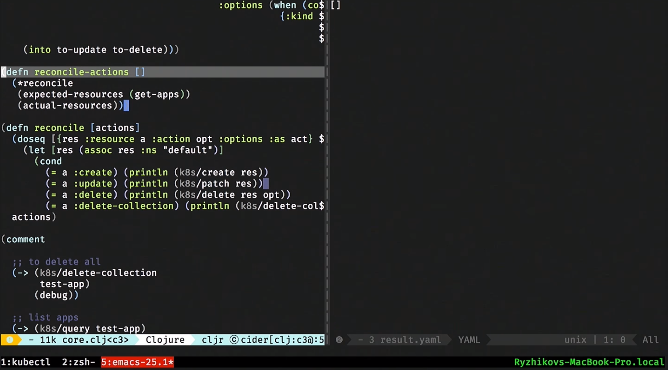
Давайте ее дернем. Ничего страшного в ней нет, ее можно дебажить. Она говорит, что нужно создать ingress-сервис, сделать в нем две записи, создать деплоймент 1 и 2, создать сервис 1 и 2.
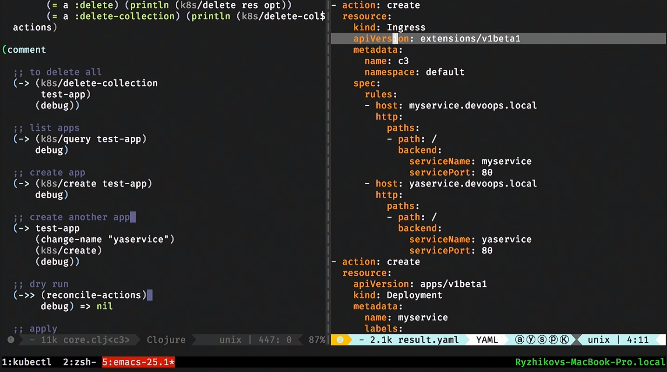
В данном случае уже должен быть только один сервис. Мы видим по ingress, что остается только одна запись.
Дальше все, что остается, это написать функцию, которая применит этот патч к Kubernetes-кластеру. Для этого мы просто передадим reconcile-actions в функцию reconcile, и все применится. И вот мы видим, что поднялся POD, сделался deployment и запустился сервис.

Давайте добавим еще один сервис: еще раз выполним функцию reconcile-actions. Посмотрим, что произошло. Все запустилось, все хорошо.

Как с этим быть? Мы все это упаковываем в Docker-container. После этого пишем функцию, которая периодически просыпается, делает reconcile и засыпает. Скорость не очень важна, она может спать по пять секунд и делать reconcile-actions не так часто.

Наш кастомный контроллер — это просто сервис, который будет просыпаться и периодически вычислять патч.
Сейчас у нас два сервиса задеплоино, давайте удалим одно из приложений. Посмотрим, как отреагировал наш кластер: все ок. Удаляем второй: все очистилось.

Давайте посмотрим глазами разработчика. Ему нужно просто сказать Kubernetes apply и задать имя нового сервиса. Делаем это, наш контроллер все подцепил и создал.

Дальше мы все это собираем в deployment сервис, и штатными средствами Kubernetes этот кастомный контроллер закидываем в кластер. Мы создали абстракцию за 200 строчек кода.
Это все похоже на HELM, но на самом деле мощнее. Контроллер работает в кластере: он видит базу, видит внешний мир и его можно сделать достаточно умным.
Собственный CI
Рассмотрим примеры расширения Kubernetes. Мы решили, что CI должен быть частью инфраструктуры. Это хорошо, это удобно с точки зрения безопасности — приватный репозиторий. Мы пытались использовать jenkins, но он — устаревшее средство. Захотелось хакерского CI. Интерфейсы нам не нужны, мы любим ChatOps: пусть просто скажет в чат, упал билд или нет. Кроме того, хотелось все локально отлаживать.

Мы сели и за неделю написали свой CI. Просто как расширение к Kubernetes. Если задуматься над CI, то это просто инструмент, который запускает какие-то jobs. В рамках этого job мы что-то билдим, прогоняем тесты, зачастую деплоим.
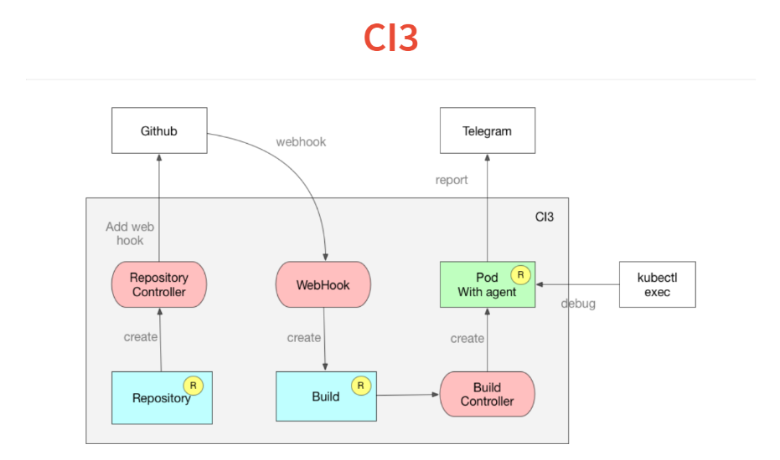
Как это все работает? Оно построено на такой же концепции кастомных контроллеров. Во-первых, мы закидываем в Kubernetes описание того, за какими репозиториями мы следим. Контроллер просто идет на гитхаб и добавляет web-hook. У нас остается интроспекция.
Дальше приходит web-hook, единственная задача которого — обработать входящий JSON и скинуть его в кастомный ресурс build, который тоже складывается в базу Kubernetes. За ресурсом build у нас следит build controller, который считывает manifest, лежащий внутри проекта, и запускает POD. В этом POD-е запускаются все необходимые сервисы.
В POD-е очень простенький agent, который читает декларацию в стиле travis или circleci, а в YAML набор шагов. Он их начинает выполнять. После чего в конце билда он закидывает свой результат в Telegram.
Другая фича, которую мы получили вместе с Kubernetes — это то, что одной из команд в выполнении вашего CI или continuous delivery можно поставить просто while true sleep 10, и ваш POD зависнет на этом шаге. Вы делаете kubectl exec, оказываетесь внутри вашего билда и можете дебажить.
Другая фича — все построено на докерах и отлаживать скрипт можно локально, запуская докер. На это все ушло две недели и 300 строчек кода.
Работа с postgres
Наш продукт построен на postgres, мы используем всякие его интересные фичи. Мы даже написали ряд extensions. Но мы не можем использовать RDS или еще что-то.
Сейчас мы в процессе разработки оператора для неубиваемого postgres. Озвучу архитектуру. Я хочу сказать «Кластер, дай мне postgres, который нельзя убить». Добавить к этому, что мне нужно две асинхронные реплики, одну синхронную, бэкапы ежедневно и до терабайта. Я это все закидываю, дальше у меня cluster controller начинает заниматься оркестрацией и разворачиванием моего контейнера. Он создает pginstance-ресурсы, которые отвечают за каждый istance postgres. Это будет cluster postgres.
Дальше pginstance controller, достаточно простой, просто пытается запустить там POD или deployment с этим postgres. Сердцем является persistent volume. Вся эта машина берет полный контроль над postgres. Вы даете ей Docker-container, в котором есть только binary postgres. Все остальное: конфигурацию и создание стартового кластера postgres делает сам контроллер. Он делает это так, чтобы мы позже могли реконфигурировать, и так, чтобы он мог настроить репликацию, уровни логов и т.д. В начале временный POD проезжается поверх persistent volume и создает там postgres cluster для master.
Далее поверх этого запускается deployment с master. Потом таким же образом создается persistent volume. Другой POD проезжается, делает базовый бекап, стягивает его, и поверх этого запускается deployment со slave.
Далее cluster controller создает backup ресурс (после того, как ему описали бекапы). А backup controller уже берет его и закидывает в какой-нибудь S3.

Что дальше?
Давайте представим с вами ближайшее будущее. Может так получиться, что рано или поздно у нас будут такие интересные кастомные ресурсы, кастомные контроллеры, что я скажу «Дай мне postgres, дай мне kafka, оставь мне CI и все это запусти». Все будет просто.
Если говорить не о ближайшем будущем, то я, как декларативный программист, считаю, что выше функционального программирования только логическое или реляционное. Там у нас operations семантика полностью отделена от information-семантики. Если мы посмотрим внимательно на наши кастомные контроллеры, которые мы делали, то у нас в базе лежит, например, resource application. А мы из него выводим еще три дополнительных ресурса. Это очень похоже на вьюху в базе данных. Это выведение фактов. Это logical или relation вьюха.
Следующий шаг для Kubernetes — вместо рубленого REST API дать некую иллюзию реляционной или логической базы, где можно просто написать правило. Поскольку у нас рано или поздно все стекается в базу, включая фидбек, правила могут звучать так: «Если нагрузка увеличилась вот так, то увеличь репликацию так». У нас будет маленькое sql или логическое правило. Нужен только generic движок, который за этим будет следить. Но это светлое будущее.

Больше крутых докладов — на конференции DevOops 2018! Все спикеры и программа — на сайте.Если у вас дома стоят на полке «The DevOps Handbook», «Learning Chef: A Guide to Configuration Management and Automation», «How to containerize your Go code» или новенькая «Liquid Software: How to Achieve Trusted Continuous Updates in the DevOps World» — захватите их с собой на конференцию. В дискуссионных зонах после докладов мы организуем небольшие автограф-сессии с авторами этих книг.
Только вдумайтесь: уникальная возможность получить автограф от самого Джона Уиллиса!
А еще приятный бонус: до 1 октября билет на DevOops 2018 можно забронировать со скидкой.
Комментариев нет:
Отправить комментарий