Массачусетский Технологический институт. Курс лекций #6.858. «Безопасность компьютерных систем». Николай Зельдович, Джеймс Микенс. 2014 год
Computer Systems Security — это курс о разработке и внедрении защищенных компьютерных систем. Лекции охватывают модели угроз, атаки, которые ставят под угрозу безопасность, и методы обеспечения безопасности на основе последних научных работ. Темы включают в себя безопасность операционной системы (ОС), возможности, управление потоками информации, языковую безопасность, сетевые протоколы, аппаратную защиту и безопасность в веб-приложениях.
Лекция 1: «Вступление: модели угроз» Часть 1 / Часть 2 / Часть 3
Лекция 2: «Контроль хакерских атак» Часть 1 / Часть 2 / Часть 3
Лекция 3: «Переполнение буфера: эксплойты и защита» Часть 1 / Часть 2 / Часть 3
Лекция 4: «Разделение привилегий» Часть 1 / Часть 2 / Часть 3
Лекция 5: «Откуда берутся ошибки систем безопасности» Часть 1 / Часть 2
Лекция 6: «Возможности» Часть 1 / Часть 2 / Часть 3
Лекция 7: «Песочница Native Client» Часть 1 / Часть 2 / Часть 3
Лекция 8: «Модель сетевой безопасности» Часть 1 / Часть 2 / Часть 3
Лекция 9: «Безопасность Web-приложений» Часть 1 / Часть 2 / Часть 3
Лекция 10: «Символьное выполнение» Часть 1 / Часть 2 / Часть 3
Лекция 11: «Язык программирования Ur/Web» Часть 1 / Часть 2 / Часть 3
Лекция 12: «Сетевая безопасность» Часть 1 / Часть 2 / Часть 3
Лекция 13: «Сетевые протоколы» Часть 1 / Часть 2 / Часть 3
Лекция 14: «SSL и HTTPS» Часть 1 / Часть 2 / Часть 3
Лекция 15: «Медицинское программное обеспечение» Часть 1 / Часть 2 / Часть 3
Лекция 16: «Атаки через побочный канал» Часть 1 / Часть 2 / Часть 3
Лекция 17: «Аутентификация пользователя» Часть 1 / Часть 2 / Часть 3
Лекция 18: «Частный просмотр интернета» Часть 1 / Часть 2 / Часть 3
Лекция 19: «Анонимные сети» Часть 1 / Часть 2 / Часть 3
Лекция 20: «Безопасность мобильных телефонов» Часть 1 / Часть 2 / Часть 3
Лекция 21: «Отслеживание данных» Часть 1 / Часть 2 / Часть 3
Студент: таким образом, идеальным решением будет архитектурная поддержка?
Профессор: да, для этого тоже имеются методы. Однако это немного сложно, потому что, как вы видите, мы выделили состояние taint рядом с самой переменной. Поэтому, если вы думаете о поддержке, которую осуществляет само оборудование, может быть очень трудно изменить компоновку «железа», потому что здесь всё запечено в кремний. Но если это возможно на высоком уровне в виртуальной машине Dalvic, можно представить, что можно будет размещать рядом переменные и их заражение и на аппаратном уровне. Так что если изменить компоновку в кремнии, то вы, вероятно, можете сделать эту работу.

Студент: а что TaintDroid делает с информацией, которая строится на разрешениях git ветвей, Branch permissions?
Профессор: мы вернемся к этому через секунду, так что просто придержите эту мысль, пока мы до неё не доберемся.
Студент: любопытно, не может ли здесь возникнуть переполнение буфера, потому что эти вещи – переменные и их заражения — складываются вместе?
Профессор: это хороший вопрос. Можно было бы надеяться, что в таком языке, как Java, нет переполнения буфера. Но в случае с языком C может случиться что-то катастрофическое, потому что если вы каким-то образом сделали переполнение буфера, а затем перезаписали теги taint для переменных, то в стеки установятся их нулевые значения и данные свободно «утекут» в сеть.
Студент: думаю, что всё это можно предсказать?
Профессор: совершенно верно. Вопрос переполнения буфера можно решить с помощью «канареек» – стековых индикаторов, потому что если у вас имеются эти данные в стеке, то вы не захотите делать их не перезаписываемыми или не захотите, чтобы уже перезаписанные значения были бы взломаны каким-то образом. Так что вы совершенно правы — можно просто не допускать переполнения буфера.
Короче говоря, на этом низком уровне x86/ARM можно обеспечить отслеживание taint, хотя это может дороговато и немного сложно осуществить правильным образом. Вы можете спросить, почему мы в первую очередь решаем вопрос отслеживания заражений вместо того, чтобы следить за тем, как программа пытается отправить что-то по сети, просто выполняя при этом сканирование данных, которые кажутся нам конфиденциальными. Это представляется довольно лёгким, потому что тогда нам не понадобится динамически отслеживать всё, что делает программа.

Проблема в том, что это будет работать только на уровне эвристики. На самом деле, если злоумышленник знает, что вы поступаете именно таким образом, он легко сможет вас взломать. Если вы просто сидите там и пытаетесь сделать grep для номеров социального страхования, злоумышленник может просто использовать кодировку base 64 или сделать какую-то другую дурацкую вещь, например, сжатие. Обход фильтра такого типа довольно тривиален, поэтому на практике этого совершенно недостаточно для обеспечения безопасности.
Теперь давайте вернемся к вашему вопросу о том, как мы можем отслеживать потоки, протекающие через ветви Branch. Это приведет нас к теме, которая называется «Неявные потоки», или Implicit Flows. Неявный поток обычно возникает, когда у вас имеется зараженное значение, которое будет влиять на способ назначения другой переменной, даже если эта переменная неявного потока не назначает переменные напрямую. Приведу конкретный пример.
Допустим, у вас есть оператор if, который посмотрит на ваш IMEI и скажет: «если он больше 42, то я назначу х = 0, в противном случае я назначу х = 1».
Интересно то, что сначала мы рассматриваем конфиденциальные данные IMEI и выполняем их сравнение с некоторым числом, но затем, назначая х, мы не присваиваем ничего, что было бы получено непосредственно из этих конфиденциальных данных.
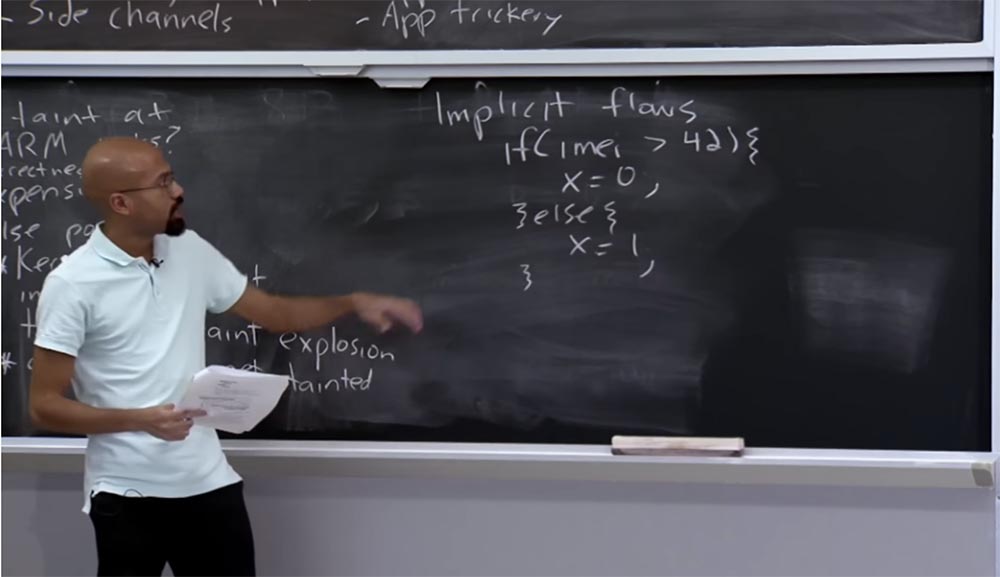
Это пример одного из неявных потоков. Значение x действительно зависит от расположенного выше сравнения, но противник, если он умен, может построить свой код таким образом, что в нём не будет прослеживаться никакой прямой связи.
Обратите внимание, что даже здесь, вместо того, чтобы просто назначать x = 0, х=1, вы можете просто поместить команду отправить что-то по сети, то есть вы можете сказать по сети, что x = 0 или х=1, или что-то вроде этого. Это пример одного из таких неявных потоков, которым не может управлять система, подобная TaintDroid. Итак, это называется неявным потоком в отличие от явного потока, например, оператора присваивания. Так что разработчики знают об этой проблеме.
Если я правильно понял, меня спросили, что произойдёт, если у нас имеется какая-то машинная функция, которая делает нечто аналогичное приведённому примеру, и поэтому системе TaintDroid это знать не обязательно, потому что TaintDroid не сможет заглянуть в этот машинный код и увидеть вещи такого рода. Кстати, разработчики утверждают, что они будут управлять этим с помощью машинно-ориентированных методов, которые определяются самой виртуальной машиной и они будут рассматривать способ, которым этот метод осуществляется. Например, мы берём два этих числа и затем возвращаем их среднюю величину. В этом случае система TaintDroid будет доверять машинной функции, поэтому нам нужно выяснить, какой должна быть соответствующая политика заражения taint.
Тем не менее, вы правы, что если что-то подобное было скрыто внутри машинного кода и по какой-то причине не подвергнуто открытой ревизии, то ручные политики, которые придумали авторы TaintDroid, могут не уловить этот неявный поток. Фактически это может позволить информации как-то просочиться. Причем там может быть даже прямой поток, который не заметили авторы TaintDroid, и у нас может иметь место даже более прямая утечка.

Студент: то есть на практике это кажется очень опасным, верно? Потому что вы можете буквально стереть все заражённые значения, просто глядя на 3 последних строчки.
Профессор: у нас было несколько занятий, где рассматривалось, как неявные потоки совершают такие вещи. Существует несколько способов это исправить. Одним из походов для предотвращения таких вещей является назначение тега taint для PC, по существу вы заразите его с помощью Branch test. Идея заключается в том, что мы с человеческой точки зрения можем рассмотреть этот код и сказать, что здесь существует этот неявный поток, потому что, чтобы попасть сюда, нам нужно было покопаться в конфиденциальных данных.
Так что же это означает на уровне реализации? Это значит, что чтобы попасть сюда, в PC должно иметься что-то, что было заражено конфиденциальными данными. То есть можно сказать, что мы получили эти данные, потому что PC был установлен здесь – х=0 – или здесь – х=1.
В общем можно себе представить, что система проведёт некоторый анализ и выяснит, что в данном месте Implicit flows PC вообще не заражен, далее он подхватывает заражение от IMEI, и в этом месте, где х=0, PC уже заражен. В конечном итоге произойдет то, что если x — это переменная, которая изначально отображается без taint, то мы скажем: «хорошо, в этом месте x=0, мы получаем заражение от PC, которое фактически было заражено выше, в IMEI». Здесь есть некоторые тонкости, но в целом можно проследить, как PC устанавливается и затем пытается распространить заражение на целевых операторов.
Это понятно? Если вы хотите узнать побольше, то мы можем поговорить на эту тему, потому что я проделал много исследований такого рода. Тем не менее, система, которую я только что описал, опять-таки может быть слишком консервативной. Представьте, что вместо х=1 здесь у нас, как и вверху, тоже находится х = 0. В этом случае нет никакого смысла заражать х чем-то связанным с IMEI, потому из этих ветвей не может просочиться никакая информация.
Но если вы пользуетесь машинной схемой заражения PC, то можете переоценить, сколько переменных x было испорчено. Существуют некоторые тонкости, которые вы можете проделать, чтобы попытаться обойти некоторые из этих проблем, но это будет немного сложно.
Студент: когда вы выходите из заявления if, вы также выходите из Branch, и вы очищаетесь от заражения?
Профессор: как правило, да, как только заканчивается набор переменных, PC будет очищен от заражения. Заражение устанавливается только внутри этих ветвей от х до х. Причина в том, что когда вы спускаетесь сюда вниз, вы делаете это независимо от того, каким был IMEI.
Мы говорили о том, что отслеживание заражения на этом очень низком уровне полезно, хотя довольно дорогостояще, потому что это действительно позволит увидеть, каково время жизни ваших данных. Пару лекций назад мы говорили о том, что довольно часто ключевые данные живут в памяти намного дольше, чем вы думаете.
Можно представить, что хотя отслеживание заражения на уровне x86 или ARM довольно дорого, вы можете использовать это для аудита вашей системы. Например, можно заразить некий секретный ключ, который ввел пользователь, и проследить, куда и как это движется по всей системе. Это автономный анализ, он не влияет на пользователей, поэтому нормально, что он может быть медленным. Подобный анализ поможет выяснить, что, например, вот эти данные попадают в буфер клавиатуры, эти на внешний сервер, эти куда-либо ещё. Так что даже если это медленный процесс, он все равно может быть очень полезным.
Как я уже говорил, полезным свойством TaintDroid является то, что он ограничивает «вселенную» источников заражения и поглотителей зараженной информации. Но как разработчик, вы, вероятно, захотите иметь более точный контроль над метками заражений, с которыми взаимодействует ваша программа. Поэтому как программист, вы захотите сделать следующее.
Итак, вы объявляете некоторый int такого вида и называете его X, а затем связываете с ним метку. Смысл этой метки в том, что Алиса является владельцем информации, которую она разрешает просмотреть Бобу, или же эта информация помечена для просмотра Бобом. TaintDroid не позволяет вам этого сделать, потому что он по существу контролирует эту вселенную меток, но как программист, вы можете захотеть это проделать.
Предположим, что в вашей программе имеются входные и выходные каналы, и они тоже снабжены метками. Это те метки, которые вы выбрали как программист, в отличие от самой системы, пытающейся сказать, что подобные вещи предопределяются заранее. Скажем, для входных каналов вы устанавливаете значения read, которые получают метку канала.
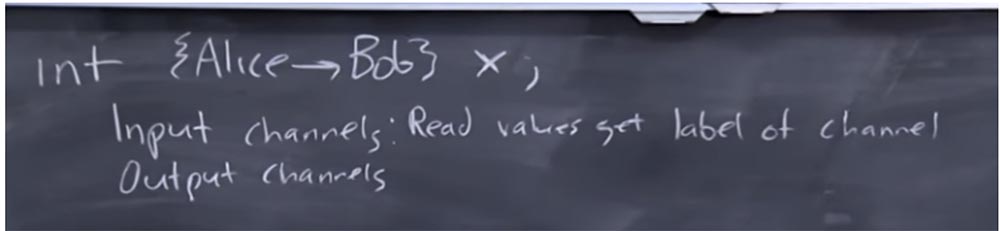
Это очень похоже на то, как работает TaintDroid – если прочитываются значения датчика GPS, они помечаются тегом taint канала GPS, но теперь вы как программист сами выбираете эти метки. В таком случае метка выходного канала должна совпадать со значением метки, которое мы записали.

Здесь можно представить и другие политики, но основная идея заключается в том, что существуют менеджеры программ, которые позволяют разработчику выбрать, что это за метки и какой может быть их семантика. Это потребует от программиста много работы, результатом которой станет возможность проводить статическую проверку. Под статической я имею в виду проверку, которая выполняется во время компиляции и может «поймать» множество типов ошибок информационного потока.
Так что если вы старательно обозначите метками с соответствующими разрешениями все каналы сети и каналы экрана, а затем тщательно разместите свои данные, которые приведены на доске в качестве примера, то во время компиляции компилятор сможет сказать вам: «эй, если вы запустите эту программу, то у вас может возникнуть утечка информации, потому что часть данных пройдёт через канал, который не является доверенным».
На высоком уровне статическая проверка сможет поймать много таких ошибок, потому что подобные комментарии int {Alice Bob} х немного похожи на типы. Так же, как компиляторы могут ловить ошибки, связанные с типами, на языке типов, они могут точно также работать с кодом, написанном на приведенном выше языке, говоря, что если вы запустите данную программу, это может стать проблемой. Поэтому вам нужно исправить то, как работают метки, возможно, вам понадобится что-то рассекретить, и так далее.
Таким образом, в зависимости от языка, эти метки могут ассоциироваться с людьми, с портами ввода-вывода и подобными вещами. TaintDroid даёт возможность ознакомиться с принципами работы информационных потоков и утечек информации, однако существуют более сложные системы с более выраженной семантикой управления этими процессами.
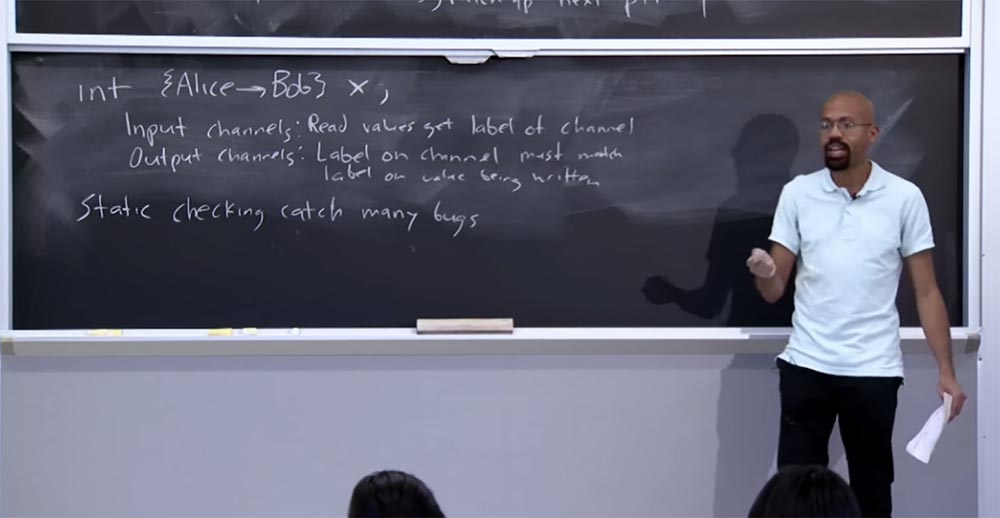
Учтите, что когда мы говорим о статической проверке, нам предпочтительно поймать как можно больше сбоев и ошибок именно при помощи статистической проверки, а не динамической проверки. На это имеется весьма деликатная причина. Допустим, что мы откладываем все статические проверки на время выполнения программы, что мы определенно можем сделать.
Проблема в том, что сбой или успех этих проверок представляет собой неявный канал. Таким образом, злоумышленник может предоставить программе некоторую информацию, а затем проверить, не вызвало ли это сбой программы. Если сбой произошёл, хакер может сказать: «ага, мы прошли некоторую динамическую проверку потока информации, значит, здесь имеется какой-то секрет относительно значений, влияющих на процесс вычислений». Поэтому вы захотите попытаться сделать эти проверки как можно более статичными.
Если вы хотите больше информации об этих вещах, вам стоит ознакомиться с Jif. Это очень мощная система, которая создала методы вычислений меток labels. Вы можете начать с неё и двигаться в этом направлении дальше. Мой коллега -профессор Зельдович сделал много хорошего в этой области, так что вы можете поговорить с ним на эту тему.
Интересно, что TaintDroid очень ограничен в возможностях рассмотрения и описания меток. Существуют системы, которые позволяют вам делать более мощные вещи.
Наконец, я хотел бы поговорить о том, что мы можем сделать, если захотим отслеживать информационные потоки с помощью традиционных программ или с помощью программ, написанных на C или C++, которые не поддерживают все эти вещи в процессе выполнения кода. Существует очень разумная система TightLip, и некоторые из авторов этой же статьи рассматривают вопрос о том, как можно отслеживать утечки информации в системе, в которой мы вообще не хотим ничего изменять в самом приложении.
Основная идея заключается в том, что здесь водится понятие doppelganger processes, или «двойники процессов». Система TightLip по умолчанию использует двойник процесса. Первое, что она делает, это периодически сканирует файловую систему пользователя, разыскивая конфиденциальные типы файлов. Это может быть что-то вроде файлов электронной почты, текстовых документов и так далее. Для каждого из этих файлов система создаёт его «подчищенную» версию. То есть в файле письма электронной почты она заменит информацию «кому» или «от кого», строкой той же длины, содержащей фиктивные данные, например, пробелы. Это выполняется в виде фонового процесса.
Второе, что проделывает TightLip, когда запускается какой-то процесс, это определяет, не пытается ли этот процесс получить доступ к конфиденциальному файлу. Если такой доступ имеет место, TightLip создаёт двойник этого процесса. Этот двойник выглядит точно так же, как оригинальный процесс, который пытается затронуть конфиденциальные данные, но коренное отличие состоит в том, что двойник, я обозначу его DG, считывает вычищенные данные.

Представьте, что выполняется некий процесс, который пытается получить доступ к вашему файлу электронной почты. Система порождает этот новый процесс, doppelganger, точно такой же, как оригинальный, но теперь он читает вычищенные данные вместо реальных конфиденциальных данных. По сути, TightLip параллельно запускает оба эти процесса и наблюдает за ними, чтобы видеть, что они делают. Если оба процесса выполняют те же системные вызовы с теми же аргументами, то, предположительно, эти системные вызовы не зависят от конфиденциальных данных. Другими словами, если я запускаю процесс, который пытается открыть какой-то конфиденциальный файл, я предоставляю ему подчищенную версию файла и даю возможность выполнить свою работу, и если процесс – двойник делает то же самое, что и обычный процесс, то, по-видимому, конфиденциальные данные вообще не оказывают никакого влияния.

Так что, по сути, TightLip позволит этим процессам выполняться, а затем проверит системные вызовы. При этом может случиться так, что в некоторых случаях системные вызовы будут отличаться. Например, двойник начнёт делать то, чего никогда бы не сделал оригинальный процесс, предположим, сетевой вызов. Так же, как и в случае TaintDroid, когда этот двойник пытается сделать сетевой вызов, мы говорим: «ага, вероятно, мы должны остановить то, что сейчас происходит, и что-то с этим сделать».
Итак, если системные вызовы отличаются и двойник делает сетевой вызов, тогда мы собираемся либо поднять тревогу для привлечения внимания пользователя, либо что-то еще. Как и в TaintDroid, здесь имеется определенная политика, которую вы можете добавить к какой-то конкретной системе, которую собираетесь использовать. Здесь есть интересный момент — так или иначе, на этот процесс — двойник повлияли возвращенные конфиденциальные данные. Это значит, что если пользователь не думал, что конкретный процесс собирается извлечь конфиденциальные данные, то теперь он может провести аудит программы, чтобы выяснить, почему эта программа намеревалась отправить эти данные по сети.
Студент: я думаю, что если вы нажимаете на что что-то вроде файла Word, вы должны знать, что процесс-двойник обнулит файл именно этого типа.
Профессор: правильно, это хороший вопрос. Поэтому я собирался обсудить некоторые ограничения, и одно из них заключается именно в этом. Необходимо иметь скрубберы для каждого типа файлов. Вы не можете просто взять скруббер для электронной почты и использовать его в Word. Потому что если эти скрубберы что-то пропустят, так как не будут способны редактировать какие-то типы файлов, то система может не отследить место утечки конфиденциальных данных. Так что вы совершенно правы насчет этого.
Студент: я так понимаю, что процесс должен сначала осмотреть все данные, прежде чем запустить двойник? Иначе он может просто отправить какие-то неочищенные данные в сеть.
Профессор: нет, это не так. Двойник может попытаться рассмотреть такую вещь, как адрес электронной почты, прежде чем он пытается отправить его, но процесс-двойник не должен знать о том, что он получил эти странные очищенные данные. Это возвращает нас к вопросу, о котором мы только что говорили. Если ваш скруббер не «вычищает» вещи семантически разумным способом, двойник потерпит сбой, потому что ожидал вещь конкретного формата, который не смог получить.
Но на высоком уровне, идея заключается в том, что мы пытаемся обмануть двойник, чтобы он всё проделал обычным путём, но только с теми данными, которые отличаются от оригинальной версии, и посмотреть, будет ли иметь место это расхождение.

Единственный недостаток – это то, что TightLip по существу помещает скрубберы в TCB, и если они не сработают должным образом, то может произойти сбой процесса-двойника, и мы не поймаем некоторые нарушения. Но самое хорошее в этом то, что он работает с устаревшими системами. Так что нам не нужно ничего менять в работе приложения. Мы просто должны внести некоторые незначительные изменения в ядро ОС, чтобы иметь возможность отслеживать системные вызовы, а затем продолжить свою работу. Это очень полезное свойство TightLip.
При этом накладные расходы системы представляют собой лишь расходы на работу дополнительного процесса, что не слишком обременяют современную операционную систему. Это просто своего рода аккуратный способ выполнить ограниченное отслеживание taint без внесения серьезных изменений в среду выполнения или в приложения.
Студент: мы только выполняем оба процесса параллельно или ждём, пока закончится каждый из них? Запускаем ли мы оба процесса, а затем после их окончания проверяем идентичность системных вызовов?
Профессор: это хороший вопрос! Пока процесс-двойник DG делает то, что ОС может контролировать и удерживать на локальном компьютере, он работает параллельно оригинальному процессу. Но как только двойник пытается повлиять на внешнее состояние, например, пытается подключить сеть, или совершить что-то, о чем не знает ядро, в этот момент вы должны остановить его и объявить об успехе проверки.
Желаю всем хорошего Дня Благодарения, увидимся на следующей неделе.
Полная версия курса доступна здесь.
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас оформив заказ или порекомендовав знакомым, 30% скидка для пользователей Хабра на уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps от $20 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps до января бесплатно при оплате на срок от полугода, заказать можно тут.
Dell R730xd в 2 раза дешевле? Только у нас 2 х Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 ТВ от $249 в Нидерландах и США! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?
Комментариев нет:
Отправить комментарий