Многие постоянные читатели и авторы сайта наверное задумывались о том, какой жизненный цикл имеют опубликованные здесь статьи. И хотя интуитивно это и так более-менее ясно (очевидно например, что статья на первой странице имеет максимальное число просмотров), но сколько конкретно?
Для сбора статистики воспользуемся Python, Pandas, Matplotlib и Raspberry Pi.
Тех кому интересно, что из этого получилось, прошу под кат.
Сбор данных
Для начала определимся с метриками — что мы хотим узнать. Тут все просто, у каждой статьи есть 4 основных параметра, отображаемых на странице — это количество просмотров, лайков, закладок и комментариев. Их мы и будем анализировать.
Желающие сразу увидеть результаты, могут перейти ко третьей части, а пока будет про программирование.
Общий план: распарсим нужные данные из веб-страницы, сохраним с CSV, и посмотрим что у нас получилось за период в несколько дней. Для начала загрузим текст статьи (обработка исключений опущена для наглядности):
link = "https://habr.com/ru/post/000001/"
f = urllib.urlopen(link)
data_str = f.read()
Теперь из строки data_str (она разумеется, в HTML) нужно извлечь данные. Открываем в браузере исходный код (непринципиальные элементы убраны):
<ul class="post-stats post-stats_post js-user_" id="infopanel_post_438514">
<li class="post-stats__item post-stats__item_voting-wjt">
<span class="voting-wjt__counter voting-wjt__counter_positive js-score" title="Общий рейтинг 448: ↑434 и ↓14">+420</span>
</li>
<span class="btn_inner"><svg class="icon-svg_bookmark" width="10" height="16"><use xlink:href="https://habr.com/images/1550155671/common-svg-sprite.svg#book" /></svg><span class="bookmark__counter js-favs_count" title="Количество пользователей, добавивших публикацию в закладки">320</span></span>
<li class="post-stats__item post-stats__item_views">
<div class="post-stats__views" title="Количество просмотров">
<span class="post-stats__views-count">219k</span>
</div>
</li>
<li class="post-stats__item post-stats__item_comments">
<a href="https://habr.com/ru/post/438514/#comments" class="post-stats__comments-link" <span class="post-stats__comments-count" title="Читать комментарии">577</span>
</a>
</li>
<li class="post-stats__item">
<span class="icon-svg_report"><svg class="icon-svg" width="32" height="32" viewBox="0 0 32 32" aria-hidden="true" version="1.1" role="img"><path d="M0 0h32v32h-32v-32zm14 6v12h4v-12h-4zm0 16v4h4v-4h-4z"/></svg>
</span>
</li>
</ul>
Нетрудно видеть, что нужный нам текст находится внутри блока '<ul class=«post-stats post-stats_post js-user_>', а нужные элементы находятся в блоках c названиями voting-wjt__counter, bookmark__counter, post-stats__views-count и post-stats__comments-count. По названиям все вполне очевидно.
Наследуем класс str и добавим в него метод извлечения подстроки, находящейся между двух тегов:
class Str(str):
def find_between(self, first, last):
try:
start = self.index(first) + len(first)
end = self.index(last, start)
return Str(self[start:end])
except ValueError:
return Str("")
Можно было обойтись и без наследования, но это позволит написать более лаконичный код. С ним все извлечение данных умещается в 4 строки:
votes = data_str.find_between('span class="voting-wjt__counter voting-wjt__counter_positive js-score"', 'span').find_between('>', '<')
bookmarks = data_str.find_between('span class="bookmark__counter js-favs_count"', 'span').find_between('>', '<')
views = data_str.find_between('span class="post-stats__views-count"', 'span').find_between('>', '<')
comments = data_str.find_between('span class="post-stats__comments-count"', 'span').find_between('>', '<')
Но это еще не все. Как можно видеть, число комментариев или просмотров может храниться в виде строки типа „12.1k“, которая напрямую в int не переводится.
Добавим функцию конвертации такой строки в число:
def to_int(self):
s = self.lower().replace(",", ".")
if s[-1:] == "k":
# "1.23k" => 1.23*1000 => 1230
return int(1000*float(s.replace("k", "")))
return int(self)
Осталось только добавить timestamp, и можно сохранять данные в csv:
timestamp = strftime("%Y-%m-%dT%H:%M:%S.000", gmtime())
str_out = "{},votes:{},bookmarks:{},views:{},comments:{};".format(timestamp, votes.to_int(), bookmarks.to_int(), views.to_int(), comments.to_int())
Поскольку нам интересно проанализировать несколько статей, добавим возможность указания ссылки через командную строку. Также будем формировать имя файла лога по ID статьи:
link = sys.argv[1] # "https://habr.com/ru/post/000001/"
link_path = urlparse.urlparse(link.strip("/")).path # https://habr.com/ru/post/000001/ => /ru/post/000001
link_parts = os.path.split(link_path) # /ru/post/000001=> ('/ru/post', '000001')
log_file = "habr_log%s.txt" % link_parts[1]
И самый последний шаг. Вынесем код в функции, в цикле опрашиваем данные, и записываем результаты в лог.
delay_s = 5*60
while True:
# Get data
data_str = get_as_str(link)
data_csv = extract_as_csv(data_str)
print data_csv
# Append data to log
with open(log_file, "a") as logfile:
logfile.write(data_csv + '\n')
sleep(delay_s)
Как можно видеть, обновление данных сделано раз в 5 минут, чтобы не создавать нагрузки на сервер. Файл программы я сохранил под названием habr_parse.py, при его запуске он будет сохранять данные, пока программа не будет закрыта.
Далее, желательно сохранить данные, хотя бы за несколько дней. Т.к. держать компьютер включенным несколько дней неохота, берем Raspberry Pi — его мощности для такой задачи без проблем хватит, да и в отличие от ПК, Raspberry Pi не шумит и почти не потребляет электроэнергии. Заходим по SSH и запускаем наш скрипт:
nohup python habr_parse.py https://habr.com/ru/post/0000001/ &
Команда nohup оставляет скрипт работать в фоне после закрытия консоли.
Как бонус, можно запустить в фоне http-сервер, введя команду „nuhup python -m SimpleHTTPServer 8000 &“. Это позволит смотреть результаты прямо в браузере в любой момент, открывая ссылку вида http://192.168.1.101:8000 (адрес разумеется может быть другим).
Теперь можно оставить Raspberry Pi включенным, и вернуться к проекту через несколько дней.
Анализ данных
Если все было сделано правильно, то на выходе должен быть примерно такой лог:
2019-02-12T22:26:28.000,votes:12,bookmarks:0,views:448,comments:1;
2019-02-12T22:31:29.000,votes:12,bookmarks:0,views:467,comments:1;
2019-02-12T22:36:30.000,votes:14,bookmarks:1,views:482,comments:1;
2019-02-12T22:41:30.000,votes:14,bookmarks:2,views:497,comments:1;
2019-02-12T22:46:31.000,votes:14,bookmarks:2,views:513,comments:1;
2019-02-12T22:51:32.000,votes:14,bookmarks:2,views:527,comments:1;
2019-02-12T22:56:32.000,votes:14,bookmarks:2,views:543,comments:1;
2019-02-12T23:01:33.000,votes:14,bookmarks:2,views:557,comments:2;
2019-02-12T23:06:34.000,votes:14,bookmarks:2,views:567,comments:3;
2019-02-12T23:11:35.000,votes:13,bookmarks:2,views:590,comments:4;
...
2019-02-13T02:47:03.000,votes:15,bookmarks:3,views:1100,comments:20;
2019-02-13T02:52:04.000,votes:15,bookmarks:3,views:1200,comments:20;
Посмотрим, как его можно обработать. Для начала, загрузим csv в pandas dataframe:
import pandas as pd
import numpy as np
import datetime
log_path = "habr_data.txt"
df = pd.read_csv(log_path, header=None, names=['datetime', 'votes', 'bookmarks', 'views', 'comments'])
Добавим функции для конвертации и усреднения, и извлечем необходимые данные:
def to_float(s):
# "bookmarks:22" => 22.0
num = ''.join(i for i in s if i.isdigit())
return float(num)
def running_mean(l, N=2):
sum = 0
result = len(l)*[0]
for i in range(0, N):
sum = sum + l[i]
result[i] = sum / (i + 1)
for i in range(N, len(l)):
sum = sum - l[i - N] + l[i]
result[i] = sum / N
return result
log_path = "habr_data.txt"
df = pd.read_csv(log_path, header=None, names=['datetime', 'votes', 'bookmarks', 'views', 'comments'])
print df.head()
dates = pd.to_datetime(df['datetime'], format='%Y-%m-%dT%H:%M:%S.%f')
dates += datetime.timedelta(hours=3)
views = df["views"].map(to_float, na_action=None)
views_avg = running_mean(views.values.tolist())
votes = df["votes"].map(to_float, na_action=None)
bookmarks = df["bookmarks"].map(to_float, na_action=None)
comments = df["comments"].map(to_float, na_action=None)
viewspervotes = views/votes
viewsperbookmarks = views/bookmarks
Усреднение нужно потому, что число просмотров на сайте выводится с шагом 100, что приводит к „рваному“ графику. В принципе это не обязательно, но с усреднением смотрится лучше. В коде также прибавляется московский часовой пояс (время на Raspberry Pi оказалось в GMT).
Наконец, можно вывести графики и посмотреть что получилось.
import matplotlib.pyplot as plt
# Draw
fig, ax = plt.subplots()
# plt.plot(dates, votes, 'ro', markersize=1, label='Votes')
# plt.plot(dates, bookmarks, 'go', markersize=1, label='Bookmarks')
# plt.plot(dates, comments, 'go', markersize=1, label='Comments')
ax.plot(dates, views_avg, 'bo', markersize=1, label='Views')
# plt.plot(dates, views_g, 'bo', markersize=1, label='Views')
# plt.plot(dates, viewspervotes, 'ro', markersize=1, label='Views/Votes')
# plt.plot(dates, viewsperbookmarks, 'go', markersize=1, label='Views/Bookmarks')
ax.xaxis.set_major_formatter(mdates.DateFormatter("%d-%d-%Y"))
ax.xaxis.set_major_locator(mdates.DayLocator())
ax.xaxis.set_minor_locator(mdates.HourLocator(interval=1))
fig.autofmt_xdate()
plt.legend(loc='best')
plt.xticks(rotation=45, ha="right")
plt.tight_layout()
plt.show()
Результаты
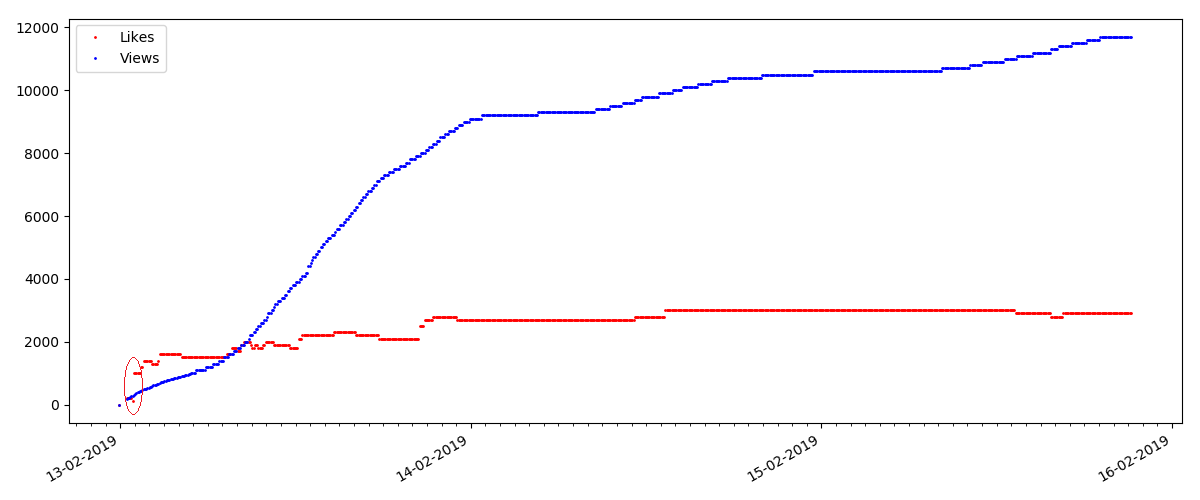
В начале каждого графика есть пустое место, которое объясняется просто — когда скрипт запускался, статьи уже были опубликованы, так что данные собирались не с нуля. „Нулевая“ точка была добавлена вручную из описания времени публикации статьи.
Все выложенные графики сгенерированы matplotlib и вышеприведенным кодом.
По результатам, исследованные статьи я разделил на 3 группы. Деление условно, хотя некий смысл в нем все же есть.
«Горячая» статья
Это статья на какую-то популярную и актуальную тему, с названием вроде „Как МТС списывает деньги“ или „Роскомнадзор заблокировал
Такие статьи имеют большое число просмотров и комментариев, но „ажиотаж“ длится максимум несколько дней. Также видна небольшая разница в росте числа просмотров в дневное и ночное время (но не столь значительная как ожидалось — видимо, Хабр читают практически со всех часовых поясов).
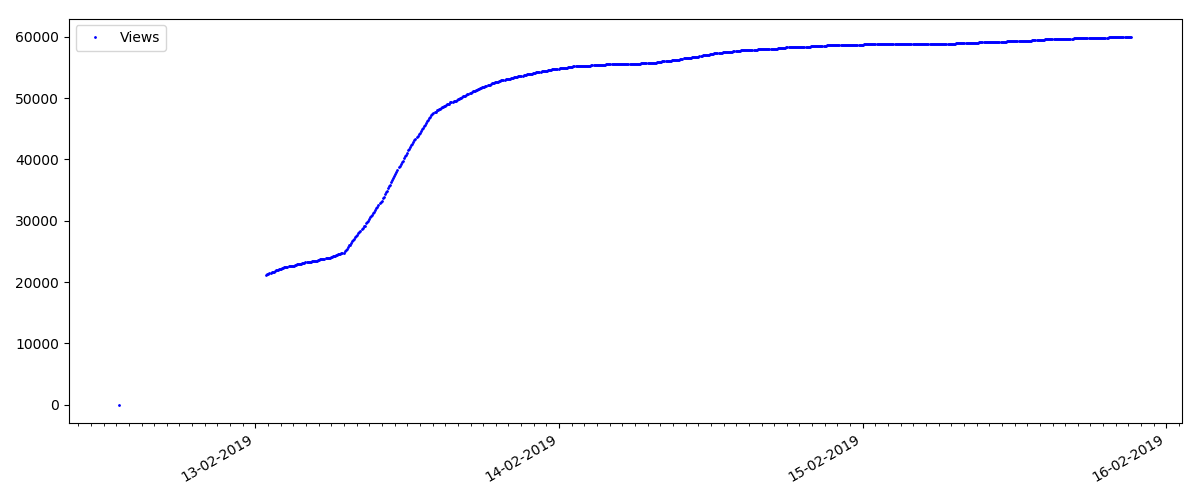
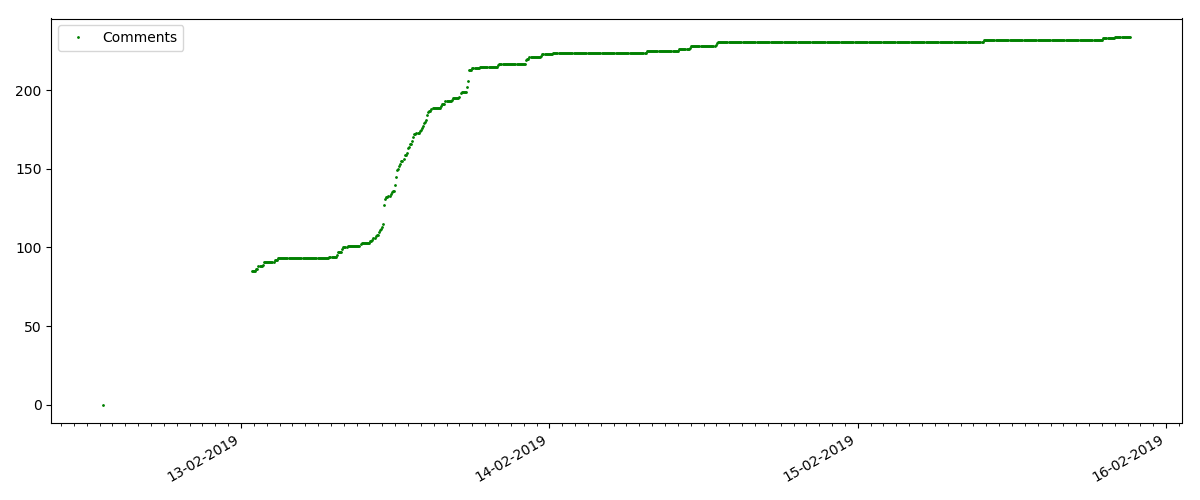
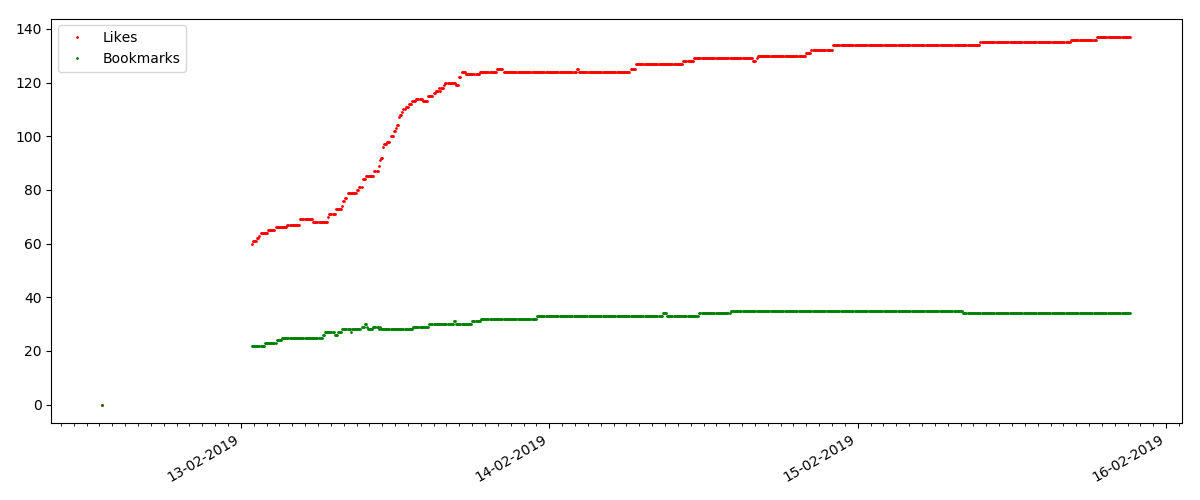
Число „лайков“ растет довольно значительно, число закладок при этом растет заметно медленнее. Это логично, т.к. статья может кому-то нравиться, но специфика текста такова, что для добавления в закладки она просто не нужна.
Cоотношение просмотров и лайков сохраняется примерно одинаковым и составляет грубо, 400:1:
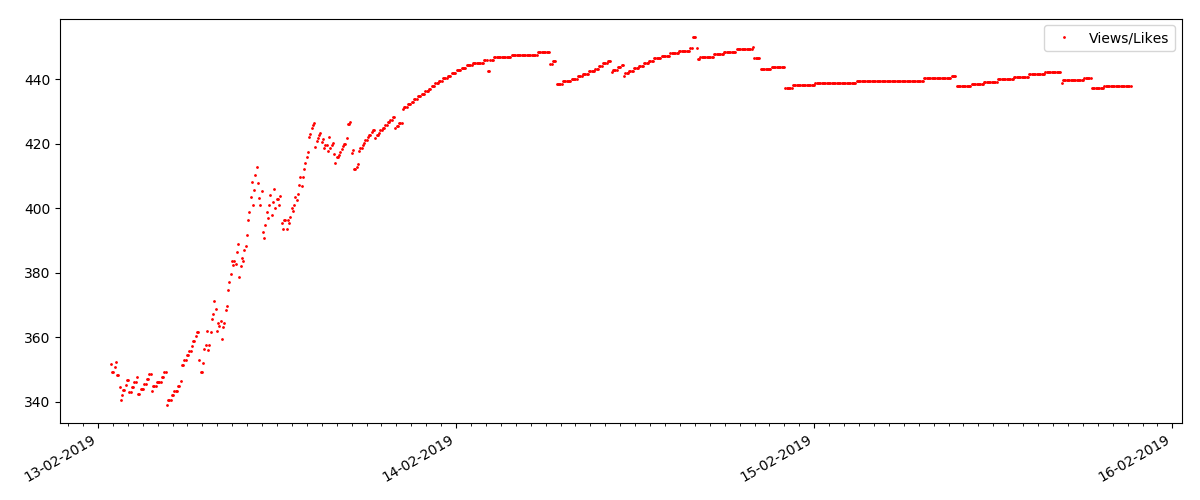
«Техническая» статья
Это более узкоспециализированная статья, типа „Настройка скриптов для Node JS“. Такая статья разумеется, набирает в разы меньше просмотров чем „горячая“, число комментариев также заметно меньше (в данном случае их оказалось всего 4).
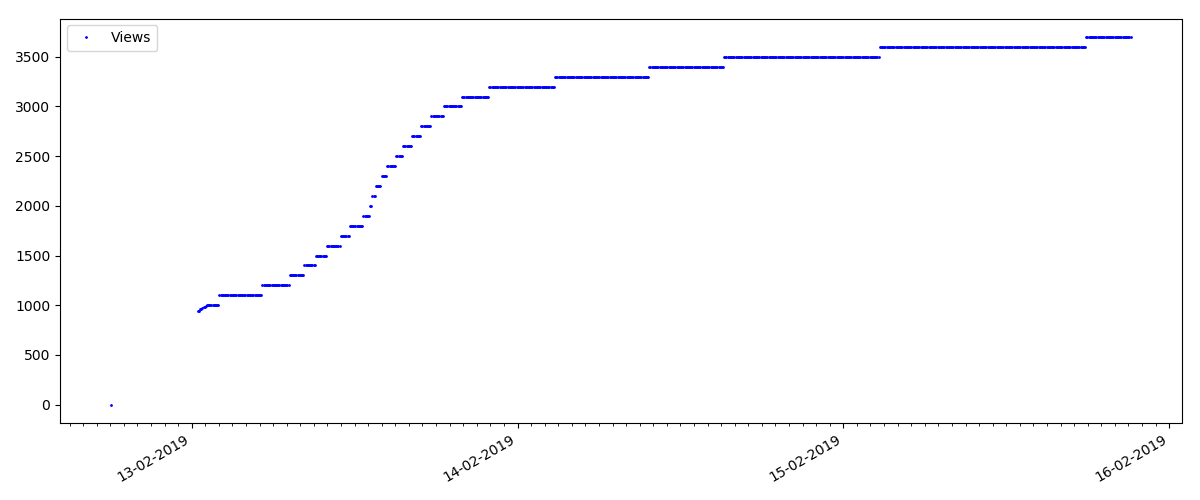
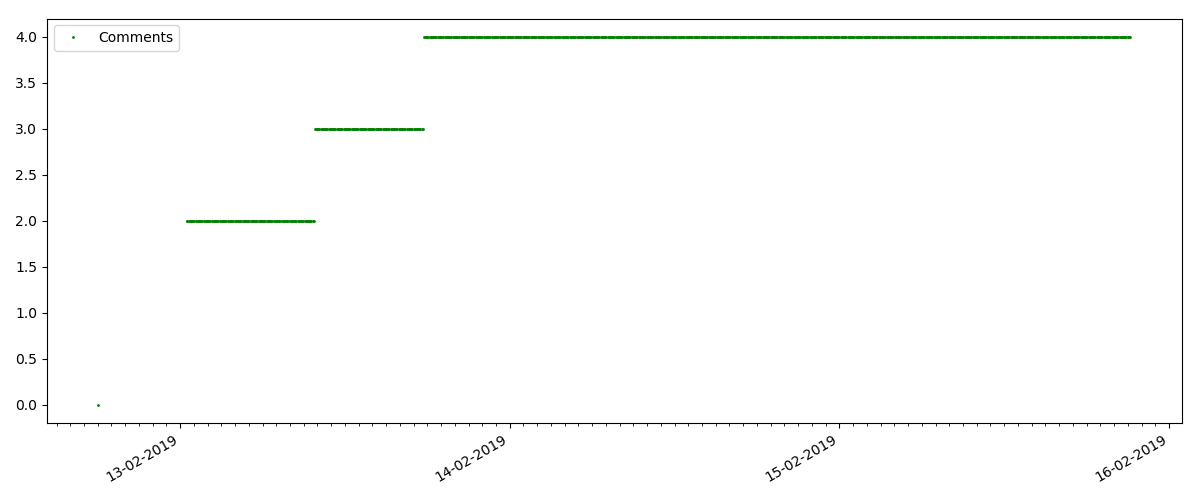
А вот следующий момент интереснее: число „лайков“ для таких статей растет заметно медленнее, чем число „закладок“. Тут все наоборот по сравнению с предыдущим вариантом — многие находят статью полезной, чтобы сохранить на будущее, но при этом читатель вовсе не обязательно нажмет „лайк“.
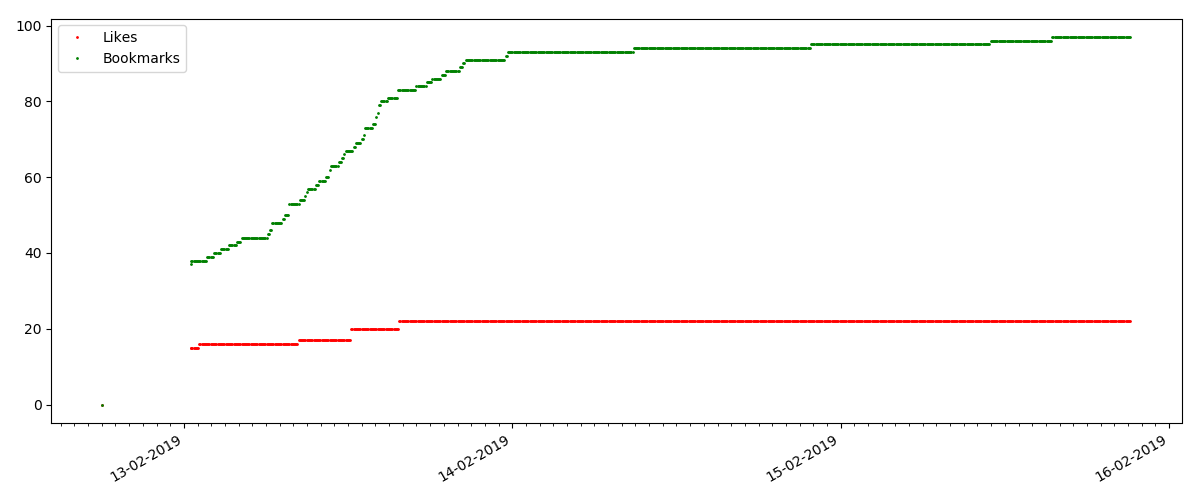
Кстати, на этот момент хотелось бы обратить внимание администраторов сайта — при расчете рейтингов статей стоит засчитывать „закладки“ параллельно с „лайками“ (например объединяя множества по „ИЛИ“). В противном случае, это приводит к перекосу в рейтинге, когда заведомо хорошая статья имеет много добавлений в закладки (т.е. читателям она определенно понравилась), но эти люди забыли или поленились нажать „лайк“.
И наконец, отношение просмотров и лайков: можно видеть, что оно заметно выше чем в первом варианте и составляет грубо, 150:1, т.е. качество контента косвенно тоже можно считать более высоким.
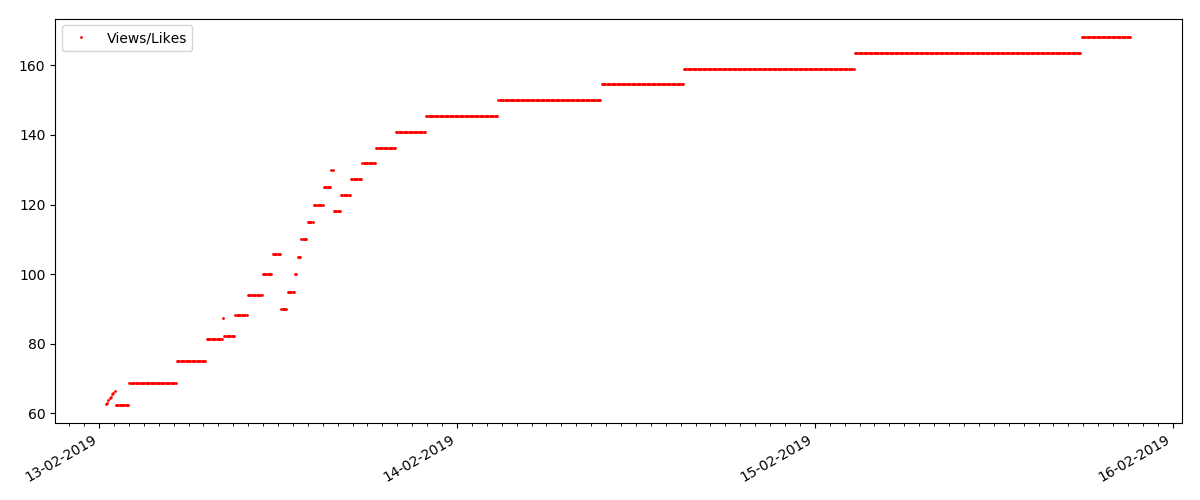
«Подозрительная» статья (но это не точно)
Для следующей рассмотренной статьи число „лайков“ выросло на треть за 5-минутный интервал (сразу на 10 при общих набранных 30 за все несколько дней).
Можно было бы заподозрить накрутку, но „теория массового обслуживания“ в принципе допускает такие всплески. А может автор просто разослал ссылку всем своим 10 знакомым, что разумеется, не запрещено правилами.
Выводы
Главный вывод — все есть тлен и майя. Даже самый популярный материал, набирающий тысячи просмотров, уйдет „в прошлое“ всего за 3-4 дня. Такова увы, специфика современного интернета, и наверно, всей современной медийной индустрии в целом. И уверен, показанные цифры специфичны не только для Хабра, но и для любого аналогичного интернет-ресурса.
В остальном, данный анализ имеет скорее „пятничный“ характер, и разумеется, не претендует на серьезное исследование. Также надеюсь кто-то нашел что-либо новое в использовании Pandas и Matplotlib.
Спасибо за внимание.
Комментариев нет:
Отправить комментарий