Многие разработчики стремятся оптимизировать свой код. Они берут строчку и переписывают ее, говоря, что так станет быстрее. Нужно остановиться. Говорить, что тот или иной код быстрее, можно только после того, как он отпрофилирован и сделаны бенчмарки. Гадание не является правильным подходом к написанию кода.
Мне давно хотелось на практическом примере продемонстрировать, как это может работать. И на днях мое внимание привлек следующий код, который как раз можно было бы использовать в качестве такого примера:
builds := store.Instance.GetBuildsFromNumberToNumber(stageBuild.BuildNumber, lastBuild.BuildNumber)
tempList := model.BuildsList{}
for i := len(builds) - 1; i >= 0; i-- {
b := builds[i]
b.PatchURLs = b.ReversePatchURLs
b.ExtractedSize = b.RPatchExtractedSize
tempList = append(tempList, b)
}
Здесь во всех элементах слайса builds, возвращаемого из базы данных, PatchURLs заменяется на ReversePatchURLs, ExtractedSize — на RPatchExtractedSize и выполняется реверс — меняется порядок элементов так, чтобы последний элемент стал первым, а первый — последним.
На мой взгляд, исходный код немного сложен для восприятия и может быть оптимизирован. Этот код выполняет простой алгоритм, состоящий из двух логических частей: изменение элементов слайса и сортировка. Но чтобы программисту вычленить эти две составляющие, понадобится время.
Несмотря на то что обе части важны, в коде реверс не так акцентируется, как хотелось бы. Он разбросан по трем оторванным друг от друга строкам: инициализация нового слайса, итерация существующего слайса в обратном порядке, добавление элемента в конец нового слайса. Тем не менее нельзя игнорировать и несомненные преимущества данного кода: код рабочий и протестирован, и если говорить объективно, то он вполне адекватный. Субъективное восприятие кода отдельным разработчиком не может служить оправданием для его переписывания. К сожалению или к счастью, мы не переписываем код только потому, что он нам просто не нравится (или, как чаще бывает, просто потому, что он не наш, см. Фатальный недостаток).
Но что, если нам удастся не только улучшить восприятие кода, но и существенно ускорить его? Это же совсем другое дело. Можно предложить несколько альтернативных алгоритмов, выполняющих заложенную в коде функциональность.
Первый вариант: перебор всех элементов в цикле range; для реверса первоначального слайса в каждой итерации добавляем элемент в начало итогового массива. Так мы могли бы избавиться от громоздкого for, переменной i, использования функции len, трудно воспринимаемого перебора элементов с конца, а также сократить количество кода на две строки (с семи строк до пяти), а чем меньше кода, тем меньше вероятность допустить в нем ошибку.
var tempList []*store.Build
for _, build := range builds {
build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize
tempList = append([]*store.Build{build}, tempList...)
}
Убрав перебор слайса с конца, мы четко разграничили операции изменения элементов (3-я строка) и реверса исходного массива (4-я строка).
Основной замысел второго варианта состоит в еще большем разнесении изменения элементов и сортировки. Сперва перебираем элементы и меняем их, а потом сортируем слайс отдельной операцией. Данный метод потребует дополнительной реализации интерфейса сортировки для слайса, но повысит читабельность и позволит полностью отделить и изолировать реверс от изменения элементов, а метод Reverse однозначно укажет читателю на желаемый результат.
var tempList []*store.Build
for _, build := range builds {
build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize
}
sort.Sort(sort.Reverse(sort.IntSlice(keys)))
Третий вариант является практически повторением второго, но для сортировки используется sort.Slice, что увеличивает объем кода на одну строчку, но позволяет избежать дополнительной реализации интерфейса сортировки.
for _, build := range builds {
build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize
}
sort.Slice(builds, func(i int, j int) bool {
return builds[i].Id > builds[j].Id
})
На первый взгляд, по внутренней сложности, количеству итераций, применяемым функциям изначальный код и первый алгоритм близки; второй и третий варианты могут казаться сложнее, но однозначно сказать, какой из четырех вариантов будет оптимальным, все же нельзя.
Итак, мы запретили себе принимать решения, основываясь на предположениях, не подкрепленных доказательствами, но очевидно, что здесь наибольший интерес представляет то, как поведет себя функция append при добавлении элемента в конец и в начало слайса. Ведь на самом деле эта функция не так проста, как кажется.
Append работает следующим образом: она либо добавляет к существующему в памяти слайсу новый элемент, если его capacity больше итоговой длины, либо резервирует в памяти место под новый слайс, копируя в него данные из первого слайса, добавляя данные второго и возвращая в качестве результата уже новый слайс.
Самый интересный нюанс в работе этой функции состоит в алгоритме, используемом для резервирования памяти под новый массив. Так как самой дорогой операцией является выделение нового участка памяти, то, чтобы сделать операцию append дешевле, разработчики Go пошли на небольшую хитрость. Поначалу, чтобы не резервировать память заново при каждом добавлении элемента, объем памяти выделяется с некоторым запасом — в два раза больше первоначального, но после определенного количества элементов объем вновь резервируемого участка памяти становится больше не в два раза, а на 25 %.
С учетом нового понимания работы функции append ответ на вопрос: «Что будет быстрее: добавлять один элемент в конец существующего слайса или добавлять к слайсу из одного элемента существующий слайс?» — уже более прозрачен. Можно предположить, что во втором случае по сравнению с первым будет больше аллокаций памяти, что прямым образом отразится на скорости работы.
Так мы плавно подошли к бенчмаркам. С помощью бенчмарков можно оценить нагрузку алгоритма на самые критичные ресурсы, такие как время выполнения и оперативная память.
Давайте напишем бенчмарк для оценки всех четырех наших алгоритмов, заодно оценим, какой прирост может нам дать отказ от сортировки (чтобы понимать, какая часть всего времени тратится именно на сортировку). Код бенчмарка:
package services
import (
"testing"
"sort"
)
type Build struct {
Id int
ExtractedSize int64
PatchUrls string
ReversePatchUrls string
RPatchExtractedSize int64
}
type Builds []*Build
func (a Builds) Len() int { return len(a) }
func (a Builds) Swap(i, j int) { a[i], a[j] = a[j], a[i] }
func (a Builds) Less(i, j int) bool { return a[i].Id < a[j].Id }
func prepare() Builds {
var builds Builds
for i := 0; i < 100000; i++ {
builds = append(builds, &Build{Id: i})
}
return builds
}
func BenchmarkF1(b *testing.B) {
data := prepare()
builds := make(Builds, len(data))
b.ResetTimer()
for i := 0; i < b.N; i++ {
var tempList Builds
copy(builds, data)
for i := len(builds) - 1; i >= 0; i-- {
b := builds[i]
b.PatchUrls, b.ExtractedSize = b.ReversePatchUrls, b.RPatchExtractedSize
tempList = append(tempList, b)
}
}
}
func BenchmarkF2(b *testing.B) {
data := prepare()
builds := make(Builds, len(data))
b.ResetTimer()
for i := 0; i < b.N; i++ {
var tempList Builds
copy(builds, data)
for _, build := range builds {
build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize
tempList = append([]*Build{build}, tempList...)
}
}
}
func BenchmarkF3(b *testing.B) {
data := prepare()
builds := make(Builds, len(data))
b.ResetTimer()
for i := 0; i < b.N; i++ {
copy(builds, data)
for _, build := range builds {
build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize
}
sort.Sort(sort.Reverse(builds))
}
}
func BenchmarkF4(b *testing.B) {
data := prepare()
builds := make(Builds, len(data))
b.ResetTimer()
for i := 0; i < b.N; i++ {
copy(builds, data)
for _, build := range builds {
build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize
}
sort.Slice(builds, func(i int, j int) bool {
return builds[i].Id > builds[j].Id
})
}
}
func BenchmarkF5(b *testing.B) {
data := prepare()
builds := make(Builds, len(data))
b.ResetTimer()
for i := 0; i < b.N; i++ {
copy(builds, data)
for _, build := range builds {
build.PatchUrls, build.ExtractedSize = build.ReversePatchUrls, build.RPatchExtractedSize
}
}
}
Запустим бенчмарк командой go test -bench=. -benchmem.
Результаты вычислений для слайсов 10, 100, 1000, 10 000 и 100 000 элементов представлены на графике ниже, где F1 — изначальный алгоритм, F2 — добавление элемента в начало массива, F3 — использование sort.Reverse для сортировки, F4 — использование sort.Slice, F5 — отказ от сортировки.
Время выполнения операции

Количество аллокаций памяти
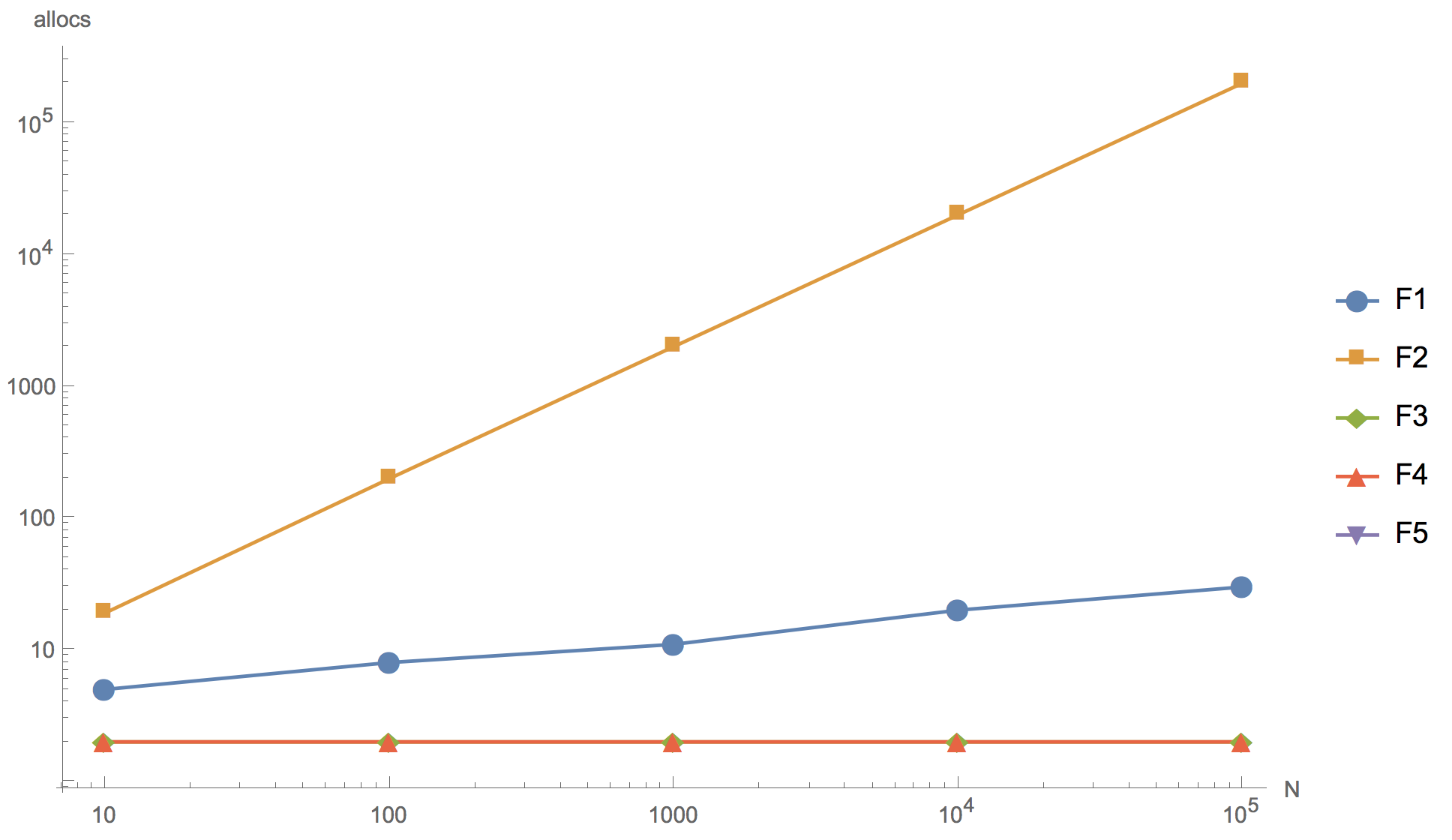
Как видно из графика, можно увеличивать массив, но конечный результат уже в принципе различим на слайсе из 10 элементов. Ни один из предложенных альтернативных алгоритмов (F2, F3, F4) не смог превзойти по скорости работы изначальный алгоритм (F1). Даже несмотря на то, что у всех, кроме F2, количество аллокаций памяти незначительно меньше, чем у изначального. Первый алгоритм (F2) с добавлением элемента в начало слайса оказался самым неэффективным: как и предполагалось, в нем слишком много аллокаций памяти, настолько, что использовать его в продуктовой разработке категорически нельзя. Алгоритм с применением встроенной функции сортировки реверсом (F3) существенно медленнее изначального. И только алгоритм с сортировкой sort.Slice сравним по скорости с изначальным алгоритмом, но при этом слегка уступает ему.
Также можно заметить, что отказ от сортировки (F5) дает существенное ускорение. Поэтому если очень хочется переписать код, то можно пойти в этом направлении, например, поднимая изначальный слайс builds из базы данных, использовать в запросе сортировку по id DESC вместо ASC. Но при этом мы вынуждены выйти за границы рассматриваемого участка кода, что влечет за собой риск привнести множественные изменения.
Выводы
Пишите бенчмарки.
Нет большого смысла тратить свое время на рассуждения о том, будет ли тот или иной код быстрее. Информация из интернета, суждения коллег и других людей, какими бы авторитетными они ни были, могут служить вспомогательными доводами, но роль главного судьи, решающего, быть или нет новому алгоритму, должна оставаться за бенчмарками.
Go только на первый взгляд довольно простой язык. Всеобъемлющее правило 80⁄20 применимо и здесь. Эти 20 % представляют собой те тонкости внутреннего устройства языка, знание которых отличает новичка от опытного разработчика. Практика написания бенчмарков для разрешения своих вопросов — один из самых дешевых и эффективных способов получить как ответ, так и более глубокое понимание внутреннего устройства и принципов работы языка Go.
Комментариев нет:
Отправить комментарий