Важно писать не только сервисы, которые хорошо работают, но и сервисы, которые хорошо ломаются.
— Я очень рад вас всех видеть. Сегодня я буду рассказывать о graceful degradation. Если вы поищете это в Яндексе, скорее всего, вы узнаете, как сделать так, чтобы ваш сайт работал без JS. Я расскажу немного про другое. Про graceful degradation применительно к бэкенду.

Начнем с определения. Как это выглядит в реальности?
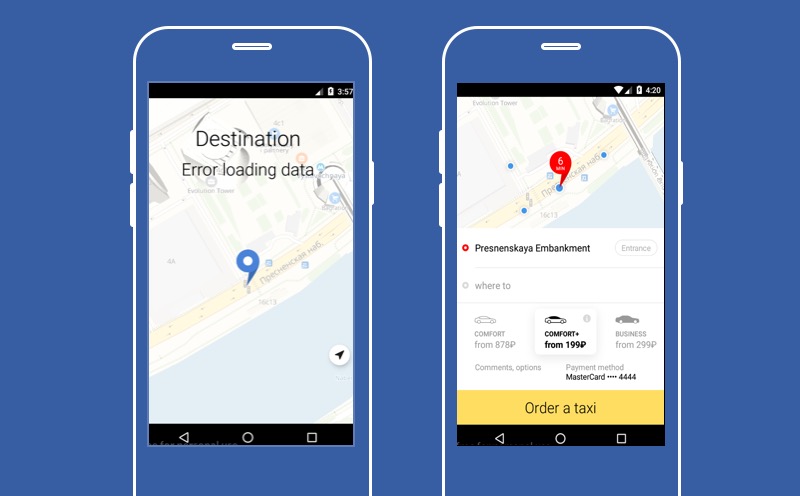
Тут представлено наше приложение Яндекс.Такси в том случае, если не работает один из сервисов — сервис выбора точки назначения, куда водитель должен вас отвезти. Как вы видите, на этом экране нет большой кнопки «Заказать такси», а значит, пользователь не сможет воспользоваться сервисом. Но можно попробовать деградировать и позволить пользователю не выбирать точку Б.
Тогда он не сможет узнать точную цену поездки, мы не сможем построить маршрут, но зато у пользователя будет кнопка «Заказать такси», и он сможет воспользоваться нашим сервисом. Основная функция нашего приложения будет доступна. Именно об этом я и хочу сегодня рассказать. О том, как правильно деградировать и что можно делать с сервисом, который сломался.
План выступления. Расскажу, как деградировать, что делать с сервисом. Можно его отключать, а еще — применять другое поведение. Потом расскажу, как понять, когда настало время выключать наш сервис. И в конце расскажу о нескольких нюансах, с которыми нам пришлось столкнуться, когда мы делали систему автоматической деградации для Яндекс.Такси.
Что можно сделать с сервисом, который сломался? Можно выключить функциональность. Если у вас не работает сервис предсказания индивидуальных точек назначения, то вы выключаете этот сервис. Если не работает чат между водителем и пассажиром, то вы выключаете чат. Если нельзя заказать машину, то вы выключаете кнопку «Заказать машину» — ой, нет, так не работает. Не всю функциональность можно выключить. И если что-то выключить нельзя, то нужно применить другой подход. Например, можно попробовать сделать макет или упрощенную функциональность. Такое упрощенное поведение мы в Яндексе называем тыквой — говорим, что сервис превратился в тыкву.
Рассмотрим эти решения подробнее.
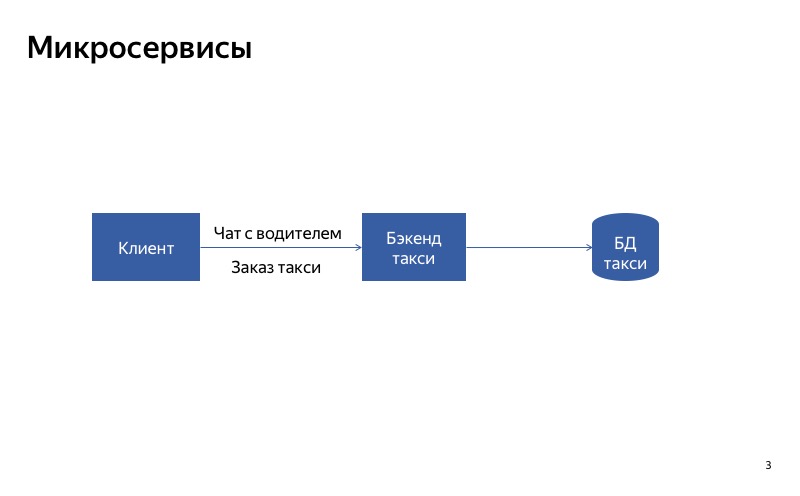
Как отключать сервисы? Наверное, можно сделать правильную архитектуру. Предположим, у нас есть один монолитный сервис. Если выходит из строя одна из его частей, то ломается весь сервис. А вот если мы разделим сервис на части так, что клиенты будут использовать разные сервисы для разных запросов, то станет значительно лучше.
Как это будет работать на примере? Есть сервис Яндекс.Такси, в котором две основные функции: заказать такси и пообщаться с водителем. Пока у нас есть один монолитный бэкенд, при отказе чата с водителем будет затронут и основная функциональность заказа такси.
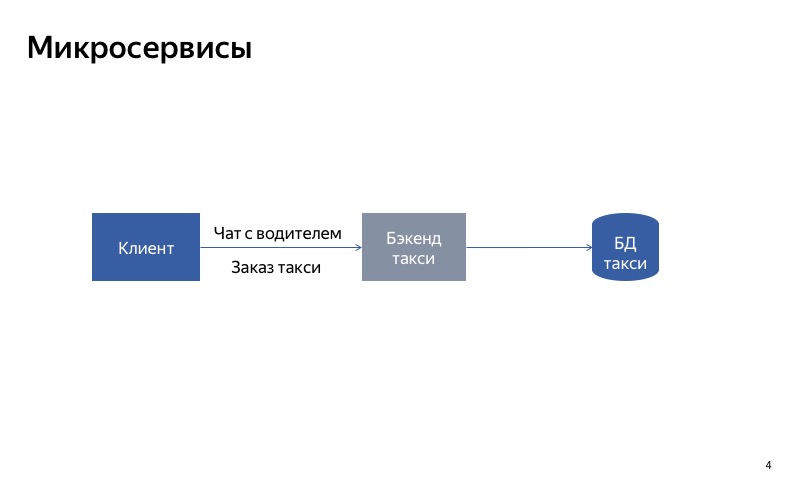
Что можно попробовать сделать? Разделить монолитный сервис на две части. Одна часть будет отвечать за заказ такси, а другая — за общение с водителем.
Теперь все выглядит гораздо лучше. Если ломается чат с водителем, то все остальное продолжает работать правильно.
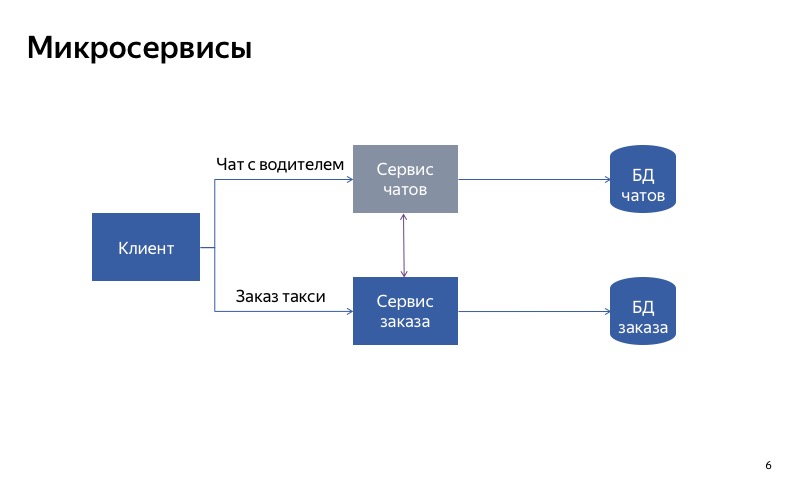
Как видите, клиент использует разные API, разные запросы, чтобы совершать заказ и осуществлять связь с водителем.
Но на самом деле кажется, что сейчас не все так хорошо, потому что есть паразитная связь между сервисом чатов и сервисом заказов. И может получиться, что сервис заказа использует неработающий сервис чатов. В таком случае основная функциональность не будет работать.
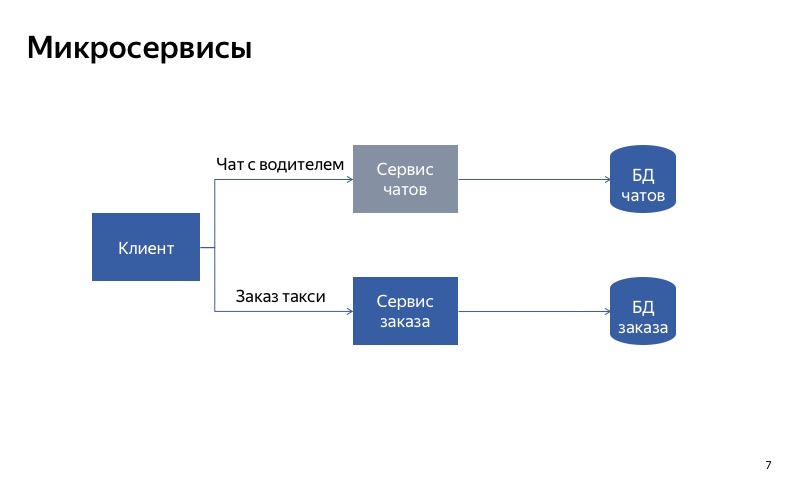
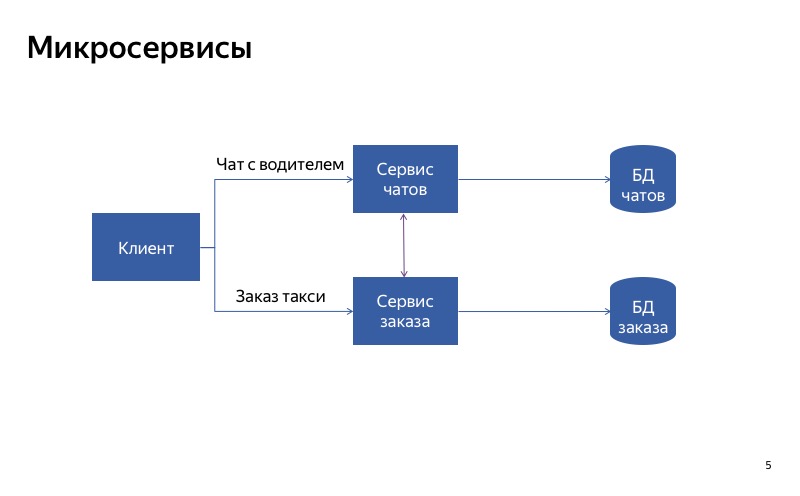
А в таком случае все гораздо лучше. Паразитная связь пропала, и теперь наши сервисы действительно независимы друг от друга. А значит, при поломке сервиса чатов вы все еще сможете воспользоваться такси.
Вывод из этого следующий: если вы хотите деградировать с использованием разделения на сервисы, то очень важно сделать так, чтобы сервисы были независимы друг от друга. Это означает, что у них должны быть разные точки входа, разные энд-поинты. У них должны быть разные рантаймы. И конечно, они должны использовать разные БД. Иначе один сломавшийся сервис может сломать за собой все остальные сервисы по цепочке.
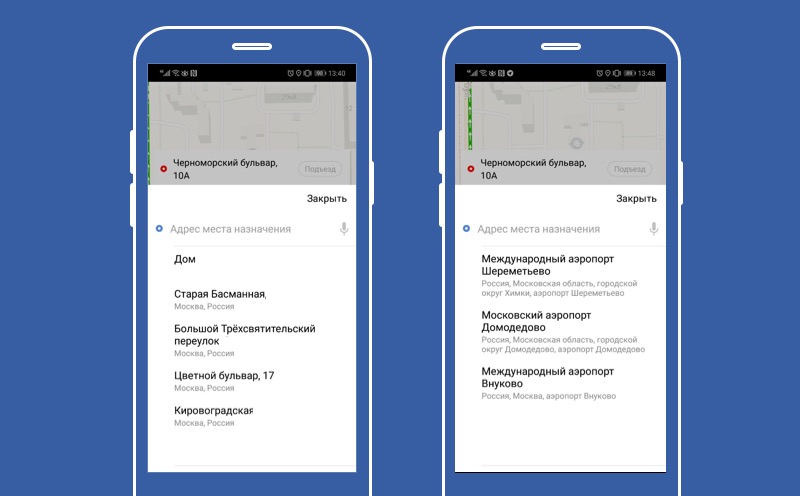
Хорошо, мы разобрали, как можно отключать функциональность. Давайте теперь посмотрим, как делать функциональность по умолчанию, как делать тыкву. На этом экране наш сервис предсказания точек назначения. Сервис использует умный ИИ, чтобы предсказать пользователю наилучшие для него в текущий момент точки назначения. А если ИИ устал, то используем поведение по умолчанию и предлагаем пользователю уехать из Москвы.
Давайте разберем, как это работает на практике.

У нас есть клиент, он обращается в сервис точек назначения и получает ошибку.
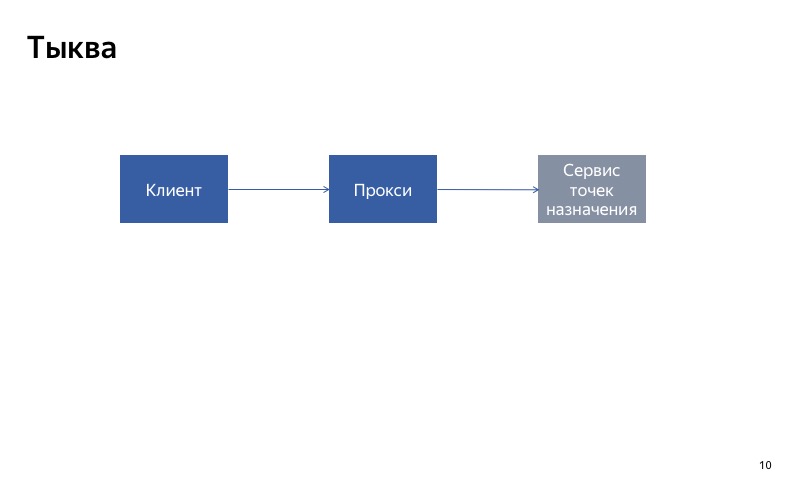
Теперь возможны две ситуации. Первая ситуация, если сбой был единичный, — это просто один непрошедший запрос. В таком случае мы просто прокинем ошибку клиенту, он сделает перезапрос и получит свои любимые точки назначения.
А вот если сбой массовый, мы включаем тыкву и пользователь получает поведение по умолчанию.

Но такое захардкоженное поведение реализовать гораздо проще, и эта тыква очень надежная, поэтому позволяет нам работать даже в том случае, когда ИИ выходит из строя. Если мы знаем, что пользователи часто ездят в аэропорты, то мы не заметим сильного ухудшения жизни пользователей.
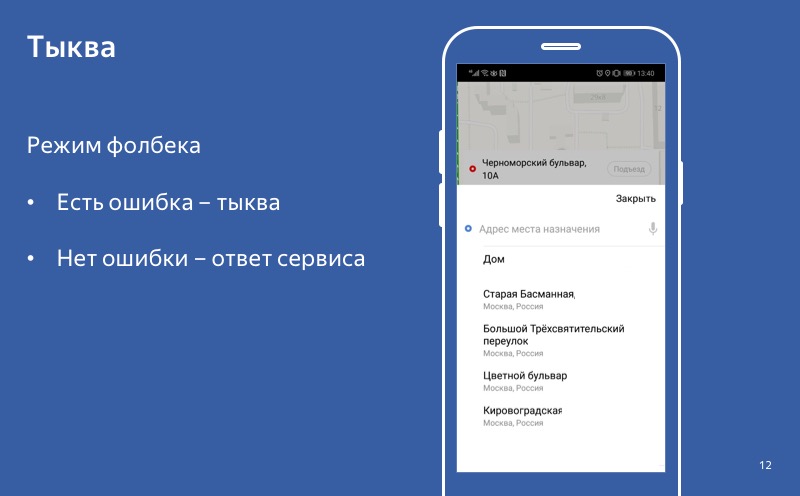
Даже если у включен режим деградации, включена тыква, но пользователь обращается в сервис и получает успешный ответ, то мы используем этот ответ, а не тыкву. И такое поведение — когда в случае получения ответа мы его и используем, а в случае ошибки используем тыкву — мы называем режимом fallback.
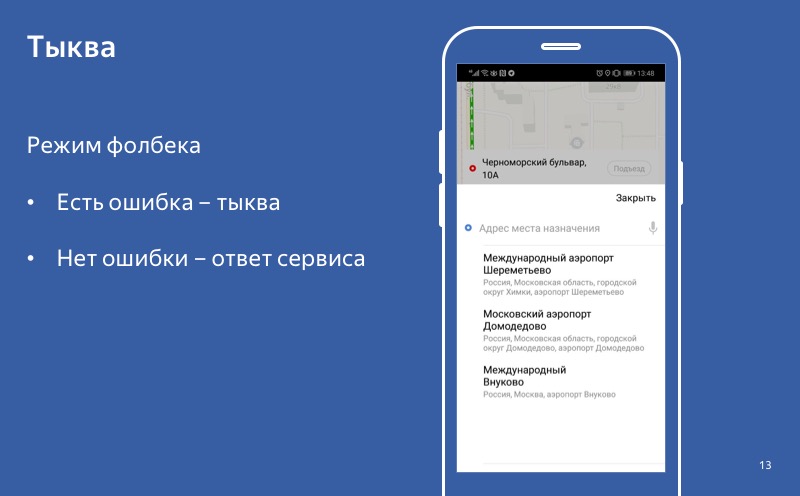
Нет ошибки — успешный ответ. Есть ошибка — тыква. Мы говорим, что включился fallback.
Я разобрал то, что можно сделать с сервисом, который сломался. Можно отключить, а можно включить тыкву. Давайте теперь перейдем ко второй части и разберемся, как диагностировать.
У нас есть два больших вопроса, на которые нужно ответить. Первый — когда нужно выключить сервис и включить тыкву. Второй — когда нужно выключить тыкву и включить назад сервис. Перед тем, как мы сможем ответить на эти вопросы, нужно прояснить один момент.
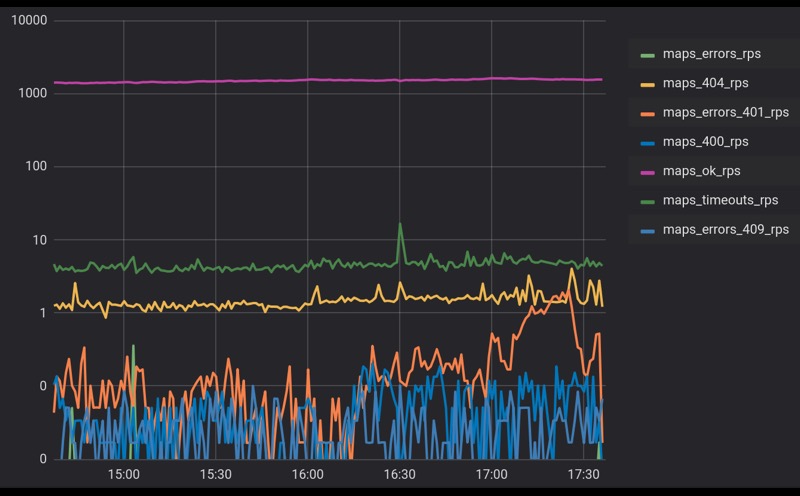
В любой сложной системе, которая взаимодействует с большим числом агентов, обязательно есть некоторый фон ошибок. На этом слайде мы видим реальный график обращений к одному из наших сервисов. На него приходит несколько тысяч RPS, ошибок мы получаем чуть меньше 1%. Здесь логарифмический масштаб.
Ошибки могут быть вызваны разными вещами. Может, это какой-то внутренний процесс, обновление каких-то БД или просто фоновые процессы. Может, клиенты ходят с неправильными запросами, но факт остается фактом: у нас всегда будет фон ошибок. Давайте его примем и будем двигаться дальше.
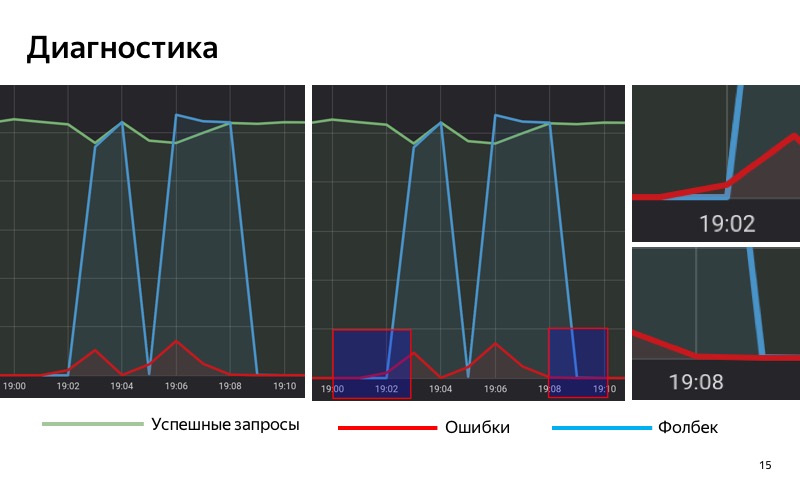
Итак, мы используем решение на основе статистики. У нас есть специальная БД, в которую мы сохраняем статистику, сохраняем количество успешных запросов, количество запросов с ошибками и запросов, для которых был включен fallback. Мы берем и накапливаем скользящим окном в некотором промежутке времени статистику по нашему сервису. Когда в этом скользящем окне доля запросов с ошибками превышает некоторый порог, мы включаем fallback. А когда число ошибок становится меньше порога, то мы его выключаем.
Обратите внимание на выделенные области. В 19:01 начали появляться первые ошибки, но пока что их доля достаточно мала, и до 19:02 мы не включаем fallback. В 19:02 порог превышен, мы включили fallback. В 19:08 обратный процесс: ошибки закончились, но еще некоторое время у нас fallback включен, потому что в нашем скользящем окне порог все еще превышен. В 19:09 мы выключили fallback.
Мы разобрали, когда выключать сервис. Надо ответить на второй вопрос: когда его включить. Все просто: мы используем то же самое решение на основе статистики.
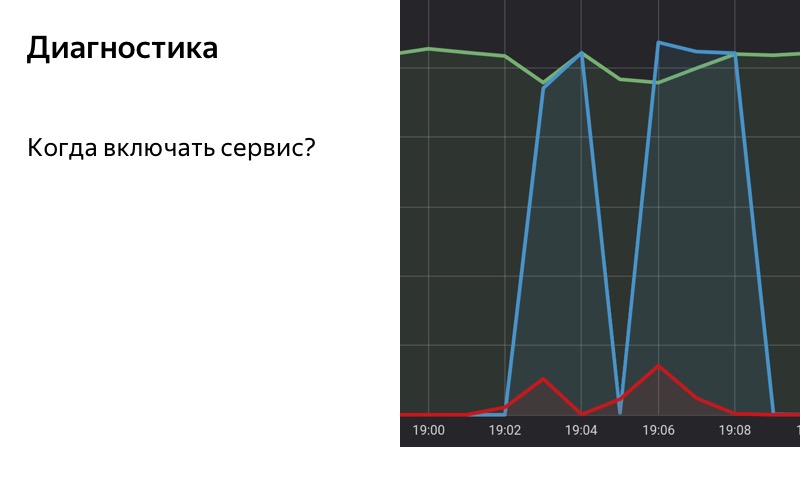
Тут важно то, что мы не снимаем нагрузку с сервиса, даже если мы включили режим деградации. Именно это позволяет нам продолжать получать статистику даже в том случае, если мы показываем пользователю тыкву. Таким образом мы можем определить, что ошибки закончились, сервис починился. Значит, можно снова включить его на полную.
Когда мы говорим про деградацию, нельзя не сказать про мониторинги. Хороший мониторинг — половина успеха, половина пути к автоматическому отключению или автоматической деградации. Нам важно понимать, какие вообще с нашим сервисом случаются проблемы, какой может быть характер ошибок и насколько часто они происходят. И возможно, на первом этапе нам даже не нужен автоматический выключатель. Просто если лампочка мониторинга загорелась, мы можем взять и отключить сервис вручную. Когда лампочка мониторинга потухла, мы включаем сервис.
Если мы делаем автоматическую деградацию, автоматический выключатель, то важно сделать мониторинг на сам fallback. Если система деградации работает достаточно хорошо, то пользователи, на самом деле, могут вообще не замечать, что у нас что-то сломалось. Мы сами можем, если не будет мониторингов, это не замечать. Важно следить за fallback, важно понять, когда он включен, когда выключен, чтобы была статистика и мы могли понимать, сколько времени функциональность не работает, становится ли наш бэкенд хуже или лучше со временем, в зависимости от того, сколько времени мы считаем проводить fallback.
С основной частью всё.
Под конец хотел бы рассказать несколько нюансов, с которыми нам пришлось столкнуться, когда мы разрабатывали систему автоматической деградации в Яндекс.Такси.
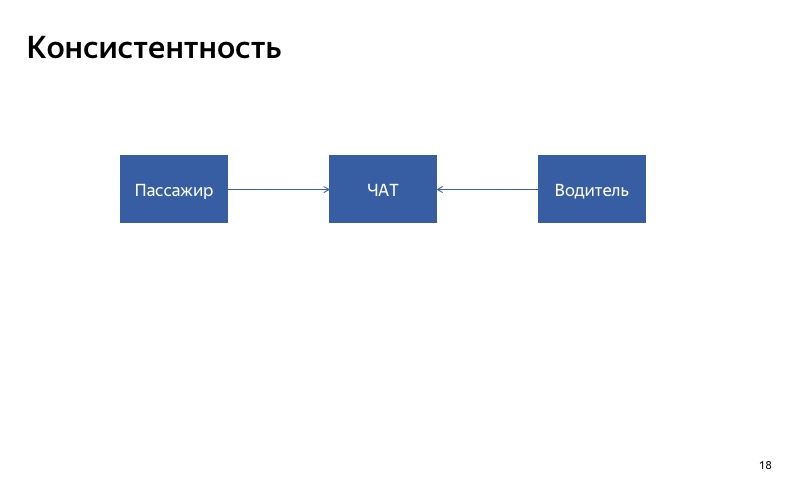
Первое, на что стоит обратить внимание, это консистентность. Если вы делаете автоматическую деградацию для некоторого сервиса, важно, чтобы сервис отвечал консистентно для всех его клиентов. Если у вас есть два клиента, которые используют сервис, важно, чтобы ответы для этих двух клиентов в случае деградации были консистентны. И если у вас есть сервис, который участвует в некотором длительном процессе, нужно понимать: возможно, в начале и конце процесса сервис будет работать правильно, а где-то посередине будет включен fallback.
Это звучит сложно, но давайте попробую объяснить на примере. Возможно, станет понятнее.
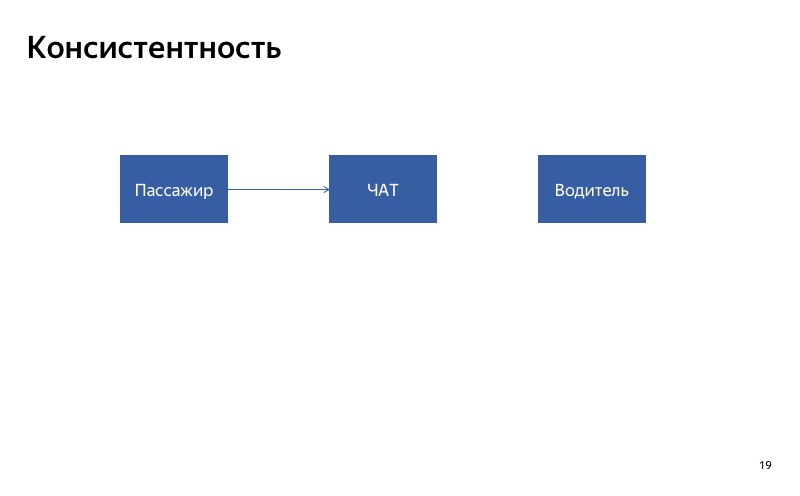
Вот наш чат между водителем и пассажиром. Самый простой способ его деградировать — отключить. Давайте представим, что сломался чат для водителя. Что получится? Клиент будет писать в чат, а водитель не увидит сообщений. Наверное, они будут очень недовольны, будут ругаться на наше приложение, когда встретятся друг с другом. В данном случае важно, чтобы чат был или одновременно включен, или одновременно выключен для всех участников этого чата. Вот что я называю консистентностью.

Второй нюанс касается того, что наше приложение Яндекс.Такси — геораспределенное: такси можно заказать в Москве, Красноярске или Хельсинки. Это приходится учитывать даже при разработке систем деградации. Представьте, что у нас есть очень много успешных запросов и совсем чуть-чуть запросов с ошибками. Казалось бы, это нормальная ситуация, фон ошибок всегда присутствует. Но на ту же самую картину можно взглянуть по-другому.
Можно увидеть, что сервис не работает в Мытищах и нужно включать fallback для этих пользователей. Вывод следующий: нужно строить правильную статистику. Для нас как для геораспределенного сервиса это в том числе означает, что нужно строить статистику в разрезе по городам. Если мы правильно сделаем статистику, мы сразу увидим, что большинство запросов из Мытищ ломается, и включим fallback именно для пользователей из Мытищ. А для всех других пользователей продолжим работать в нормальном режиме, потому что для них сервис работает правильно.

Возможно, для других сервисов будут другие условия и другие нюансы.
Наши сервисы становятся все более сложными. Часто они зависят от внешнего мира, который мы не можем предсказывать. Поэтому важно писать не только сервисы, которые хорошо работают, но и сервисы, которые хорошо ломаются. Если вы узнали что-то новое, то рассказывайте коллегам, делитесь. Лайк, шер, репост. Деградируйте правильно.
Комментариев нет:
Отправить комментарий