Свёрточные нейросети отлично справляются с классификацией искажённых изображений, в отличие от людей

В данной статье я покажу, почему передовые глубинные нейросети прекрасно могут распознавать искажённые изображения и как это помогает раскрыть удивительно простую стратегию, используемую нейросетями для классификации естественных фотографий. У этих открытий, опубликованных в ICLR 2019, есть много последствий: во-первых, они демонстрируют, что найти «решение» ImageNet гораздо проще, чем считалось. Во-вторых, они помогают нам создавать более интерпретируемые и понятные системы классификации изображений. В-третьих, они объясняют несколько явлений, наблюдаемых в современных свёрточных нейросетях (СНС), к примеру, их склонность к поиску текстур (см. другую нашу работу в ICLR 2019 и соотв. запись в блоге), и игнорирование пространственного расположения частей объекта.
Добрые старые модели «мешок слов»
В старые добрые времена, до появления глубинного обучения, распознавание естественных образов было довольно простым: определяем набор ключевых визуальных особенностей («слов»), определяем, как часто каждая визуальная особенность встречается в изображении («мешок»), и классифицируем изображение на основе этих чисел. Поэтому такие модели в компьютерном зрении называются «мешком слов» (bag-of-words или BoW). Для примера допустим, что у нас есть две визуальные особенности, глаз человека и перо, и мы хотим классифицировать изображения по двум классам, «люди» и «птицы». Простейшая модель BoW была бы такой: для каждого найденного на изображении глаза увеличиваем свидетельство в пользу «человека» на 1. И наоборот, для каждого пера увеличиваем свидетельство в пользу «птицы» на 1. Какой класс набирает больше свидетельств, таким он и будет.
Удобным свойством такой простой модели BoW является интерпретируемость и ясность процесса принятия решений: мы точно можем проверить, какие именно особенности изображения говорят в пользу того или иного класса, пространственная интеграция особенностей очень проста (по сравнению с нелинейной интеграцией особенностей в глубинных нейросетях), поэтому очень просто понять, как модель принимает свои решения.
Традиционные модели BoW были чрезвычайно популярны и прекрасно работали перед нашествием глубинного обучения, однако быстро вышли из моды из-за сравнительно низкой эффективности. Но уверены ли мы, что нейросети используют фундаментально отличающуюся от BoW стратегию принятия решений?
Глубинная интерпретируемая сеть с мешком особенностей (BagNet)
Чтобы проверить это предположение, скомбинируем интерпретируемость и ясность моделей BoW с эффективностью нейросетей. Стратегия выглядит так:
- Делим изображение на небольшие кусочки q x q.
- Пропускаем кусочки через нейросеть, чтобы получить свидетельства принадлежности к классу (логиты) для каждого кусочка.
- Суммируем свидетельства по всем кусочкам для получения решения на уровне всего изображения.
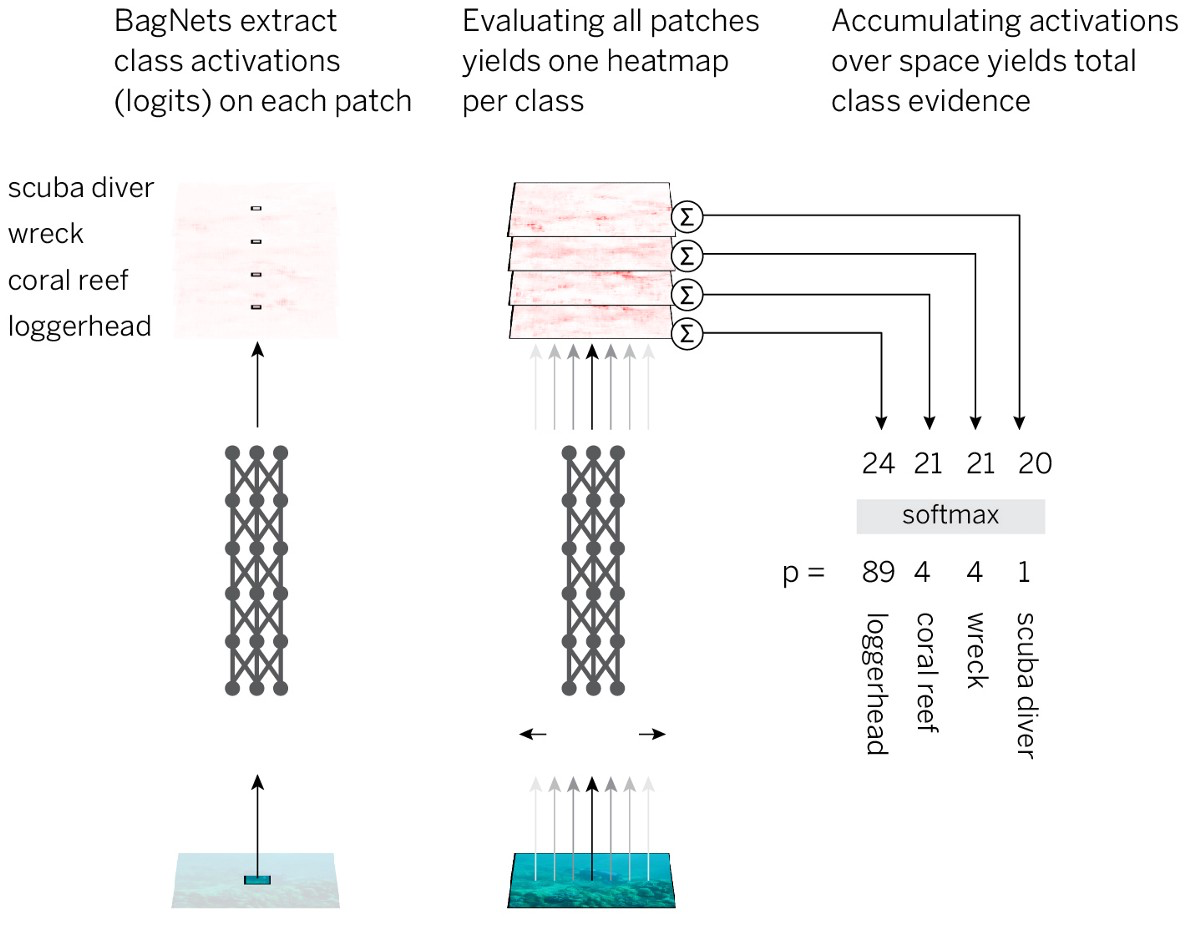
Для реализации такой стратегии простейшим способом мы берём стандартную архитектуру ResNet-50 и заменяем почти все свёртки 3х3 на свёртки 1х1. В результате каждый скрытый элемент в последнем свёрточном слое «видит» только небольшую часть картинки (то есть их поле восприятия гораздо меньше размера изображения). Так мы избегаем навязанной разметки изображения и максимально близко подходим к стандартной СНС, при этом применяя заранее спланированную стратегию. Мы называем полученную архитектуру BagNet-q, где q обозначает размер поля восприятия самого верхнего слоя (мы тестировали модель с q = 9, 17 и 33). Работает BagNet-q примерно в 2,5 дольше, чем ResNet-50.
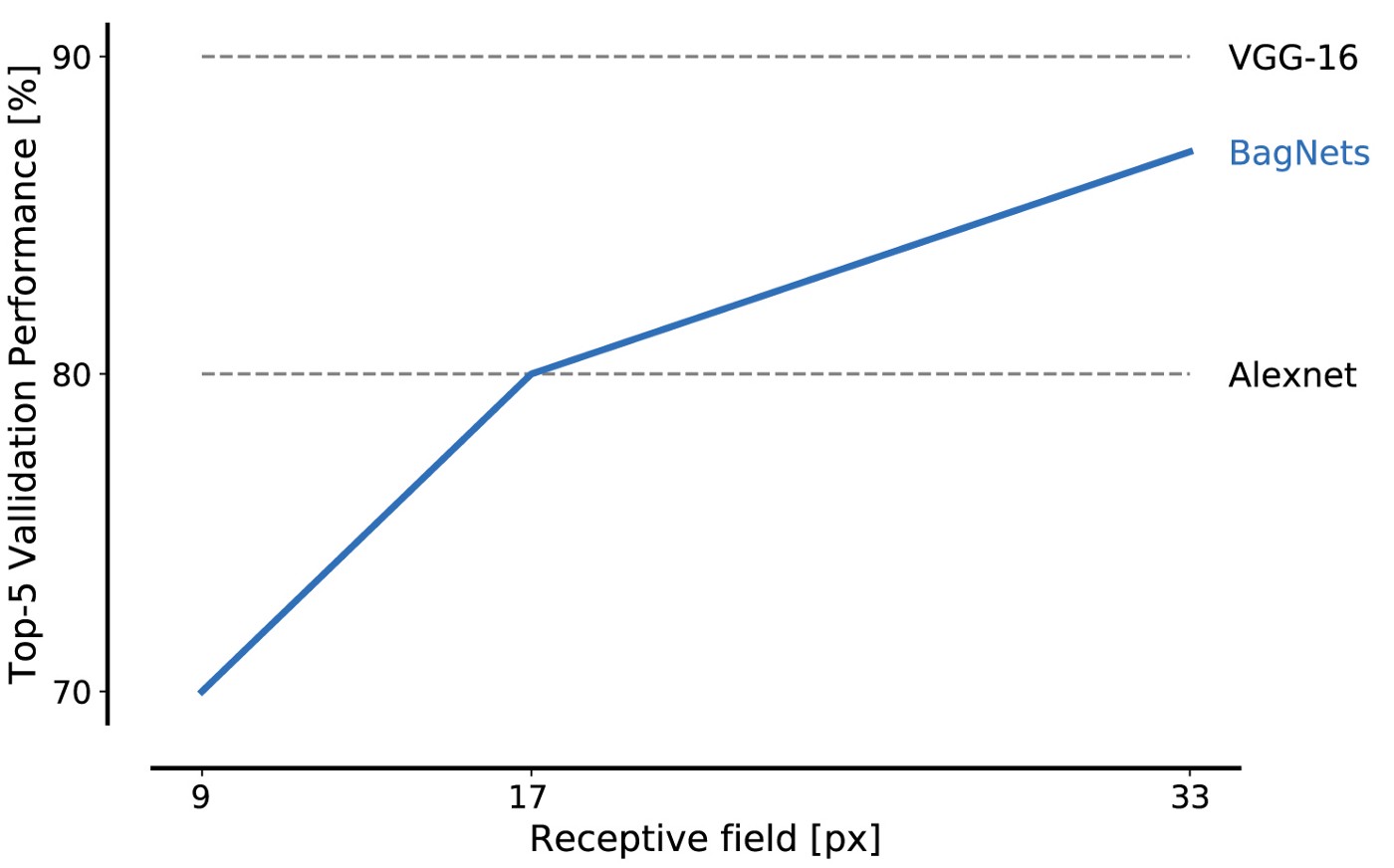
Эффективность работы BagNet на данных из базы ImageNet впечатляет даже при использовании кусочков небольшого размера: фрагментов 17х17 пикселей достаточно, чтобы достичь эффективности уровня AlexNet, а фрагментов 33х33 пикселя достаточно, чтобы достичь точности в 87%, войдя в top-5. Увеличить эффективность можно, более тщательно размещая свёртки 3х3 и подстраивая гиперпараметры.
Это наш первый основной результат: решить ImageNet можно, используя только набор небольших особенности изображений. Дальние пространственные отношения частей композиции вроде формы объектов или взаимодействия между частями объекта можно полностью проигнорировать; они совершенно не нужны для решения задачи.
Замечательная особенность BagNet’ов состоит в прозрачности их системы принятия решений. К примеру, можно узнать, какие особенности изображений окажутся наиболее характерными для заданного класса. К примеру, линь, крупная рыба, обычно распознаётся по изображению пальцев на зелёном фоне. Почему? Потому, что на большей части фотографий в этой категории стоит рыбак, держащий линя как свой трофей. И когда BagNet неправильно распознаёт изображение как линя, это обычно происходит потому, что где-то на фото есть пальцы на зелёном фоне.

Наиболее характерные части изображений. Верхний ряд в каждой ячейке соответствует правильному распознаванию, а нижний – отвлекающим фрагментам, приведшим к неправильному распознаванию
Также мы получаем точную «тепловую карту», на которой показано, какие части изображения внесли вклад в принятие решения.

Тепловые карты не являются аппроксимацией, они точно показывают вклад каждой части изображения
BagNet’ы демонстрируют, что можно получить высокую точность работы с ImageNet только лишь на основе слабых статистических корреляций между локальными особенностями изображений и категорией объектов. Если этого достаточно, то зачем бы стандартным нейросетям типа ResNet-50 изучать что-то фундаментально отличное? Заем ResNet-50 изучать сложные крупномасштабные взаимосвязи типа формы объекта, если обилия локальных особенностей изображения хватит для решения задачи?
Для проверки гипотезы о том, что современные СНС придерживаются стратегии, сходной с работой простейших BoW-сетей, мы проверили разные сети — ResNet, DenseNet и VGG на следующих «признаках» BagNet’ов:
- Решения не зависят от пространственной перетасовки особенностей изображения (это можно проверить только на моделях VGG).
- Модификации разных частей изображения не должны зависеть друг от друга (в смысле их влияния на принадлежность к классу).
- Ошибки, сделанные стандартными СНС и BagNet’ами, должны быть схожи.
- Стандартные СНС и BagNet должны быть чувствительны к сходным особенностям.
Во всех четырёх экспериментах мы обнаружили удивительно сходное поведение СНС и BagNet. К примеру, в последнем эксперименте мы показываем, что BagNet наиболее чувствительны (если их, к примеру, перекрывать) к тем же местам изображений, что и СНС. На самом деле, тепловые карты (пространственные карты чувствительности) BagNet лучше предсказывают чувствительность DenseNet-169, чем тепловые карты, полученные такими атрибуционными методами, как DeepLift (подсчитывающими тепловые карты для DenseNet-169 напрямую). Конечно, СНС не точно повторяют поведение BagNet, но определённые отклонения демонстрируют. В частности, чем глубже становятся сети, тем больше становятся размеры особенностей и дальше простираются зависимости. Поэтому глубинные нейросети действительно являются улучшением по сравнению с моделями BagNet, но не думаю, что основа их классификации как-то меняется.
Выходим за пределы классификации BoW
Наблюдение за принятием решений СНС в стиле стратегий BoW может объяснить некоторые странные особенности СНС. Во-первых, это объясняет, почему СНС так сильно завязаны на текстуры. Во-вторых, почему СНС не чувствительны к перемешиванию частей изображения. Это может даже объяснить существование состязательных стикеров и состязательных возмущений: сбивающие с толку сигналы можно поместить в любое место изображения, и СНС всё равно наверняка уловит этот сигнал, вне зависимости от того, подходит ли он к остальной части изображения.
По сути, наша работа показывает, что СНС при распознавании изображений используют множество слабых статистических закономерностей и не переходят к интеграции частей изображения на уровне объектов, как это делают люди. То же, скорее всего, верно и для других задач и сенсорных модальностей.
Нам необходимо тщательно спланировать наши архитектуры, задачи и обучающие методы, чтобы преодолеть тенденцию к использованию слабых статистических корреляций. Один из подходов – перевести искажение обучения СНС от мелких локальных особенностей к более глобальным. Другой – удалить или заменить те особенности, на которые нейросеть не должна полагаться, что мы и сделали в другой публикации для ICLR 2019, используя предобработку переноса стиля [style transfer preprocessing] для устранения текстуры естественного объекта.
Одной из крупнейших проблем, однако, остаётся сама классификация изображений: если локальных особенностей оказывается достаточно, не появляется стимула к изучению реальной «физики» естественного мира. Нам необходимо реструктуризировать задачу так, чтобы подвигнуть модели на изучение физической природы объектов. Для этого, скорее всего, придётся выйти за пределы чисто наблюдательного обучения корреляциям входных и выходных данных, чтобы модели могли извлекать причинно-следственные зависимости.
Все вместе наши результаты говорят о том, что СНС могут следовать чрезвычайно простой стратегии классификации. Тот факт, что подобное открытие можно сделать в 2019 году, подчёркивает, насколько мало мы ещё понимаем внутренние особенности работы глубинных нейросетей. Отсутствие понимания не даёт нам возможности разрабатывать фундаментально улучшенные модели и архитектуры, сокращающие разрыв между восприятием человека и машины. Углубление понимания позволит нам открыть способы сокращения этого разрыва. Это может стать чрезвычайно полезным: пытаясь сдвинуть СНС по направлению к физическим свойствам объектов, мы внезапно достигли устойчивости к шуму человеческого уровня. Я ожидаю появления большого количества других интересных результатов на нашем пути к разработке СНС, истинно постигающих физическую и причинно-следственную природу нашего мира.
Комментариев нет:
Отправить комментарий