
Предисловие
Есть на свете такая простая и очень полезная утилита — BDelta, и так вышло, что она очень давно укоренилась в нашем производственном процессе (правда её версию установить не удалось, но она точно была не последней доступной). Используем её по прямому назначению — построение бинарных патчей. Если взглянуть, что там в репозитории, — становится слегка грустно: по сути он давным-давно заброшен и многое там сильно устарело (когда-то туда внёс несколько правок мой бывший коллега, но давно это было). В общем, решил я это дело воскресить: форкнулся, выкинул то, что не планирую использовать, перегнал проект на cmake, заинлайнил «горячие» микрофункции, убрал со стека большие массивы (и массивы переменной длины, от которых у меня откровенно «бомбит»), прогнал в очередной раз профилировщик — и узнал, что около 40% времени тратится на fwrite…
Так что там с fwrite?
В данном коде fwrite (в моём конкретном тестовом случае: построение патча между близкими 300 Мб файлами, входные данные полностью в памяти) вызывается миллионы раз с буфером малого размера. Очевидно, что штука данная будет тормозить, и потому хотелось бы как-то повлиять на это безобразие. Внедрять разного рода источники данных, асинхронный ввод-вывод пока нет желания, хотелось найти решение проще. Первое, что пришло в голову — увеличить размер буфера
setvbuf(file, nullptr, _IOFBF, 64* 1024)
но существенного улучшения результата я не получил (теперь на fwrite приходилось около 37% времени) — значит дело всё же не в частой записи данных на диск. Заглянув «под капот» fwrite можно увидеть, что внутри происходит lock/unlock FILE структуры примерно так (псевдокод, весь анализ проводился под Visual Studio 2017):
size_t fwrite (const void *buffer, size_t size, size_t count, FILE *stream)
{
size_t retval = 0;
_lock_str(stream); /* lock stream */
__try
{
retval = _fwrite_nolock(buffer, size, count, stream);
}
__finally
{
_unlock_str(stream); /* unlock stream */
}
return retval;
}
Если верить профилировщику, на _fwrite_nolock приходится всего 6% времени, остальное — на оверхед. В моём конкретном случае потокобезопасность явное излишество, ей я и пожертвую, заменив вызов fwrite на _fwrite_nolock — даже с аргументами мудрить не надо. Итого: данная нехитрая манипуляция в разы сократила затраты на запись результата, которые в первоначальном варианте составляли почти половину временных затрат. Кстати, в мире POSIX есть аналогичная функция — fwrite_unlocked. Вообще говоря, то же касается и fread. Таким образом с помощью пары #define можно получить вполне себе кроссплатформенное решение без лишних блокировок в случае, если в них нет необходимости (а такое бывает весьма часто).
fwrite, _fwrite_nolock, setvbuf
Давайте абстрагируемся от оригинального проекта и займёмся тестированием конкретного случая: записи большого файла (512 Мб) предельно малыми порциями — в 1 байт. Тестовая система: AMD Ryzen 7 1700, 16 Гб ОЗУ, HDD 7200 rpm 64 Мб кэша, Windows 10 1809, бинарь строился 32-х битный, оптимизации включены, библиотека статически прилинкована.
Сэмпл для проведения эксперимента:
#include <chrono>
#include <cstdio>
#include <inttypes.h>
#include <memory>
#ifdef _MSC_VER
#define fwrite_unlocked _fwrite_nolock
#endif
using namespace std::chrono;
int main()
{
std::unique_ptr<FILE, int(*)(FILE*)> file(fopen("test.bin", "wb"), fclose);
if (!file)
{
file.release();
return 1;
}
constexpr size_t TEST_BUFFER_SIZE = 256 * 1024;
if (setvbuf(file.get(), nullptr, _IOFBF, TEST_BUFFER_SIZE) != 0)
return 2;
auto start = steady_clock::now();
const uint8_t b = 77;
constexpr size_t TEST_FILE_SIZE = 256 * 1024;
for (size_t i = 0; i < TEST_FILE_SIZE; ++i)
fwrite_unlocked(&b, 1, sizeof(b), file.get());
auto end = steady_clock::now();
auto interval = duration_cast<microseconds>(end - start);
printf("Time: %lld\n", interval.count());
return 0;
}
В качестве переменных будут выступать TEST_BUFFER_SIZE, а также для пары случаев заменим fwrite_unlocked на fwrite. Начнём со случая fwrite без явной установки размера буфера (закомментируем setvbuf и связанный код): время 27048906 мкс, скорость записи — 18.93 Мб/с. Теперь установим размер буфера в 64 Кб: время — 25037111 мкс, скорость — 20.44 Мб/с. Теперь протестируем работу _fwrite_nolock без вызова setvbuf: 7262221 мкс, скорость — 70.5 Мб/с! Дальше поэкспериментируем с размером буфера (setvbuf):
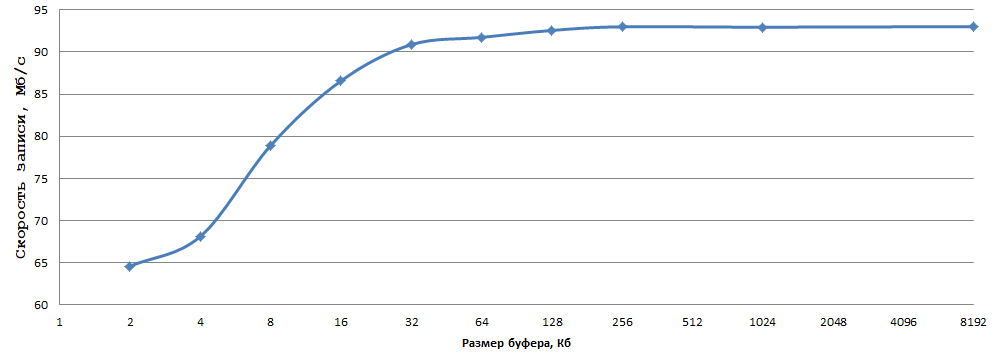
Данные получены усреднением 5 экспериментов, погрешности считать я поленился. Как по мне, 93 Мб/с при записи по 1 байту на обычный HDD — это очень неплохой результат, всего-то надо выбрать оптимальный размер буфера (в моём случае 256 Кб — в самый раз) и заменить fwrite на _fwrite_nolock/fwrite_unlocked (в случае, если не нужна потокобезопасность, разумеется). Аналогично с fread в подобных условиях. Так как «железной» машины с linux под рукой нет (одноплатники не в счёт), решил провести ограниченный эксперимент на виртуалке (Hyper-V, OpenSUSE 15, GCC 8.3.1) — закономерность, в принципе, та же: «голый» fwrite 20 Мб/с, fwrite + буфер на 256 Кб выдал 23 Мб/с, fwrite_unlocked с таким же буфером — 35 Мб/с (бинарь 64-х битный, собирался g++ -o2 -s -static-libgcc -static-libstdc++ fwrite_test.cpp -o fwrite_test).
Послесловие
Целью написания данной статьи было описание простого и действенного во многих случаях приёма (с функциями _fwrite_nolock/fwrite_unlocked я раньше как-то не сталкивался, не очень они популярны — а зря). На новизну материала не претендую, но надеюсь, что статья окажется полезной сообществу.
Комментариев нет:
Отправить комментарий