
Сначала давайте дадим определение понятию «очередь — queue».
Возьмем для рассмотрения тип очереди «FIFO»(first in, first out). Если взять значение из википедии — «это абстрактный тип данных с дисциплиной доступа к элементам». Если вкратце, это означает что мы не можем из нее доставать данные в случайном порядке, а только забирать то — что пришло первым.
Далее, нужно определиться зачем вообще они нужны?
1. Для отложенных операций. Классическим примером является обработка картинок. К примеру пользователь загрузил на сайт картинку, которую нам нужно обработать, эта операция занимает много времени, пользователь столько ждать не хочет. Поэтому мы грузим картинку, далее передаем ее в очередь. И она будет обработана, когда какой либо «worker» ее достанет.
2. Для обработки пиковых нагрузок. К примеру, есть какая-то часть системы, на которую иногда обрушивается большой трафик и она не требует мгновенного ответа. Как вариант, генерация каких-либо отчетов. Выкидывая в очередь эту задачу — мы даем возможность обрабатывать это с равномерной нагрузкой на систему.
3. Масштабируемость. И наверное самая важная причина, очередь дает возможность
масштабироваться. Это означает, что вы можете поднять несколько сервисов для обработки параллельно, что сильно повысит производительность.
Теперь давайте рассмотрим проблемы, с которыми столкнемся, если будем создавать очередь сами:
1. Параллельный доступ. Забрать из очереди определенное сообщение может только один обработчик. То есть если одновременно два сервиса попросят сообщения, каждому из них должен вернуться уникальный набор сообщений. Иначе, получится, что одно сообщение обработается два раза. Что может быть чревато.
2. Механизм дедупликации. В сервисе должна быть система, защищающая очередь от дубликатов. Может быть ситуация, в которой случайно в очередь будет отправлено один и тот-же набор данных два раза. В итоге мы одно и тоже обработаем два раза. Что опять же чревато.
3. Механизм обработки ошибок. Допустим наш сервис забрал из очереди три сообщения. Два из которых он успешно обработал, отправив запросы на удаление из очереди. А третье он не смог обработать и умер. Сообщение которое находится в статусе обработки — недоступно для других сервисов. И оно не должно навечно остаться в статусе обработки. Такое сообщение должно передаться другому обработчику по какой-то логике. Вариант реализации такой логики мы рассмотрим скоро на примере AWS SQS(Simple Queue Service)
Amazon Web Services — Simple Queue Service
Теперь давайте рассмотрим как решает эти проблемы SQS и что он может
1. Параллельный доступ. У очереди вы можете задать параметр «Visibility timeout». Он определяет, сколько по времени максимально может длиться обработка сообщения. По умолчанию он равен 30 секундам. Когда какой-либо сервис забирает сообщение, оно переводится в статус «In Flight» на 30 секунд. Если за это время не было команды удалить это сообщение из очереди, оно возвращается в начало и следующий сервис сможет его получить для обработки еще раз.
Небольшая схемка работы.
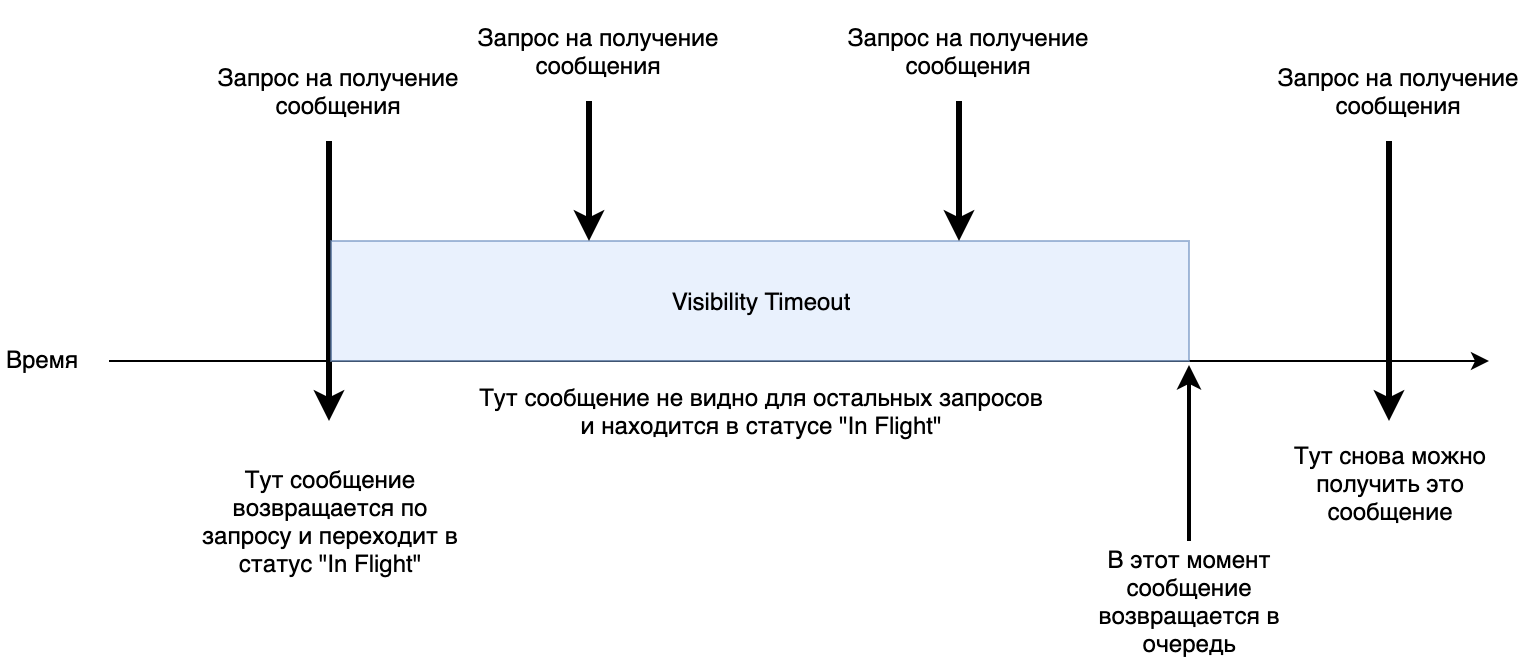
Notice: Будьте внимательны. SQS в некоторых случаях может прислать дубликат сообщения(Пункт «At-Least-Once Delivery»). По этому ваш сервис, для обработки должен быть идемпотентным.
2. Механизм обработки ошибок. В SQS можно настроить вторую очередь для «мертвых» сообщений(Dead Letter Queue). То есть те, которые не смог обработать наш сервис, будут отправляться в отдельную очередь, которой вы можете распоряжаться по своему усмотрению. Также вы можете задавать после которого кол-ва неудачных попыток сообщение перейдет в «мертвую» очередь. Неудачной попыткой считается истечение «Visibility timeout». То есть если за это время не было отправлено запроса на удаление, такое сообщение будет считаться необработанным и вернется в основную очередь или перейдет в «мертвую».
3. Дедупликация сообщений. Так же SQS имеет систему защиты от дубликатов. У каждого сообщения есть «Deduplication Id», SQS не добавит в очередь сообщение с
повторным «Deduplication Id» в течении 5 минут. Вы обязаны задавать «Deduplication Id» в каждом сообщении или включить генерацию id на основе контента. Это означает что в «Deduplication Id» будет попадать хэш сгенерированный исходя из вашего контента. Параметр «Content-Based Deduplication». Подробнее о дедупликации
Notice: Будьте внимательны, если отправить два одинаковых сообщения в течении 5 минут и у вас включен «Content-Based Deduplication» SQS не добавит второе сообщение в очередь.
Notice: Будьте внимательны, к примеру если на девайсе отпала связь, и он не получил ответ и затем отправил повторный запрос спустя 5 минут, дубликат создастся.4. Long poll. Длительный опрос. SQS поддерживает такой тип подключения с максимальным таймаутом в 20 секунд. Что нам позволяет сэкономить на трафике и «дерганье» сервиса.
5. Метрики. Так же Amazon предоставляет подробные метрики по очередям. Такие как кол-во полученных/отправленных/удаленных сообщений, размеры в КБ этих сообщений и прочее. Также вы можете подключить SQS к сервису логов CloudWatch. Там сможете увидеть еще подробнее. Так же там можно настроить так называемые «сигналы тревоги»(Alarms) и вы можете настраивать действия по каким либо событиям. Подробнее о подключении к SQS. И Документация по CloudWatch
Теперь давайте рассмотрим настройки очереди:
Основные:
Default Visibility Timeout - кол-во секунд/минут/часов, за которое сообщение после получения не будет видно для получения. Максимальное время на обработку — 12 часов.
Message Retention Period — кол-во секунд/минут/часов/дней, которое означает, сколько по времени будут в очереди храниться необработанные сообщения. Максимально — 14 дней.
Maximum Message Size — максимальный размер сообщения в KB. Значение от 1KB до 256KB.
Delivery Delay - можно задать время задержки доставки сообщения в очередь. От 0 секунд до 15 минут(Фактически, сообщения будут находится в очереди, но не будут видны для получения).
Receive Message Wait Time — время, сколько будет держаться коннект в случае, если мы используем «Long poll», для получения новых сообщений.
Content-Based Deduplication — флаг, если установлен в true, то в каждое сообщение будет добавлен «Deduplication Id» в виде SHA-256 хэша, сгенерированный из контента.
Настройки «мертвой очереди»
Use Redrive Policy — флаг, если установлен, то сообщения после нескольких попыток будут перенаправляться.
Dead Letter Queue — имя «мертвой» очереди, в которую будут отправляться необработанные сообщения.
Maximum Receives — кол-во неудачных попыток обработки, после которых сообщение будет отправляться в «мертвую» очередь
Notice: Также обратите внимание, что все основные параметры мы можем отправлять вместе с каждым сообщением отдельно. К примеру, каждое отдельное сообщение может иметь свой Visibility Timeout или Delivery Delay
Теперь немного про сами сообщения и их свойства:
Сообщение имеет несколько параметров:
1. Massage body — любой текст
2. Message Group Id - это что-то вроде тега, канала, обязателен для всех сообщений. Каждая такая группа гарантированно обрабатывается в режиме FIFO.
3. Message Deduplication Id — строка, для определения дубликатов. Если задан режим «Content-Based Deduplication», параметр не обязателен.
Также есть атрибуты сообщений
Атрибуты состоят из имени, типа и значения.
1. Name — строка
2. Type - есть несколько типов: string, number, binary. Тип приходит просто как строка, и есть возможность к типу добавить постфикс. В этом случае тип придет с этим постфиксом через точку, к примеру string.example_postfix
3. Value — строка
Notice: Обратите внимание, что максимальное кол-во атрибутов 10 ПодробностиP.S.: В этой статье изложено краткое описание про очереди, а также немного о возможностях и механике работы SQS. Следующая статья будет посвящена AWS Lambda, а потом их практическое совместное использование.
Комментариев нет:
Отправить комментарий