
Вступление
День добрый. Уже пол года у нас работает скрипт (точнее набор скриптов), генерирующий отчёты по состоянию виртуальных машин (и не только). Решил поделиться опытом создания и самим кодом. Рассчитываю на критику и на то, что данный материал может быть кому-то полезным.
Формирование потребности
Виртуальных машин у нас много (порядка 1500 ВМ распределённых по 3-м vCenter). Создаются новые и удаляются старые достаточно часто. Для сохранения порядка было добавлено несколько custom полей в vCenter, чтобы разделять ВМ на Подсистемы, указывать тестовые ли они, а также кем и когда созданы. Человеческий фактор привёл к тому, что более половины машин остались с незаполненными полями, что усложняло работу. Раз в пол года кто-то психовал, затевал работу по актуализации этих данных, но результат переставал быть актуальным уже недели через полторы.
Сразу уточню, что все понимают, что должны быть заявки на создание машин, процесс по их созданию, и т.д. и т.п. И при этом все этому процессу неукоснительно следуют и во всём порядок. У нас, к сожалению, не так, но это не предмет статьи :)
В общем, было принято решение автоматизировать проверку правильности заполнения полей.
Решили, что ежедневное письмо со списком неправильно заполненных машин на всех ответственных инженеров и их начальников будет хорошим началом.
На этот момент одним из коллег уже был внедрён скрипт на PowerShell, который каждый день по расписанию собирал информацию по всем машинам всех vCenter-ов и формировал 3 csv документа (каждый по своему vCenter), которые выкладывались на общий диск. Было принято решение взять этот скрипт за основу и дополнить проверками с помощью языка R, по работе с которым был некоторый опыт.
В процессе доработки решение обросло информированием по почте, базой данных с основной и исторической таблицей (об этом позднее), а также анализом логов vSphere для поиска фактических создателей vm и времени их создания.
Для разработки использовались IDE RStudio Desktop и PowerShell ISE.
Скрипт запускается с обычной виндовой виртуальной машины.
Описание общей логики.
Общая логика скриптов получилась следующая.
- Собираем данные по виртуальным машинам с помощью PowerShell скрипта, который вызываем через R, результат объединяем в один csv. Обратное взаимодействие между языками сделано аналогично. (можно было гонять данные напрямую из R в PowerShell в виде переменных, но это сложно, да и имея промежуточные csv легче дебажить и делиться с кем-то промежуточными результатами).
- С помощью R формируем допустимые параметры для полей, значения которых мы проверяем. — Формируем word документ, который будет содержать значения этих полей для вставки в информационное письмо, которое будет ответом на вопросы коллег "Не ну а как я это должен заполнить?".
- Загружаем данные по всем ВМ из csv с помощью R, формируем dataframe, убираем ненужные поля и формируем информационный xlsx документ, который будет содержать сводную информацию по всем ВМ, который выкладываем на общий ресурс.
- К dataframe по всем ВМ применяем все проверки правильности заполнения полей и формируем таблицу, содержащую только ВМ с неправильно заполненными полями (и только эти поля).
- Полученный список ВМ отправляем на другой PowerShell скрипт, который будет смотреть логи vCenter на предмет событий создания ВМ, что позволит указать предполагаемое время создания ВМ и предполагаемого создателя. Это на случай, когда никто не сознаётся, чья машина. Данный скрипт работает не быстро, особенно, если логов много, поэтому смотрим только последние 2 недели, а также используем workflow, который позволяет выполнять поиск информации по нескольким ВМ одновременно. В примере скрипта есть подробные комментарии по данному механизму. Результат складываем в csv, который опять загружаем в R.
- Формируем красиво отформатированный xlsx документ, в котором будут выделены красным цветом неправильно заполненные поля, применены фильтры к некоторым колонкам, а также указаны дополнительные колонки, содержащие предполагаемых создателей и время создания ВМ.
- Формируем электронное письмо, куда вкладываем документ, описывающий допустимые значения полей, а также таблицу с неправильно заполненными вм. В тексте указываем общее количество неправильно созданных ВМ, ссылку на общий ресурс и мотивационную картинку. Если неправильно заполненных ВМ нет — отправляем другое письмо с более радостной мотивационной картинкой.
- Записываем данные по всем ВМ в БД SQL Server с учётом внедрённого механизма исторических таблиц (очень интересный механизм — о котором подробнее дальше)
Собственно скрипты
# Путь к рабочей директории (нужно для корректной работы через виндовый планировщик заданий)
setwd("C:\\Scripts\\getVm")
#### Подгружаем необходимые пакеты ####
library(tidyverse)
library(xlsx)
library(mailR)
library(rmarkdown)
##### Определяем пути к исходным файлам и другие переменные #####
source(file = "const.R", local = T, encoding = "utf-8")
# Проверяем существование файла со всеми ВМ и удаляем, если есть.
if (file.exists(filenameVmCreationRules)) {file.remove(filenameVmCreationRules)}
#### Создаём вордовский документ с допустимыми полями
render("VM_name_rules.Rmd",
output_format = word_document(),
output_file = filenameVmCreationRules)
# Проверяем существование файла со всеми ВМ и удаляем, если есть
if (file.exists(allVmXlsxPath)) {file.remove(allVmXlsxPath)}
#### Забираем данные по всем машинам через PowerShell скрипт. На выходе получим csv.
system(paste0("powershell -File ", getVmPsPath))
# Полный df
fullXslx_df <- allVmXlsxPath %>%
read.csv2(stringsAsFactors = FALSE)
# Проверяем корректность заполненных полей
full_df <- fullXslx_df %>%
mutate(
# Сначала убираем все лишние пробелы и табуляции, потом учитываем разделитель запятую, потом проверяем вхождение в допустимые значения,
isSubsystemCorrect = Subsystem %>%
gsub("[[:space:]]", "", .) %>%
str_split(., ",") %>%
map(function(x) (all(x %in% AllowedValues$Subsystem))) %>%
as.logical(),
isOwnerCorrect = Owner %in% AllowedValues$Owner,
isCategoryCorrect = Category %in% AllowedValues$Category,
isCreatorCorrect = (!is.na(Creator) & Creator != ''),
isCreation.DateCorrect = map(Creation.Date, IsDate)
)
# Проверяем существование файла со всеми ВМ и удаляем, если есть.
if (file.exists(filenameAll)) {file.remove(filenameAll)}
#### Формируем xslx файл с отчётом ####
# Общие данные на отдельный лист
full_df %>% write.xlsx(file=filenameAll,
sheetName=names[1],
col.names=TRUE,
row.names=FALSE,
append=FALSE)
#### Формируем xslx файл с неправильно заполненными полями ####
# Формируем df
incorrect_df <- full_df %>%
select(VM.Name,
IP.s,
Owner,
Subsystem,
Creator,
Category,
Creation.Date,
isOwnerCorrect,
isSubsystemCorrect,
isCategoryCorrect,
isCreatorCorrect,
vCenter.Name) %>%
filter(isSubsystemCorrect == F |
isOwnerCorrect == F |
isCategoryCorrect == F |
isCreatorCorrect == F)
# Проверяем существование файла со всеми ВМ и удаляем, если есть.
if (file.exists(filenameIncVM)) {file.remove(filenameIncVM)}
# Сохраняем список VM с незаполненными полями в csv
incorrect_df %>%
select(VM.Name) %>%
write_csv2(path = filenameIncVM, append = FALSE)
# Фильтруем для вставки в почту
incorrect_df_filtered <- incorrect_df %>%
select(VM.Name,
IP.s,
Owner,
Subsystem,
Category,
Creator,
vCenter.Name,
Creation.Date
)
# Считаем количество строк
numberOfRows <- nrow(incorrect_df)
#### Начало условия ####
# Дальше либо у нас есть неправильно заполненные поля, либо нет.
# Если есть - запускаем ещё один скрипт
if (numberOfRows > 0) {
# Проверяем существование файла с создателями и удаляем, если есть.
if (file.exists(creatorsFilePath)) {file.remove(creatorsFilePath)}
# Запускаем PowerShell скрипт, который найдёт создателей найденных VM. На выходе получим csv.
system(paste0("powershell -File ", getCreatorsPath))
# Читаем файл с создателями
creators_df <- creatorsFilePath %>%
read.csv2(stringsAsFactors = FALSE)
# Фильтруем для вставки в почту, добавляем данные из таблицы с создателями
incorrect_df_filtered <- incorrect_df_filtered %>%
select(VM.Name,
IP.s,
Owner,
Subsystem,
Category,
Creator,
vCenter.Name,
Creation.Date
) %>%
left_join(creators_df, by = "VM.Name") %>%
rename(`Предполагаемый создатель` = CreatedBy,
`Предполагаемая дата создания` = CreatedOn)
# Формируем тело письма
emailBody <- paste0(
'<html>
<h3>Добрый день, уважаемые коллеги.</h3>
<p>Полную актуальную информацию по виртуальным машинам вы можете посмотреть на диске H: вот тут:<p>
<p>\\\\server.ru\\VM\\', sourceFileFormat, '</p>
<p>Также во вложении список ВМ с <strong>некорректно заполненными</strong> полями. Всего их <strong>', numberOfRows,'</strong>.</p>
<p>В таблице появилось 2 дополнительные колонки. <strong>Предполагаемый создатель</strong> и <strong>Предполагаемая дата создания</strong>, которые достаются из логов vCenter за последние 2 недели</p>
<p>Просьба создателей машин уточнить данные и заполнить поля корректно. Правила заполнения полей также во вложении</p>
<p><img src="data/meme.jpg"></p>
</html>'
)
# Проверяем существование файла
if (file.exists(filenameIncorrect)) {file.remove(filenameIncorrect)}
# Формируем красивую таблицу с форматами и т.д.
source(file = "email.R", local = T, encoding = "utf-8")
#### Формируем письмо с плохо подписанными машинами ####
send.mail(from = emailParams$from,
to = emailParams$to,
subject = "ВМ с некорректно заполненными полями",
body = emailBody,
encoding = "utf-8",
html = TRUE,
inline = TRUE,
smtp = emailParams$smtpParams,
authenticate = TRUE,
send = TRUE,
attach.files = c(filenameIncorrect, filenameVmCreationRules),
debug = FALSE)
#### Дальше пойдёт блок, если нет проблем с ВМ ####
} else {
# Формируем тело письма
emailBody <- paste0(
'<html>
<h3>Добрый день, уважаемые коллеги</h3>
<p>Полную актуальную информацию по виртуальным машинам вы можете посмотреть на диске H: вот тут:<p>
<p>\\\\server.ru\\VM\\', sourceFileFormat, '</p>
<p>Также, на текущий момент, все поля ВМ корректно заполнены</p>
<p><img src="data/meme_correct.jpg"></p>
</html>'
)
#### Формируем письмо без плохо заполненных VM ####
send.mail(from = emailParams$from,
to = emailParams$to,
subject = "Сводная информация",
body = emailBody,
encoding = "utf-8",
html = TRUE,
inline = TRUE,
smtp = emailParams$smtpParams,
authenticate = TRUE,
send = TRUE,
debug = FALSE)
}
####### Записываем данные в БД #####
source(file = "DB.R", local = T, encoding = "utf-8")
# Данные для подключения и другие переменные
$vCenterNames = @(
"vcenter01",
"vcenter02",
"vcenter03"
)
$vCenterUsername = "myusername"
$vCenterPassword = "mypassword"
$filename = "C:\Scripts\getVm\data\allvm\all-vm-$(get-date -f yyyy-MM-dd).csv"
$destinationSMB = "\\server.ru\myfolder$\vm"
$IP0=""
$IP1=""
$IP2=""
$IP3=""
$IP4=""
$IP5=""
# Подключение ко всем vCenter, что содержатся в переменной. Будет работать, если логин и пароль одинаковые (например, доменные)
Connect-VIServer -Server $vCenterNames -User $vCenterUsername -Password $vCenterPassword
write-host ""
# Создаём функцию с циклом по всем vCenter-ам
function Get-VMinventory {
# В этой переменной будет списко всех ВМ, как объектов
$AllVM = Get-VM | Sort Name
$cnt = $AllVM.Count
$count = 1
# Начинаем цикл по всем ВМ и собираем необходимые параметры каждого объекта
foreach ($vm in $AllVM) {
$StartTime = $(get-date)
$IP0 = $vm.Guest.IPAddress[0]
$IP1 = $vm.Guest.IPAddress[1]
$IP2 = $vm.Guest.IPAddress[2]
$IP3 = $vm.Guest.IPAddress[3]
$IP4 = $vm.Guest.IPAddress[4]
$IP5 = $vm.Guest.IPAddress[5]
If ($IP0 -ne $null) {If ($IP0.Contains(":") -ne 0) {$IP0=""}}
If ($IP1 -ne $null) {If ($IP1.Contains(":") -ne 0) {$IP1=""}}
If ($IP2 -ne $null) {If ($IP2.Contains(":") -ne 0) {$IP2=""}}
If ($IP3 -ne $null) {If ($IP3.Contains(":") -ne 0) {$IP3=""}}
If ($IP4 -ne $null) {If ($IP4.Contains(":") -ne 0) {$IP4=""}}
If ($IP5 -ne $null) {If ($IP5.Contains(":") -ne 0) {$IP5=""}}
$cluster = $vm | Get-Cluster | Select-Object -ExpandProperty name
$Bootime = $vm.ExtensionData.Runtime.BootTime
$TotalHDDs = $vm.ProvisionedSpaceGB -as [int]
$CreationDate = $vm.CustomFields.Item("CreationDate") -as [string]
$Creator = $vm.CustomFields.Item("Creator") -as [string]
$Category = $vm.CustomFields.Item("Category") -as [string]
$Owner = $vm.CustomFields.Item("Owner") -as [string]
$Subsystem = $vm.CustomFields.Item("Subsystem") -as [string]
$IPS = $vm.CustomFields.Item("IP") -as [string]
$vCPU = $vm.NumCpu
$CorePerSocket = $vm.ExtensionData.config.hardware.NumCoresPerSocket
$Sockets = $vCPU/$CorePerSocket
$Id = $vm.Id.Split('-')[2] -as [int]
# Собираем все параметры в один объект
$Vmresult = New-Object PSObject
$Vmresult | add-member -MemberType NoteProperty -Name "Id" -Value $Id
$Vmresult | add-member -MemberType NoteProperty -Name "VM Name" -Value $vm.Name
$Vmresult | add-member -MemberType NoteProperty -Name "Cluster" -Value $cluster
$Vmresult | add-member -MemberType NoteProperty -Name "Esxi Host" -Value $VM.VMHost
$Vmresult | add-member -MemberType NoteProperty -Name "IP Address 1" -Value $IP0
$Vmresult | add-member -MemberType NoteProperty -Name "IP Address 2" -Value $IP1
$Vmresult | add-member -MemberType NoteProperty -Name "IP Address 3" -Value $IP2
$Vmresult | add-member -MemberType NoteProperty -Name "IP Address 4" -Value $IP3
$Vmresult | add-member -MemberType NoteProperty -Name "IP Address 5" -Value $IP4
$Vmresult | add-member -MemberType NoteProperty -Name "IP Address 6" -Value $IP5
$Vmresult | add-member -MemberType NoteProperty -Name "vCPU" -Value $vCPU
$Vmresult | Add-Member -MemberType NoteProperty -Name "CPU Sockets" -Value $Sockets
$Vmresult | Add-Member -MemberType NoteProperty -Name "Core per Socket" -Value $CorePerSocket
$Vmresult | add-member -MemberType NoteProperty -Name "RAM (GB)" -Value $vm.MemoryGB
$Vmresult | add-member -MemberType NoteProperty -Name "Total-HDD (GB)" -Value $TotalHDDs
$Vmresult | add-member -MemberType NoteProperty -Name "Power State" -Value $vm.PowerState
$Vmresult | add-member -MemberType NoteProperty -Name "OS" -Value $VM.ExtensionData.summary.config.guestfullname
$Vmresult | Add-Member -MemberType NoteProperty -Name "Boot Time" -Value $Bootime
$Vmresult | add-member -MemberType NoteProperty -Name "VMTools Status" -Value $vm.ExtensionData.Guest.ToolsStatus
$Vmresult | add-member -MemberType NoteProperty -Name "VMTools Version" -Value $vm.ExtensionData.Guest.ToolsVersion
$Vmresult | add-member -MemberType NoteProperty -Name "VMTools Version Status" -Value $vm.ExtensionData.Guest.ToolsVersionStatus
$Vmresult | add-member -MemberType NoteProperty -Name "VMTools Running Status" -Value $vm.ExtensionData.Guest.ToolsRunningStatus
$Vmresult | add-member -MemberType NoteProperty -Name "Creation Date" -Value $CreationDate
$Vmresult | add-member -MemberType NoteProperty -Name "Creator" -Value $Creator
$Vmresult | add-member -MemberType NoteProperty -Name "Category" -Value $Category
$Vmresult | add-member -MemberType NoteProperty -Name "Owner" -Value $Owner
$Vmresult | add-member -MemberType NoteProperty -Name "Subsystem" -Value $Subsystem
$Vmresult | add-member -MemberType NoteProperty -Name "IP's" -Value $IPS
$Vmresult | add-member -MemberType NoteProperty -Name "vCenter Name" -Value $vm.Uid.Split('@')[1].Split(':')[0]
# Считаем общее и оставшееся время выполнения и выводим на экран результаты. Использовалось для тестирования, но по факту оказалось очень удобно.
$elapsedTime = $(get-date) - $StartTime
$totalTime = "{0:HH:mm:ss}" -f ([datetime]($elapsedTime.Ticks*($cnt - $count)))
clear-host
Write-Host "Processing" $count "from" $cnt
Write-host "Progress:" ([math]::Round($count/$cnt*100, 2)) "%"
Write-host "You have about " $totalTime "for cofee"
Write-host ""
$count++
# Выводим результат, чтобы цикл "знал" что является результатом выполнения одного прохода
$Vmresult
}
}
# Вызываем получившуюся функцию и сразу выгружаем результат в csv
$allVm = Get-VMinventory | Export-CSV -Path $filename -NoTypeInformation -UseCulture -Force
# Пытаемся выложить полученный файл в нужное нам место и, в случае ошибки, пишем лог.
try
{
Copy-Item $filename -Destination $destinationSMB -Force -ErrorAction SilentlyContinue
}
catch
{
$error | Export-CSV -Path $filename".error" -NoTypeInformation -UseCulture -Force
}
# Путь к файлу, из которого будем доставать список VM
$VMfilePath = "C:\Scripts\getVm\creators_VM\creators_VM_$(get-date -f yyyy-MM-dd).csv"
# Путь к файлу, в который будем записывать результат
$filePath = "C:\Scripts\getVm\data\creators\creators-$(get-date -f yyyy-MM-dd).csv"
# Создаём вокрфлоу
Workflow GetCreators-Wf
{
# Параметры, которые можно будет передать при вызове скрипта
param([string[]]$VMfilePath)
# Параметры, которые доступны только внутри workflow
$vCenterUsername = "myusername"
$vCenterPassword = "mypassword"
$daysToLook = 14
$start = (get-date).AddDays(-$daysToLook)
$finish = get-date
# Значения, которые будут вписаны в csv для машин, по которым не будет ничего найдено
$UnknownUser = "UNKNOWN"
$UnknownCreatedTime = "0000-00-00"
# Определяем параметры подключения и выводной файл, которые будут доступны во всём скрипте.
$vCenterNames = @(
"vcenter01",
"vcenter02",
"vcenter03"
)
# Получаем список VM из csv и загружаем соответствующие объекты
$list = Import-Csv $VMfilePath -UseCulture | select -ExpandProperty VM.Name
# Цикл, который будет выполняться параллельно (по 5 машин за раз)
foreach -parallel ($row in $list)
{
# Это скрипт, который видит только свои переменные и те, которые ему переданы через $Using
InlineScript {
# Время начала выполнения отдельного блока
$StartTime = $(get-date)
Write-Host ""
Write-Host "Processing $Using:row started at $StartTime"
Write-Host ""
# Подключение оборачиваем в переменную, чтобы информация о нём не мешалась в консоли
$con = Connect-VIServer -Server $Using:vCenterNames -User $Using:vCenterUsername -Password $Using:vCenterPassword
# Получаем объект vm
$vm = Get-VM -Name $Using:row
# Ниже 2 одинаковые команды. Одна с фильтром по времени, вторая - без. Можно пользоваться тем,
$Event = $vm | Get-VIEvent -Start $Using:start -Finish $Using:finish -Types Info | Where { $_.Gettype().Name -eq "VmBeingDeployedEvent" -or $_.Gettype().Name -eq "VmCreatedEvent" -or $_.Gettype().Name -eq "VmRegisteredEvent" -or $_.Gettype().Name -eq "VmClonedEvent"}
# $Event = $vm | Get-VIEvent -Types Info | Where { $_.Gettype().Name -eq "VmBeingDeployedEvent" -or $_.Gettype().Name -eq "VmCreatedEvent" -or $_.Gettype().Name -eq "VmRegisteredEvent" -or $_.Gettype().Name -eq "VmClonedEvent"}
# Заполняем параметры в зависимости от того, удалось ли в логах найти что-то
If (($Event | Measure-Object).Count -eq 0){
$User = $Using:UnknownUser
$Created = $Using:UnknownCreatedTime
$CreatedFormat = $Using:UnknownCreatedTime
} Else {
If ($Event.Username -eq "" -or $Event.Username -eq $null) {
$User = $Using:UnknownUser
} Else {
$User = $Event.Username
} # Else
$CreatedFormat = $Event.CreatedTime
# Один из коллег отдельно просил, чтобы время было в таком формате, поэтому дублируем его. А в БД пойдёт нормальный формат.
$Created = $Event.CreatedTime.ToString('yyyy-MM-dd')
} # Else
Write-Host "Creator for $vm is $User. Creating object."
# Создаём объект. Добавляем параметры.
$Vmresult = New-Object PSObject
$Vmresult | add-member -MemberType NoteProperty -Name "VM Name" -Value $vm.Name
$Vmresult | add-member -MemberType NoteProperty -Name "CreatedBy" -Value $User
$Vmresult | add-member -MemberType NoteProperty -Name "CreatedOn" -Value $CreatedFormat
$Vmresult | add-member -MemberType NoteProperty -Name "CreatedOnFormat" -Value $Created
# Выводим результаты
$Vmresult
} # Inline
} # ForEach
}
$Creators = GetCreators-Wf $VMfilePath
# Записываем результат в файл
$Creators | select 'VM Name', CreatedBy, CreatedOn | Export-Csv -Path $filePath -NoTypeInformation -UseCulture -Force
Write-Host "CSV generetion finisghed at $(get-date). PROFIT"
Отдельного внимания заслуживает библиотека xlsx, которая позволила сделать вложение к письму наглядно отформатированным (как любит руководство), а не просто csv таблицей.
# Создаём новую книгу
# Возможные значения : "xls" и "xlsx"
wb<-createWorkbook(type="xlsx")
# Стили для имён рядов и колонок в таблицах
TABLE_ROWNAMES_STYLE <- CellStyle(wb) + Font(wb, isBold=TRUE)
TABLE_COLNAMES_STYLE <- CellStyle(wb) + Font(wb, isBold=TRUE) +
Alignment(wrapText=TRUE, horizontal="ALIGN_CENTER") +
Border(color="black", position=c("TOP", "BOTTOM"),
pen=c("BORDER_THIN", "BORDER_THICK"))
# Создаём новый лист
sheet <- createSheet(wb, sheetName = names[2])
# Добавляем таблицу
addDataFrame(incorrect_df_filtered,
sheet, startRow=1, startColumn=1, row.names=FALSE, byrow=FALSE,
colnamesStyle = TABLE_COLNAMES_STYLE,
rownamesStyle = TABLE_ROWNAMES_STYLE)
# Меняем ширину, чтобы форматирование было автоматическим
autoSizeColumn(sheet = sheet, colIndex=c(1:ncol(incorrect_df)))
# Добавляем фильтры
addAutoFilter(sheet, cellRange = "C1:G1")
# Определяем стиль
fo2 <- Fill(foregroundColor="red")
cs2 <- CellStyle(wb,
fill = fo2,
dataFormat = DataFormat("@"))
# Находим ряды с неверно заполненным полем Владельца и применяем к ним определённый стиль
rowsOwner <- getRows(sheet, rowIndex = (which(!incorrect_df$isOwnerCorrect) + 1))
cellsOwner <- getCells(rowsOwner, colIndex = which( colnames(incorrect_df_filtered) == "Owner" ))
lapply(names(cellsOwner), function(x) setCellStyle(cellsOwner[[x]], cs2))
# Находим ряды с неверно заполненным полем Подсистемы и применяем к ним определённый стиль
rowsSubsystem <- getRows(sheet, rowIndex = (which(!incorrect_df$isSubsystemCorrect) + 1))
cellsSubsystem <- getCells(rowsSubsystem, colIndex = which( colnames(incorrect_df_filtered) == "Subsystem" ))
lapply(names(cellsSubsystem), function(x) setCellStyle(cellsSubsystem[[x]], cs2))
# Аналогично по Категории
rowsCategory <- getRows(sheet, rowIndex = (which(!incorrect_df$isCategoryCorrect) + 1))
cellsCategory <- getCells(rowsCategory, colIndex = which( colnames(incorrect_df_filtered) == "Category" ))
lapply(names(cellsCategory), function(x) setCellStyle(cellsCategory[[x]], cs2))
# Создатель
rowsCreator <- getRows(sheet, rowIndex = (which(!incorrect_df$isCreatorCorrect) + 1))
cellsCreator <- getCells(rowsCreator, colIndex = which( colnames(incorrect_df_filtered) == "Creator" ))
lapply(names(cellsCreator), function(x) setCellStyle(cellsCreator[[x]], cs2))
# Сохраняем файл
saveWorkbook(wb, filenameIncorrect)
На выходе получается примерно вот так:
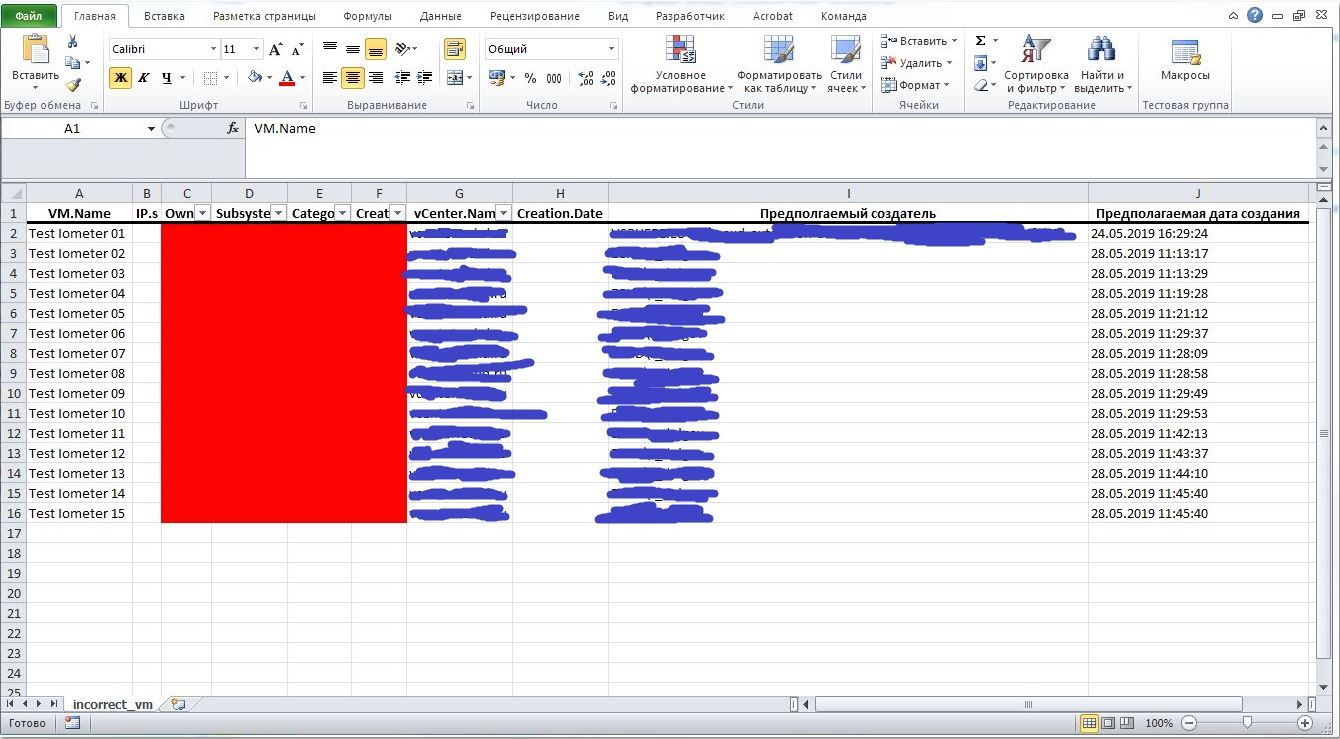
Также был интересный нюанс по настройке Windows scheduller. Никак не получалось подобрать правильные параметры прав и настроек, чтобы всё запускалось, как нужно. В итоге была найдена библиотека R, которая сама создаёт задание по запуску R скрипта и даже не забывает про файл для логов. Потом можно ручками подправить задание.
library(taskscheduleR)
myscript <- file.path(getwd(), "all_vm.R")
## запускаем скрипт через 62 секунды
taskscheduler_create(taskname = "getAllVm", rscript = myscript,
schedule = "ONCE", starttime = format(Sys.time() + 62, "%H:%M"))
## запускаем скрипт каждый день в 09:10
taskscheduler_create(taskname = "getAllVmDaily", rscript = myscript,
schedule = "WEEKLY",
days = c("MON", "TUE", "WED", "THU", "FRI"),
starttime = "02:00")
## удаляем задачи
taskscheduler_delete(taskname = "getAllVm")
taskscheduler_delete(taskname = "getAllVmDaily")
# Смотрим логи (последние 4 строчки)
tail(readLines("all_vm.log"), sep ="\n", n = 4)
Отдельно про БД
После настройки скрипта стали проявляться другие вопросы. Например, хотелось найти дату, когда ВМ была удалена, а логи в vCenter уже потёрлись. Поскольку скрипт складывает файлы в папку каждый день и не чистит (чистим руками, когда вспоминаем), то можно просмотреть старые файлы и найти первый файл, в котором данной ВМ нет. Но это не круто.
Захотелось создать историческую БД.
На помощь пришёл функционал MS SQL SERVER — system-versioned temporal table. Его обычно переводят, как временнЫе (не врЕменные) таблицы.
Можно подробно почитать в официальной документации Microsoft.
Если вкратце — создаём таблицу, говорим, что она у нас будет с версионностью и SQL Server создаёт 2 дополнительные datetime колонки в этой таблице (дату создания записи и дату окончания жизни записи) и дополнительную таблицу, в которую будут писаться изменения. В результате получаем актуальную информацию и, путём несложных запросов, примеры которых даны в документации, можем увидеть либо жизненный цикл конкретной виртуальной машины, либо состояние всех ВМ на определённый момент времени.
С точки зрения производительности — транзакция записи в основную таблицу не будет завершена, пока не завершится транзакция записи в временную таблицу. Т.е. на таблицах с большим количеством операций записи этот функционал надо внедрять с осторожностью, но в нашем случае это прям очень прикольная штука.
Для того, чтобы механизм корректно работал пришлось на R дописать небольшой кусок кода, который сравнивал бы новую таблицу с данными по всем ВМ с той, что хранится в БД и записывала в неё только изменившиеся строки. Код не особо хитрый, использует библиотеку compareDF, но его я тоже приведу ниже.
# Подцепляем пакеты
library(odbc)
library(compareDF)
# Формируем коннект
con <- dbConnect(odbc(),
Driver = "ODBC Driver 13 for SQL Server",
Server = DBParams$server,
Database = DBParams$database,
UID = DBParams$UID,
PWD = DBParams$PWD,
Port = 1433)
#### Проверяем есть ли таблица. Если нет - создаём. ####
if (!dbExistsTable(con, DBParams$TblName)) {
#### Создаём таблицу ####
create <- dbSendStatement(
con,
paste0(
'CREATE TABLE ',
DBParams$TblName,
'(
[Id] [int] NOT NULL PRIMARY KEY CLUSTERED,
[VM.Name] [varchar](255) NULL,
[Cluster] [varchar](255) NULL,
[Esxi.Host] [varchar](255) NULL,
[IP.Address.1] [varchar](255) NULL,
[IP.Address.2] [varchar](255) NULL,
[IP.Address.3] [varchar](255) NULL,
[IP.Address.4] [varchar](255) NULL,
[IP.Address.5] [varchar](255) NULL,
[IP.Address.6] [varchar](255) NULL,
[vCPU] [int] NULL,
[CPU.Sockets] [int] NULL,
[Core.per.Socket] [int] NULL,
[RAM..GB.] [int] NULL,
[Total.HDD..GB.] [int] NULL,
[Power.State] [varchar](255) NULL,
[OS] [varchar](255) NULL,
[Boot.Time] [varchar](255) NULL,
[VMTools.Status] [varchar](255) NULL,
[VMTools.Version] [int] NULL,
[VMTools.Version.Status] [varchar](255) NULL,
[VMTools.Running.Status] [varchar](255) NULL,
[Creation.Date] [varchar](255) NULL,
[Creator] [varchar](255) NULL,
[Category] [varchar](255) NULL,
[Owner] [varchar](255) NULL,
[Subsystem] [varchar](255) NULL,
[IP.s] [varchar](255) NULL,
[vCenter.Name] [varchar](255) NULL,
DateFrom datetime2 GENERATED ALWAYS AS ROW START NOT NULL,
DateTo datetime2 GENERATED ALWAYS AS ROW END NOT NULL,
PERIOD FOR SYSTEM_TIME (DateFrom, DateTo)
) ON [PRIMARY]
WITH (SYSTEM_VERSIONING = ON (HISTORY_TABLE = ', DBParams$TblHistName,'));'
)
)
# Отправляем подготовленный запрос
dbClearResult(create)
} # if
#### Начало работы с таблицей ####
# Обозначаем таблицу, с которой будем работать
allVM_db_con <- tbl(con, DBParams$TblName)
#### Сравниваем таблицы ####
# Собираем данные с таблицы (убираем служебные временные поля)
allVM_db <- allVM_db_con %>%
select(c(-"DateTo", -"DateFrom")) %>%
collect()
# Создаём таблицу со сравнением объектов. Сравниваем по Id
# Удалённые объекты там будут помечены через -, созданные через +, изменённые через - и +
ctable_VM <- fullXslx_df %>%
compare_df(allVM_db,
c("Id"))
#### Удаление строк ####
# Выдираем Id виртуалок, записи о которых надо удалить
remove_Id <- ctable_VM$comparison_df %>%
filter(chng_type == "-") %>%
select(Id)
# Проверяем, что есть записи (если записей нет - и удалять ничего не нужно)
if (remove_Id %>% nrow() > 0) {
# Конструируем шаблон для запроса на удаление данных
delete <- dbSendStatement(con,
paste0('
DELETE
FROM ',
DBParams$TblName,
' WHERE "Id"=?
') # paste
) # send
# Создаём запрос на удаление данных
dbBind(delete, remove_Id)
# Отправляем подготовленный запрос
dbClearResult(delete)
} # if
#### Добавление строк ####
# Выделяем таблицу, содержащую строки, которые нужно добавить.
allVM_add <- ctable_VM$comparison_df %>%
filter(chng_type == "+") %>%
select(-chng_type)
# Проверяем, есть ли строки, которые нужно добавить и добавляем (если нет - не добавляем)
if (allVM_add %>% nrow() > 0) {
# Пишем таблицу со всеми необходимыми данными
dbWriteTable(con,
DBParams$TblName,
allVM_add,
overwrite = FALSE,
append = TRUE)
} # if
#### Не забываем сделать дисконнект ####
dbDisconnect(con)
Итого
В результате внедрения скрипта, за несколько месяцев был наведён и поддерживается порядок. Иногда неправильно заполненные ВМ появляются, но скрипт служит неплохим напоминанием и редкая ВМ попадает в список 2 дня подряд.
Также был сделан задел на анализ исторических данных.
Понятно, что многое из этого можно реализовать не "на коленке", а профильным ПО, но задача была интересной и, можно сказать, факультативной.
R в очередной раз показал себя прекрасным универсальным языком, который прекрасно подходит не только для решения статистических задач, но и выступает прекрасной "прокладкой" между другими источниками данных.

Комментариев нет:
Отправить комментарий