В большинстве случаев HTTP-запросы к серверу работают надёжно и возвращают желаемый результат. Однако в некоторых ситуациях запросы могут оказываться неудачными.
Представьте себе, как кто-то работает с вашим веб-сайтом через точку доступа в поезде, который несётся по стране со скоростью 200 километров в час. Сетевое соединение при таком раскладе может быть медленным, но запросы к серверу, несмотря на это, делают своё дело.
А что если поезд попадёт в туннель? Тут высока вероятность того, что связь с интернетом прервётся и веб-приложение не сможет «достучаться» до сервера. В этом случае пользователю придётся перезагрузить страницу приложения после того, как поезд выедет из туннеля и соединение с интернетом восстановится.
Перезагрузка страницы способна оказать воздействие на текущее состояние приложения. Это значит, что пользователь может, например, потерять данные, которые он ввёл в форму.
Вместо того чтобы просто смириться с тем фактом, что некий запрос оказался неудачным, лучше будет несколько раз его повторить и показать пользователю соответствующее уведомление. При таком подходе, когда пользователь поймёт, что приложение пытается справиться с проблемой, он, скорее всего, не станет перезагружать страницу.

Материал, перевод которого мы сегодня публикуем, посвящён разбору нескольких способов повторения неудачных запросов в Angular-приложениях.
Повтор неудачных запросов
Давайте воспроизведём ситуацию, с которой может столкнуться пользователь, работающий в интернете из поезда. Мы создадим бэкенд, который обрабатывает запрос неправильно в ходе трёх первых попыток обратиться к нему, возвращая данные лишь с четвёртой попытки.
Обычно, пользуясь Angular, мы создаём сервис, подключаем
HttpClient и используем его для получения данных с бэкенда.
import {Injectable} from '@angular/core';
import {HttpClient} from '@angular/common/http';
import {EMPTY, Observable} from 'rxjs';
import {catchError} from 'rxjs/operators';
@Injectable()
export class GreetingService {
private GREET_ENDPOINT = 'http://localhost:3000';
constructor(private httpClient: HttpClient) {
}
greet(): Observable<string> {
return this.httpClient.get<string>(`${this.GREET_ENDPOINT}/greet`).pipe(
catchError(() => {
// Выполняем обработку ошибок
return EMPTY;
})
);
}
}
Тут нет ничего особенного. Мы подключаем модуль Angular
HttpClient и выполняем простой GET-запрос. Если запрос вернёт ошибку — мы выполняем некий код для её обработки и возвращаем пустой Observable (наблюдаемый объект) для того чтобы проинформировать об этом то, что инициировало запрос. Этот код как бы говорит: «Возникла ошибка, но всё в порядке, я с этим справлюсь».
Большинство приложений выполняет HTTP-запросы именно так. В вышеприведённом коде запрос выполняется лишь один раз. После этого он либо возвращает данные, полученные с сервера, либо оказывается неудачным.
Как повторить запрос в том случае, если конечная точка /greet недоступна или возвращает ошибку? Может быть, существует подходящий оператор RxJS? Конечно, он существует. В RxJS есть операторы для всего чего угодно.
Первое, что в этой ситуации может прийти в голову, это — оператор retry. Посмотрим на его определение: «Возвращает Observable, который воспроизводит исходный Observable за исключением error. Если исходный Observable вызывает error, то этот метод, вместо распространения ошибки, выполнит повторную подписку на исходный Observable.
Максимальное число повторных подписок ограничено count (это — числовой параметр, передаваемый методу)».
Оператор retry очень похож на то, что нам нужно. Поэтому давайте встроим его в нашу цепочку.
import {Injectable} from '@angular/core';
import {HttpClient} from '@angular/common/http';
import {EMPTY, Observable} from 'rxjs';
import {catchError, retry, shareReplay} from 'rxjs/operators';
@Injectable()
export class GreetingService {
private GREET_ENDPOINT = 'http://localhost:3000';
constructor(private httpClient: HttpClient) {
}
greet(): Observable<string> {
return this.httpClient.get<string>(`${this.GREET_ENDPOINT}/greet`).pipe(
retry(3),
catchError(() => {
// Выполняем обработку ошибок
return EMPTY;
}),
shareReplay()
);
}
}
Мы успешно воспользовались оператором
retry. Посмотрим на то, как это повлияло на поведение HTTP-запроса, который выполняется в экспериментальном приложении. Вот GIF-файл большого размера, который демонстрирует экран этого приложения и вкладку Network инструментов разработчика браузера. Вы встретите здесь ещё несколько таких демонстраций.
{kind=link}
Наше приложение устроено предельно просто. Оно просто выполняет HTTP-запрос при нажатии на кнопку PING THE SERVER.
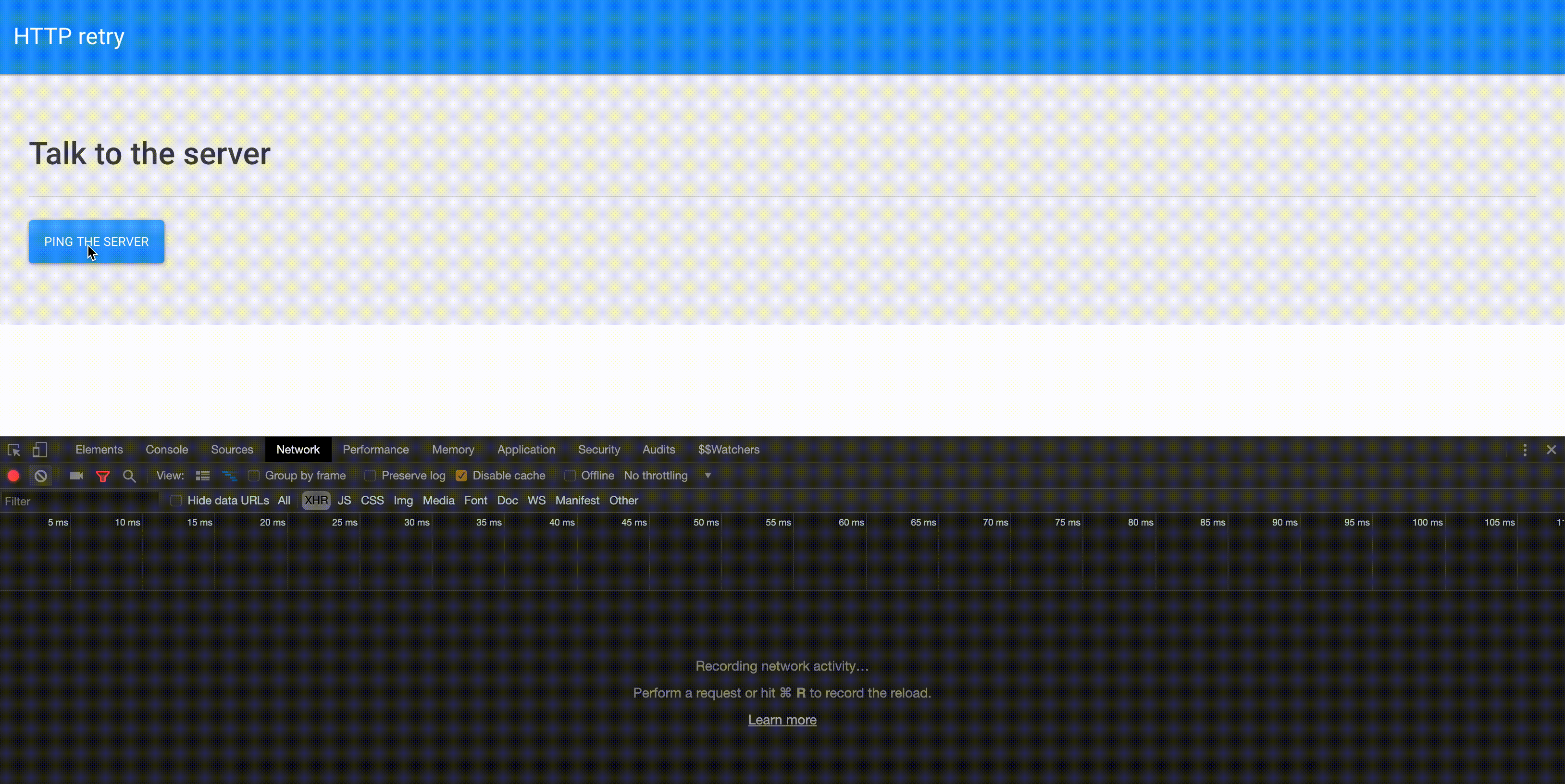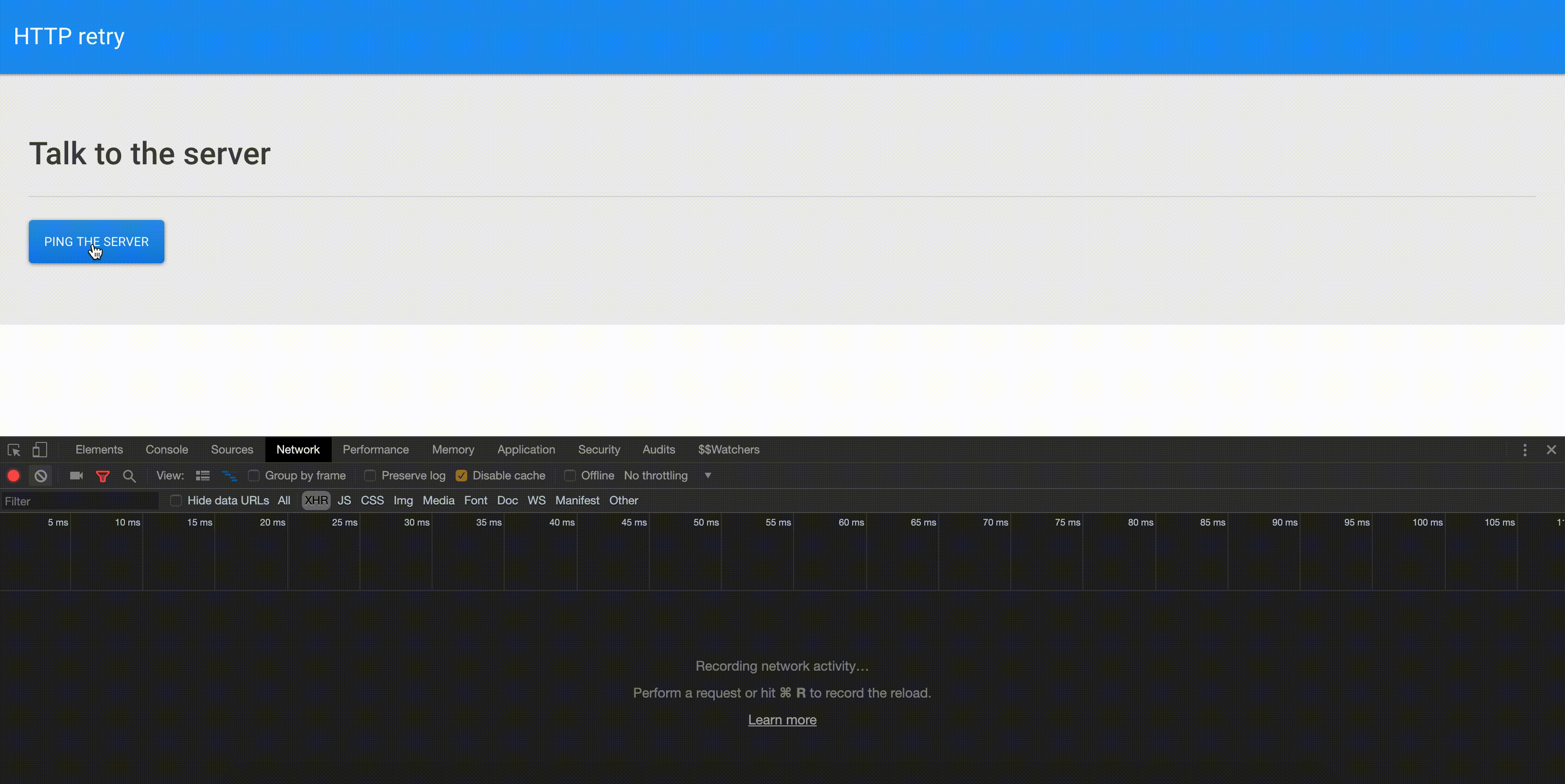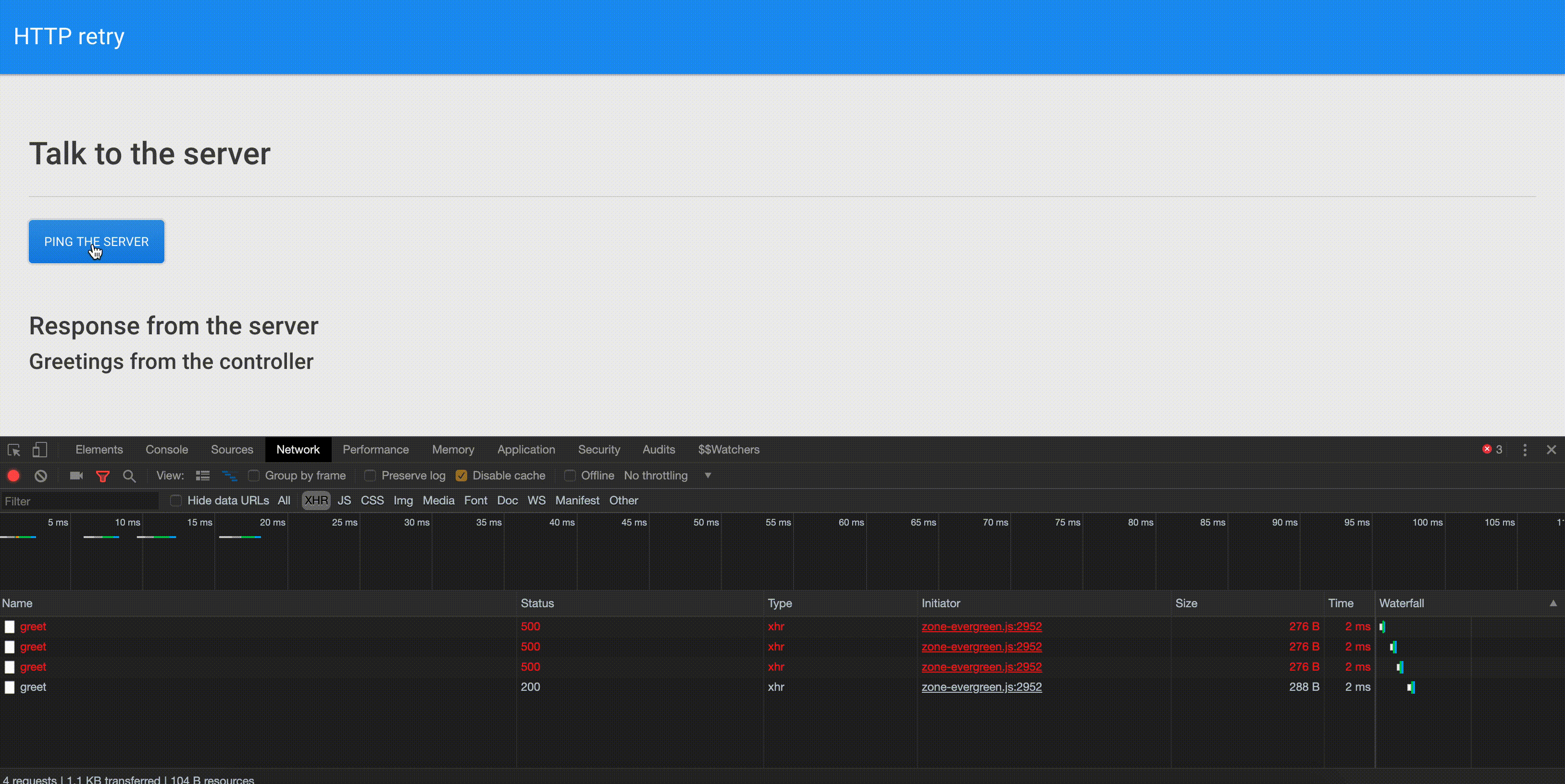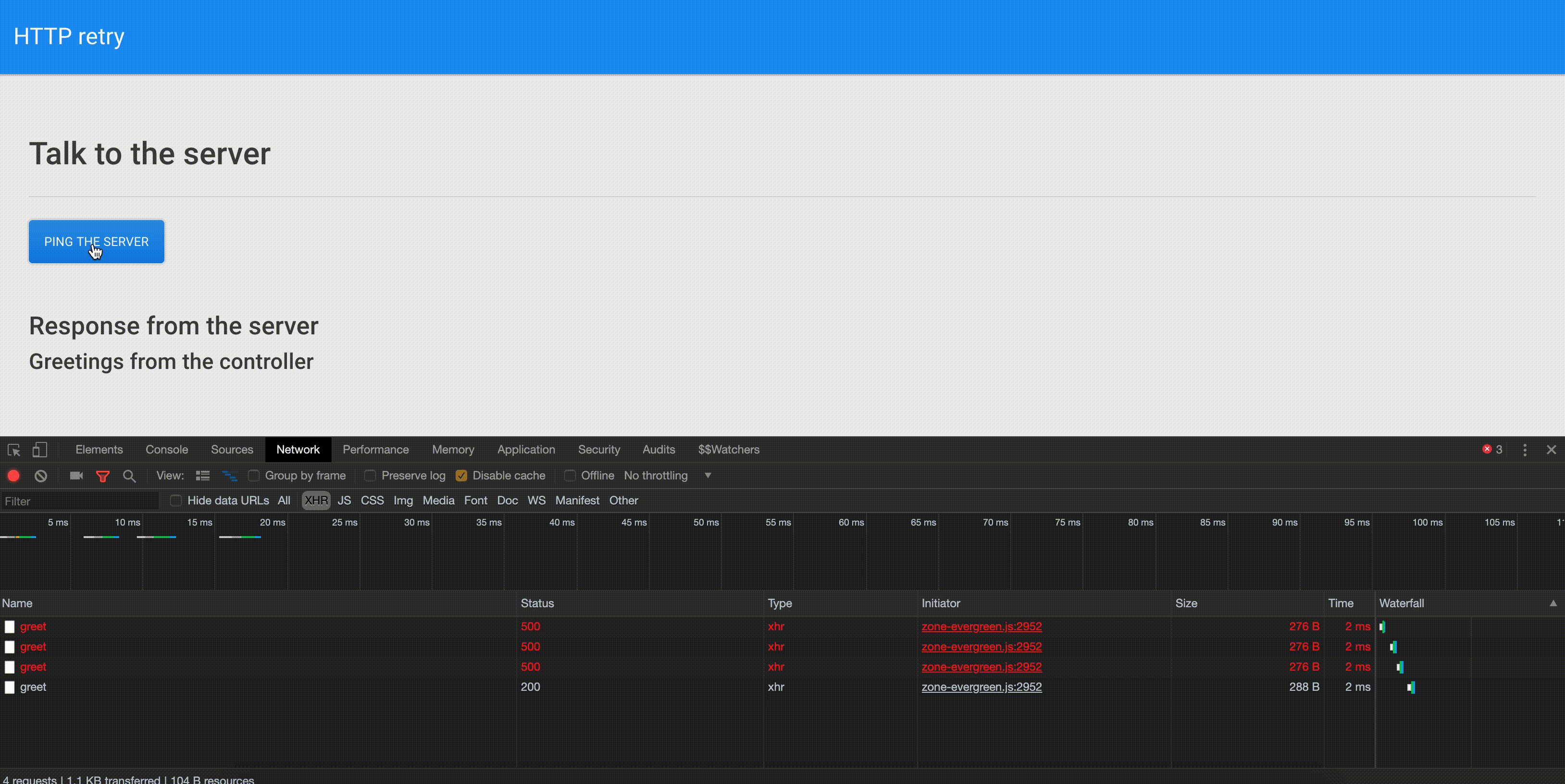
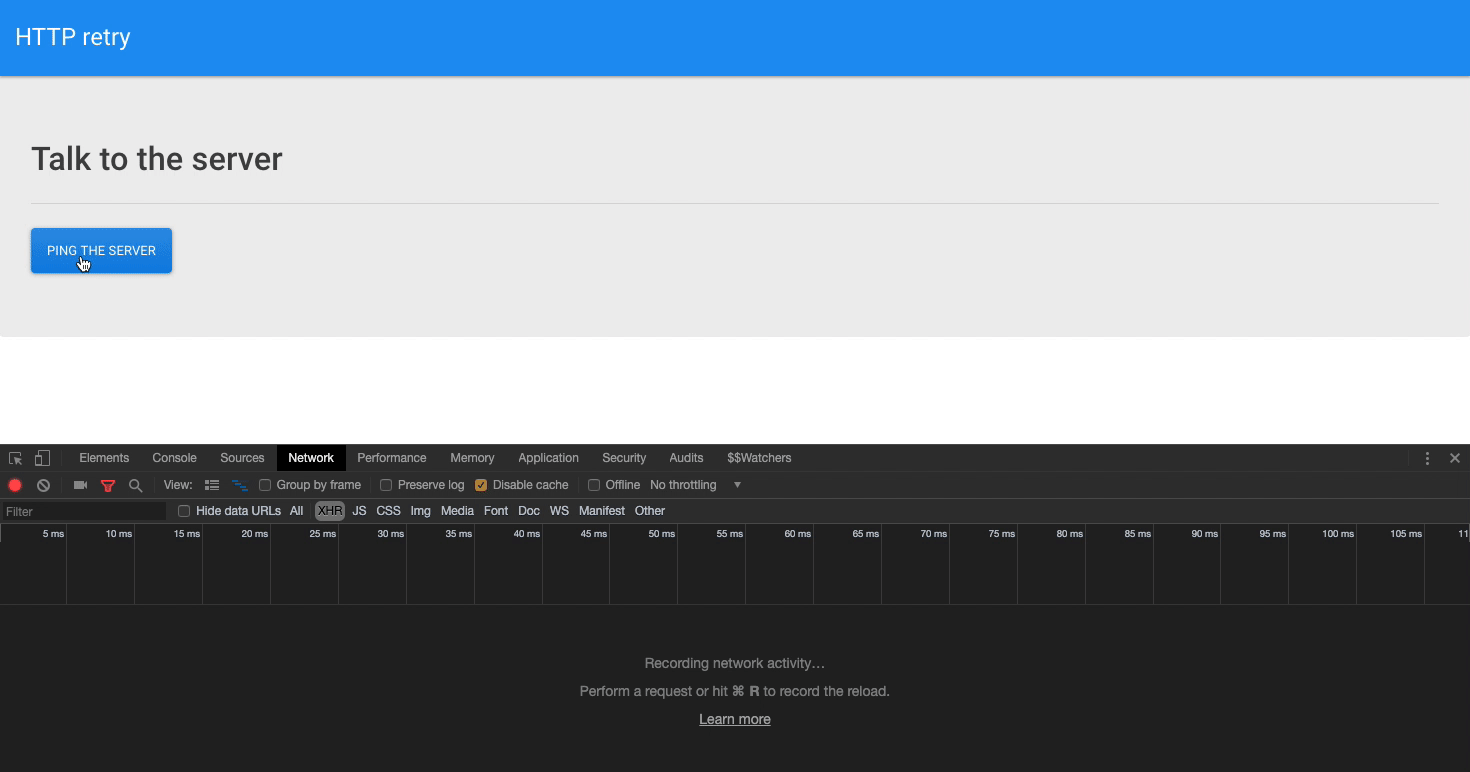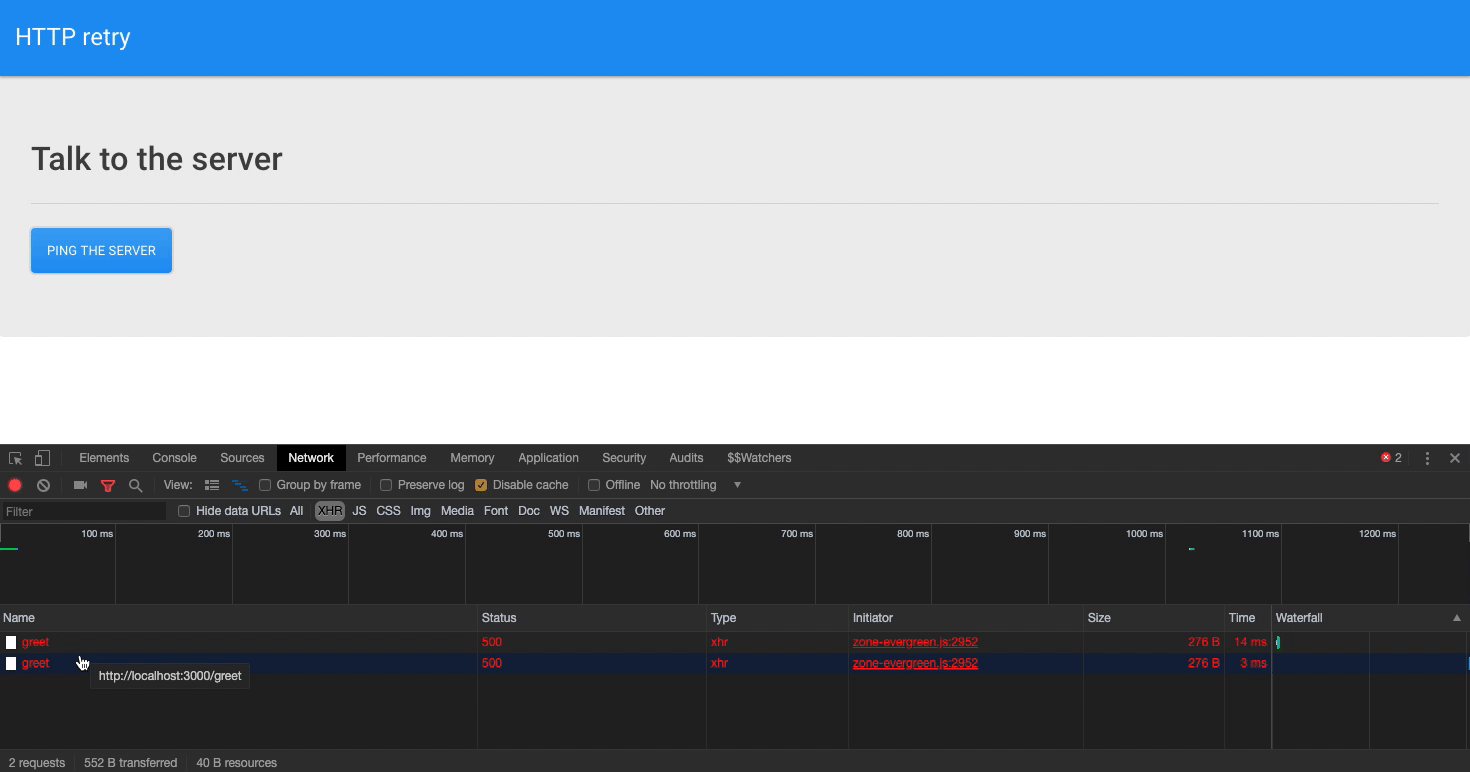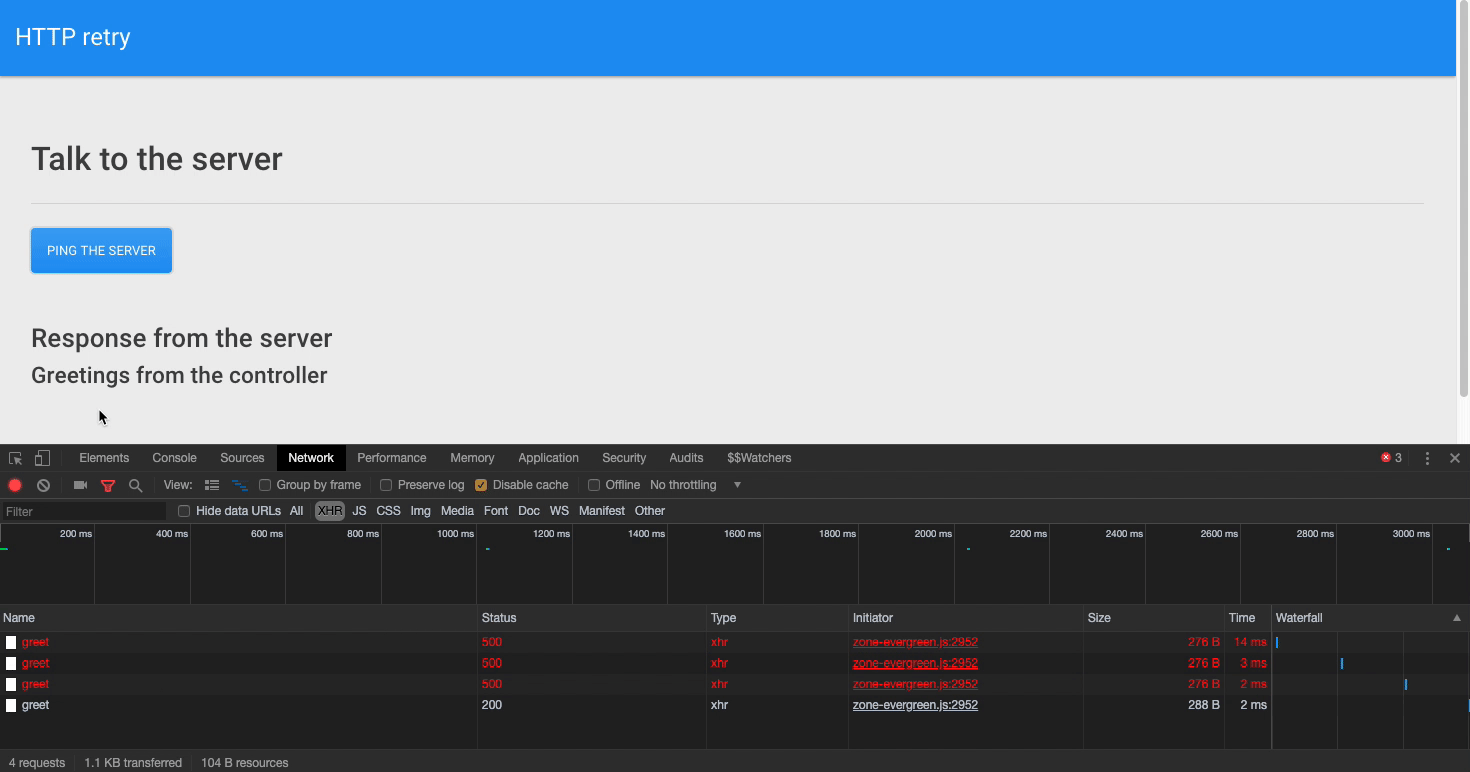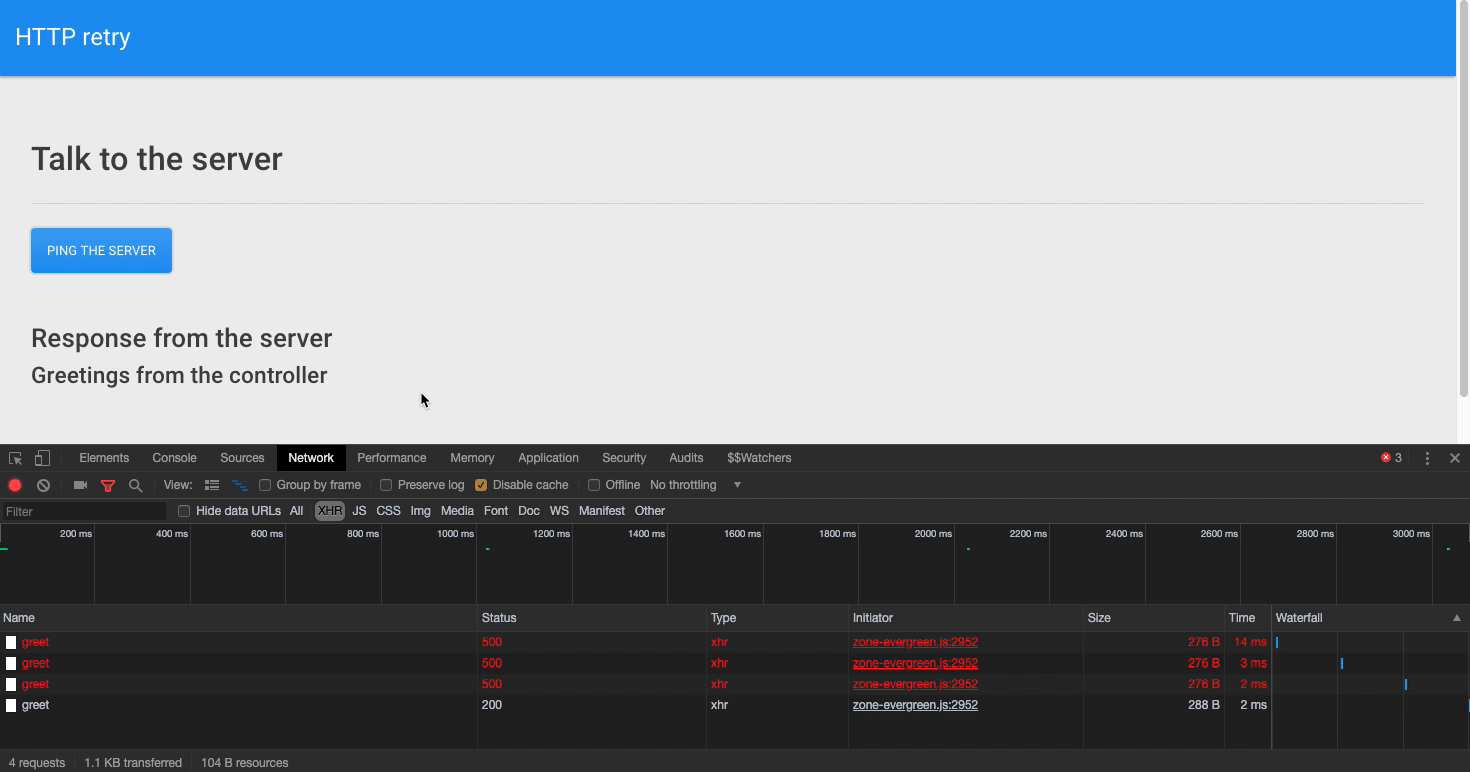
Как уже было сказано, бэкенд возвращает ошибку при выполнении первых трёх попыток выполнить к нему запрос, а при поступлении к нему четвёртого запроса возвращает обычный ответ.
На вкладке инструментов разработчика Network можно видеть, что оператор retry решает поставленную перед ним задачу и трижды повторяет выполнение неудавшегося запроса. Последняя попытка оказывается удачной, приложение получает ответ, на странице появляется соответствующее сообщение.
Всё это очень хорошо. Теперь приложение умеет повторять неудавшиеся запросы.
Однако этот пример ещё можно улучшать. Обратите внимание на то, что сейчас повторные запросы выполняются немедленно после выполнения запросов, которые оказываются неудачными. Такое поведение системы не принесёт особой пользы в нашей ситуации — тогда, когда поезд попадает в туннель и интернет-соединение на некоторое время теряется.
Отложенный повтор неудачных запросов
Поезд, который попал в туннель, не выезжает из него мгновенно. Он проводит там некоторое время. Поэтому нужно «растянуть» период, в течение которого мы выполняем повторные запросы к серверу. Сделать это можно, отложив выполнение повторных попыток.
Для этого нам нужно лучше контролировать процесс выполнения повторных запросов. Нам нужно, чтобы мы могли бы принимать решения о том, когда именно нужно выполнять повторные запросы. Это значит, что возможностей оператора retry нам уже недостаточно. Поэтому снова обратимся к документации по RxJS.
В документации имеется описание оператора retryWhen, который, как кажется, нас устроит. В документации он описан так: «Возвращает Observable, который воспроизводит исходный Observable за исключением error. Если исходный Observable вызывает error, то этот метод выдаст Throwable, который вызвал ошибку, Observable, возвращённому из notifier. Если этот Observable вызовет complete или error, тогда этот метод вызовет complete или error на дочерней подписке. В противном случае этот метод повторно подпишется на исходный Observable».
Да уж, определение не из простых. Давайте опишем то же самое более доступным языком.
Оператор retryWhen принимает коллбэк, который возвращает Observable. Возвращённый Observable принимает решение о том, как будет вести себя оператор retryWhen, основываясь на некоторых правилах. А именно, вот как ведёт себя оператор retryWhen:
- Он прекращает работу и выдаёт ошибку в том случае, если возвращённый Observable выдаёт ошибку.
- Он завершает работу в том случае, если возвращённый Observable сообщает о завершении работы.
- В других случаях, при успешном возврате Observable, он повторяет выполнение исходного Observable
Коллбэк вызывается лишь в том случае, когда исходный Observable выдаёт ошибку в первый раз.
Теперь мы можем воспользоваться этими знаниями для того чтобы создать механизм отложенного повтора неудачного запроса с помощью оператора RxJS retryWhen.
retryWhen((errors: Observable<any>) => errors.pipe(
delay(delayMs),
mergeMap(error => retries-- > 0 ? of(error) : throwError(getErrorMessage(maxEntry))
))
)
Если исходный Observable, который является нашим HTTP-запросом, вернёт ошибку, тогда вызывается оператор
retryWhen. В коллбэке у нас есть доступ к ошибке, которая вызвала неудачу. Мы откладываем errors, уменьшаем число повторных попыток и возвращаем новый Observable, который выдаёт ошибку.
Основываясь на правилах оператора retryWhen, этот Observable, так как он выдаёт значение, выполняет повтор запроса. Если повтор несколько раз оказывается неудачным и значение переменной retries уменьшается до 0, тогда мы завершаем работу с выдачей возникшей при выполнении запроса ошибки.
Замечательно! Видимо, мы можем взять код, приведённый выше и заменить им оператор retry, который имеется в нашей цепочке. Но тут мы немного притормозим.
Как быть с переменной retries? Это переменная содержит текущее состояние системы повтора неудачных запросов. Где она объявляется? Когда состояние сбрасывается? Состоянием нужно управлять внутри потока, а не вне его.
▍Создание собственного оператора delayedRetry
Мы можем решить проблему управления состоянием и улучшить читабельность кода, оформив вышеприведённый код в виде отдельного оператора RxJS.
Существуют разные способы создания собственных RxJS-операторов. То, каким именно методом воспользоваться, сильно зависит от того, как устроен тот или иной оператор.
Наш оператор построен на базе существующих операторов RxJS. В результате мы можем воспользоваться самым простым способом создания собственных операторов. В нашем случае RxJs-оператор — это всего лишь функция со следующей сигнатурой:
const customOperator = (src: Observable<A>) => Observable<B>
Этот оператор принимает исходный Observable и возвращает ещё один Observable.
Так как наш оператор позволяет пользователю указать то, как часто должны выполняться повторные запросы, и то, сколько раз их нужно выполнять, нам нужно обернуть вышеприведённое объявление функции в фабричную функцию, которая принимает в качестве параметров значения delayMs (задержка между повторами) и maxRetry (максимальное количество повторов).
const customOperator = (delayMs: number, maxRetry: number) => {
return (src: Observable<A>) => Observable<B>
}
Если вы хотите создать оператор, в основе которого не лежат существующие операторы, вам нужно обратить внимание на обработку ошибок и подписок. Более того, вам понадобится расширить класс
Observable и реализовать функцию lift.
Если вам это интересно — загляните сюда.
Итак, давайте, основываясь на вышеприведённых фрагментах кода, напишем собственный RxJs-оператор.
import {Observable, of, throwError} from 'rxjs';
import {delay, mergeMap, retryWhen} from 'rxjs/operators';
const getErrorMessage = (maxRetry: number) =>
`Tried to load Resource over XHR for ${maxRetry} times without success. Giving up`;
const DEFAULT_MAX_RETRIES = 5;
export function delayedRetry(delayMs: number, maxRetry = DEFAULT_MAX_RETRIES) {
let retries = maxRetry;
return (src: Observable<any>) =>
src.pipe(
retryWhen((errors: Observable<any>) => errors.pipe(
delay(delayMs),
mergeMap(error => retries-- > 0 ? of(error) : throwError(getErrorMessage(maxRetry))
))
)
);
}
Отлично. Теперь мы можем импортировать этот оператор в клиентский код. Воспользуемся им при выполнении HTTP-запроса.
return this.httpClient.get<string>(`${this.GREET_ENDPOINT}/greet`).pipe(
delayedRetry(1000, 3),
catchError(error => {
console.log(error);
// Выполняем обработку ошибок
return EMPTY;
}),
shareReplay()
);
Мы поместили оператор
delayedRetry в цепочку и передали ему, в качестве параметров, числа 1000 и 3. Первый параметр задаёт задержку в миллисекундах между попытками выполнения повторных запросов. Второй параметр определяет максимальное количество повторных запросов.
Перезапустим приложение и посмотрим на то, как работает новый оператор.
{kind=link}
Проанализировав поведение программы с помощью инструментов разработчика браузера, мы можем увидеть, что выполнение повторных попыток выполнения запроса откладывается на секунду. После получения правильного ответа на запрос в окне приложения появится соответствующее сообщение.
Экспоненциальное откладывание запроса
Давайте разовьём идею отложенного повтора неудачных запросов. Ранее мы всегда откладывали выполнение каждого из повторных запросов на одно и то же время.
Здесь же мы поговорим о том, как увеличивать задержку после каждой попытки. Первая попытка повтора запроса выполняется через секунду, вторая — через две секунды, третья — через три.
Создадим новый оператор, retryWithBackoff, который реализует это поведение.
import {Observable, of, throwError} from 'rxjs';
import {delay, mergeMap, retryWhen} from 'rxjs/operators';
const getErrorMessage = (maxRetry: number) =>
`Tried to load Resource over XHR for ${maxRetry} times without success. Giving up.`;
const DEFAULT_MAX_RETRIES = 5;
const DEFAULT_BACKOFF = 1000;
export function retryWithBackoff(delayMs: number, maxRetry = DEFAULT_MAX_RETRIES, backoffMs = DEFAULT_BACKOFF) {
let retries = maxRetry;
return (src: Observable<any>) =>
src.pipe(
retryWhen((errors: Observable<any>) => errors.pipe(
mergeMap(error => {
if (retries-- > 0) {
const backoffTime = delayMs + (maxRetry - retries) * backoffMs;
return of(error).pipe(delay(backoffTime));
}
return throwError(getErrorMessage(maxRetry));
}
))));
}
Если воспользоваться этим оператором в приложении и испытать его — можно увидеть, как задержка выполнения повторного запроса растёт после каждой новой попытки.
После каждой попытки мы определённое время выжидаем, повторяем запрос и увеличиваем время ожидания. Тут, как обычно, после того, как сервер вернёт правильный ответ на запрос, мы выводим сообщение в окне приложения.
Итоги
Повтор неудачных HTTP-запросов делает приложения стабильнее. Это особенно значимо при выполнении очень важных запросов, без данных, получаемых посредством которых, приложение не может нормально работать. Например, это могут быть конфигурационные данные, содержащие адреса серверов, с которыми нужно взаимодействовать приложению.
В большинстве сценариев оператора RxJs retry недостаточно для организации надёжной системы повтора неудачных запросов. Оператор retryWhen даёт разработчику более высокий уровень контроля над повторными запросами. Он позволяет настраивать интервал выполнения повторных запросов. Благодаря возможностям этого оператора можно реализовать схему отложенных повторов или повторов с экспоненциальным откладыванием.
При реализации в цепочках RxJS шаблонов поведения, которые подходят для повторного использования, рекомендуется оформлять их в виде новых операторов. Вот репозиторий, код из которого использовался в этом материале.
Уважаемые читатели! Как вы решаете задачу повтора неудачных HTTP-запросов?

Комментариев нет:
Отправить комментарий