
Современный веб практически немыслим без медиаконтента: смартфоны есть практически у каждой нашей бабушки, все сидят в соцсетях, и простои в обслуживании дорого обходятся компаниям. Вашему вниманию рассказ от компании Badoo, как она организовала отдачу фотографий с помощью аппаратного решения, с какими проблемами производительности столкнулась в процессе, чем они были вызваны, ну и как эти проблемы были решены с помощью софтового решения на основе Nginx, обеспечив при этом отказоустойчивость на всех уровнях. Благодарим авторов рассказа Олега Ефимова и Александра Дымова, которые поделились своим опытом на конференции Uptime day 4.
— Вначале небольшое введение про то, как мы фотографии храним и кэшируем. У нас есть слой, на котором мы фотографии храним, и слой, где мы фотографии кэшируем. При этом, если мы хотим добиваться большого хитрейта и мы хотим снижать нагрузку на стораджи – нам важно, чтобы каждая фотография какого-то отдельного пользователя лежала на одном кэширующем сервере. Иначе нам пришлось ставить во столько раз больше дисков, во сколько у нас больше серверов. Хитрейт у нас в районе 95%, то есть мы в 100 раз снижаем нагрузку на наши storage, и для того, чтобы это сделать, еще 10 лет назад, когда все это строилось, мы имели 50 серверов. Соответствено, для того, чтобы эти фотографии отдавать, нам нужно было по сути 50 внешних доменов, которые по сути эти серверы обслуживают. И сразу естественно встал вопрос: а если у нас один сервер упадет, будет недоступен, мы по сути теряем какую часть трафика? Мы посмотрели, что есть на рынке, и решили купить железку, чтобы она решила все наши проблемы. Выбор пал на решение компании FX-network (которая купила NGINX, Inc).
Что эта железка делает: по сути, это железный роутер, который делает железное redundancy своих внешних портов и позволяет роутить трафик, основываясь на топологии сети, на каких-то настройках, делает health-check’и. Нам было важно то, что эту железку можно программировать. Соответственно, мы могли описать логику, как фотографии какого-то определенного пользователя отдавались с какого-то конкретного кэша. Как это выглядит? Есть железка, которая смотрит в интернет по одному домену, одному ip, делает ssl offload, разбирает http-запросы, из IRule выбирает номер кэша, куда пойти, и пускает туда трафик. При этом она делает health-cheсk’и, и в случае недоступности какой-то машины мы сделали на тот момент так, что трафик пускается на один резервный сервер. С точки зрения конфигурирования есть, конечно, некоторые нюансы, но в целом все довольно просто: мы прописываем карту, соответствие какого-то числа нашему ip в сети, говорим, что слушать мы будем на 80-м, 443-м порту, говорим, что, если сервер недоступен, то нужно пускать трафик на резервный, в данном случае 35-й, и описываем кучу логики, как эту архитектуру надо разбирать. Единственная проблема была в том, что язык, которым программируется железка, это язык tcl. Если кто вообще такой помнит… язык этот больше write-only, чем язык, удобный для программирования.
Но тем не менее, что мы получили? Мы получили железку, которая обеспечивает высокую доступность нашей инфраструктуры, роутит весь наш трафик, обеспечивает health-cheсk’и и просто работает, причем работало довольно долго, за последние 10 лет к ней не было никаких нареканий. К началу 2018 года мы уже отдавали около 80k фотографий в секунду. Это где-то примерно 80 гигабит трафика с обоих наших дата-центров.
Однако…
В начале 2018 года мы на графиках увидели некрасивую картину: явное возрастание времени отдачи фотографий. Нас перестало устраивать. Проблема в том, что такое поведение было видно только в самый пик трафика — для нашей компании это ночь с воскресенья на понедельник. Но все остальное время система вела себя как обычно, никаких признаков поломки.

Тем не менее, проблему надо было решать. Мы определили возможные узкие места и начали их ликвидировать. Первое — это понятно, мы расширили uplinks внешние, мы провели полную ревизию внутренних uplinks, нашли все возможные узкие места и как-то там порешали, но очевидного результата всё это не дало, проблема не исчезла.
Возможным узким местом была производительность самих фото-кэшей, мы думали, что, возможно, начали упираться где-то в них. Что ж: расширили производительность, в основном, сетевые порты на фотокэшах, но опять же, никакого явного улучшения не видели. В конце концов, обратили пристальное внимание на производительность самого ltm-а и тут увидели на графиках печальную картину: загрузка всех cpu начинает идти плавно, но потом резко упирается в полку. При этом ltm перестает адекватно реагировать на health-check'и uplink'ом и начинает их случайным образом выключать. Что ведет к серьезной деградации производительности. То есть мы определили источник проблемы, определили узкое место, осталось решить, что же мы будем делать.
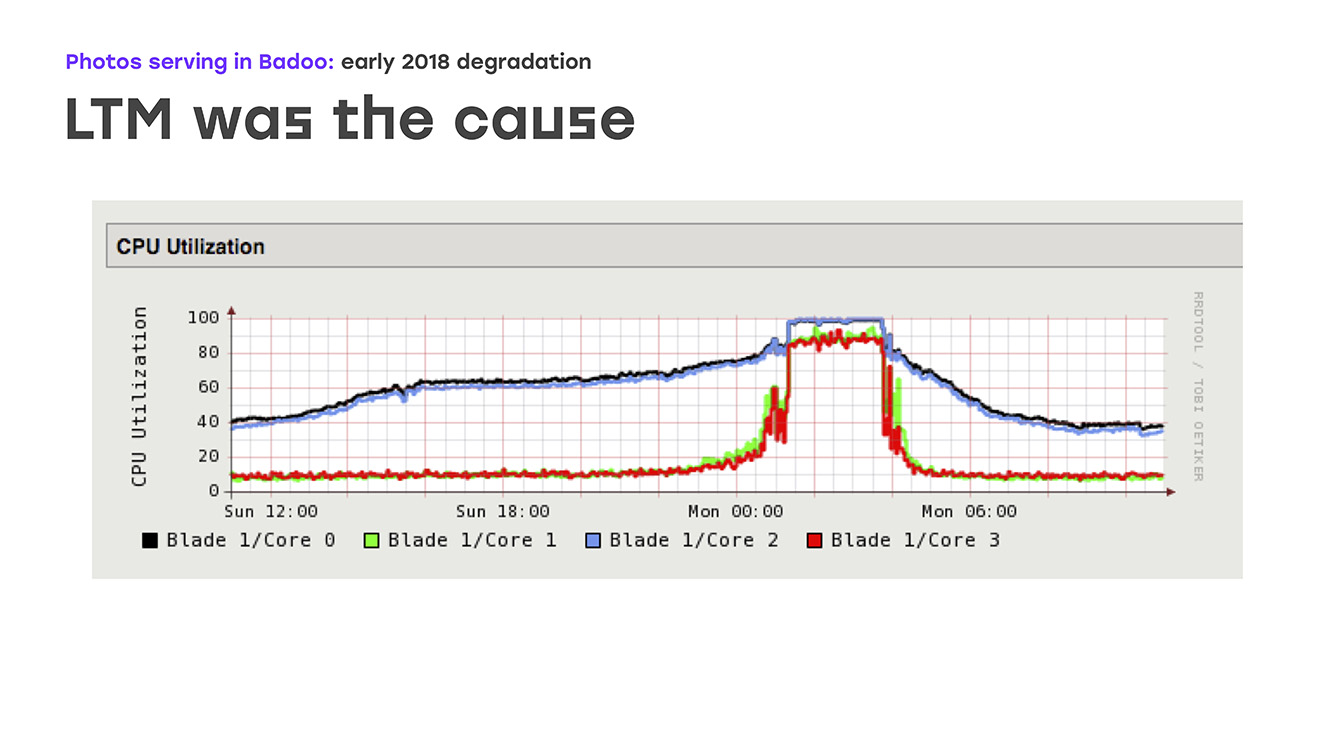
Первое, само напрашивающееся, что мы могли предпринять, — это как-то модернизировать сам ltm, но тут есть свои нюансы, потому что это железо достаточно уникальное, ты не пойдешь в ближайший супермаркет, не купишь. Это отдельный контракт, отдельный контракт на лицензию, и быстро это все не будет. Второй вариант — это начать думать самому, придумать свое решение, на своих компонентах, желательно с использованием программы с открытым доступом. Осталось только решить, что именно мы выберем для этого и сколько времени мы потратим на решение этой проблемы, ведь пользователи недополучали фотографий. Стало быть, надо делать все это очень-очень быстро, прям можно сказать — вчера.
Ну соответственно, так как задача сложилась «сделать что-то максимально быстро и используя то железо, которое у нас есть», первое, что мы подумали, — это просто снять с фронта какие-то машины не самые мощные, поставить туда Nginx, с которым мы умеем работать, и попробовать реализовать всю ту самую логику, которую раньше делала железка. То есть фактически мы оставляли нашу железку, ставили еще 4 сервера, которые должны были сконфигурировать, делали для них внешние домены по аналогии с тем, как это было 10 лет назад… То есть мы теряли немножко в доступности, в случае падения этих машин, но тем не менее, решали локально проблему наших пользователей. Соответственно, логика остается той же самой, мы ставим Nginx, он умеет делать SSL-offload, мы можем на конфигах как-то спрограммировать логику роутинга, health-check'и и просто продублировать ту логику, которая у нас была до этого.
Садимся писать конфиги. Сначала казалось, что все было очень просто, но, к сожалению, под каждую задачу найти мануалы очень сложно, поэтому не советуем просто гуглить — как сконфигурировать Nginx для фотографий, или для видео, или для чего-то еще, — а все-таки обратиться к официальной документации, которая покажет, какие настройки вообще стоит трогать. Но конкретный параметр лучше подбирать самим. Ну, дальше все просто: описываем серверы, которые у нас есть, описываем сертификаты… Но самое интересное — это, собственно, сама логика роутинга.
Поначалу нам казалось, что мы просто описываем наш локейшн, матчим в нем номер нашего фотокэша, руками там либо генератором описываем, сколько нам нужно апстримов, в каждом апстриме указываем сервер, на который должен идти трафик, и бэкапный сервер — в случае, если основной сервер недоступен. Но, наверное, если б все было б так просто, мы бы просто разошлись по домам и ничего не рассказывали. К сожалению, с дефолтными настройками Nginx, которые, в общем-то сделаны за долгие годы разработки и не совсем под этот кейс… конфиг выглядит так: в случае если у какого-то апстрим-сервера происходит ошибка запроса либо таймаут, Nginx всегда переключает трафик на следующий. При этом после первого фейла в течение 10 секунд сервер также будет выключен, причем и по ошибке, и по таймауту — это даже нельзя никак конфигурировать. То есть если мы уберем или сбросим в апстрим-директиве опцию таймаут, то все равно, хоть Nginx не будет обрабатывать этот запрос дальше и ответит какой-нибудь не очень хорошей ошибкой, — сервер будет выключаться.
Чтобы этого избежать, мы сделали две вещи:
а) запретили делать это Nginx'у руками — и к сожалению, единственный способ сделать это — просто задать настройки max fails.
б) вспомнили, что мы в других проектах используем модуль, который позволяет делать фоновые health-check'и — соответственно, мы сделали довольно частые health-check'и, чтобы простой в случае аварии у нас был минимальным.
К сожалению, это тоже не все, потому что буквально первые две недели работы этой схемы показали, что Cppcheck — тоже штука ненадежная: на апстрим-сервере может быть поднят не Nginx, или Nginx в дестейте, в этом случае ядро соединение будет принимать, health-check будет проходить, а работать соответственно не будет. Поэтому мы сразу же заменили это на health-check http'шный, сделали определенный, который если уж отдает 200, то все работает в этом скрипте. Можно делать дополнительную логику — например, в случае кэширующих серверов проверять, что правильно смонтирована файловая система.
И нас бы это устроило, за исключением того, что на данный момент схема полностью повторяла то, что делала железка, но мы-то хотели сделать лучше. Раньше у нас был один резервный сервер, и, наверное, это не очень хорошо, потому что если серверов у вас сто, то когда падает один-второй-третий, один резервный сервер вряд ли справится с нагрузкой. Поэтому мы решили резерв-линию распределить по всем серверам: сделали просто еще один отдельный апстрим, записали туда все наши сервера с определенными параметрами в соответствии с тем, какую они могут нагрузку обслуживать, добавили те же самые health-check'и, которые у нас были до этого. И, соответственно, так как внутри одного апстрима нельзя ходить в другой апстрим, нужно было сделать так, чтобы в случае фейла основного апстрима, в котором просто записывали правильный, нужный фотокэш, мы просто через RF Bay шли на fullback, откуда шли на резервный апрстрим.
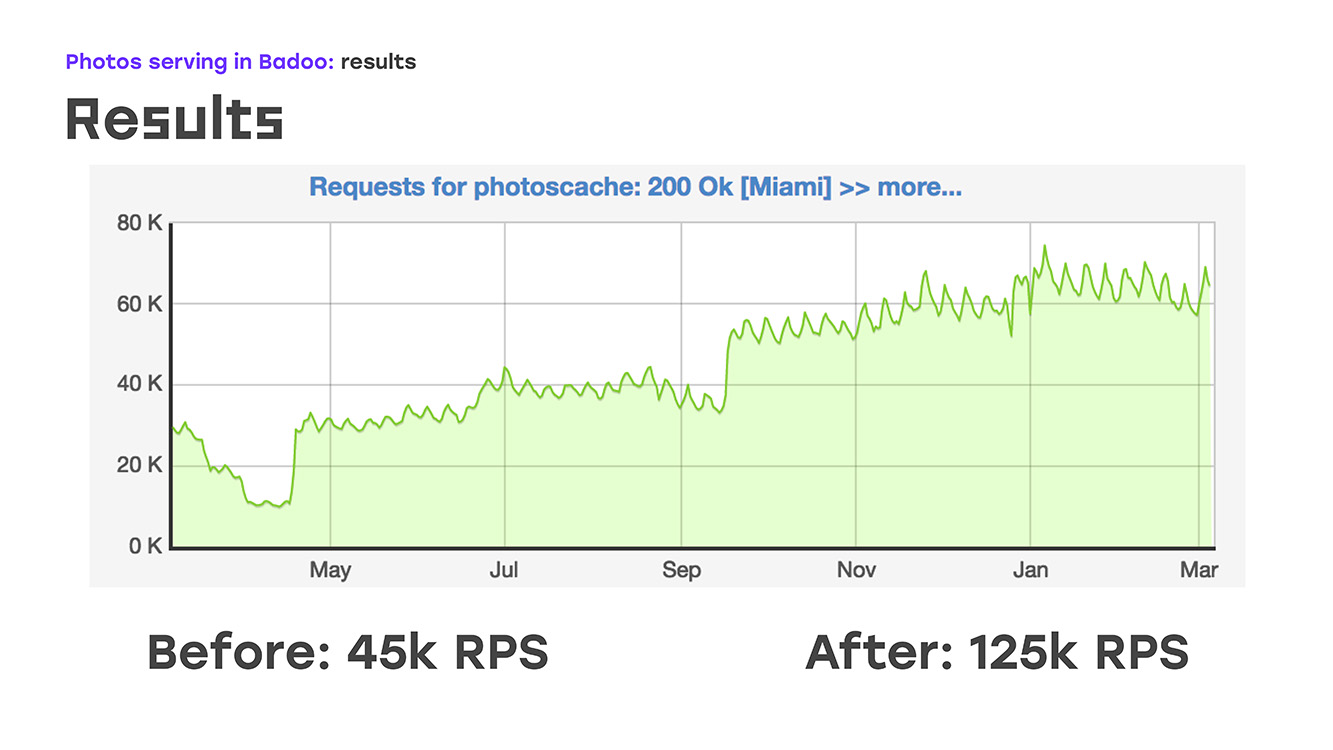
И буквально добавив четыре сервера, мы вот что получили: заменили часть нагрузки — сняли с ltm на эти сервера, реализовали там ту же логику, используя стандартное железо и софт, сразу же получили бонусом, что эти сервера можно масштабировать, потому что их можно просто поставить столько, сколько нужно. Ну и единственный минус — мы потеряли высокую доступность для внешних пользователей. Но на тот момент пришлось этим пожертвовать, потому что надо было решить проблему незамедлительно. Итак, часть нагрузки мы сняли, это около 40% на тот момент, ltm'у стало хорошо, а фотографии мы уже буквально через две недели после начала проблемы стали отдавать не 45k запросов в секунду, а 55k. По сути, мы выросли на 20% — это явно тот трафик, который мы недоотдавали пользователю. И после этого начали думать, как решить оставшуюся проблему — обеспечить высокую внешнюю доступность.
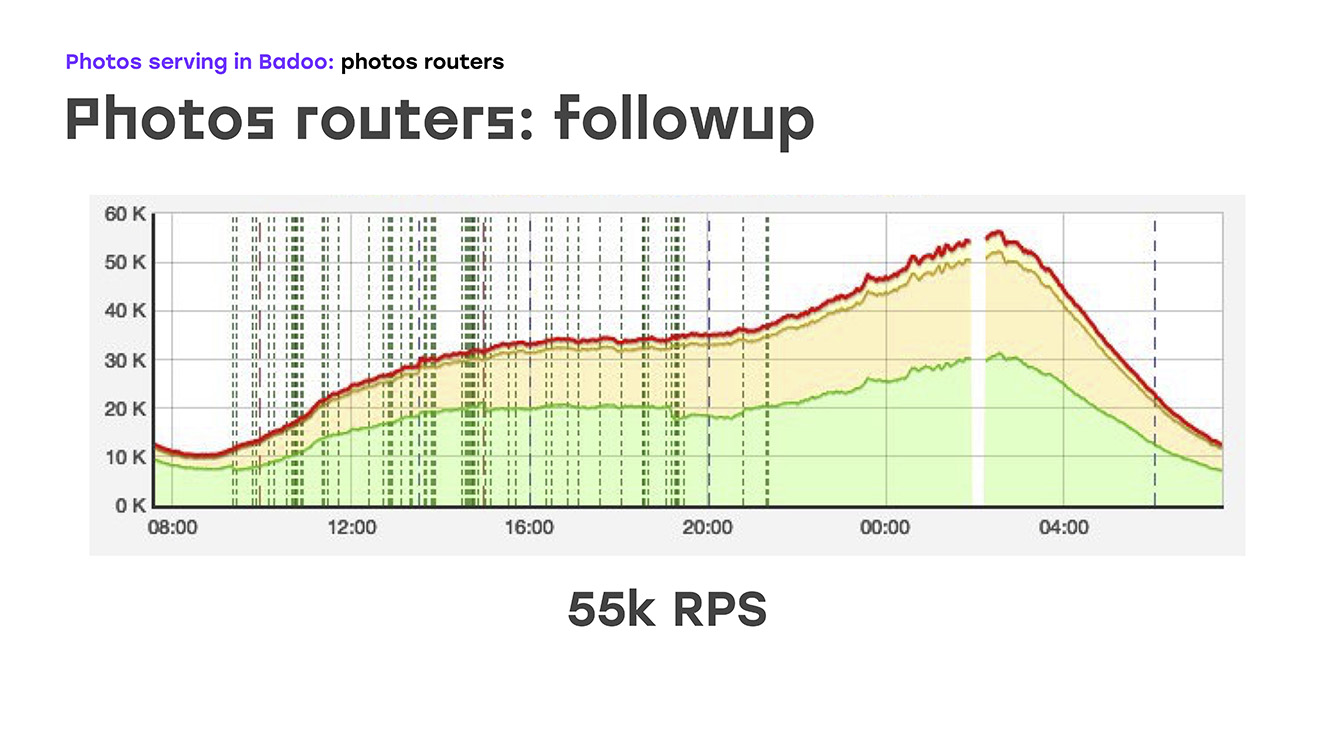
У нас была некоторая пауза, в которую мы обсуждали, какое решение мы будем для этого использовать. Были предложения обеспечивать надежность с помощью DNS, с помощью каких-то самописных скриптов, протоколов динамической маршрутизации… вариантов было много, но уже стало ясно, что для по-настоящему надежной отдачи фотографий нужно ввести еще один слой, который будет за этим следить. Мы назвали эти машины photo directors. В качестве программного обеспечения, на которое мы опирались, был выбрал Keepalived.
Для начала — из чего Keepalived состоит. Первое — это протокол VRRP, широко известный сетевикам, расположен на сетевом оборудовании, оьбеспечивающем отказоустойчивость внешнего IP-адреса, на который соединяются клиенты. Вторая часть это — IPVS, IP virtual server, для балансировки между фото-роутерами и обеспечения отказоустойчивости на этом уровне. И третье — health-check'и.
Начнем с первой части: VRRP — как это выглядит? Есть некий virtual ip, на который есть запись в dns badoocdn.com, куда подключаются клиенты. В какой-то момент времени у нас ip-адрес присутствует на каком-то одном сервере. Между серверами бегают по протоколу VRRP keepalived-пакеты, и в случае если мастер пропадает с радаров — сервер перезагрузился или еще что-нибудь, то бэкапный сервер автоматически поднимает этот ip адрес у себя — не надо делать никаких ручных действий. Отличаются мастер и бэкап, в основном priority: чем оно выше, тем больше шансов, что машина станет мастер. Очень большое достоинство, то что не надо конфигурировать ip-адреса на самом сервере, достаточно описать их в конфиге, и если при этом ip-адресам необходимы какие-то кастомные правила маршрутизации, это описывается прямо в конфиге, тем же синтаксисом, как это описывается в пакете VRRP. Никаких незнакомых вещей вам не встретится.
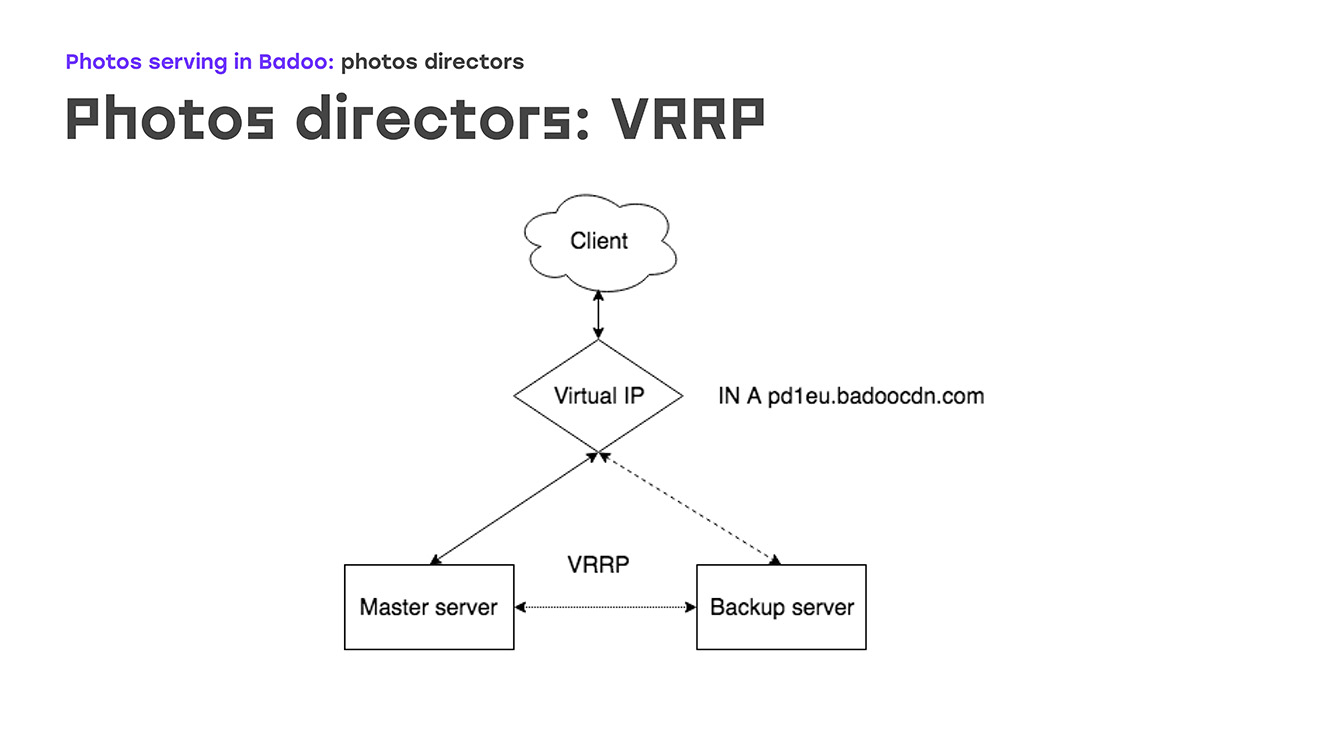
Как это выглядит на практике? Что происходит, если один из серверов уходит в отказ? Как только мастер пропадает, у нас бэкап прекращает получать адвертисменты и автоматически становится мастером. Через какое-то время мы починили мастер, перезагрузили, подняли Keepalived — приходят адвертисменты с бОльшим приоритетом, чем у бэкапа, и бэкап автоматически превращается обратно, снимает с себя ip-адреса, никаких ручных действий при этом делать не надо.

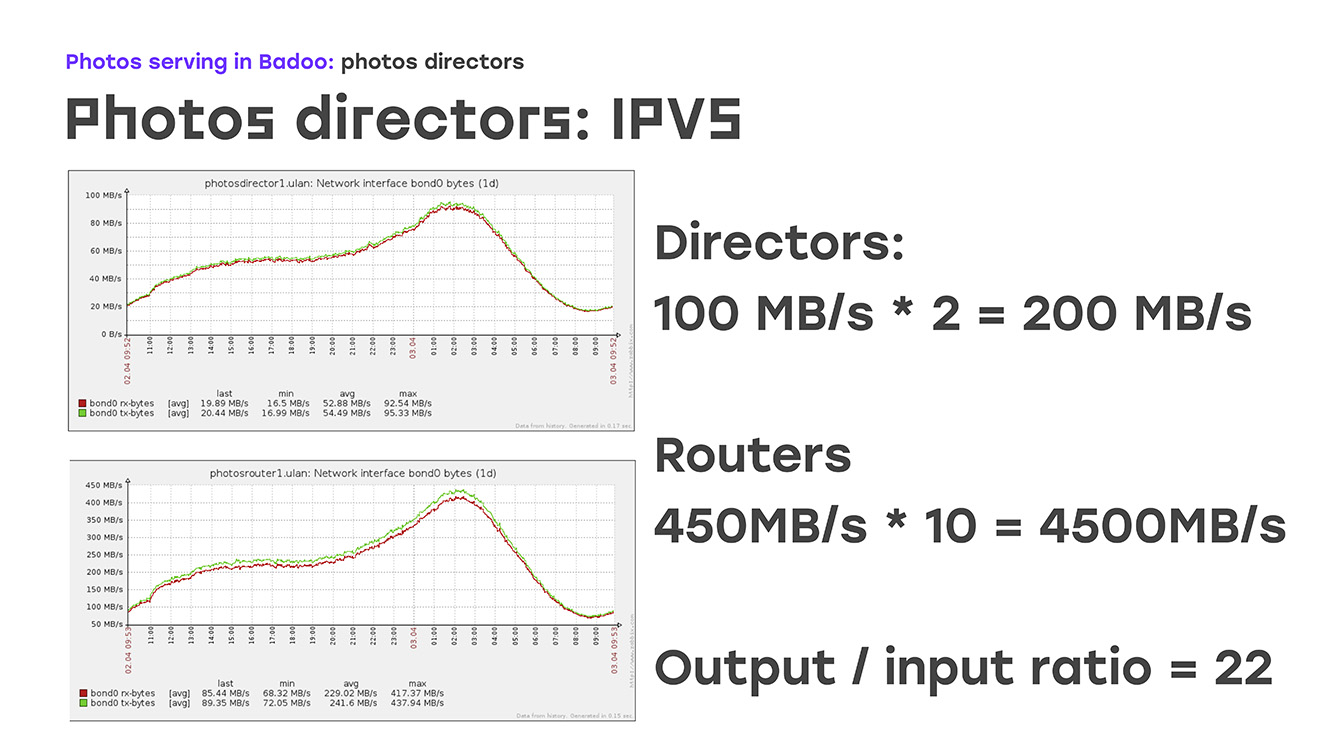
Таким образом, отказоустойчивость внешнего IP-адреса мы обеспечили. Следующая часть — это с внешнего ip-адреса как-то балансировать трафик на фото-роутеры, которые уже детерминируют его. С протоколами балансировки все достаточно ясно. Это либо простой round-robin, либо немножко более сложные вещи, wrr, list connection и так далее. Это в принципе описано в документации, ничего такого особого нет. А вот метод доставки… Тут остановимся поподробнее — почему выбрали один из них. Это NAT, Direct Routing и TUN. Дело в том, что мы сразу закладывались на отдачу 100 гигабит трафика с площадок. Это если прикинуть, нужно 10 гигабитных карточек, правильно? 10 гигабитных карточек в одном сервере — это уже выходит за рамки, по крайней мере, нашего понятия «стандартное оборудование». И тут мы вспомнили, что мы не просто отдаем какой-то трафик, мы отдаем фотографии.
В чем особенность? — Колоссальная разница между входящим и исходящим трафиком. Входящий трафик очень маленький, исходящий очень большой. Если посмотреть на эти графики, то видно, что в данный момент из директа поступает порядка 200 Мб в секунду, это самый обычный день. Отдаем же мы обратно 4,500 мб в секунду, соотношение у нас примерно 1/22. Уже понятно, что нам для полного обеспечения исходящего трафика на 22 сервера рабочих достаточно одного, который принимает это соединение. Тут нам на помощь приходит как раз алгоритм direct routing, алгоритм маршрутизации.
{kind=link}
Как это выглядит? Фото-директор у нас согласно своей таблице передает соединения на фото-роутеры. Но обратный трафик фото-роутеры отправляют уже напрямую в интернет, отправляют клиенту, он не проходит обратно через фото-директор, таким образом, минимальным количеством машин мы обеспечиваем полную отказоустойчивость и прокачку всего трафика. В конфигах это выглядит следующим образом: мы указываем алгоритм, в нашем случае это простой rr, обеспечиваем метод директ-роутинг и дальше начинаем перечислять все реальные сервера, сколько их у нас есть. Которые будут этот трафик детерминировать. В случае, если у нас там появляются еще один-два, несколько серверов, возникает такая необходимость — просто дописываем эту секцию в конфиге и особо не паримся. Со стороны реальных серверов, со стороны фото-роутера такой метод требует самого минимального конфигурирования, он прекрасно описан в документации, и подводных камней там нет.
Что особенно приятно — такое решение не подразумевает кардинальной переделки локальной сети, для нас это было важно, нам надо было решить это минимальными затратами. Если посмотреть на вывод команды IPVS admin, то мы увидим, как это выглядит. Вот у нас есть некий виртуальный сервер, на 443 порту, слушает, принимает соединение, идет перечисление всех рабочих серверов, и видно, что connection — он, плюс-минус, одинаковый. Если мы посмотрим статистику, на том же виртуальном сервере, — у нас есть входящие пакеты, входящие соединения, но абсолютно отсутствуют исходящие. Исходящие соединения идут напрямую клиенту. Хорошо, разбалансировать мы смогли. Теперь, что будет, если у нас один из фото-роутеров уходит в отказ? Ведь железо есть железо. Может уйти в kernel panic, может сломаться, может сгореть блок питания. Что угодно. Для этого и нужны health-check'и. Они могут быть как самыми простыми — проверка на то, как порт у нас открыт, — так и какая-то более сложными, вплоть до каких-то самописных скриптов, которые будут даже бизнес-логику будут проверять.
{kind=link}
Мы остановились где-то посередине: у нас идет https-запрос на определенный location, вызывается скрипт, если он отвечает 200-м ответом, мы считаем, что с этим сервером все нормально, что он живой и его совершенно спокойно можно включать.
Как это, опять же, выглядит на практике. Выключили сервер допустим на обслуживание — перепрошивка BIOS, например. В логах у нас тут же происходит таймаут, видим первая строчка, потом после трех попыток помечается как «зафейлен», и он удаляется просто из списка.

Возможен еще второй вариант поведения, когда просто VS выставляется в ноль, но в случае отдачи фотографии это работает плохо. Сервер поднимается, запускается там Nginx, тут же health-check'и понимают, что коннект проходит, что все отлично, и сервер появляется у нас в списке, и на него тут же автоматически начинает подаваться нагрузка. Никаких при этом ручных действий от дежурного админа не требуется. Ночью сервер перезагрузился — отдел мониторинга нам по этому поводу ночью не звонит. В известность ставят, что такое было, все нормально.
Итак, достаточно простым способ, с помощью небольшого количества сервером мы проблему внешней отказоустойчивости решили.
Осталось сказать, что все это, конечно же, нужно мониторить. Отдельно нужно отметить, что Keepalivede, как очень давно написанный софт, имеет кучу способов его замониторить, как с помощью проверок через DBus, SMTP, SNMP, так и стандартным zabbix'ом. Плюс, он сам по себе умеет писать письма практически на каждый чих, и честно говоря, мы в какой-то момент думали даже выключить, потому что пишет он очень много писем на любое переключение трафика, включения, на каждый ip-шник и так далее. Конечно, если серверов много, то можно этими письмами себя завалить. Стандартными способами мониторим nginx на фото-роутерах, и никуда не делся мониторинг железа. Мы бы, конечно, советовали еще две вещи: это во-первых, внешние health-check'и доступности, потому что даже если все работает, на самом деле, возможно, пользователи фотографии не получают из-за проблем с внешними провайдерами или чего-то более сложного. Всегда стоит держать где-нибудь в другой сети, в amazon или еще где-то, отдельную машину, которая сможет снаружи пинговать ваши сервера, и также стоит использовать либо normal detection, для тех, кто умеет в хитрый machine learning, либо простой мониторинг, хотя бы для того, чтобы отслеживать, если реквесты резко упали, либо наоборот, выросли. Тоже бывает полезно.
Подведем итоги: мы, по сути, заменили железное решение, которое в какой-то момент перестало нас устраивать, довольно простой системой, которая делает все тоже самое, то есть обеспечивает детерминирование трафика и дальнейший умный роутинг с нужными health-check'ами. Мы увеличили стабильность этой системы, то есть на каждый слой у нас все также высокая доступность, плюс мы бонусом получили то, что на каждом слое довольно просто все это масштабировать, потому что это стандартное железо со стандартным софтом, то есть тем самым мы упростили себе диагностику возможных проблем.
Что мы в итоге получили? Проблема у нас была в январские праздники 2018-го. За первые полгода пока мы вводили эту схему в строй, расширяли уже на весь трафик, чтобы весь трафик снять с ltm, мы выросли только по трафику в одном дата-центре с 40 гигабит до 60 гигабит, и при этом за весь 2018-й год смогли отдавать практически в три раза больше фотографий в секунду.
Комментариев нет:
Отправить комментарий