Перед тем как начать реализацию новой фичи, приходится изрядно поломать голову.
Разработка сложного функционала требует тонкой координации усилий коллектива инженеров. И одним из важнейших моментов является вопрос распараллеливания задач.
Возможно ли избавить фронтовиков от необходимости ждать реализацию бэка? Есть ли способ распараллелить разработку отдельных фрагментов UI?
Тему распараллеливания задач в веб-разработке мы и рассмотрим в этой статье.
Проблема
Итак, давайте для начала обозначим проблему. Представьте, что у вас есть матерый продукт (интернет сервис), в котором собрано довольно много разных микросервисов. Каждый микросервис в вашей системе — это своего рода мини-приложение интегрированное в общую архитектуру и решающее какую-то конкретную проблему пользователя сервиса. Представьте, что сегодня утром (в последний день спринта) к вам обратился Product Owner по имени Василий и обявил: "В следующем спринте мы начинаем пилить Импорт Данных, который сделает пользователей сервиса еще счастливее. Он позволит пользователю в сервис залить сразу стопиццот дофигаллиардов позиций из дремучей 1С!".
Представьте что вы менеджер или тимлид и слушаете все эти восторженные описания счастливых пользователей не с позиции бизнеса. Вы оцениваете сколько трудозатрат все это потребует. Как хороший менеджер вы прикладываете все усилия, чтобы уменьшить аппетиты Василия на скоуп задач для MVP (здесь и далее, Minimum Viable Product). При этом два главных требования для MVP — способность системы импорта выдержать большую нагрузку и работа в фоне, выкинуть нельзя.
Вы понимаете, что традиционным подходом, когда все данные обрабатываются в пределах одного запроса пользователя, обойтись не удастся. Тут придется городить огород всяких фоновых воркеров. Придется завязываться на Event Bus, думать о том как работает балансировщик нагрузки, распределенная БД и т.п. В общем все прелести микросервисной архитектуры. В итоге вы делаете вывод, что разработка бэкенда под эту фичу затянется, в гадалки не ходи.
Автоматом встает вопрос: "A что будут делать фронтовики все это время пока нет никакого API?".
Кроме того, выясняется, что данные-то надо импортировать не сразу. Нужно сначала провалидировать их и дать пользователю поправить все найденные ошибки. Получается хитрый воркфлоу и на фронтенде тоже. А запилить фичу надо, как водится, "вчера". Стало быть и фронтовиков надо как-то так скоординировать, чтобы они не толкались в одной репе, не порождали конфликтов и спокойно пилили каждый свой кусок (см. КДПВ в начале статьи).
В иной ситуации мы могли бы начать пилить с бэка к фронту. Сначала реализовать бэкенд и проверить, что он держит нагрузку, а потом спокойно навешивать на него фронтэнд. Но загвоздка в том, что спеки описывают новую фичу в общих чертах, имеют пробелы и спорные моменты с точки зрения юзабилити. А что, если в конце реализации фронта выяснится, что в таком виде фича не удовлетворит пользователя? Изменения юзабилити могут потребовать изменений в модели данных. Придется переделывать и фронт и бэк, что будет очень дорого.
Agile пытается нам помочь
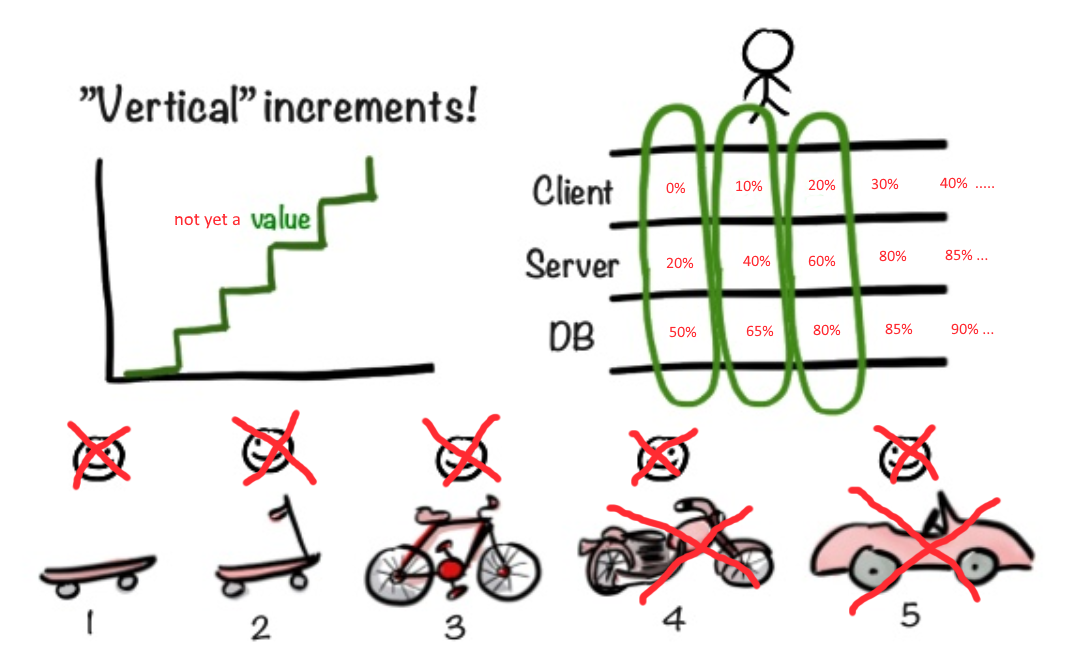
Гибкие методологии дают мудрый совет. "Начните со скейта и покажите пользователю. Вдруг ему понравится. Если понравилось, продолжайте в том же духе, прикручивайте новые фишки."
Но что, если пользователю сразу нужен как минимум мотоцикл, причем уже через две-три недели? Что если для начала работы над фасадом мотоцикла нужно хотя бы определиться с габаритами мотора и размерами ходовой части?
Как сделать так, чтобы реализация фасада не откладывалась до тех пор, пока не появится определенность с остальными слоями приложения?
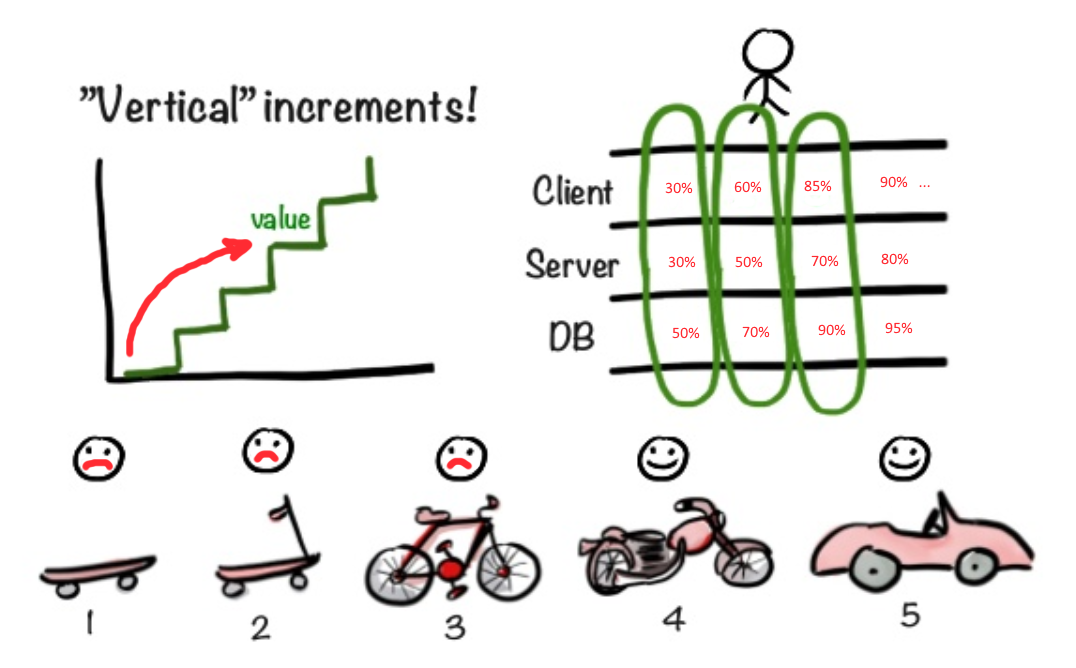
В нашей ситуации лучше применить другой подход. Лучше сразу начать делать фасад (фронт), чтобы убедиться в корректности изначального представления об MVP. С одной стороны, подсунуть Product Owner'у Василию декоративный фасад, за которым ничего нет, кажется читерством, надувательством. С другой стороны, мы очень быстро получаем таким образом фидбек именно о той части функционала, c которой в первую очередь столкнется пользователь. У вас может быть неимоверно крутая архитектура, но если удобства использования нет, то какульками забросают все приложение целиком, не разбираясь в деталях. Поэтому мне кажется более важным выдать максимально функциональный UI как можно быстре, вместо того, чтобы синхронизировать прогресс фронтовой части с бэкендом. Нет смысла выдавать на пробу недоделанный UI и бэк, функционал которых не удовлетворяет главным требованиям. В то же время выдача 80% требуемого функционала UI, но без работающего бэка, вполне может оказаться профитной.
Немного технических деталей
Итак, я уже описывал вкратце какую фичу мы собираемся реализовать. Добавим немного технических деталей.
Пользователь должен иметь возможность выгрузить в сервис файл данных большого объема. Содержимое этого файла должно соответствовать определенному формату (например, CSV). В файле должна быть определенная структура данных и есть обязательные поля, которые не должны быть пустыми. Иными словам, после выгрузки в бэкенде нужно будет данные провалидировать. Валидация может длиться значительное время. Держать коннект к бэкенду открытым нельзя (отвалится по таймауту). Поэтому мы должны быстро принять файл и запустить фоновую обработку. По окончанию валидации мы должны оповестить пользователя, что он может приступить к редактированию данных. Пользователь должен исправить ошибки, обнаруженные при валидации.
После того, как все ошибки исправлены, пользователь нажимает кнопку импорта. Исправленные данные отправляются обратно в бэкенд. для завершения процедуры импорта. О ходе всех стадий импорта мы должны оповещать фронтенд.
Самый эффективный способ оповещения — WebSocket'ы. С фронта через Websocket с определенным периодом будут отправляться запросы на получения текущего статуса фоновоой обработки данных. Для фоновой обработки данных нам понадобятся фоновые обработчики, распределенная очередь команд, Event Bus и т.д.
Dataflow видется следующим (для справки):
- Через файловый API браузера просим пользователя выбрать нужный файл с диска.
- Через AJAX отправляем файл в бэкенд.
- Ожидаем окончания валидации и распарсивания файла с данными (опрашиваем статус фоновой операции через Websocket).
- По окончании валидации грузим подготовленные к импорту данные и рендерим их в таблице на странице импорта.
- Пользователь редактирует данные, исправляет ошибки. По нажатию на кнопку внизу страницы отправляем исправленные данные в бэкенд.
- Опять на клиентской стороне запускаем периодический опрос статуса фоновой операции.
- До окончания текущего импорта у пользователя не должно быть возможности запустить новый импорт (даже в соседнем окне браузера или на соседнем компьютере).
План разработки
Мокап UI vs. Прототип UI

Давайте сразу обозначим разницу между Wireframe, Mockup, Prototype.
На рисунке выше изображен Wireframe. Это просто рисунок (в цифре или на бумаге — не суть важно). С другими двумя понятиями сложнее.
Мокап — это такая форма представления будущего интерфейса, которая используется только в качестве презентации и в последствии будет заменена полностью. Эта форма в будущем будет отложена в архив как образец. Реальный интерфейс будет делаться с помощью других инструментов. Мокап можно сделать в векторном редакторе с достаточной детализацией дизайна, но потом фронтенд-разработчики просто отложат его в сторону и будут подглядывать на него как образец. Мокап может быть сделан даже в специализированных браузерных конструкторах и снабжен ограниченной интерактивностью. Но судьба его неизменна. Он станет образцом в альбоме Design Guide.
Прототип же создается с помощью тех же инструментов, что и будущий интерфейс пользователя (например, React). Код прототипа размещается в общем репозитарии приложения. Он не будет заменен, как это происходит с мокапом. Сначало его используют для проверки концепции (Proof of Concept, PoC). Потом, если он пройдет проверку, его начнут развивать, постепенно превращая в полноценный интерфейс пользователя.
Теперь ближе к делу...
Представим, что коллеги из цеха дизайна представили нам артефакты своего творческого процесса: mockup'ы будущего интерфейса. Наша задача спланировать работу так, чтобы как можно скорее сделать параллельную работу фронтовиков возможной.
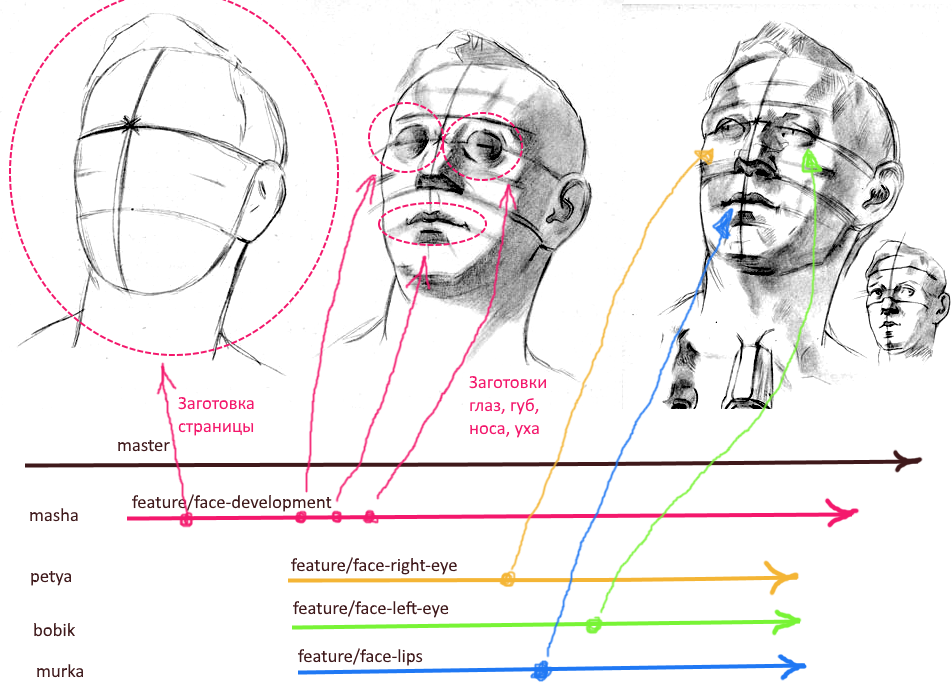
Как составление алгоритма начинается с блок-схемы, так и создание прототипа начинаем с минималистичного Wireframe'а (см. рисунок выше). На этом Wireframe мы делим будущий функционал на крупные блоки. Главный принцип тут — фокусировка ответственности. Не следует разделять один кусок функциональности на разные блоки. Мухи идут в один блок, а котлеты в другой.
Далее нужно как можно быстрее создать заготовку страницы (пустышку), настроить Routing и разместить в меню ссылку на эту страницу. Затем нужно создать заготовки базовых компонентов (по одному на каждый блок в Wireframe прототипа). И закаммитать этот своеобразный фреймворк в ветку разработки новой фичи.
Получаем такую иерархию веток в git:
master ---------------------- >
└ feature/import-dev ------ >
Ветка "import-dev" будет играть роль development бранча для всей фичи. У этой ветки желательно закрепить одного ответственного человека (мэйнтейнера), который мержит атомарные изменения от всех параллельно работающих над фичей коллег. Также желательно не делать прямых каммитов в эту ветку, чтобы уменьшить шанс конфликтов и неожиданных изменений при мерже в эту ветку атомарных пулл реквестов.
Т.к. у нас на этот момент уже созданы компоненты для основных блоков на странице, то можно уже сразу создавать отдельные ветки под каждый блок UI. Финальная иерархия может выглядеть так:
master ----------------------- >
└ feature/import-dev ------- >
├ feature/import-head ---- >
├ feature/import-filter -- >
├ feature/import-table --- >
├ feature/import-pager --- >
└ feature/import-footer -- >
Примечание: неважно в какой момент создать эти атомарные бранчи и конвенция наименования, представленная выше, не единственная годная. Бранч можно создать непосредственно перед началом работы. А имена бранчей должны быть понятны всем участникам разработки. Имя должно быть как можно короче и при этом явно указывать на то, за какую часть функционала ветка отвечает.
Подходом, описанным выше, мы обеспечиваем безконфликтную работу нескольких разработчиков UI. У каждого фрагмента UI свой каталог в иерархии проекта. В каталоге фрагмента есть основной компонент, его набор стилей и свой набор дочерних компонентов. Также у каждого фрагмента может быть свой менеджер состояния (MobX, Redux, VueX сторы). Возможно, компоненты фрагмента используют какие-то глобальные стили. Однако изменять глобальные стили при разработке фрагмента новой страницы запрещено. Изменять дефолтное поведение и стиль общего атома дизайна также не стоит.
Примечание: под "атомом дизайна" подразумевается элемент из набора стандартных компонентов нашего сервиса — см. Atomic Design; в нашем случае предполагается, что система Атомарного Дизайна уже реализована.
Итак, мы физически отделили фронтовиков друг от друга. Теперь каждый из них может работать спокойно, не боясь конфликтов при мерже. Также каждый может в любой момент создать пулл реквест из своей ветки в feature/import-dev. Уже сейчас можно спокойно набрасывать статичесий контент и даже формировать интерактив в пределах одного хранилища состояния.
Но как нам обеспечить возможность взаимодействия фрагментов UI между собой?
Нам необходимо реализовать связующее звено между фрагментами. На роль связки между фрагментами подходит JS сервис, выполняющий роль шлюза для обмена данными с бэком. Через этот же сервис можно реализовать нотификацию о событиях. Подписываясь на одни события, фрагменты неявно будут включены общий жизненный цикл микросервиса. Изменения данных в одном фрагменте приведут к необходимости обновить состояние другого фрагмента. Иными словами, мы сделали интеграцию фрагменто посредством данных и событийной модели.
Для создания этого сервиса нам понадобится еще одна ветка в git:
master --------------------------- >
└ feature/import-dev ----------- >
├ feature/import-js-service -- >
├ feature/import-head -------- >
├ feature/import-filter ------ >
├ feature/import-table ------- >
├ feature/import-pager ------- >
└ feature/import-footer ------ >
Примечание: не пугайтесь количества веток и не стесняйтесь плодить ветки. Git позволяет эффективно работать с большим количеством ветвлений. Когда вырабатывается привычка, ветвиться становится легко:
$/> git checkout -b feature/import-service
$/> git commit .
$/> git push origin HEAD
$/> git checkout feature/import-dev
$/> git merge feature/import-service
Кому-то это покажется напряжным, но профит минимизации конфликтов весомее. К тому же пока вы эксклюзивный владелец ветки, можете без опасений делать push -f без риска повредить чью-то локальную историю каммитов.
Фэйковые данные
Итак, на предыдущем этапе мы сделали заготовку интеграционного JS-сервиса (importService), сделали заготовки фрагментов UI. Но без данных наш прототип работать не будет. Ничего не рисуется кроме статических декораций.
Теперь нам надо определиться с примерной моделью данных и создать эти данные в виде JSON или JS файлов (выбор в пользу того или другого зависит от настройки импортов в вашем проекте; настроен ли json-loader). Наш importService, а также его тесты (о них будем думать попозже) импортируют из этих файлов данные, необходимые для имитации ответов от реального бэкенда (он пока еще не реализован). Куда положить эти данные не суть важно. Главное, чтобы их можно было легко импортировать в сам importService и тесты в нашем микросервисе.
Формат данных, конвенцию именования полей желательно обговорить с разработчиками бэка сразу. Можно, например, договориться об использовании формата, соответствующего спецификации OpenAPI Specification. Какой бы спецификации формата данных ни следовал бэк, фэйковые данные мы создаем в точном соответствии формату данных в бэке.
Примечание: не бойтесь ошибиться с моделью фэйковых данных; ваша задача сделать драфтовую версию контракта данных, который потом все равно будет согласоваться с разработчиками бэкенда.
Контракты
Фэйковые данные могут служить хорошим заделом для начала работы над спецификацией будущего API в бэке. И тут неважно кто и насколько качественно реализует драфт модели. Решающее значение играет совместное обсуждение и согласование с участием разработчиков фронта и бэка.
Для описания контрактов (спецификации API) можно использовать специализированные инструменты. Напр., OpenAPI / Swagger. По-хорошему, при описании API с таким инструментом нет нужды в присутствии всех разработчиков. Этим может заниматься один разработчик (редактор спецификации). Результатом коллективного обсуждения нового API должны были стать некие артефакты вроде MFU (Meeting Follow Up), по которым редактор спецификации и конструирует справочник для будущего API.
По окончании создания драфта спецификации не должно потребоваться много времени, чтобы проверить корректность. Каждый участник коллективного обсуждения сможет независимо от других сделать беглый осмотр для проверки, что его мнение было учтено. Если что-то покажется некорректным, то можно будет уточнить через редактора спецификации (обычные рабочие коммуникации). Если все удовлетворены спецификацией, то ее можно опубликовать и использовать как документацию на сервис.
Юнит-Тестирование
Примечание: Лично для меня ценность юнит-тестов довольная низка. Тут я согласен с Дэвидом Хансоном (David Heinemeier Hansson @ RailsConf). "Юнит-тесты — это отличный способ убедиться, что ваша программа ожидаемым образом делает д… мо." Но я допускаю особые кейсы, когда юнит-тесты приносят много пользы.
Теперь, когда мы определились с фэйковыми данными, можно приступать к тестированию базового функционала. Для тестирования фронтовых компонентов можно использовать такие инструменты как karma, jest, mocha, chai, jasmine. Обычно рядом с тестируемым ресурсом JS кладется одноименный файл с постфиксом "spec" или "test":
importService
├ importService.js
└ importService.test.js
Конкретное значение постфикса зависит от настроек сборщика пакетов JS в вашем проекте.
Конечно, в ситуации, когда бэк находится в "противозачаточном" состоянии, очень трудно покрыть юнит-тестами все возможные кейсы. Но и предназначение у юнит-тестов немного другое. Они призваны протестировать работу отдельных кусочков логики.
К примеру, хорошо покрывать юнит-тестами разного рода хэлперы (helper), через которые между JS компонентами и сервисами расшариваются куски логики или неких алгоритмов. Также этими тестами можно покрыть поведение в компонентах и сторах MobX, Redux, VueX в ответ на изменение данных пользователем.
Интеграционное и E2E-тестирование
Под интеграционными тестами подразумеваются проверки поведения системы на соответствие спецификации. Т.е. проверяется, что пользователь увидит именно то поведение, которое описано в спеках. Это более высокий уровень тестирования в сравнении с юнит-тестами.
Например, тест, проверяющий появление ошибки под обязательным полем, когда пользователь стёр весь текст. Или тест, проверяющий, что генерируется ошибка при попытке сохранить невалидные данные.
E2E-тесты (End-to-End) работают на ещё более высоком уровне. Они проверяют, что поведение UI корректно. Например, проверка, что после отправки файла с данными в сервис, пользователю показывается крутилка, сигнализирующая о длящемся асинхронном процессе. Или проверка, что визуализация стандартных компонентов сервиса соответствует гайдам от дизайнеров.
Этот вид тестов работает при помощи некоторого фреймворка автоматизации UI. Например, это может быть Selenium. Такие тесты вместе с Selenium WebDriver запускаются в некотором браузере (обычно Chrome с "headless mode"). Работают они долго, но снижают нагрузку на специалистов QA, делая за них смоук тест.
Написание этих видов тестов довольно трудоемко. Чем раньше мы начнем их писать, тем лучше. Не смотря на то, что унас нет еще полноценного бэка, мы уже можем начинать описывать интеграционные тесты. У нас уже есть спецификация.
С описанием E2E тестов препятствий еще меньше. Мы уже набросали стандартные компоненты из библиотеки атомов дизайна. Реализовали специфичные куски UI. Сделали некоторый интерактив поверх фэйковых данных и API в importService. Ничто не мешает начать автоматизацию UI как минимум для базовых кейсов.
Написанием этих тестов можно опять же озадачить отдельных разработчиков, если имеются не озадаченные люди. И также для описания тестов можно завести отдельную ветку (как описано выше). В ветки для тестов нужно будет периодически мержить обновления из ветки "feature/import-dev".
Общая последовательность мержей будет такой:
- Например, девелопер из ветки "feature/import-filter" создал ПР. Этот ПР проревьюили и мэйнтейнер ветки "feature/import-dev" вливает этот ПР.
- Мэйнтейнер обявляет, что влито обновление.
- Девелопер в ветке "feature/import-tests-e2e" затягивает крайние изменения мержем из "-dev ветки.
CI и автоматизация тестирования
Фронтовые тесты реализуются с помощью инструментов, работающих через CLI. В package.json прописываются команды для запуска разных видов тестов. Эти команды используются не только девелоперами в локальной среде. Они нужны еще и для запуска тестов в среде CI (Continuous Integration).
Если сейчас мы запустим билд в CI и ошибок не обнаружится, то в тестовую среду будет доставлен наш долгожданный прототип (80% функционала на фронте при не реализованном еще бэке). Мы сможем показать Василию приблизительное поведение будущего микросервиса. Васлилий попинает этот прототип и, возможно, сделает кое-какие замечания (возможно даже серьезные). На данном этапе вносить коррективы не дорого. В нашем случае бэк требует серьезных архитектурных изменений, поэтому работа по нему может идти медленнее, чем по фронту. Пока бэк не финализирован, внесение изменений в план его разработки не приведет к катастрофическим последствиям. При необходимости что-то поменять на этом этапе мы попросим внести коррективы в спецификацию API (в сваггере). После этого повторяются шаги, описанные выше. Фронтовики по-прежнему не зависят от бэкендеров. Отдельные специалисты фронтенда не зависят друг от друга.
Бэкенда. Контроллеры-заглушки
Отправной точкой разработки API в бэке является утвержденная спецификация API (OpenAPI / Swagger). При наличии спецификации работу в бэке также станет легче распараллеливать. Анализ спецификации должен навести разработчиков на мысль об основных элементах архитектуры. Какие общие компоненты / сервисы нужно создать, прежде чем приступать к реализации отдельных вызовов API. И тут опять же можно применить подход как с заготовками для UI.
Мы можем начать сверху, т.е. с наружнего слоя нашего бэка (с контроллеров). На этой стадии мы начинаем с роутинга, заготовок контроллеров и фэйковых данных. Слой сервисов (BL) и доступа к данным (DAL) мы пока не делаем. Просто переносим данные из JS в бэкенд и программируем контроллеры так, чтобы они реализовывали ожидаемые ответы для базовых кейсов, выдавая куски из фэйковых данных.
По завершению этой стадии фронтовики должны получить работающий бэкенд на статичных тестовых данных. Причем именно тех данных, на которых фронтовики пишут интеграционные тесты. По идее, в этот момент не должно составить большого труда переключить JS шлюз (importService) на использование заготовок контроллеров в бэке.
Ответная часть для запросов через Websocket концептуально не отличается от Web API контроллеров. Эту "ответку" также делаем на тестовых данных и подключаем importService к этой заготовке.
В конечном итоге весь JS должен быть переведен на работу с реальным сервером.
Бэкенд. Финализация контроллеров. Заглушки в DAO
Теперь настает очередь финализировать внешний слой бэка. Для контроллеров один за одним реализуются сервисы в BL. Теперь сервисы будут работать с фэйковыми данными. Добавкой на данном этапе является то, что в сервисах мы уже реализуем реальную бизнес-логику. На этой стадии желательно начать добавление новых тестов в соответствии с бизнес-логикой из спецификаций. Тут важно, чтобы не упал ни один интеграционный тест.
Примечание: мы по-прежнему не зависим от того, реализована ли схема данных в БД.
Бэкенд. Финализация DAO. Реальная БД
После того, как схема данных реализована в БД, мы можем перенести в нее тестовые данные из предыдущих этапов и переключить наш зачаточный DAL на работу с реальным сервером БД. Т.к. мы в БД переносим изначальные данные, создававшиеся для фронта, все тесты должны остаться актуальными. Если какой-то из тестов упадет, значит что-то пошло не так и нужно разбираться.
Примечание: вообще с очень большой вероятностью работы со схемой данных в БД для новой фичи будет немного; возможно изменения в БД будут сделаны одновременно с реализацией сервисов в BL.
По окончанию этой стадии мы получаем полноценный микросервис, альфа-версию. Эту версию уже можно показать внутренним пользователям (Product Owner'у, продуктологу или еще кому-то) для оценки как MVP.
Дальше уже пойдут стандартные итерации Agile по работе над исправлением багов, реализацией дополнительных фишек и финальной полировкой.
Заключение
Думаю не стоит использовать вышеописанное вслепую как руководство к действию. Сначала нужно примерить и адаптировать к своему проекту. Выше описан подход способный отвязать отдельных разработчиков друг от друга и позволить им работать в параллели при определенных условиях. Все телодвижения с бранчеванием и переносом данных, реализация заготовок на фэйковых данных кажутся значительным оверхэдом. Профит в этих накладных расходах появляется за счет увеличения параллелизма. Если в команде разработки состоят полтора землекопа два фуллстэка или один фротовик с одним бэкендером, то профита от такого подхода, наверное, будет неочень много. Хотя и в этой ситуации некоторые моменты вполне могут повысить эффективность разработки.
Профит этого подхода появляется тогда, когда мы в самом начале быстро реализуем заготовки, максимально приближенные к будущей реальной реализации и физически разделяем работы над разными частями на уровне структуры файлов в проекте и на уровне системы управления кодом (git).
Надеюсь, что вы нашли данную статью полезной.
Спасибо за внимание!
Комментариев нет:
Отправить комментарий