
О продуктовой аналитике на Хабре пишут не так часто, но публикации, причем хорошие, появляются с завидной регулярностью. Большинство статей о продуктовой аналитике появились за последние пару лет, и это логично — ведь продуктовая разработка становится все более важной как для IT, так и для бизнеса, лишь косвенно связанного с информационными технологиями.
Здесь же, на Хабре, была опубликована статья, в которой неплохо описаны ожидания компании от продуктового аналитика. Такой специалист должен, во-первых, искать и находить перспективные точки роста продукта, во-вторых, идентифицировать и подтверждать актуальность проблемы путем ее формулировки и масштабирования. Точнее не скажешь. Но продуктовая аналитика развивается, появляются новые инструменты для работы и тренды, которые помогают работать продуктовым аналитикам. Как раз о трендах, в привязке к работе мобильных приложений и сервисов мы и поговорим в этой статье.
Настраиваемый сбор данных
Сейчас данные, которые дают возможность компании улучшить свою работу, внедрив персонализированный подход в обслуживании клиентов, собираются всеми — от интернет-компаний вроде Google до ритейлеров типа Walmart.
Это информация не только о клиентах, но и о погодных условиях, которые могут повлиять на работу компании, размер среднего чека, предпочтения покупателей, динамике покупок определенных товаров, загруженности точек продаж и т.п. Но проблема в том, что данных становится все больше, а бизнесу очень сложно отделить существенную информацию от несущественной.

Можно собрать петабайты данных, а потом выяснится, что компании для улучшения своей работы нужна лишь малая толика собранной информации. Все остальное — «белый шум», который никак не помогает двигаться вперед. Поиск нужных данных все больше начинает походить на поиск иголки в стоге сена. Только стог размером с айсберг, а иголка — тонкая и очень маленькая.
Любому типу бизнеса нужен инструмент, который позволяет уточнить ключевые требования к собираемым данным. Сбор данных должен настраиваться там, где ожидаются проблемы, поскольку «где тонко, там и рвется». Соответственно, такой инструмент должен выявлять самые актуальные и важные критерии и проводить поиск именно с их помощью.
Ограничение собираемых данных дает возможность снизить затраты на сбор, хранение и обработку информации. Текущие методы работы зачастую приводят к тому, что большая часть данных просто годами «пылится» на жестких дисках.
В качестве важного тренда представляется внедрение “умных” систем сбора данных — трекеров, к которым прокинута обратная связь от результатов “грубой” аналитики. Такой coarse grained подход, по своей логике похожий на гибридные QM/MM системы в молекулярном моделировании больших белков или на фрактальные алгоритмы сжатия картинок: крупная, грубая картина пользовательского пути анализируется быстрым пайплайном и находятся ребра (переходы между событиями) с самым большим потенциалом анализа, такие ребра разбиваются трекером на более мелкие события и сбор данных в итоге постоянно адаптируется под требуемую точностью анализа и конечную задачу аналитики.
Этот же подход с накинутой обратной связью на сбор и хранение данных может быть использован для “самоочищающихся данных”, когда мы принципиально не храним лишнего, используем быстрые компактные базы для грубых данных (Greenplum DB, Clickhouse) и большие медленные для детальных (Apache Kafka), кроме того мы перестаем хранить общие для всех данные, сводя поведенческие сегменты пользователей и отдельно сохраняя их модели предпочтений.
Ускорение обратной связи и предиктивная аналитика
Самое время поговорить об обратной связи более принципиального рода — сама аналитика является обратной связью, регулирующей то, как компания работает со своими клиентами.
Для нормальной работы любой компании, у которой есть мобильное приложение или сервис, нужна обратная связь, которая позволяет выявлять проблемы и решать их путем поиска гипотез о возможных решениях и запуска тестов.
Временную задержку обратной связи нужно сократить до минимума. Есть два способа сделать это.
Использовать предиктивные метрики вместо исторических. В этом случае ускорить обратную связь, значит не дожидаться, пока клиент, пользователь, придет или не придет к определенной цели, чтобы начать корректировать ситуацию. Метод позволяет предсказать, опираясь на модели, построенные по историческим данным, с какой вероятностью конкретный клиент достигнет каких экранов и кнопок приложения, или внешних целей — выкупов товара, звонков в отдел продаж и т.д. Зачем это компании? Чтобы иметь возможность повлиять на судьбу конкретного клиента или подобных ему новых клиентов как можно быстрее. Второе особенно важно для быстрого перераспределения бюджетов рекламных каналов — если какой-то канал вдруг изменил тип поставляемых клиентов, можно его бюджет изменить, не дожидаясь конечных действий — заказов или наоборот отписок, отказов.
Добиться ускорения зачастую можно просто заменив реальные метрики на то, что может быть предсказано. Еще один положительный момент — модель калибруется на всех данных, так что, если использовать текущую информацию, полученную только что, есть возможность улучшить предсказание. Такая модель будет постоянно обновляться, а залежи данных для формирования исторических метрик будут просто не нужны.
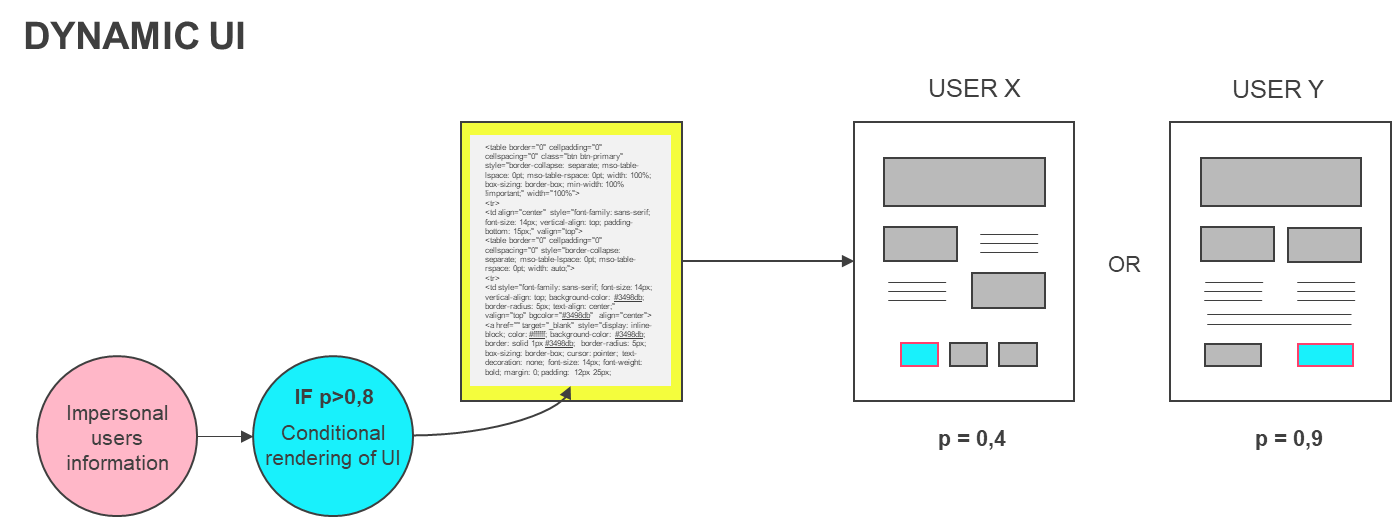
В качестве примера можно представить ситуацию, когда мы создаем динамический интерфейс сервиса или приложения. И различные элементы интерфейса, предположим, кнопки, появляются в зависимости от того, что известно о пользователе.
Еще один пример — работа голосового ассистента и приобретение билетов на самолет. У существующих цифровых помощников нужно много чего улучшить, в первую очередь — персонализацию. Так, если попробовать заказать билет при помощи Siri, она покажет обширную выборку доступных вариантов. Но здесь нужна персонализация, чтобы в итоге ассистент показал 2-3 подходящих варианта, не более. И предиктивная аналитика — один из способов добиться желаемого, так как можно продолжить намерения клиента, не заставляя его зачитывать (в этом случае важно не путать этот метод с ML для распознавания речи, обсуждаемая предиктивная аналитика будет работать поверх событий из уже распознанных в текст слов клиента).
Ускорение процессов тестирования на сегментах. Результаты продуктового анализа компании обычно тестируют на всей аудитории компании или сервиса. Но гораздо эффективнее проводить тесты на отдельных сегментах, именно тех, где наблюдалась проблема.
Кстати, есть интересный метод, который можно назвать «однорукий бандит против A/B тестов». Почему «однорукий бандит»? В любом казино есть эти игровые автоматы, причем все эти автоматы настроены по-разному в одном и том же заведении. Не всегда, но чаще всего. Представим, что мы хотим выявить «бандита», который выдает выигрыш чаще других. Для этого начинаем тестировать все автоматы. Но там, где выигрыш чуть больше — мы будем выделять для игры больше монеток. Достоинство этой схемы в том, что отдельные сегменты тестирования можно запускать параллельно, а удачные результаты экстраполируются на все остальные сегменты, получается непрерывная оптимизация вместо тестирования с контролем.
Метод «однорукого бандита» на практике можно использовать при тестировании мобильного приложения. Так, разным сегментам пользователей демонстрируются разные интерфейсы/экраны, также оставляется и контрольный сегмент, что дает возможность reinforcement learning роботу и аналитику, наблюдающему за ним, оценить взаимодействие пользователей из разных сегментов с различными экранами. Как только ситуация проясняется, успешная находка формулируется как доработка ко всему приложению, либо проводится персонализация, разделяющая функционал приложения для разных сегментов. Модели пользователей и модели взаимодействия пользователей с приложениями могут быть разными. Используя абстрактные эмбединги (screen2vec по аналогии с word2vec), модель можно строить на одном приложении, а применять, пусть и с ограничениями, на втором. Это делает возможным перенос аналитических инсайтов между разными версиями, платформами, релизами и даже партнерскими приложениями. Конечно, необходимо контролировать применимость чужих моделей, чтобы не выстрелить себе в ногу.
Автоматизация обратной связи
Для того, чтобы маргинально сократить время цикла обратной связи, можно попытаться разработать автоматические и автономные элементы приложения или аналитические микросервисы реального времени. Это особенно захватывает воображения — кнопки и элементы интерфейса могли бы сами оценивать поведение пользователя и влияние разных факторов на весь пользовательский путь и его бизнес метрики — конверсию, средний чек, вовлеченность и retention. Это открывает возможность без вмешательства человека определить ценность отдельных элементов в плане повышения заказов или лояльности клиентов, причем отдельные этапы аналитики просто не используются, поскольку процесс автоматизирован. Кнопки сами себя регулируют, имея пробрасываемые сигналы от других кнопок в пользовательском пути и от центрального регулятора, они постоянно оптимизируют свое поведение.

На определенном уровне этот момент можно сравнить с саморегуляцией жизнедеятельности живого организма. В нем есть самостоятельные агенты — отдельные клетки, позволяющие целому организму саморегулироваться. Что касается приложений, можно представить себе ситуацию, когда экосистема компонентов интерфейса регулирует друг друга, считывая траектории пользователей и обмениваясь важной информацией, такой как сегменты и типы пользователей и их опыт взаимодействия с пользователями в прошлом. Такой набор умных компонентов мы называем Business Driven Intellectual Agents и сейчас на базе наших исследований мы собираем экспериментальный прототип такого подхода. Вероятно первое время он будет играть чисто исследовательскую функцию и вдохновлять нас и другие команды разработать полноценный framework, совместимый с распространенными платформами построения интерфейсов — React JS, Java, Kotlin и Swift.
Пока же такой технологии нет, но ее появления можно ожидать не только от нас буквально со дня на день. Скорее всего она будет выглядеть как фреймворк или SDK для predictive UI интерфейса. Подобную технологию мы демонстрировали на Yandex Data Driven 2019 на примере модификации Kickstarter приложения, когда на клиенте сериализованная модель считала вероятность потери пользователя и осуществляла условный рендеринг элементов интерфейса в зависимости от нее.
Как будет выглядеть продуктовая аналитика через 20 лет? На самом деле, уже сейчас сама отрасль, где все или почти все делается вручную, устарела. Да, появляются новые инструменты, которые позволяют увеличить эффективность работы. Но все равно все это слишком медленно и неповоротливо, в современных условиях нужно работать быстрее. Обнаружение и исправление проблем в будущем должно происходить автономно.
Вполне вероятно, что приложения будут «учиться друг у друга». Так, например, приложение, которое используется раз в месяц, сможет перенимать актуальные для него модели пользователей их предпочтения к эмбедингам CJM у другого приложения, которое используется ежедневно. В этом случае скорость развития первого приложения может значительно вырасти.
Внутри самой аналитики, хорошо поставленных задач на автоматизацию аналитических пайплайнов пока очень мало, почти всюду аналитики воюют с плохой разметкой данных или нечетко поставленными бизнес целями. Но постепенно, по мере проникновения разработки внутрь аналитики, применения ML внутри аналитики сугубо для решения аналитических задач, а также по мере цифровизации HR и более корректного переноса целей и задач между отделами, ландшафт продуктовой аналитики начнет сильно меняться и характерные задачи будут автоматизированы. А обмен инсайтами и методами превратится в обмен кодом и настройку автономных агентов, выполняющих роль гибкого интерфейса для пользователя и оптимизирующего бизнес робота для компании. Конечно, все это наступит еще не скоро, но задел на будущее уже есть, так что само будущее продуктовой аналитики где-то рядом.
Комментариев нет:
Отправить комментарий