
Итак, Edition-Based Redefinition. Почему у нас вообще возникла такая необходимость в изучении данной технологии, причем здесь термин «высокая доступность» и как Edition-Based Redefinition поможет нам как Oracle-разработчикам экономить время?
Что предложено в качестве решения корпорацией Oracle? Что же творится на задворках при применении данной технологии, с какими проблемами мы столкнулись… В общем, вопросов много. Ответить на них я постараюсь в двух постах по теме, и первый из них — уже под катом.
Каждая команда разработчиков, создавая свое приложение, стремится сделать максимально доступный, максимально отказоустойчивый, максимально надежный алгоритм. Почему мы все к этому стремимся? Наверное, не потому, что мы с вами такие хорошие и хотим выпустить классный продукт. Точнее, не только потому, что мы с вами такие хорошие. Это также важно для бизнеса. Несмотря на то, что мы можем написать крутой алгоритм, покрыть его unit-тестами, посмотреть, что он отказоустойчив, у нас все равно (у Oracle-разработчиков) есть проблема — мы сталкиваемся с необходимостью апгрейдить наши приложения. Например, наши коллеги в системе лояльности вынуждены это вообще делать по ночам.
Если бы это происходило на лету, пользователи бы видели у себя картинку: «Извините пожалуйста!», «Не грустите!», «Подождите, у нас тут обновления и технические работы». Почему же это так важно для бизнеса? А очень просто — бизнес уже давно в свои потери закладывает не только потери реальных каких-то товаров, материальных ценностей, но и потери от простоя инфраструктуры. Например, по данным журнала Forbes, еще в 13 году одна минута простоя сервиса Amazon стоила тогда 66 тысяч долларов. То есть, за полчаса ребята потеряли практически 2 млн долларов.
Понятно, что для среднего и малого бизнеса, а не для такого гиганта как Amazon, эти количественные характеристики будут значительно меньше, но тем не менее, в относительном эквиваленте, это по-прежнему остается значительной оценочной характеристикой.
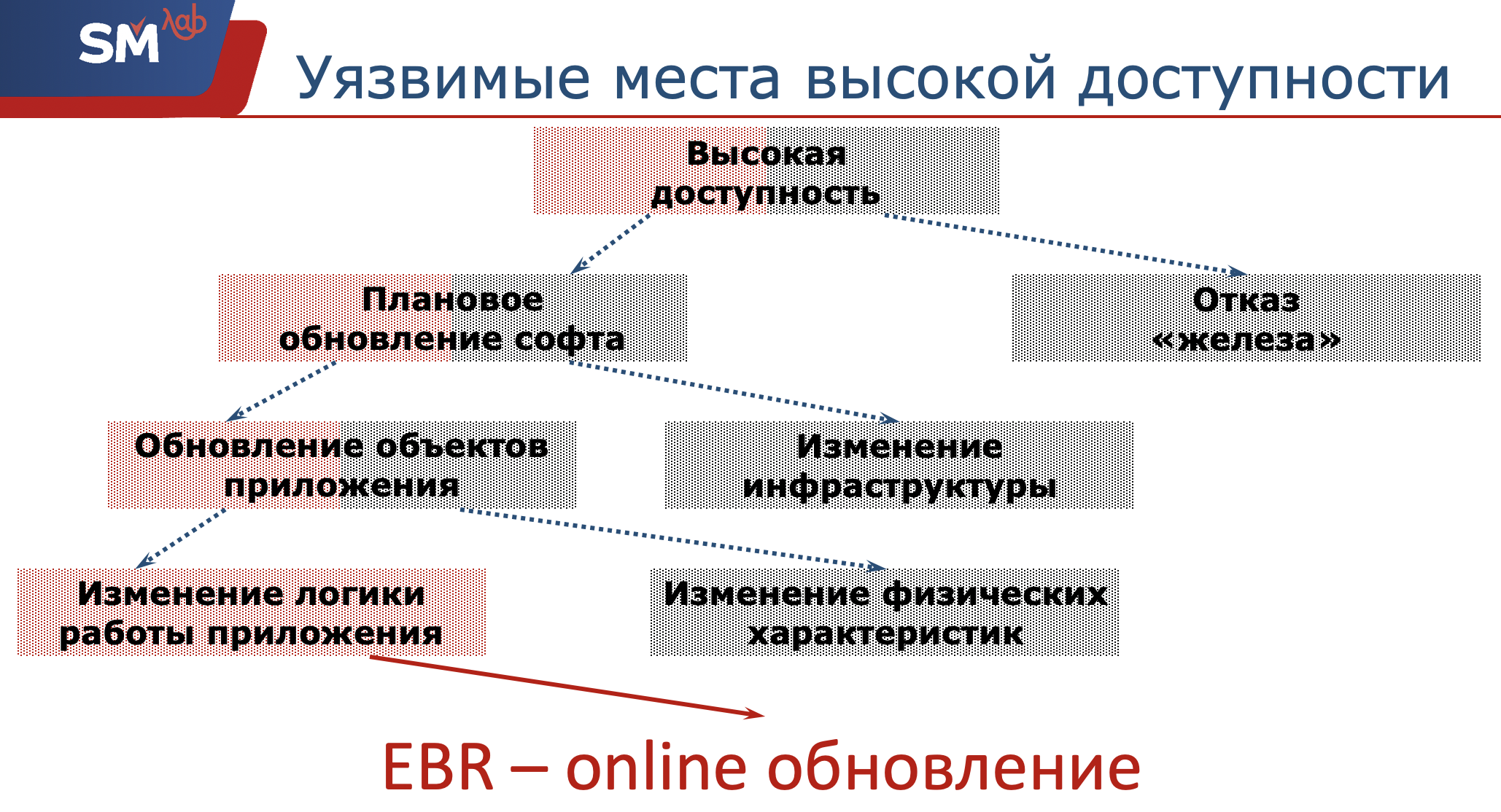
Итак, нам необходимо обеспечить высокую доступность нашего приложения. Какие же потенциально опасные места есть для этой доступности у Oracle-разработчиков?
Перво-наперво, у нас может отказать железо. Мы как разработчики за это не отвечаем. Сетевые администраторы должны обеспечить работоспособность сервера и структурных объектов. То, к чему мы с вами ведем, это апгрейд софта. Опять же, плановые обновления ПО можно разделить на два класса. Либо у нас происходит изменение какой-то инфраструктуры, например, обновляется операционка, на которой крутится сервер. Либо мы решили переехать на новый релиз Oracle (хорошо бы мы успешно на него переехали :) )… Либо, второй класс, это то, к чему мы имеем максимальное отношение — это обновление объектов приложения, которое мы с вами разрабатываем.
Опять же, это обновление можно разделить еще на два класса.
Либо мы меняем какие-то физические характеристики данного объекта (я думаю, что каждый Oracle-разработчик иногда сталкивался с тем, что у него индекс упал, приходилось индекс на лету перестраивать). Или, допустим, мы вводили новые секции в наши таблицы, то есть никакой остановки не произойдет. А то самое проблемное место — это изменение логики работы приложения.
Так при чем же здесь Edition-Based Redefinition? А эта технология — она как раз-таки о том, как обновить приложение онлайн, на лету, не затронув при этом работу пользователей.

Какие же требования выдвигаются к этому самому онлайн-обновлению? Мы должны сделать это незаметно для пользователя, то есть все должно остаться в работоспособном состоянии, все приложения. При условии, что у нас может произойти такая ситуация, когда пользователь сел, начал работать и резко вспомнил, что у него срочное совещание, либо ему нужно машину на сервис отвезти. Он встал, выбежал из-за своего рабочего места. А мы в это время как-то обновили наше приложение, изменилась логика работы, у нас уже подконнектились новые пользователи, начали по-новому обрабатываться данные. Так вот, нам необходимо в конечном итоге обеспечить обмен данными между исходной версией приложения и новой версией приложения. Вот они, два требования, которые выдвигаются к онлайн-обновлениям.

Что же предложено в качестве решения? Начиная с версии 11.2 Release Oracle появляется технология Edition-Based Redefenition и вводятся такие понятия как edition, editionable objects, editioning view, cross-edition trigger. Мы позволили себе такой перевод как “версионирование”. Вообще технологию EBR с некоторой натяжкой можно было бы назвать версионированием объектов СУБД внутри самой СУБД.
Так что же такое Edition как сущность?
Это некий своеобразный контейнер, внутри которого можно изменять и устанавливать код. Внутри собственной области видимости, внутри собственной версии. При этом данные будут изменяться и записываться только в те структуры, которые видны в текущем Edition. За это будут отвечать версионирующие представления, и их работу мы рассмотрим далее.

Это то, как примерно выглядит технология снаружи. Как же это работает? Для начала — на уровне кода. У нас будет наше с вами исходное приложение, версия 1, в котором есть какие-то алгоритмы, обрабатывающие наши данные. Когда мы понимаем, что нам необходимо произвести апгрейд, при создании нового edition происходит следующее: все объекты, обрабатывающие код, наследуются в новый edition… При этом в этой только что созданной песочнице мы можем развлекаться как хотим, незаметно для пользователя: можем изменить работу какой-то функции, процедуры; изменить работу пакета; мы можем даже отказаться от использования какого-то объекта.
Что при этом произойдет? Исходная версия остается неизменной, она остается доступной пользователю и весь функционал доступен. В той версии, которую создали мы, в новом еdition, те объекты, которые не были изменены — остались неизменными, то есть, унаследованные из исходной версии приложения. С тем блоком, которой мы с вами затронули, происходит актуализация объектов в новой версии. И естественно, при удалении какого-то объекта, он нам недоступен в новой версии нашего приложения, но при этом остается функционален в исходной версии.Вот так просто это работает на уровне кода.

Что же происходит со структурами данных и при чем здесь версионирующее представление?

Поскольку под структурами данных будем понимать таблицу, а версионирующее представление, это, по сути дела, оболочка ( я назвала для себя этологической “смотрелкой” на нашу таблицу), представляющую собой проекцию на исходные колонки. Когда же мы с вами понимаем, что нам необходимо изменить работу нашего приложения, и, допустим, как-то добавить колонки в таблицу, либо вообще запретить их использование, мы создаем новое версионирующее представление в нашей новой версии.

Соответственно, в ней мы будем задействовать только тот набор колонок, который нам необходим, который мы будем обрабатывать. Итак, в исходной версии приложения данные пишутся в тот набор, который определен в этой области видимости. Новое приложение будет писать в тот набор колонок, который определен в его области видимости.

Со структурами понятно, но что же происходит с данными? И как все это связано между собой, У нас были данные, хранились в исходных структурах. Когда мы понимаем, что у нас некий алгоритм, позволяющий преобразовать данные из исходной структуры и разложить эти данные в новой структуре, этот алгоритм можно положить в так называемые кросс-версионные триггеры. Они как раз направлены на то, чтобы видеть структуры из разных версий приложения. То есть, при условии наличия такого алгоритма, мы можем его повесить на таблицу. При этом будет происходить трансформация данных из исходных структур в новые, и за это будут отвечать прогрессивные форвард-триггеры. При условии, что нам необходимо обеспечить перенос данных в старую версию, опять же, на основе какого-то алгоритма, за это будут отвечать реверсивные триггеры.
Что происходит, когда мы определились, что у нас изменилась структура данных и мы готовы работать уже в параллельном режиме и для старой версии приложения, и для новой версии приложения? Мы просто можем инициализировать заполнение новых структур каким-то холостым апдейтом. После этого обе наших версии приложения становятся доступны для использования пользователю. Функционал остается для старых пользователей из старой версии приложения, для новых пользователей функционал будет из новой версии приложения.
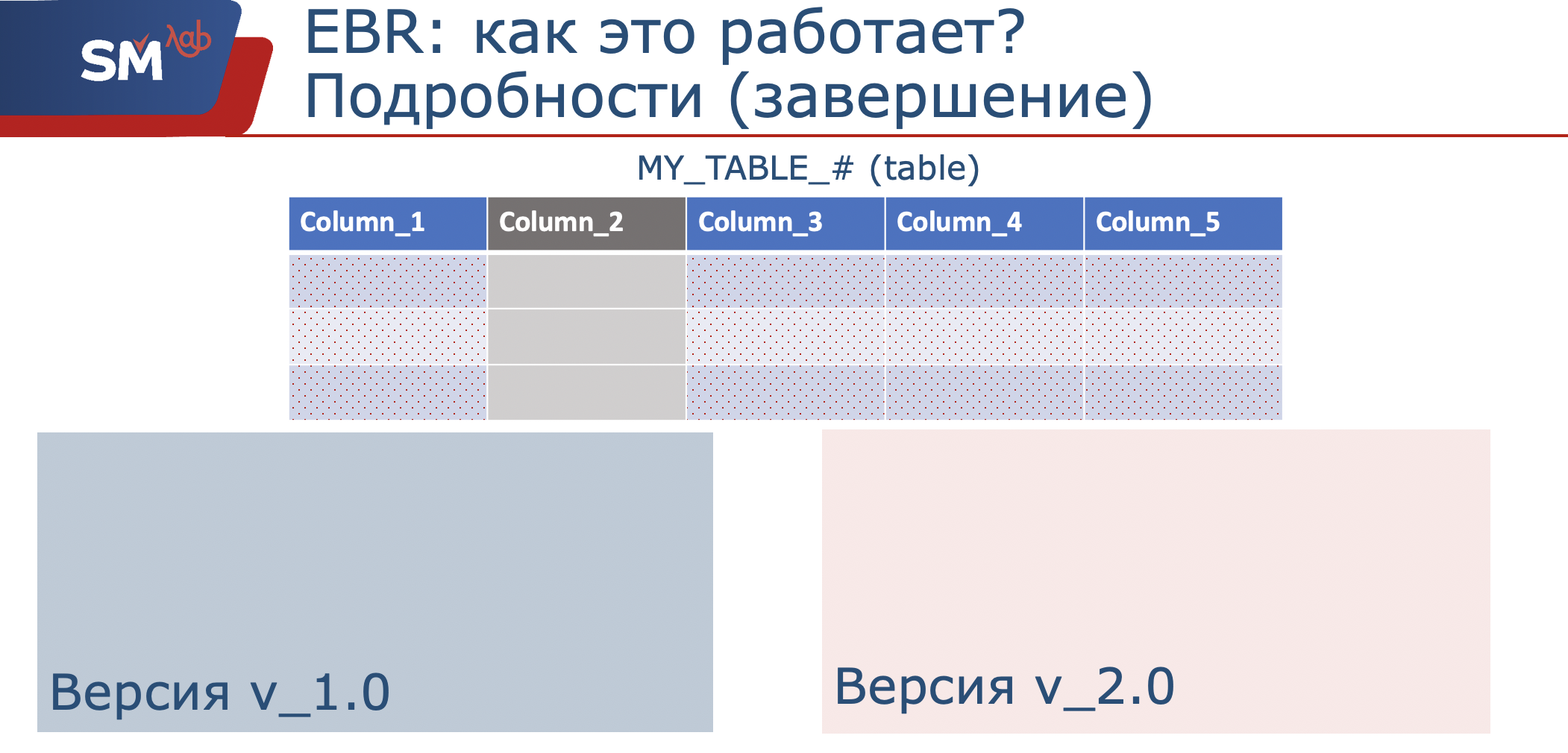
Когда мы поняли, что пользователи от старого приложения все отконнектились, эта версия может быть скрыта из использования. Возможно даже изменена структура данных. Мы помним, что у нас версионирующее представление в новой созданной версии будет уже смотреть только на набор колонок 1, 3,4,5. Ну и соответственно, если у нас нет необходимости в этой структуре, ее можно удалить. Вот примерно вкратце как это работает.

Какие же ограничения наложены? То есть, молодцы Oracle, отлично Oracle, прекрасно Oracle: придумали классную штуку. Первое ограничение на сегодняшний момент — объекты версионируемого типа, это PL/SQL-объекты, то есть процедуры, пакеты, функции, триггеры и так далее. Версионируются синонимы и версионируются представления.
Что не версионируется и никогда не будет версионироваться — это таблицы и индексы, материализованные представления. То есть, в первом варианте мы с вами изменяем только метаданные и можем хранить их копий сколько угодно… на самом деле, ограниченное количество копий этих метаданных, но об этом чуть позже. Второе касается пользовательских данных, и репликация их потребовала бы большого дискового пространства, что не есть логично и есть очень дорого.

Следующее ограничение — это объекты схемы будут версионированы в полной мере, тогда и только тогда, когда они будут принадлежать версионно-полномоченному пользователю. На самом деле, эти полномочия для пользователя — это просто некоторая пометочка в базе. Предоставить эти полномочия можно обычной командой. Но обращаю ваше внимание, что данное действие является необратимым. Следовательно, давайте не будем сразу, засучив рукава, все это набирать на боевом сервере, а сначала потестируемся.
Следующее ограничение — это неверсионные объекты не могут зависеть от версионированных. Ну, вполне логично. Мы как минимум, не будем понимать, в какую редакцию, в какую версию объекта смотреть. Вот на этом пункте хотелось бы заострить внимание, потому что нам пришлось побороться с этим моментом.
Далее. Версионирующие представления принадлежат владельцу схем, владельцу таблиц и единственно в каждой версии. По сути своей, версионирующее представление является оболочкой таблицы, поэтому вполне понятно, что должно быть единственной в каждой версии приложения.
Что еще немаловажно, количество версий в иерархии может быть 2000. Скорее всего, это связано с тем, чтобы не нагружать как-то сильно словарик. Я говорила изначально, что объекты, при создания нового edition, наследуются. Сейчас эта иерархия выстраивается исключительно линейная — один родитель, один потомок. Возможно, будет какая-то древовидная структура, какие-то предпосылки к этому я вижу в том, что можно задать команду создания версии как наследник от конкретного edition. На текущий момент это строго линейная иерархия, и количество звеньев в этой создаваемой цепочке равно 2000.
Понятно, что при частых каких-то апгрейдах нашего приложения это количество можно было бы исчерпать или перешагнуть, но начиная с 12 релиза Oracle крайние edition, созданные в данной цепочке, можно резать при условии того, что они более не используются.

Надеюсь, вам теперь примерно понятно, как это функционирует. Если определились — “Да, мы хотим это потрогать” — что же нужно сделать, чтобы перейти на использование данной технологии?
Перво-наперво, нужно определить стратегию использования. О чем это? Понять, как часто у нас сменяются структуры наших таблиц, потребуется ли нам использование версионирующих представлений, тем более, потребуются ли нам кросс-версионные триггеры для обеспечения изменения данных. Либо мы будем только версионировать наш PL/SQL-код. В нашем случае, когда мы тестировались, мы смотрели, что у нас все-таки таблицы меняются, поэтому мы наверное будем использовать также и версионирующие представления.
Далее, естественно, выбранной схеме предоставляются версионные полномочия.
После этого мы производим переименование таблицы. Для чего это делается? Как раз для того, чтобы защитить наши объекты PL/SQL кода от модификации таблиц.
Нашим таблицам мы решили подкидывать в конец символ диеза, учитывая 30-символьное ограничения. После этого создаются версионирующие представления с исходным именем таблиц. И уже они будут использоваться внутри кода. Важно, чтобы в первой версии, на которую мы переезжаем, версионирующее представление представляла собой полный набор колонок исходной таблицы, потому что объекты PL/SQL-кода могут обращаться как раз таки ко всем этим колонкам.
После этого мы перевешиваем DML-триггеры с таблиц на версионирующие представления (да, версионирующие представления позволяют нам повесить на них триггеры). Возможно, отзываем гранты от таблиц и выдаем их вновь созданным представлениям… По идее этих всех пунктов достаточно, нам остается перекомпилировать PL/SQL код и зависимые представления.
И-и-и-и-и… Естественно, тесты, тесты и еще как можно больше тестов. Почему тесты? Ведь не могло быть все так просто. Обо что же мы споткнулись?
Именно об этом и будет мой второй пост.
Комментариев нет:
Отправить комментарий